 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-Frequency Space Diffusion Models for Accelerated MRI
Aug 15, 2022
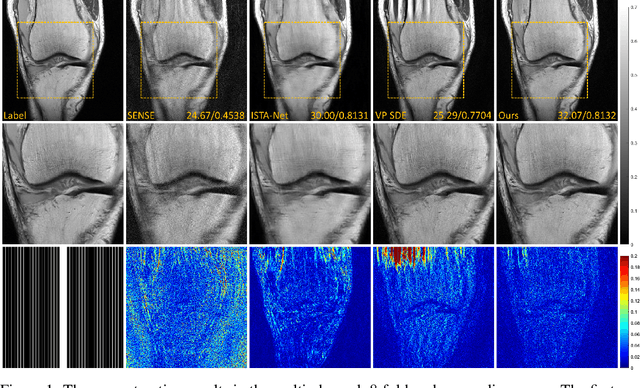
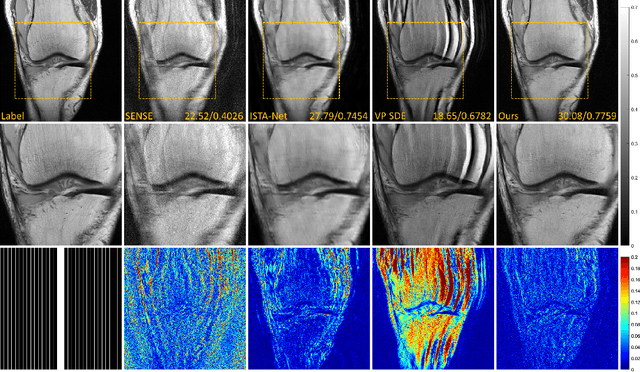
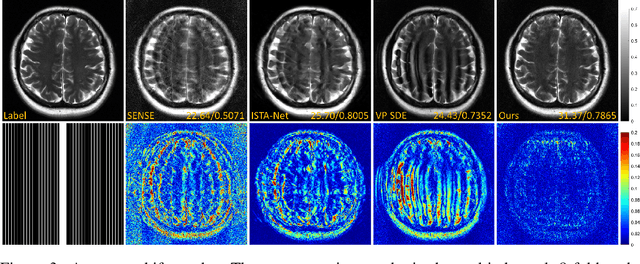
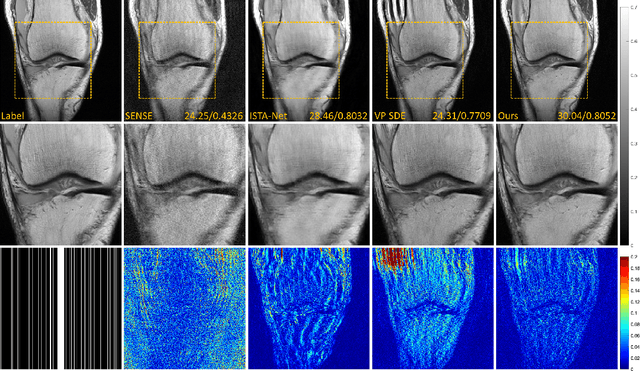
Denoising diffusion probabilistic models (DDPMs) have been shown to have superior performances in MRI reconstruction. From the perspective of continuous stochastic differential equations (SDEs), the reverse process of DDPM can be seen as maximizing the energy of the reconstructed MR image, leading to SDE sequence divergence. For this reason, a modified high-frequency DDPM model is proposed for MRI reconstruction. From its continuous SDE viewpoint, termed high-frequency space SDE (HFS-SDE), the energy concentrated low-frequency part of the MR image is no longer amplified, and the diffusion process focuses more on acquiring high-frequency prior information. It not only improves the stability of the diffusion model but also provides the possibility of better recovery of high-frequency details. Experiments on the publicly fastMRI dataset show that our proposed HFS-SDE outperforms the DDPM-driven VP-SDE, supervised deep learning methods and traditional parallel imaging methods in terms of stability and reconstruction accuracy.
