 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BVI-VFI: A Video Quality Database for Video Frame Interpolation
Oct 06, 2022


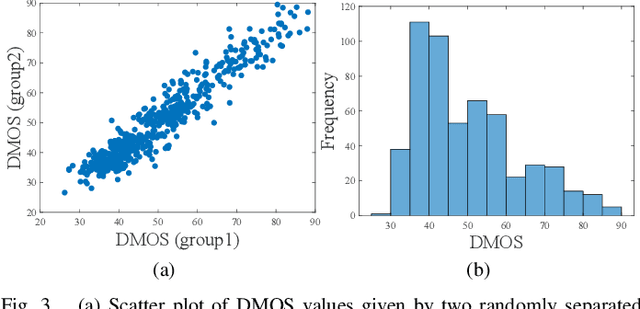
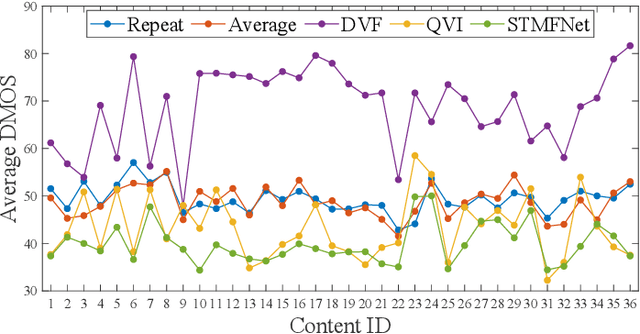
Video frame interpolation (VFI) is a fundamental research topic in video processing, which is currently attracting increased attention across the research community. While the development of more advanced VFI algorithms has been extensively researched, there remains little understanding of how humans perceive the quality of interpolated content and how well existing objective quality assessment methods perform when measuring the perceived quality. In order to narrow this research gap, we have developed a new video quality database named BVI-VFI, which contains 540 distorted sequences generated by applying five commonly used VFI algorithms to 36 diverse source videos with various spatial resolutions and frame rates. We collected more than 10,800 quality ratings for these videos through a large scale subjective study involving 189 human subjects. Based on the collected subjective scores, we further analysed the influence of VFI algorithms and frame rates on the perceptual quality of interpolated videos. Moreover, we benchmarked the performance of 28 classic and state-of-the-art objective image/video quality metrics on the new database, and demonstrated the urgent requirement for more accurate bespoke quality assessment methods for VFI. To facilitate further research in this area, we have made BVI-VFI publicly available at https://github.com/danielism97/BVI-VFI-database.
IDR: Self-Supervised Image Denoising via Iterative Data Refinement
Nov 29, 2021
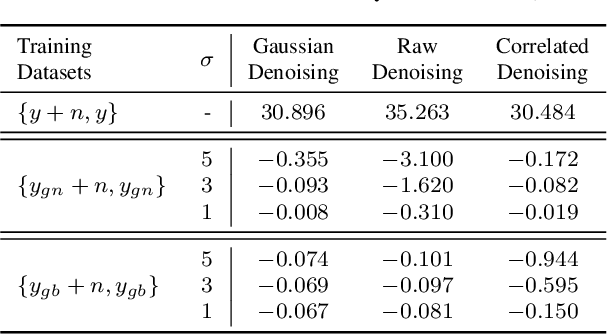
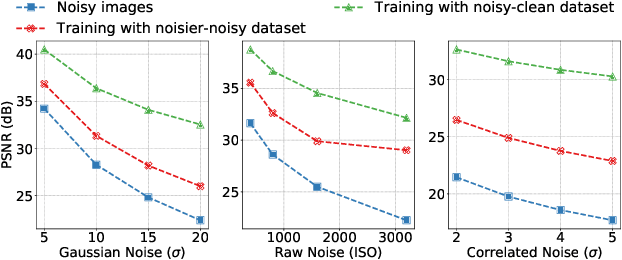
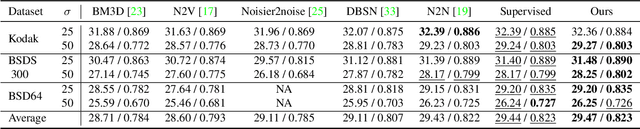
