 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MegaPortraits: One-shot Megapixel Neural Head Avatars
Jul 15, 2022
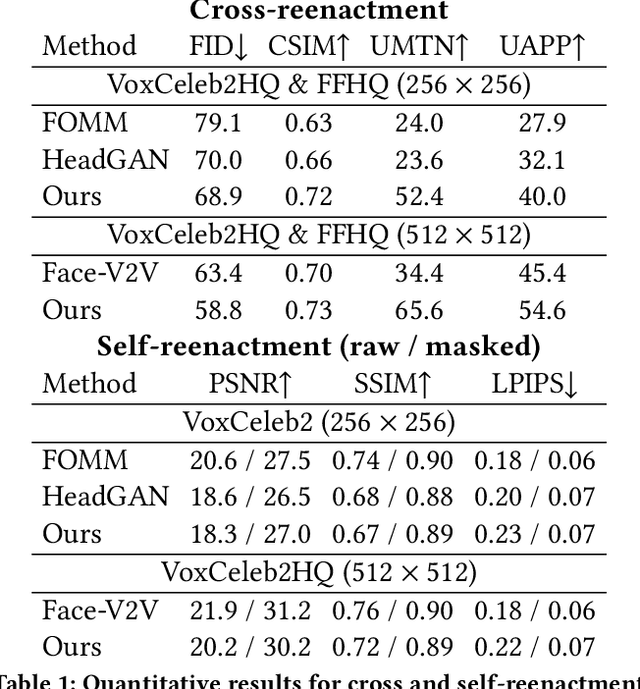
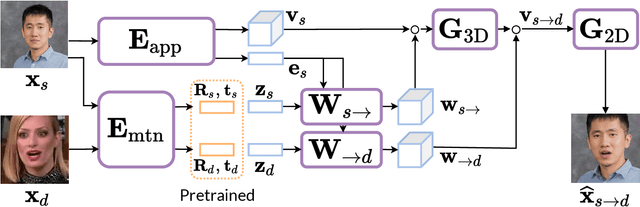
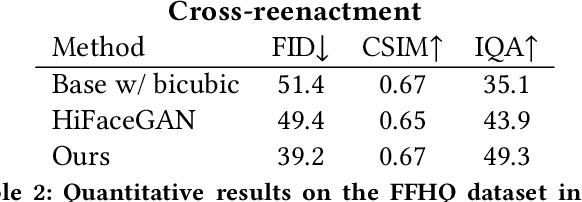

In this work, we advance the neural head avatar technology to the megapixel resolution while focusing on the particularly challenging task of cross-driving synthesis, i.e., when the appearance of the driving image is substantially different from the animated source image. We propose a set of new neural architectures and training methods that can leverage both medium-resolution video data and high-resolution image data to achieve the desired levels of rendered image quality and generalization to novel views and motion. We demonstrate that suggested architectures and methods produce convincing high-resolution neural avatars, outperforming the competitors in the cross-driving scenario. Lastly, we show how a trained high-resolution neural avatar model can be distilled into a lightweight student model which runs in real-time and locks the identities of neural avatars to several dozens of pre-defined source images. Real-time operation and identity lock are essential for many practical applications head avatar systems.
GSRFormer: Grounded Situation Recognition Transformer with Alternate Semantic Attention Refinement
Sep 01, 2022
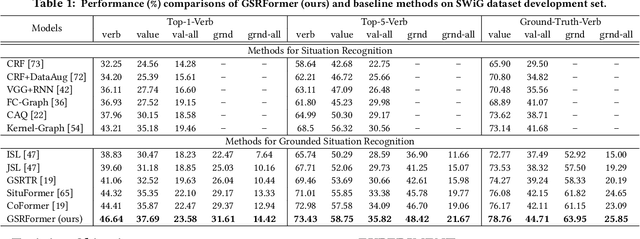

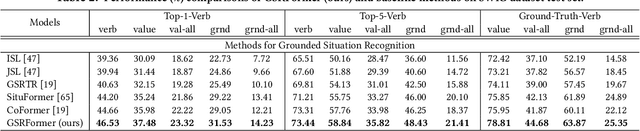
Grounded Situation Recognition (GSR) aims to generate structured semantic summaries of images for "human-like" event understanding. Specifically, GSR task not only detects the salient activity verb (e.g. buying), but also predicts all corresponding semantic roles (e.g. agent and goods). Inspired by object detection and image captioning tasks, existing methods typically employ a two-stage framework: 1) detect the activity verb, and then 2) predict semantic roles based on the detected verb. Obviously, this illogical framework constitutes a huge obstacle to semantic understanding. First, pre-detecting verbs solely without semantic roles inevitably fails to distinguish many similar daily activities (e.g., offering and giving, buying and selling). Second, predicting semantic roles in a closed auto-regressive manner can hardly exploit the semantic relations among the verb and roles. To this end, in this paper we propose a novel two-stage framework that focuses on utilizing such bidirectional relations within verbs and roles. In the first stage, instead of pre-detecting the verb, we postpone the detection step and assume a pseudo label, where an intermediate representation for each corresponding semantic role is learned from images. In the second stage, we exploit transformer layers to unearth the potential semantic relations within both verbs and semantic roles. With the help of a set of support images, an alternate learning scheme is designed to simultaneously optimize the results: update the verb using nouns corresponding to the image, and update nouns using verbs from support images. Extensive experimental results on challenging SWiG benchmarks show that our renovated framework outperforms other state-of-the-art methods under various metrics.
