 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Do Lessons from Metric Learning Generalize to Image-Caption Retrieval?
Feb 14, 2022
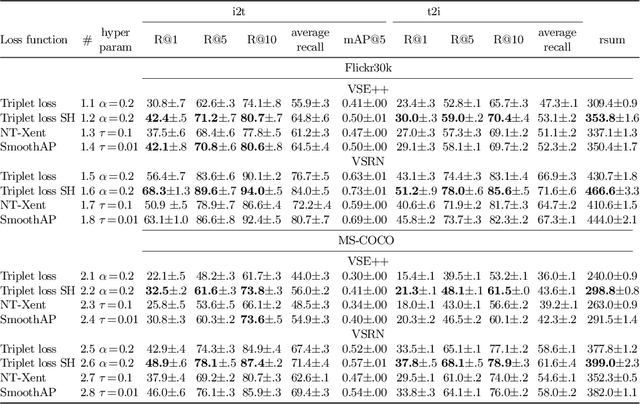
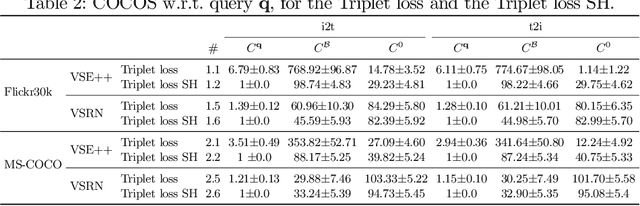
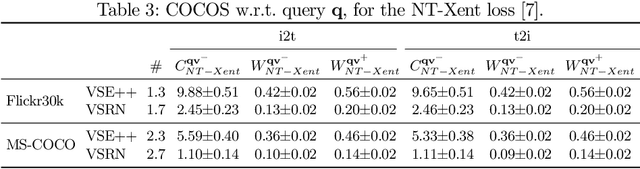

The triplet loss with semi-hard negatives has become the de facto choice for image-caption retrieval (ICR) methods that are optimized from scratch. Recent progress in metric learning has given rise to new loss functions that outperform the triplet loss on tasks such as image retrieval and representation learning. We ask whether these findings generalize to the setting of ICR by comparing three loss functions on two ICR methods. We answer this question negatively: the triplet loss with semi-hard negative mining still outperforms newly introduced loss functions from metric learning on the ICR task. To gain a better understanding of these outcomes, we introduce an analysis method to compare loss functions by counting how many samples contribute to the gradient w.r.t. the query representation during optimization. We find that loss functions that result in lower evaluation scores on the ICR task, in general, take too many (non-informative) samples into account when computing a gradient w.r.t. the query representation, which results in sub-optimal performance. The triplet loss with semi-hard negatives is shown to outperform the other loss functions, as it only takes one (hard) negative into account when computing the gradient.
IoU-Enhanced Attention for End-to-End Task Specific Object Detection
Oct 05, 2022
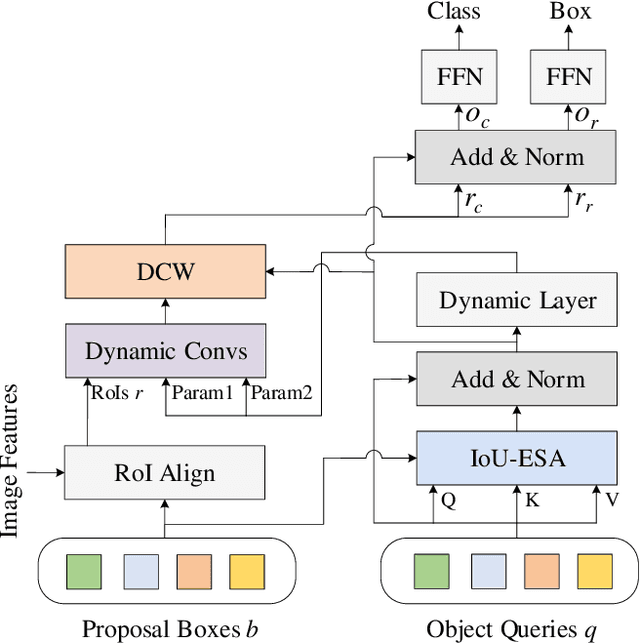

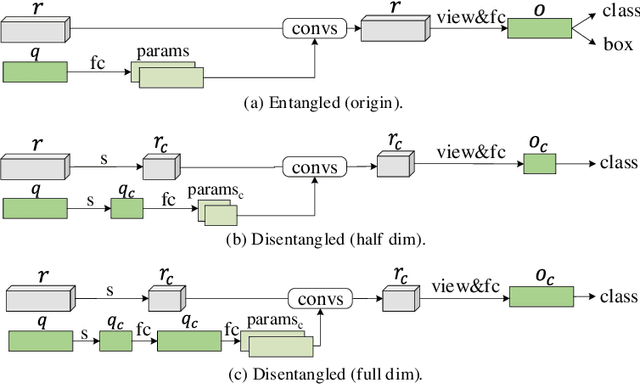
Without densely tiled anchor boxes or grid points in the image, sparse R-CNN achieves promising results through a set of object queries and proposal boxes updated in the cascaded training manner. However, due to the sparse nature and the one-to-one relation between the query and its attending region, it heavily depends on the self attention, which is usually inaccurate in the early training stage. Moreover, in a scene of dense objects, the object query interacts with many irrelevant ones, reducing its uniqueness and harming the