The lack of large-scale noisy-clean image pairs restricts supervised denoising methods' deployment in actual applications. While existing unsupervised methods are able to learn image denoising without ground-truth clean images, they either show poor performance or work under impractical settings (e.g., paired noisy images). In this paper, we present a practical unsupervised image denoising method to achieve state-of-the-art denoising performance. Our method only requires single noisy images and a noise model, which is easily accessible in practical raw image denoising. It performs two steps iteratively: (1) Constructing a noisier-noisy dataset with random noise from the noise model; (2) training a model on the noisier-noisy dataset and using the trained model to refine noisy images to obtain the targets used in the next round. We further approximate our full iterative method with a fast algorithm for more efficient training while keeping its original high performance. Experiments on real-world, synthetic, and correlated noise show that our proposed unsupervised denoising approach has superior performances over existing unsupervised methods and competitive performance with supervised methods. In addition, we argue that existing denoising datasets are of low quality and contain only a small number of scenes. To evaluate raw image denoising performance in real-world applications, we build a high-quality raw image dataset SenseNoise-500 that contains 500 real-life scenes. The dataset can serve as a strong benchmark for better evaluating raw image denoising. Code and dataset will be released at https://github.com/zhangyi-3/IDR
Bias in Automated Image Colorization: Metrics and Error Types
Feb 16, 2022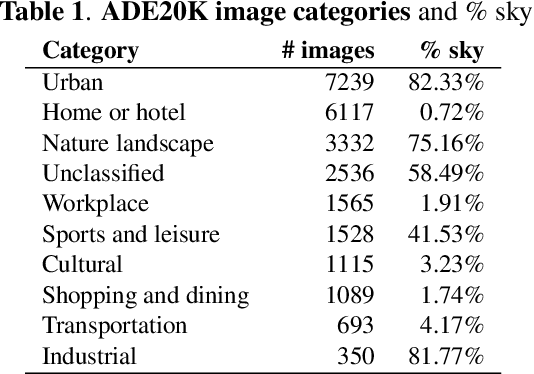
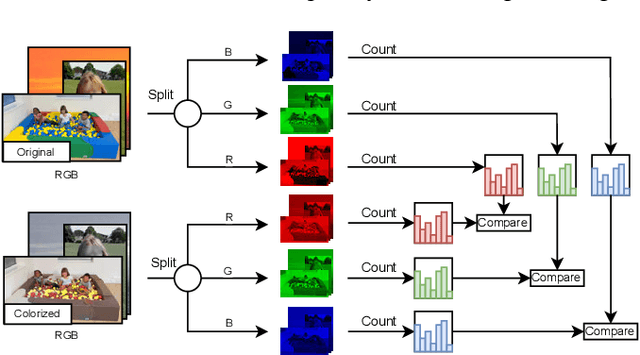
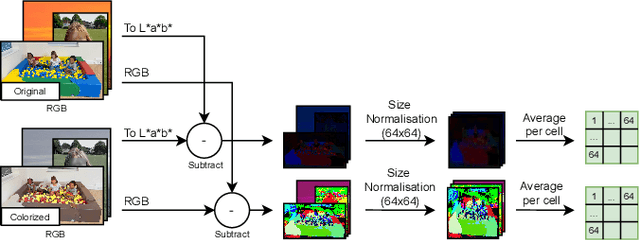
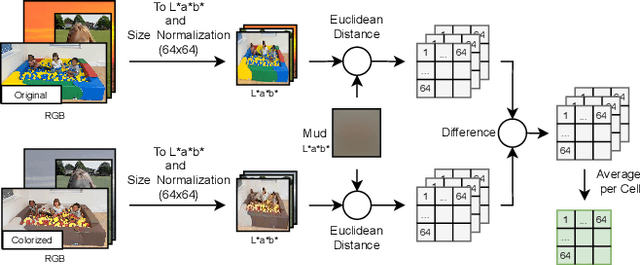
We measure the color shifts present in colorized images from the ADE20K dataset, when colorized by the automatic GAN-based DeOldify model. We introduce fine-grained local and regional bias measurements between the original and the colorized images, and observe many colorization effects. We confirm a general desaturation effect, and also provide novel observations: a shift towards the training average, a pervasive blue shift, different color shifts among image categories, and a manual categorization of colorization errors in three classes.
