 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blind Image Decomposition
Aug 28, 2021

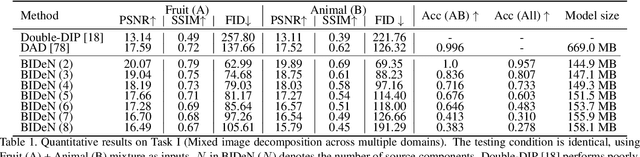
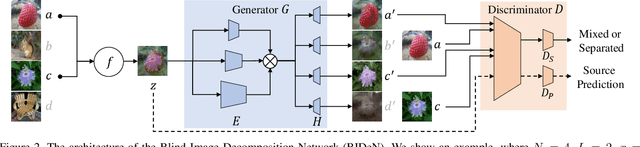

We present and study a novel task named Blind Image Decomposition (BID), which requires separating a superimposed image into constituent underlying images in a blind setting, that is, both the source components involved in mixing as well as the mixing mechanism are unknown. For example, rain may consist of multiple components, such as rain streaks, raindrops, snow, and haze. Rainy images can be treated as an arbitrary combination of these components, some of them or all of them. How to decompose superimposed images, like rainy images, into distinct source components is a crucial step towards real-world vision systems. To facilitate research on this new task, we construct three benchmark datasets, including mixed image decomposition across multiple domains, real-scenario deraining, and joint shadow/reflection/watermark removal. Moreover, we propose a simple yet general Blind Image Decomposition Network (BIDeN) to serve as a strong baseline for future work. Experimental results demonstrate the tenability of our benchmarks and the effectiveness of BIDeN. Code and project page are available.
GANSeg: Learning to Segment by Unsupervised Hierarchical Image Generation
Dec 02, 2021
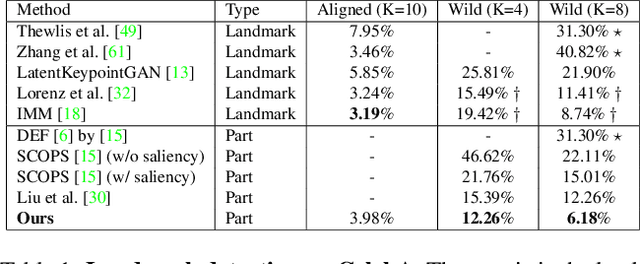
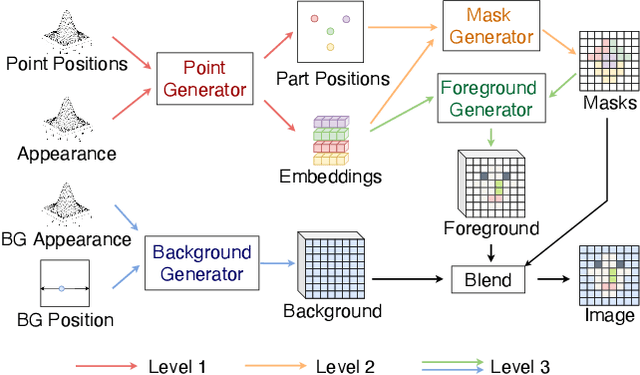
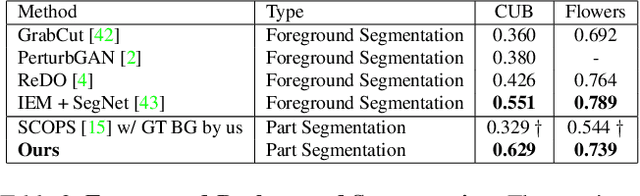
Segmenting an image into its parts is a frequent preprocess for high-level vision tasks such as image editing. However, annotating masks for supervised training is expensive. Weakly-supervised and unsupervised methods exist, but they depend on the comparison of pairs of images, such as from multi-views, frames of videos, and image transformations of single images, which limits their applicability. To address this, we propose a GAN-based approach that generates images conditioned on latent masks, thereby alleviating full or weak annotations required in previous approaches. We show that such mask-conditioned image generation can be learned faithfully when conditioning the masks in a hierarchical manner on latent keypoints that define the position of parts explicitly. Without requiring supervision of masks or points, this strategy increases robustness to viewpoint and object positions changes. It also lets us generate image-mask pairs for training a segmentation network, which outperforms the state-of-the-art unsupervised segmentation methods on established benchmarks.
