 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised detection of ash dieback disease (Hymenoscyphus fraxineus) using diffusion-based hyperspectral image clustering
Apr 19, 2022
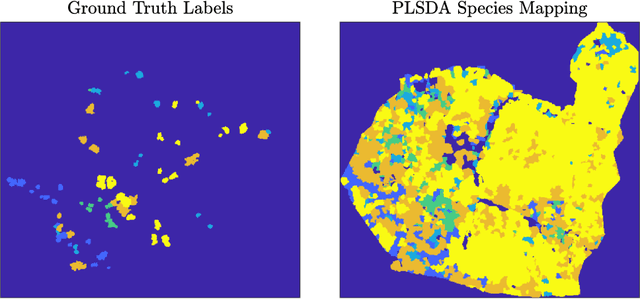

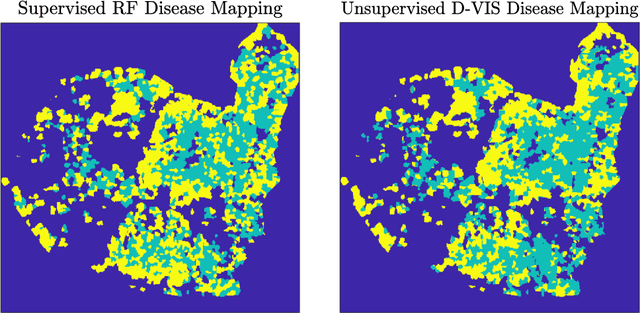
Ash dieback (Hymenoscyphus fraxineus) is an introduced fungal disease that is causing the widespread death of ash trees across Europe. Remote sensing hyperspectral images encode rich structure that has been exploited for the detection of dieback disease in ash trees using supervised machine learning techniques. However, to understand the state of forest health at landscape-scale, accurate unsupervised approaches are needed. This article investigates the use of the unsupervised Diffusion and VCA-Assisted Image Segmentation (D-VIS) clustering algorithm for the detection of ash dieback disease in a forest site near Cambridge, United Kingdom. The unsupervised clustering presented in this work has high overlap with the supervised classification of previous work on this scene (overall accuracy = 71%). Thus, unsupervised learning may be used for the remote detection of ash dieback disease without the need for expert labeling.
Im2Oil: Stroke-Based Oil Painting Rendering with Linearly Controllable Fineness Via Adaptive Sampling
Sep 27, 2022



This paper proposes a novel stroke-based rendering (SBR) method that translates images into vivid oil paintings. Previous SBR techniques usually formulate the oil painting problem as pixel-wise approximation. Different from this technique route, we treat oil painting creation as an adaptive sampling problem. Firstly, we compute a probability density map based on the texture complexity of the input image. Then we use the Voronoi algorithm to sample a set of pixels as the stroke anchors. Next, we search and generate an individual oil stroke at each anchor. Finally, we place all the strokes on the canvas to obtain the oil painting. By adjusting the hyper-parameter maximum sampling probability, we can control the oil painting fineness in a linear manner. Comparison with existing state-of-the-art oil painting techniques shows that our results have higher fidelity and more realistic textures. A user opinion test demonstrates that people behave more preference toward our oil paintings than the results of other methods. More interesting results and the code are in https://github.com/TZYSJTU/Im2Oil.
Scale-Net: Learning to Reduce Scale Differences for Large-Scale Invariant Image Matching
Dec 20, 2021
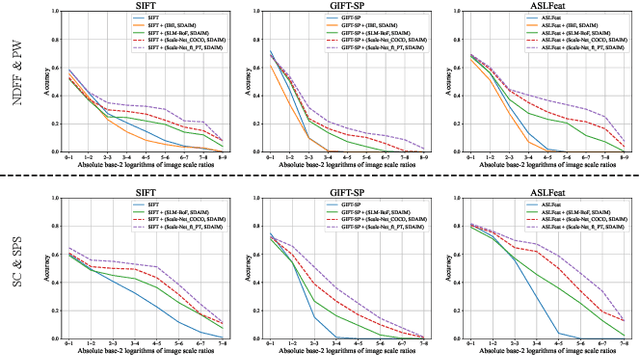

Most image matching methods perform poorly when encountering large scale changes in images. To solve this problem, firstly, we propose a scale-difference-aware image matching method (SDAIM) that reduces image scale differences before local feature extraction, via resizing both images of an image pair according to an estimated scale ratio. Secondly, in order to accurately estimate the scale ratio, we propose a covisibility-attention-reinforced matching module (CVARM) and then design a novel neural network, termed as Scale-Net, based on CVARM. The proposed CVARM can lay more stress on covisible areas within the image pair and suppress the distraction from those areas visible in only one image. Quantitative and qualitative experiments confirm that the proposed Scale-Net has higher scale ratio estimation accuracy and much better generalization ability compared with all the existing scale ratio estimation methods. Further experiments on image matching and relative pose estimation tasks demonstrate that our SDAIM and Scale-Net are able to greatly boost the performance of representative local features and state-of-the-art local feature matching methods.
