 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Contrastive Learning on Visually Homogeneous Mars Rover Images
Oct 17, 2022


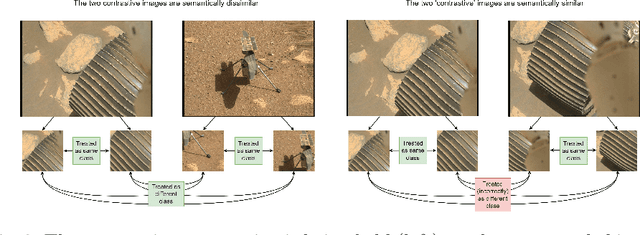

Contrastive learning has recently demonstrated superior performance to supervised learning, despite requiring no training labels. We explore how contrastive learning can be applied to hundreds of thousands of unlabeled Mars terrain images, collected from the Mars rovers Curiosity and Perseverance, and from the Mars Reconnaissance Orbiter. Such methods are appealing since the vast majority of Mars images are unlabeled as manual annotation is labor intensive and requires extensive domain knowledge. Contrastive learning, however, assumes that any given pair of distinct images contain distinct semantic content. This is an issue for Mars image datasets, as any two pairs of Mars images are far more likely to be semantically similar due to the lack of visual diversity on the planet's surface. Making the assumption that pairs of images will be in visual contrast - when they are in fact not - results in pairs that are falsely considered as negatives, impacting training performance. In this study, we propose two approaches to resolve this: 1) an unsupervised deep clustering step on the Mars datasets, which identifies clusters of images containing similar semantic content and corrects false negative errors during training, and 2) a simple approach which mixes data from different domains to increase visual diversity of the total training dataset. Both cases reduce the rate of false negative pairs, thus minimizing the rate in which the model is incorrectly penalized during contrastive training. These modified approaches remain fully unsupervised end-to-end. To evaluate their performance, we add a single linear layer trained to generate class predictions based on these contrastively-learned features and demonstrate increased performance compared to supervised models; observing an improvement in classification accuracy of 3.06% using only 10% of the labeled data.
Polar Transformation Based Multiple Instance Learning Assisting Weakly Supervised Image Segmentation With Loose Bounding Box Annotations
Mar 03, 2022
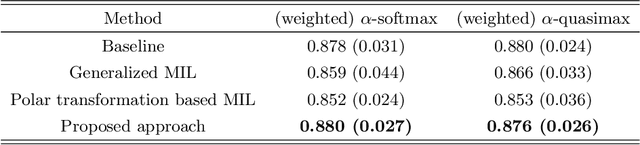
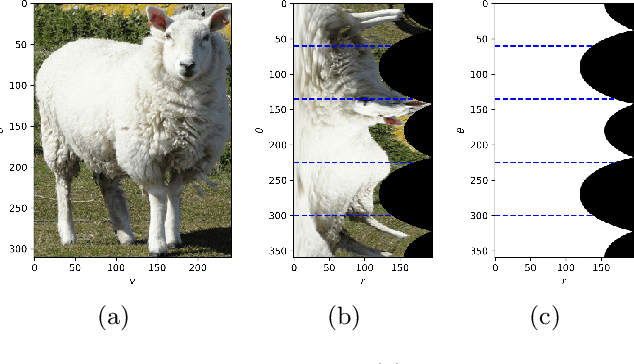
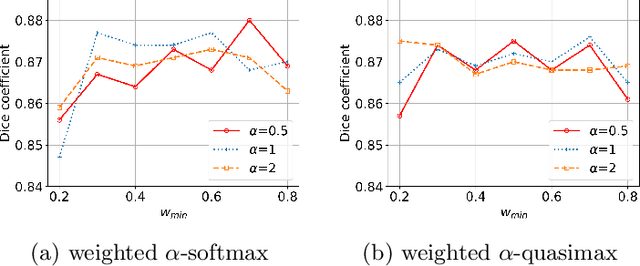
This study investigates weakly supervised image segmentation using loose bounding box supervision. It presents a multiple instance learning strategy based on polar transformation to assist image segmentation when loose bounding boxes are employed as supervision. In this strategy, weighted smooth maximum approximation is introduced to incorporate the observation that pixels closer to the origin of the polar transformation are more likely to belong to the object in the bounding box. The proposed approach was evaluated on a public medical dataset using Dice coefficient. The results demonstrate its superior performance. The codes are available at \url{https://github.com/wangjuan313/wsis-polartransform}.