FCDSN-DC: An Accurate and Lightweight Convolutional Neural Network for Stereo Estimation with Depth Completion
Sep 14, 2022



We propose an accurate and lightweight convolutional neural network for stereo estimation with depth completion. We name this method fully-convolutional deformable similarity network with depth completion (FCDSN-DC). This method extends FC-DCNN by improving the feature extractor, adding a network structure for training highly accurate similarity functions and a network structure for filling inconsistent disparity estimates. The whole method consists of three parts. The first part consists of fully-convolutional densely connected layers that computes expressive features of rectified image pairs. The second part of our network learns highly accurate similarity functions between this learned features. It consists of densely-connected convolution layers with a deformable convolution block at the end to further improve the accuracy of the results. After this step an initial disparity map is created and the left-right consistency check is performed in order to remove inconsistent points. The last part of the network then uses this input together with the corresponding left RGB image in order to train a network that fills in the missing measurements. Consistent depth estimations are gathered around invalid points and are parsed together with the RGB points into a shallow CNN network structure in order to recover the missing values. We evaluate our method on challenging real world indoor and outdoor scenes, in particular Middlebury, KITTI and ETH3D were it produces competitive results. We furthermore show that this method generalizes well and is well suited for many applications without the need of further training. The code of our full framework is available at: https://github.com/thedodo/FCDSN-DC
Prediction method of Soundscape Impressions using Environmental Sounds and Aerial Photographs
Sep 09, 2022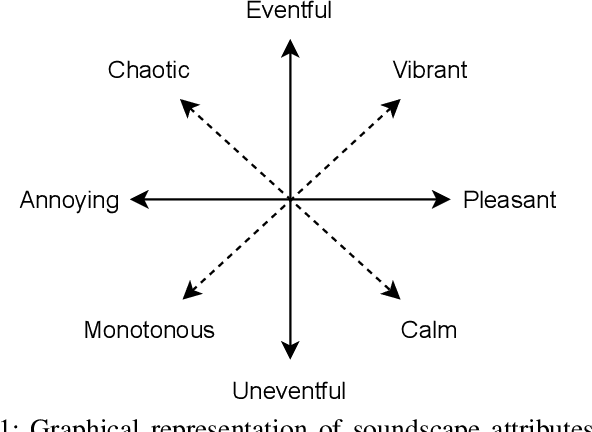
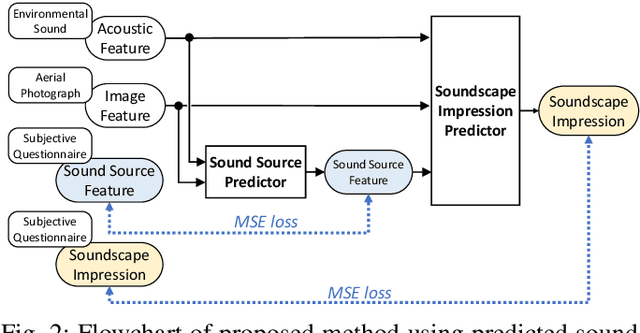

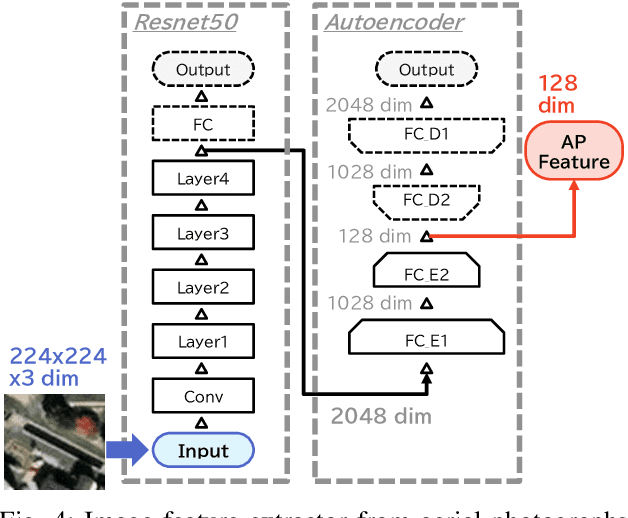
