 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LiT: Zero-Shot Transfer with Locked-image Text Tuning
Nov 15, 2021
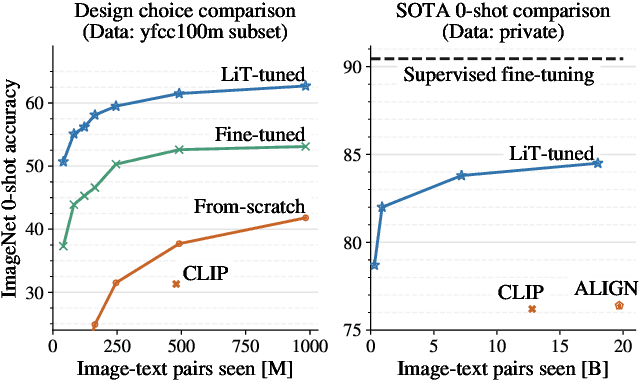
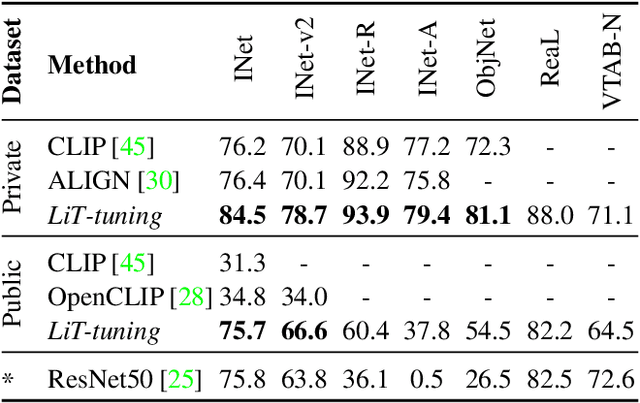
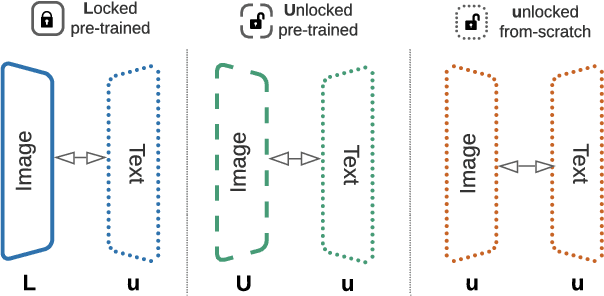

This paper presents contrastive-tuning, a simple method employing contrastive training to align image and text models while still taking advantage of their pre-training. In our empirical study we find that locked pre-trained image models with unlocked text models work best. We call this instance of contrastive-tuning "Locked-image Text tuning" (LiT-tuning), which just teaches a text model to read out good representations from a pre-trained image model for new tasks. A LiT-tuned model gains the capability of zero-shot transfer to new vision tasks, such as image classification or retrieval. The proposed LiT-tuning is widely applicable; it works reliably with multiple pre-training methods (supervised and unsupervised) and across diverse architectures (ResNet, Vision Transformers and MLP-Mixer) using three different image-text datasets. With the transformer-based pre-trained ViT-g/14 model, the LiT-tuned model achieves 84.5% zero-shot transfer accuracy on the ImageNet test set, and 81.1% on the challenging out-of-distribution ObjectNet test set.