Learning Multiple Probabilistic Degradation Generators for Unsupervised Real World Image Super Resolution
Jan 26, 2022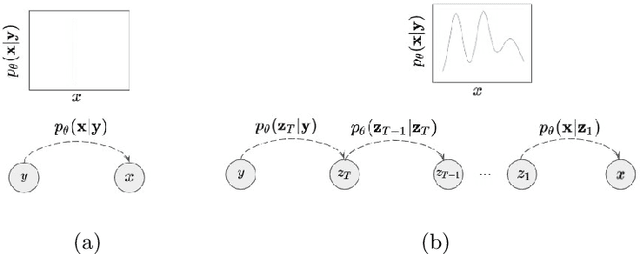

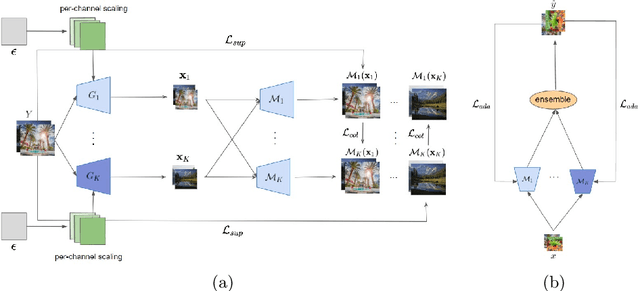

Unsupervised real world super resolution (USR) aims at restoring high-resolution (HR) images given low-resolution (LR) inputs when paired data is unavailable. One of the most common approaches is synthesizing noisy LR images using GANs and utilizing a synthetic dataset to train the model in a supervised manner. The goal of modeling the degradation generator is to approximate the distribution of LR images given a HR image. Previous works simply assumed the conditional distribution as a delta function and learned the deterministic mapping from HR image to a LR image. Instead, we propose the probabilistic degradation generator. Our degradation generator is a deep hierarchical latent variable model and more suitable for modeling the complex distribution. Furthermore, we train multiple degradation generators to enhance the mode coverage and apply the novel collaborative learning. We outperform several baselines on benchmark datasets in terms of PSNR and SSIM and demonstrate the robustness of our method on unseen data distribution.
ECO-TR: Efficient Correspondences Finding Via Coarse-to-Fine Refinement
Sep 25, 2022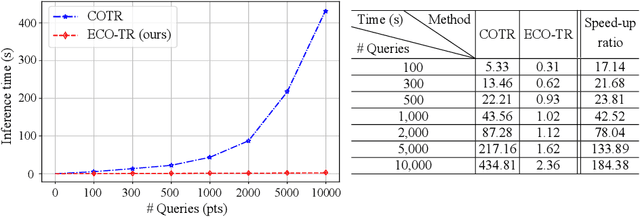
