 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prediction of motion induced magnetic fields for human brain MRI at 3T
Sep 30, 2022
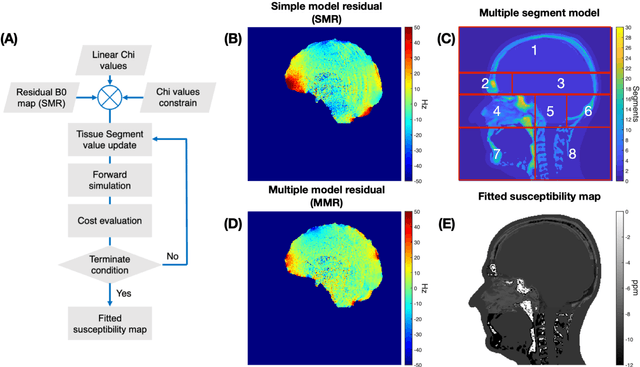
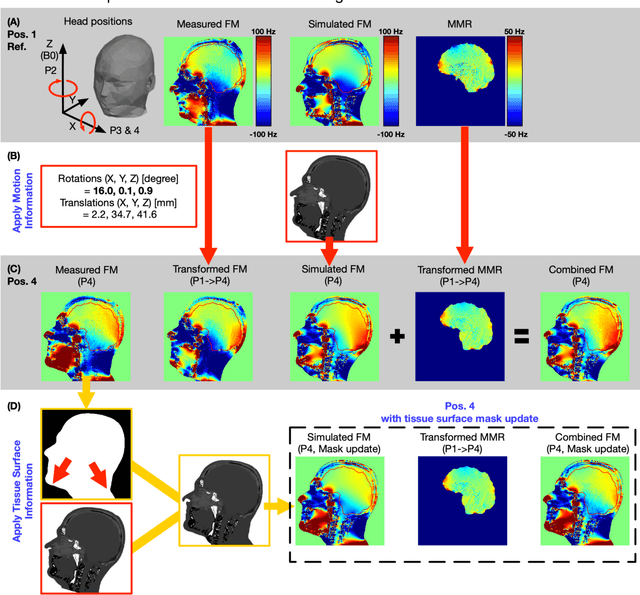
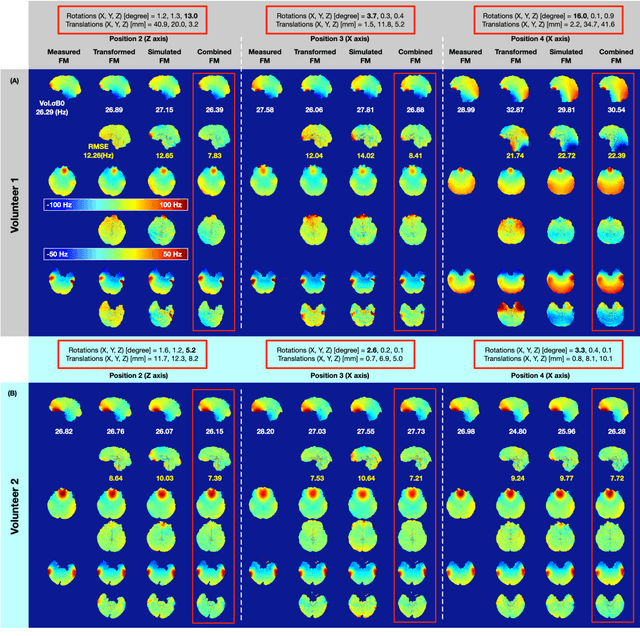
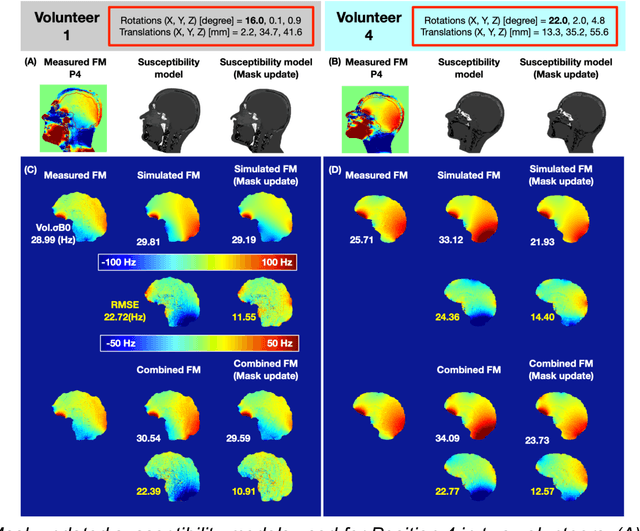
Objective Maps of B0 field inhomogeneities are often used to improve MRI image quality, even in a retrospective fashion. These field inhomogeneities depend on the exact head position within the static field but acquiring field maps (FM) at every position is time consuming. Here we explore different ways to obtain B0 predictions at different head positions. Methods FM were predicted from iterative simulations with four field factors: 1) sample induced B0 field, 2) system's spherical harmonic shim field, 3) perturbing field originating outside the field of view, 4) sequence phase errors. The simulation was improved by including local susceptibility sources estimated from UTE scans and position-specific masks. The estimation performance of the simulated FMs and a transformed FM, obtained from the measured reference FM, were compared with the actual FM at different head positions. Results The transformed FM provided inconsistent results for large head movements (>5 degree rotation), while the simulation strategy had a superior prediction accuracy for all positions. The simulated FM was used to optimize B0 shims with up to 22.2% improvement with respect to the transformed FM approach. Conclusion The proposed simulation strategy is able to predict movement induced B0 field inhomogeneities yielding more precise estimates of the ground truth field homogeneity than the transformed FM.
Content-Aware Differential Privacy with Conditional Invertible Neural Networks
Jul 29, 2022
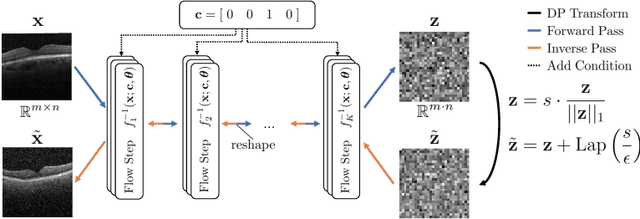

