 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition
Dec 13, 2021
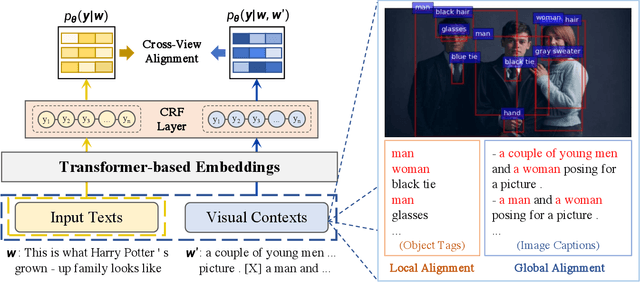
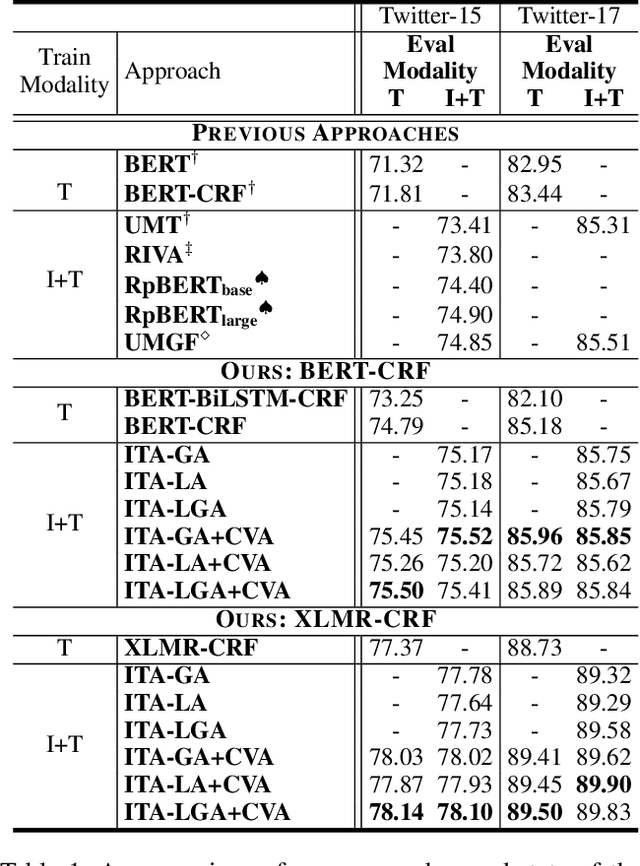
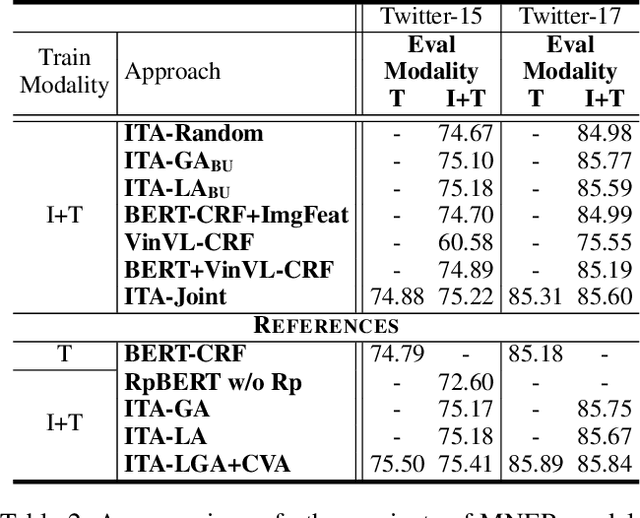
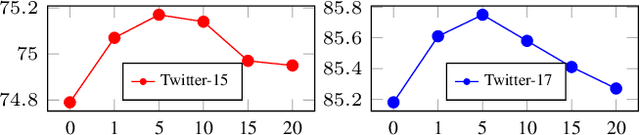
Recently, Multi-modal Named Entity Recognition (MNER) has attracted a lot of attention. Most of the work utilizes image information through region-level visual representations obtained from a pretrained object detector and relies on an attention mechanism to model the interactions between image and text representations. However, it is difficult to model such interactions as image and text representations are trained separately on the data of their respective modality and are not aligned in the same space. As text representations take the most important role in MNER, in this paper, we propose {\bf I}mage-{\bf t}ext {\bf A}lignments (ITA) to align image features into the textual space, so that the attention mechanism in transformer-based pretrained textual embeddings can be better utilized. ITA first locally and globally aligns regional object tags and image-level captions as visual contexts, concatenates them with the input texts as a new cross-modal input, and then feeds it into a pretrained textual embedding model. This makes it easier for the attention module of a pretrained textual embedding model to model the interaction between the two modalities since they are both represented in the textual space. ITA further aligns the output distributions predicted from the cross-modal input and textual input views so that the MNER model can be more practical and robust to noises from images. In our experiments, we show that ITA models can achieve state-of-the-art accuracy on multi-modal Named Entity Recognition datasets, even without image information.