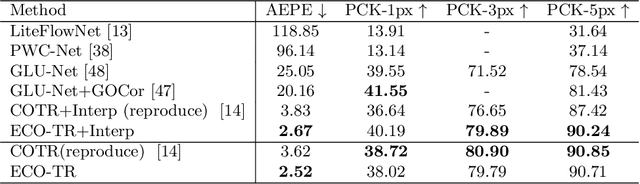
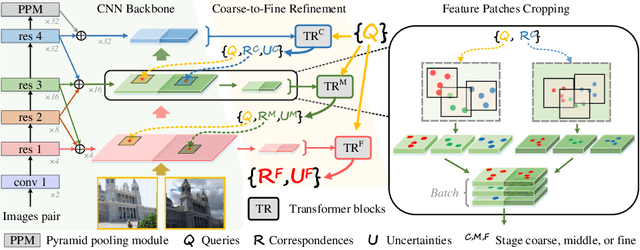
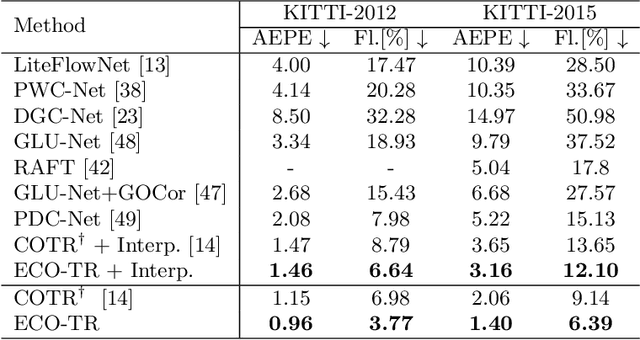
Modeling sparse and dense image matching within a unified functional correspondence model has recently attracted increasing research interest. However, existing efforts mainly focus on improving matching accuracy while ignoring its efficiency, which is crucial for realworld applications. In this paper, we propose an efficient structure named Efficient Correspondence Transformer (ECO-TR) by finding correspondences in a coarse-to-fine manner, which significantly improves the efficiency of functional correspondence model. To achieve this, multiple transformer blocks are stage-wisely connected to gradually refine the predicted coordinates upon a shared multi-scale feature extraction network. Given a pair of images and for arbitrary query coordinates, all the correspondences are predicted within a single feed-forward pass. We further propose an adaptive query-clustering strategy and an uncertainty-based outlier detection module to cooperate with the proposed framework for faster and better predictions. Experiments on various sparse and dense matching tasks demonstrate the superiority of our method in both efficiency and effectiveness against existing state-of-the-arts.