Self-adversarial Multi-scale Contrastive Learning for Semantic Segmentation of Thermal Facial Images
Sep 21, 2022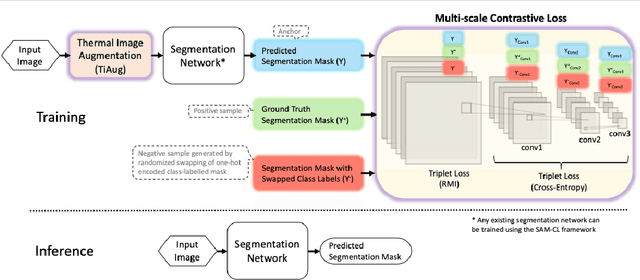
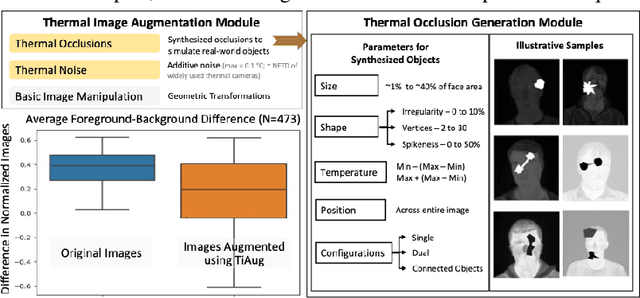
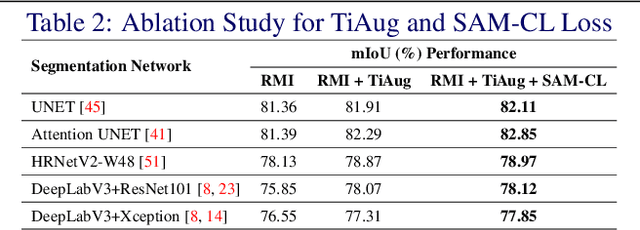
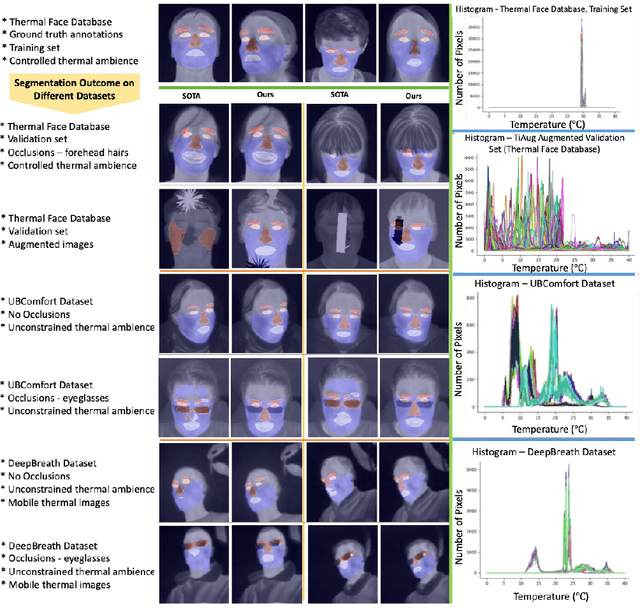
Reliable segmentation of thermal facial images in unconstrained settings such as thermal ambience and occlusions is challenging as facial features lack salience. Limited availability of datasets from such settings further makes it difficult to train segmentation networks. To address the challenge, we propose Self-Adversarial Multi-scale Contrastive Learning (SAM-CL) as a generic learning framework to train segmentation networks. SAM-CL framework constitutes SAM-CL loss function and a thermal image augmentation (TiAug) as a domain-specific augmentation technique to simulate unconstrained settings based upon existing datasets collected from controlled settings. We use the Thermal-Face-Database to demonstrate effectiveness of our approach. Experiments conducted on the existing segmentation networks- UNET, Attention-UNET, DeepLabV3 and HRNetv2 evidence the consistent performance gain from the SAM-CL framework. Further, we present a qualitative analysis with UBComfort and DeepBreath datasets to discuss how our proposed methods perform in handling unconstrained situations.