Stochastic Planner-Actor-Critic for Unsupervised Deformable Image Registration
Dec 14, 2021
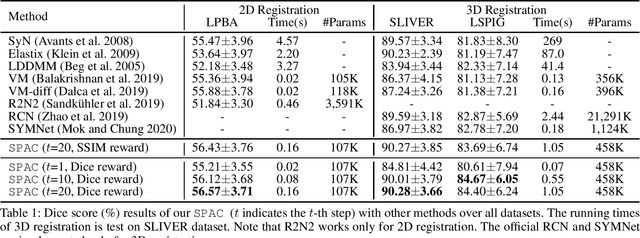
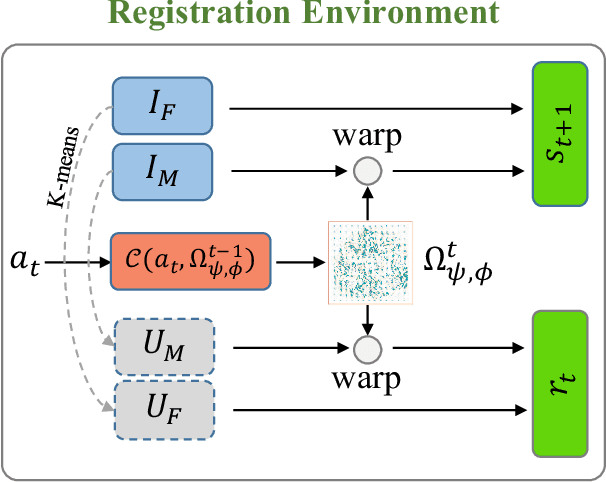
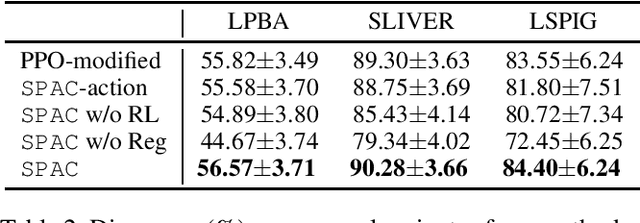
Large deformations of organs, caused by diverse shapes and nonlinear shape changes, pose a significant challenge for medical image registration. Traditional registration methods need to iteratively optimize an objective function via a specific deformation model along with meticulous parameter tuning, but which have limited capabilities in registering images with large deformations. While deep learning-based methods can learn the complex mapping from input images to their respective deformation field, it is regression-based and is prone to be stuck at local minima, particularly when large deformations are involved. To this end, we present Stochastic Planner-Actor-Critic (SPAC), a novel reinforcement learning-based framework that performs step-wise registration. The key notion is warping a moving image successively by each time step to finally align to a fixed image. Considering that it is challenging to handle high dimensional continuous action and state spaces in the conventional reinforcement learning (RL) framework, we introduce a new concept `Plan' to the standard Actor-Critic model, which is of low dimension and can facilitate the actor to generate a tractable high dimensional action. The entire framework is based on unsupervised training and operates in an end-to-end manner. We evaluate our method on several 2D and 3D medical image datasets, some of which contain large deformations. Our empirical results highlight that our work achieves consistent, significant gains and outperforms state-of-the-art methods.
