 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiRA: Discriminative, Restorative, and Adversarial Learning for Self-supervised Medical Image Analysis
Apr 21, 2022
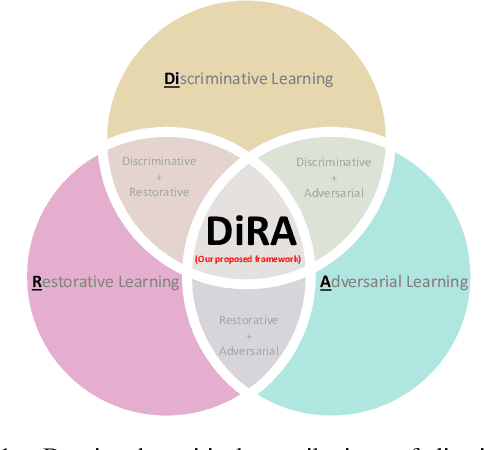

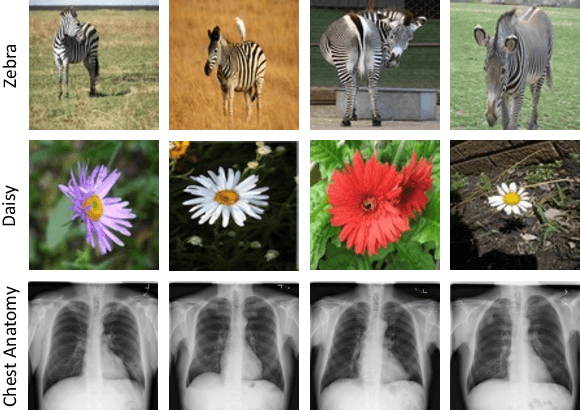
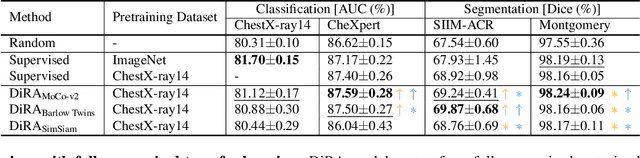
Discriminative learning, restorative learning, and adversarial learning have proven beneficial for self-supervised learning schemes in computer vision and medical imaging. Existing efforts, however, omit their synergistic effects on each other in a ternary setup, which, we envision, can significantly benefit deep semantic representation learning. To realize this vision, we have developed DiRA, the first framework that unites discriminative, restorative, and adversarial learning in a unified manner to collaboratively glean complementary visual information from unlabeled medical images for fine-grained semantic representation learning. Our extensive experiments demonstrate that DiRA (1) encourages collaborative learning among three learning ingredients, resulting in more generalizable representation across organs, diseases, and modalities; (2) outperforms fully supervised ImageNet models and increases robustness in small data regimes, reducing annotation cost across multiple medical imaging applications; (3) learns fine-grained semantic representation, facilitating accurate lesion localization with only image-level annotation; and (4) enhances state-of-the-art restorative approaches, revealing that DiRA is a general mechanism for united representation learning. All code and pre-trained models are available at https: //github.com/JLiangLab/DiRA.
