 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3DPCT: 3D Point Cloud Transformer with Dual Self-attention
Sep 21, 2022
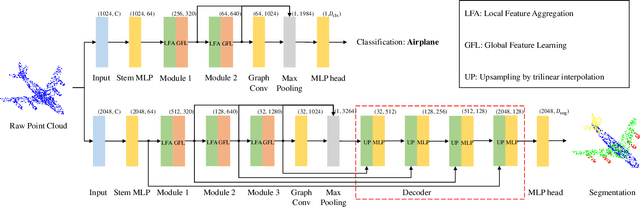
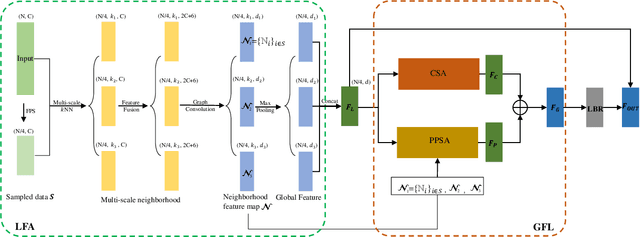
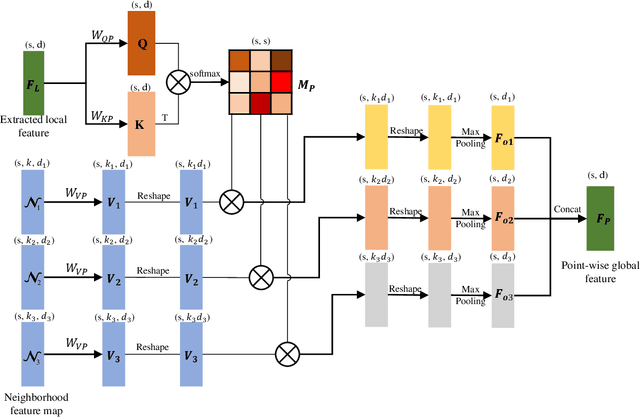
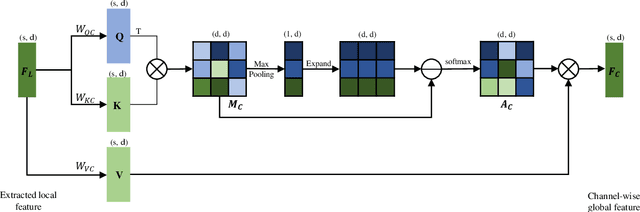
Transformers have resulted in remarkable achievements in the field of image processing. Inspired by this great success, the application of Transformers to 3D point cloud processing has drawn more and more attention. This paper presents a novel point cloud representational learning network, 3D Point Cloud Transformer with Dual Self-attention (3DPCT) and an encoder-decoder structure. Specifically, 3DPCT has a hierarchical encoder, which contains two local-global dual-attention modules for the classification task (three modules for the segmentation task), with each module consisting of a Local Feature Aggregation (LFA) block and a Global Feature Learning (GFL) block. The GFL block is dual self-attention, with both point-wise and channel-wise self-attention to improve feature extraction. Moreover, in LFA, to better leverage the local information extracted, a novel point-wise self-attention model, named as Point-Patch Self-Attention (PPSA), is designed. The performance is evaluated on both classification and segmentation datasets, containing both synthetic and real-world data. Extensive experiments demonstrate that the proposed method achieved state-of-the-art results on both classification and segmentation tasks.