ClipCap: CLIP Prefix for Image Captioning
Nov 18, 2021
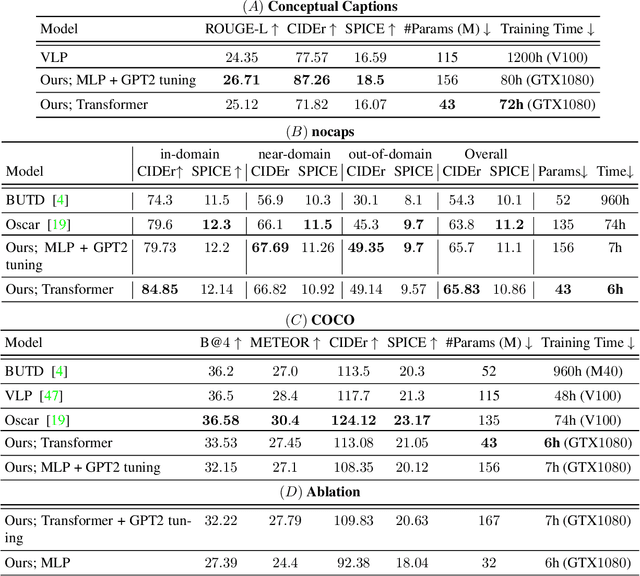
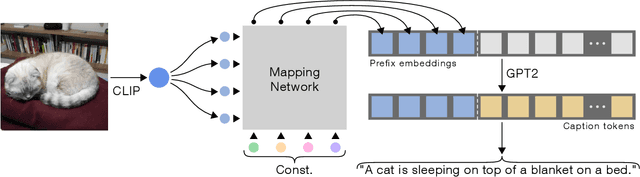

Image captioning is a fundamental task in vision-language understanding, where the model predicts a textual informative caption to a given input image. In this paper, we present a simple approach to address this task. We use CLIP encoding as a prefix to the caption, by employing a simple mapping network, and then fine-tunes a language model to generate the image captions. The recently proposed CLIP model contains rich semantic features which were trained with textual context, making it best for vision-language perception. Our key idea is that together with a pre-trained language model (GPT2), we obtain a wide understanding of both visual and textual data. Hence, our approach only requires rather quick training to produce a competent captioning model. Without additional annotations or pre-training, it efficiently generates meaningful captions for large-scale and diverse datasets. Surprisingly, our method works well even when only the mapping network is trained, while both CLIP and the language model remain frozen, allowing a lighter architecture with less trainable parameters. Through quantitative evaluation, we demonstrate our model achieves comparable results to state-of-the-art methods on the challenging Conceptual Captions and nocaps datasets, while it is simpler, faster, and lighter. Our code is available in https://github.com/rmokady/CLIP_prefix_caption.
Histogram of Oriented Gradients Meet Deep Learning: A Novel Multi-task Deep Network for Medical Image Semantic Segmentation
Apr 02, 2022
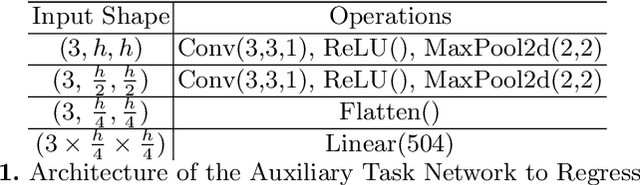
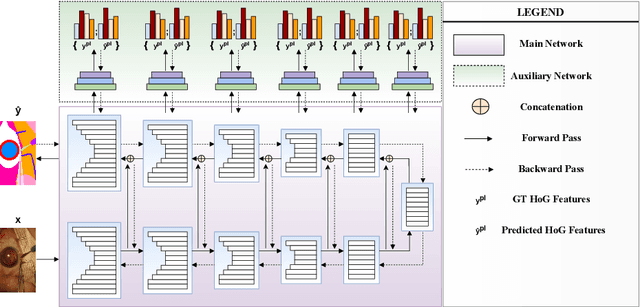
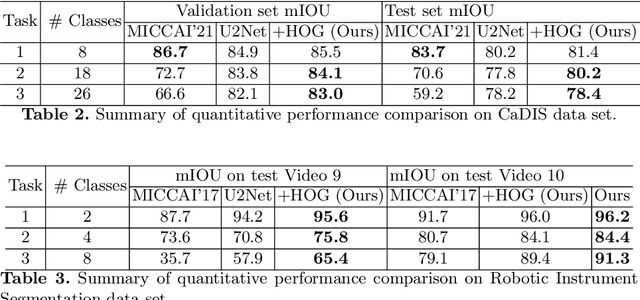
We present our novel deep multi-task learning method for medical image segmentation. Existing multi-task methods demand ground truth annotations for both the primary and auxiliary tasks. Contrary to it, we propose to generate the pseudo-labels of an auxiliary task in an unsupervised manner. To generate the pseudo-labels, we leverage Histogram of Oriented Gradients (HOGs), one of the most widely used and powerful hand-crafted features for detection. Together with the ground truth semantic segmentation masks for the primary task and pseudo-labels for the auxiliary task, we learn the parameters of the deep network to minimise the loss of both the primary task and the auxiliary task jointly. We employed our method on two powerful and widely used semantic segmentation networks: UNet and U2Net to train in a multi-task setup. To validate our hypothesis, we performed experiments on two different medical image segmentation data sets. From the extensive quantitative and qualitative results, we observe that our method consistently improves the performance compared to the counter-part method. Moreover, our method is the winner of FetReg Endovis Sub-challenge on Semantic Segmentation organised in conjunction with MICCAI 2021.