CRCNet: Few-shot Segmentation with Cross-Reference and Region-Global Conditional Networks
Aug 23, 2022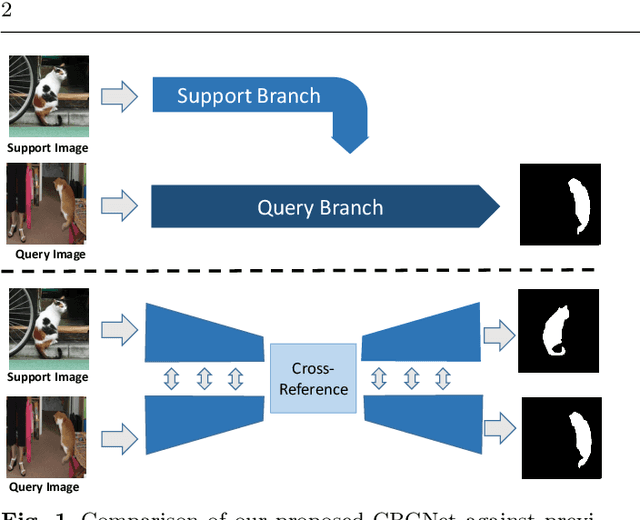

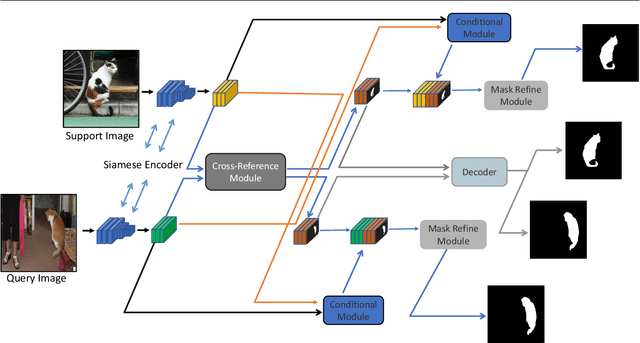

Few-shot segmentation aims to learn a segmentation model that can be generalized to novel classes with only a few training images. In this paper, we propose a Cross-Reference and Local-Global Conditional Networks (CRCNet) for few-shot segmentation. Unlike previous works that only predict the query image's mask, our proposed model concurrently makes predictions for both the support image and the query image. Our network can better find the co-occurrent objects in the two images with a cross-reference mechanism, thus helping the few-shot segmentation task. To further improve feature comparison, we develop a local-global conditional module to capture both global and local relations. We also develop a mask refinement module to refine the prediction of the foreground regions recurrently. Experiments on the PASCAL VOC 2012, MS COCO, and FSS-1000 datasets show that our network achieves new state-of-the-art performance.
Crowd Counting on Heavily Compressed Images with Curriculum Pre-Training
Aug 15, 2022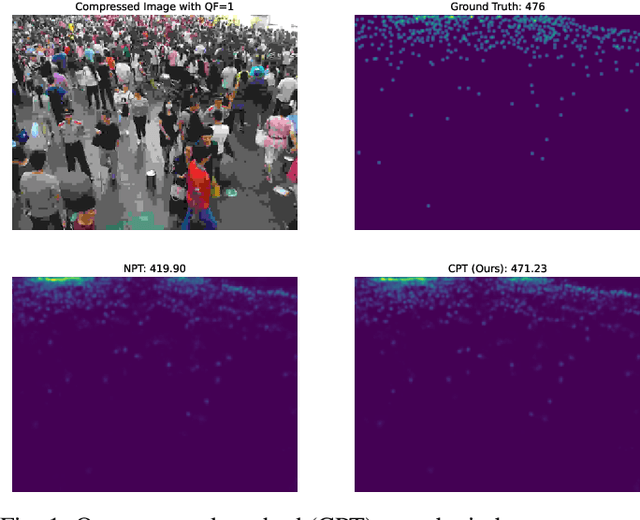

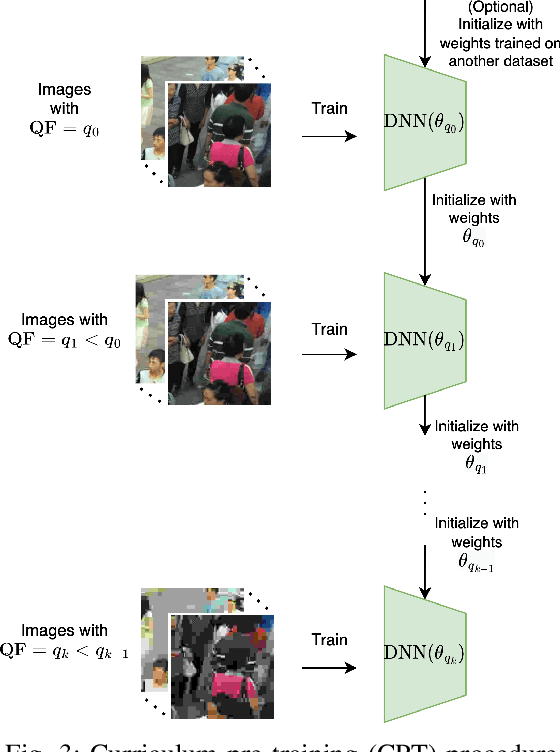
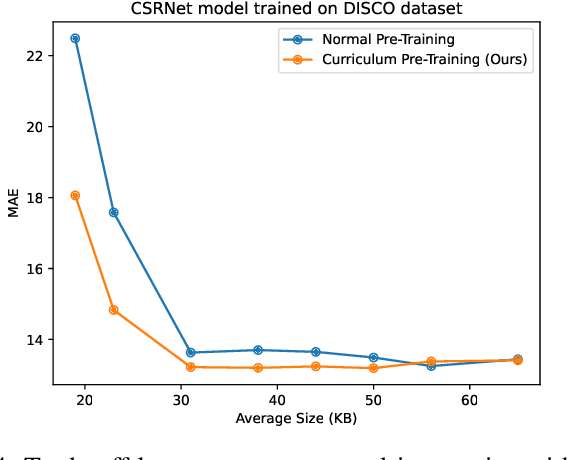
JPEG image compression algorithm is a widely used technique for image size reduction in edge and cloud computing settings. However, applying such lossy compression on images processed by deep neural networks can lead to significant accuracy degradation. Inspired by the curriculum learning paradigm, we present a novel training approach called curriculum pre-training (CPT) for crowd counting on compressed