Differential privacy (DP) has arisen as the gold standard in protecting an individual's privacy in datasets by adding calibrated noise to each data sample. While the application to categorical data is straightforward, its usability in the context of images has been limited. Contrary to categorical data the meaning of an image is inherent in the spatial correlation of neighboring pixels making the simple application of noise infeasible. Invertible Neural Networks (INN) have shown excellent generative performance while still providing the ability to quantify the exact likelihood. Their principle is based on transforming a complicated distribution into a simple one e.g. an image into a spherical Gaussian. We hypothesize that adding noise to the latent space of an INN can enable differentially private image modification. Manipulation of the latent space leads to a modified image while preserving important details. Further, by conditioning the INN on meta-data provided with the dataset we aim at leaving dimensions important for downstream tasks like classification untouched while altering other parts that potentially contain identifying information. We term our method content-aware differential privacy (CADP). We conduct experiments on publicly available benchmarking datasets as well as dedicated medical ones. In addition, we show the generalizability of our method to categorical data. The source code is publicly available at https://github.com/Cardio-AI/CADP.
Rigidity Preserving Image Transformations and Equivariance in Perspective
Jan 31, 2022



We characterize the class of image plane transformations which realize rigid camera motions and call these transformations `rigidity preserving'. In particular, 2D translations of pinhole images are not rigidity preserving. Hence, when using CNNs for 3D inference tasks, it can be beneficial to modify the inductive bias from equivariance towards translations to equivariance towards rigidity preserving transformations. We investigate how equivariance with respect to rigidity preserving transformations can be approximated in CNNs, and test our ideas on both 6D object pose estimation and visual localization. Experimentally, we improve on several competitive baselines.
