 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Preserving Privacy in Federated Learning with Ensemble Cross-Domain Knowledge Distillation
Sep 10, 2022
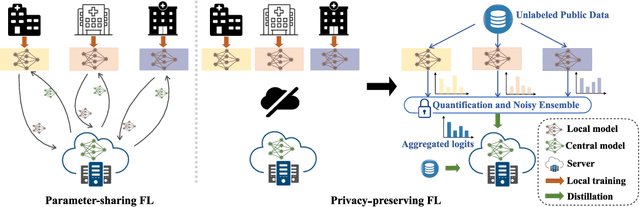
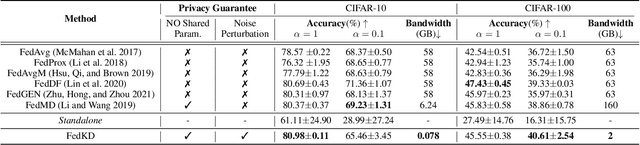
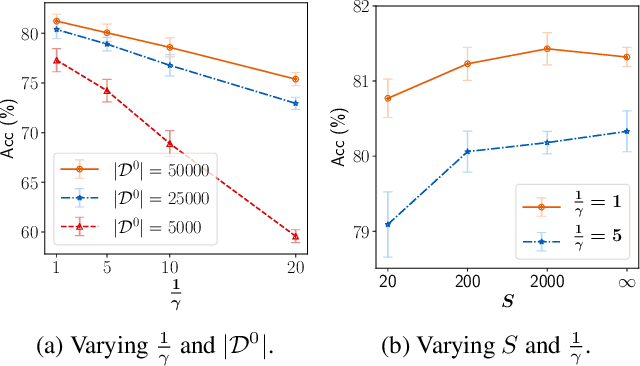
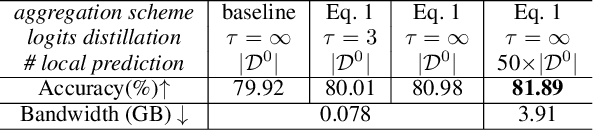
Federated Learning (FL) is a machine learning paradigm where local nodes collaboratively train a central model while the training data remains decentralized. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they suffer from communication bottlenecks. More importantly, they risk privacy leakage. In this work, we develop a privacy preserving and communication efficient method in a FL framework with one-shot offline knowledge distillation using unlabeled, cross-domain public data. We propose a quantized and noisy ensemble of local predictions from completely trained local models for stronger privacy guarantees without sacrificing accuracy. Based on extensive experiments on image classification and text classification tasks, we show that our privacy-preserving method outperforms baseline FL algorithms with superior performance in both accuracy and communication efficiency.
A Secure and Efficient Multi-Object Grasping Detection Approach for Robotic Arms
Sep 08, 2022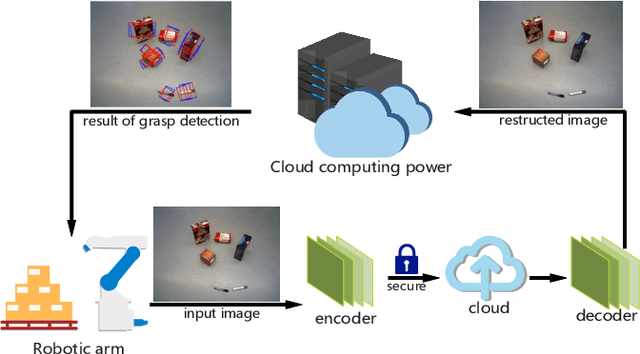



Robotic arms are widely used in automatic industries. However, with wide applications of deep learning in robotic arms, there are new challenges such as the allocation of grasping computing power and the growing demand for security. In this work, we propose a robotic arm grasping approach based on deep learning and edge-cloud collaboration. This approach realizes the arbitrary grasp planning of the robot arm and considers the grasp efficiency and information security. In addition, the encoder and decoder trained by GAN enable the images to be encrypted while compressing, which ensures the security of privacy. The model achieves 92% accuracy on the OCID dataset, the image compression ratio reaches 0.03%, and the structural difference value is higher than 0.91.