Revisiting Global Statistics Aggregation for Improving Image Restoration
Dec 08, 2021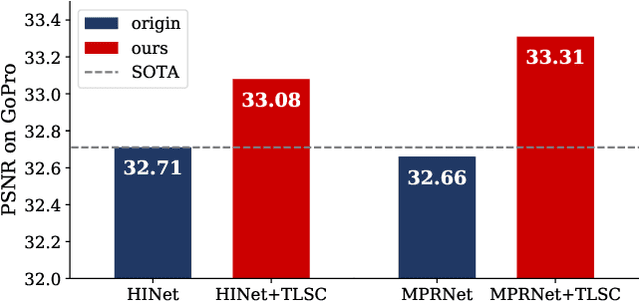
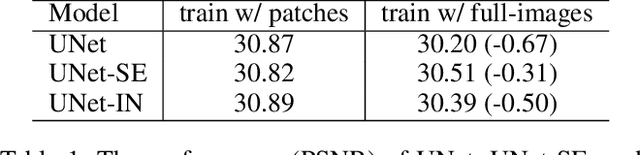
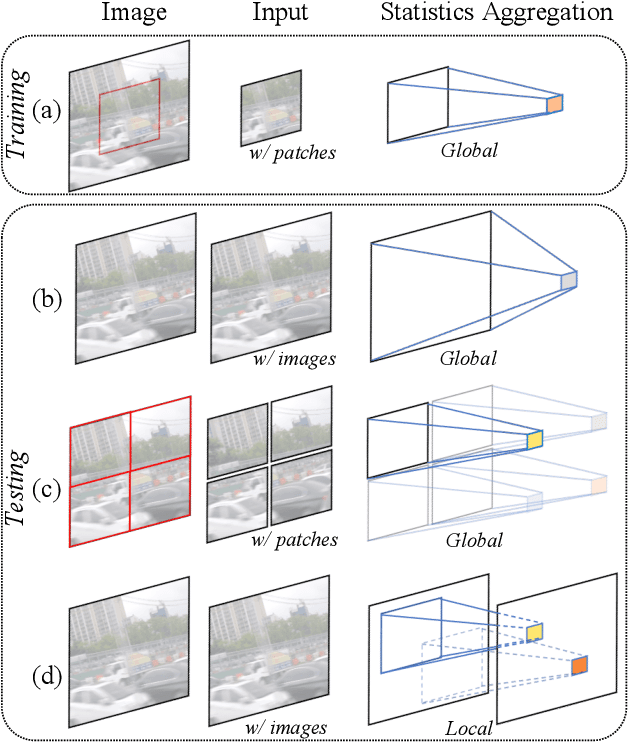
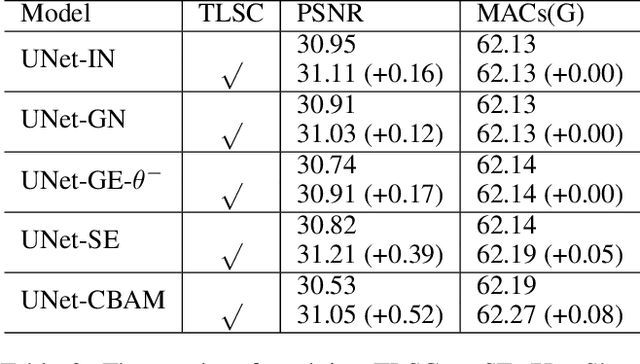
Global spatial statistics, which are aggregated along entire spatial dimensions, are widely used in top-performance image restorers. For example, mean, variance in Instance Normalization (IN) which is adopted by HINet, and global average pooling (i.e. mean) in Squeeze and Excitation (SE) which is applied to MPRNet. This paper first shows that statistics aggregated on the patches-based/entire-image-based feature in the training/testing phase respectively may distribute very differently and lead to performance degradation in image restorers. It has been widely overlooked by previous works. To solve this issue, we propose a simple approach, Test-time Local Statistics Converter (TLSC), that replaces the region of statistics aggregation operation from global to local, only in the test time. Without retraining or finetuning, our approach significantly improves the image restorer's performance. In particular, by extending SE with TLSC to the state-of-the-art models, MPRNet boost by 0.65 dB in PSNR on GoPro dataset, achieves 33.31 dB, exceeds the previous best result 0.6 dB. In addition, we simply apply TLSC to the high-level vision task, i.e. semantic segmentation, and achieves competitive results. Extensive quantity and quality experiments are conducted to demonstrate TLSC solves the issue with marginal costs while significant gain. The code is available at https://github.com/megvii-research/tlsc.