images, which alleviates the drop in accuracy resulting from lossy compression. We verify the effectiveness of our approach by extensive experiments on three crowd counting datasets, two crowd counting DNN models and various levels of compression. Our proposed training method is not overly sensitive to hyper-parameters, and reduces the error, particularly for heavily compressed images, by up to 19.70%.
Bridged Transformer for Vision and Point Cloud 3D Object Detection
Oct 04, 2022

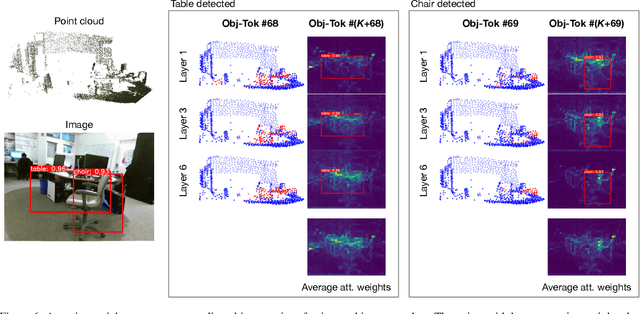
3D object detection is a crucial research topic in computer vision, which usually uses 3D point clouds as input in conventional setups. Recently, there is a trend of leveraging multiple sources of input data, such as complementing the 3D point cloud with 2D images that often have richer color and fewer noises. However, due to the heterogeneous geometrics of the 2D and 3D representations, it prevents us from applying off-the-shelf neural networks to achieve multimodal fusion. To that end, we propose Bridged Transformer (BrT), an end-to-end architecture for 3D object detection. BrT is simple and effective, which learns to identify 3D and 2D object bounding boxes from both points and image patches. A key element of BrT lies in the utilization of object queries for bridging 3D and 2D spaces, which unifies different sources of data representations in Transformer. We adopt a form of feature aggregation realized by point-to-patch projections which further strengthen the correlations between images and points. Moreover, BrT works seamlessly for fusing the point cloud with multi-view images. We experimentally show that BrT surpasses state-of-the-art methods on SUN RGB-D and ScanNetV2 datasets.