Privacy-Preserving Person Detection Using Low-Resolution Infrared Cameras
Sep 22, 2022
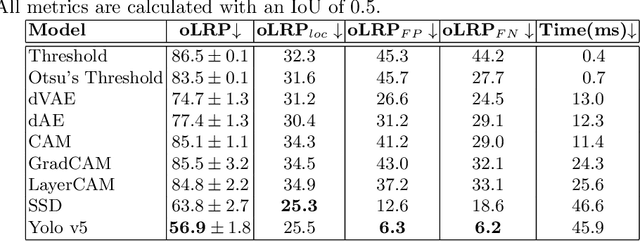
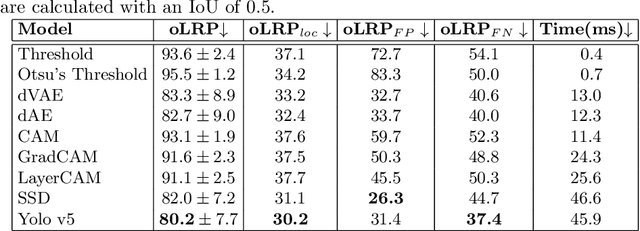
In intelligent building management, knowing the number of people and their location in a room are important for better control of its illumination, ventilation, and heating with reduced costs and improved comfort. This is typically achieved by detecting people using compact embedded devices that are installed on the room's ceiling, and that integrate low-resolution infrared camera, which conceals each person's identity. However, for accurate detection, state-of-the-art deep learning models still require supervised training using a large annotated dataset of images. In this paper, we investigate cost-effective methods that are suitable for person detection based on low-resolution infrared images. Results indicate that for such images, we can reduce the amount of supervision and computation, while still achieving a high level of detection accuracy. Going from single-shot detectors that require bounding box annotations of each person in an image, to auto-encoders that only rely on unlabelled images that do not contain people, allows for considerable savings in terms of annotation costs, and for models with lower computational costs. We validate these experimental findings on two challenging top-view datasets with low-resolution infrared images.
HairCLIP: Design Your Hair by Text and Reference Image
Dec 09, 2021
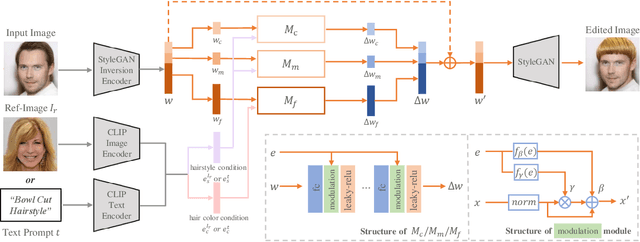
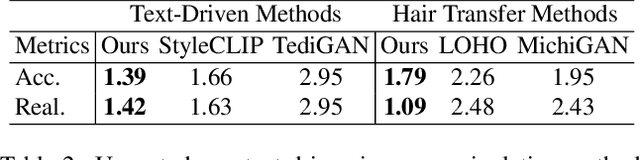

Hair editing is an interesting and challenging problem in computer vision and graphics. Many existing methods require well-drawn sketches or masks as conditional inputs for editing, however these interactions are neither straightforward nor efficient. In order to free users from the tedious interaction process, this paper proposes a new hair editing interaction mode, which enables manipulating hair attributes individually or jointly based on the texts or reference images provided by users. For this purpose, we encode the image and text conditions in a shared embedding space and propose a unified hair editing framework by leveraging the powerful image text representation capability of the Contrastive Language-Image Pre-Training (CLIP) model. With the carefully designed network structures and loss functions, our framework can perform high-quality hair editing in a disentangled manner. Extensive experiments demonstrate the superiority of our approach in terms of manipulation accuracy, visual realism of editing results, and irrelevant attribute preservation. Project repo is https://github.com/wty-ustc/HairCLIP.