performance. This paper proposes to use IoU between different boxes as a prior for the value routing in self attention. The original attention matrix multiplies the same size matrix computed from the IoU of proposal boxes, and they determine the routing scheme so that the irrelevant features can be suppressed. Furthermore, to accurately extract features for both classification and regression, we add two lightweight projection heads to provide the dynamic channel masks based on object query, and they multiply with the output from dynamic convs, making the results suitable for the two different tasks. We validate the proposed scheme on different datasets, including MS-COCO and CrowdHuman, showing that it significantly improves the performance and increases the model convergence speed.
Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
Mar 28, 2022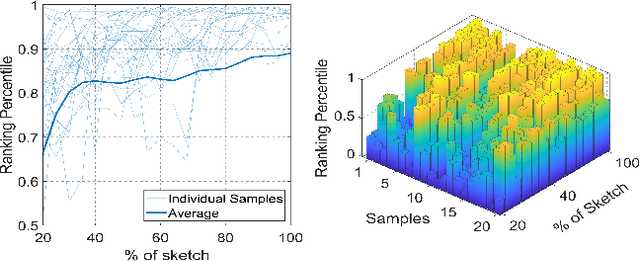
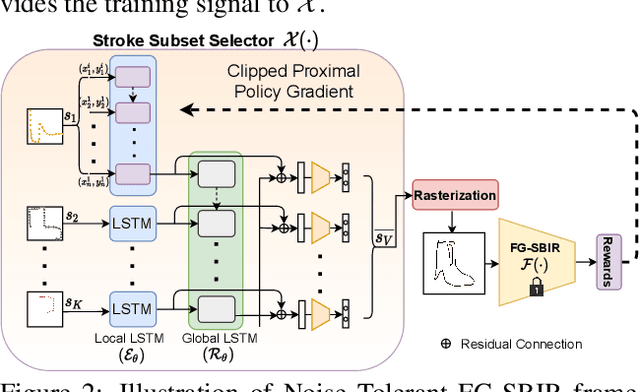
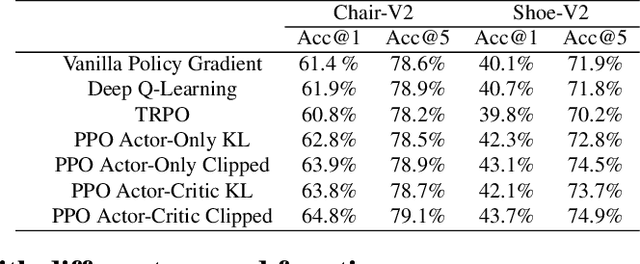
Sketching enables many exciting applications, notably, image retrieval. The fear-to-sketch problem (i.e., "I can't sketch") has however proven to be fatal for its widespread adoption. This paper tackles this "fear" head on, and for the first time, proposes an auxiliary module for existing retrieval models that predominantly lets the users sketch without having to worry. We first conducted a pilot study that revealed the secret lies in the existence of noisy strokes, but not so much of the "I can't sketch". We consequently design a stroke subset selector that {detects noisy strokes, leaving only those} which make a positive contribution towards successful retrieval. Our Reinforcement Learning based formulation quantifies the importance of each stroke present in a given subset, based on the extent to which that stroke contributes to retrieval. When combined with pre-trained retrieval models as a pre-processing module, we achieve a significant gain of 8%-10% over standard baselines and in turn report new state-of-the-art performance. Last but not least, we demonstrate the selector once trained, can also be used in a plug-and-play manner to empower various sketch applications in ways that were not previously possible.