We investigate an method for quantifying city characteristics based on impressions of a sound environment. The quantification of the city characteristics will be beneficial to government policy planning, tourism projects, etc. In this study, we try to predict two soundscape impressions, meaning pleasantness and eventfulness, using sound data collected by the cloud-sensing method. The collected sounds comprise meta information of recording location using Global Positioning System. Furthermore, the soundscape impressions and sound-source features are separately assigned to the cloud-sensing sounds by assessments defined using Swedish Soundscape-Quality Protocol, assessing the quality of the acoustic environment. The prediction models are built using deep neural networks with multi-layer perceptron for the input of 10-second sound and the aerial photographs of its location. An acoustic feature comprises equivalent noise level and outputs of octave-band filters every second, and statistics of them in 10~s. An image feature is extracted from an aerial photograph using ResNet-50 and autoencoder architecture. We perform comparison experiments to demonstrate the benefit of each feature. As a result of the comparison, aerial photographs and sound-source features are efficient to predict impression information. Additionally, even if the sound-source features are predicted using acoustic and image features, the features also show fine results to predict the soundscape impression close to the result of oracle sound-source features.
Transformer-based Flood Scene Segmentation for Developing Countries
Oct 09, 2022



Floods are large-scale natural disasters that often induce a massive number of deaths, extensive material damage, and economic turmoil. The effects are more extensive and longer-lasting in high-population and low-resource developing countries. Early Warning Systems (EWS) constantly assess water levels and other factors to forecast floods, to help minimize damage. Post-disaster, disaster response teams undertake a Post Disaster Needs Assessment (PDSA) to assess structural damage and determine optimal strategies to respond to highly affected neighbourhoods. However, even today in developing countries, EWS and PDSA analysis of large volumes of image and video data is largely a manual process undertaken by first responders and volunteers. We propose FloodTransformer, which to the best of our knowledge, is the first visual transformer-based model to detect and segment flooded areas from aerial images at disaster sites. We also propose a custom