 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mitigating Channel-wise Noise for Single Image Super Resolution
Dec 14, 2021




In practice, images can contain different amounts of noise for different color channels, which is not acknowledged by existing super-resolution approaches. In this paper, we propose to super-resolve noisy color images by considering the color channels jointly. Noise statistics are blindly estimated from the input low-resolution image and are used to assign different weights to different color channels in the data cost. Implicit low-rank structure of visual data is enforced via nuclear norm minimization in association with adaptive weights, which is added as a regularization term to the cost. Additionally, multi-scale details of the image are added to the model through another regularization term that involves projection onto PCA basis, which is constructed using similar patches extracted across different scales of the input image. The results demonstrate the super-resolving capability of the approach in real scenarios.
Towards Effective Multi-Label Recognition Attacks via Knowledge Graph Consistency
Jul 11, 2022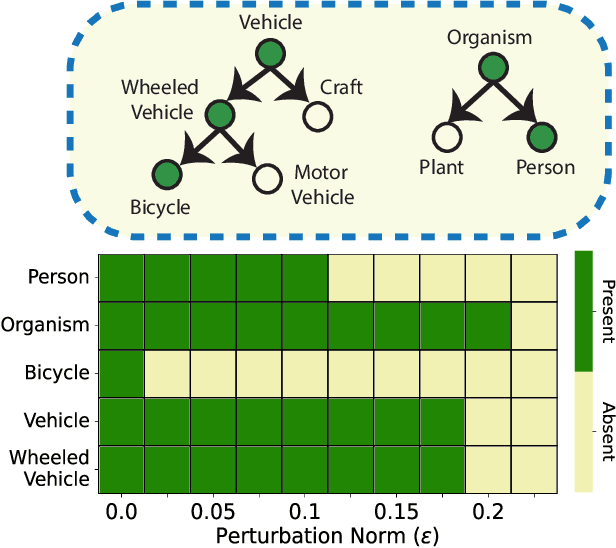
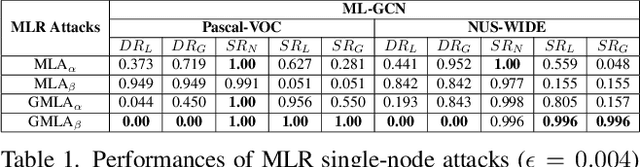
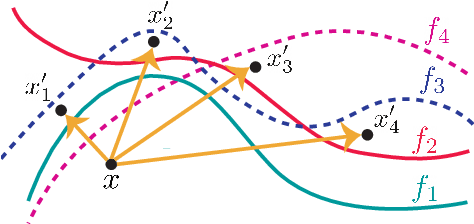
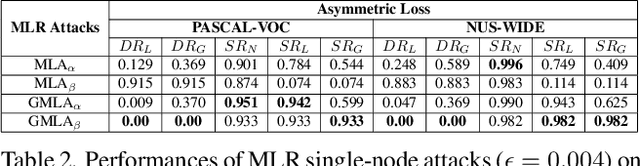
Many real-world applications of image recognition require multi-label learning, whose goal is to find all labels in an image. Thus, robustness of such systems to adversarial image perturbations is extremely important. However, despite a large body of recent research on adversarial attacks, the scope of the existing works is mainly limited to the multi-class setting, where each image contains a single label. We show that the naive extensions of multi-class attacks to the multi-label setting lead to violating label relationships, modeled by a knowledge graph, and can be detected using a consistency verification scheme. Therefore, we propose a graph-consistent multi-label attack framework, which searches for small image perturbations that lead to misclassifying a desired target set while respecting label hierarchies. By extensive experiments on two datasets and using several multi-label recognition models, we show that our method generates extremely successful attacks that, unlike naive multi-label perturbations, can produce model predictions consistent with the knowledge graph.