NewsStories: Illustrating articles with visual summaries
Jul 26, 2022
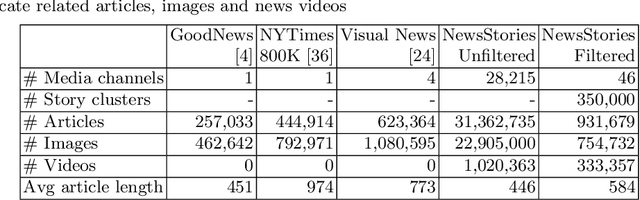
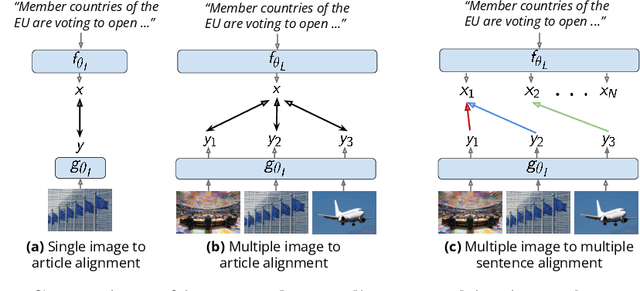
Recent self-supervised approaches have used large-scale image-text datasets to learn powerful representations that transfer to many tasks without finetuning. These methods often assume that there is one-to-one correspondence between its images and their (short) captions. However, many tasks require reasoning about multiple images and long text narratives, such as describing news articles with visual summaries. Thus, we explore a novel setting where the goal is to learn a self-supervised visual-language representation that is robust to varying text length and the number of images. In addition, unlike prior work which assumed captions have a literal relation to the image, we assume images only contain loose illustrative correspondence with the text. To explore this problem, we introduce a large-scale multimodal dataset containing over 31M articles, 22M images and 1M videos. We show that state-of-the-art image-text alignment methods are not robust to longer narratives with multiple images. Finally, we introduce an intuitive baseline that outperforms these methods on zero-shot image-set retrieval by 10% on the GoodNews dataset.
Feature Decoupling in Self-supervised Representation Learning for Open Set Recognition
Sep 28, 2022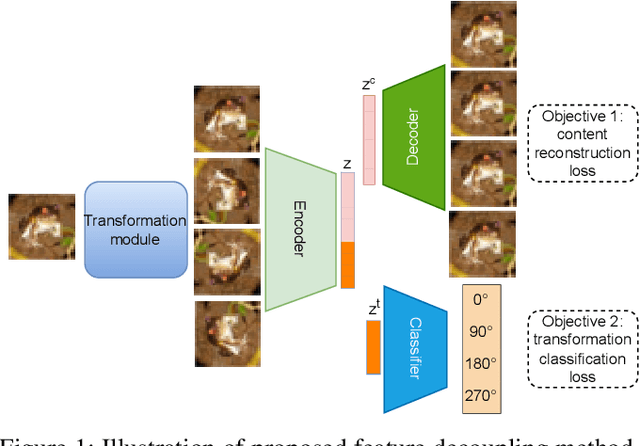

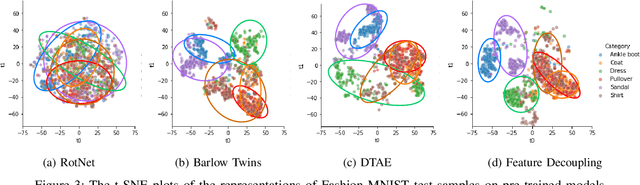
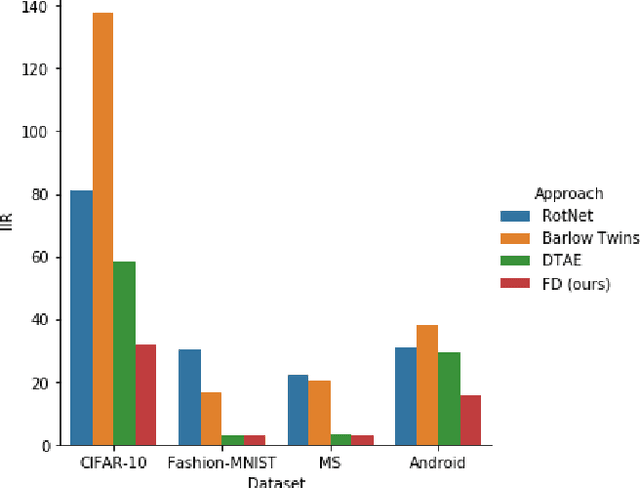
Assuming unknown classes could be present during classification, the open set recognition (OSR) task aims to classify an instance into a known class or reject it as unknown. In this paper, we use a two-stage training strategy for the OSR problems. In the first stage, we introduce a self-supervised feature decoupling method that finds the content features of the input samples from the known classes. Specifically, our feature decoupling approach learns a representation that can be split into content features and transformation features. In the second stage, we fine-tune the content features with the class labels. The fine-tuned content features are then used for the OSR problems. Moreover, we consider an unsupervised OSR scenario, where we cluster the content features learned from the first stage. To measure representation quality, we introduce intra-inter ratio (IIR). Our experimental results indicate that our proposed self-supervised approach outperforms others in image and malware OSR problems. Also, our analyses indicate that IIR is correlated with OSR performance.