Semantic Representation and Dependency Learning for Multi-Label Image Recognition
Apr 08, 2022
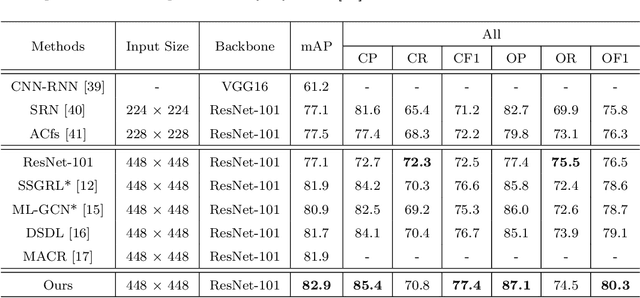
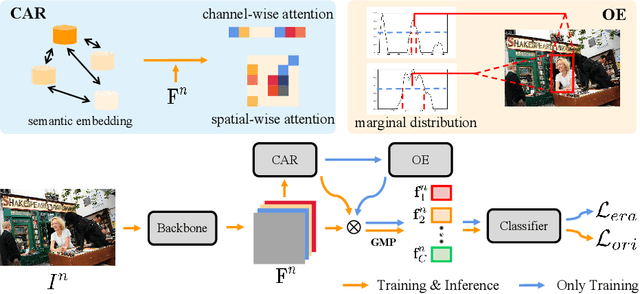
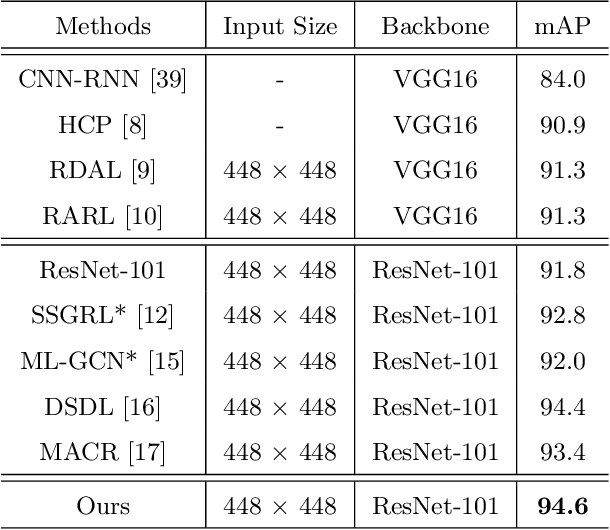
Recently many multi-label image recognition (MLR) works have made significant progress by introducing pre-trained object detection models to generate lots of proposals or utilizing statistical label co-occurrence enhance the correlation among different categories. However, these works have some limitations: (1) the effectiveness of the network significantly depends on pre-trained object detection models that bring expensive and unaffordable computation; (2) the network performance degrades when there exist occasional co-occurrence objects in images, especially for the rare categories. To address these problems, we propose a novel and effective semantic representation and dependency learning (SRDL) framework to learn category-specific semantic representation for each category and capture semantic dependency among all categories. Specifically, we design a category-specific attentional regions (CAR) module to generate channel/spatial-wise attention matrices to guide model to focus on semantic-aware regions. We also design an object erasing (OE) module to implicitly learn semantic dependency among categories by erasing semantic-aware regions to regularize the network training. Extensive experiments and comparisons on two popular MLR benchmark datasets (i.e., MS-COCO and Pascal VOC 2007) demonstrate the effectiveness of the proposed framework over current state-of-the-art algorithms.
Learning with Label Noise for Image Retrieval by Selecting Interactions
Dec 21, 2021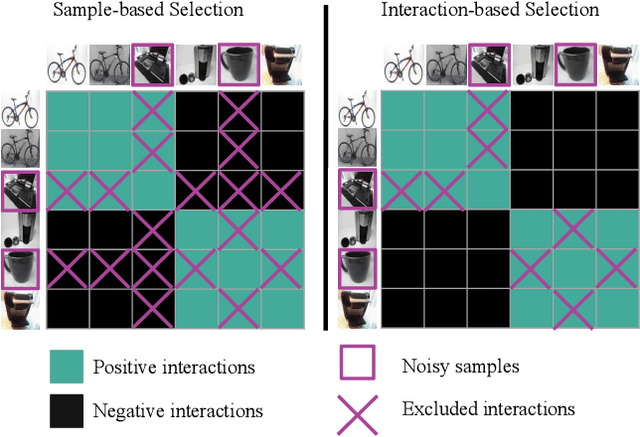
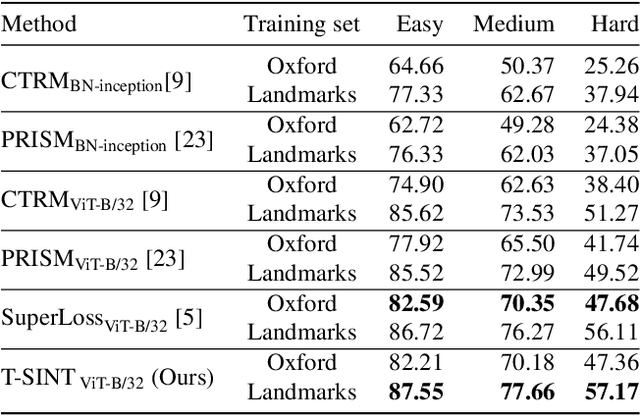
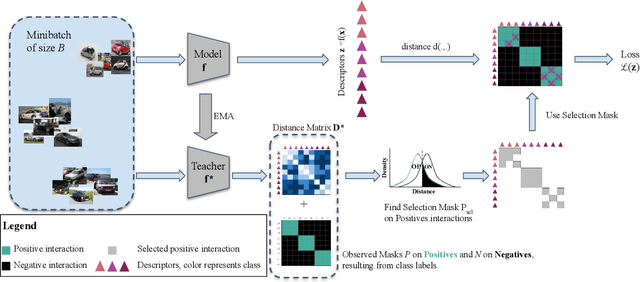
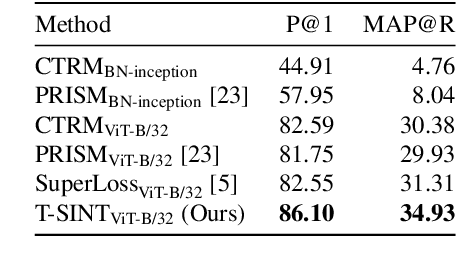
Learning with noisy labels is an active research area for image classification. However, the effect of noisy labels on image retrieval has been less studied. In this work, we propose a noise-resistant method for image retrieval named Teacher-based Selection of Interactions, T-SINT, which identifies noisy interactions, ie. elements in the distance