Tuning of Mixture-of-Experts Mixed-Precision Neural Networks
Sep 29, 2022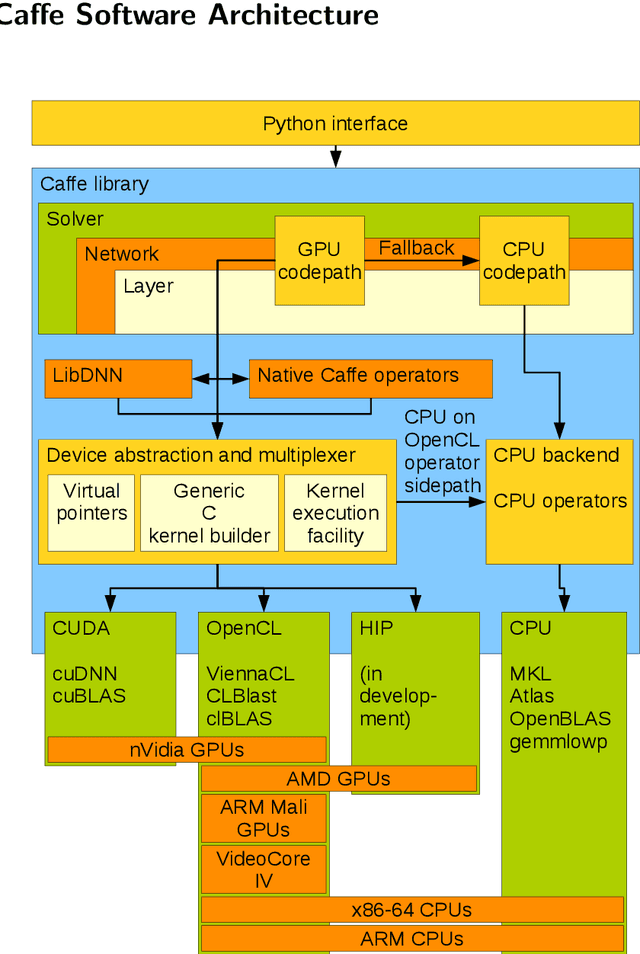
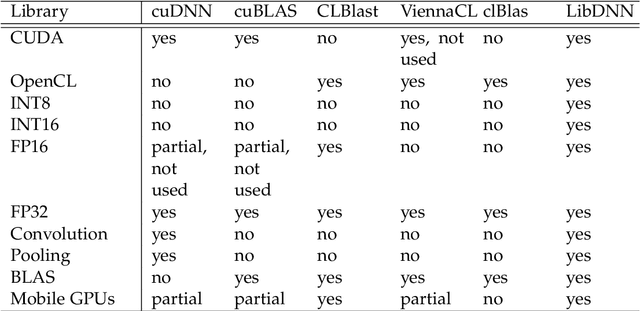
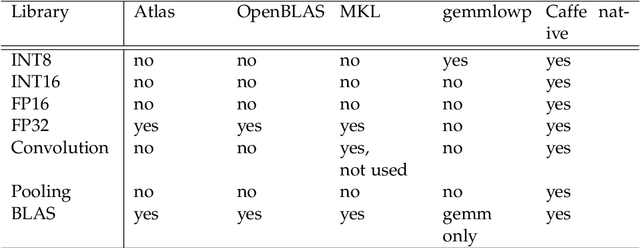
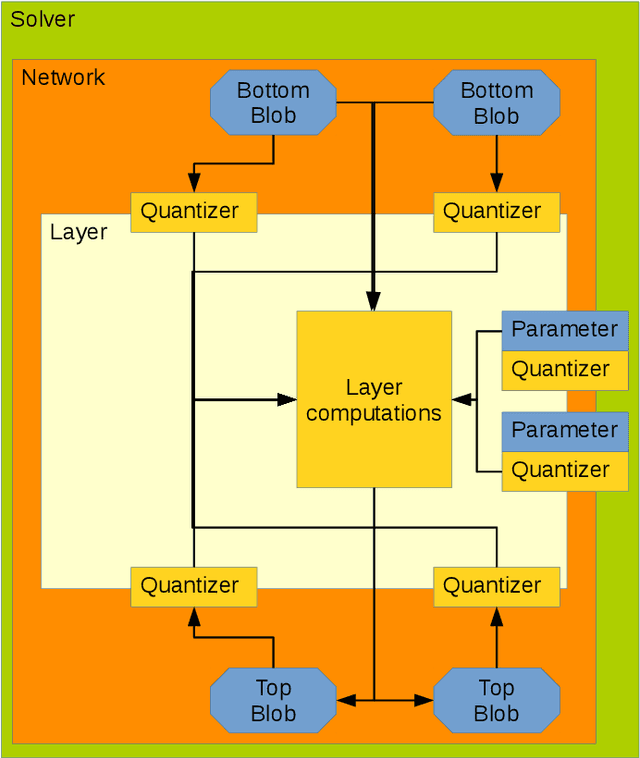
Deep learning has become a useful data analysis method, however mainstream adaption in distributed computer software and embedded devices has been low so far. Often, adding deep learning inference in mainstream applications and devices requires new hardware with signal processors suited for convolutional neural networks. This work adds new data types (quantized 16-bit and 8-bit integer, 16-bit floating point) to Caffe in order to save memory and increase inference speed on existing commodity graphics processors with OpenCL, common in everyday devices. Existing models can be executed effortlessly in mixed-precision mode. Additionally, we propose a variation of mixture-of-experts to increase inference speed on AlexNet for image classification. We managed to decrease memory usage up to 3.29x while increasing inference speed up to 3.01x on certain devices. We demonstrate with five simple examples how the presented techniques can easily be applied to different machine learning problems. The whole pipeline, consisting of models, example python scripts and modified Caffe library, is available as Open Source software.