Vision+X: A Survey on Multimodal Learning in the Light of Data
Oct 05, 2022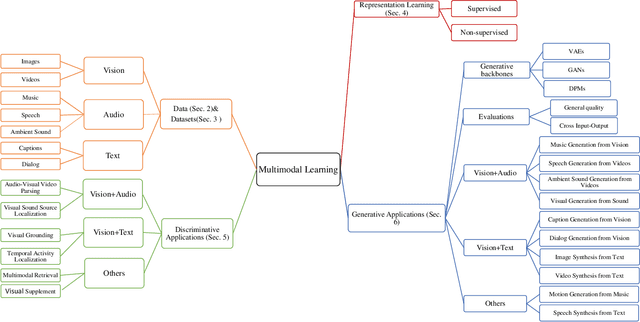

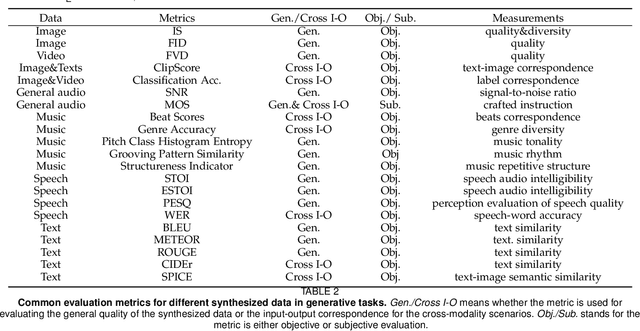
We are perceiving and communicating with the world in a multisensory manner, where different information sources are sophisticatedly processed and interpreted by separate parts of the human brain to constitute a complex, yet harmonious and unified sensing system. To endow the machines with true intelligence, the multimodal machine learning that incorporates data from various modalities has become an increasingly popular research area with emerging technical advances in recent years. In this paper, we present a survey on multimodal machine learning from a novel perspective considering not only the purely technical aspects but also the nature of different data modalities. We analyze the commonness and uniqueness of each data format ranging from vision, audio, text and others, and then present the technical development categorized by the combination of Vision+X, where the vision data play a fundamental role in most multimodal learning works. We investigate the existing literature on multimodal learning from both the representation learning and downstream application levels, and provide an additional comparison in the light of their technical connections with the data nature, e.g., the semantic consistency between image objects and textual descriptions, or the rhythm correspondence between video dance moves and musical beats. The exploitation of the alignment, as well as the existing gap between the intrinsic nature of data modality and the technical designs, will benefit future research studies to better address and solve a specific challenge related to the concrete multimodal task, and to prompt a unified multimodal machine learning framework closer to a real human intelligence system.
AOE-Net: Entities Interactions Modeling with Adaptive Attention Mechanism for Temporal Action Proposals Generation
Oct 05, 2022Temporal action proposal generation (TAPG) is a challenging task, which requires localizing action intervals in an untrimmed video. Intuitively, we as humans, perceive an action through the interactions between actors, relevant objects, and the surrounding environment. Despite the significant progress of TAPG, a vast majority of existing methods ignore the aforementioned principle of the human perceiving process by applying a backbone network into a given video as a black-box. In this paper, we propose to model these interactions with a multi-modal representation network, namely, Actors-Objects-Environment Interaction Network (AOE-Net). Our AOE-Net consists of two modules, i.e., perception-based multi-modal representation (PMR) and boundary-matching module (BMM). Additionally, we introduce adaptive attention mechanism (AAM) in PMR to focus only on main actors (or relevant objects) and model the relationships among them. PMR module represents each video snippet by a visual-linguistic feature, in which main actors and surrounding environment are represented by visual information, whereas relevant objects are depicted by linguistic features through an image-text model. BMM module processes the sequence of visual-linguistic features as its input and generates action proposals. Comprehensive experiments and extensive ablation studies on ActivityNet-1.3 and THUMOS-14 datasets show that our proposed AOE-Net outperforms previous state-of-the-art methods with remarkable performance and generalization for both TAPG and temporal action detection. To prove the robustness and effectiveness of AOE-Net, we further conduct an ablation study on egocentric videos, i.e. EPIC-KITCHENS 100 dataset. Source code is available upon acceptance.