Slice estimation in diffusion MRI of neonatal and fetal brains in image and spherical harmonics domains using autoencoders
Aug 29, 2022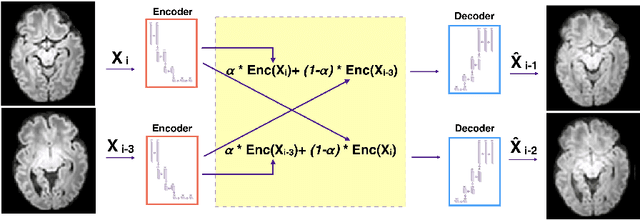
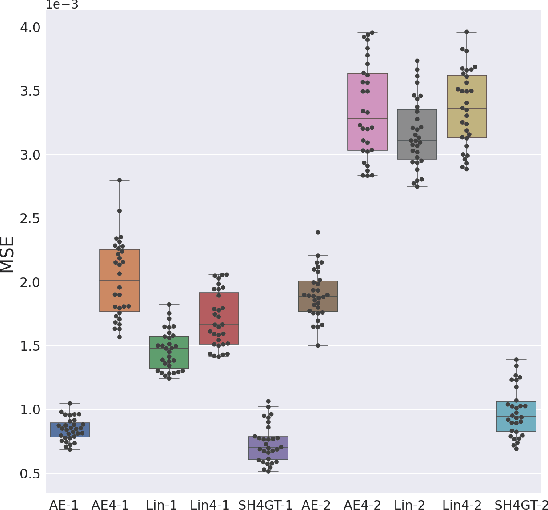
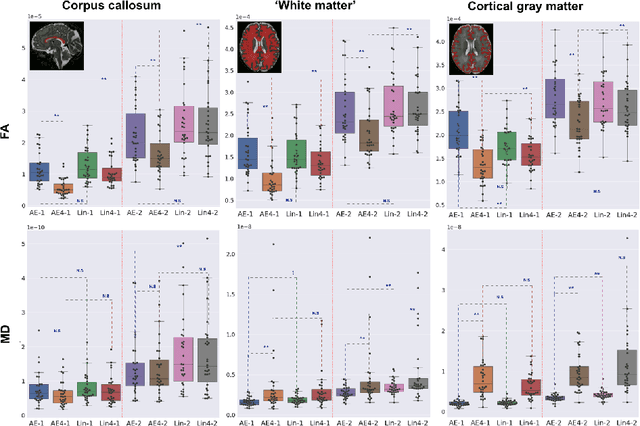
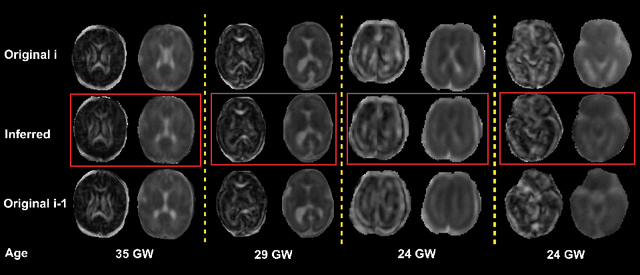
Diffusion MRI (dMRI) of the developing brain can provide valuable insights into the white matter development. However, slice thickness in fetal dMRI is typically high (i.e., 3-5 mm) to freeze the in-plane motion, which reduces the sensitivity of the dMRI signal to the underlying anatomy. In this study, we aim at overcoming this problem by using autoencoders to learn unsupervised efficient representations of brain slices in a latent space, using raw dMRI signals and their spherical harmonics (SH) representation. We first learn and quantitatively validate the autoencoders on the developing Human Connectome Project pre-term newborn data, and further test the method on fetal data. Our results show that the autoencoder in the signal domain better synthesized the raw signal. Interestingly, the fractional anisotropy and, to a lesser extent, the mean diffusivity, are best recovered in missing slices by using the autoencoder trained with SH coefficients. A comparison was performed with the same maps reconstructed using an autoencoder trained with raw signals, as well as conventional interpolation methods of raw signals and SH coefficients. From these results, we conclude that the recovery of missing/corrupted slices should be performed in the signal domain if the raw signal is aimed to be recovered, and in the SH domain if diffusion tensor properties (i.e., fractional anisotropy) are targeted. Notably, the trained autoencoders were able to generalize to fetal dMRI data acquired using a much smaller number of diffusion gradients and a lower b-value, where we qualitatively show the consistency of the estimated diffusion tensor maps.