Self-supervised Pre-training for Semantic Segmentation in an Indoor Scene
Oct 04, 2022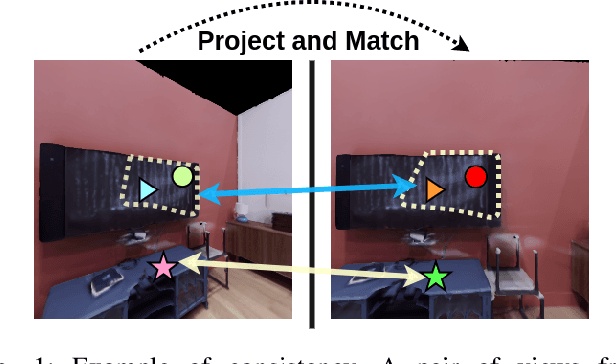
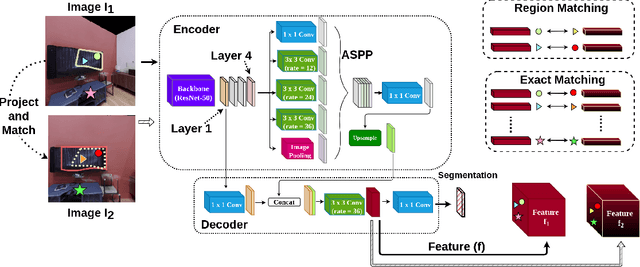

The ability to endow maps of indoor scenes with semantic information is an integral part of robotic agents which perform different tasks such as target driven navigation, object search or object rearrangement. The state-of-the-art methods use Deep Convolutional Neural Networks (DCNNs) for predicting semantic segmentation of an image as useful representation for these tasks. The accuracy of semantic segmentation depends on the availability and the amount of labeled data from the target environment or the ability to bridge the domain gap between test and training environment. We propose RegConsist, a method for self-supervised pre-training of a semantic segmentation model, exploiting the ability of the agent to move and register multiple views in the novel environment. Given the spatial and temporal consistency cues used for pixel level data association, we use a variant of contrastive learning to train a DCNN model for predicting semantic segmentation from RGB views in the target environment. The proposed method outperforms models pre-trained on ImageNet and achieves competitive performance when using models that are trained for exactly the same task but on a different dataset. We also perform various ablation studies to analyze and demonstrate the efficacy of our proposed method.