Data drift correction via time-varying importance weight estimator
Oct 04, 2022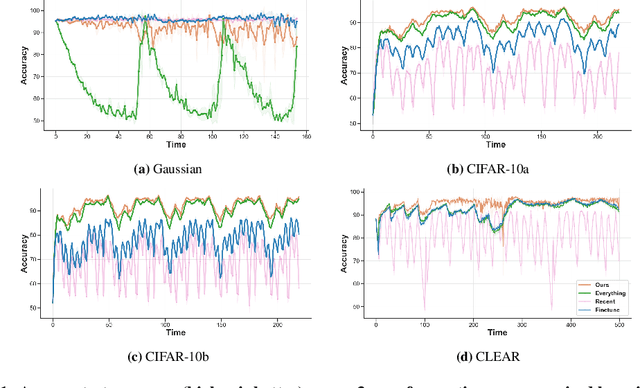

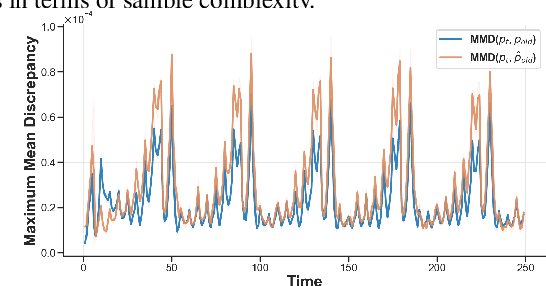
Real-world deployment of machine learning models is challenging when data evolves over time. And data does evolve over time. While no model can work when data evolves in an arbitrary fashion, if there is some pattern to these changes, we might be able to design methods to address it. This paper addresses situations when data evolves gradually. We introduce a novel time-varying importance weight estimator that can detect gradual shifts in the distribution of data. Such an importance weight estimator allows the training method to selectively sample past data -- not just similar data from the past like a standard importance weight estimator would but also data that evolved in a similar fashion in the past. Our time-varying importance weight is quite general. We demonstrate different ways of implementing it that exploit some known structure in the evolution of data. We demonstrate and evaluate this approach on a variety of problems ranging from supervised learning tasks (multiple image classification datasets) where the data undergoes a sequence of gradual shifts of our design to reinforcement learning tasks (robotic manipulation and continuous control) where data undergoes a shift organically as the policy or the task changes.
Improving Sample Quality of Diffusion Models Using Self-Attention Guidance
Oct 04, 2022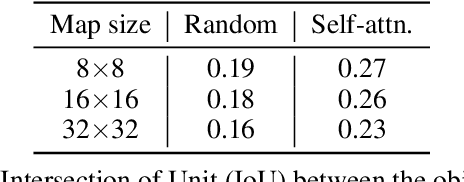
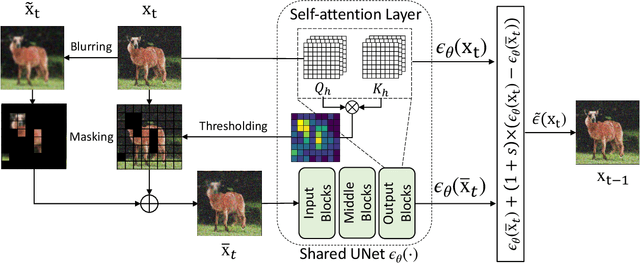
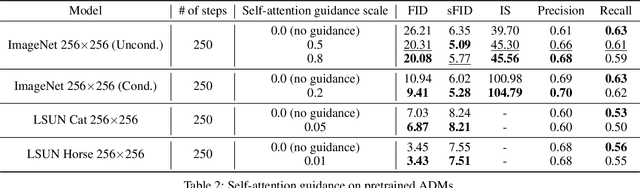

Following generative adversarial networks (GANs), a de facto standard model for image generation, denoising diffusion models (DDMs) have been actively researched and attracted strong attention due to their capability to generate images with high quality and diversity. However, the way the internal self-attention mechanism works inside the UNet of DDMs is under-explored. To unveil them, in this paper, we first investigate the self-attention operations within the black-boxed diffusion models and build hypotheses. Next, we verify the hypotheses about the self-attention map by conducting frequency analysis and testing the relationships with the generated objects. In consequence, we find out that the attention map is closely related to the quality of generated images. On the other hand, diffusion guidance methods based on additional information such as labels are proposed to improve the quality of generated images. Inspired by these methods, we present label-free guidance based on the intermediate self-attention map that can guide existing pretrained diffusion models to generate images with higher fidelity. In addition to the enhanced sample quality when used alone, we show that the results are further improved by combining our method with classifier guidance on ImageNet 128x128.