Heterogeneous reconstruction of deformable atomic models in Cryo-EM
Sep 29, 2022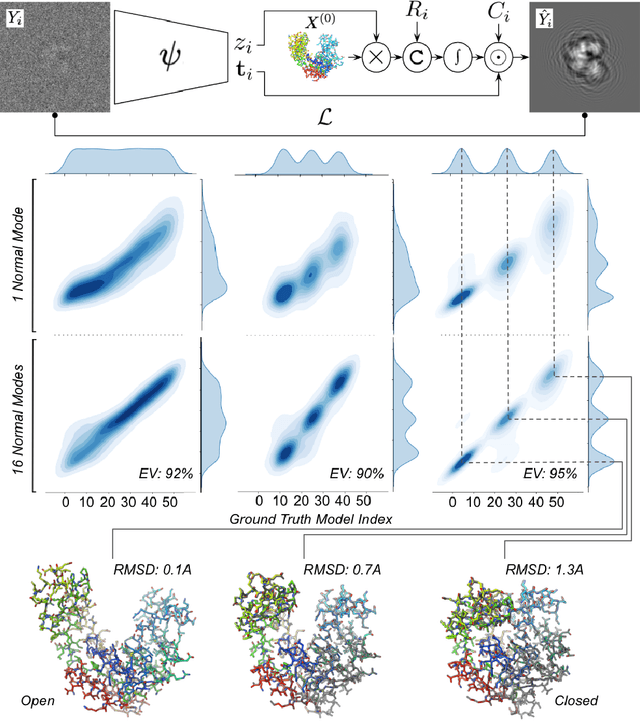
Cryogenic electron microscopy (cryo-EM) provides a unique opportunity to study the structural heterogeneity of biomolecules. Being able to explain this heterogeneity with atomic models would help our understanding of their functional mechanisms but the size and ruggedness of the structural space (the space of atomic 3D cartesian coordinates) presents an immense challenge. Here, we describe a heterogeneous reconstruction method based on an atomistic representation whose deformation is reduced to a handful of collective motions through normal mode analysis. Our implementation uses an autoencoder. The encoder jointly estimates the amplitude of motion along the normal modes and the 2D shift between the center of the image and the center of the molecule . The physics-based decoder aggregates a representation of the heterogeneity readily interpretable at the atomic level. We illustrate our method on 3 synthetic datasets corresponding to different distributions along a simulated trajectory of adenylate kinase transitioning from its open to its closed structures. We show for each distribution that our approach is able to recapitulate the intermediate atomic models with atomic-level accuracy.
Contextformer: A Transformer with Spatio-Channel Attention for Context Modeling in Learned Image Compression
Mar 04, 2022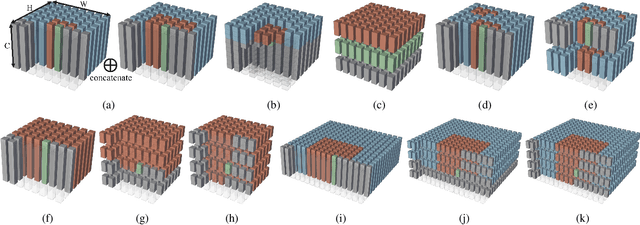

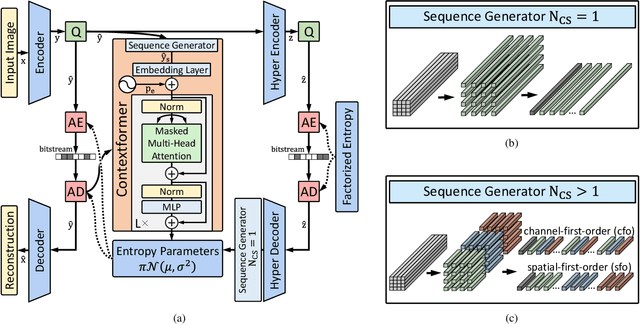
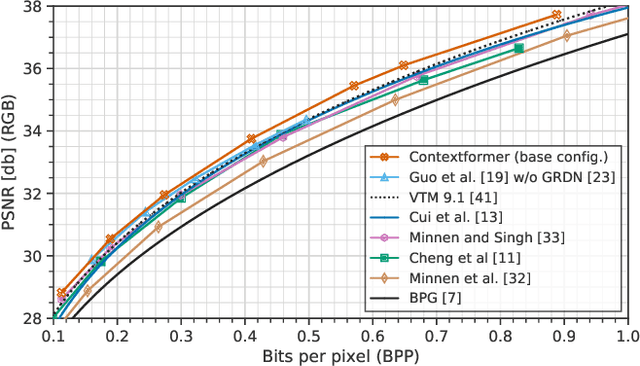
Entropy modeling is a key component for high-performance image compression algorithms. Recent developments in autoregressive context modeling helped learning-based methods to surpass their classical counterparts. However, the performance of those models can be further improved due to the underexploited spatio-channel dependencies in latent space, and the suboptimal implementation of context adaptivity. Inspired by the adaptive characteristics of the transformers, we propose a transformer-based context model, a.k.a. Contextformer, which generalizes the de facto standard attention mechanism to spatio-channel attention. We replace the context model of a modern compression framework with the Contextformer and test it on the widely used Kodak image dataset. Our experimental results show that the proposed model provides up to 10% rate savings compared to the standard Versatile Video Coding (VVC) Test Model (VTM) 9.1, and outperforms various learning-based models.
