 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Facial Representation Learning with Facial Region Awareness
Mar 04, 2024
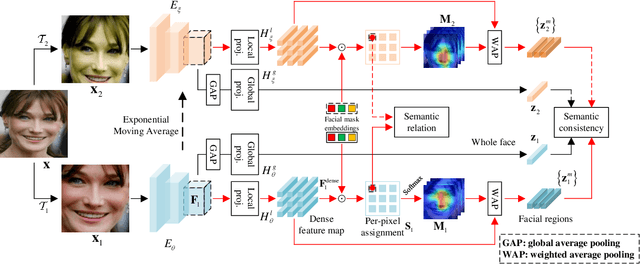

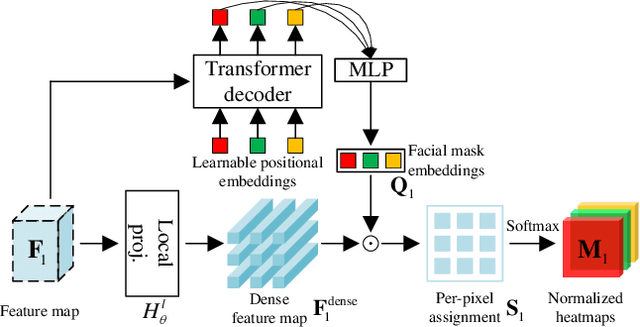
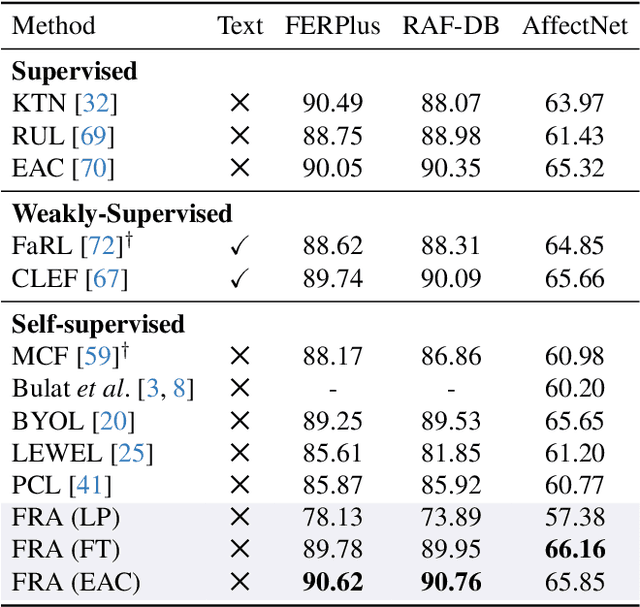
Self-supervised pre-training has been proved to be effective in learning transferable representations that benefit various visual tasks. This paper asks this question: can self-supervised pre-training learn general facial representations for various facial analysis tasks? Recent efforts toward this goal are limited to treating each face image as a whole, i.e., learning consistent facial representations at the image-level, which overlooks the consistency of local facial representations (i.e., facial regions like eyes, nose, etc). In this work, we make a first attempt to propose a novel self-supervised facial representation learning framework to learn consistent global and local facial representations, Facial Region Awareness (FRA). Specifically, we explicitly enforce the consistency of facial regions by matching the local facial representations across views, which are extracted with learned heatmaps highlighting the facial regions. Inspired by the mask prediction in supervised semantic segmentation, we obtain the heatmaps via cosine similarity between the per-pixel projection of feature maps and facial mask embeddings computed from learnable positional embeddings, which leverage the attention mechanism to globally look up the facial image for facial regions. To learn such heatmaps, we formulate the learning of facial mask embeddings as a deep clustering problem by assigning the pixel features from the feature maps to them. The transfer learning results on facial classification and regression tasks show that our FRA outperforms previous pre-trained models and more importantly, using ResNet as the unified backbone for various tasks, our FRA achieves comparable or even better performance compared with SOTA methods in facial analysis tasks.