A distribution-dependent Mumford-Shah model for unsupervised hyperspectral image segmentation
Mar 28, 2022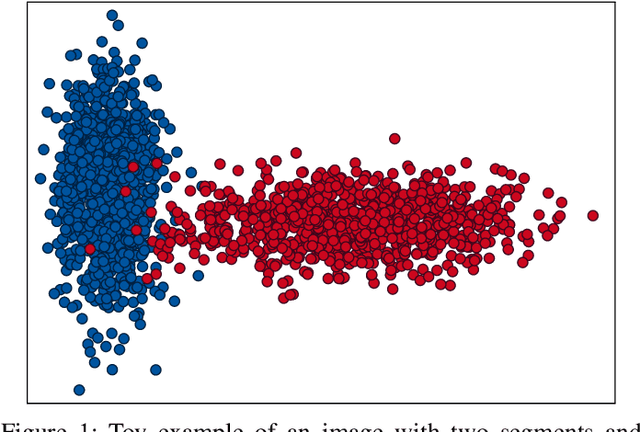
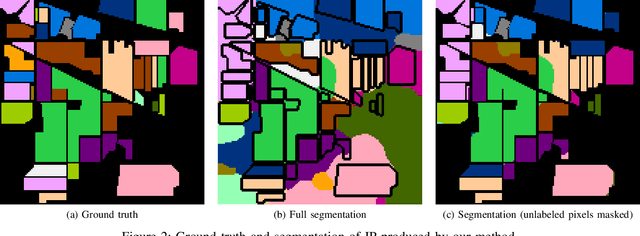
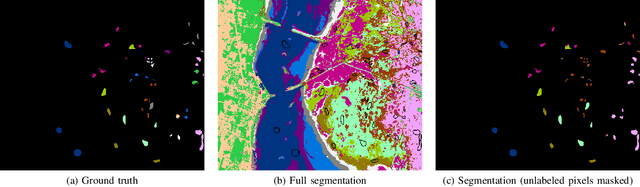
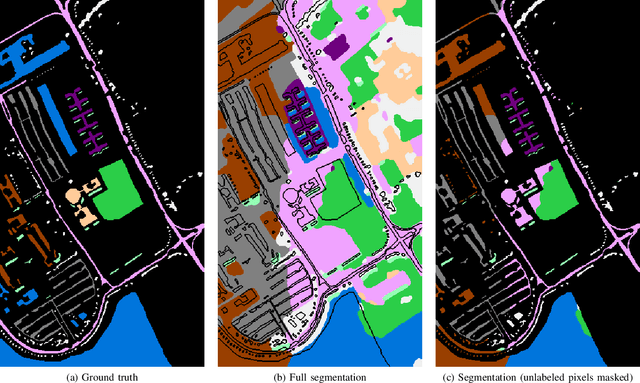
Hyperspectral images provide a rich representation of the underlying spectrum for each pixel, allowing for a pixel-wise classification/segmentation into different classes. As the acquisition of labeled training data is very time-consuming, unsupervised methods become crucial in hyperspectral image analysis. The spectral variability and noise in hyperspectral data make this task very challenging and define special requirements for such methods. Here, we present a novel unsupervised hyperspectral segmentation framework. It starts with a denoising and dimensionality reduction step by the well-established Minimum Noise Fraction (MNF) transform. Then, the Mumford-Shah (MS) segmentation functional is applied to segment the data. We equipped the MS functional with a novel robust distribution-dependent indicator function designed to handle the characteristic challenges of hyperspectral data. To optimize our objective function with respect to the parameters for which no closed form solution is available, we propose an efficient fixed point iteration scheme. Numerical experiments on four public benchmark datasets show that our method produces competitive results, which outperform two state-of-the-art methods substantially on three of these datasets.
The Role Of Biology In Deep Learning
Sep 07, 2022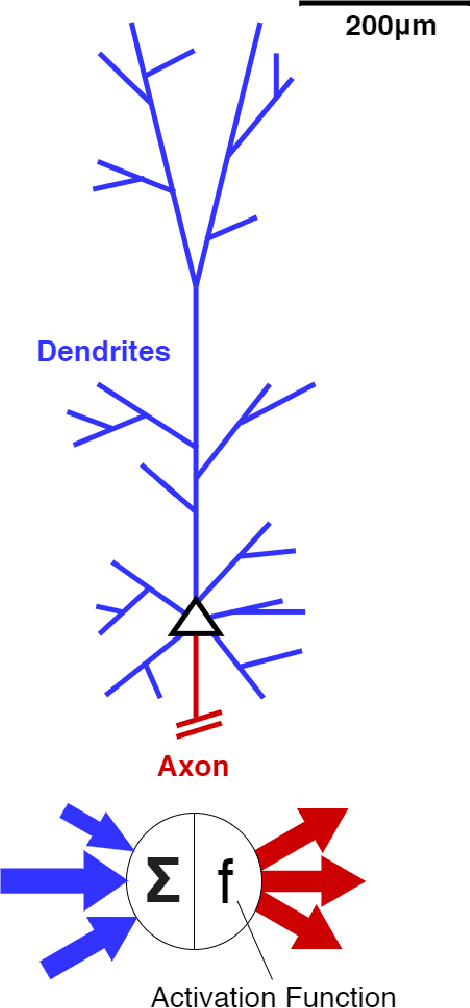
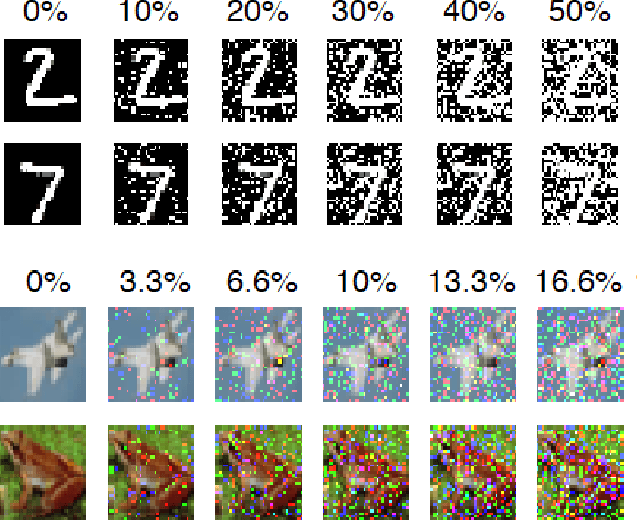
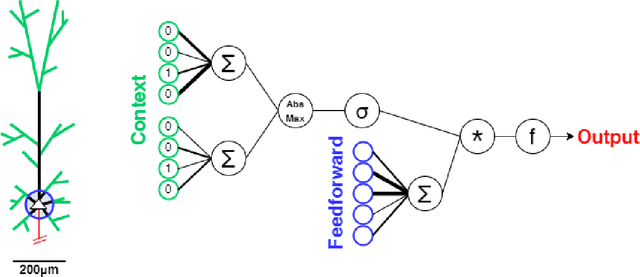
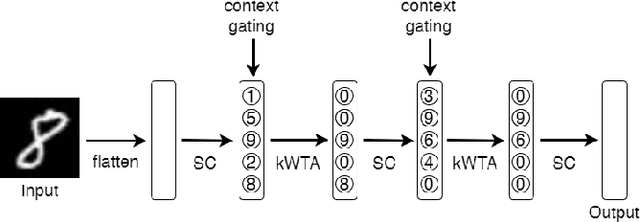
Artificial neural networks took a lot of inspiration from their biological counterparts in becoming our best machine perceptual systems. This work summarizes some of that history and incorporates modern theoretical neuroscience into experiments with artificial neural networks from the field of deep learning. Specifically, iterative magnitude pruning is used to train sparsely connected networks with 33x fewer weights without loss in performance. These are