Safety Metrics and Losses for Object Detection in Autonomous Driving
Sep 21, 2022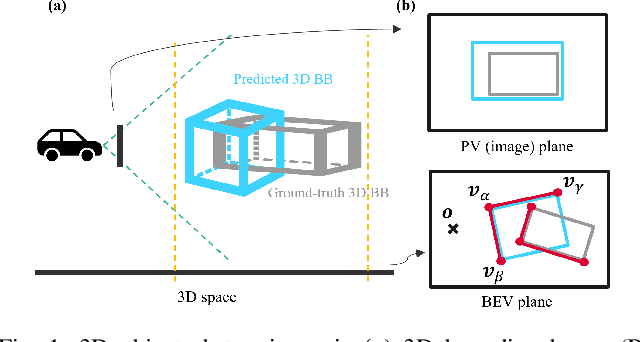
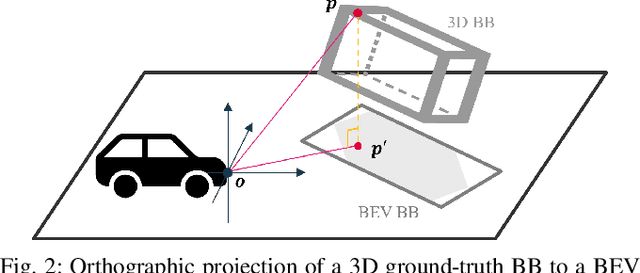
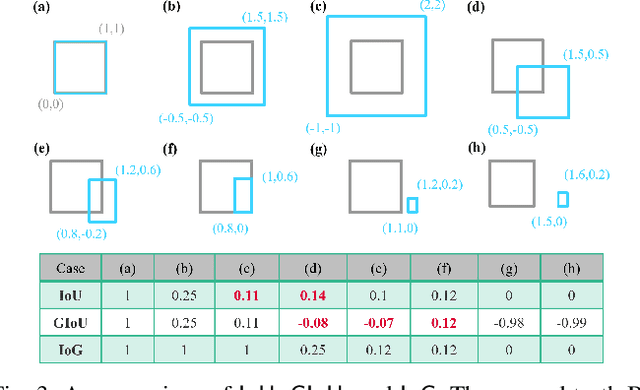
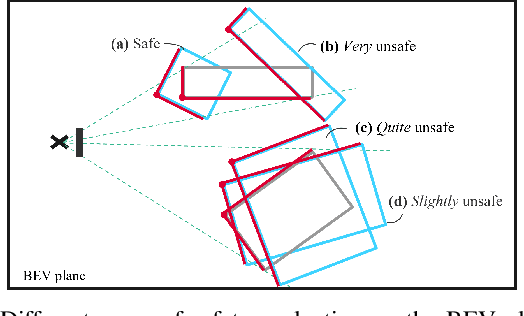
State-of-the-art object detectors have been shown effective in many applications. Usually, their performance is evaluated based on accuracy metrics such as mean Average Precision. In this paper, we consider a safety property of 3D object detectors in the context of Autonomous Driving (AD). In particular, we propose an essential safety requirement for object detectors in AD and formulate it into a specification. During the formulation, we find that abstracting 3D objects with projected 2D bounding boxes on the image and bird's-eye-view planes allows for a necessary and sufficient condition to the proposed safety requirement. We then leverage the analysis and derive qualitative and quantitative safety metrics based on the Intersection-over-Ground-Truth measure and a distance ratio between predictions and ground truths. Finally, for continual improvement, we formulate safety losses that can be used to optimize object detectors towards higher safety scores. Our experiments with public models on the MMDetection3D library and the nuScenes datasets demonstrate the validity of our consideration and proposals.
Which country is this picture from? New data and methods for DNN-based country recognition
Sep 02, 2022



Predicting the country where a picture has been taken from has many potential applications, like detection of false claims, impostors identification, prevention of disinformation campaigns, identification of fake news and so on. Previous works have focused mostly on the estimation of the geo-coordinates where a picture has been taken. Yet, recognizing the country where an image has been taken could potentially be more important, from a semantic and forensic point of view, than identifying its spatial coordinates. So far only a few works have addressed this task, mostly by relying on images containing characteristic landmarks, like iconic monuments. In the above framework, this paper provides two main contributions. First, we introduce a new dataset, the VIPPGeo dataset, containing almost 4 million images, that can be used to train DL models for country classification. The dataset contains only urban images given the relevance of this kind of image for country recognition, and it has been built by paying attention to removing non-significant images, like images portraying faces or specific, non-relevant objects, like airplanes or ships. Secondly, we used the dataset to train a deep learning architecture casting the country recognition problem as a classification problem. The experiments, we performed, show that our network provides significantly better results than current state of the art. In particular, we found that asking the network to directly identify the country provides better results than estimating the geo-coordinates first and then using them to trace back to the country where the picture was taken.