Exploring Robust Features for Few-Shot Object Detection in Satellite Imagery
Mar 08, 2024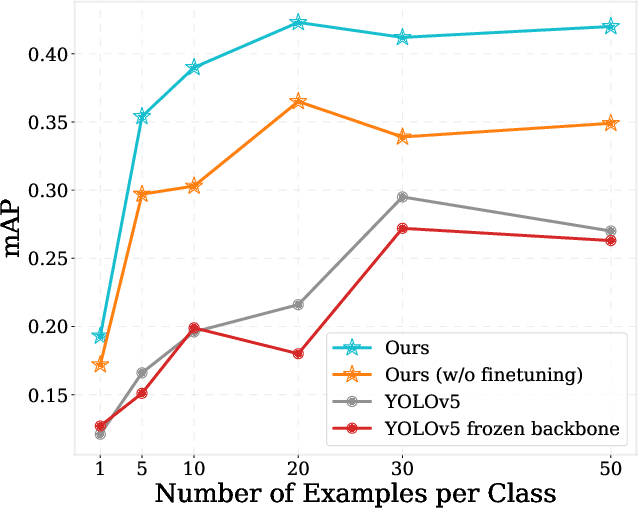
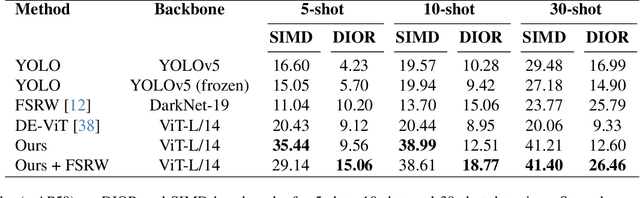
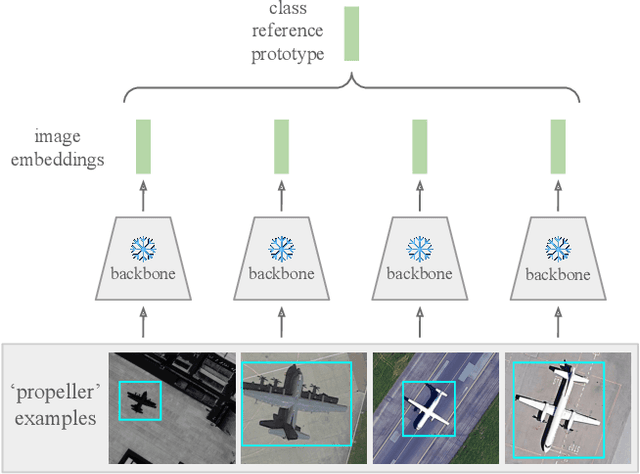
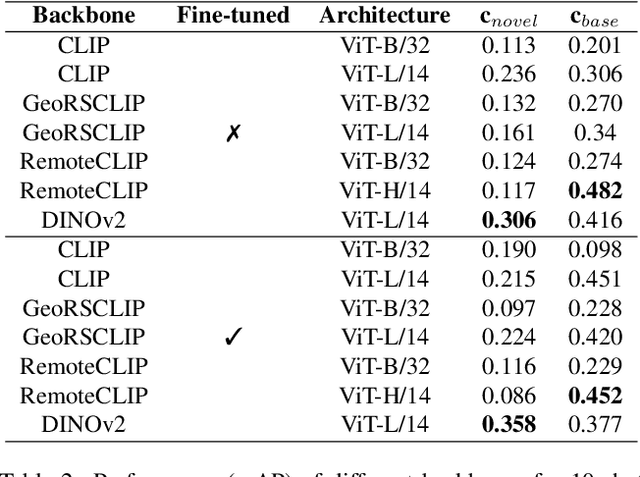
The goal of this paper is to perform object detection in satellite imagery with only a few examples, thus enabling users to specify any object class with minimal annotation. To this end, we explore recent methods and ideas from open-vocabulary detection for the remote sensing domain. We develop a few-shot object detector based on a traditional two-stage architecture, where the classification block is replaced by a prototype-based classifier. A large-scale pre-trained model is used to build class-reference embeddings or prototypes, which are compared to region proposal contents for label prediction. In addition, we propose to fine-tune prototypes on available training images to boost performance and learn differences between similar classes, such as aircraft types. We perform extensive evaluations on two remote sensing datasets containing challenging and rare objects. Moreover, we study the performance of both visual and image-text features, namely DINOv2 and CLIP, including two CLIP models specifically tailored for remote sensing applications. Results indicate that visual features are largely superior to vision-language models, as the latter lack the necessary domain-specific vocabulary. Lastly, the developed detector outperforms fully supervised and few-shot methods evaluated on the SIMD and DIOR datasets, despite minimal training parameters.