Graph Attention Transformer Network for Multi-Label Image Classification
Mar 08, 2022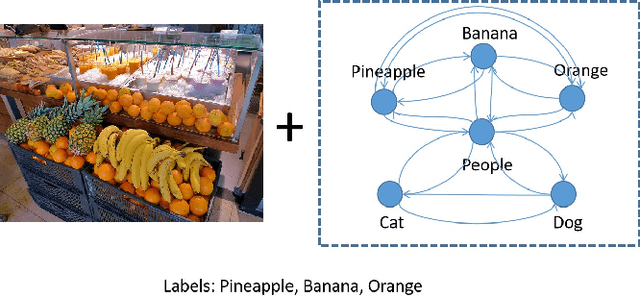
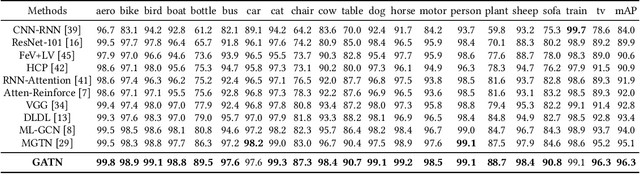
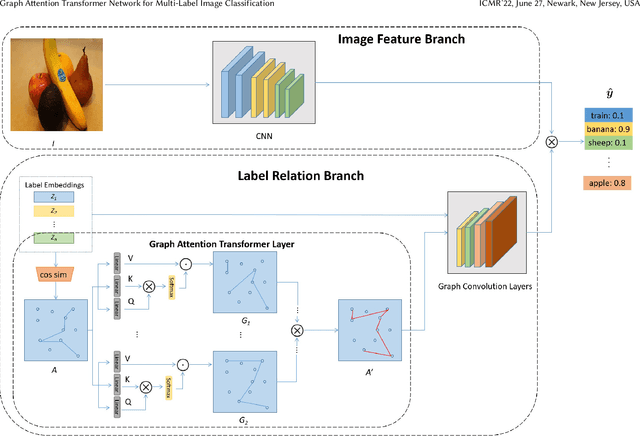
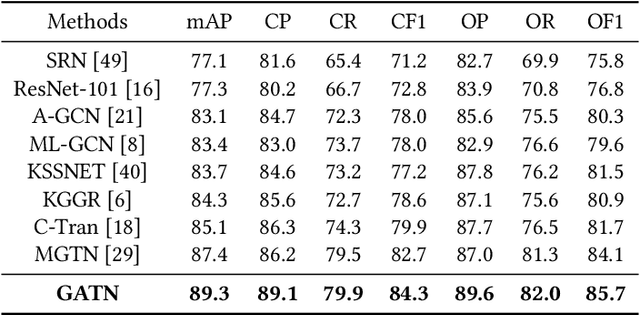
Multi-label classification aims to recognize multiple objects or attributes from images. However, it is challenging to learn from proper label graphs to effectively characterize such inter-label correlations or dependencies. Current methods often use the co-occurrence probability of labels based on the training set as the adjacency matrix to model this correlation, which is greatly limited by the dataset and affects the model's generalization ability. In this paper, we propose a Graph Attention Transformer Network (GATN), a general framework for multi-label image classification that can effectively mine complex inter-label relationships. First, we use the cosine similarity based on the label word embedding as the initial correlation matrix, which can represent rich semantic information. Subsequently, we design the graph attention transformer layer to transfer this adjacency matrix to adapt to the current domain. Our extensive experiments have demonstrated that our proposed methods can achieve state-of-the-art performance on three datasets.