SIM-STEM Lab: Incorporating Compressed Sensing Theory for Fast STEM Simulation
Jul 22, 2022


Recently it has been shown that precise dose control and an increase in the overall acquisition speed of atomic resolution scanning transmission electron microscope (STEM) images can be achieved by acquiring only a small fraction of the pixels in the image experimentally and then reconstructing the full image using an inpainting algorithm. In this paper, we apply the same inpainting approach (a form of compressed sensing) to simulated, sub-sampled atomic resolution STEM images. We find that it is possible to significantly sub-sample the area that is simulated, the number of g-vectors contributing the image, and the number of frozen phonon configurations contributing to the final image while still producing an acceptable fit to a fully sampled simulation. Here we discuss the parameters that we use and how the resulting simulations can be quantifiably compared to the full simulations. As with any Compressed Sensing methodology, care must be taken to ensure that isolated events are not excluded from the process, but the observed increase in simulation speed provides significant opportunities for real time simulations, image classification and analytics to be performed as a supplement to experiments on a microscope to be developed in the future.
Unsupervised Severely Deformed Mesh Reconstruction (DMR) from a Single-View Image
Jan 23, 2022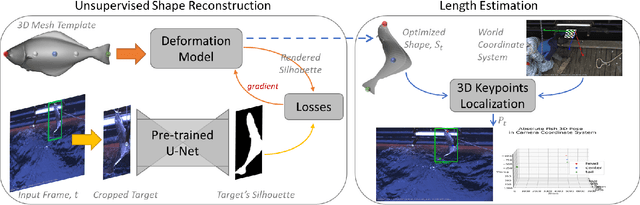
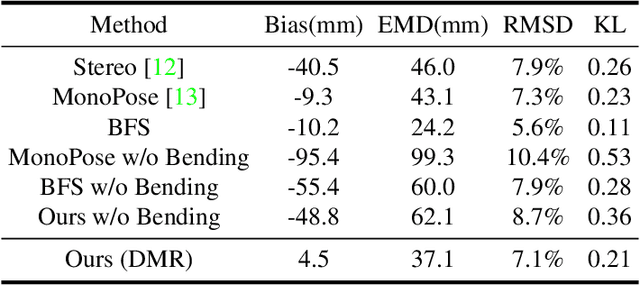

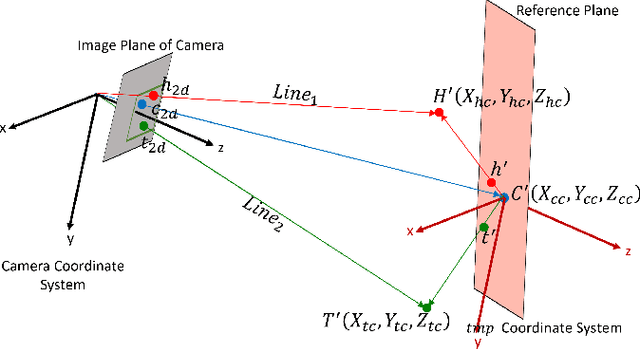
Much progress has been made in the supervised learning of 3D reconstruction of rigid objects from multi-view images or a video. However, it is more challenging to reconstruct severely deformed objects from a single-view RGB image in an unsupervised manner. Although training-based methods, such as specific category-level training, have been shown to successfully reconstruct rigid objects and slightly deformed objects like birds from a single-view image, they cannot effectively handle severely deformed objects and neither can be applied to some downstream tasks in the real world due to the inconsistent semantic meaning of vertices, which are crucial in defining the adopted 3D templates of objects to be reconstructed. In this work, we introduce a template-based method to infer 3D shapes from a single-view image and apply the reconstructed mesh to a downstream task, i.e., absolute length measurement. Without using 3D ground truth, our method faithfully reconstructs 3D meshes and achieves state-of-the-art accuracy in a length measurement task on a severely deformed fish dataset.