D3C2-Net: Dual-Domain Deep Convolutional Coding Network for Compressive Sensing
Jul 27, 2022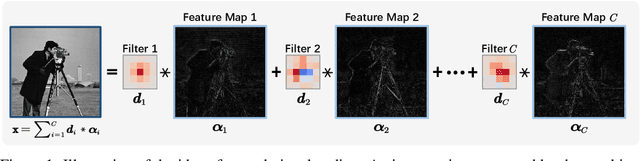

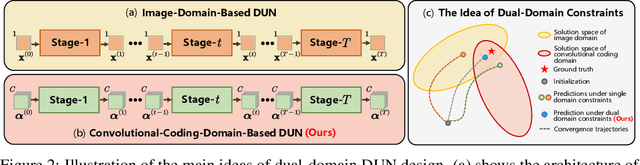
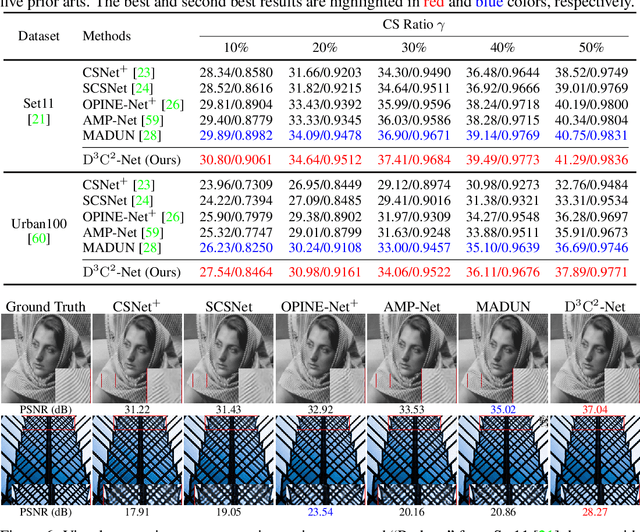
Mapping optimization algorithms into neural networks, deep unfolding networks (DUNs) have achieved impressive success in compressive sensing (CS). From the perspective of optimization, DUNs inherit a well-defined and interpretable structure from iterative steps. However, from the viewpoint of neural network design, most existing DUNs are inherently established based on traditional image-domain unfolding, which takes one-channel images as inputs and outputs between adjacent stages, resulting in insufficient information transmission capability and inevitable loss of the image details. In this paper, to break the above bottleneck, we first propose a generalized dual-domain optimization framework, which is general for inverse imaging and integrates the merits of both (1) image-domain and (2) convolutional-coding-domain priors to constrain the feasible region in the solution space. By unfolding the proposed framework into deep neural networks, we further design a novel Dual-Domain Deep Convolutional Coding Network (D3C2-Net) for CS imaging with the capability of transmitting high-throughput feature-level image representation through all the unfolded stages. Experiments on natural and MR images demonstrate that our D3C2-Net achieves higher performance and better accuracy-complexity trade-offs than other state-of-the-arts.