What is Healthy? Generative Counterfactual Diffusion for Lesion Localization
Jul 25, 2022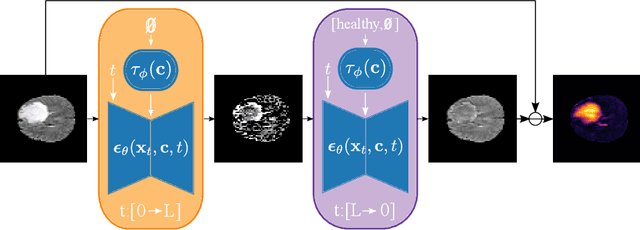
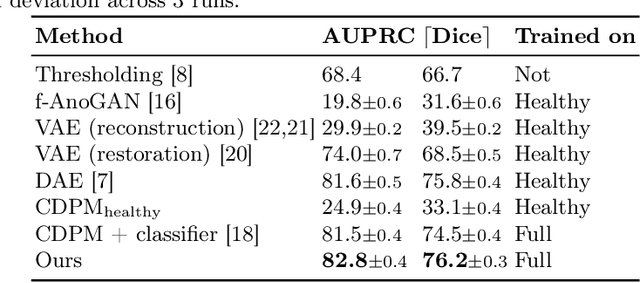
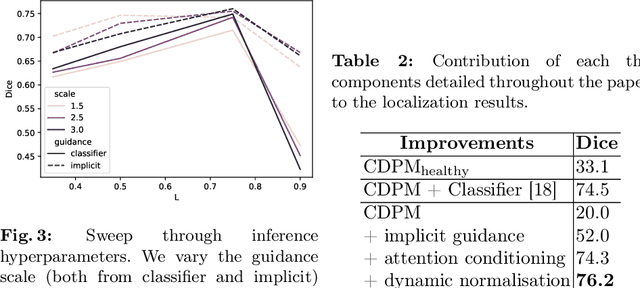
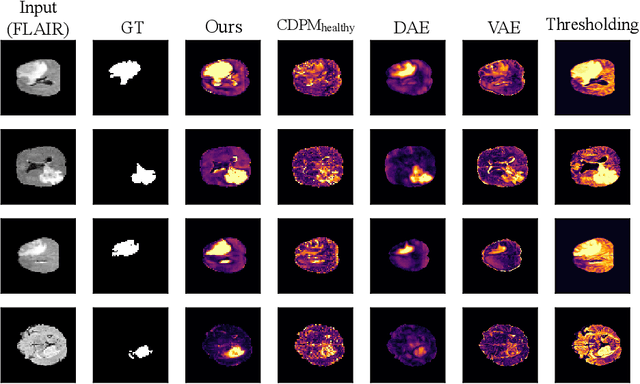
Reducing the requirement for densely annotated masks in medical image segmentation is important due to cost constraints. In this paper, we consider the problem of inferring pixel-level predictions of brain lesions by only using image-level labels for training. By leveraging recent advances in generative diffusion probabilistic models (DPM), we synthesize counterfactuals of "How would a patient appear if X pathology was not present?". The difference image between the observed patient state and the healthy counterfactual can be used for inferring the location of pathology. We generate counterfactuals that correspond to the minimal change of the input such that it is transformed to healthy domain. This requires training with healthy and unhealthy data in DPMs. We improve on previous counterfactual DPMs by manipulating the generation process with implicit guidance along with attention conditioning instead of using classifiers. Code is available at https://github.com/vios-s/Diff-SCM.
An Overview of Violence Detection Techniques: Current Challenges and Future Directions
Sep 21, 2022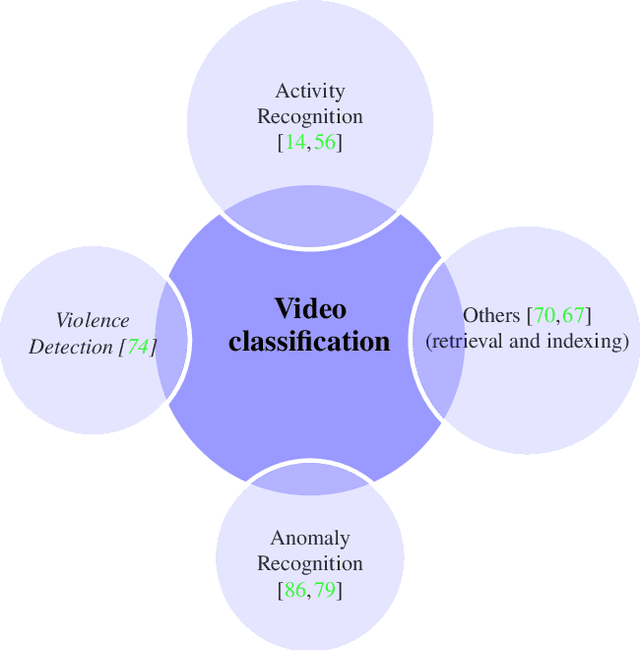
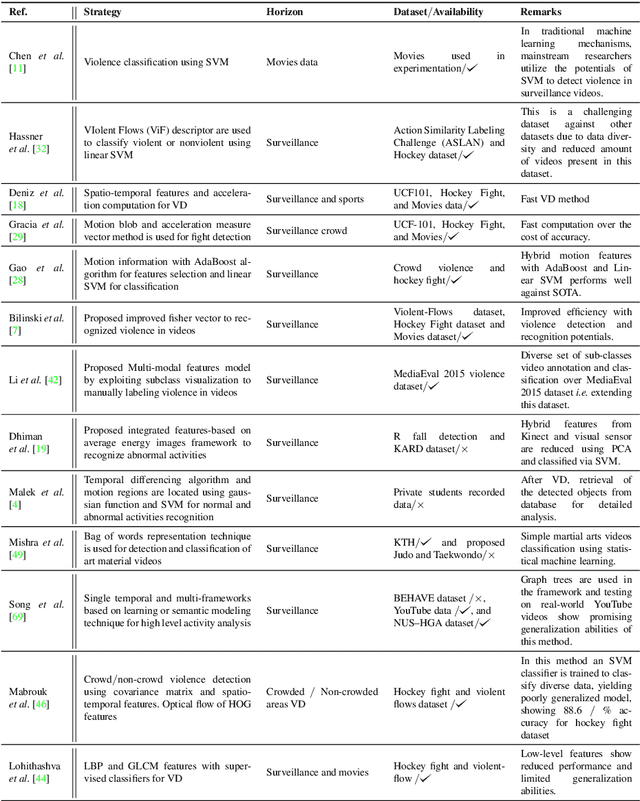

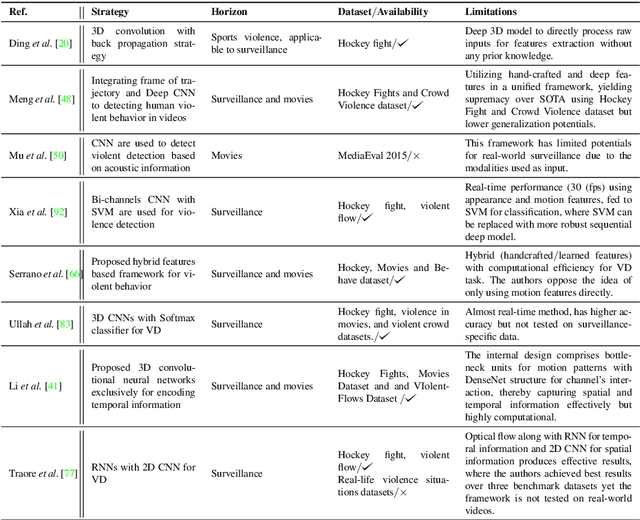
The Big Video Data generated in today's smart cities has raised concerns from its purposeful usage perspective, where surveillance cameras, among many others are the most prominent resources to contribute to the huge volumes of data, making its automated analysis a difficult task in terms of computation and preciseness. Violence Detection (VD), broadly plunging under Action and Activity recognition domain, is used to analyze Big Video data for anomalous actions incurred due to humans. The VD literature is traditionally based on manually engineered features, though advancements to deep learning based standalone models are developed for real-time VD analysis. This paper focuses