Repurposing Existing Deep Networks for Caption and Aesthetic-Guided Image Cropping
Jan 07, 2022
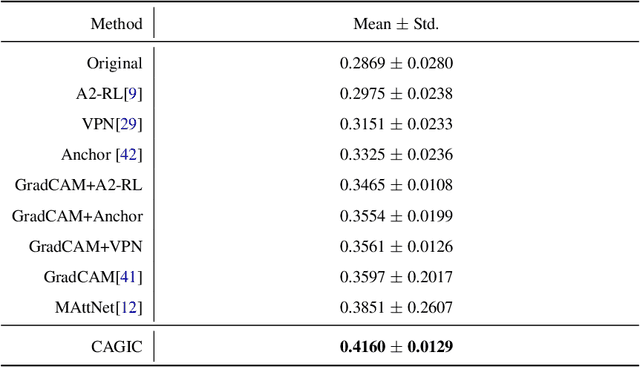
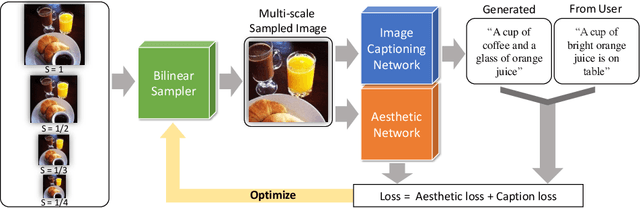
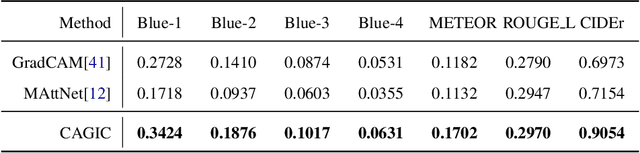
We propose a novel optimization framework that crops a given image based on user description and aesthetics. Unlike existing image cropping methods, where one typically trains a deep network to regress to crop parameters or cropping actions, we propose to directly optimize for the cropping parameters by repurposing pre-trained networks on image captioning and aesthetic tasks, without any fine-tuning, thereby avoiding training a separate network. Specifically, we search for the best crop parameters that minimize a combined loss of the initial objectives of these networks. To make the optimization table, we propose three strategies: (i) multi-scale bilinear sampling, (ii) annealing the scale of the crop region, therefore effectively reducing the parameter space, (iii) aggregation of multiple optimization results. Through various quantitative and qualitative evaluations, we show that our framework can produce crops that are well-aligned to intended user descriptions and aesthetically pleasing.
AesUST: Towards Aesthetic-Enhanced Universal Style Transfer
Aug 27, 2022

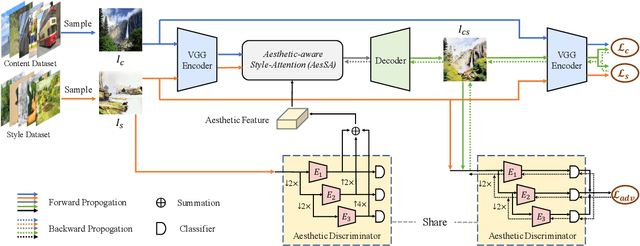
Recent studies have shown remarkable success in universal style transfer which transfers arbitrary visual styles to content images. However, existing approaches suffer from the aesthetic-unrealistic problem that introduces disharmonious patterns and evident artifacts, making the results easy to spot from real paintings. To address this limitation, we propose AesUST, a novel Aesthetic-enhanced Universal Style Transfer approach that can generate aesthetically more realistic and pleasing results for arbitrary styles. Specifically, our approach introduces an aesthetic discriminator to learn the universal human-delightful aesthetic features from a large corpus of artist-created paintings. Then, the aesthetic features are incorporated to enhance the style transfer process via a novel Aesthetic-aware Style-Attention (AesSA) module. Such an AesSA module enables our AesUST to efficiently and flexibly integrate the style patterns according to the global aesthetic channel distribution of the style image and the local semantic spatial distribution of the content image. Moreover, we also develop a new two-stage transfer training strategy with two aesthetic regularizations to train our model more effectively, further improving stylization performance. Extensive experiments and user studies demonstrate that our approach synthesizes aesthetically more harmonious and realistic results than state of the art, greatly narrowing the disparity with real artist-created paintings. Our code is available at https://github.com/EndyWon/AesUST.