Quality Evaluation of Arbitrary Style Transfer: Subjective Study and Objective Metric
Aug 01, 2022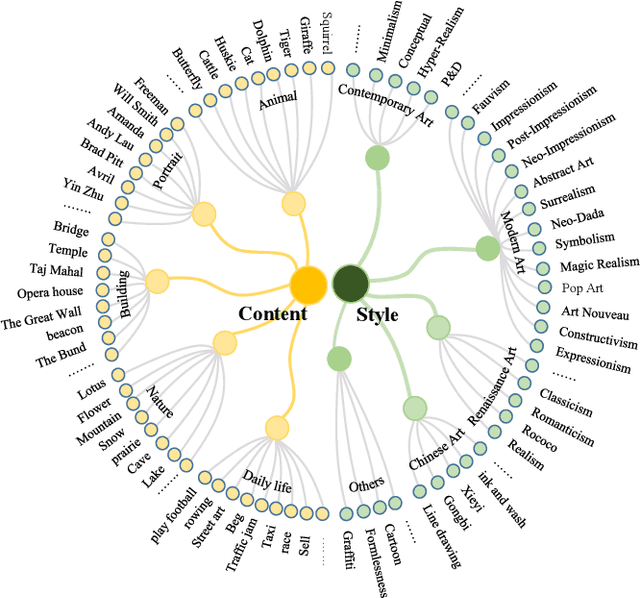
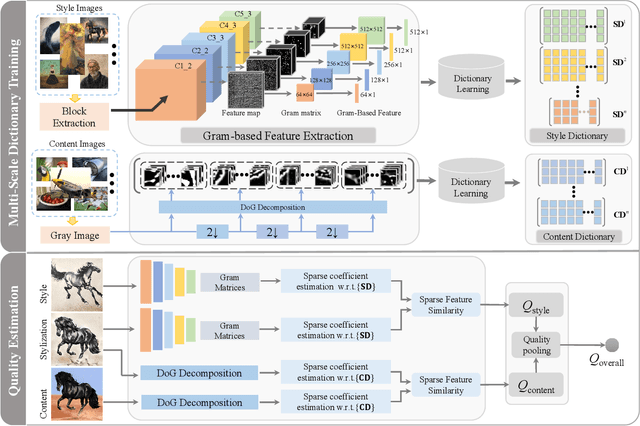

Arbitrary neural style transfer is a vital topic with research value and industrial application prospect, which strives to render the structure of one image using the style of another. Recent researches have devoted great efforts on the task of arbitrary style transfer (AST) for improving the stylization quality. However, there are very few explorations about the quality evaluation of AST images, even it can potentially guide the design of different algorithms. In this paper, we first construct a new AST images quality assessment database (AST-IQAD) that consists 150 content-style image pairs and the corresponding 1200 stylized images produced by eight typical AST algorithms. Then, a subjective study is conducted on our AST-IQAD database, which obtains the subjective rating scores of all stylized images on the three subjective evaluations, i.e., content preservation (CP), style resemblance (SR), and overall visual (OV). To quantitatively measure the quality of AST image, we proposed a new sparse representation-based image quality evaluation metric (SRQE), which computes the quality using the sparse feature similarity. Experimental results on the AST-IQAD have demonstrated the superiority of the proposed method. The dataset and source code will be released at https://github.com/Hangwei-Chen/AST-IQAD-SRQE
Injecting Semantic Concepts into End-to-End Image Captioning
Dec 09, 2021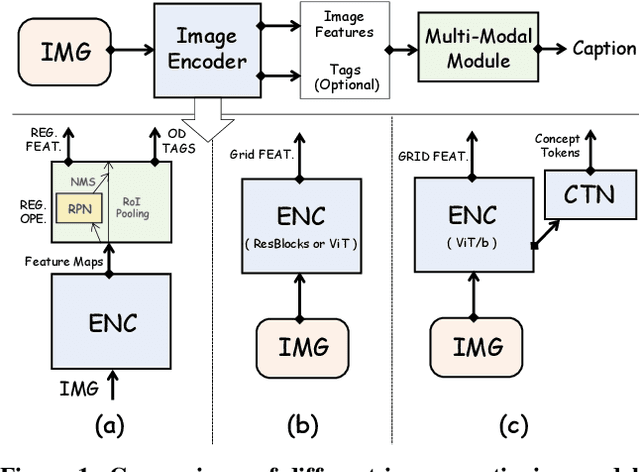
