 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stochastic Attribute Modeling for Face Super-Resolution
Jul 16, 2022
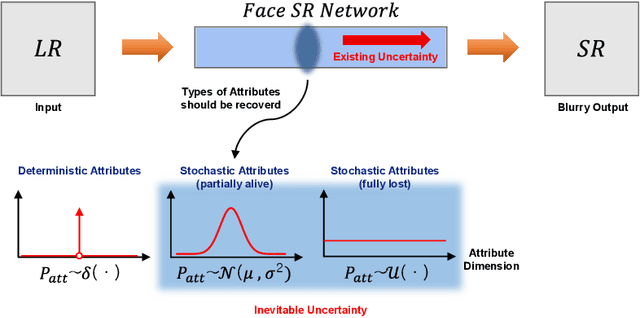
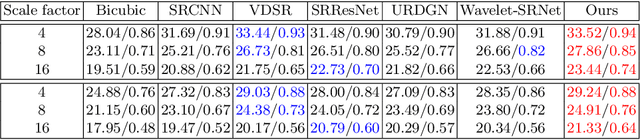

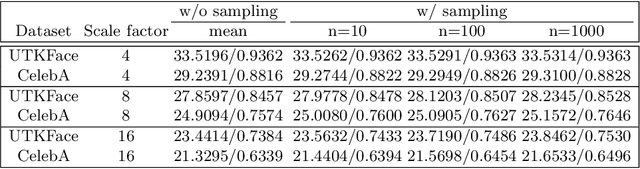
When a high-resolution (HR) image is degraded into a low-resolution (LR) image, the image loses some of the existing information. Consequently, multiple HR images can correspond to the LR image. Most of the existing methods do not consider the uncertainty caused by the stochastic attribute, which can only be probabilistically inferred. Therefore, the predicted HR images are often blurry because the network tries to reflect all possibilities in a single output image. To overcome this limitation, this paper proposes a novel face super-resolution (SR) scheme to take into the uncertainty by stochastic modeling. Specifically, the information in LR images is separately encoded into deterministic and stochastic attributes. Furthermore, an Input Conditional Attribute Predictor is proposed and separately trained to predict the partially alive stochastic attributes from only the LR images. Extensive evaluation shows that the proposed method successfully reduces the uncertainty in the learning process and outperforms the existing state-of-the-art approaches.
Diffusion Models for Implicit Image Segmentation Ensembles
Dec 27, 2021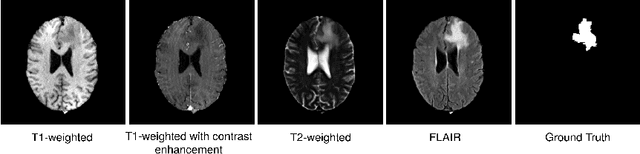
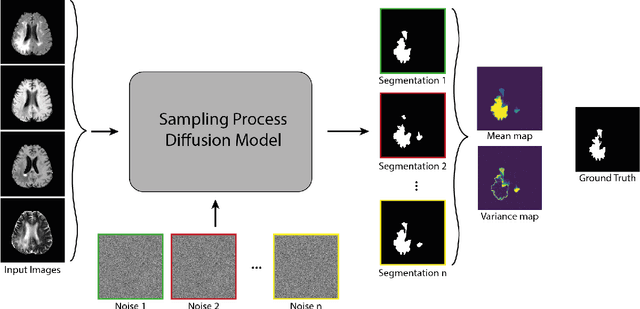

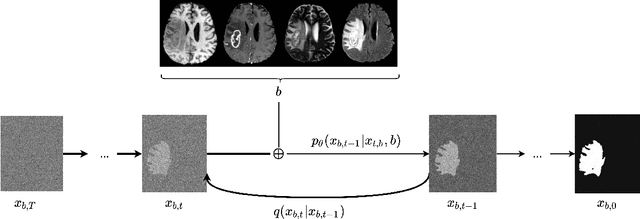
Diffusion models have shown impressive performance for generative modelling of images. In this paper, we present a novel semantic segmentation method based on diffusion models. By modifying the training and sampling scheme, we show that diffusion models can perform lesion segmentation of medical images. To generate an image specific segmentation, we train the model on the ground truth segmentation, and use the image as a prior during training and in every step during the sampling process. With the given stochastic sampling process, we can generate a distribution of segmentation masks. This property allows us to compute pixel-wise uncertainty maps of the segmentation, and allows an implicit ensemble of segmentations that increases the segmentation performance. We evaluate our method on the BRATS2020 dataset for brain tumor segmentation. Compared to state-of-the-art segmentation models, our approach yields good segmentation results and, additionally, detailed uncertainty maps.