matrix, and selects correct positive and negative interactions to be considered in the retrieval loss by using a teacher-based training setup which contributes to the stability. As a result, it consistently outperforms state-of-the-art methods on high noise rates across benchmark datasets with synthetic noise and more realistic noise.
NeuralRoom: Geometry-Constrained Neural Implicit Surfaces for Indoor Scene Reconstruction
Oct 13, 2022


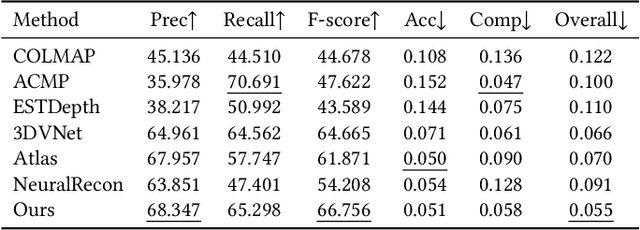
We present a novel neural surface reconstruction method called NeuralRoom for reconstructing room-sized indoor scenes directly from a set of 2D images. Recently, implicit neural representations have become a promising way to reconstruct surfaces from multiview images due to their high-quality results and simplicity. However, implicit neural representations usually cannot reconstruct indoor scenes well because they suffer severe shape-radiance ambiguity. We assume that the indoor scene consists of texture-rich and flat texture-less regions. In texture-rich regions, the multiview stereo can obtain accurate results. In the flat area, normal estimation networks usually obtain a good normal estimation. Based on the above observations, we reduce the possible spatial variation range of implicit neural surfaces by reliable geometric priors to alleviate shape-radiance ambiguity. Specifically, we use multiview stereo results to limit the NeuralRoom optimization space and then use reliable geometric priors to guide NeuralRoom training. Then the NeuralRoom would produce a neural scene representation that can render an image consistent with the input training images. In addition, we propose a smoothing method called perturbation-residual restrictions to improve the accuracy and completeness of the flat region, which assumes that the sampling points in a local surface should have the same normal and similar distance to the observation center. Experiments on the ScanNet dataset show that our method can reconstruct the texture-less area of indoor scenes while maintaining the accuracy of detail. We also apply NeuralRoom to more advanced multiview reconstruction algorithms and significantly improve their reconstruction quality.