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Mar 08, 2024
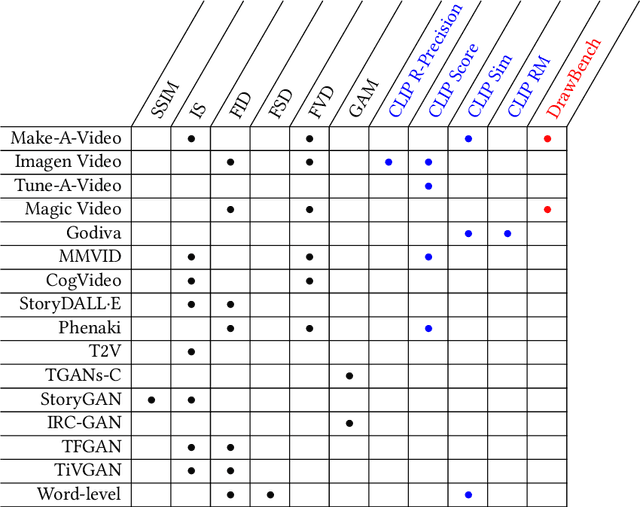
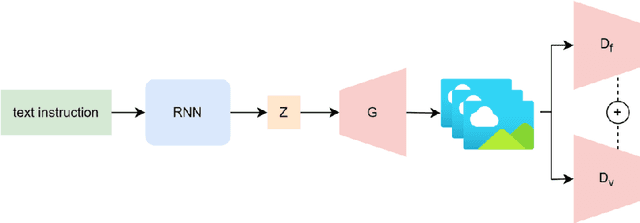
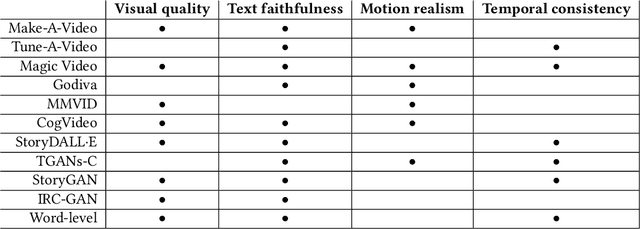
Text-to-video generation marks a significant frontier in the rapidly evolving domain of generative AI, integrating advancements in text-to-image synthesis, video captioning, and text-guided editing. This survey critically examines the progression of text-to-video technologies, focusing on the shift from traditional generative models to the cutting-edge Sora model, highlighting developments in scalability and generalizability. Distinguishing our analysis from prior works, we offer an in-depth exploration of the technological frameworks and evolutionary pathways of these models. Additionally, we delve into practical applications and address ethical and technological challenges such as the inability to perform multiple entity handling, comprehend causal-effect learning, understand physical interaction, perceive object scaling and proportioning, and combat object hallucination which is also a long-standing problem in generative models. Our comprehensive discussion covers the topic of enablement of text-to-video generation models as human-assistive tools and world models, as well as eliciting model's shortcomings and summarizing future improvement direction that mainly centers around training datasets and evaluation metrics (both automatic and human-centered). Aimed at both newcomers and seasoned researchers, this survey seeks to catalyze further innovation and discussion in the growing field of text-to-video generation, paving the way for more reliable and practical generative artificial intelligence technologies.