Spikformer: When Spiking Neural Network Meets Transformer
Sep 29, 2022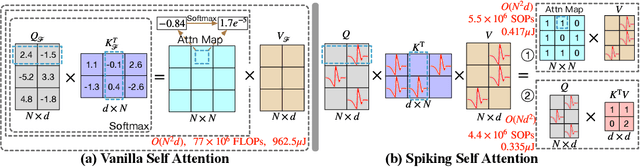
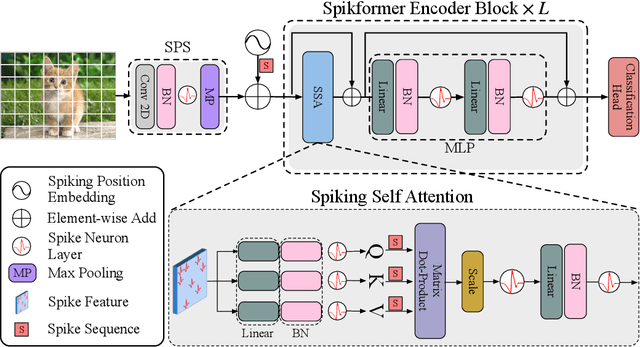
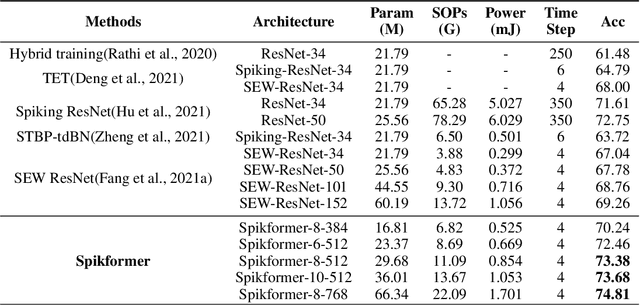
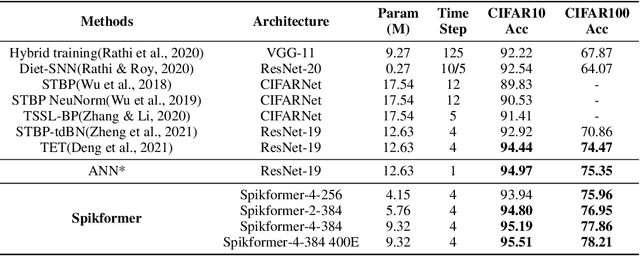
We consider two biologically plausible structures, the Spiking Neural Network (SNN) and the self-attention mechanism. The former offers an energy-efficient and event-driven paradigm for deep learning, while the latter has the ability to capture feature dependencies, enabling Transformer to achieve good performance. It is intuitively promising to explore the marriage between them. In this paper, we consider leveraging both self-attention capability and biological properties of SNNs, and propose a novel Spiking Self Attention (SSA) as well as a powerful framework, named Spiking Transformer (Spikformer). The SSA mechanism in Spikformer models the sparse visual feature by using spike-form Query, Key, and Value without softmax. Since its computation is sparse and avoids multiplication, SSA is efficient and has low computational energy consumption. It is shown that Spikformer with SSA can outperform the state-of-the-art SNNs-like frameworks in image classification on both neuromorphic and static datasets. Spikformer (66.3M parameters) with comparable size to SEW-ResNet-152 (60.2M,69.26%) can achieve 74.81% top1 accuracy on ImageNet using 4 time steps, which is the state-of-the-art in directly trained SNNs models.