Neural Frank-Wolfe Policy Optimization for Region-of-Interest Intra-Frame Coding with HEVC/H.265
Sep 27, 2022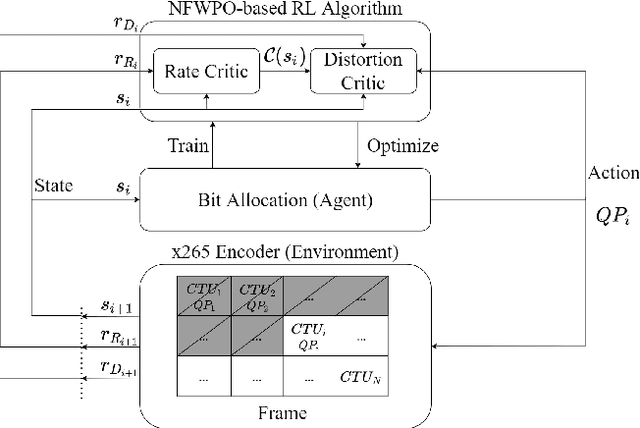
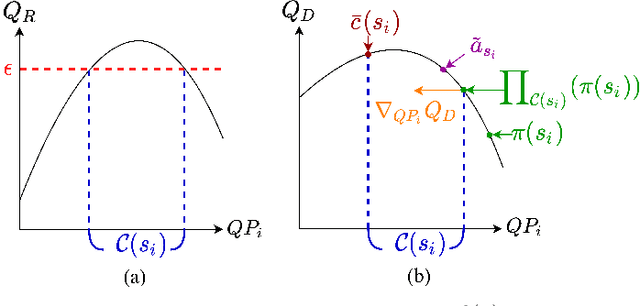
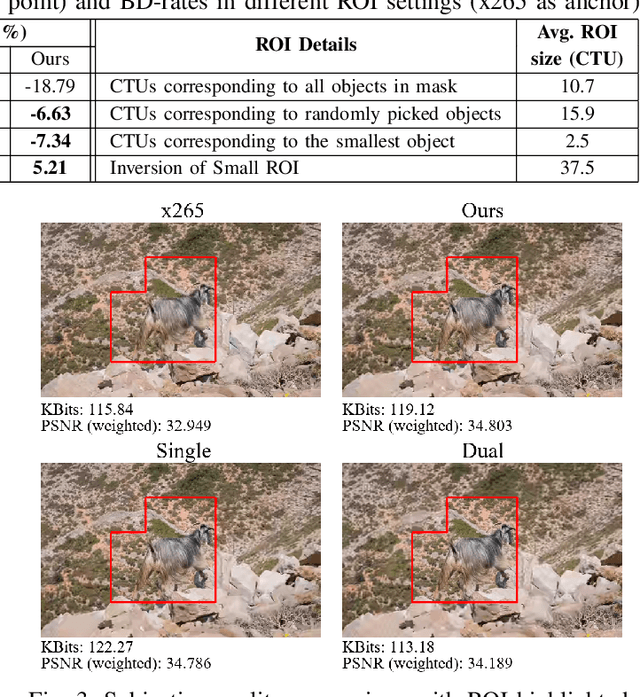
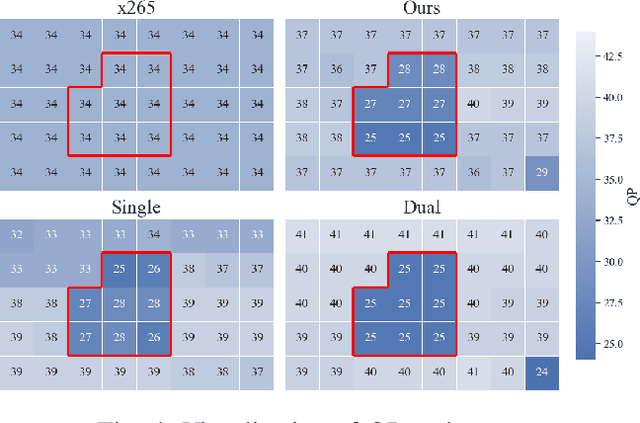
This paper presents a reinforcement learning (RL) framework that utilizes Frank-Wolfe policy optimization to solve Coding-Tree-Unit (CTU) bit allocation for Region-of-Interest (ROI) intra-frame coding. Most previous RL-based methods employ the single-critic design, where the rewards for distortion minimization and rate regularization are weighted by an empirically chosen hyper-parameter. Recently, the dual-critic design is proposed to update the actor by alternating the rate and distortion critics. However, its convergence is not guaranteed. To address these issues, we introduce Neural Frank-Wolfe Policy Optimization (NFWPO) in formulating the CTU-level bit allocation as an action-constrained RL problem. In this new framework, we exploit a rate critic to predict a feasible set of actions. With this feasible set, a distortion critic is invoked to update the actor to maximize the ROI-weighted image quality subject to a rate constraint. Experimental results produced with x265 confirm the superiority of the proposed method to the other baselines.
IL-MCAM: An interactive learning and multi-channel attention mechanism-based weakly supervised colorectal histopathology image classification approach
Jun 07, 2022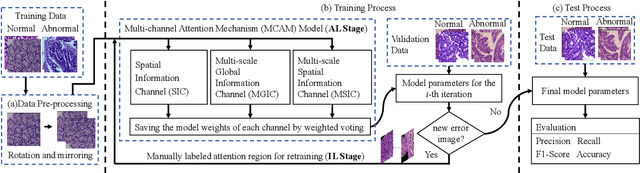
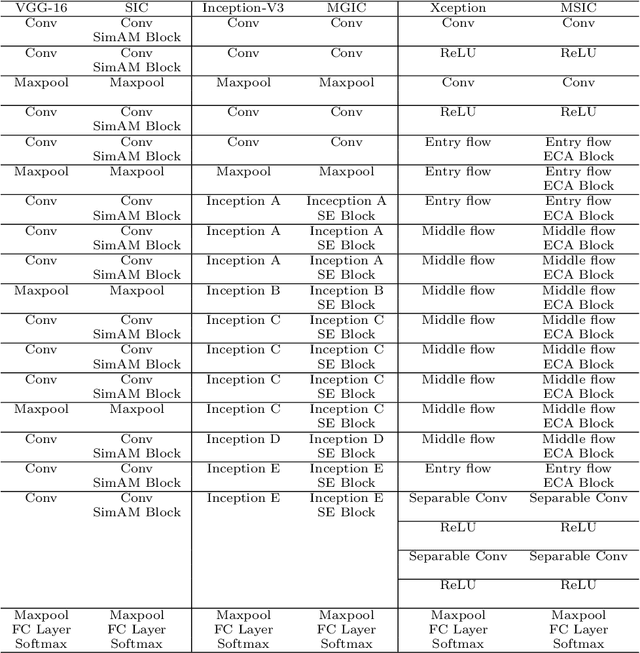
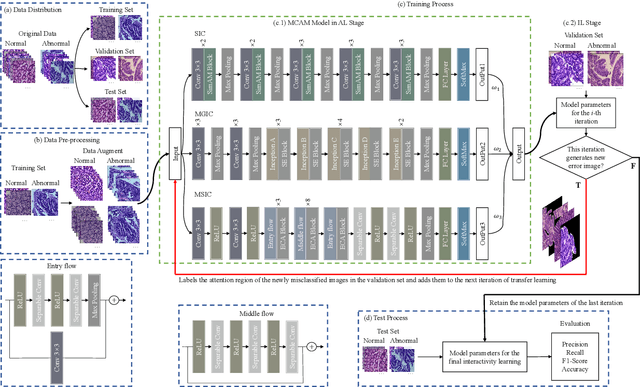
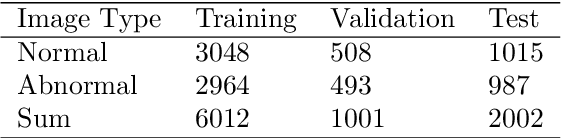