Fusing Convolutional Neural Network and Geometric Constraint for Image-based Indoor Localization
Jan 05, 2022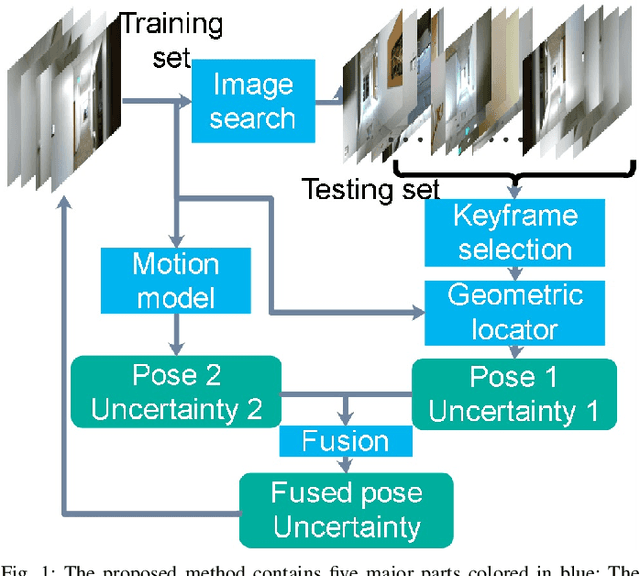
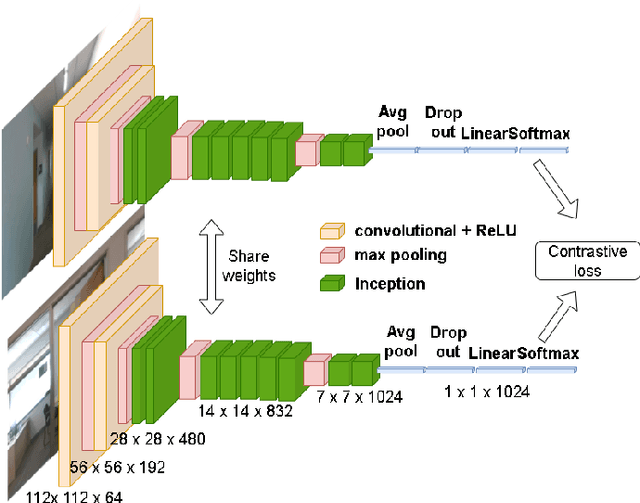
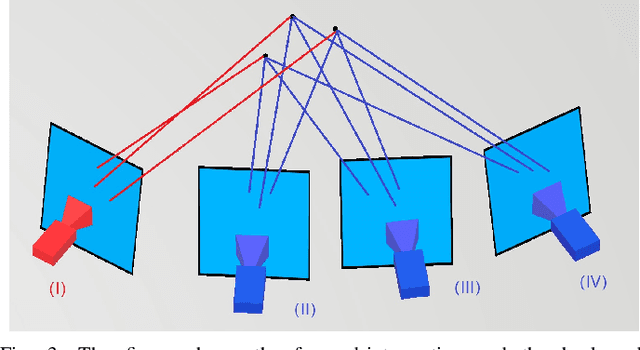

This paper proposes a new image-based localization framework that explicitly localizes the camera/robot by fusing Convolutional Neural Network (CNN) and sequential images' geometric constraints. The camera is localized using a single or few observed images and training images with 6-degree-of-freedom pose labels. A Siamese network structure is adopted to train an image descriptor network, and the visually similar candidate image in the training set is retrieved to localize the testing image geometrically. Meanwhile, a probabilistic motion model predicts the pose based on a constant velocity assumption. The two estimated poses are finally fused using their uncertainties to yield an accurate pose prediction. This method leverages the geometric uncertainty and is applicable in indoor scenarios predominated by diffuse illumination. Experiments on simulation and real data sets demonstrate the efficiency of our proposed method. The results further show that combining the CNN-based framework with geometric constraint achieves better accuracy when compared with CNN-only methods, especially when the training data size is small.
FETA: Towards Specializing Foundation Models for Expert Task Applications
Sep 08, 2022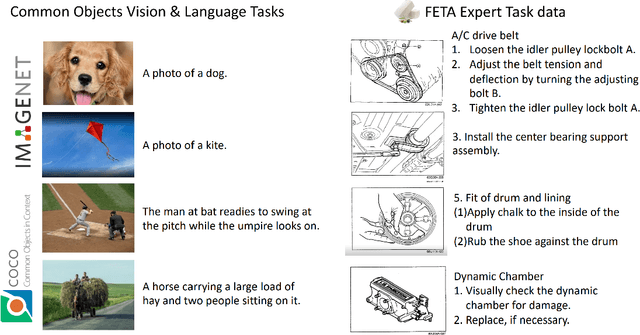

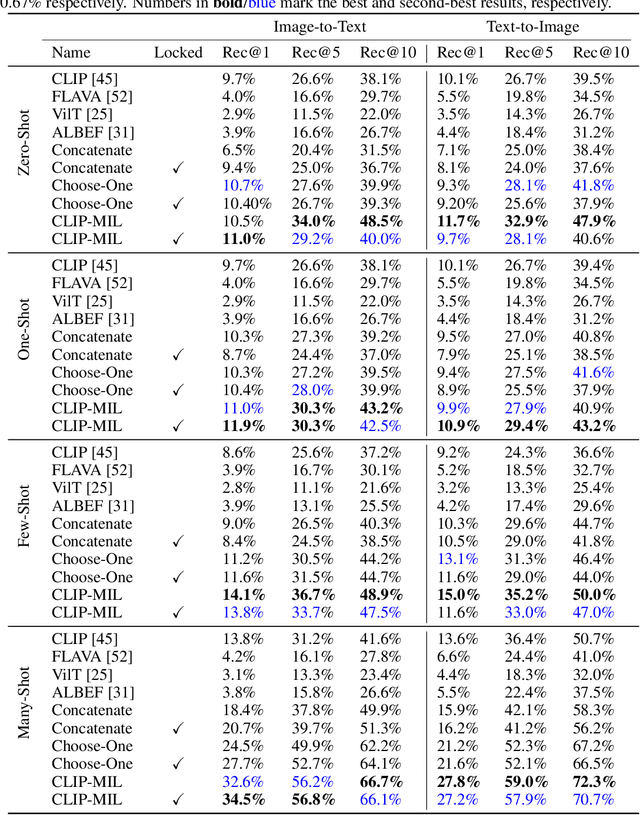
Foundation Models (FMs) have demonstrated unprecedented capabilities including zero-shot learning, high fidelity data synthesis, and out of domain generalization. However, as we show in this paper, FMs still have poor out-of-the-box performance on expert tasks (e.g. retrieval of car manuals technical illustrations from language queries), data for which is either unseen or belonging to a long-tail part of the data distribution of the huge datasets used for FM pre-training. This underlines the necessity to explicitly evaluate and finetune FMs on such expert tasks, arguably ones that appear