used to test and ultimately reject the hypothesis that weight sparsity alone improves image noise robustness. Recent work mitigated catastrophic forgetting using weight sparsity, activation sparsity, and active dendrite modeling. This paper replicates those findings, and extends the method to train convolutional neural networks on a more challenging continual learning task. The code has been made publicly available.
Automatic Ultrasound Image Segmentation of Supraclavicular Nerve Using Dilated U-Net Deep Learning Architecture
Aug 09, 2022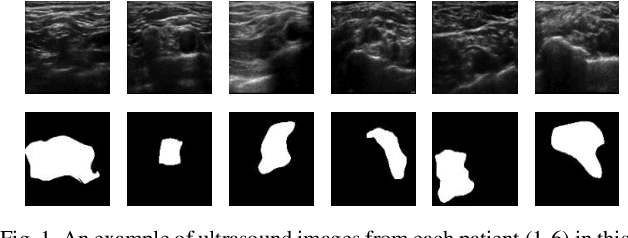
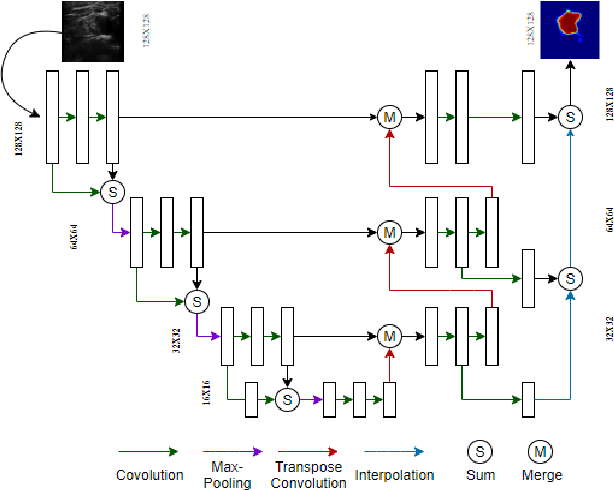
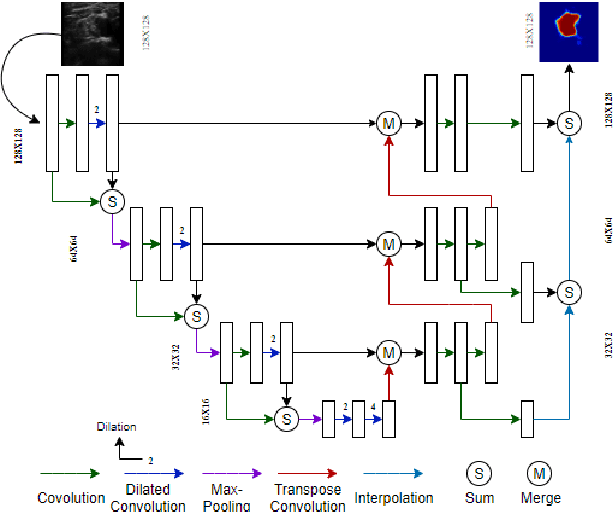

Automated object recognition in medical images can facilitate medical diagnosis and treatment. In this paper, we automatically segmented supraclavicular nerves in ultrasound images to assist in injecting peripheral nerve blocks. Nerve blocks are generally used for pain treatment after surgery, where ultrasound guidance is used to inject local anesthetics next to target nerves. This treatment blocks the transmission of pain signals to the brain, which can help improve the rate of recovery from surgery and significantly decrease the requirement for postoperative opioids. However, Ultrasound Guided Regional Anesthesia (UGRA) requires anesthesiologists to visually recognize the actual nerve position in the ultrasound images. This is a complex task given the myriad visual presentations of nerves in ultrasound images, and their visual similarity to many neighboring tissues. In this study, we used an automated nerve detection system for the UGRA Nerve Block treatment. The system can recognize the position of the nerve in ultrasound images using Deep Learning techniques. We developed a model to capture features of nerves by training two deep neural networks with skip connections: two extended U-Net architectures with and without dilated convolutions. This solution could potentially lead to an improved blockade of targeted nerves in regional anesthesia.
Hierarchical Image Classification with A Literally Toy Dataset
Nov 01, 2021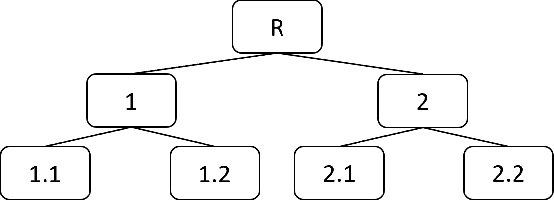
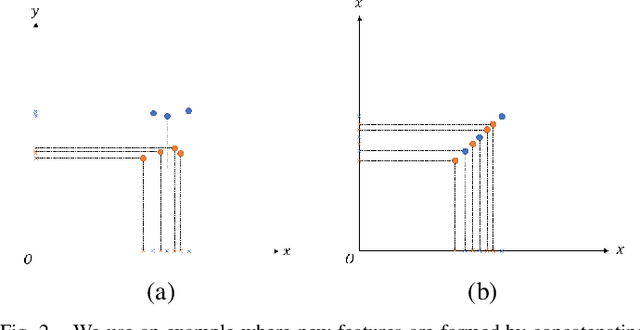