metric, Flood Capacity (FC) to measure the spatial extent of water coverage and quantify the segmented flooded area for EWS and PDSA analyses. We use the SWOC Flood segmentation dataset and achieve 0.93 mIoU, outperforming all other methods. We further show the robustness of this approach by validating across unseen flood images from other flood data sources.
Self-supervised Video Representation Learning with Motion-Aware Masked Autoencoders
Oct 09, 2022
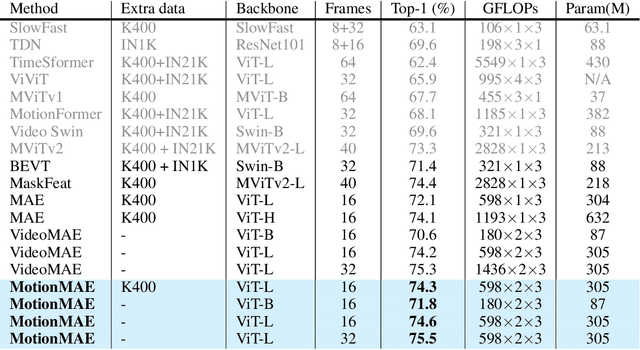
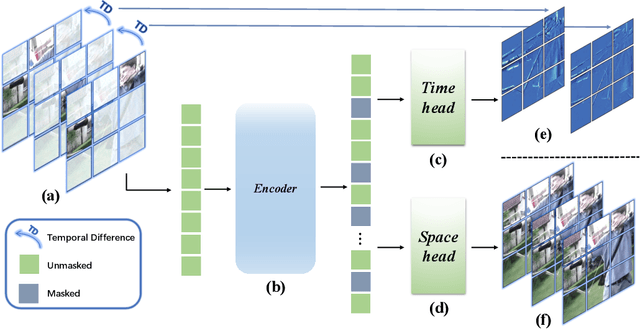
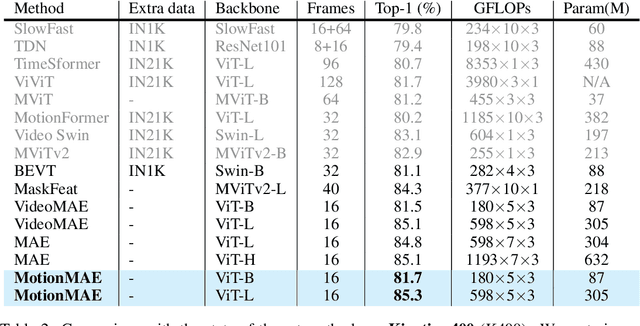
Masked autoencoders (MAEs) have emerged recently as art self-supervised spatiotemporal representation learners. Inheriting from the image counterparts, however, existing video MAEs still focus largely on static appearance learning whilst are limited in learning dynamic temporal information hence less effective for video downstream tasks. To resolve this drawback, in this work we present a motion-aware variant -- MotionMAE. Apart from learning to reconstruct individual masked patches of video frames, our model is designed to additionally predict the corresponding motion structure information over time. This motion information is available at the temporal difference of nearby frames. As a result, our model can extract effectively both static appearance and dynamic motion spontaneously, leading to superior spatiotemporal representation learning capability. Extensive experiments show that our MotionMAE outperforms significantly both supervised learning baseline and state-of-the-art MAE alternatives, under both domain-specific and domain-generic pretraining-then-finetuning settings. In particular, when using ViT-B as the backbone our MotionMAE surpasses the prior art model by a margin of 1.2% on Something-Something V2 and 3.2% on UCF101 in domain-specific pretraining setting. Encouragingly, it also surpasses the competing MAEs by a large margin of over 3% on the challenging video object segmentation task. The code is available at https://github.com/happy-hsy/MotionMAE.
Tiered Pruning for Efficient Differentialble Inference-Aware Neural Architecture Search
Sep 23, 2022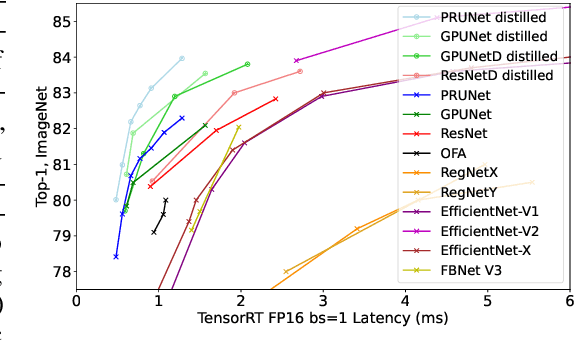
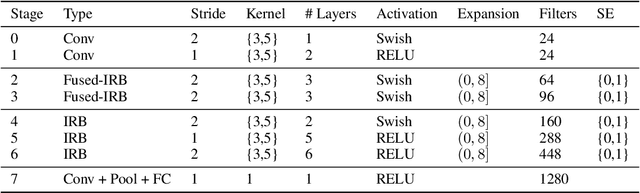
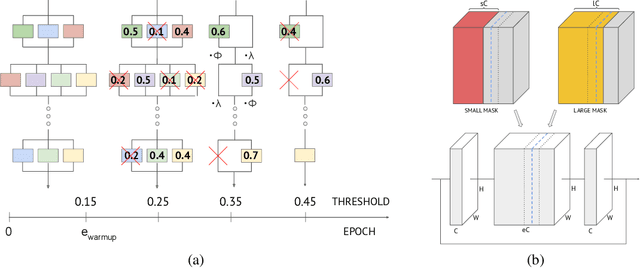
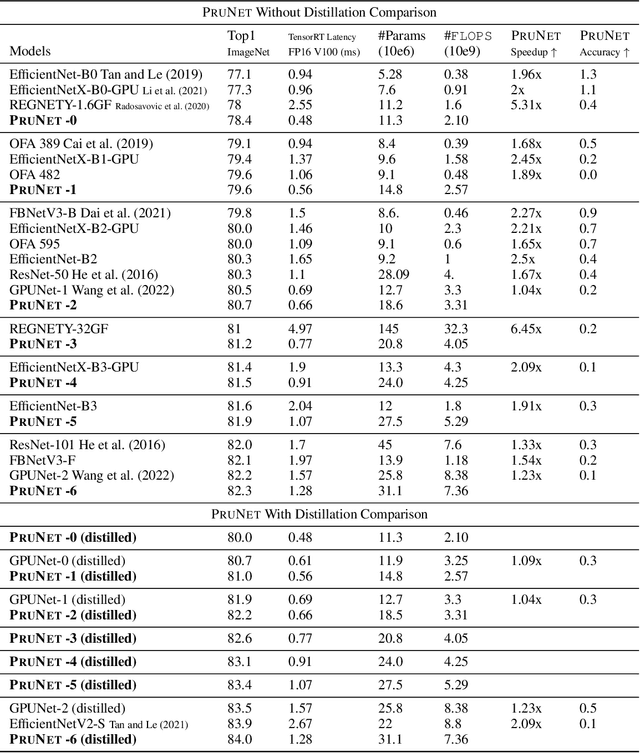