Enforcing safety for vision-based controllers via Control Barrier Functions and Neural Radiance Fields
Sep 25, 2022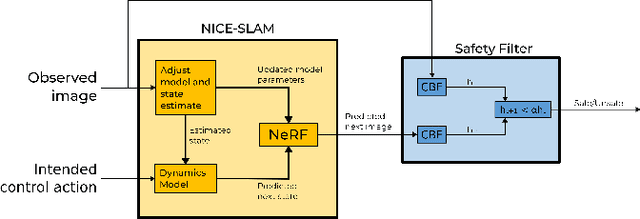

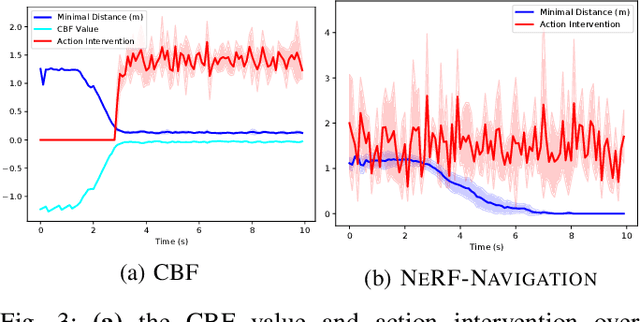
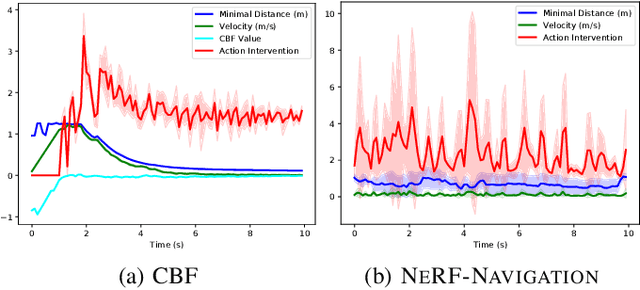
To navigate complex environments, robots must increasingly use high-dimensional visual feedback (e.g. images) for control. However, relying on high-dimensional image data to make control decisions raises important questions; particularly, how might we prove the safety of a visual-feedback controller? Control barrier functions (CBFs) are powerful tools for certifying the safety of feedback controllers in the state-feedback setting, but CBFs have traditionally been poorly-suited to visual feedback control due to the need to predict future observations in order to evaluate the barrier function. In this work, we solve this issue by leveraging recent advances in neural radiance fields (NeRFs), which learn implicit representations of 3D scenes and can render images from previously-unseen camera perspectives, to provide single-step visual foresight for a CBF-based controller. This novel combination is able to filter out unsafe actions and intervene to preserve safety. We demonstrate the effect of our controller in real-time simulation experiments where it successfully prevents the robot from taking dangerous actions.