EAGLE: Eigen Aggregation Learning for Object-Centric Unsupervised Semantic Segmentation
Mar 03, 2024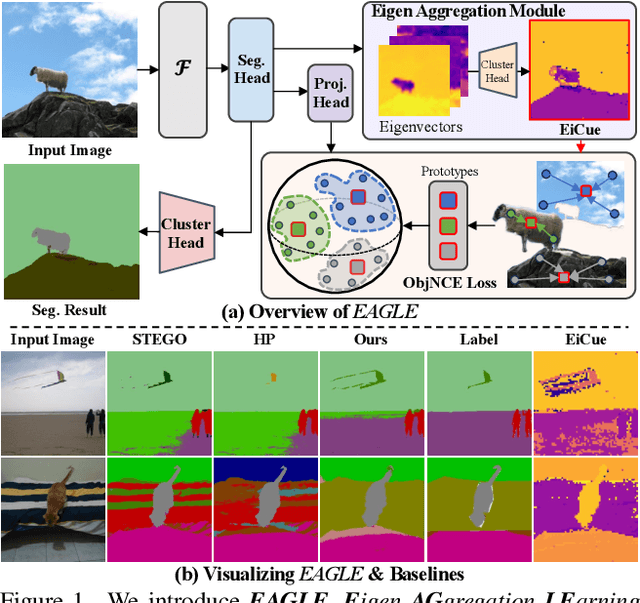
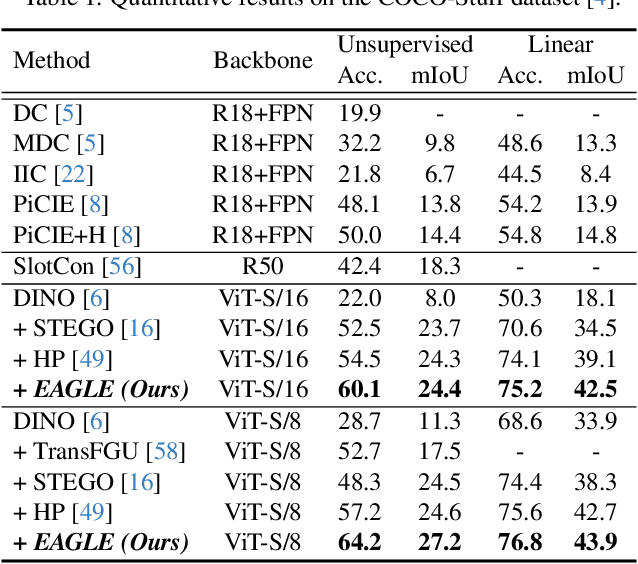
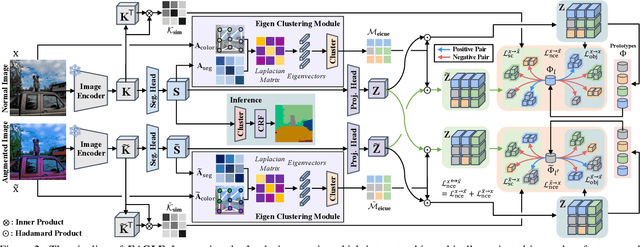
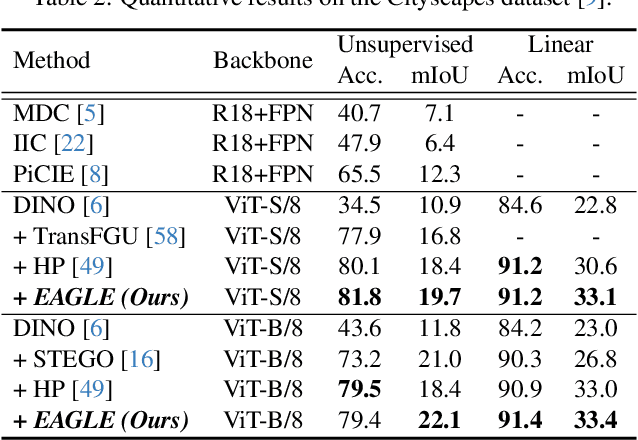
Semantic segmentation has innately relied on extensive pixel-level labeled annotated data, leading to the emergence of unsupervised methodologies. Among them, leveraging self-supervised Vision Transformers for unsupervised semantic segmentation (USS) has been making steady progress with expressive deep features. Yet, for semantically segmenting images with complex objects, a predominant challenge remains: the lack of explicit object-level semantic encoding in patch-level features. This technical limitation often leads to inadequate segmentation of complex objects with diverse structures. To address this gap, we present a novel approach, EAGLE, which emphasizes object-centric representation learning for unsupervised semantic segmentation. Specifically, we introduce EiCue, a spectral technique providing semantic and structural cues through an eigenbasis derived from the semantic similarity matrix of deep image features and color affinity from an image. Further, by incorporating our object-centric contrastive loss with EiCue, we guide our model to learn object-level representations with intra- and inter-image object-feature consistency, thereby enhancing semantic accuracy. Extensive experiments on COCO-Stuff, Cityscapes, and Potsdam-3 datasets demonstrate the state-of-the-art USS results of EAGLE with accurate and consistent semantic segmentation across complex scenes.