Deep Cervix Model Development from Heterogeneous and Partially Labeled Image Datasets
Jan 18, 2022Cervical cancer is the fourth most common cancer in women worldwide. The availability of a robust automated cervical image classification system can augment the clinical care provider's limitation in traditional visual inspection with acetic acid (VIA). However, there are a wide variety of cervical inspection objectives which impact the labeling criteria for criteria-specific prediction model development. Moreover, due to the lack of confirmatory test results and inter-rater labeling variation, many images are left unlabeled. Motivated by these challenges, we propose a self-supervised learning (SSL) based approach to produce a pre-trained cervix model from unlabeled cervical images. The developed model is further fine-tuned to produce criteria-specific classification models with the available labeled images. We demonstrate the effectiveness of the proposed approach using two cervical image datasets. Both datasets are partially labeled and labeling criteria are different. The experimental results show that the SSL-based initialization improves classification performance (Accuracy: 2.5% min) and the inclusion of images from both datasets during SSL further improves the performance (Accuracy: 1.5% min). Further, considering data-sharing restrictions, we experimented with the effectiveness of Federated SSL and find that it can improve performance over the SSL model developed with just its images. This justifies the importance of SSL-based cervix model development. We believe that the present research shows a novel direction in developing criteria-specific custom deep models for cervical image classification by combining images from different sources unlabeled and/or labeled with varying criteria, and addressing image access restrictions.
Tunable Image Quality Control of 3-D Ultrasound using Switchable CycleGAN
Dec 06, 2021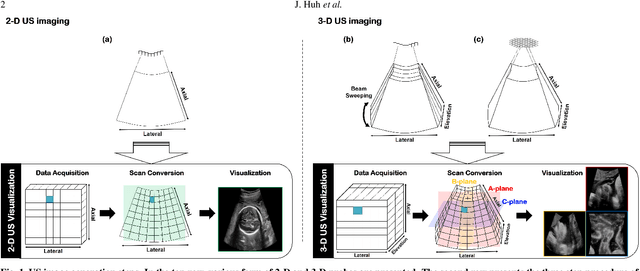
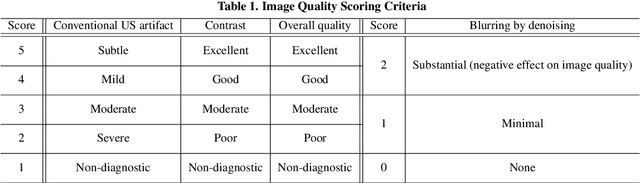
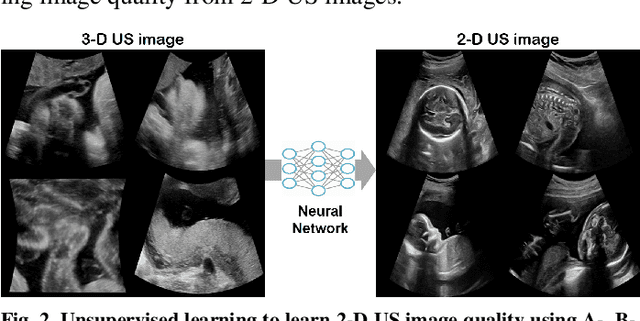
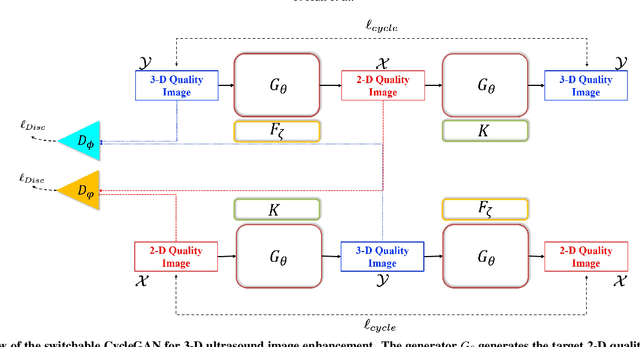
In contrast to 2-D ultrasound (US) for uniaxial plane imaging, a 3-D US imaging system can visualize a volume along three axial planes. This allows for a full view of the anatomy, which is useful for gynecological (GYN) and obstetrical (OB) applications. Unfortunately, the 3-D US has an inherent limitation in resolution compared to the 2-D US. In the case of 3-D US with a 3-D mechanical probe, for example, the image quality is comparable along the beam direction, but significant deterioration in image quality is often observed in the other two axial image planes. To address this, here we propose a novel unsupervised deep learning approach to improve 3-D US image quality. In particular, using {\em unmatched} high-quality 2-D US images as a reference, we trained a recently proposed switchable CycleGAN architecture so that every mapping plane in 3-D US can learn the image quality of 2-D US images. Thanks to the switchable architecture, our network can also provide real-time control of image enhancement level based on user preference, which is ideal for a user-centric scanner setup. Extensive experiments with clinical evaluation confirm that our method offers significantly improved image quality as well user-friendly flexibility.