Learning Dual Memory Dictionaries for Blind Face Restoration
Oct 15, 2022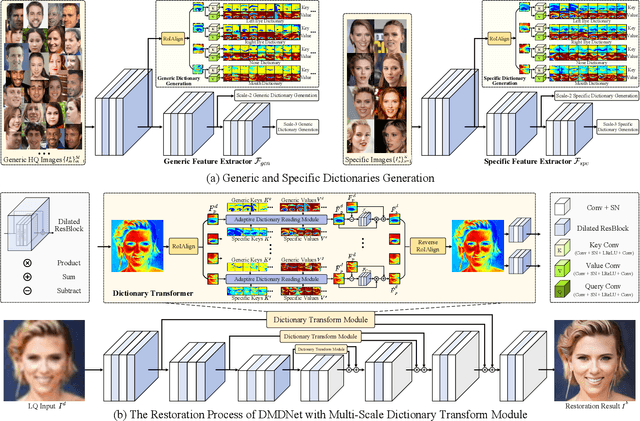
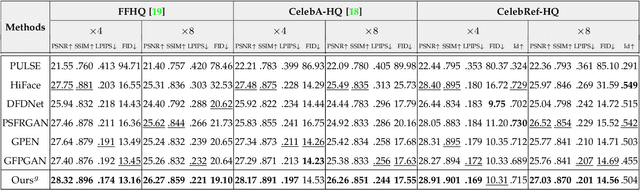
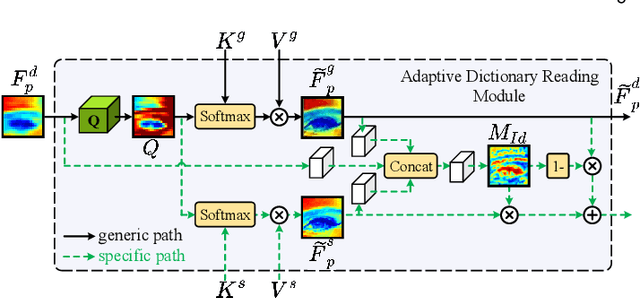
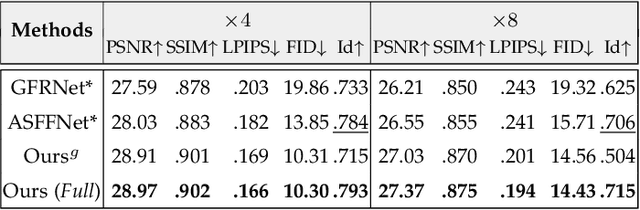
To improve the performance of blind face restoration, recent works mainly treat the two aspects, i.e., generic and specific restoration, separately. In particular, generic restoration attempts to restore the results through general facial structure prior, while on the one hand, cannot generalize to real-world degraded observations due to the limited capability of direct CNNs' mappings in learning blind restoration, and on the other hand, fails to exploit the identity-specific details. On the contrary, specific restoration aims to incorporate the identity features from the reference of the same identity, in which the requirement of proper reference severely limits the application scenarios. Generally, it is a challenging and intractable task to improve the photo-realistic performance of blind restoration and adaptively handle the generic and specific restoration scenarios with a single unified model. Instead of implicitly learning the mapping from a low-quality image to its high-quality counterpart, this paper suggests a DMDNet by explicitly memorizing the generic and specific features through dual dictionaries. First, the generic dictionary learns the general facial priors from high-quality images of any identity, while the specific dictionary stores the identity-belonging features for each person individually. Second, to handle the degraded input with or without specific reference, dictionary transform module is suggested to read the relevant details from the dual dictionaries which are subsequently fused into the input features. Finally, multi-scale dictionaries are leveraged to benefit the coarse-to-fine restoration. Moreover, a new high-quality dataset, termed CelebRef-HQ, is constructed to promote the exploration of specific face restoration in the high-resolution space.