Thermal hand image segmentation for biometric recognition
Feb 23, 2022
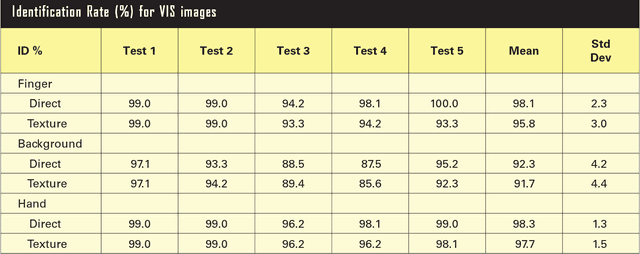
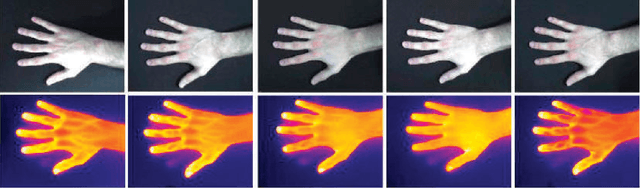

In this paper we present a method to identify people by means of thermal (TH) and visible (VIS) hand images acquired simultaneously with a TESTO 882-3 camera. In addition, we also present a new database specially acquired for this work. The real challenge when dealing with TH images is the cold finger areas, which can be confused with the acquisition surface. This problem is solved by taking advantage of the VIS information. We have performed different tests to show how TH and VIS images work in identification problems. Experimental results reveal that TH hand image is as suitable for biometric recognition systems as VIS hand images, and better results are obtained when combining this information. A Biometric Dispersion Matcher has been used as a feature vector dimensionality reduction technique as well as a classification task. Its selection criteria helps to reduce the length of the vectors used to perform identification up to a hundred measurements. Identification rates reach a maximum value of 98.3% under these conditions, when using a database of 104 people.
* 12 pages
Modeling Image Quantization Tradeoffs for Optimal Compression
Dec 14, 2021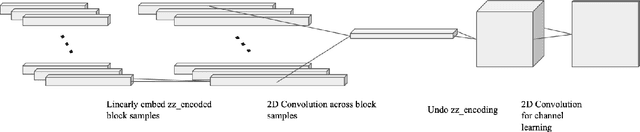
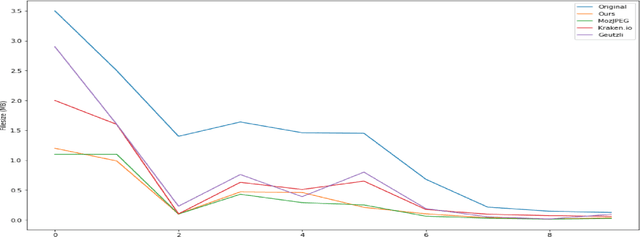
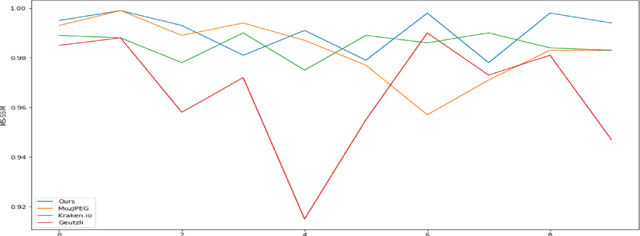
All Lossy compression algorithms employ similar compression schemes -- frequency domain transform followed by quantization and lossless encoding schemes. They target tradeoffs by quantizating high frequency data to increase compression rates which come at the cost of higher image distortion. We propose a new method of optimizing quantization tables using Deep Learning and a minimax loss function that more accurately measures the tradeoffs between rate and distortion parameters (RD) than previous methods. We design a convolutional neural network (CNN) that learns a mapping between image blocks and quantization tables in an unsupervised manner. By processing images across all channels at once, we can achieve stronger performance by also measuring tradeoffs in information loss between different channels. We initially target optimization on JPEG images but feel that this can be expanded to any lossy compressor.