Rapid dynamic speech imaging at 3 Tesla using combination of a custom vocal tract coil, variable density spirals and manifold regularization
Sep 06, 2022
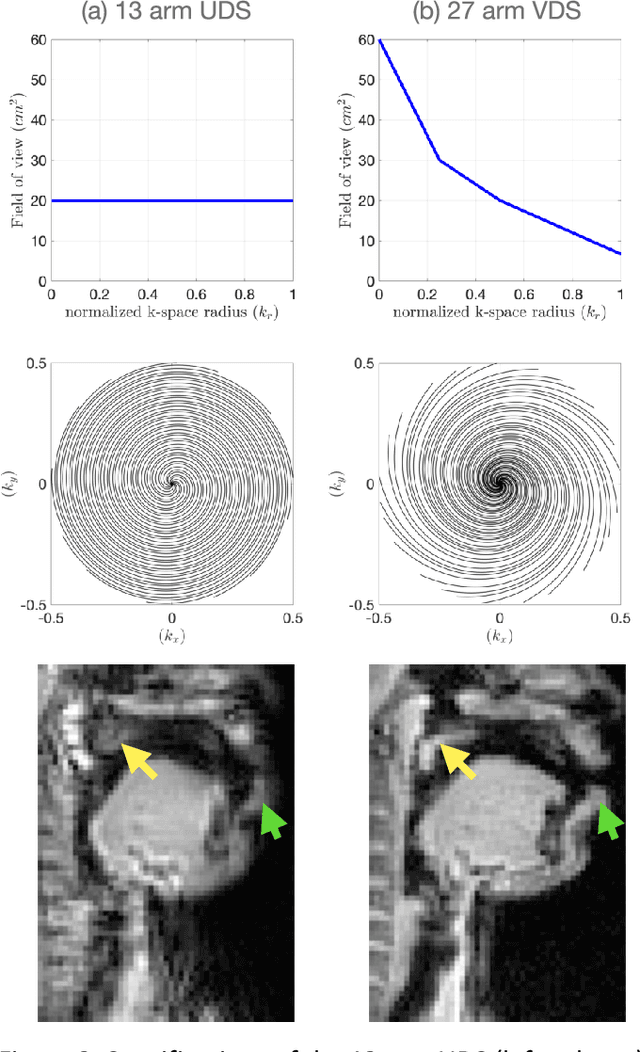
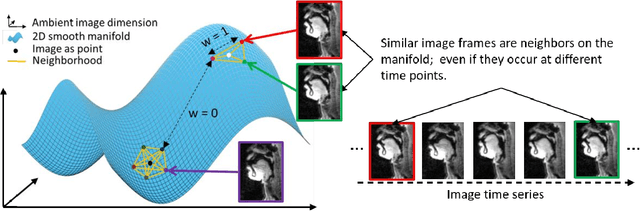
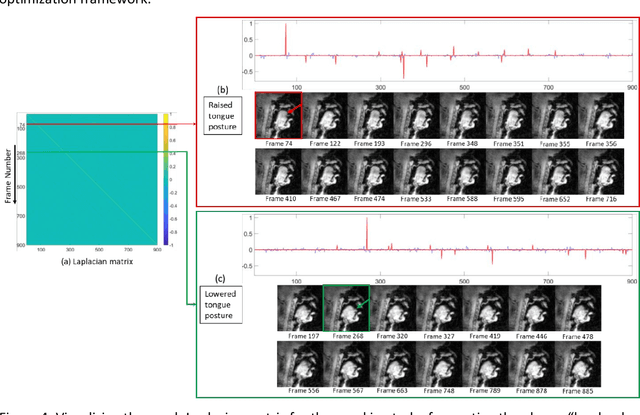
Purpose: To improve dynamic speech imaging at 3 Tesla. Methods: A novel scheme combining a 16-channel vocal tract coil, variable density spirals (VDS), and manifold regularization was developed. Short readout duration spirals (1.3 ms long) were used to minimize sensitivity to off-resonance. The manifold model leveraged similarities between frames sharing similar vocal tract postures without explicit motion binning. Reconstruction was posed as a SENSE-based non-local soft weighted temporal regularization scheme. The self-navigating capability of VDS was leveraged to learn the structure of the manifold. Our approach was compared against low-rank and finite difference reconstruction constraints on two volunteers performing repetitive and arbitrary speaking tasks. Blinded image quality evaluation in the categories of alias artifacts, spatial blurring, and temporal blurring were performed by three experts in voice research. Results: We achieved a spatial resolution of 2.4mm2/pixel and a temporal resolution of 17.4 ms/frame for single slice imaging, and 52.2 ms/frame for concurrent 3-slice imaging. Implicit motion binning of the manifold scheme for both repetitive and fluent speaking tasks was demonstrated. The manifold scheme provided superior fidelity in modeling articulatory motion compared to low rank and temporal finite difference schemes. This was reflected by higher image quality scores in spatial and temporal blurring categories. Our technique exhibited faint alias artifacts, but offered a reduced interquartile range of scores compared to other methods in alias artifact category. Conclusion: Synergistic combination of a custom vocal-tract coil, variable density spirals and manifold regularization enables robust dynamic speech imaging at 3 Tesla.