SuperVessel: Segmenting High-resolution Vessel from Low-resolution Retinal Image
Jul 28, 2022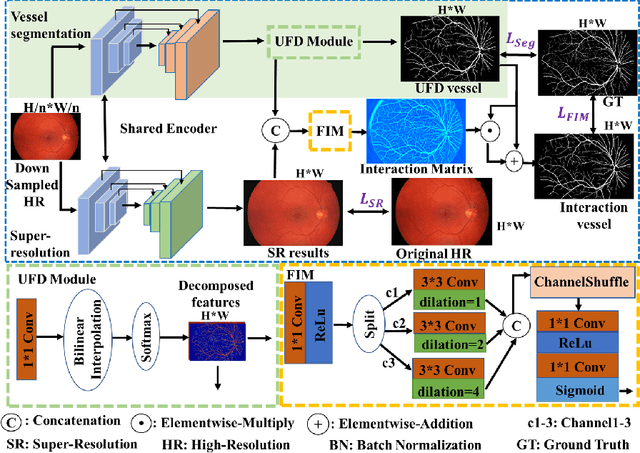
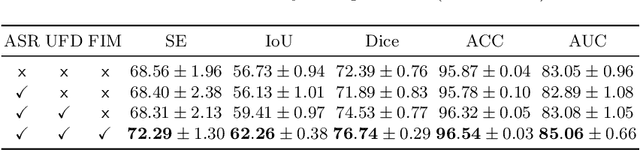
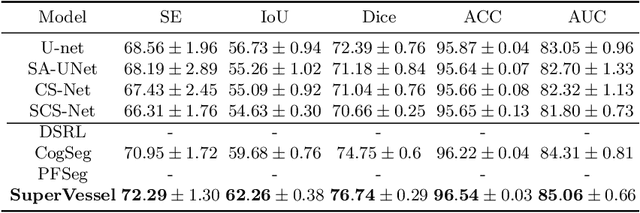
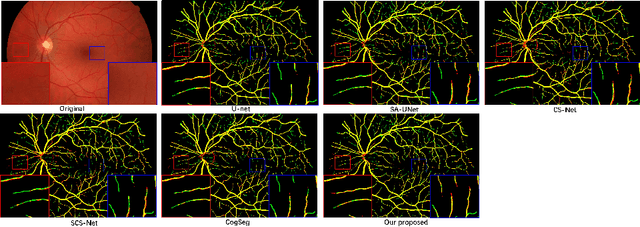
Vascular segmentation extracts blood vessels from images and serves as the basis for diagnosing various diseases, like ophthalmic diseases. Ophthalmologists often require high-resolution segmentation results for analysis, which leads to super-computational load by most existing methods. If based on low-resolution input, they easily ignore tiny vessels or cause discontinuity of segmented vessels. To solve these problems, the paper proposes an algorithm named SuperVessel, which gives out high-resolution and accurate vessel segmentation using low-resolution images as input. We first take super-resolution as our auxiliary branch to provide potential high-resolution detail features, which can be deleted in the test phase. Secondly, we propose two modules to enhance the features of the interested segmentation region, including an upsampling with feature decomposition (UFD) module and a feature interaction module (FIM) with a constraining loss to focus on the interested features. Extensive experiments on three publicly available datasets demonstrate that our proposed SuperVessel can segment more tiny vessels with higher segmentation accuracy IoU over 6%, compared with other state-of-the-art algorithms. Besides, the stability of SuperVessel is also stronger than other algorithms. We will release the code after the paper is published.