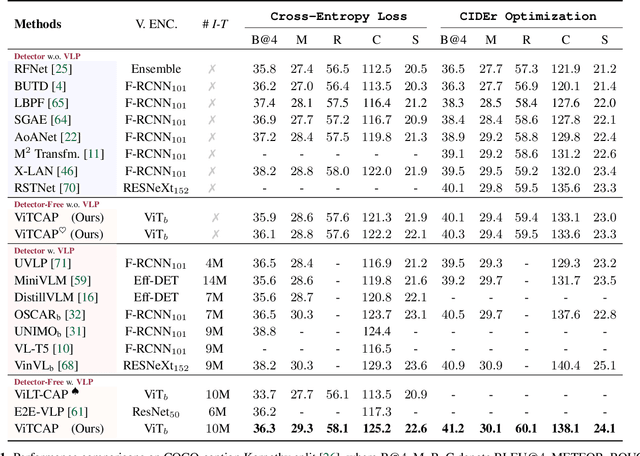
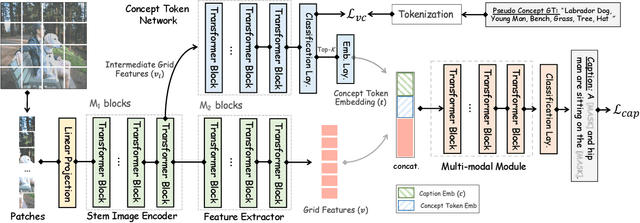
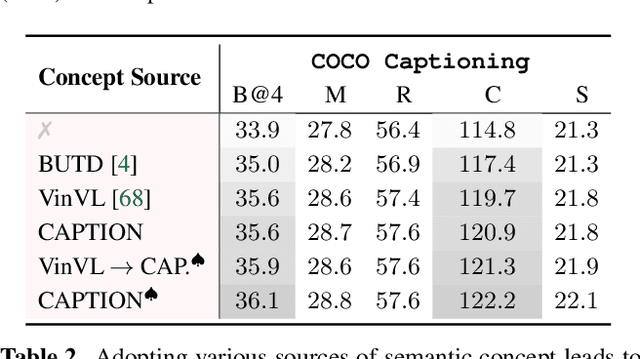
Tremendous progress has been made in recent years in developing better image captioning models, yet most of them rely on a separate object detector to extract regional features. Recent vision-language studies are shifting towards the detector-free trend by leveraging grid representations for more flexible model training and faster inference speed. However, such development is primarily focused on image understanding tasks, and remains less investigated for the caption generation task. In this paper, we are concerned with a better-performing detector-free image captioning model, and propose a pure vision transformer-based image captioning model, dubbed as ViTCAP, in which grid representations are used without extracting the regional features. For improved performance, we introduce a novel Concept Token Network (CTN) to predict the semantic concepts and then incorporate them into the end-to-end captioning. In particular, the CTN is built on the basis of a vision transformer and is designed to predict the concept tokens through a classification task, from which the rich semantic information contained greatly benefits the captioning task. Compared with the previous detector-based models, ViTCAP drastically simplifies the architectures and at the same time achieves competitive performance on various challenging image captioning datasets. In particular, ViTCAP reaches 138.1 CIDEr scores on COCO-caption Karpathy-split, 93.8 and 108.6 CIDEr scores on nocaps, and Google-CC captioning datasets, respectively.