Calorie Aware Automatic Meal Kit Generation from an Image
Dec 18, 2021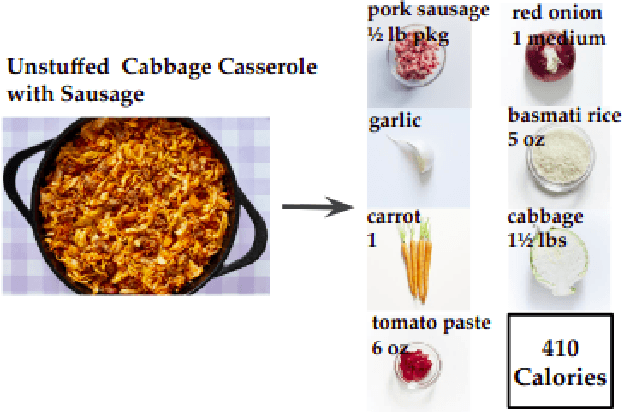
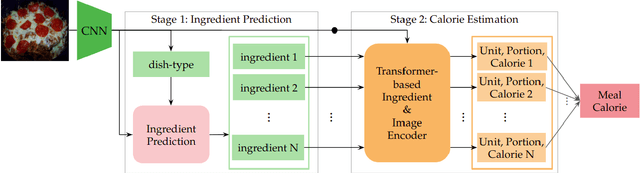
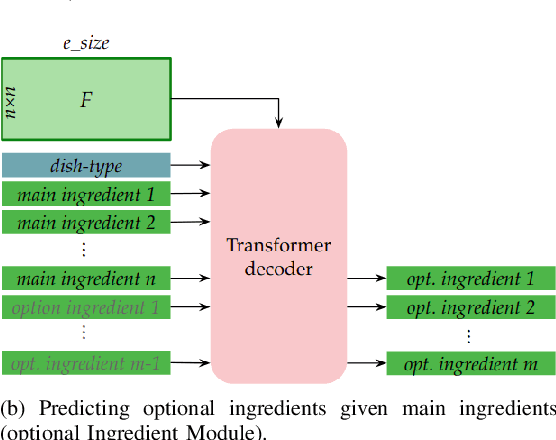
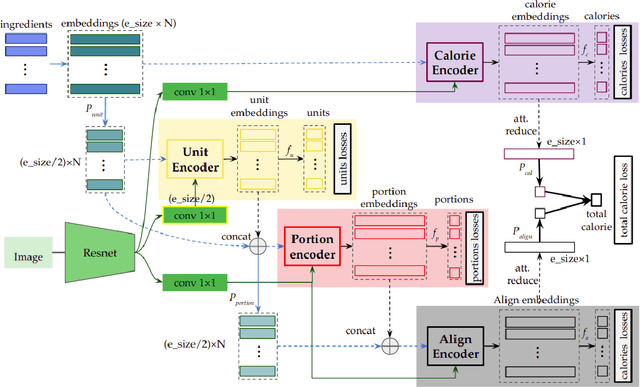
Calorie and nutrition research has attained increased interest in recent years. But, due to the complexity of the problem, literature in this area focuses on a limited subset of ingredients or dish types and simple convolutional neural networks or traditional machine learning. Simultaneously, estimation of ingredient portions can help improve calorie estimation and meal re-production from a given image. In this paper, given a single cooking image, a pipeline for calorie estimation and meal re-production for different servings of the meal is proposed. The pipeline contains two stages. In the first stage, a set of ingredients associated with the meal in the given image are predicted. In the second stage, given image features and ingredients, portions of the ingredients and finally the total meal calorie are simultaneously estimated using a deep transformer-based model. Portion estimation introduced in the model helps improve calorie estimation and is also beneficial for meal re-production in different serving sizes. To demonstrate the benefits of the pipeline, the model can be used for meal kits generation. To evaluate the pipeline, the large scale dataset Recipe1M is used. Prior to experiments, the Recipe1M dataset is parsed and explicitly annotated with portions of ingredients. Experiments show that using ingredients and their portions significantly improves calorie estimation. Also, a visual interface is created in which a user can interact with the pipeline to reach accurate calorie estimations and generate a meal kit for cooking purposes.