ManiFest: Manifold Deformation for Few-shot Image Translation
Nov 26, 2021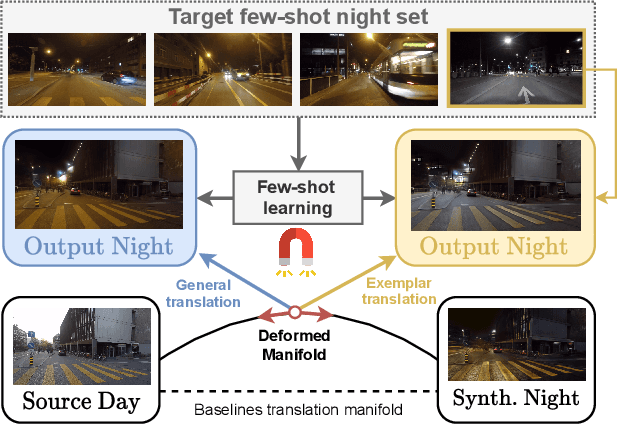
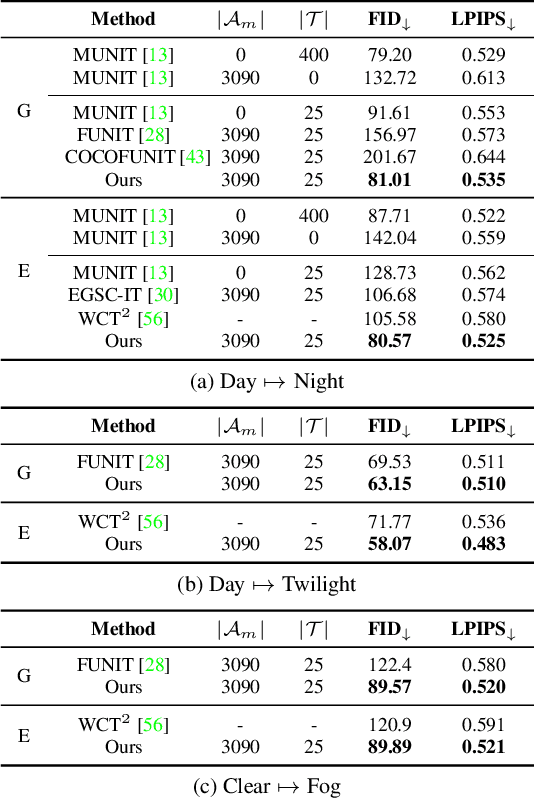
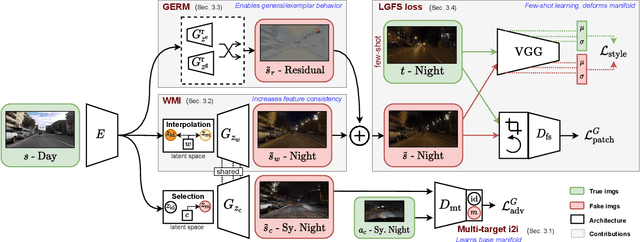
Most image-to-image translation methods require a large number of training images, which restricts their applicability. We instead propose ManiFest: a framework for few-shot image translation that learns a context-aware representation of a target domain from a few images only. To enforce feature consistency, our framework learns a style manifold between source and proxy anchor domains (assumed to be composed of large numbers of images). The learned manifold is interpolated and deformed towards the few-shot target domain via patch-based adversarial and feature statistics alignment losses. All of these components are trained simultaneously during a single end-to-end loop. In addition to the general few-shot translation task, our approach can alternatively be conditioned on a single exemplar image to reproduce its specific style. Extensive experiments demonstrate the efficacy of ManiFest on multiple tasks, outperforming the state-of-the-art on all metrics and in both the general- and exemplar-based scenarios. Our code will be open source.
DIG: Draping Implicit Garment over the Human Body
Sep 24, 2022
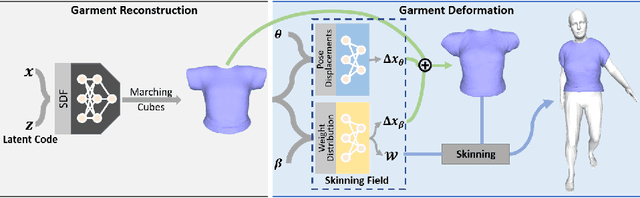

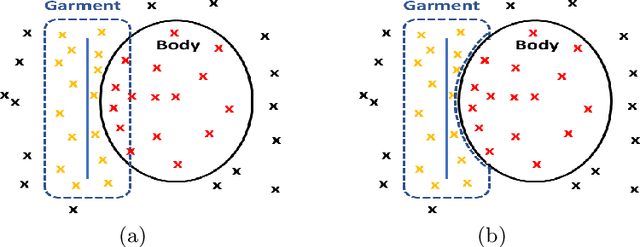
Existing data-driven methods for draping garments over human bodies, despite being effective, cannot handle garments of arbitrary topology and are typically not end-to-end differentiable. To address these limitations, we propose an end-to-end differentiable pipeline that represents garments using implicit surfaces and learns a skinning field conditioned on shape and pose parameters of an articulated body model. To limit body-garment interpenetrations and artifacts, we propose an interpenetration-aware pre-processing strategy of training data and a novel training loss that penalizes self-intersections while draping garments. We demonstrate that our method yields more accurate results for garment reconstruction and deformation with respect to state of the art methods. Furthermore, we show that our method, thanks to its end-to-end differentiability, allows to recover body and garments parameters jointly from image observations, something that previous work could not do.