We propose three novel pruning techniques to improve the cost and results of inference-aware Differentiable Neural Architecture Search (DNAS). First, we introduce , a stochastic bi-path building block for DNAS, which can search over inner hidden dimensions with memory and compute complexity. Second, we present an algorithm for pruning blocks within a stochastic layer of the SuperNet during the search. Third, we describe a novel technique for pruning unnecessary stochastic layers during the search. The optimized models resulting from the search are called PruNet and establishes a new state-of-the-art Pareto frontier for NVIDIA V100 in terms of inference latency for ImageNet Top-1 image classification accuracy. PruNet as a backbone also outperforms GPUNet and EfficientNet on the COCO object detection task on inference latency relative to mean Average Precision (mAP).
Composition and Style Attributes Guided Image Aesthetic Assessment
Nov 08, 2021
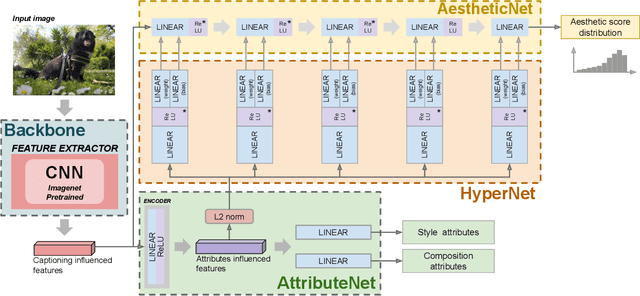

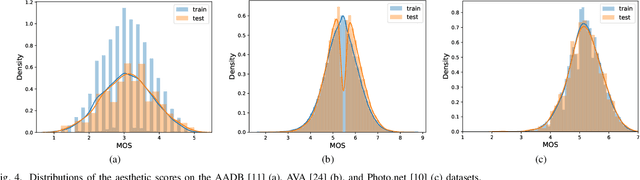
The aesthetic quality of an image is defined as the measure or appreciation of the beauty of an image. Aesthetics is inherently a subjective property but there are certain factors that influence it such as, the semantic content of the image, the attributes describing the artistic aspect, the photographic setup used for the shot, etc. In this paper we propose a method for the automatic prediction of the aesthetics of an image that is based on the analysis of the semantic content, the artistic style and the composition of the image. The proposed network includes: a pre-trained network for semantic features extraction (the Backbone); a Multi Layer Perceptron (MLP) network that relies on the Backbone features for the prediction of image attributes (the AttributeNet); a self-adaptive Hypernetwork that exploits the attributes prior encoded into the embedding generated by the AttributeNet to predict the parameters of the target network dedicated to aesthetic estimation (the AestheticNet). Given an image, the proposed multi-network is able to predict: style and composition attributes, and aesthetic score distribution. Results on three benchmark datasets demonstrate the effectiveness of the proposed method, while the ablation study gives a better understanding of the proposed network.
