 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Advancing Generative Model Evaluation: A Novel Algorithm for Realistic Image Synthesis and Comparison in OCR System
Feb 28, 2024
This research addresses a critical challenge in the field of generative models, particularly in the generation and evaluation of synthetic images. Given the inherent complexity of generative models and the absence of a standardized procedure for their comparison, our study introduces a pioneering algorithm to objectively assess the realism of synthetic images. This approach significantly enhances the evaluation methodology by refining the Fr\'echet Inception Distance (FID) score, allowing for a more precise and subjective assessment of image quality. Our algorithm is particularly tailored to address the challenges in generating and evaluating realistic images of Arabic handwritten digits, a task that has traditionally been near-impossible due to the subjective nature of realism in image generation. By providing a systematic and objective framework, our method not only enables the comparison of different generative models but also paves the way for improvements in their design and output. This breakthrough in evaluation and comparison is crucial for advancing the field of OCR, especially for scripts that present unique complexities, and sets a new standard in the generation and assessment of high-quality synthetic images.
Adapting Learned Image Codecs to Screen Content via Adjustable Transformations
Feb 27, 2024As learned image codecs (LICs) become more prevalent, their low coding efficiency for out-of-distribution data becomes a bottleneck for some applications. To improve the performance of LICs for screen content (SC) images without breaking backwards compatibility, we propose to introduce parameterized and invertible linear transformations into the coding pipeline without changing the underlying baseline codec's operation flow. We design two neural networks to act as prefilters and postfilters in our setup to increase the coding efficiency and help with the recovery from coding artifacts. Our end-to-end trained solution achieves up to 10% bitrate savings on SC compression compared to the baseline LICs while introducing only 1% extra parameters.
SLCF-Net: Sequential LiDAR-Camera Fusion for Semantic Scene Completion using a 3D Recurrent U-Net
Mar 13, 2024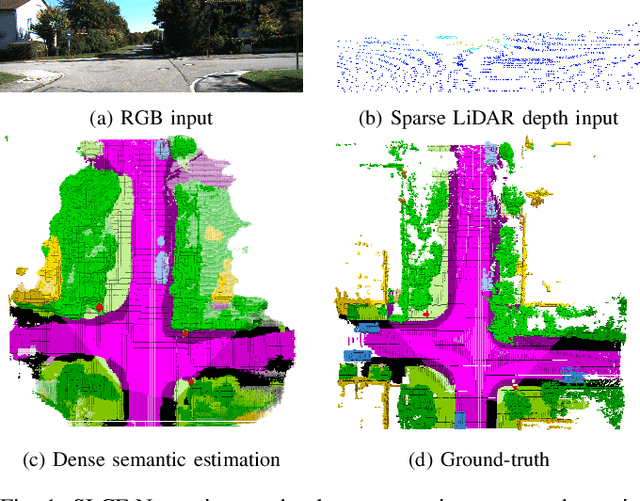
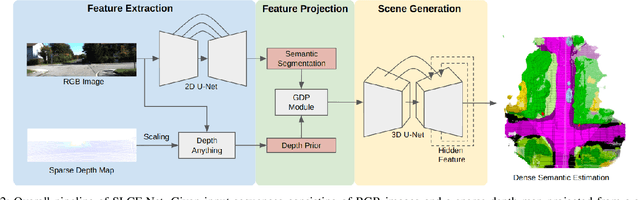
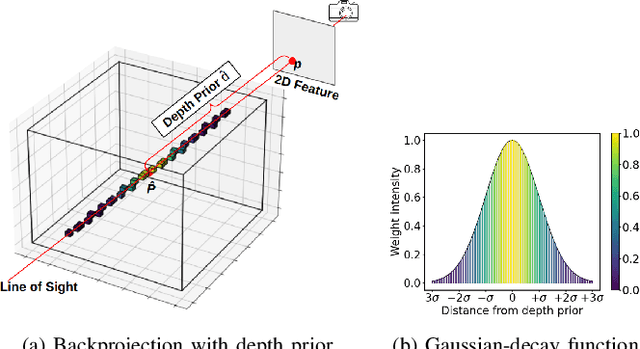
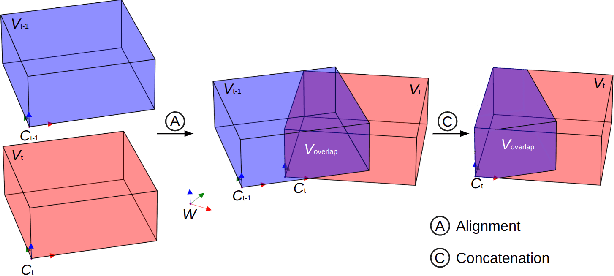
We introduce SLCF-Net, a novel approach for the Semantic Scene Completion (SSC) task that sequentially fuses LiDAR and camera data. It jointly estimates missing geometry and semantics in a scene from sequences of RGB images and sparse LiDAR measurements. The images are semantically segmented by a pre-trained 2D U-Net and a dense depth prior is estimated from a depth-conditioned pipeline fueled by Depth Anything. To associate the 2D image features with the 3D scene volume, we introduce Gaussian-decay Depth-prior Projection (GDP). This module projects the 2D features into the 3D volume along the line of sight with a Gaussian-decay function, centered around the depth prior. Volumetric semantics is computed by a 3D U-Net. We propagate the hidden 3D U-Net state using the sensor motion and design a novel loss to ensure temporal consistency. We evaluate our approach on the SemanticKITTI dataset and compare it with leading SSC approaches. The SLCF-Net excels in all SSC metrics and shows great temporal consistency.
Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization
Mar 13, 2024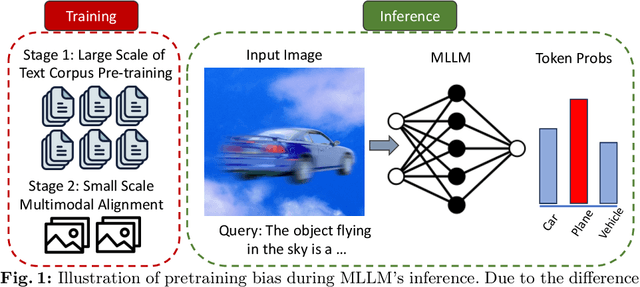


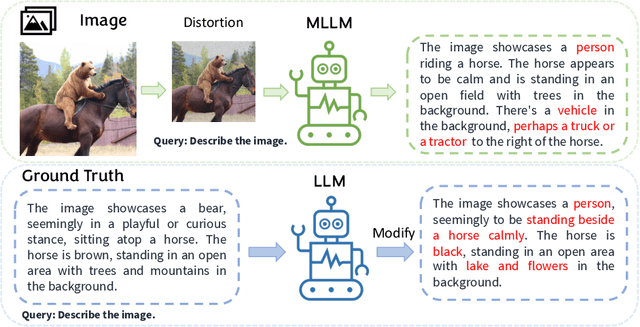
Multimodal Large Language Models (MLLMs) excel in generating responses based on visual inputs. However, they often suffer from a bias towards generating responses similar to their pretraining corpus, overshadowing the importance of visual information. We treat this bias as a "preference" for pretraining statistics, which hinders the model's grounding in visual input. To mitigate this issue, we propose Bootstrapped Preference Optimization (BPO), which conducts preference learning with datasets containing negative responses bootstrapped from the model itself. Specifically, we propose the following two strategies: 1) using distorted image inputs to the MLLM for eliciting responses that contain signified pretraining bias; 2) leveraging text-based LLM to explicitly inject erroneous but common elements into the original response. Those undesirable responses are paired with original annotated responses from the datasets to construct the preference dataset, which is subsequently utilized to perform preference learning. Our approach effectively suppresses pretrained LLM bias, enabling enhanced grounding in visual inputs. Extensive experimentation demonstrates significant performance improvements across multiple benchmarks, advancing the state-of-the-art in multimodal conversational systems.