An Experiment Design Paradigm using Joint Feature Selection and Task Optimization
Oct 13, 2022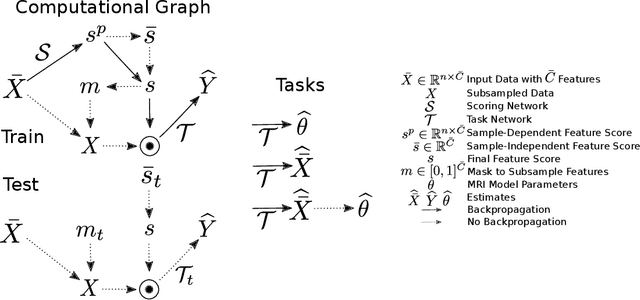
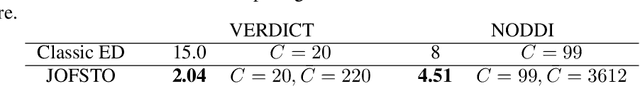

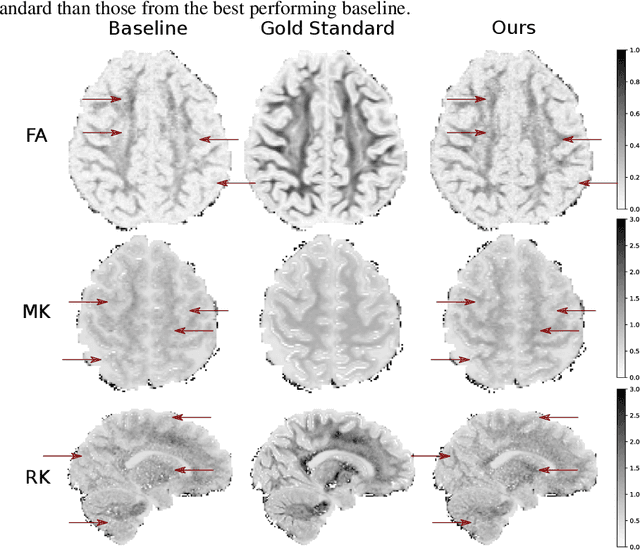
This paper presents a subsampling-task paradigm for data-driven task-specific experiment design (ED) and a novel method in populationwide supervised feature selection (FS). Optimal ED, the choice of sampling points under constraints of limited acquisition-time, arises in a wide variety of scientific and engineering contexts. However the continuous optimization used in classical approaches depend on a-priori parameter choices and challenging non-convex optimization landscapes. This paper proposes to replace this strategy with a subsampling-task paradigm, analogous to populationwide supervised FS. In particular, we introduce JOFSTO, which performs JOint Feature Selection and Task Optimization. JOFSTO jointly optimizes two coupled networks: one for feature scoring, which provides the ED, the other for execution of a downstream task or process. Unlike most FS problems, e.g. selecting protein expressions for classification, ED problems typically select from highly correlated globally informative candidates rather than seeking a small number of highly informative features among many uninformative features. JOFSTO's construction efficiently identifies potentially correlated, but effective subsets and returns a trained task network. We demonstrate the approach using parameter estimation and mapping problems in quantitative MRI, where economical ED is crucial for clinical application. Results from simulations and empirical data show the subsampling-task paradigm strongly outperforms classical ED, and within our paradigm, JOFSTO outperforms state-of-the-art supervised FS techniques. JOFSTO extends immediately to wider image-based ED problems and other scenarios where the design must be specified globally across large numbers of acquisitions. Code will be released.
Reducing Annotation Effort by Identifying and Labeling Contextually Diverse Classes for Semantic Segmentation Under Domain Shift
Oct 13, 2022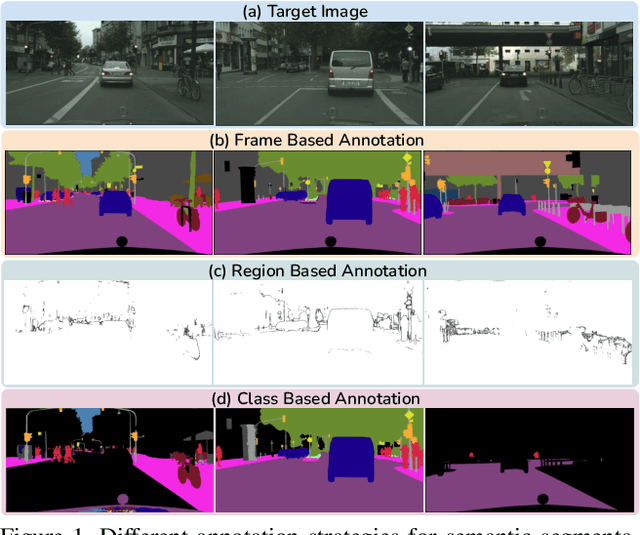
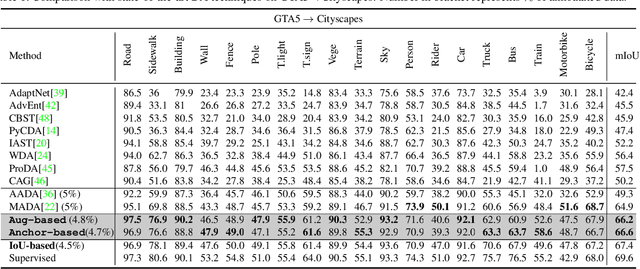
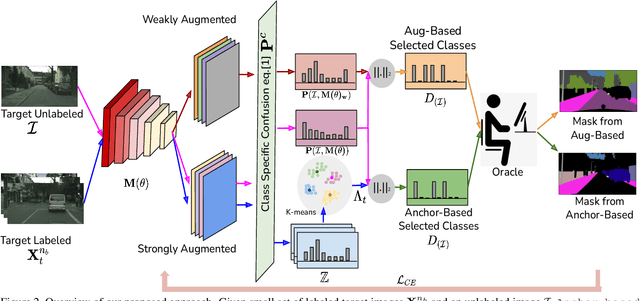
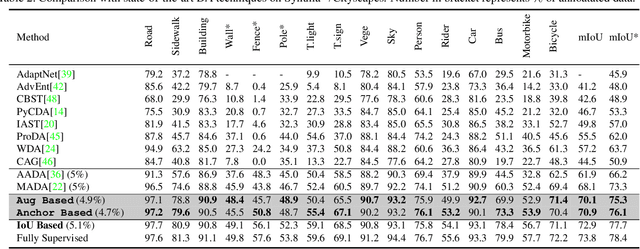