on overview of deep sequence learning approaches along with localization strategies of the detected violence. This overview also dives into the initial image processing and machine learning-based VD literature and their possible advantages such as efficiency against the current complex models. Furthermore,the datasets are discussed, to provide an analysis of the current models, explaining their pros and cons with future directions in VD domain derived from an in-depth analysis of the previous methods.
FaceQgen: Semi-Supervised Deep Learning for Face Image Quality Assessment
Jan 03, 2022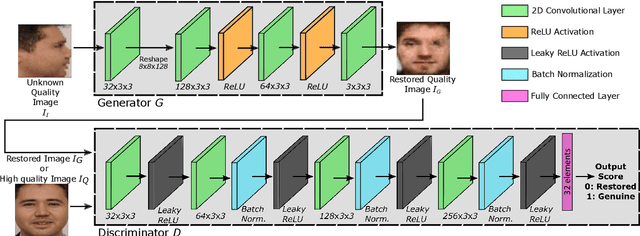
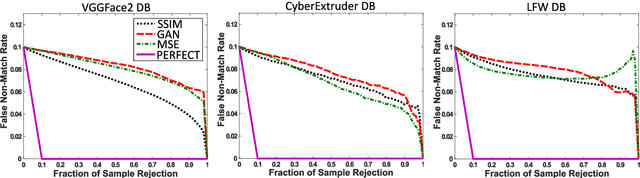
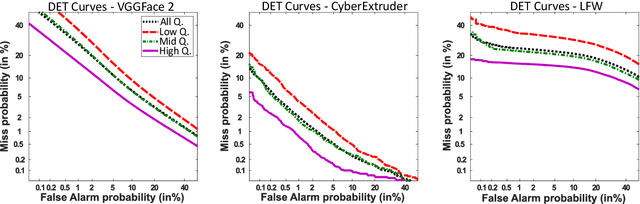
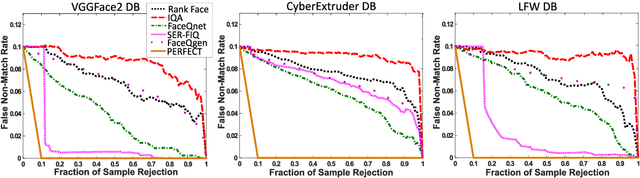
In this paper we develop FaceQgen, a No-Reference Quality Assessment approach for face images based on a Generative Adversarial Network that generates a scalar quality measure related with the face recognition accuracy. FaceQgen does not require labelled quality measures for training. It is trained from scratch using the SCface database. FaceQgen applies image restoration to a face image of unknown quality, transforming it into a canonical high quality image, i.e., frontal pose, homogeneous background, etc. The quality estimation is built as the similarity between the original and the restored images, since low quality images experience bigger changes due to restoration. We compare three different numerical quality measures: a) the MSE between the original and the restored images, b) their SSIM, and c) the output score of the Discriminator of the GAN. The results demonstrate that FaceQgen's quality measures are good estimators of face recognition accuracy. Our experiments include a comparison with other quality assessment methods designed for faces and for general images, in order to position FaceQgen in the state of the art. This comparison shows that, even though FaceQgen does not surpass the best existing face quality assessment methods in terms of face recognition accuracy prediction, it achieves good enough results to demonstrate the potential of semi-supervised learning