A Simple and Powerful Global Optimization for Unsupervised Video Object Segmentation
Sep 19, 2022
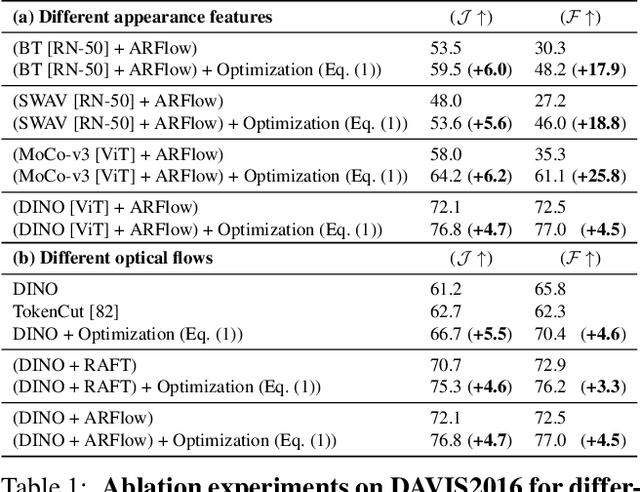

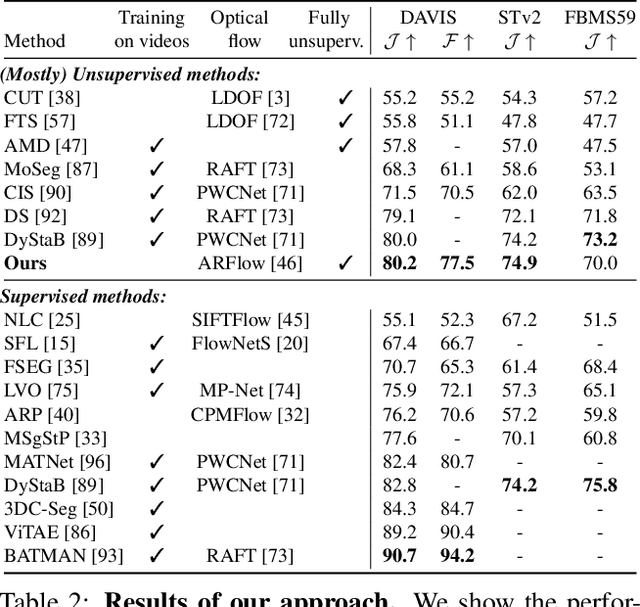
We propose a simple, yet powerful approach for unsupervised object segmentation in videos. We introduce an objective function whose minimum represents the mask of the main salient object over the input sequence. It only relies on independent image features and optical flows, which can be obtained using off-the-shelf self-supervised methods. It scales with the length of the sequence with no need for superpixels or sparsification, and it generalizes to different datasets without any specific training. This objective function can actually be derived from a form of spectral clustering applied to the entire video. Our method achieves on-par performance with the state of the art on standard benchmarks (DAVIS2016, SegTrack-v2, FBMS59), while being conceptually and practically much simpler. Code is available at https://ponimatkin.github.io/ssl-vos.
Sound and Complete Verification of Polynomial Networks
Sep 15, 2022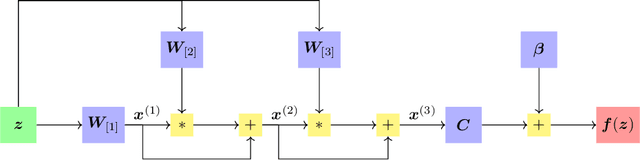
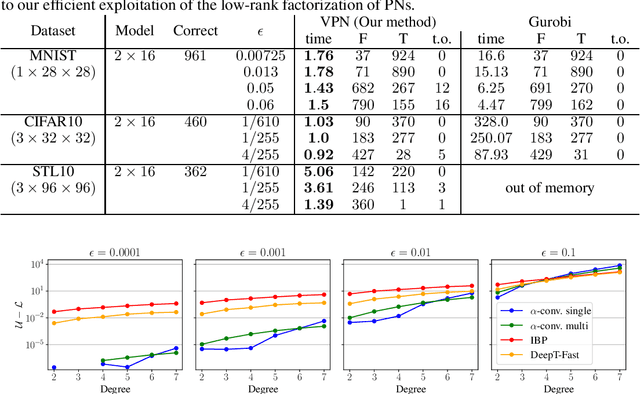
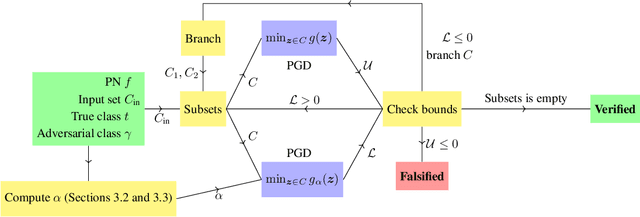
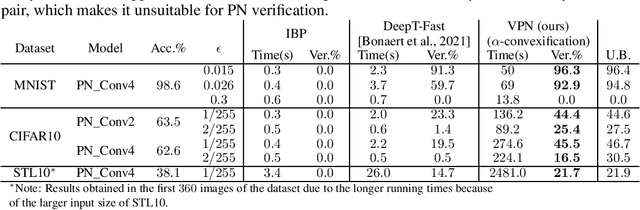
Polynomial Networks (PNs) have demonstrated promising performance on face and image recognition recently. However, robustness of PNs is unclear and thus obtaining certificates becomes imperative for enabling their adoption in real-world applications. Existing verification algorithms on ReLU neural networks (NNs) based on branch and bound (BaB) techniques cannot be trivially applied to PN verification. In this work, we devise a new bounding method, equipped with BaB for global convergence guarantees, called VPN. One key insight is that we obtain much tighter bounds than the interval bound propagation baseline. This enables sound and complete PN verification with empirical validation on MNIST, CIFAR10 and STL10 datasets. We believe our method has its own interest to NN verification.