PS-NeRV: Patch-wise Stylized Neural Representations for Videos
Aug 07, 2022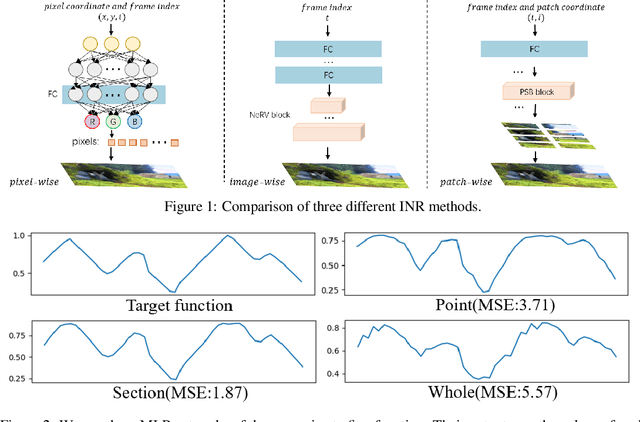
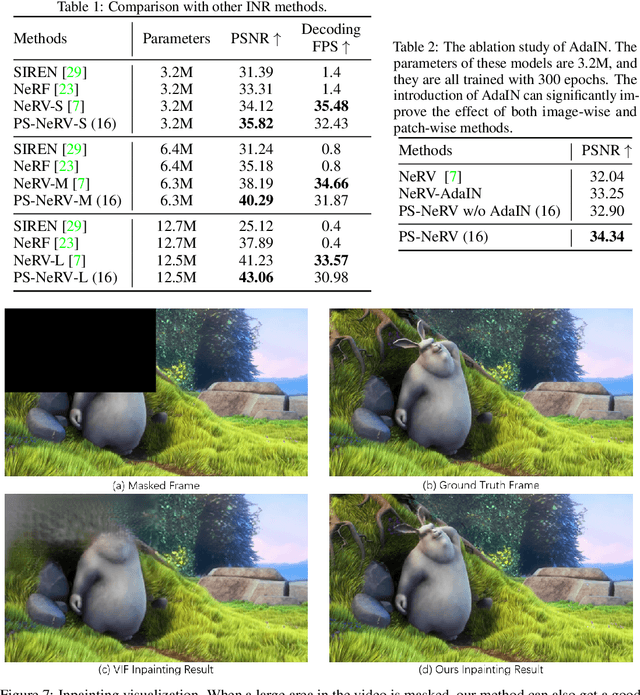
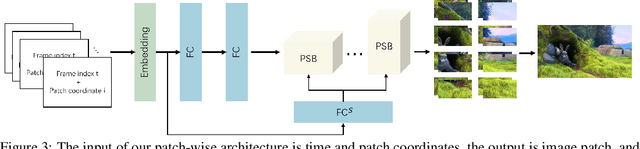
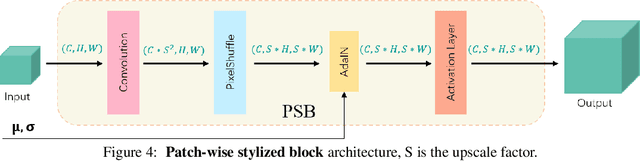
We study how to represent a video with implicit neural representations (INRs). Classical INRs methods generally utilize MLPs to map input coordinates to output pixels. While some recent works have tried to directly reconstruct the whole image with CNNs. However, we argue that both the above pixel-wise and image-wise strategies are not favorable to video data. Instead, we propose a patch-wise solution, PS-NeRV, which represents videos as a function of patches and the corresponding patch coordinate. It naturally inherits the advantages of image-wise methods, and achieves excellent reconstruction performance with fast decoding speed. The whole method includes conventional modules, like positional embedding, MLPs and CNNs, while also introduces AdaIN to enhance intermediate features. These simple yet essential changes could help the network easily fit high-frequency details. Extensive experiments have demonstrated its effectiveness in several video-related tasks, such as video compression and video inpainting.