Hitchhiker's guide to cancer-associated lymphoid aggregates in histology images: manual and deep learning-based quantification approaches
Mar 06, 2024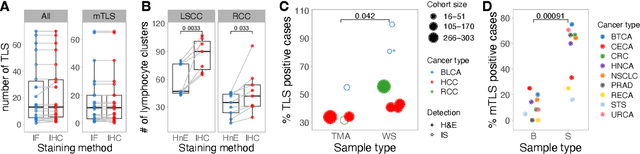
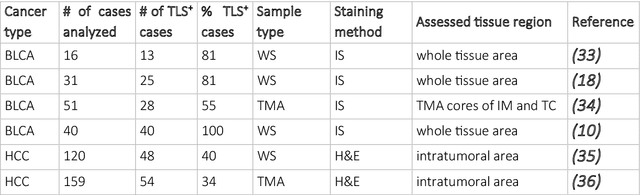
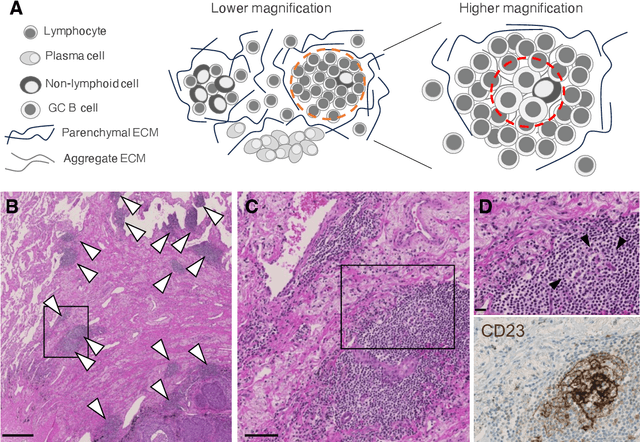
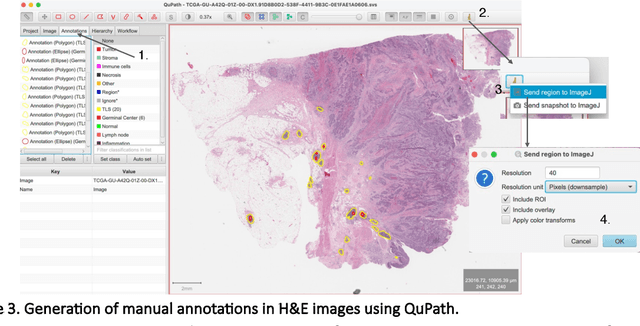
Quantification of lymphoid aggregates including tertiary lymphoid structures with germinal centers in histology images of cancer is a promising approach for developing prognostic and predictive tissue biomarkers. In this article, we provide recommendations for identifying lymphoid aggregates in tissue sections from routine pathology workflows such as hematoxylin and eosin staining. To overcome the intrinsic variability associated with manual image analysis (such as subjective decision making, attention span), we recently developed a deep learning-based algorithm called HookNet-TLS to detect lymphoid aggregates and germinal centers in various tissues. Here, we additionally provide a guideline for using manually annotated images for training and implementing HookNet-TLS for automated and objective quantification of lymphoid aggregates in various cancer types.
Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use
Mar 05, 2024
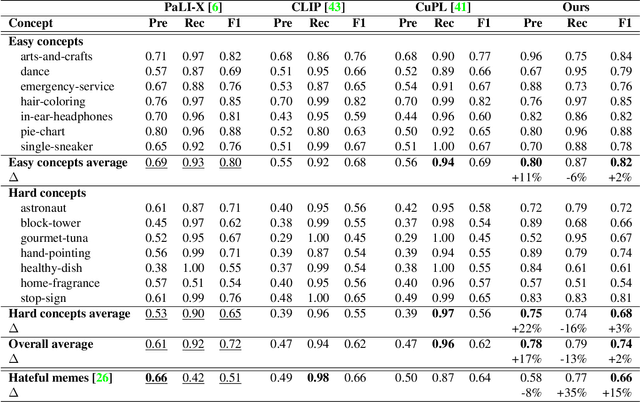
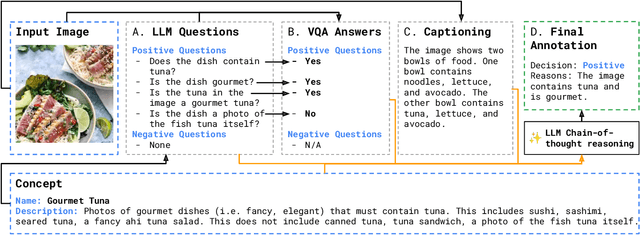
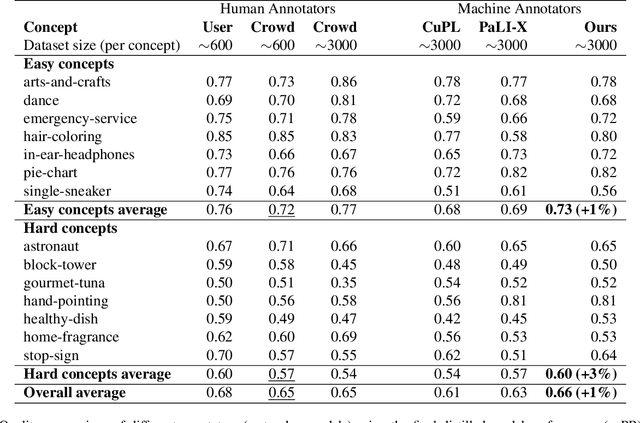
From content moderation to wildlife conservation, the number of applications that require models to recognize nuanced or subjective visual concepts is growing. Traditionally, developing classifiers for such concepts requires substantial manual effort measured in hours, days, or even months to identify and annotate data needed for training. Even with recently proposed Agile Modeling techniques, which enable rapid bootstrapping of image classifiers, users are still required to spend 30 minutes or more of monotonous, repetitive data labeling just to train a single classifier. Drawing on Fiske's Cognitive Miser theory, we propose a new framework that alleviates manual effort by replacing human labeling with natural language interactions, reducing the total effort required to define a concept by an order of magnitude: from labeling 2,000 images to only 100 plus some natural