A State-of-the-art Survey of U-Net in Microscopic Image Analysis: from Simple Usage to Structure Mortification
Feb 14, 2022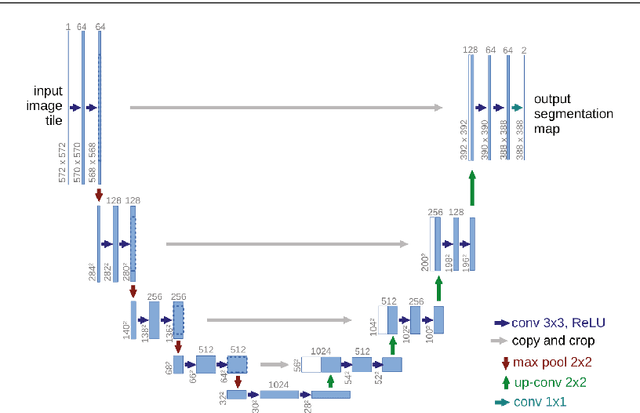
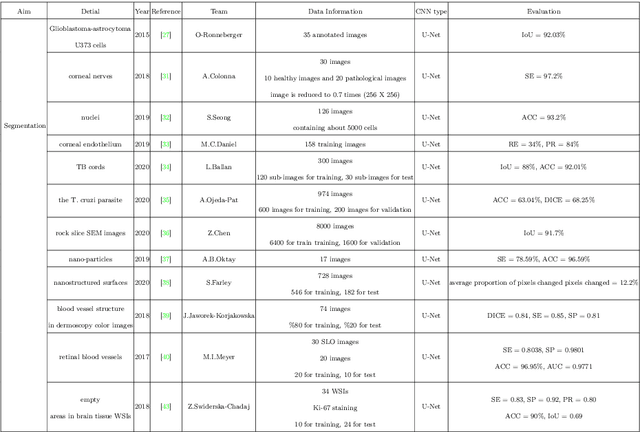
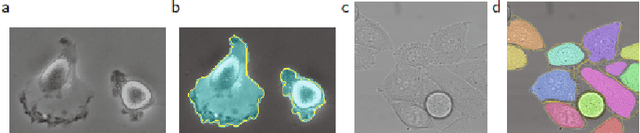
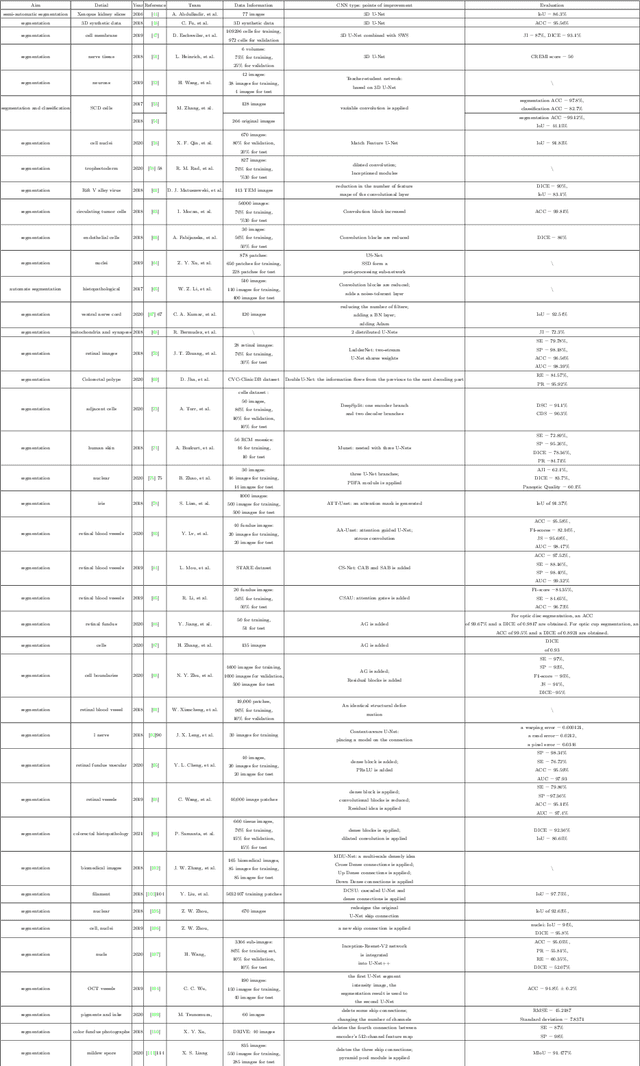
Image analysis technology is used to solve the inadvertences of artificial traditional methods in disease, wastewater treatment, environmental change monitoring analysis and convolutional neural networks (CNN) play an important role in microscopic image analysis. An important step in detection, tracking, monitoring, feature extraction, modeling and analysis is image segmentation, in which U-Net has increasingly applied in microscopic image segmentation. This paper comprehensively reviews the development history of U-Net, and analyzes various research results of various segmentation methods since the emergence of U-Net and conducts a comprehensive review of related papers. First, This paper has summarizes the improved methods of U-Net and then listed the existing significances of image segmentation techniques and their improvements that has introduced over the years. Finally, focusing on the different improvement strategies of U-Net in different papers, the related work of each application target is reviewed according to detailed technical categories to facilitate future research. Researchers can clearly see the dynamics of transmission of technological development and keep up with future trends in this interdisciplinary field.
AutoLC: Search Lightweight and Top-Performing Architecture for Remote Sensing Image Land-Cover Classification