Image Fusion Transformer
Jul 20, 2021
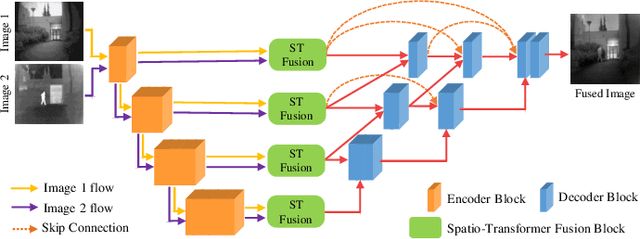
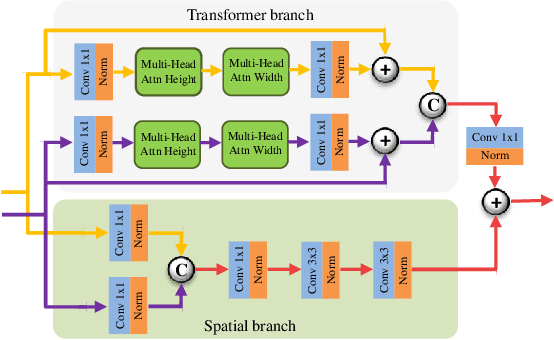
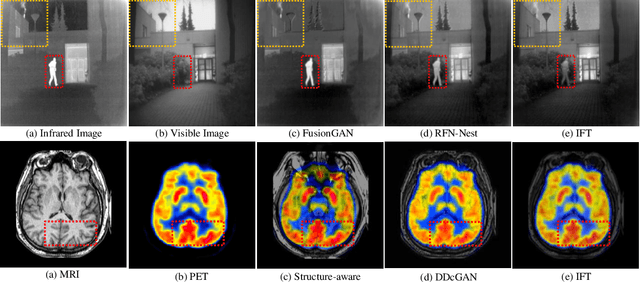
In image fusion, images obtained from different sensors are fused to generate a single image with enhanced information. In recent years, state-of-the-art methods have adopted Convolution Neural Networks (CNNs) to encode meaningful features for image fusion. Specifically, CNN-based methods perform image fusion by fusing local features. However, they do not consider long-range dependencies that are present in the image. Transformer-based models are designed to overcome this by modeling the long-range dependencies with the help of self-attention mechanism. This motivates us to propose a novel Image Fusion Transformer (IFT) where we develop a transformer-based multi-scale fusion strategy that attends to both local and long-range information (or global context). The proposed method follows a two-stage training approach. In the first stage, we train an auto-encoder to extract deep features at multiple scales. In the second stage, multi-scale features are fused using a Spatio-Transformer (ST) fusion strategy. The ST fusion blocks are comprised of a CNN and a transformer branch which capture local and long-range features, respectively. Extensive experiments on multiple benchmark datasets show that the proposed method performs better than many competitive fusion algorithms. Furthermore, we show the effectiveness of the proposed ST fusion strategy with an ablation analysis. The source code is available at: https://github.com/Vibashan/Image-Fusion-Transformer.