Improving Multi-fidelity Optimization with a Recurring Learning Rate for Hyperparameter Tuning
Sep 26, 2022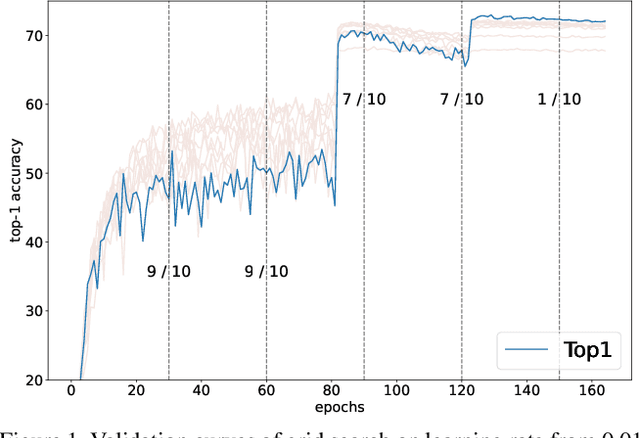
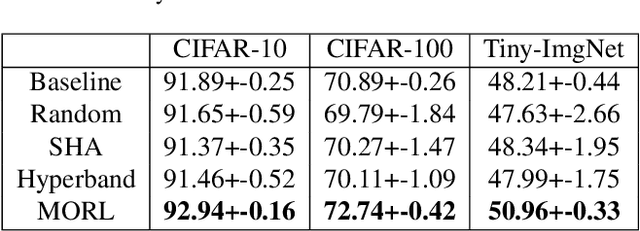
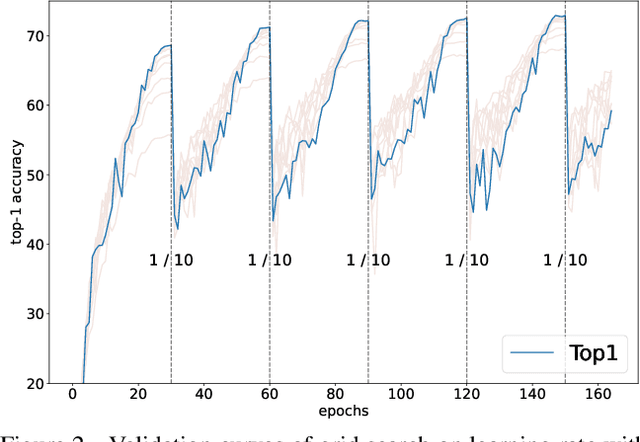
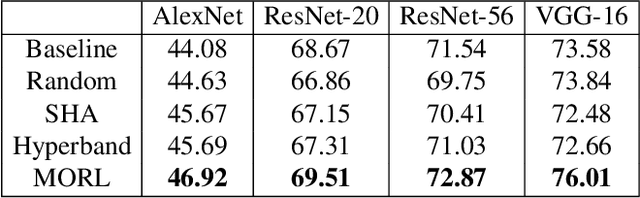
Despite the evolution of Convolutional Neural Networks (CNNs), their performance is surprisingly dependent on the choice of hyperparameters. However, it remains challenging to efficiently explore large hyperparameter search space due to the long training times of modern CNNs. Multi-fidelity optimization enables the exploration of more hyperparameter configurations given budget by early termination of unpromising configurations. However, it often results in selecting a sub-optimal configuration as training with the high-performing configuration typically converges slowly in an early phase. In this paper, we propose Multi-fidelity Optimization with a Recurring Learning rate (MORL) which incorporates CNNs' optimization process into multi-fidelity optimization. MORL alleviates the problem of slow-starter and achieves a more precise low-fidelity approximation. Our comprehensive experiments on general image classification, transfer learning, and semi-supervised learning demonstrate the effectiveness of MORL over other multi-fidelity optimization methods such as Successive Halving Algorithm (SHA) and Hyperband. Furthermore, it achieves significant performance improvements over hand-tuned hyperparameter configuration within a practical budget.