Image Fusion Transformer
Jul 19, 2021
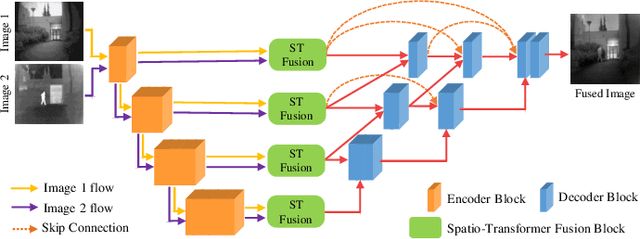
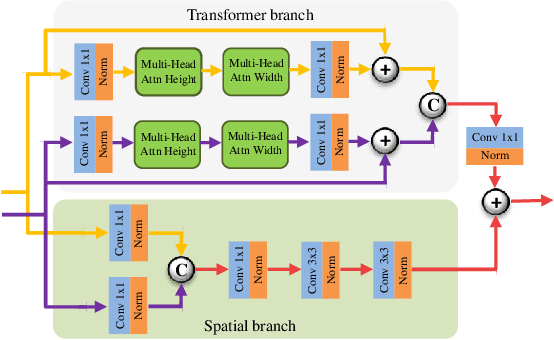
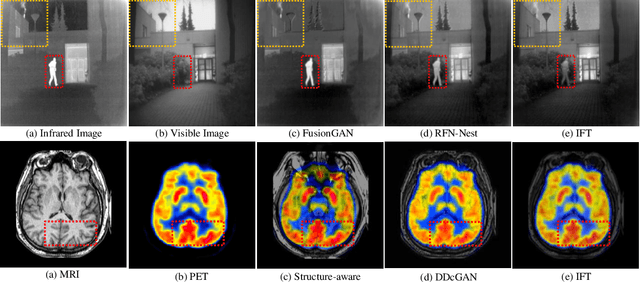
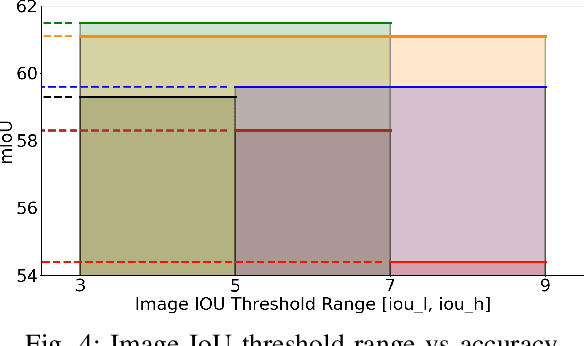
In image fusion, images obtained from different sensors are fused to generate a single image with enhanced information. In recent years, state-of-the-art methods have adopted Convolution Neural Networks (CNNs) to encode meaningful features for image fusion. Specifically, CNN-based methods perform image fusion by fusing local features. However, they do not consider long-range dependencies that are present in the image. Transformer-based models are designed to overcome this by modeling the long-range dependencies with the help of self-attention mechanism. This motivates us to propose a novel Image Fusion Transformer (IFT) where we develop a transformer-based multi-scale fusion strategy that attends to both local and long-range information (or global context). The proposed method follows a two-stage training approach. In the first stage, we train an auto-encoder to extract deep features at multiple scales. In the second stage, multi-scale features are fused using a Spatio-Transformer (ST) fusion strategy. The ST fusion blocks are comprised of a CNN and a transformer branch which capture local and long-range features, respectively. Extensive experiments on multiple benchmark datasets show that the proposed method performs better than many competitive fusion algorithms. Furthermore, we show the effectiveness of the proposed ST fusion strategy with an ablation analysis. The source code is available at: https://github.com/Vibashan/Image-Fusion-Transformer}{https://github.com/Vibashan/Image-Fusion-Transformer.
Multi-Field De-interlacing using Deformable Convolution Residual Blocks and Self-Attention
Sep 21, 2022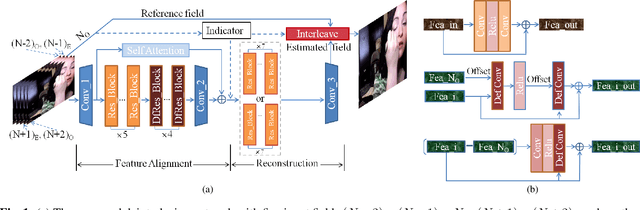