Image Fusion Transformer
Jul 20, 2021
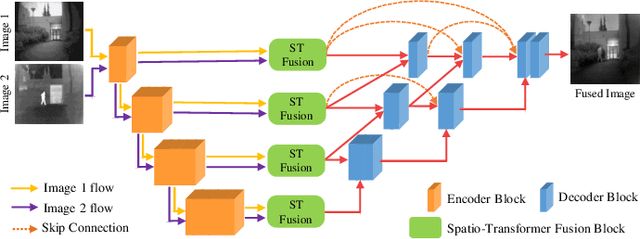
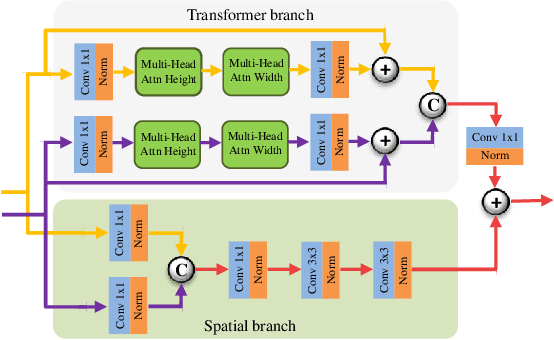
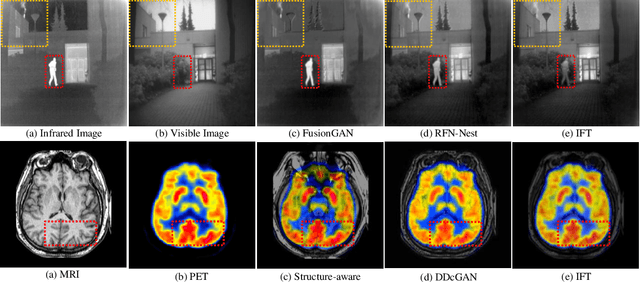
In image fusion, images obtained from different sensors are fused to generate a single image with enhanced information. In recent years, state-of-the-art methods have adopted Convolution Neural Networks (CNNs) to encode meaningful features for image fusion. Specifically, CNN-based methods perform image fusion by fusing local features. However, they do not consider long-range dependencies that are present in the image. Transformer-based models are designed to overcome this by modeling the long-range dependencies with the help of self-attention mechanism. This motivates us to propose a novel Image Fusion Transformer (IFT) where we develop a transformer-based multi-scale fusion strategy that attends to both local and long-range information (or global context). The proposed method follows a two-stage training approach. In the first stage, we train an auto-encoder to extract deep features at multiple scales. In the second stage, multi-scale features are fused using a Spatio-Transformer (ST) fusion strategy. The ST fusion blocks are comprised of a CNN and a transformer branch which capture local and long-range features, respectively. Extensive experiments on multiple benchmark datasets show that the proposed method performs better than many competitive fusion algorithms. Furthermore, we show the effectiveness of the proposed ST fusion strategy with an ablation analysis. The source code is available at: https://github.com/Vibashan/Image-Fusion-Transformer.
ImpressLearn: Continual Learning via Combined Task Impressions
Oct 05, 2022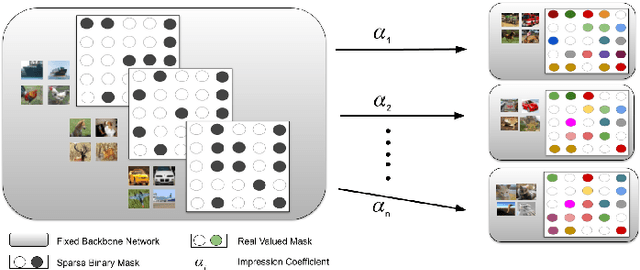
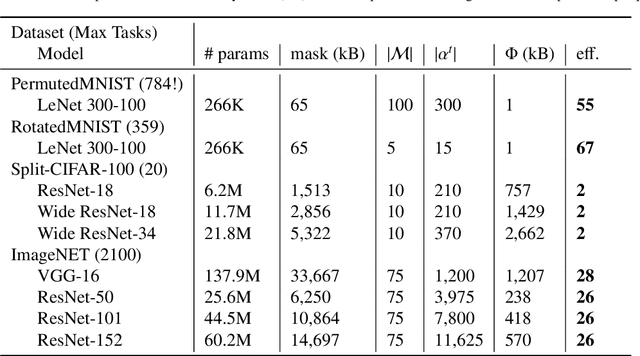
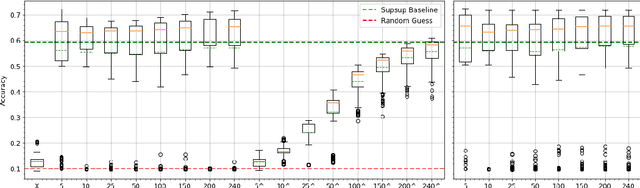
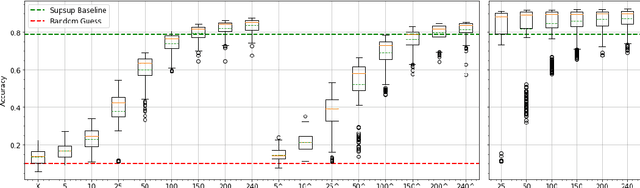