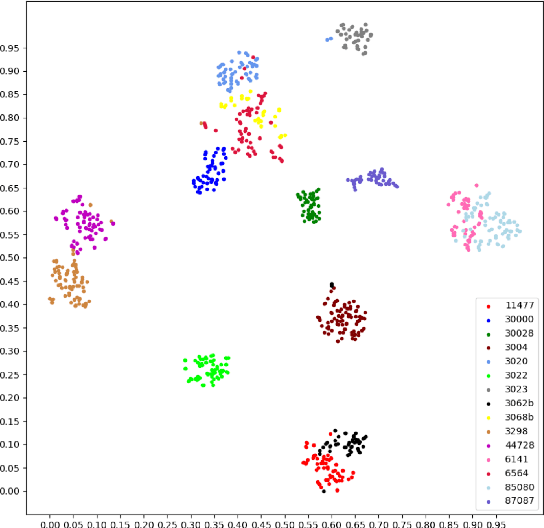
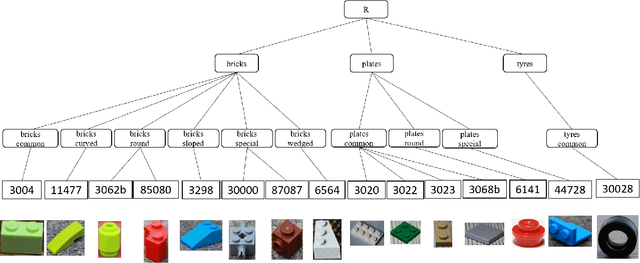
Unsupervised domain adaptation (UDA) in image classification remains a big challenge. In existing UDA image dataset, classes are usually organized in a flattened way, where a plain classifier can be trained. Yet in some scenarios, the flat categories originate from some base classes. For example, buggies belong to the class bird. We define the classification task where classes have characteristics above and the flat classes and the base classes are organized hierarchically as hierarchical image classification. Intuitively, leveraging such hierarchical structure will benefit hierarchical image classification, e.g., two easily confusing classes may belong to entirely different base classes. In this paper, we improve the performance of classification by fusing features learned from a hierarchy of labels. Specifically, we train feature extractors supervised by hierarchical labels and with UDA technology, which will output multiple features for an input image. The features are subsequently concatenated to predict the finest-grained class. This study is conducted with a new dataset named Lego-15. Consisting of synthetic images and real images of the Lego bricks, the Lego-15 dataset contains 15 classes of bricks. Each class originates from a coarse-level label and a middle-level label. For example, class "85080" is associated with bricks (coarse) and bricks round (middle). In this dataset, we demonstrate that our method brings about consistent improvement over the baseline in UDA in hierarchical image classification. Extensive ablation and variant studies provide insights into the new dataset and the investigated algorithm.
NamedMask: Distilling Segmenters from Complementary Foundation Models
Sep 22, 2022

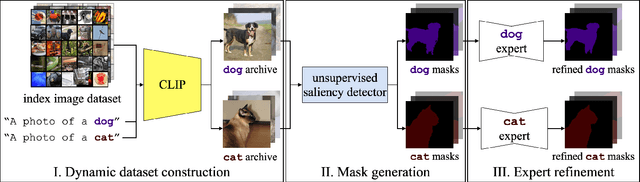
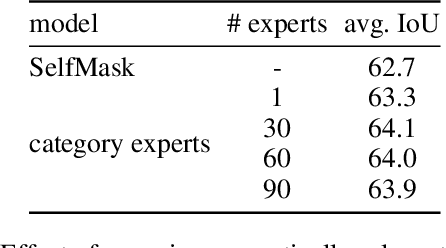