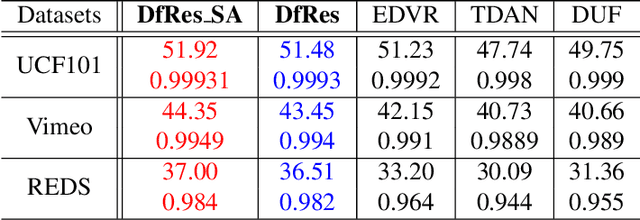
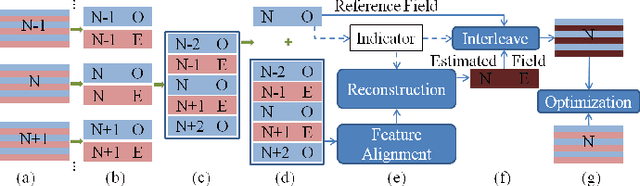

Although deep learning has made significant impact on image/video restoration and super-resolution, learned deinterlacing has so far received less attention in academia or industry. This is despite deinterlacing is well-suited for supervised learning from synthetic data since the degradation model is known and fixed. In this paper, we propose a novel multi-field full frame-rate deinterlacing network, which adapts the state-of-the-art superresolution approaches to the deinterlacing task. Our model aligns features from adjacent fields to a reference field (to be deinterlaced) using both deformable convolution residual blocks and self attention. Our extensive experimental results demonstrate that the proposed method provides state-of-the-art deinterlacing results in terms of both numerical and perceptual performance. At the time of writing, our model ranks first in the Full FrameRate LeaderBoard at https://videoprocessing.ai/benchmarks/deinterlacer.html
Low rank prior and l0 norm to remove impulse noise in images
Sep 12, 2022
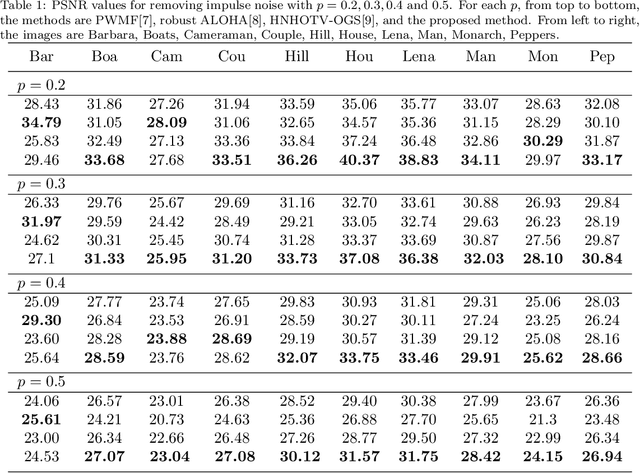
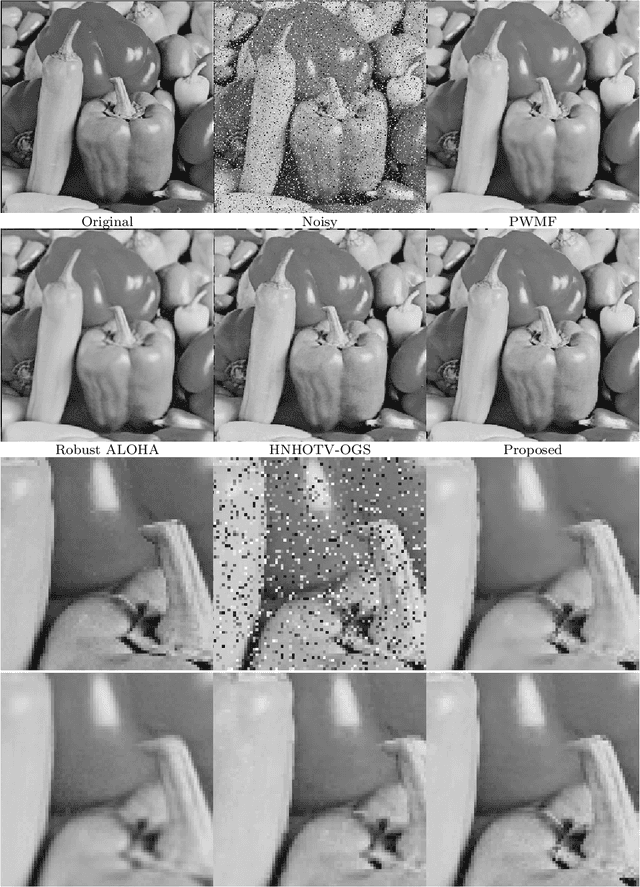

Patch-based low rank is an important prior assumption for image processing. Moreover, according to our calculation, the optimization of l0 norm corresponds to the maximum likelihood estimation under random-valued impulse noise. In this article, we thus combine exact rank and l0 norm for removing the noise. It is solved formally using the alternating direction method of multipliers (ADMM), with our previous patch-based weighted filter (PWMF) producing initial images. Since this model is not convex, we consider it as a Plug-and-Play ADMM, and do not discuss theoretical convergence properties. Experiments show that this method has very good performance, especially for weak or medium contrast images.