the most in practical real-world applications. In this paper, we propose a first of its kind FETA benchmark built around the task of teaching FMs to understand technical documentation, via learning to match their graphical illustrations to corresponding language descriptions. Our FETA benchmark focuses on text-to-image and image-to-text retrieval in public car manuals and sales catalogue brochures. FETA is equipped with a procedure for completely automatic annotation extraction (code would be released upon acceptance), allowing easy extension of FETA to more documentation types and application domains in the future. Our automatic annotation leads to an automated performance metric shown to be consistent with metrics computed on human-curated annotations (also released). We provide multiple baselines and analysis of popular FMs on FETA leading to several interesting findings that we believe would be very valuable to the FM community, paving the way towards real-world application of FMs for practical expert tasks currently 'overlooked' by standard benchmarks focusing on common objects.
Learning True Rate-Distortion-Optimization for End-To-End Image Compression
Jan 05, 2022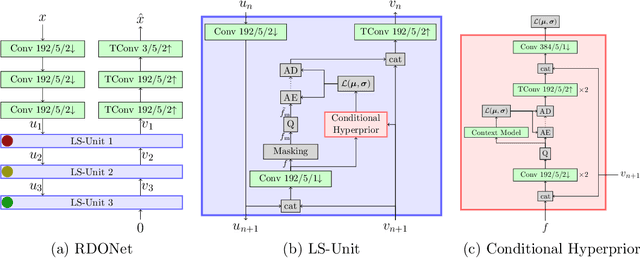
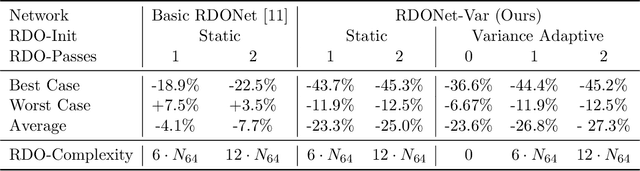


Even though rate-distortion optimization is a crucial part of traditional image and video compression, not many approaches exist which transfer this concept to end-to-end-trained image compression. Most frameworks contain static compression and decompression models which are fixed after training, so efficient rate-distortion optimization is not possible. In a previous work, we proposed RDONet, which enables an RDO approach comparable to adaptive block partitioning in HEVC. In this paper, we enhance the training by introducing low-complexity estimations of the RDO result into the training. Additionally, we propose fast and very fast RDO inference modes. With our novel training method, we achieve average rate savings of 19.6% in MS-SSIM over the previous RDONet model, which equals rate savings of 27.3% over a comparable conventional deep image coder.