Improving Contrastive Learning on Visually Homogeneous Mars Rover Images
Oct 17, 2022

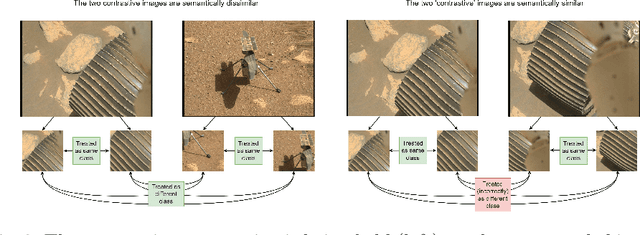

Contrastive learning has recently demonstrated superior performance to supervised learning, despite requiring no training labels. We explore how contrastive learning can be applied to hundreds of thousands of unlabeled Mars terrain images, collected from the Mars rovers Curiosity and Perseverance, and from the Mars Reconnaissance Orbiter. Such methods are appealing since the vast majority of Mars images are unlabeled as manual annotation is labor intensive and requires extensive domain knowledge. Contrastive learning, however, assumes that any given pair of distinct images contain distinct semantic content. This is an issue for Mars image datasets, as any two pairs of Mars images are far more likely to be semantically similar due to the lack of visual diversity on the planet's surface. Making the assumption that pairs of images will be in visual contrast - when they are in fact not - results in pairs that are falsely considered as negatives, impacting training performance. In this study, we propose two approaches to resolve this: 1) an unsupervised deep clustering step on the Mars datasets, which identifies clusters of images containing similar semantic content and corrects false negative errors during training, and 2) a simple approach which mixes data from different domains to increase visual diversity of the total training dataset. Both cases reduce the rate of false negative pairs, thus minimizing the rate in which the model is incorrectly penalized during contrastive training. These modified approaches remain fully unsupervised end-to-end. To evaluate their performance, we add a single linear layer trained to generate class predictions based on these contrastively-learned features and demonstrate increased performance compared to supervised models; observing an improvement in classification accuracy of 3.06% using only 10% of the labeled data.