Which country is this picture from? New data and methods for DNN-based country recognition
Sep 02, 2022



Predicting the country where a picture has been taken from has many potential applications, like detection of false claims, impostors identification, prevention of disinformation campaigns, identification of fake news and so on. Previous works have focused mostly on the estimation of the geo-coordinates where a picture has been taken. Yet, recognizing the country where an image has been taken could potentially be more important, from a semantic and forensic point of view, than identifying its spatial coordinates. So far only a few works have addressed this task, mostly by relying on images containing characteristic landmarks, like iconic monuments. In the above framework, this paper provides two main contributions. First, we introduce a new dataset, the VIPPGeo dataset, containing almost 4 million images, that can be used to train DL models for country classification. The dataset contains only urban images given the relevance of this kind of image for country recognition, and it has been built by paying attention to removing non-significant images, like images portraying faces or specific, non-relevant objects, like airplanes or ships. Secondly, we used the dataset to train a deep learning architecture casting the country recognition problem as a classification problem. The experiments, we performed, show that our network provides significantly better results than current state of the art. In particular, we found that asking the network to directly identify the country provides better results than estimating the geo-coordinates first and then using them to trace back to the country where the picture was taken.
Normal and Visibility Estimation of Human Face from a Single Image
Mar 09, 2022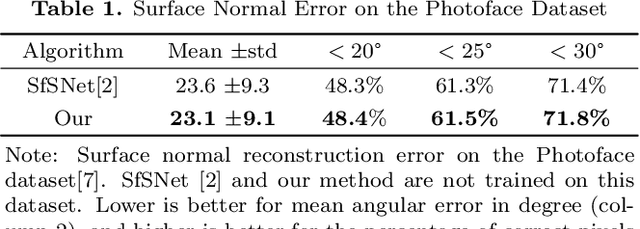
Recent work on the intrinsic image of humans starts to consider the visibility of incident illumination and encodes the light transfer function by spherical harmonics. In this paper, we show that such a light transfer function can be further decomposed into visibility and cosine terms related to surface normal. Such decomposition allows us to recover the surface normal in addition to visibility. We propose a deep learning-based approach with a reconstruction loss for training on real-world images. Results show that compared with previous works, the reconstruction of human face from our method better reveals the surface normal and shading details especially around regions where visibility effect is strong.
Open-Vocabulary Panoptic Segmentation with MaskCLIP
Aug 18, 2022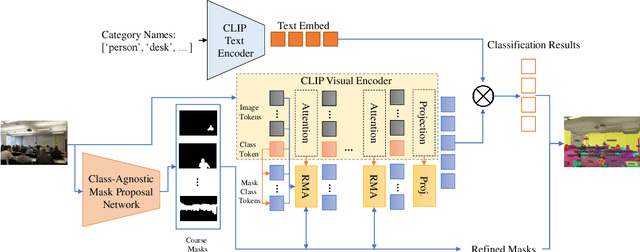
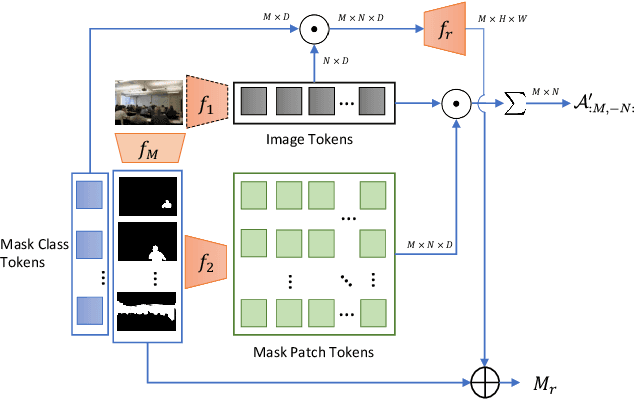
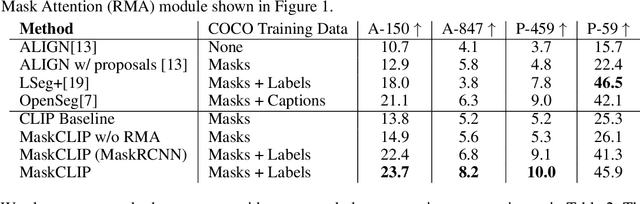
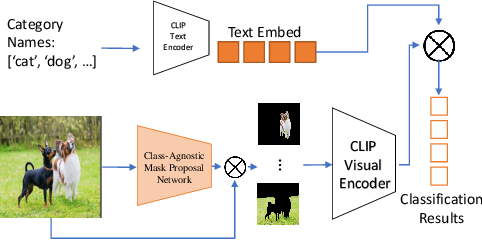