In recent years, colorectal cancer has become one of the most significant diseases that endanger human health. Deep learning methods are increasingly important for the classification of colorectal histopathology images. However, existing approaches focus more on end-to-end automatic classification using computers rather than human-computer interaction. In this paper, we propose an IL-MCAM framework. It is based on attention mechanisms and interactive learning. The proposed IL-MCAM framework includes two stages: automatic learning (AL) and interactivity learning (IL). In the AL stage, a multi-channel attention mechanism model containing three different attention mechanism channels and convolutional neural networks is used to extract multi-channel features for classification. In the IL stage, the proposed IL-MCAM framework continuously adds misclassified images to the training set in an interactive approach, which improves the classification ability of the MCAM model. We carried out a comparison experiment on our dataset and an extended experiment on the HE-NCT-CRC-100K dataset to verify the performance of the proposed IL-MCAM framework, achieving classification accuracies of 98.98% and 99.77%, respectively. In addition, we conducted an ablation experiment and an interchangeability experiment to verify the ability and interchangeability of the three channels. The experimental results show that the proposed IL-MCAM framework has excellent performance in the colorectal histopathological image classification tasks.
LION: Latent Point Diffusion Models for 3D Shape Generation
Oct 12, 2022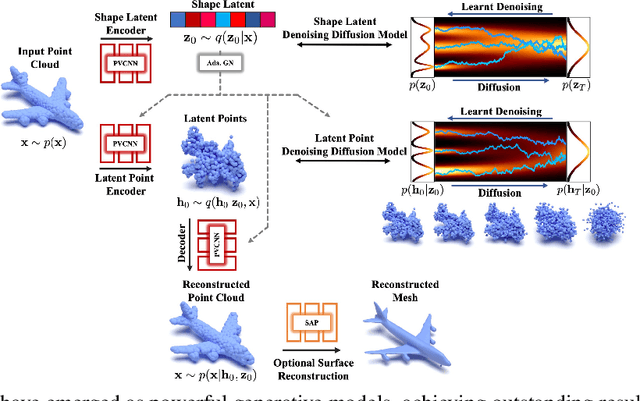