Surrogate-based cross-correlation for particle image velocimetry
Dec 10, 2021
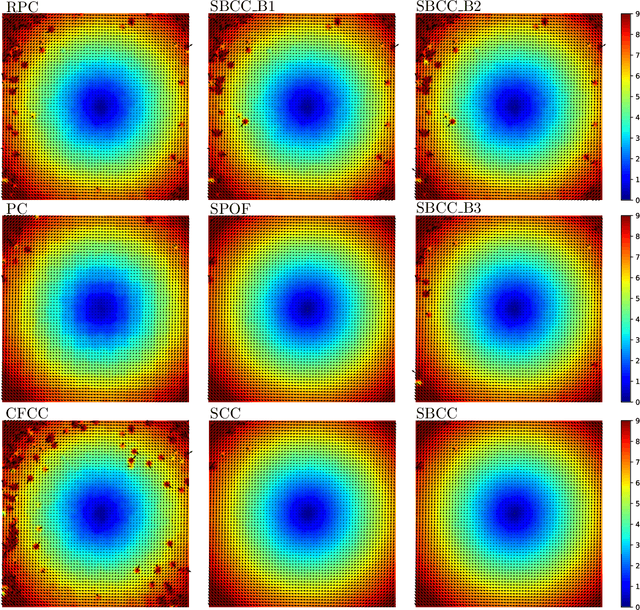
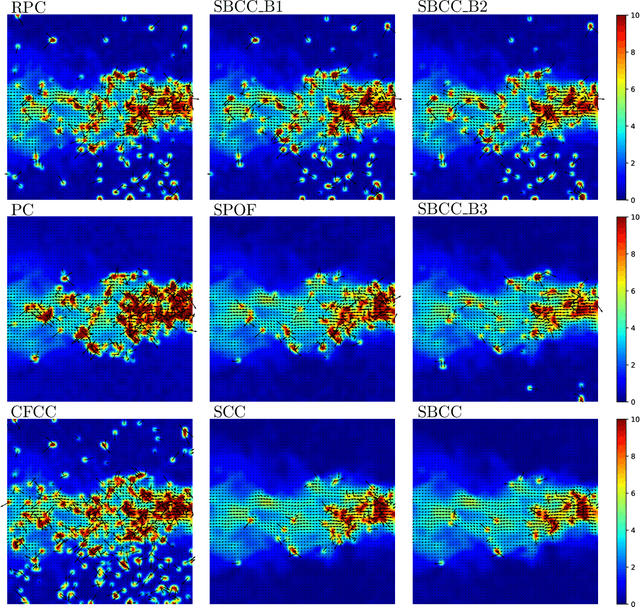
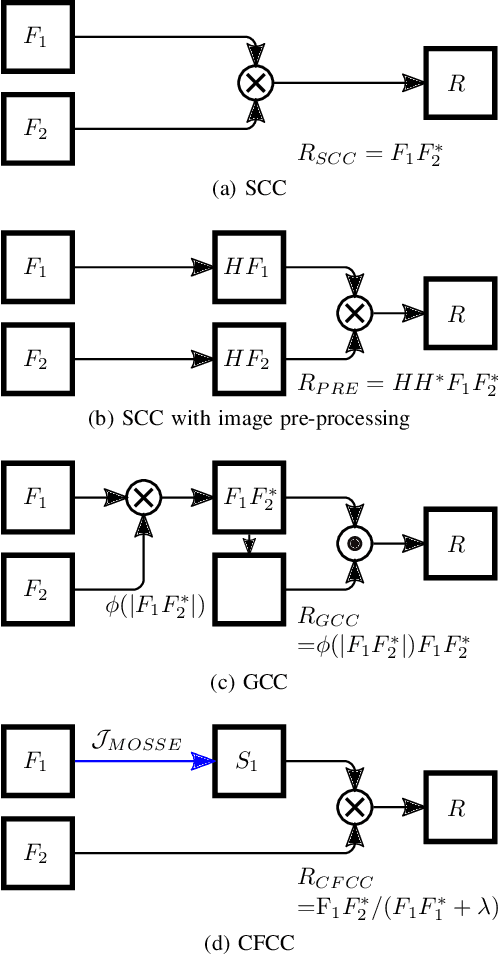
This paper presents a novel surrogate-based cross-correlation (SBCC) framework to improve the correlation performance between two image signals. The basic idea behind the SBCC is that an optimized surrogate filter/image, supplanting one original image, will produce a more robust and more accurate correlation signal. The cross-correlation estimation of the SBCC is formularized with an objective function composed of surrogate loss and correlation consistency loss. The closed-form solution provides an efficient estimation. To our surprise, the SBCC framework could provide an alternative view to explain a set of generalized cross-correlation (GCC) methods and comprehend the meaning of parameters. With the help of our SBCC framework, we further propose four new specific cross-correlation methods, and provide some suggestions for improving existing GCC methods. A noticeable fact is that the SBCC could enhance the correlation robustness by incorporating other negative context images. Considering the sub-pixel accuracy and robustness requirement of particle image velocimetry (PIV), the contribution of each term in the objective function is investigated