This work proposes a new method to sequentially train a deep neural network on multiple tasks without suffering catastrophic forgetting, while endowing it with the capability to quickly adapt to unseen tasks. Starting from existing work on network masking (Wortsman et al., 2020), we show that simply learning a linear combination of a small number of task-specific masks (impressions) on a randomly initialized backbone network is sufficient to both retain accuracy on previously learned tasks, as well as achieve high accuracy on new tasks. In contrast to previous methods, we do not require to generate dedicated masks or contexts for each new task, instead leveraging transfer learning to keep per-task parameter overhead small. Our work illustrates the power of linearly combining individual impressions, each of which fares poorly in isolation, to achieve performance comparable to a dedicated mask. Moreover, even repeated impressions from the same task (homogeneous masks), when combined can approach the performance of heterogeneous combinations if sufficiently many impressions are used. Our approach scales more efficiently than existing methods, often requiring orders of magnitude fewer parameters and can function without modification even when task identity is missing. In addition, in the setting where task labels are not given at inference, our algorithm gives an often favorable alternative to the entropy based task-inference methods proposed in (Wortsman et al., 2020). We evaluate our method on a number of well known image classification data sets and architectures.
Synthetic Aperture Radar Image Change Detection via Layer Attention-Based Noise-Tolerant Network
Aug 09, 2022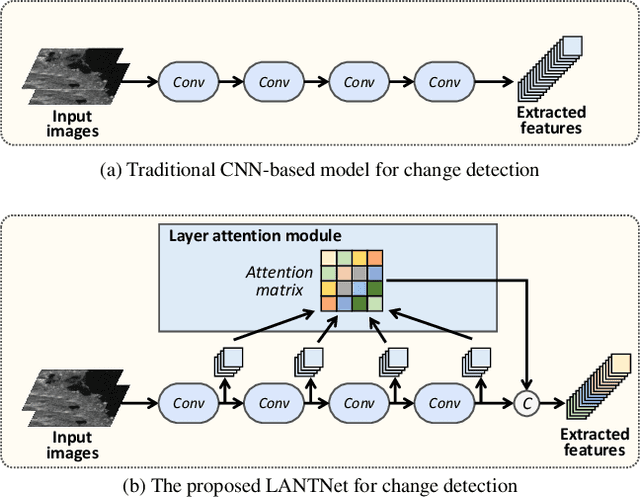
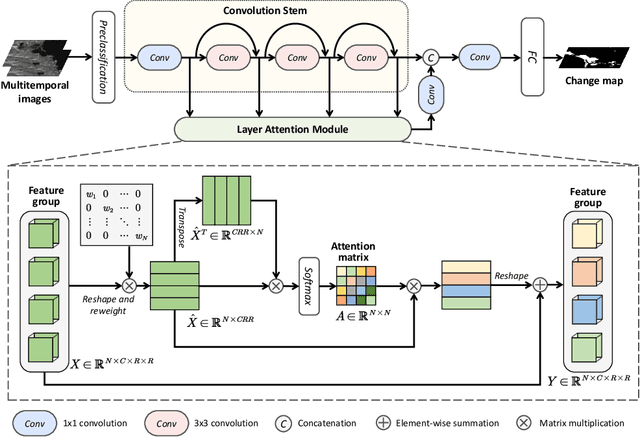
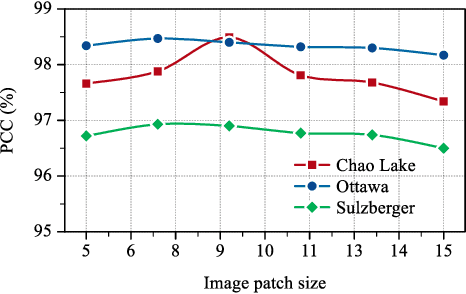

Recently, change detection methods for synthetic aperture radar (SAR) images based on convolutional neural networks (CNN) have gained increasing research attention. However, existing CNN-based methods neglect the interactions among multilayer convolutions, and errors involved in the preclassification restrict the network optimization. To this end, we proposed a layer attention-based noise-tolerant network, termed LANTNet. In particular, we design a layer attention module that adaptively weights the feature of different convolution layers. In addition, we design a noise-tolerant loss function that effectively suppresses the impact of noisy labels. Therefore, the model is insensitive to noisy labels in the preclassification results. The experimental results on three SAR datasets show that the proposed LANTNet performs better compared to several state-of-the-art methods. The source codes are available at https://github.com/summitgao/LANTNet