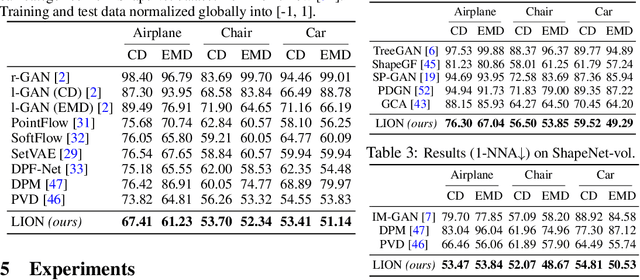
Denoising diffusion models (DDMs) have shown promising results in 3D point cloud synthesis. To advance 3D DDMs and make them useful for digital artists, we require (i) high generation quality, (ii) flexibility for manipulation and applications such as conditional synthesis and shape interpolation, and (iii) the ability to output smooth surfaces or meshes. To this end, we introduce the hierarchical Latent Point Diffusion Model (LION) for 3D shape generation. LION is set up as a variational autoencoder (VAE) with a hierarchical latent space that combines a global shape latent representation with a point-structured latent space. For generation, we train two hierarchical DDMs in these latent spaces. The hierarchical VAE approach boosts performance compared to DDMs that operate on point clouds directly, while the point-structured latents are still ideally suited for DDM-based modeling. Experimentally, LION achieves state-of-the-art generation performance on multiple ShapeNet benchmarks. Furthermore, our VAE framework allows us to easily use LION for different relevant tasks: LION excels at multimodal shape denoising and voxel-conditioned synthesis, and it can be adapted for text- and image-driven 3D generation. We also demonstrate shape autoencoding and latent shape interpolation, and we augment LION with modern surface reconstruction techniques to generate smooth 3D meshes. We hope that LION provides a powerful tool for artists working with 3D shapes due to its high-quality generation, flexibility, and surface reconstruction. Project page and code: https://nv-tlabs.github.io/LION.