PaddingFlow: Improving Normalizing Flows with Padding-Dimensional Noise
Mar 13, 2024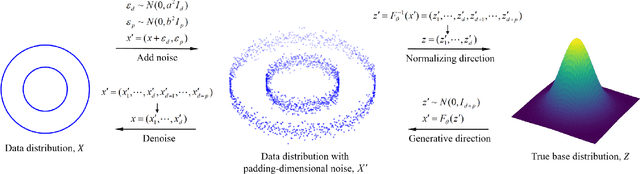
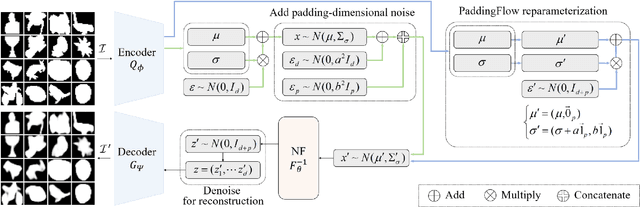
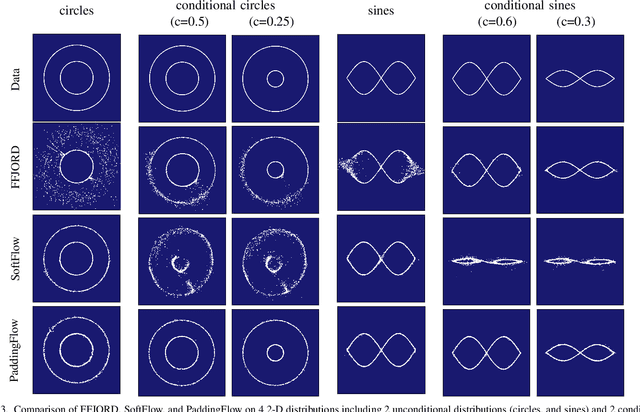
Normalizing flow is a generative modeling approach with efficient sampling. However, Flow-based models suffer two issues, which are manifold and discrete data. If the target distribution is a manifold, which means the dimension of the latent target distribution and the dimension of the data distribution are unmatched, flow-based models might perform badly. Discrete data makes flow-based models collapse into a degenerate mixture of point masses. In this paper, to sidestep such two issues we propose PaddingFlow, a novel dequantization method, which improves normalizing flows with padding-dimensional noise. PaddingFlow is easy to implement, computationally cheap, widely suitable for various tasks, and generates samples that are unbiased estimations of the data. Especially, our method can overcome the limitation of existing dequantization methods that have to change the data distribution, which might degrade performance. We validate our method on the main benchmarks of unconditional density estimation, including five tabular datasets and four image datasets for VAE models, and the IK experiments which are conditional density estimation. The results show that PaddingFlow can provide improvement on all tasks in this paper.
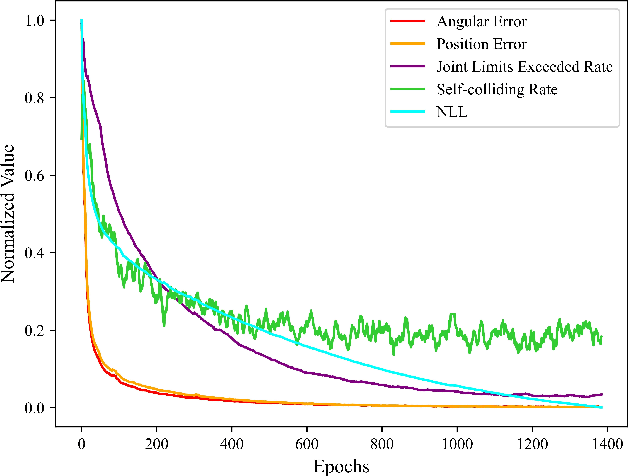
Spatiotemporal Predictive Pre-training for Robotic Motor Control
Mar 14, 2024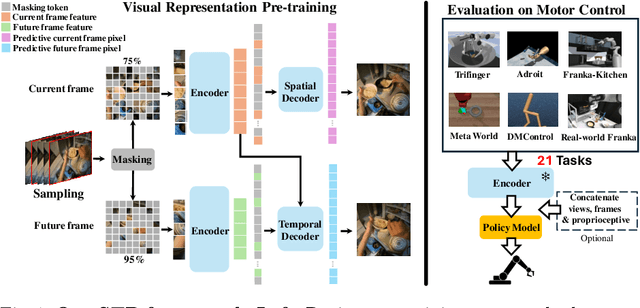
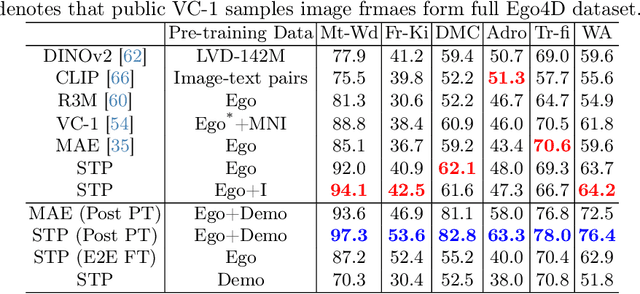


Robotic motor control necessitates the ability to predict the dynamics of environments and interaction objects. However, advanced self-supervised pre-trained visual representations (PVRs) in robotic motor control, leveraging large-scale egocentric videos, often focus solely on learning the static content features of sampled image frames. This neglects the crucial temporal motion clues in human video data, which implicitly contain key knowledge about sequential interacting and manipulating with the environments and objects. In this paper, we present a simple yet effective robotic motor control visual pre-training framework that jointly performs spatiotemporal predictive learning utilizing large-scale video data, termed as STP. Our STP samples paired frames from video clips. It adheres to two key designs in a multi-task learning manner. First, we perform spatial prediction on the masked current frame for learning content features. Second, we utilize the future frame with an extremely high masking ratio as a condition, based on the masked current frame, to conduct temporal prediction of future frame for capturing motion features. These efficient designs ensure that our representation focusing on motion information while capturing spatial details. We carry out the largest-scale evaluation of PVRs for robotic motor control to date, which encompasses 21 tasks within a real-world Franka robot arm and 5 simulated environments. Extensive experiments demonstrate the effectiveness of STP as well as unleash its generality and data efficiency by further post-pre-training and hybrid pre-training.