A Simple Approach to Adversarial Robustness in Few-shot Image Classification
Apr 11, 2022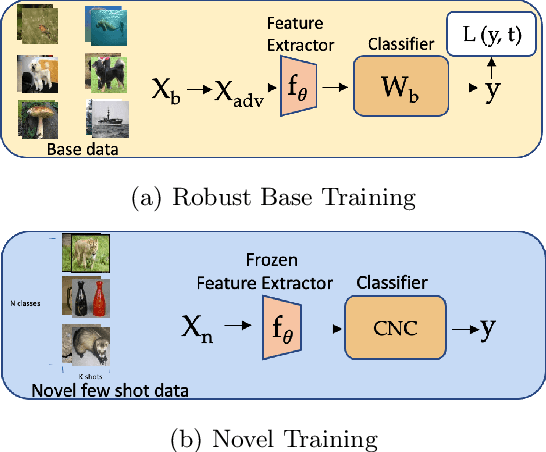
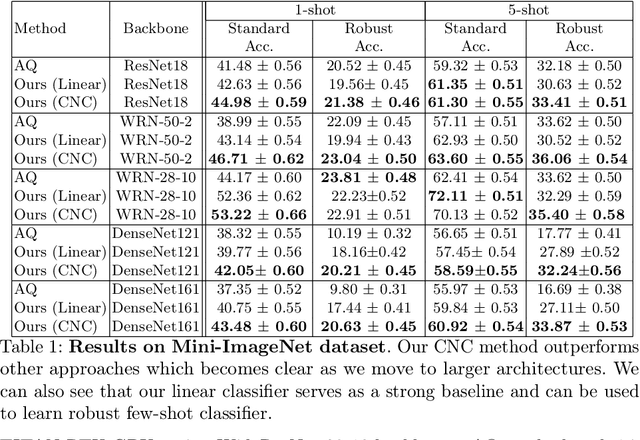
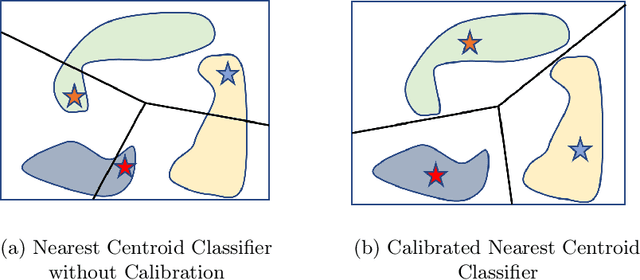
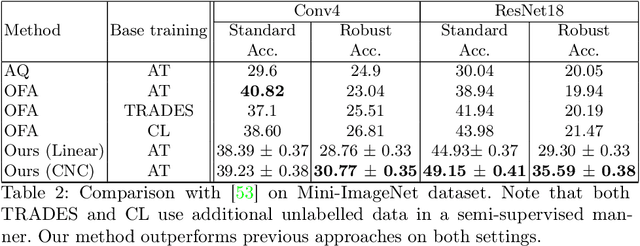
Few-shot image classification, where the goal is to generalize to tasks with limited labeled data, has seen great progress over the years. However, the classifiers are vulnerable to adversarial examples, posing a question regarding their generalization capabilities. Recent works have tried to combine meta-learning approaches with adversarial training to improve the robustness of few-shot classifiers. We show that a simple transfer-learning based approach can be used to train adversarially robust few-shot classifiers. We also present a method for novel classification task based on calibrating the centroid of the few-shot category towards the base classes. We show that standard adversarial training on base categories along with calibrated centroid-based classifier in the novel categories, outperforms or is on-par with state-of-the-art advanced methods on standard benchmarks for few-shot learning. Our method is simple, easy to scale, and with little effort can lead to robust few-shot classifiers. Code is available here: \url{https://github.com/UCDvision/Simple_few_shot.git}