approaches for quality estimation (in particular, data-driven learning based on a single high quality image per subject), having the capacity to improve its performance in the future with adequate refinement of the model and the significant advantage over competing methods of not needing quality labels for its development. This makes FaceQgen flexible and scalable without expensive data curation.
Dense-TNT: Efficient Vehicle Type Classification Neural Network Using Satellite Imagery
Sep 27, 2022
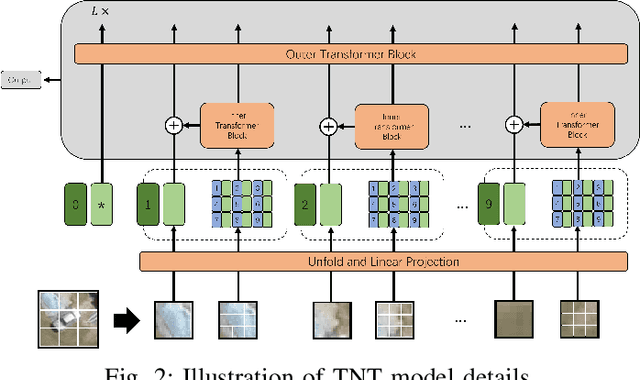
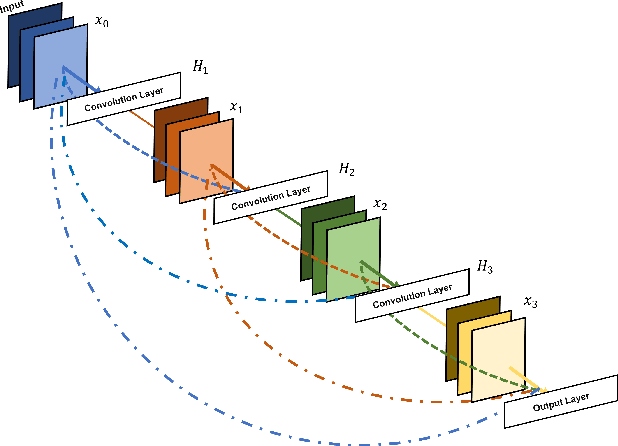
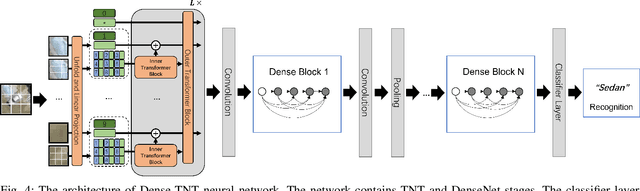
Accurate vehicle type classification serves a significant role in the intelligent transportation system. It is critical for ruler to understand the road conditions and usually contributive for the traffic light control system to response correspondingly to alleviate traffic congestion. New technologies and comprehensive data sources, such as aerial photos and remote sensing data, provide richer and high-dimensional information. Also, due to the rapid development of deep neural network technology, image based vehicle classification methods can better extract underlying objective features when processing data. Recently, several deep learning models have been proposed to solve the problem. However, traditional pure convolutional based approaches have constraints on global information extraction, and the complex environment, such as bad weather, seriously limits the recognition capability. To improve the vehicle type classification capability under complex environment, this study proposes a novel Densely Connected Convolutional Transformer in Transformer Neural Network (Dense-TNT) framework for the vehicle type classification by stacking Densely Connected Convolutional Network (DenseNet) and Transformer in Transformer (TNT) layers. Three-region vehicle data and four different weather conditions are deployed for recognition capability evaluation. Experimental findings validate the recognition ability of our proposed vehicle classification model with little decay, even under the heavy foggy weather condition.