May 11, 2022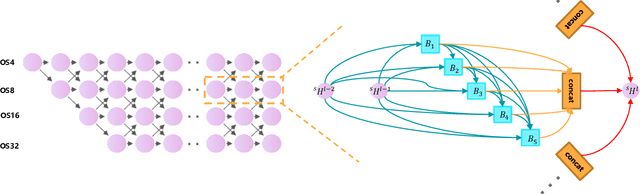
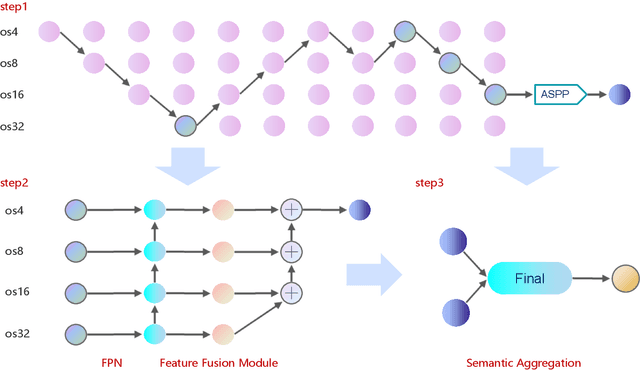
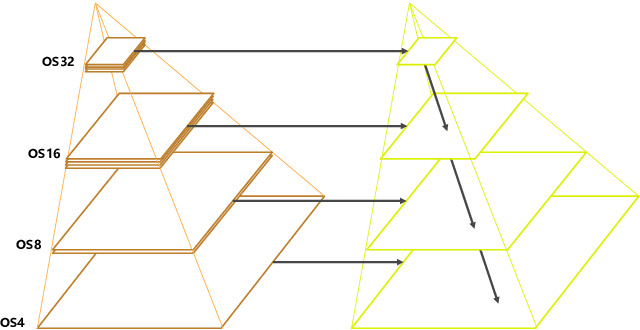

Land-cover classification has long been a hot and difficult challenge in remote sensing community. With massive High-resolution Remote Sensing (HRS) images available, manually and automatically designed Convolutional Neural Networks (CNNs) have already shown their great latent capacity on HRS land-cover classification in recent years. Especially, the former can achieve better performance while the latter is able to generate lightweight architecture. Unfortunately, they both have shortcomings. On the one hand, because manual CNNs are almost proposed for natural image processing, it becomes very redundant and inefficient to process HRS images. On the other hand, nascent Neural Architecture Search (NAS) techniques for dense prediction tasks are mainly based on encoder-decoder architecture, and just focus on the automatic design of the encoder, which makes it still difficult to recover the refined mapping when confronting complicated HRS scenes. To overcome their defects and tackle the HRS land-cover classification problems better, we propose AutoLC which combines the advantages of two methods. First, we devise a hierarchical search space and gain the lightweight encoder underlying gradient-based search strategy. Second, we meticulously design a lightweight but top-performing decoder that is adaptive to the searched encoder of itself. Finally, experimental results on the LoveDA land-cover dataset demonstrate that our AutoLC method outperforms the state-of-art manual and automatic methods with much less computational consumption.