GiT: Towards Generalist Vision Transformer through Universal Language Interface
Mar 14, 2024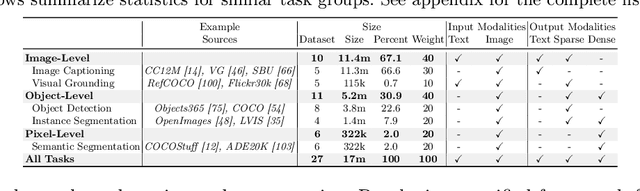

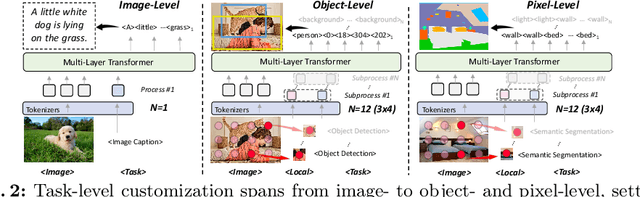
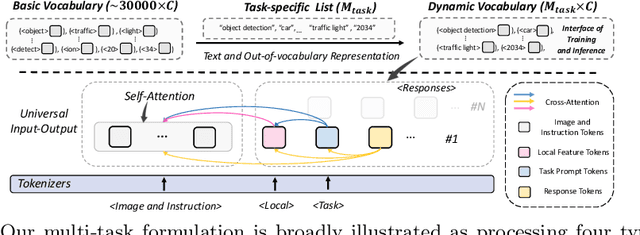
This paper proposes a simple, yet effective framework, called GiT, simultaneously applicable for various vision tasks only with a vanilla ViT. Motivated by the universality of the Multi-layer Transformer architecture (e.g, GPT) widely used in large language models (LLMs), we seek to broaden its scope to serve as a powerful vision foundation model (VFM). However, unlike language modeling, visual tasks typically require specific modules, such as bounding box heads for detection and pixel decoders for segmentation, greatly hindering the application of powerful multi-layer transformers in the vision domain. To solve this, we design a universal language interface that empowers the successful auto-regressive decoding to adeptly unify various visual tasks, from image-level understanding (e.g., captioning), over sparse perception (e.g., detection), to dense prediction (e.g., segmentation). Based on the above designs, the entire model is composed solely of a ViT, without any specific additions, offering a remarkable architectural simplification. GiT is a multi-task visual model, jointly trained across five representative benchmarks without task-specific fine-tuning. Interestingly, our GiT builds a new benchmark in generalist performance, and fosters mutual enhancement across tasks, leading to significant improvements compared to isolated training. This reflects a similar impact observed in LLMs. Further enriching training with 27 datasets, GiT achieves strong zero-shot results over various tasks. Due to its simple design, this paradigm holds promise for narrowing the architectural gap between vision and language. Code and models will be available at \url{https://github.com/Haiyang-W/GiT}.