ExCon: Explanation-driven Supervised Contrastive Learning for Image Classification
Nov 28, 2021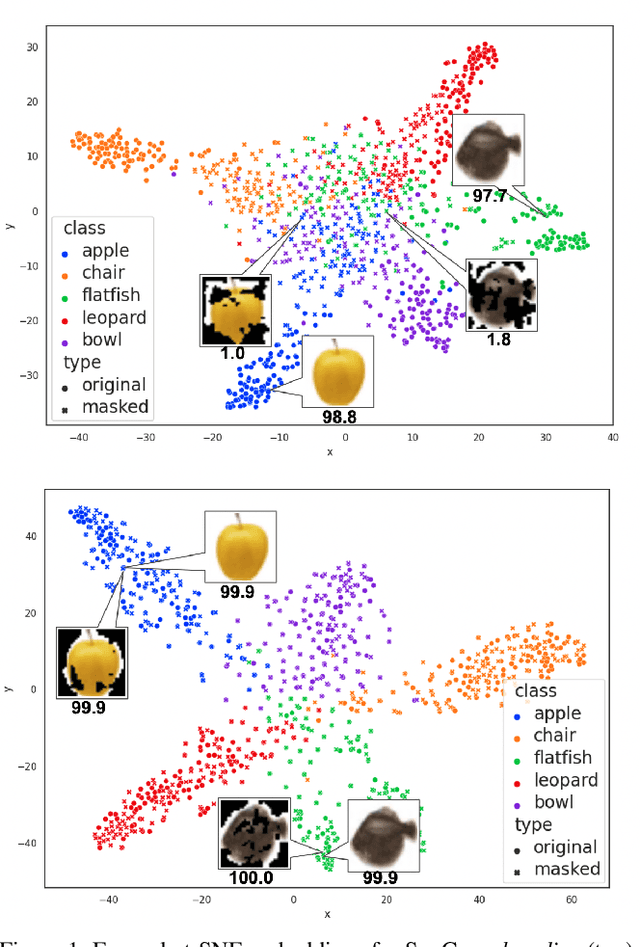
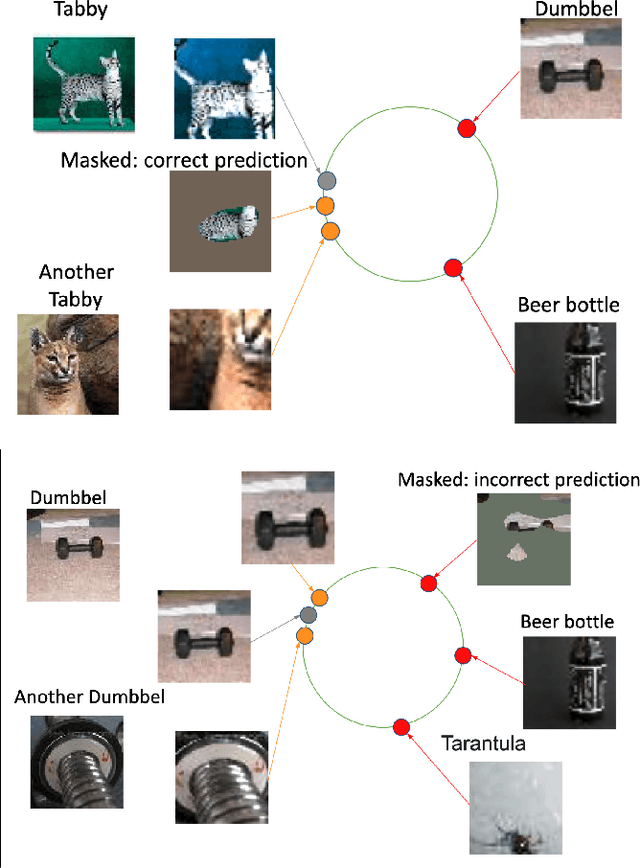
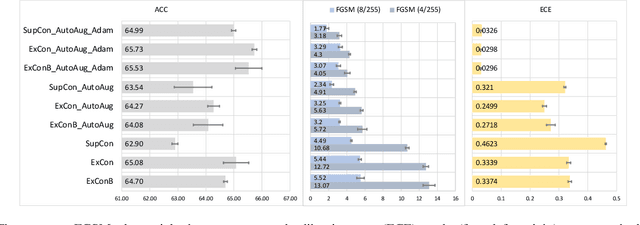
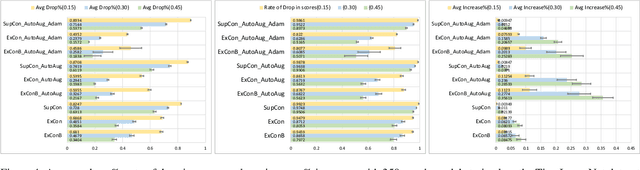
Contrastive learning has led to substantial improvements in the quality of learned embedding representations for tasks such as image classification. However, a key drawback of existing contrastive augmentation methods is that they may lead to the modification of the image content which can yield undesired alterations of its semantics. This can affect the performance of the model on downstream tasks. Hence, in this paper, we ask whether we can augment image data in contrastive learning such that the task-relevant semantic content of an image is preserved. For this purpose, we propose to leverage saliency-based explanation methods to create content-preserving masked augmentations for contrastive learning. Our novel explanation-driven supervised contrastive learning (ExCon) methodology critically serves the dual goals of encouraging nearby image embeddings to have similar content and explanation. To quantify the impact of ExCon, we conduct experiments on the CIFAR-100 and the Tiny ImageNet datasets. We demonstrate that ExCon outperforms vanilla supervised contrastive learning in terms of classification, explanation quality, adversarial robustness as well as calibration of probabilistic predictions of the model in the context of distributional shift.