Single MR Image Super-Resolution using Generative Adversarial Network
Jul 16, 2022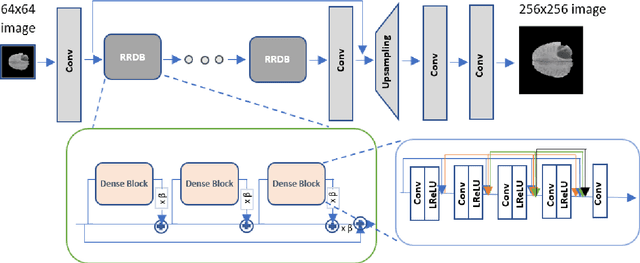
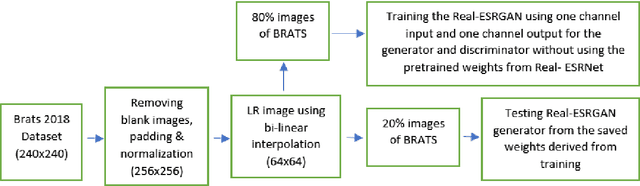

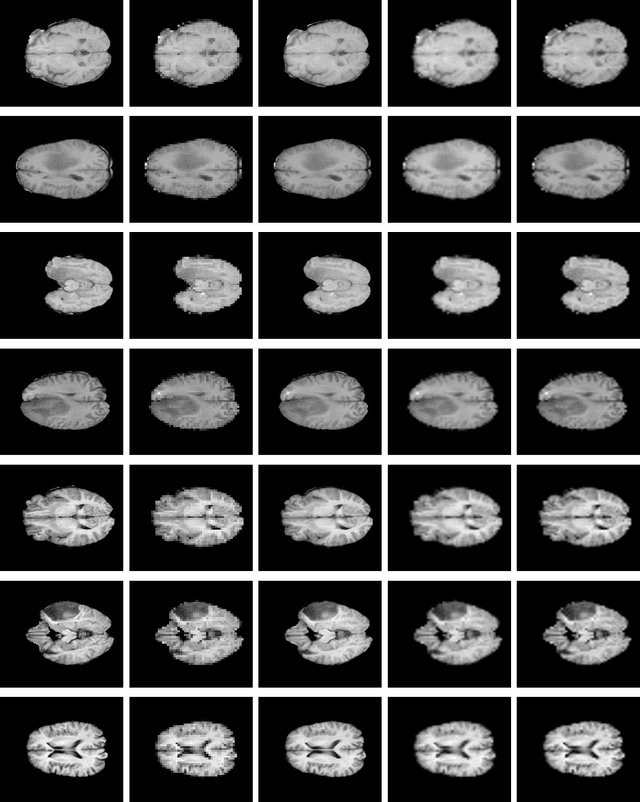
Spatial resolution of medical images can be improved using super-resolution methods. Real Enhanced Super Resolution Generative Adversarial Network (Real-ESRGAN) is one of the recent effective approaches utilized to produce higher resolution images, given input images of lower resolution. In this paper, we apply this method to enhance the spatial resolution of 2D MR images. In our proposed approach, we slightly modify the structure of the Real-ESRGAN to train 2D Magnetic Resonance images (MRI) taken from the Brain Tumor Segmentation Challenge (BraTS) 2018 dataset. The obtained results are validated qualitatively and quantitatively by computing SSIM (Structural Similarity Index Measure), NRMSE (Normalized Root Mean Square Error), MAE (Mean Absolute Error), and VIF (Visual Information Fidelity) values.