In this paper, we tackle a new computer vision task, open-vocabulary panoptic segmentation, that aims to perform panoptic segmentation (background semantic labeling + foreground instance segmentation) for arbitrary categories of text-based descriptions. We first build a baseline method without finetuning nor distillation to utilize the knowledge in the existing CLIP model. We then develop a new method, MaskCLIP, that is a Transformer-based approach using mask queries with the ViT-based CLIP backbone to perform semantic segmentation and object instance segmentation. Here we design a Relative Mask Attention (RMA) module to account for segmentations as additional tokens to the ViT CLIP model. MaskCLIP learns to efficiently and effectively utilize pre-trained dense/local CLIP features by avoiding the time-consuming operation to crop image patches and compute feature from an external CLIP image model. We obtain encouraging results for open-vocabulary panoptic segmentation and state-of-the-art results for open-vocabulary semantic segmentation on ADE20K and PASCAL datasets. We show qualitative illustration for MaskCLIP with custom categories.
Rethinking skip connection model as a learnable Markov chain
Sep 30, 2022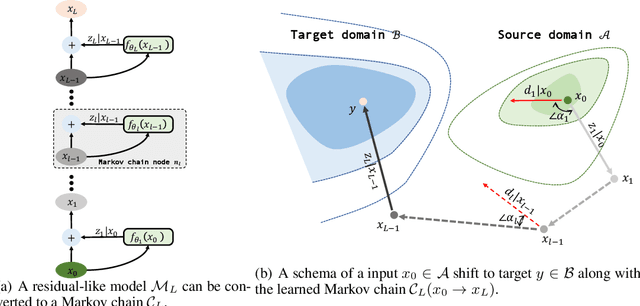

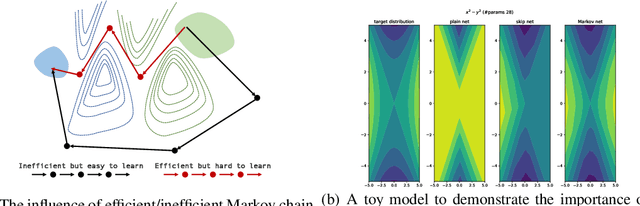
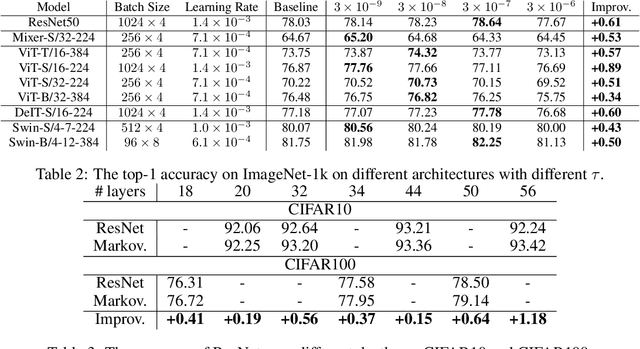
Over past few years afterward the birth of ResNet, skip connection has become the defacto standard for the design of modern architectures due to its widespread adoption, easy optimization and proven performance. Prior work has explained the effectiveness of the skip connection mechanism from different perspectives. In this work, we deep dive into the model's behaviors with skip connections which can be formulated as a learnable Markov chain. An efficient Markov chain is preferred as it always maps the input data to the target domain in a better way. However, while a model is explained as a Markov chain, it is not guaranteed to be optimized following an efficient Markov chain by existing SGD-based optimizers which are prone to get trapped in local optimal points. In order to towards a more efficient Markov chain, we propose a simple routine of penal connection to make any residual-like model become a learnable Markov chain. Aside from that, the penal connection can also be viewed as a particular model regularization and can be easily implemented with one line of code in the most popular deep learning frameworks~\footnote{Source code: \url{https://github.com/densechen/penal-connection}}. The encouraging experimental results in multi-modal translation and image recognition empirically confirm our conjecture of the learnable Markov chain view and demonstrate the superiority of the proposed penal connection.