The goal of this work is to segment and name regions of images without access to pixel-level labels during training. To tackle this task, we construct segmenters by distilling the complementary strengths of two foundation models. The first, CLIP (Radford et al. 2021), exhibits the ability to assign names to image content but lacks an accessible representation of object structure. The second, DINO (Caron et al. 2021), captures the spatial extent of objects but has no knowledge of object names. Our method, termed NamedMask, begins by using CLIP to construct category-specific archives of images. These images are pseudo-labelled with a category-agnostic salient object detector bootstrapped from DINO, then refined by category-specific segmenters using the CLIP archive labels. Thanks to the high quality of the refined masks, we show that a standard segmentation architecture trained on these archives with appropriate data augmentation achieves impressive semantic segmentation abilities for both single-object and multi-object images. As a result, our proposed NamedMask performs favourably against a range of prior work on five benchmarks including the VOC2012, COCO and large-scale ImageNet-S datasets.
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
Sep 22, 2022



As several industries are moving towards modeling massive 3D virtual worlds, the need for content creation tools that can scale in terms of the quantity, quality, and diversity of 3D content is becoming evident. In our work, we aim to train performant 3D generative models that synthesize textured meshes which can be directly consumed by 3D rendering engines, thus immediately usable in downstream applications. Prior works on 3D generative modeling either lack geometric details, are limited in the mesh topology they can produce, typically do not support textures, or utilize neural renderers in the synthesis process, which makes their use in common 3D software non-trivial. In this work, we introduce GET3D, a Generative model that directly generates Explicit Textured 3D meshes with complex topology, rich geometric details, and high-fidelity textures. We bridge recent success in the differentiable surface modeling, differentiable rendering as well as 2D Generative Adversarial Networks to train our model from 2D image collections. GET3D is able to generate high-quality 3D textured meshes, ranging from cars, chairs, animals, motorbikes and human characters to buildings, achieving significant improvements over previous methods.