Realistic Blur Synthesis for Learning Image Deblurring
Feb 17, 2022
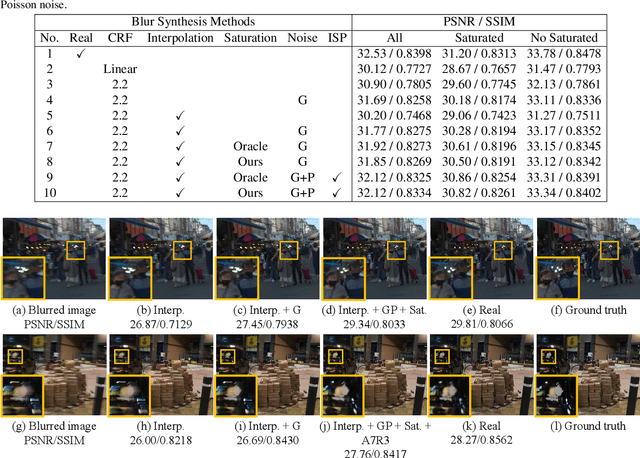
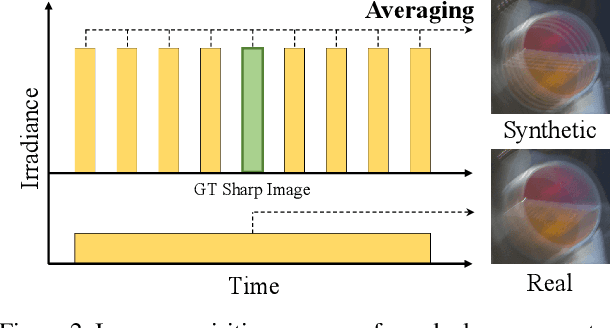

Training learning-based deblurring methods demands a significant amount of blurred and sharp image pairs. Unfortunately, existing synthetic datasets are not realistic enough, and existing real-world blur datasets provide limited diversity of scenes and camera settings. As a result, deblurring models trained on them still suffer from the lack of generalization ability for handling real blurred images. In this paper, we analyze various factors that introduce differences between real and synthetic blurred images, and present a novel blur synthesis pipeline that can synthesize more realistic blur. We also present RSBlur, a novel dataset that contains real blurred images and the corresponding sequences of sharp images. The RSBlur dataset can be used for generating synthetic blurred images to enable detailed analysis on the differences between real and synthetic blur. With our blur synthesis pipeline and RSBlur dataset, we reveal the effects of different factors in the blur synthesis. We also show that our synthesis method can improve the deblurring performance on real blurred images.
U-shape Transformer for Underwater Image Enhancement
Dec 03, 2021
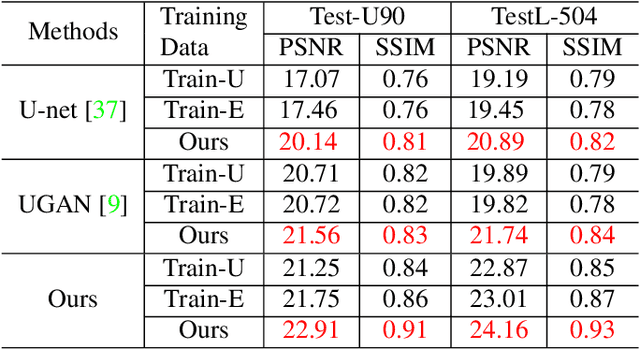
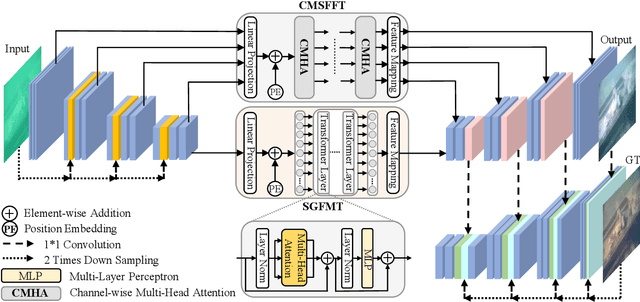
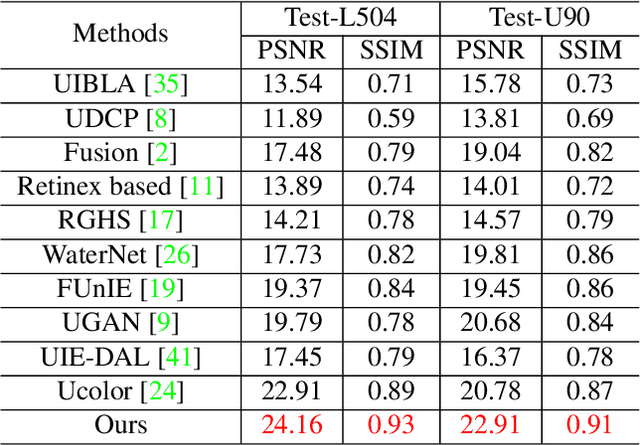
The light absorption and scattering of underwater impurities lead to poor underwater imaging quality. The existing data-driven based underwater image enhancement (UIE) techniques suffer from the lack of a large-scale dataset containing various underwater scenes and high-fidelity reference images. Besides, the inconsistent attenuation in different color channels and space areas is not fully considered for boosted enhancement. In this work, we constructed a large-scale underwater image (LSUI) dataset including 5004 image pairs, and reported an U-shape Transformer network where the transformer model is for the first time introduced to the UIE task. The U-shape Transformer is integrated with a channel-wise multi-scale feature fusion transformer (CMSFFT) module and a spatial-wise global feature modeling transformer (SGFMT) module, which reinforce the network's attention to the color channels and space areas with more serious attenuation. Meanwhile, in order to further improve the contrast and saturation, a novel loss function combining RGB, LAB and LCH color spaces is designed following the human vision principle. The extensive experiments on available datasets validate the state-of-the-art performance of the reported technique with more than 2dB superiority.