Neural Contourlet Network for Monocular 360 Depth Estimation
Aug 03, 2022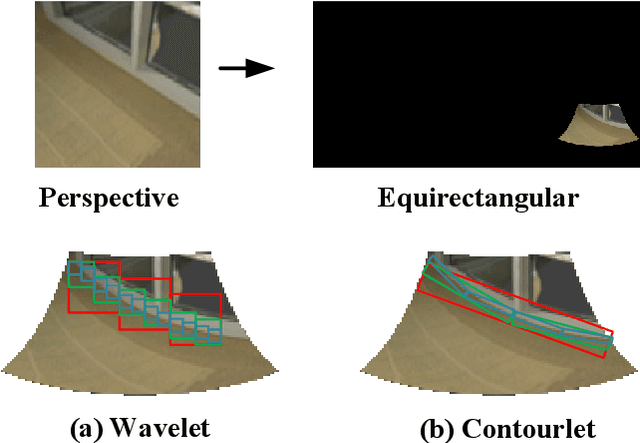


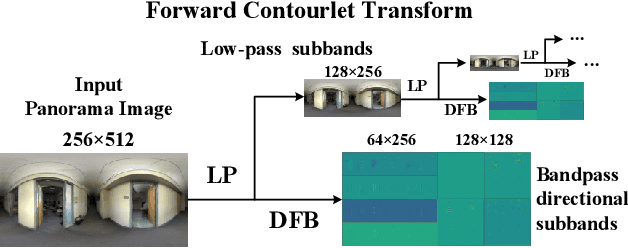
For a monocular 360 image, depth estimation is a challenging because the distortion increases along the latitude. To perceive the distortion, existing methods devote to designing a deep and complex network architecture. In this paper, we provide a new perspective that constructs an interpretable and sparse representation for a 360 image. Considering the importance of the geometric structure in depth estimation, we utilize the contourlet transform to capture an explicit geometric cue in the spectral domain and integrate it with an implicit cue in the spatial domain. Specifically, we propose a neural contourlet network consisting of a convolutional neural network and a contourlet transform branch. In the encoder stage, we design a spatial-spectral fusion module to effectively fuse two types of cues. Contrary to the encoder, we employ the inverse contourlet transform with learned low-pass subbands and band-pass directional subbands to compose the depth in the decoder. Experiments on the three popular panoramic image datasets demonstrate that the proposed approach outperforms the state-of-the-art schemes with faster convergence. Code is available at https://github.com/zhijieshen-bjtu/Neural-Contourlet-Network-for-MODE.