IoU-Enhanced Attention for End-to-End Task Specific Object Detection
Oct 05, 2022
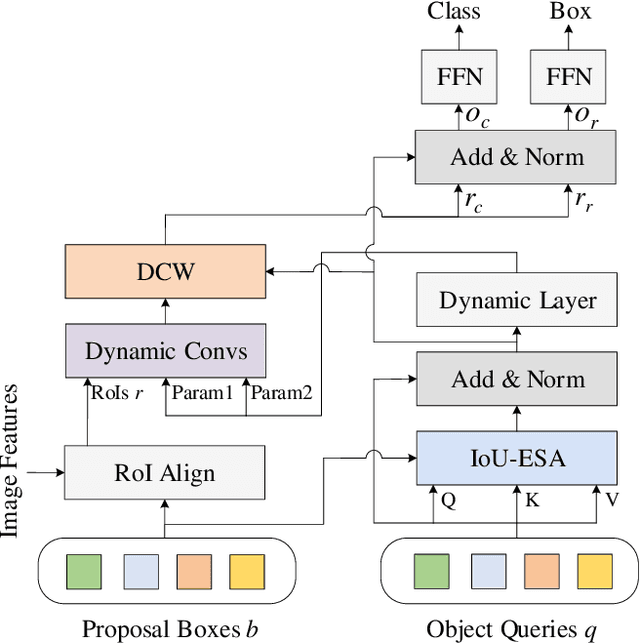

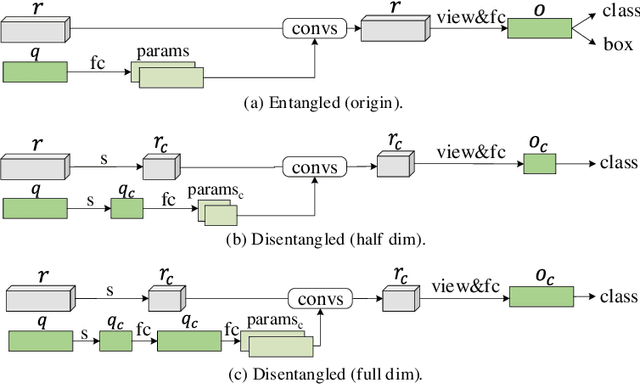
Without densely tiled anchor boxes or grid points in the image, sparse R-CNN achieves promising results through a set of object queries and proposal boxes updated in the cascaded training manner. However, due to the sparse nature and the one-to-one relation between the query and its attending region, it heavily depends on the self attention, which is usually inaccurate in the early training stage. Moreover, in a scene of dense objects, the object query interacts with many irrelevant ones, reducing its uniqueness and harming the performance. This paper proposes to use IoU between different boxes as a prior for the value routing in self attention. The original attention matrix multiplies the same size matrix computed from the IoU of proposal boxes, and they determine the routing scheme so that the irrelevant features can be suppressed. Furthermore, to accurately extract features for both classification and regression, we add two lightweight projection heads to provide the dynamic channel masks based on object query, and they multiply with the output from dynamic convs, making the results suitable for the two different tasks. We validate the proposed scheme on different datasets, including MS-COCO and CrowdHuman, showing that it significantly improves the performance and increases the model convergence speed.