with particles' images. Compared with the state-of-the-art baseline methods, the SBCC methods exhibit improved performance (accuracy and robustness) on the synthetic dataset and several challenging real experimental PIV cases.
Optimized Design Method for Satellite Constellation Configuration Based on Real-time Coverage Area Evaluation
Sep 16, 2022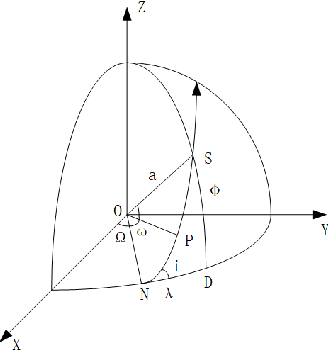
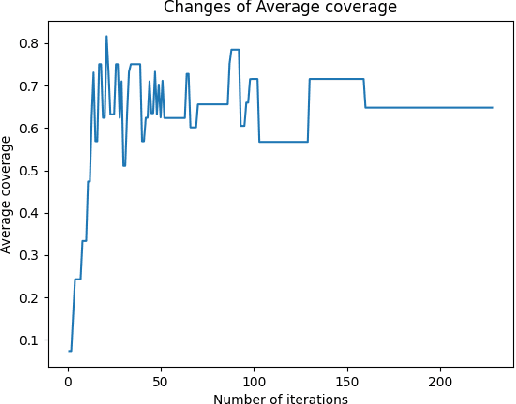
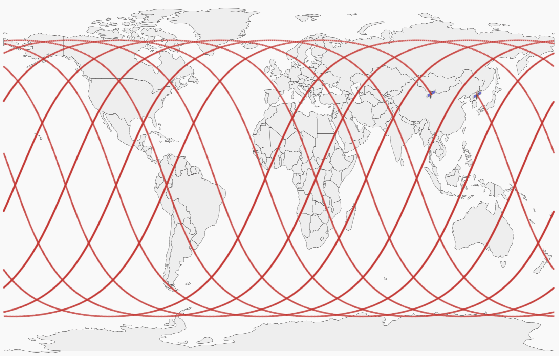
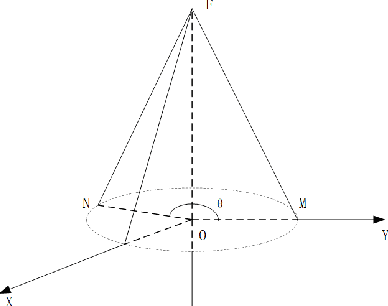
When using constellation synergy to image large areas for reconnaissance, it is required to achieve the coverage capability requirements with minimal consumption of observation resources to obtain the most optimal constellation observation scheme. With the minimum number of satellites and meeting the real-time ground coverage requirements as the optimization objectives, this paper proposes an optimized design of satellite constellation configuration for full coverage of large-scale regional imaging by using an improved simulated annealing algorithm combined with the real-time coverage evaluation method of hexagonal discretization. The algorithm can adapt to experimental conditions, has good efficiency, and can meet industrial accuracy requirements. The effectiveness and adaptability of the algorithm are tested in simulation applications.