Less is More: Rethinking Few-Shot Learning and Recurrent Neural Nets
Sep 28, 2022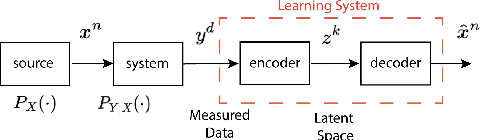



The statistical supervised learning framework assumes an input-output set with a joint probability distribution that is reliably represented by the training dataset. The learner is then required to output a prediction rule learned from the training dataset's input-output pairs. In this work, we provide meaningful insights into the asymptotic equipartition property (AEP) \citep{Shannon:1948} in the context of machine learning, and illuminate some of its potential ramifications for few-shot learning. We provide theoretical guarantees for reliable learning under the information-theoretic AEP, and for the generalization error with respect to the sample size. We then focus on a highly efficient recurrent neural net (RNN) framework and propose a reduced-entropy algorithm for few-shot learning. We also propose a mathematical intuition for the RNN as an approximation of a sparse coding solver. We verify the applicability, robustness, and computational efficiency of the proposed approach with image deblurring and optical coherence tomography (OCT) speckle suppression. Our experimental results demonstrate significant potential for improving learning models' sample efficiency, generalization, and time complexity, that can therefore be leveraged for practical real-time applications.
FD-MAR: Fourier Dual-domain Network for CT Metal Artifact Reduction
Jul 24, 2022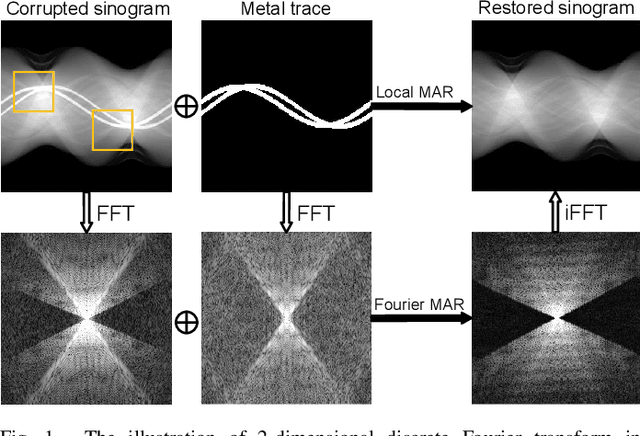
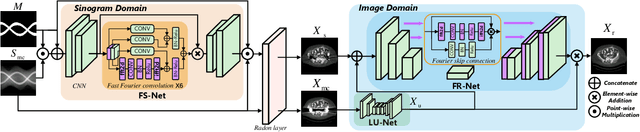
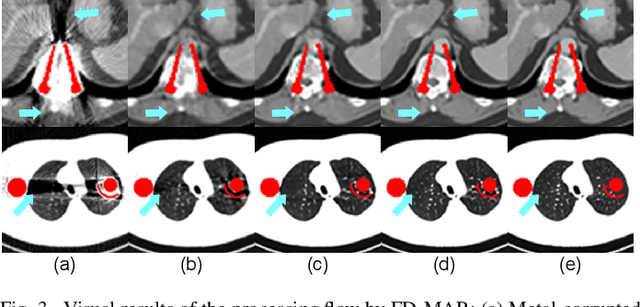
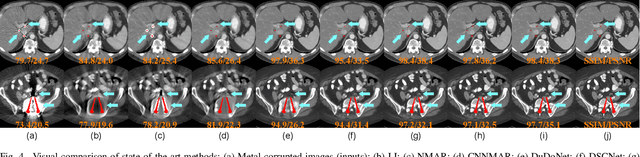
The presence of high-density objects such as metal implants and dental fillings can introduce severely streak-like artifacts in computed tomography (CT) images, greatly limiting subsequent diagnosis. Although various deep neural networks-based methods have been proposed for metal artifact reduction (MAR), they usually suffer from poor performance due to limited exploitation of global context in the sinogram domain, secondary artifacts introduced in the image domain, and the requirement of precise metal masks. To address these issues, this paper explores fast Fourier convolution for MAR in both sinogram and image domains, and proposes a Fourier dual-domain network for MAR, termed FD-MAR. Specifically, we first propose a Fourier sinogram restoration network, which can leverage sinogram-wide receptive context to fill in the metal-corrupted region from uncorrupted region and, hence, is robust to the metal trace. Second, we propose a Fourier refinement network in the image domain, which can refine the reconstructed images in a local-to-global manner by exploring image-wide context information. As a result, the proposed FD-MAR can explore the sinogram- and image-wide receptive fields for MAR. By optimizing FD-MAR with a composite loss function, extensive experimental results demonstrate the superiority of the proposed FD-MAR over the state-of-the-art MAR methods in terms of quantitative metrics and visual comparison. Notably, FD-MAR does not require precise metal masks, which is of great importance in clinical routine.