Exploring Inter-frequency Guidance of Image for Lightweight Gaussian Denoising
Dec 22, 2021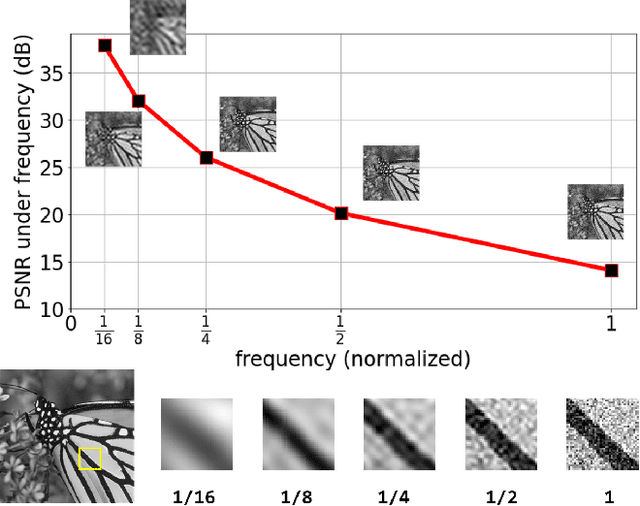

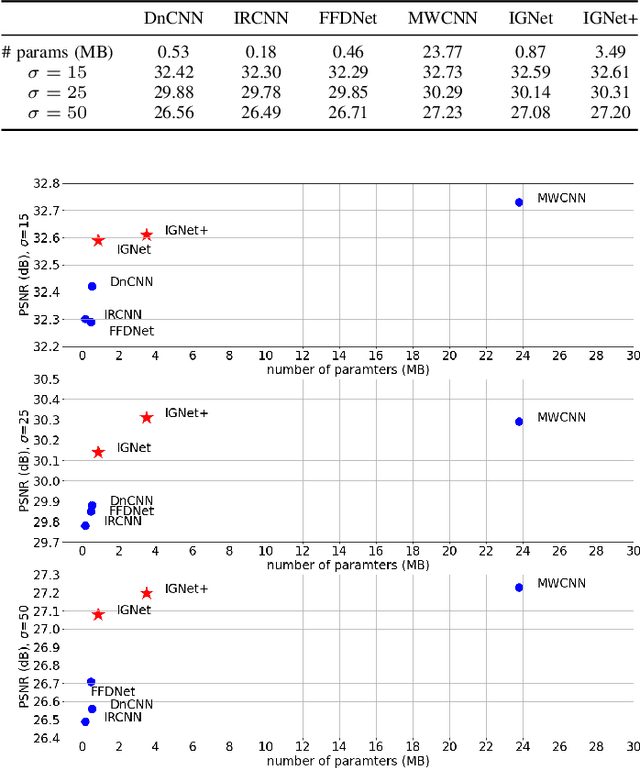
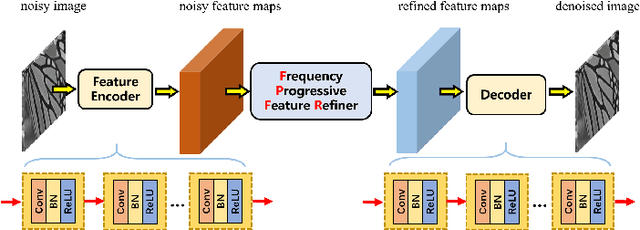
Image denoising is of vital importance in many imaging or computer vision related areas. With the convolutional neural networks showing strong capability in computer vision tasks, the performance of image denoising has also been brought up by CNN based methods. Though CNN based image denoisers show promising results on this task, most of the current CNN based methods try to learn the mapping from noisy image to clean image directly, which lacks the explicit exploration of prior knowledge of images and noises. Natural images are observed to obey the reciprocal power law, implying the low-frequency band of image tend to occupy most of the energy. Thus in the condition of AGWN (additive gaussian white noise) deterioration, low-frequency band tend to preserve a higher PSNR than high-frequency band. Considering the spatial morphological consistency of different frequency bands, low-frequency band with more fidelity can be used as a guidance to refine the more contaminated high-frequency bands. Based on this thought, we proposed a novel network architecture denoted as IGNet, in order to refine the frequency bands from low to high in a progressive manner. Firstly, it decomposes the feature maps into high- and low-frequency subbands using DWT (discrete wavelet transform) iteratively, and then each low band features are used to refine the high band features. Finally, the refined feature maps are processed by a decoder to recover the clean result. With this design, more inter-frequency prior and information are utilized, thus the model size can be lightened while still perserves competitive results. Experiments on several public datasets show that our model obtains competitive performance comparing with other state-of-the-art methods yet with a lightweight structure.