IOP-FL: Inside-Outside Personalization for Federated Medical Image Segmentation
Apr 16, 2022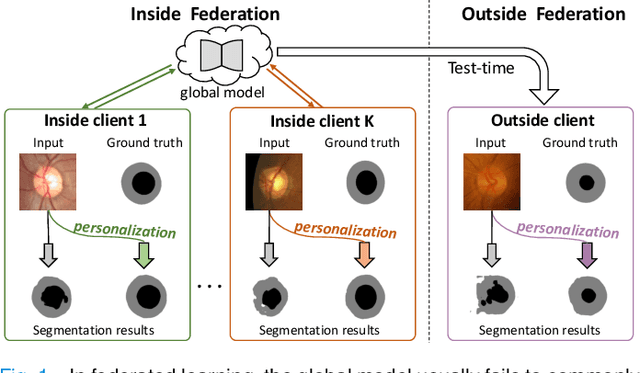
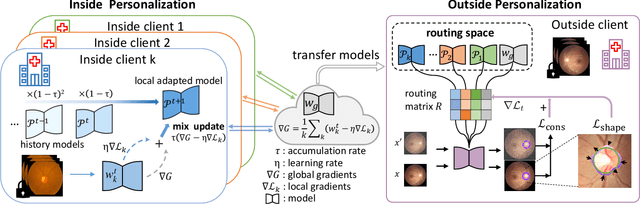
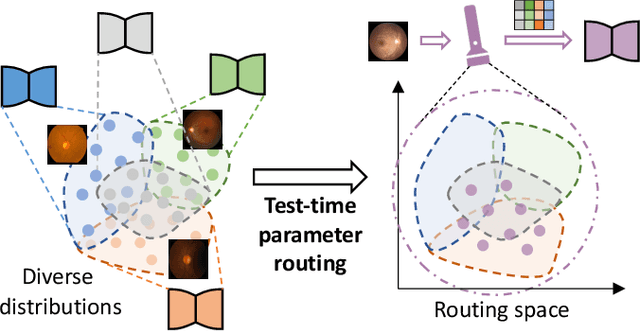
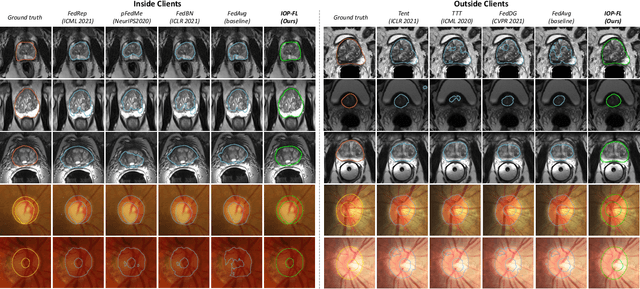
Federated learning (FL) allows multiple medical institutions to collaboratively learn a global model without centralizing all clients data. It is difficult, if possible at all, for such a global model to commonly achieve optimal performance for each individual client, due to the heterogeneity of medical data from various scanners and patient demographics. This problem becomes even more significant when deploying the global model to unseen clients outside the FL with new distributions not presented during federated training. To optimize the prediction accuracy of each individual client for critical medical tasks, we propose a novel unified framework for both Inside and Outside model Personalization in FL (IOP-FL). Our inside personalization is achieved by a lightweight gradient-based approach that exploits the local adapted model for each client, by accumulating both the global gradients for common knowledge and local gradients for client-specific optimization. Moreover, and importantly, the obtained local personalized models and the global model can form a diverse and informative routing space to personalize a new model for outside FL clients. Hence, we design a new test-time routing scheme inspired by the consistency loss with a shape constraint to dynamically incorporate the models, given the distribution information conveyed by the test data. Our extensive experimental results on two medical image segmentation tasks present significant improvements over SOTA methods on both inside and outside personalization, demonstrating the great potential of our IOP-FL scheme for clinical practice. Code will be released at https://github.com/med-air/IOP-FL.