PosSAM: Panoptic Open-vocabulary Segment Anything
Mar 14, 2024
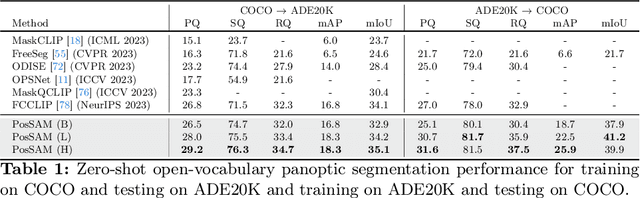

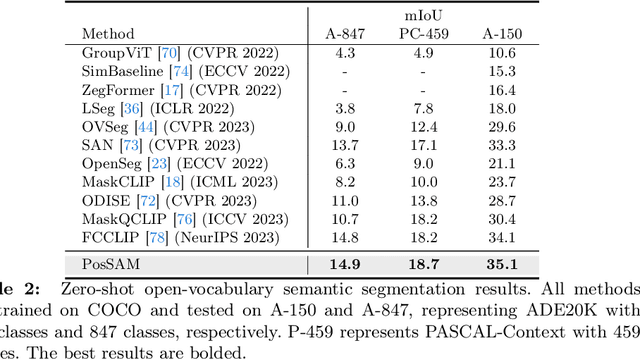
In this paper, we introduce an open-vocabulary panoptic segmentation model that effectively unifies the strengths of the Segment Anything Model (SAM) with the vision-language CLIP model in an end-to-end framework. While SAM excels in generating spatially-aware masks, it's decoder falls short in recognizing object class information and tends to oversegment without additional guidance. Existing approaches address this limitation by using multi-stage techniques and employing separate models to generate class-aware prompts, such as bounding boxes or segmentation masks. Our proposed method, PosSAM is an end-to-end model which leverages SAM's spatially rich features to produce instance-aware masks and harnesses CLIP's semantically discriminative features for effective instance classification. Specifically, we address the limitations of SAM and propose a novel Local Discriminative Pooling (LDP) module leveraging class-agnostic SAM and class-aware CLIP features for unbiased open-vocabulary classification. Furthermore, we introduce a Mask-Aware Selective Ensembling (MASE) algorithm that adaptively enhances the quality of generated masks and boosts the performance of open-vocabulary classification during inference for each image. We conducted extensive experiments to demonstrate our methods strong generalization properties across multiple datasets, achieving state-of-the-art performance with substantial improvements over SOTA open-vocabulary panoptic segmentation methods. In both COCO to ADE20K and ADE20K to COCO settings, PosSAM outperforms the previous state-of-the-art methods by a large margin, 2.4 PQ and 4.6 PQ, respectively. Project Website: https://vibashan.github.io/possam-web/.
FastVideoEdit: Leveraging Consistency Models for Efficient Text-to-Video Editing
Mar 10, 2024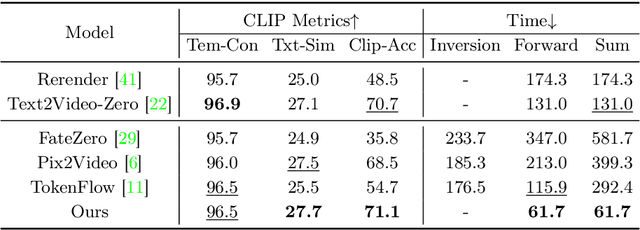
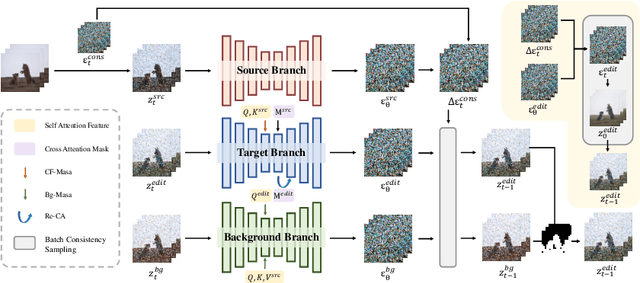
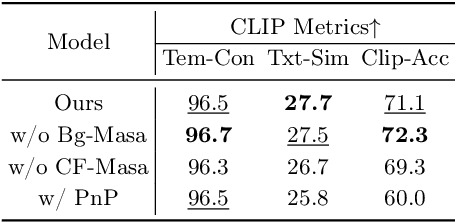

Diffusion models have demonstrated remarkable capabilities in text-to-image and text-to-video generation, opening up possibilities for video editing based on textual input. However, the computational cost associated with sequential sampling in diffusion models poses challenges for efficient video editing. Existing approaches relying on image generation models for video editing suffer from time-consuming one-shot fine-tuning, additional condition extraction, or DDIM inversion, making real-time applications impractical. In this work, we propose FastVideoEdit, an efficient zero-shot video editing approach inspired by Consistency Models (CMs). By leveraging the self-consistency property of CMs, we eliminate the need for time-consuming inversion or additional condition extraction, reducing editing time. Our method enables direct mapping from source video to target video with strong preservation ability utilizing a special variance schedule. This results in improved speed advantages, as fewer sampling steps can be used while maintaining comparable generation quality. Experimental results validate the state-of-the-art performance and speed advantages of FastVideoEdit across evaluation metrics encompassing editing speed, temporal consistency, and text-video alignment.