language interactions. Our framework leverages recent advances in foundation models, both large language models and vision-language models, to carve out the concept space through conversation and by automatically labeling training data points. Most importantly, our framework eliminates the need for crowd-sourced annotations. Moreover, our framework ultimately produces lightweight classification models that are deployable in cost-sensitive scenarios. Across 15 subjective concepts and across 2 public image classification datasets, our trained models outperform traditional Agile Modeling as well as state-of-the-art zero-shot classification models like ALIGN, CLIP, CuPL, and large visual question-answering models like PaLI-X.
Improving Android Malware Detection Through Data Augmentation Using Wasserstein Generative Adversarial Networks
Mar 05, 2024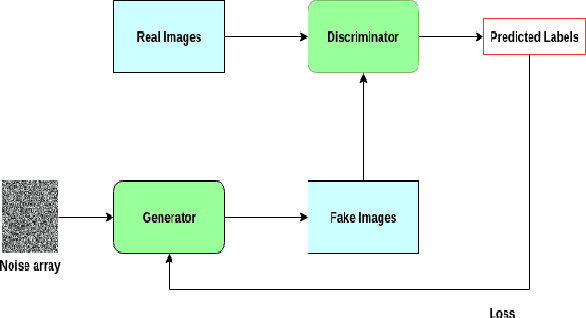
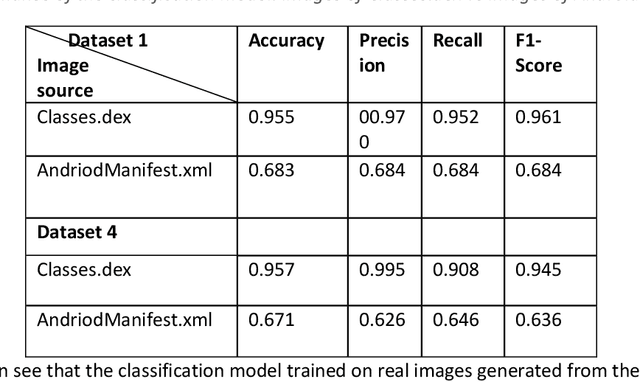
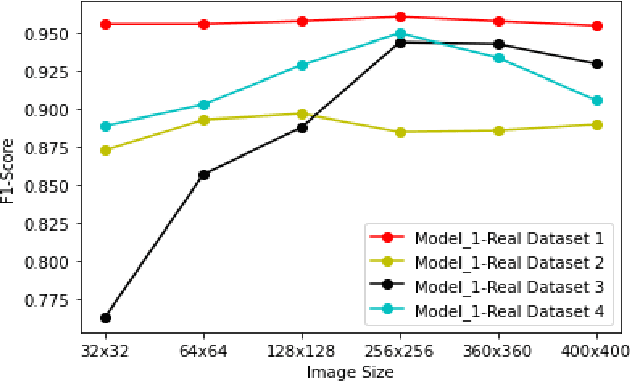
Generative Adversarial Networks (GANs) have demonstrated their versatility across various applications, including data augmentation and malware detection. This research explores the effectiveness of utilizing GAN-generated data to train a model for the detection of Android malware. Given the considerable storage requirements of Android applications, the study proposes a method to synthetically represent data using GANs, thereby reducing storage demands. The proposed methodology involves creating image representations of features extracted from an existing dataset. A GAN model is then employed to generate a more extensive dataset consisting of realistic synthetic grayscale images. Subsequently, this synthetic dataset is utilized to train a Convolutional Neural Network (CNN) designed to identify previously unseen Android malware applications. The study includes a comparative analysis of the CNN's performance when trained on real images versus synthetic images generated by the GAN. Furthermore, the research explores variations in performance between the Wasserstein Generative Adversarial Network (WGAN) and the Deep Convolutional Generative Adversarial Network (DCGAN). The investigation extends to studying the impact of image size and malware obfuscation on