AdaFocusV3: On Unified Spatial-temporal Dynamic Video Recognition
Sep 27, 2022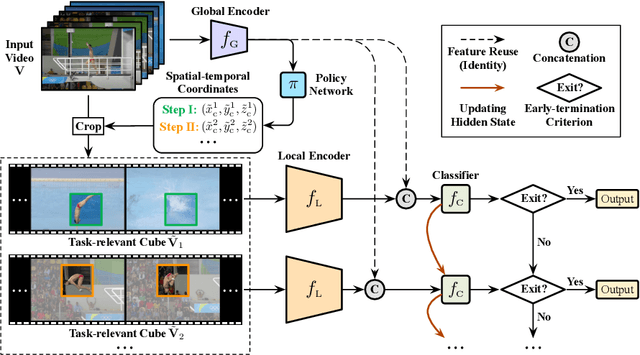
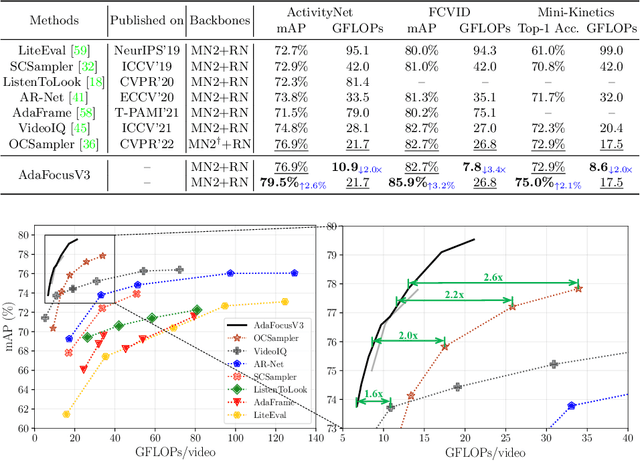
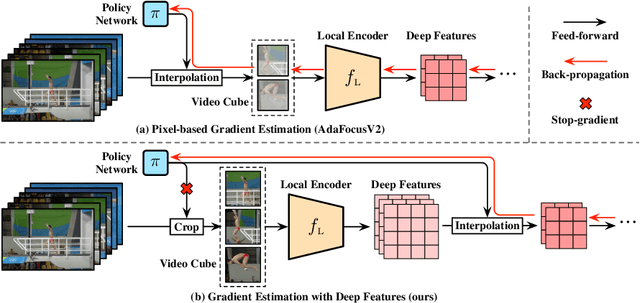
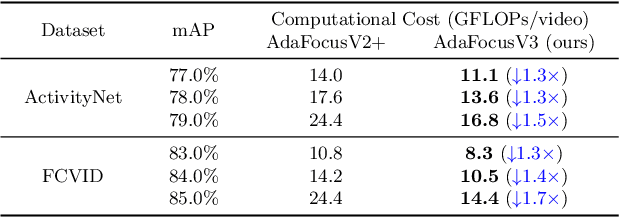
Recent research has revealed that reducing the temporal and spatial redundancy are both effective approaches towards efficient video recognition, e.g., allocating the majority of computation to a task-relevant subset of frames or the most valuable image regions of each frame. However, in most existing works, either type of redundancy is typically modeled with another absent. This paper explores the unified formulation of spatial-temporal dynamic computation on top of the recently proposed AdaFocusV2 algorithm, contributing to an improved AdaFocusV3 framework. Our method reduces the computational cost by activating the expensive high-capacity network only on some small but informative 3D video cubes. These cubes are cropped from the space formed by frame height, width, and video duration, while their locations are adaptively determined with a light-weighted policy network on a per-sample basis. At test time, the number of the cubes corresponding to each video is dynamically configured, i.e., video cubes are processed sequentially until a sufficiently reliable prediction is produced. Notably, AdaFocusV3 can be effectively trained by approximating the non-differentiable cropping operation with the interpolation of deep features. Extensive empirical results on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2 and Diving48) demonstrate that our model is considerably more efficient than competitive baselines.