A Perturbation Resistant Transformation and Classification System for Deep Neural Networks
Aug 25, 2022



Deep convolutional neural networks accurately classify a diverse range of natural images, but may be easily deceived when designed, imperceptible perturbations are embedded in the images. In this paper, we design a multi-pronged training, input transformation, and image ensemble system that is attack agnostic and not easily estimated. Our system incorporates two novel features. The first is a transformation layer that computes feature level polynomial kernels from class-level training data samples and iteratively updates input image copies at inference time based on their feature kernel differences to create an ensemble of transformed inputs. The second is a classification system that incorporates the prediction of the undefended network with a hard vote on the ensemble of filtered images. Our evaluations on the CIFAR10 dataset show our system improves the robustness of an undefended network against a variety of bounded and unbounded white-box attacks under different distance metrics, while sacrificing little accuracy on clean images. Against adaptive full-knowledge attackers creating end-to-end attacks, our system successfully augments the existing robustness of adversarially trained networks, for which our methods are most effectively applied.
Graph Spatio-Spectral Total Variation Model for Hyperspectral Image Denoising
Jul 22, 2022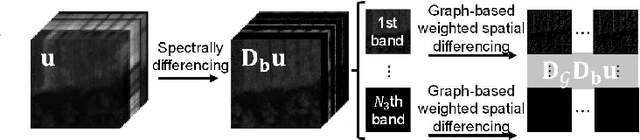


The spatio-spectral total variation (SSTV) model has been widely used as an effective regularization of hyperspectral images (HSI) for various applications such as mixed noise removal. However, since SSTV computes local spatial differences uniformly, it is difficult to remove noise while preserving complex spatial structures with fine edges and textures, especially in situations of high noise intensity. To solve this problem, we propose a new TV-type regularization called Graph-SSTV (GSSTV), which generates a graph explicitly reflecting the spatial structure of the target HSI from noisy HSIs and incorporates a weighted spatial difference operator designed based on this graph. Furthermore, we formulate the mixed noise removal problem as a convex optimization problem involving GSSTV and develop an efficient algorithm based on the primal-dual splitting method to solve this problem. Finally, we demonstrate the effectiveness of GSSTV compared with existing HSI regularization models through experiments on mixed noise removal. The source code will be available at https://www.mdi.c.titech.ac.jp/publications/gsstv.
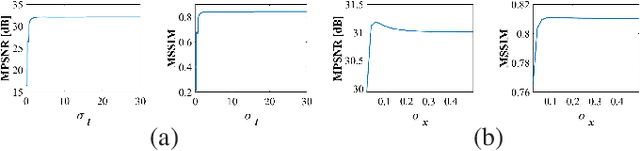
MT-UDA: Towards Unsupervised Cross-modality Medical Image Segmentation with Limited Source Labels
Mar 23, 2022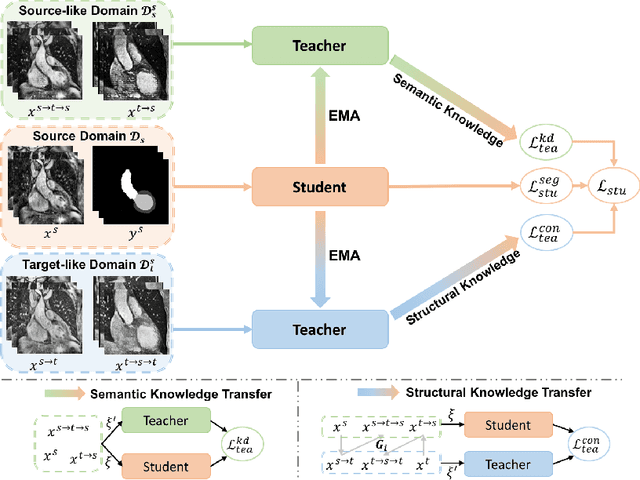
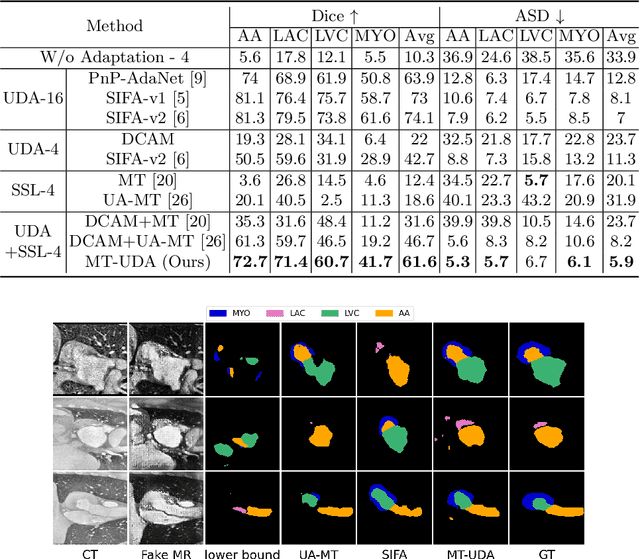
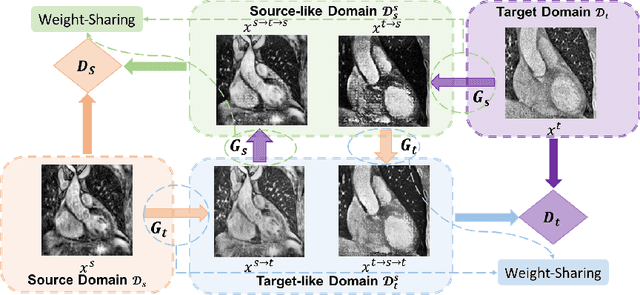