In Active Domain Adaptation (ADA), one uses Active Learning (AL) to select a subset of images from the target domain, which are then annotated and used for supervised domain adaptation (DA). Given the large performance gap between supervised and unsupervised DA techniques, ADA allows for an excellent trade-off between annotation cost and performance. Prior art makes use of measures of uncertainty or disagreement of models to identify `regions' to be annotated by the human oracle. However, these regions frequently comprise of pixels at object boundaries which are hard and tedious to annotate. Hence, even if the fraction of image pixels annotated reduces, the overall annotation time and the resulting cost still remain high. In this work, we propose an ADA strategy, which given a frame, identifies a set of classes that are hardest for the model to predict accurately, thereby recommending semantically meaningful regions to be annotated in a selected frame. We show that these set of `hard' classes are context-dependent and typically vary across frames, and when annotated help the model generalize better. We propose two ADA techniques: the Anchor-based and Augmentation-based approaches to select complementary and diverse regions in the context of the current training set. Our approach achieves 66.6 mIoU on GTA to Cityscapes dataset with an annotation budget of 4.7% in comparison to 64.9 mIoU by MADA using 5% of annotations. Our technique can also be used as a decorator for any existing frame-based AL technique, e.g., we report 1.5% performance improvement for CDAL on Cityscapes using our approach.
Towards Accurate Facial Landmark Detection via Cascaded Transformers
Aug 23, 2022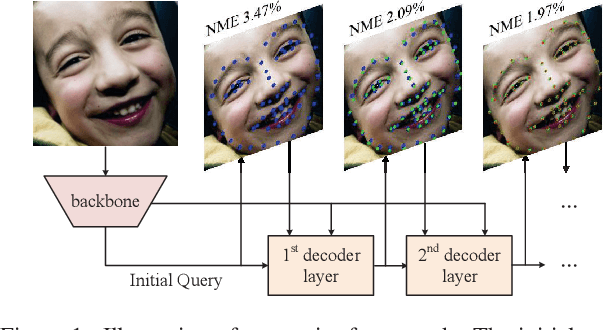
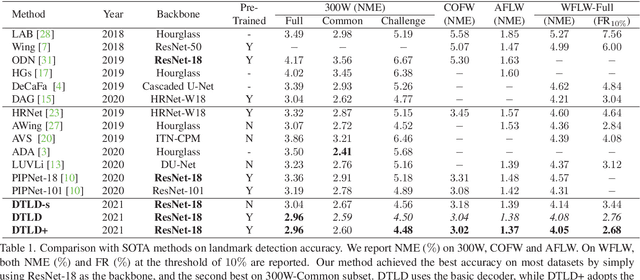
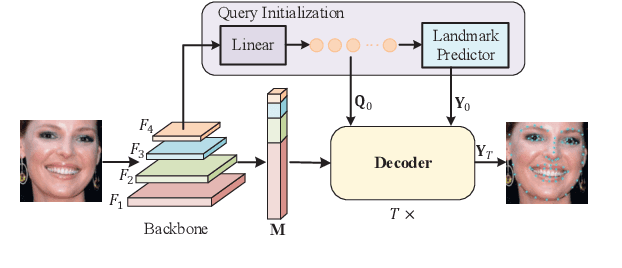

Accurate facial landmarks are essential prerequisites for many tasks related to human faces. In this paper, an accurate facial landmark detector is proposed based on cascaded transformers. We formulate facial landmark detection as a coordinate regression task such that the model can be trained end-to-end. With self-attention in transformers, our model can inherently exploit the structured relationships between landmarks, which would benefit landmark detection under challenging conditions such as large pose and occlusion. During cascaded refinement, our model is able to extract the most relevant image features around the target landmark for coordinate prediction, based on deformable attention mechanism, thus bringing more accurate alignment. In addition, we propose a novel decoder that refines image features and landmark positions simultaneously. With few parameter increasing, the detection performance improves further. Our model achieves new state-of-the-art performance on several standard facial landmark detection benchmarks, and shows good generalization ability in cross-dataset evaluation.