ECO-TR: Efficient Correspondences Finding Via Coarse-to-Fine Refinement
Sep 25, 2022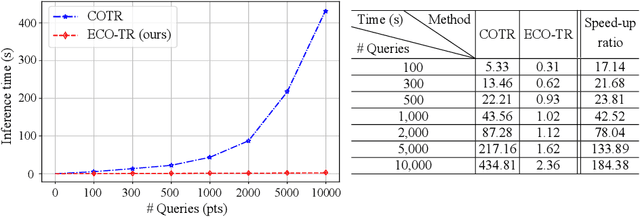
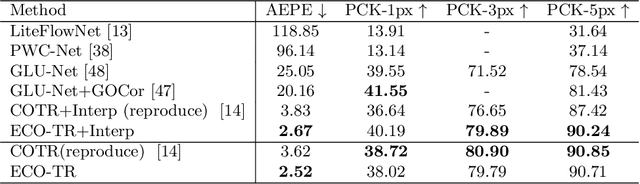
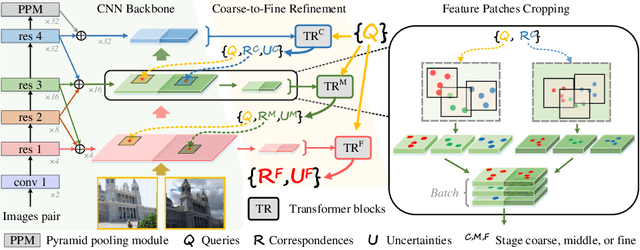
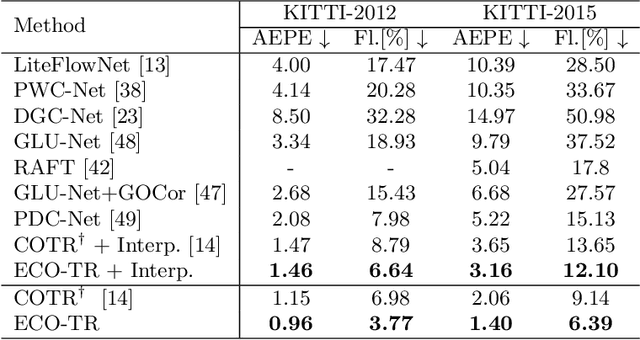
Modeling sparse and dense image matching within a unified functional correspondence model has recently attracted increasing research interest. However, existing efforts mainly focus on improving matching accuracy while ignoring its efficiency, which is crucial for realworld applications. In this paper, we propose an efficient structure named Efficient Correspondence Transformer (ECO-TR) by finding correspondences in a coarse-to-fine manner, which significantly improves the efficiency of functional correspondence model. To achieve this, multiple transformer blocks are stage-wisely connected to gradually refine the predicted coordinates upon a shared multi-scale feature extraction network. Given a pair of images and for arbitrary query coordinates, all the correspondences are predicted within a single feed-forward pass. We further propose an adaptive query-clustering strategy and an uncertainty-based outlier detection module to cooperate with the proposed framework for faster and better predictions. Experiments on various sparse and dense matching tasks demonstrate the superiority of our method in both efficiency and effectiveness against existing state-of-the-arts.