CDSE-UNet: Enhancing COVID-19 CT Image Segmentation with Canny Edge Detection and Dual-Path SENet Feature Fusion
Mar 03, 2024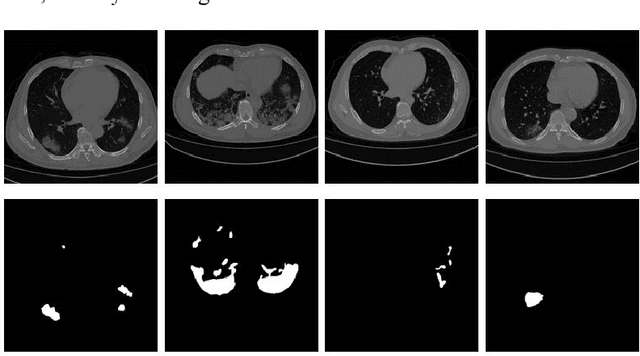
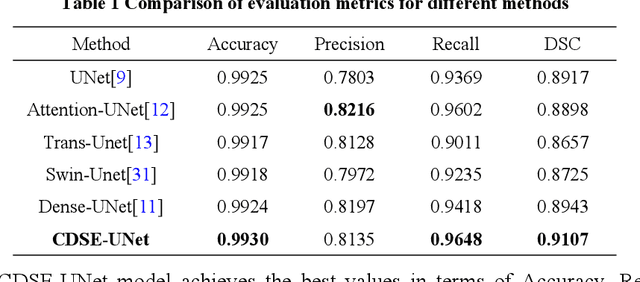
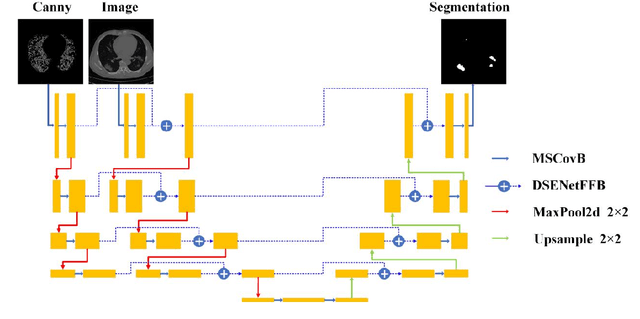
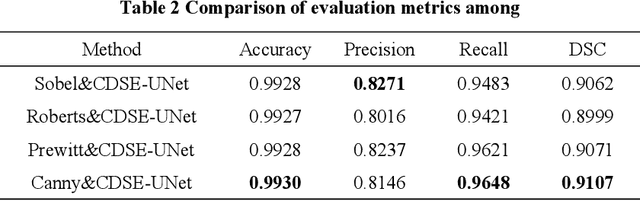
Accurate segmentation of COVID-19 CT images is crucial for reducing the severity and mortality rates associated with COVID-19 infections. In response to blurred boundaries and high variability characteristic of lesion areas in COVID-19 CT images, we introduce CDSE-UNet: a novel UNet-based segmentation model that integrates Canny operator edge detection and a dual-path SENet feature fusion mechanism. This model enhances the standard UNet architecture by employing the Canny operator for edge detection in sample images, paralleling this with a similar network structure for semantic feature extraction. A key innovation is the Double SENet Feature Fusion Block, applied across corresponding network layers to effectively combine features from both image paths. Moreover, we have developed a Multiscale Convolution approach, replacing the standard Convolution in UNet, to adapt to the varied lesion sizes and shapes. This addition not only aids in accurately classifying lesion edge pixels but also significantly improves channel differentiation and expands the capacity of the model. Our evaluations on public datasets demonstrate CDSE-UNet's superior performance over other leading models, particularly in segmenting large and small lesion areas, accurately delineating lesion edges, and effectively suppressing noise