Two-Stream Graph Convolutional Network for Intra-oral Scanner Image Segmentation
Apr 19, 2022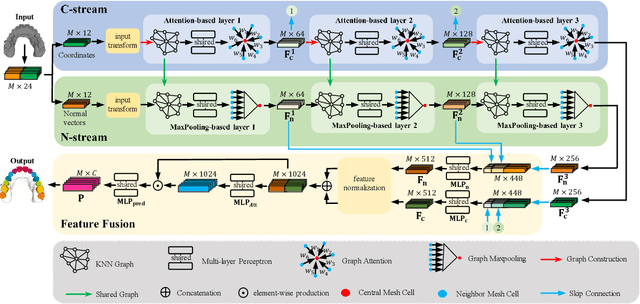
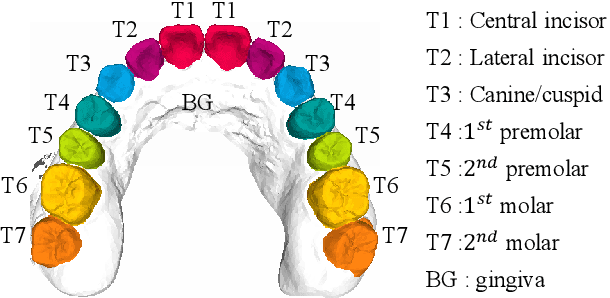
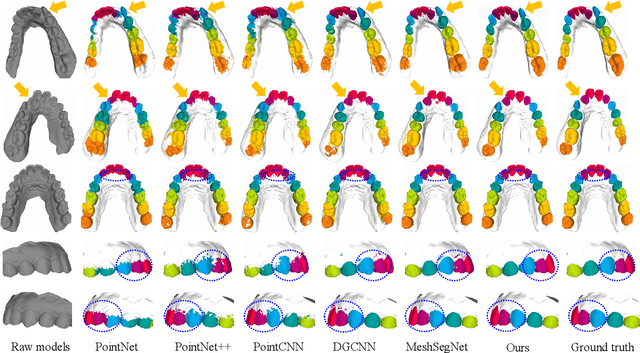
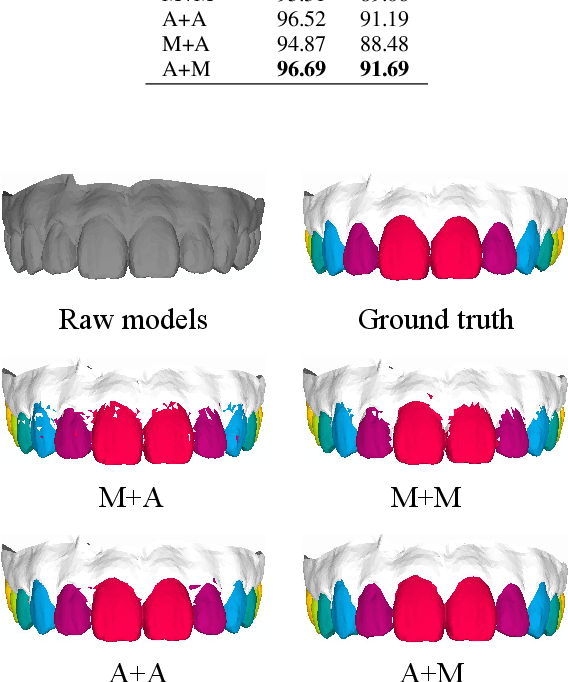
Precise segmentation of teeth from intra-oral scanner images is an essential task in computer-aided orthodontic surgical planning. The state-of-the-art deep learning-based methods often simply concatenate the raw geometric attributes (i.e., coordinates and normal vectors) of mesh cells to train a single-stream network for automatic intra-oral scanner image segmentation. However, since different raw attributes reveal completely different geometric information, the naive concatenation of different raw attributes at the (low-level) input stage may bring unnecessary confusion in describing and differentiating between mesh cells, thus hampering the learning of high-level geometric representations for the segmentation task. To address this issue, we design a two-stream graph convolutional network (i.e., TSGCN), which can effectively handle inter-view confusion between different raw attributes to more effectively fuse their complementary information and learn discriminative multi-view geometric representations. Specifically, our TSGCN adopts two input-specific graph-learning streams to extract complementary high-level geometric representations from coordinates and normal vectors, respectively. Then, these single-view representations are further fused by a self-attention module to adaptively balance the contributions of different views in learning more discriminative multi-view representations for accurate and fully automatic tooth segmentation. We have evaluated our TSGCN on a real-patient dataset of dental (mesh) models acquired by 3D intraoral scanners. Experimental results show that our TSGCN significantly outperforms state-of-the-art methods in 3D tooth (surface) segmentation. Github: https://github.com/ZhangLingMing1/TSGCNet.
* 11 pages, 6 figures. arXiv admin note: text overlap with arXiv:2012.13697