Document Layout Analysis with Aesthetic-Guided Image Augmentation
Nov 27, 2021
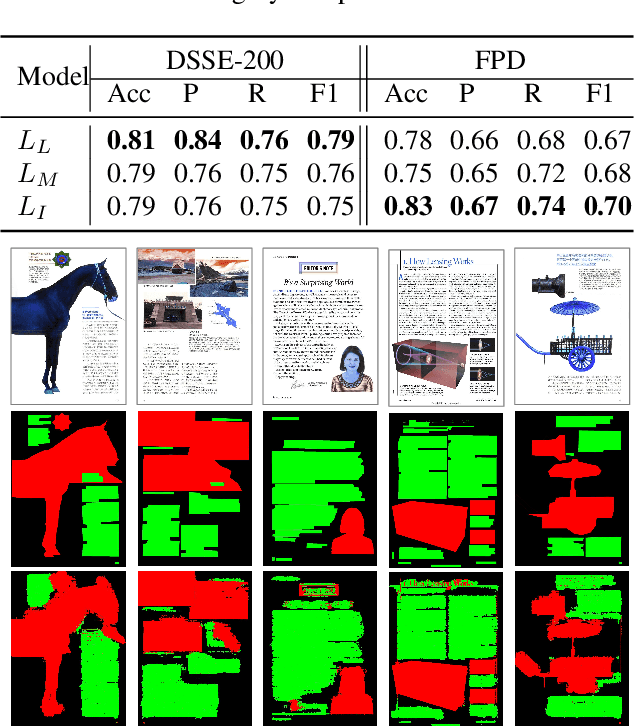
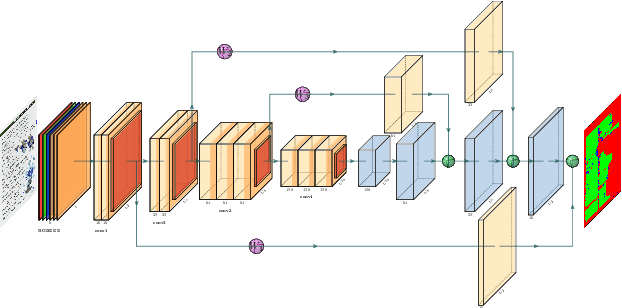
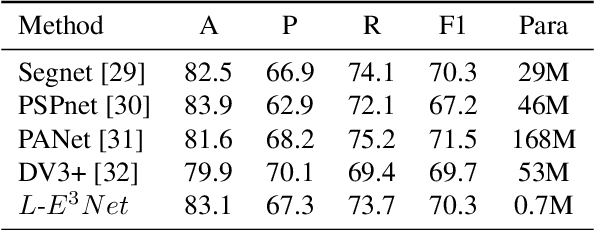
Document layout analysis (DLA) plays an important role in information extraction and document understanding. At present, document layout analysis has reached a milestone achievement, however, document layout analysis of non-Manhattan is still a challenge. In this paper, we propose an image layer modeling method to tackle this challenge. To measure the proposed image layer modeling method, we propose a manually-labeled non-Manhattan layout fine-grained segmentation dataset named FPD. As far as we know, FPD is the first manually-labeled non-Manhattan layout fine-grained segmentation dataset. To effectively extract fine-grained features of documents, we propose an edge embedding network named L-E^3Net. Experimental results prove that our proposed image layer modeling method can better deal with the fine-grained segmented document of the non-Manhattan layout.