Exploring Cross-Domain Pretrained Model for Hyperspectral Image Classification
Apr 07, 2022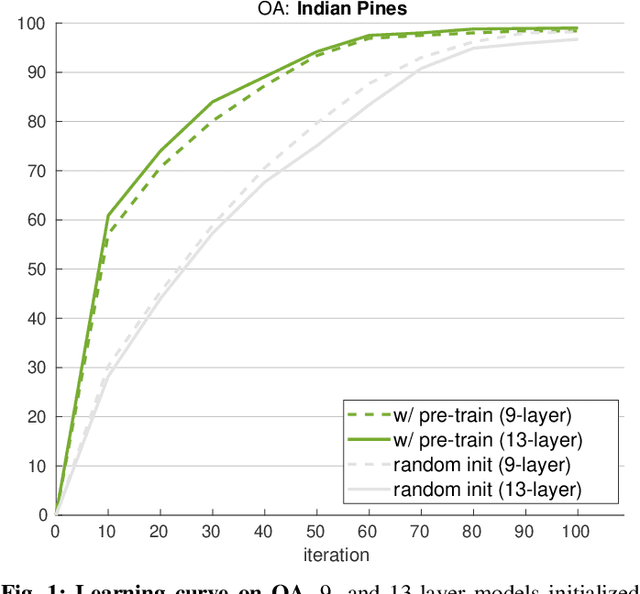
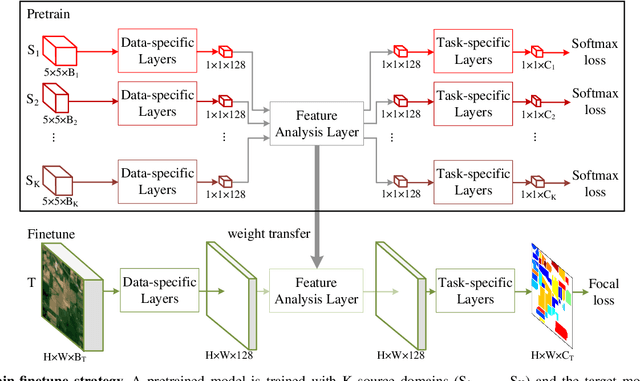
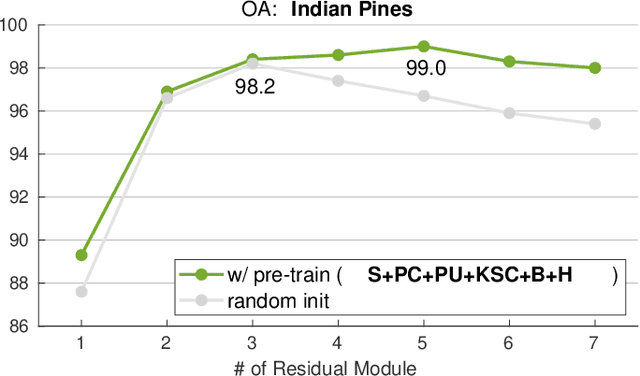
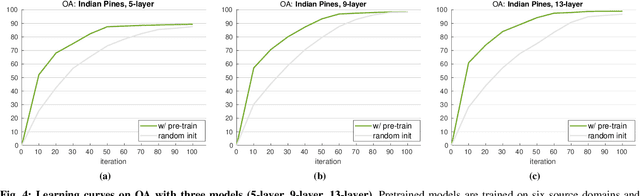
A pretrain-finetune strategy is widely used to reduce the overfitting that can occur when data is insufficient for CNN training. First few layers of a CNN pretrained on a large-scale RGB dataset are capable of acquiring general image characteristics which are remarkably effective in tasks targeted for different RGB datasets. However, when it comes down to hyperspectral domain where each domain has its unique spectral properties, the pretrain-finetune strategy no longer can be deployed in a conventional way while presenting three major issues: 1) inconsistent spectral characteristics among the domains (e.g., frequency range), 2) inconsistent number of data channels among the domains, and 3) absence of large-scale hyperspectral dataset. We seek to train a universal cross-domain model which can later be deployed for various spectral domains. To achieve, we physically furnish multiple inlets to the model while having a universal portion which is designed to handle the inconsistent spectral characteristics among different domains. Note that only the universal portion is used in the finetune process. This approach naturally enables the learning of our model on multiple domains simultaneously which acts as an effective workaround for the issue of the absence of large-scale dataset. We have carried out a study to extensively compare models that were trained using cross-domain approach with ones trained from scratch. Our approach was found to be superior both in accuracy and in training efficiency. In addition, we have verified that our approach effectively reduces the overfitting issue, enabling us to deepen the model up to 13 layers (from 9) without compromising the accuracy.