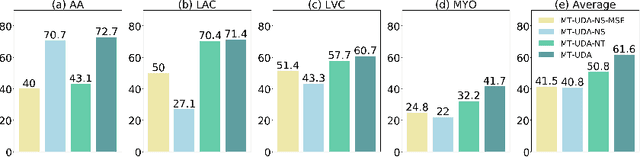
The success of deep convolutional neural networks (DCNNs) benefits from high volumes of annotated data. However, annotating medical images is laborious, expensive, and requires human expertise, which induces the label scarcity problem. Especially when encountering the domain shift, the problem becomes more serious. Although deep unsupervised domain adaptation (UDA) can leverage well-established source domain annotations and abundant target domain data to facilitate cross-modality image segmentation and also mitigate the label paucity problem on the target domain, the conventional UDA methods suffer from severe performance degradation when source domain annotations are scarce. In this paper, we explore a challenging UDA setting - limited source domain annotations. We aim to investigate how to efficiently leverage unlabeled data from the source and target domains with limited source annotations for cross-modality image segmentation. To achieve this, we propose a new label-efficient UDA framework, termed MT-UDA, in which the student model trained with limited source labels learns from unlabeled data of both domains by two teacher models respectively in a semi-supervised manner. More specifically, the student model not only distills the intra-domain semantic knowledge by encouraging prediction consistency but also exploits the inter-domain anatomical information by enforcing structural consistency. Consequently, the student model can effectively integrate the underlying knowledge beneath available data resources to mitigate the impact of source label scarcity and yield improved cross-modality segmentation performance. We evaluate our method on MM-WHS 2017 dataset and demonstrate that our approach outperforms the state-of-the-art methods by a large margin under the source-label scarcity scenario.
* Accept by MICCAI 2021, code at: https://github.com/jacobzhaoziyuan/MT-UDA
Using Image Transformations to Learn Network Structure
Dec 06, 2021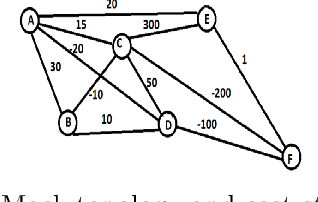
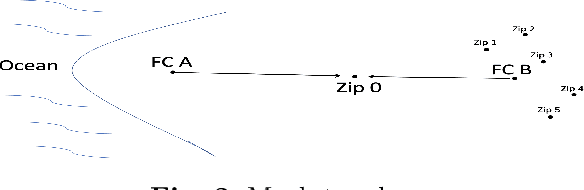
Many learning tasks require observing a sequence of images and making a decision. In a transportation problem of designing and planning for shipping boxes between nodes, we show how to treat the network of nodes and the flows between them as images. These images have useful structural information that can be statistically summarized. Using image compression techniques, we reduce an image down to a set of numbers that contain interpretable geographic information that we call geographic signatures. Using geographic signatures, we learn network structure that can be utilized to recommend future network connectivity. We develop a Bayesian reinforcement algorithm that takes advantage of statistically summarized network information as priors and user-decisions to reinforce an agent's probabilistic decision.