Diffusion Models for Implicit Image Segmentation Ensembles
Dec 27, 2021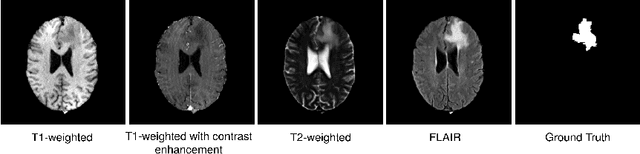
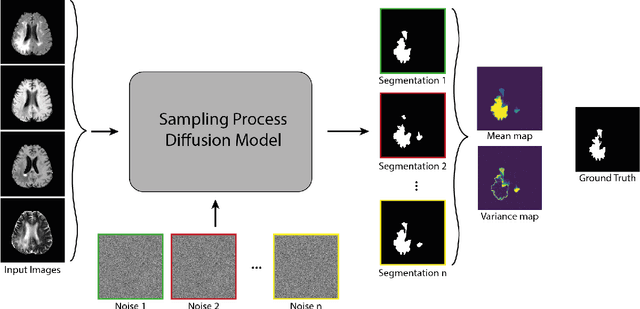

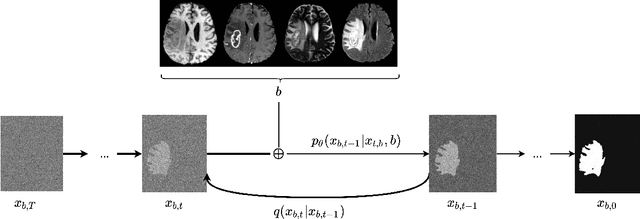
Diffusion models have shown impressive performance for generative modelling of images. In this paper, we present a novel semantic segmentation method based on diffusion models. By modifying the training and sampling scheme, we show that diffusion models can perform lesion segmentation of medical images. To generate an image specific segmentation, we train the model on the ground truth segmentation, and use the image as a prior during training and in every step during the sampling process. With the given stochastic sampling process, we can generate a distribution of segmentation masks. This property allows us to compute pixel-wise uncertainty maps of the segmentation, and allows an implicit ensemble of segmentations that increases the segmentation performance. We evaluate our method on the BRATS2020 dataset for brain tumor segmentation. Compared to state-of-the-art segmentation models, our approach yields good segmentation results and, additionally, detailed uncertainty maps.
Adnexal Mass Segmentation with Ultrasound Data Synthesis
Sep 25, 2022Ovarian cancer is the most lethal gynaecological malignancy. The disease is most commonly asymptomatic at its early stages and its diagnosis relies on expert evaluation of transvaginal ultrasound images. Ultrasound is the first-line imaging modality for characterising adnexal masses, it requires significant expertise and its analysis is subjective and labour-intensive, therefore open to error. Hence, automating processes to facilitate and standardise the evaluation of scans is desired in clinical practice. Using supervised learning, we have demonstrated that segmentation of adnexal masses is possible, however, prevalence and label imbalance restricts the performance on under-represented classes. To mitigate this we apply a novel pathology-specific data synthesiser. We create synthetic medical images with their corresponding ground truth segmentations by using Poisson image editing to integrate less common masses into other samples. Our approach achieves the best performance across all classes, including an improvement of up to 8% when compared with nnU-Net baseline approaches.