Negative Evidence Matters in Interpretable Histology Image Classification
Jan 07, 2022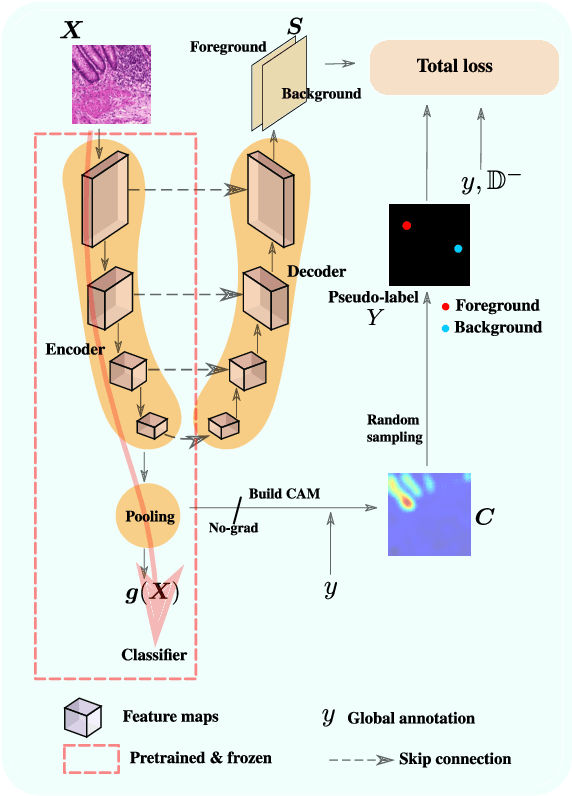
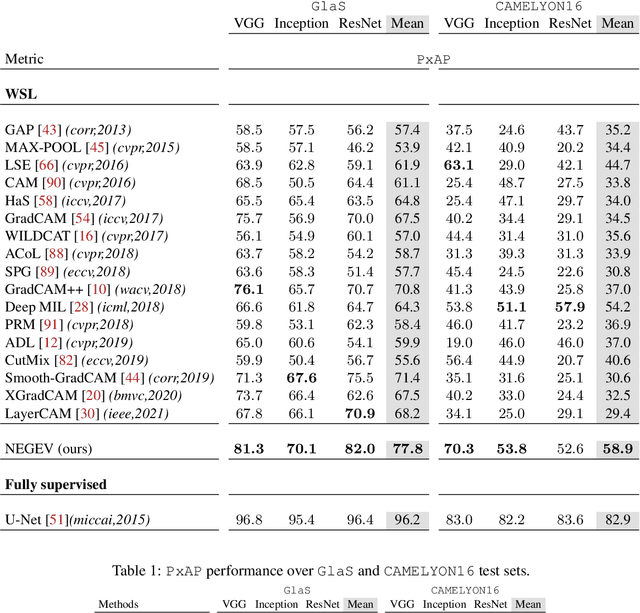

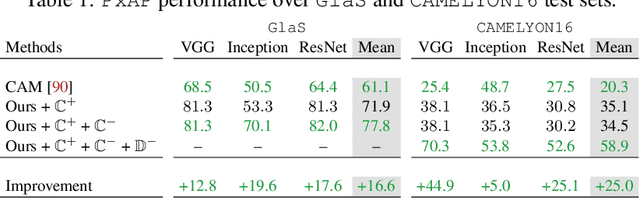
Using only global annotations such as the image class labels, weakly-supervised learning methods allow CNN classifiers to jointly classify an image, and yield the regions of interest associated with the predicted class. However, without any guidance at the pixel level, such methods may yield inaccurate regions. This problem is known to be more challenging with histology images than with natural ones, since objects are less salient, structures have more variations, and foreground and background regions have stronger similarities. Therefore, methods in computer vision literature for visual interpretation of CNNs may not directly apply. In this work, we propose a simple yet efficient method based on a composite loss function that leverages information from the fully negative samples. Our new loss function contains two complementary terms: the first exploits positive evidence collected from the CNN classifier, while the second leverages the fully negative samples from the training dataset. In particular, we equip a pre-trained classifier with a decoder that allows refining the regions of interest. The same classifier is exploited to collect both the positive and negative evidence at the pixel level to train the decoder. This enables to take advantages of the fully negative samples that occurs naturally in the data, without any additional supervision signals and using only the image class as supervision. Compared to several recent related methods, over the public benchmark GlaS for colon cancer and a Camelyon16 patch-based benchmark for breast cancer using three different backbones, we show the substantial improvements introduced by our method. Our results shows the benefits of using both negative and positive evidence, ie, the one obtained from a classifier and the one naturally available in datasets. We provide an ablation study of both terms. Our code is publicly available.