the classification model's effectiveness. The data augmentation approach implemented in this study resulted in a notable performance enhancement of the classification model, ranging from 1.5% to 7%, depending on the dataset. The highest achieved F1 score reached 0.975. Keywords--Generative Adversarial Networks, Android Malware, Data Augmentation, Wasserstein Generative Adversarial Network
PalmProbNet: A Probabilistic Approach to Understanding Palm Distributions in Ecuadorian Tropical Forest via Transfer Learning
Mar 05, 2024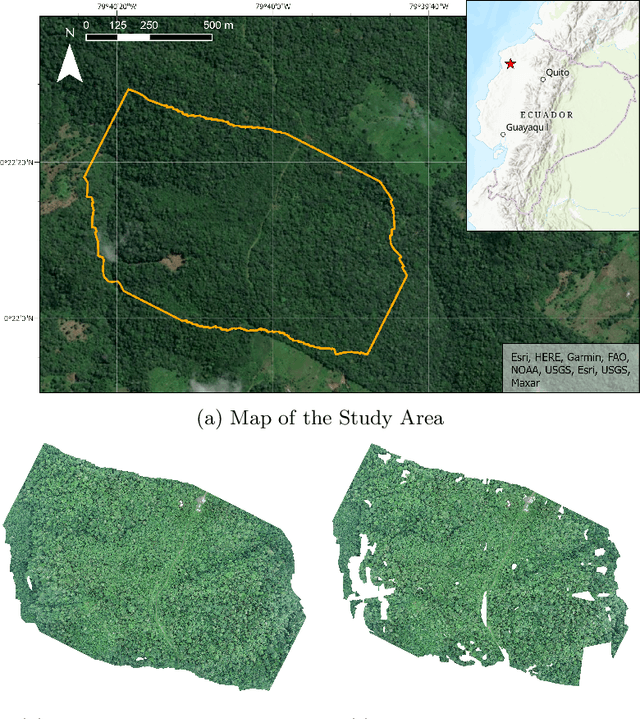
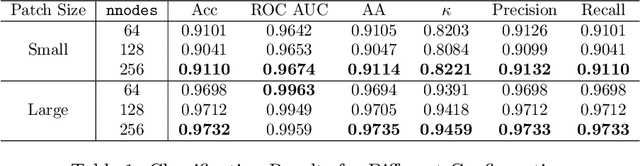


Palms play an outsized role in tropical forests and are important resources for humans and wildlife. A central question in tropical ecosystems is understanding palm distribution and abundance. However, accurately identifying and localizing palms in geospatial imagery presents significant challenges due to dense vegetation, overlapping canopies, and variable lighting conditions in mixed-forest landscapes. Addressing this, we introduce PalmProbNet, a probabilistic approach utilizing transfer learning to analyze high-resolution UAV-derived orthomosaic imagery, enabling the detection of palm trees within the dense canopy of the Ecuadorian Rainforest. This approach represents a substantial advancement in automated palm detection, effectively pinpointing palm presence and locality in mixed tropical rainforests. Our process begins by generating an orthomosaic image from UAV images, from which we extract and label palm and non-palm image patches in two distinct sizes. These patches are then used to train models with an identical architecture, consisting of an unaltered pre-trained ResNet-18 and a Multilayer Perceptron (MLP) with specifically trained parameters. Subsequently, PalmProbNet employs a sliding window technique on the landscape orthomosaic, using both small and large window sizes to generate a probability heatmap. This heatmap effectively visualizes the distribution of palms, showcasing the scalability and adaptability of our approach in various forest densities. Despite the challenging terrain, our method demonstrated remarkable performance, achieving an accuracy of 97.32% and a Cohen's kappa of 94.59% in testing.