Decomposed Knowledge Distillation for Class-Incremental Semantic Segmentation
Oct 12, 2022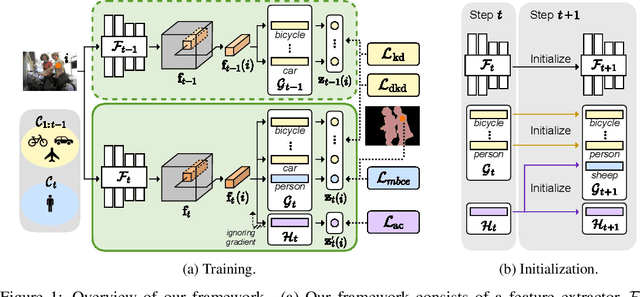
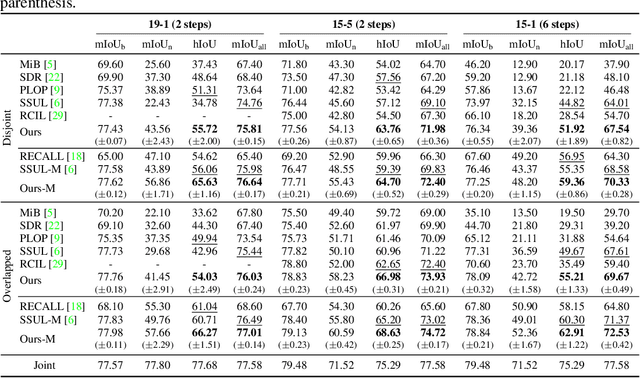
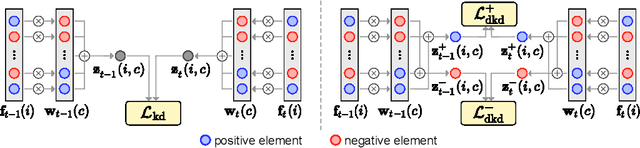
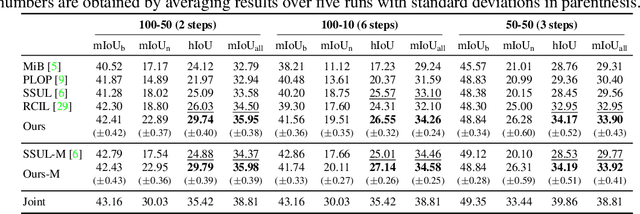
Class-incremental semantic segmentation (CISS) labels each pixel of an image with a corresponding object/stuff class continually. To this end, it is crucial to learn novel classes incrementally without forgetting previously learned knowledge. Current CISS methods typically use a knowledge distillation (KD) technique for preserving classifier logits, or freeze a feature extractor, to avoid the forgetting problem. The strong constraints, however, prevent learning discriminative features for novel classes. We introduce a CISS framework that alleviates the forgetting problem and facilitates learning novel classes effectively. We have found that a logit can be decomposed into two terms. They quantify how likely an input belongs to a particular class or not, providing a clue for a reasoning process of a model. The KD technique, in this context, preserves the sum of two terms (i.e., a class logit), suggesting that each could be changed and thus the KD does not imitate the reasoning process. To impose constraints on each term explicitly, we propose a new decomposed knowledge distillation (DKD) technique, improving the rigidity of a model and addressing the forgetting problem more effectively. We also introduce a novel initialization method to train new classifiers for novel classes. In CISS, the number of negative training samples for novel classes is not sufficient to discriminate old classes. To mitigate this, we propose to transfer knowledge of negatives to the classifiers successively using an auxiliary classifier, boosting the performance significantly. Experimental results on standard CISS benchmarks demonstrate the effectiveness of our framework.