DiffusionCLIP: Text-guided Image Manipulation Using Diffusion Models
Oct 06, 2021
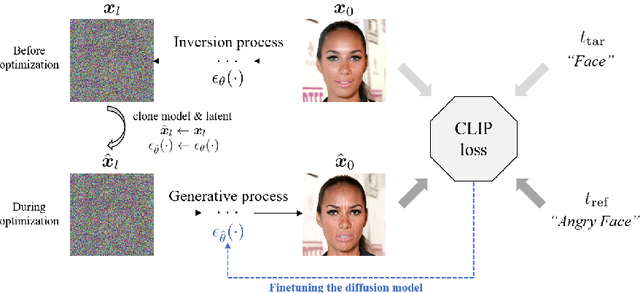

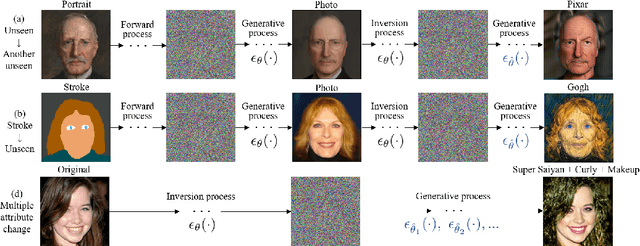
Diffusion models are recent generative models that have shown great success in image generation with the state-of-the-art performance. However, only a few researches have been conducted for image manipulation with diffusion models. Here, we present a novel DiffusionCLIP which performs text-driven image manipulation with diffusion models using Contrastive Language-Image Pre-training (CLIP) loss. Our method has a performance comparable to that of the modern GAN-based image processing methods for in and out-of-domain image processing tasks, with the advantage of almost perfect inversion even without additional encoders or optimization. Furthermore, our method can be easily used for various novel applications, enabling image translation from an unseen domain to another unseen domain or stroke-conditioned image generation in an unseen domain, etc. Finally, we present a novel multiple attribute control with DiffusionCLIPby combining multiple fine-tuned diffusion models.
BuFF: Burst Feature Finder for Light-Constrained 3D Reconstruction
Sep 20, 2022

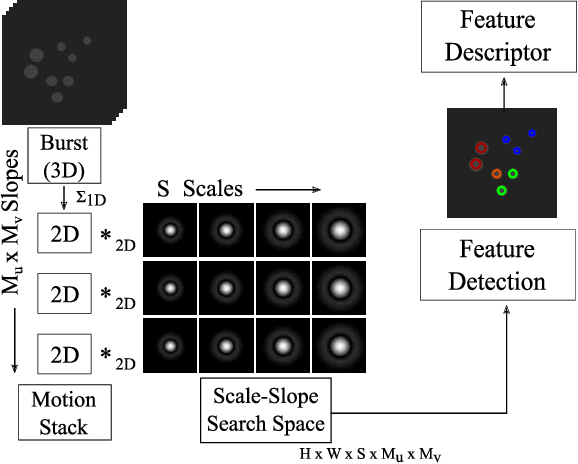

Robots operating at night using conventional vision cameras face significant challenges in reconstruction due to noise-limited images. Previous work has demonstrated that burst-imaging techniques can be used to partially overcome this issue. In this paper, we develop a novel feature detector that operates directly on image bursts that enhances vision-based reconstruction under extremely low-light conditions. Our approach finds keypoints with well-defined scale and apparent motion within each burst by jointly searching in a multi-scale and multi-motion space. Because we describe these features at a stage where the images have higher signal-to-noise ratio, the detected features are more accurate than the state-of-the-art on conventional noisy images and burst-merged images and exhibit high precision, recall, and matching performance. We show improved feature performance and camera pose estimates and demonstrate improved structure-from-motion performance using our feature detector in challenging light-constrained scenes. Our feature finder provides a significant step towards robots operating in low-light scenarios and applications including night-time operations.