Time Weaver: A Conditional Time Series Generation Model
Mar 05, 2024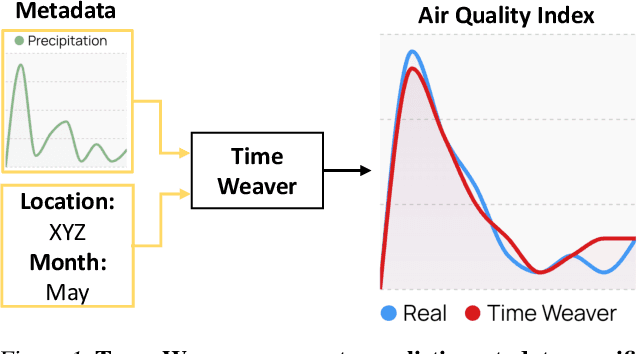
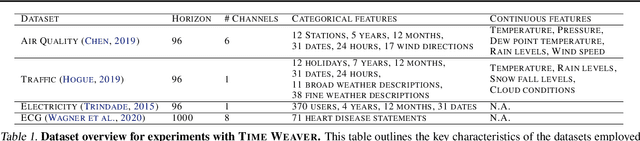
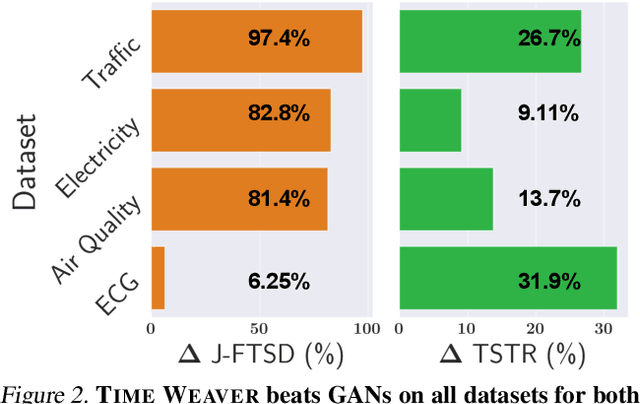
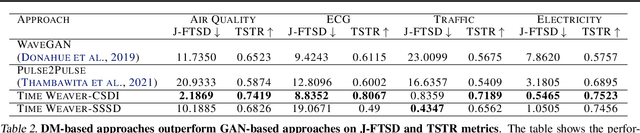
Imagine generating a city's electricity demand pattern based on weather, the presence of an electric vehicle, and location, which could be used for capacity planning during a winter freeze. Such real-world time series are often enriched with paired heterogeneous contextual metadata (weather, location, etc.). Current approaches to time series generation often ignore this paired metadata, and its heterogeneity poses several practical challenges in adapting existing conditional generation approaches from the image, audio, and video domains to the time series domain. To address this gap, we introduce Time Weaver, a novel diffusion-based model that leverages the heterogeneous metadata in the form of categorical, continuous, and even time-variant variables to significantly improve time series generation. Additionally, we show that naive extensions of standard evaluation metrics from the image to the time series domain are insufficient. These metrics do not penalize conditional generation approaches for their poor specificity in reproducing the metadata-specific features in the generated time series. Thus, we innovate a novel evaluation metric that accurately captures the specificity of conditional generation and the realism of the generated time series. We show that Time Weaver outperforms state-of-the-art benchmarks, such as Generative Adversarial Networks (GANs), by up to 27% in downstream classification tasks on real-world energy, medical, air quality, and traffic data sets.
ChatEarthNet: A Global-Scale, High-Quality Image-Text Dataset for Remote Sensing
Feb 17, 2024An in-depth comprehension of global land cover is essential in Earth observation, forming the foundation for a multitude of applications. Although remote sensing technology has advanced rapidly, leading to a proliferation of satellite imagery, the inherent complexity of these images often makes them difficult for non-expert users to understand. Natural language, as a carrier of human knowledge, can be a bridge between common users and complicated satellite imagery. In this context, we introduce a global-scale, high-quality image-text dataset for remote sensing, providing natural language descriptions for Sentinel-2 data to facilitate the understanding of satellite imagery for common users. Specifically, we utilize Sentinel-2 data for its global coverage as the foundational image source, employing semantic segmentation labels from the European Space Agency's (ESA) WorldCover project to enrich the descriptions of land covers. By conducting in-depth semantic analysis, we formulate detailed prompts to elicit rich descriptions from ChatGPT. To enhance the dataset's quality, we introduce the manual verification process. This step involves manual inspection and correction to refine the dataset, thus significantly improving its accuracy and quality. Finally, we offer the community ChatEarthNet, a large-scale image-text dataset characterized by global coverage, high quality, wide-ranging diversity, and detailed descriptions. ChatEarthNet consists of 163,488 image-text pairs with captions generated by ChatGPT-3.5 and an additional 10,000 image-text pairs with captions generated by ChatGPT-4V(ision). This dataset has significant potential for training vision-language foundation models and evaluating large vision-language models for remote sensing. The dataset will be made publicly available.