Generative Steganography Network
Aug 14, 2022
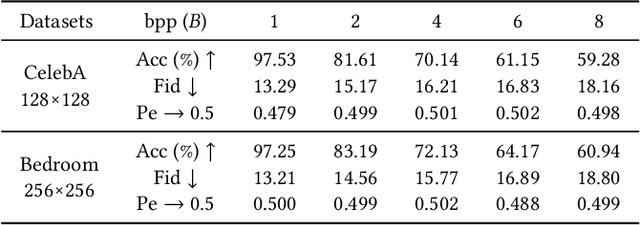
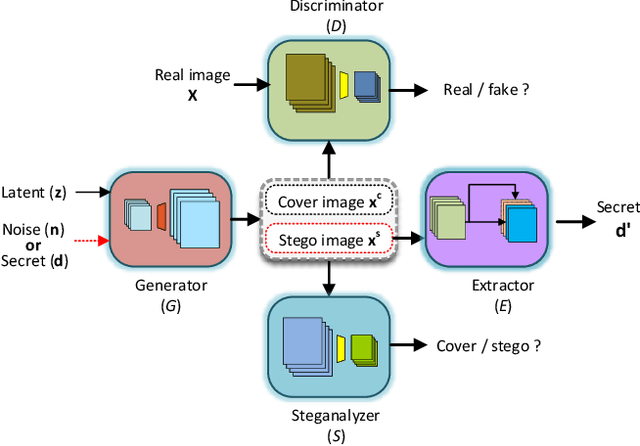
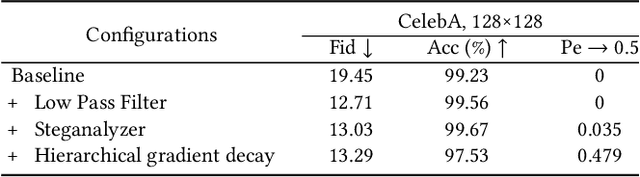
Steganography usually modifies cover media to embed secret data. A new steganographic approach called generative steganography (GS) has emerged recently, in which stego images (images containing secret data) are generated from secret data directly without cover media. However, existing GS schemes are often criticized for their poor performances. In this paper, we propose an advanced generative steganography network (GSN) that can generate realistic stego images without using cover images. We firstly introduce the mutual information mechanism in GS, which helps to achieve high secret extraction accuracy. Our model contains four sub-networks, i.e., an image generator ($G$), a discriminator ($D$), a steganalyzer ($S$), and a data extractor ($E$). $D$ and $S$ act as two adversarial discriminators to ensure the visual quality and security of generated stego images. $E$ is to extract the hidden secret from generated stego images. The generator $G$ is flexibly constructed to synthesize either cover or stego images with different inputs. It facilitates covert communication by concealing the function of generating stego images in a normal generator. A module named secret block is designed to hide secret data in the feature maps during image generation, with which high hiding capacity and image fidelity are achieved. In addition, a novel hierarchical gradient decay (HGD) skill is developed to resist steganalysis detection. Experiments demonstrate the superiority of our work over existing methods.
Maximal Independent Vertex Set applied to Graph Pooling
Aug 02, 2022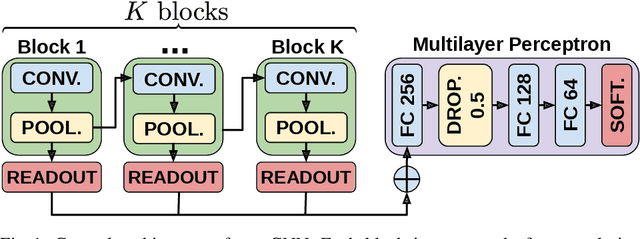
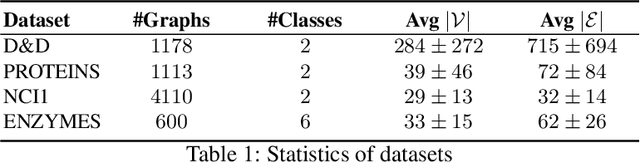
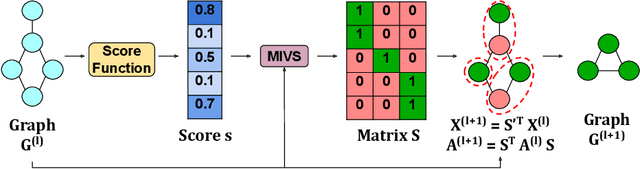

Convolutional neural networks (CNN) have enabled major advances in image classification through convolution and pooling. In particular, image pooling transforms a connected discrete grid into a reduced grid with the same connectivity and allows reduction functions to take into account all the pixels of an image. However, a pooling satisfying such properties does not exist for graphs. Indeed, some methods are based on a vertex selection step which induces an important loss of information. Other methods learn a fuzzy clustering of vertex sets which induces almost complete reduced graphs. We propose to overcome both problems using a new pooling method, named MIVSPool. This method is based on a selection of vertices called surviving vertices using a Maximal Independent Vertex Set (MIVS) and an assignment of the remaining vertices to the survivors. Consequently, our method does not discard any vertex information nor artificially increase the density of the graph. Experimental results show an increase in accuracy for graph classification on various standard datasets.