 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detecting Twenty-thousand Classes using Image-level Supervision
Jan 07, 2022
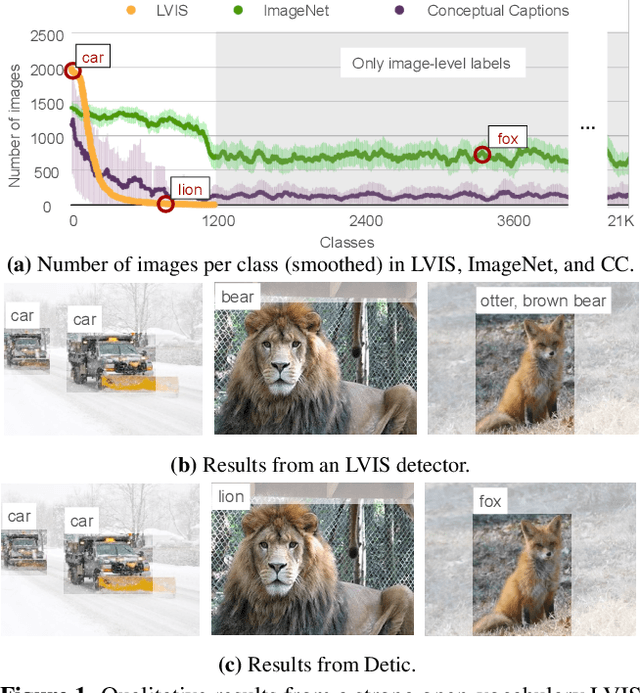
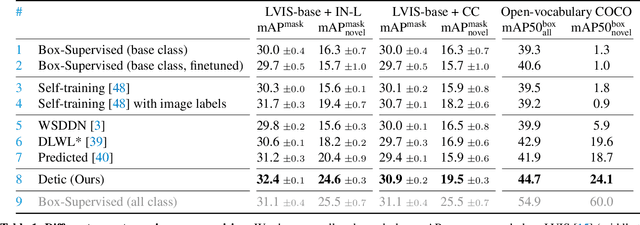


Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets are larger and easier to collect. We propose Detic, which simply trains the classifiers of a detector on image classification data and thus expands the vocabulary of detectors to tens of thousands of concepts. Unlike prior work, Detic does not assign image labels to boxes based on model predictions, making it much easier to implement and compatible with a range of detection architectures and backbones. Our results show that Detic yields excellent detectors even for classes without box annotations. It outperforms prior work on both open-vocabulary and long-tail detection benchmarks. Detic provides a gain of 2.4 mAP for all classes and 8.3 mAP for novel classes on the open-vocabulary LVIS benchmark. On the standard LVIS benchmark, Detic reaches 41.7 mAP for all classes and 41.7 mAP for rare classes. For the first time, we train a detector with all the twenty-one-thousand classes of the ImageNet dataset and show that it generalizes to new datasets without fine-tuning. Code is available at https://github.com/facebookresearch/Detic.
ROS georegistration: Aerial Multi-spectral Image Simulator for the Robot Operating System
Jan 19, 2022



This article describes a software package called ROS georegistration intended for use with the Robot Operating System (ROS) and the Gazebo 3D simulation environment. ROSgeoregistration provides tools for the simulation, test and deployment of aerial georegistration algorithms and is made available with a link provided in the paper. A model creation package is provided which downloads multi-spectral images from the Google Earth Engine database and, if necessary, incorporates these images into a single, possibly very large, reference image. Additionally a Gazebo plugin which uses the real-time sensor pose and image formation model to generate simulated imagery using the specified reference image is provided along with related plugins for UAV relevant data. The novelty of this work is threefold: (1) this is the first system to link the massive multi-spectral imaging database of Google's Earth Engine to the Gazebo simulator, (2) this is the first example of a system that can simulate geospatially and radiometrically accurate imagery from multiple sensor views of the same terrain region, and (3) integration with other UAS tools creates a new holistic UAS simulation environment to support UAS system and subsystem development where real-world testing would generally be prohibitive. Sensed imagery and ground truth registration information is published to client applications which can receive imagery synchronously with telemetry from other payload sensors, e.g., IMU, GPS/GNSS, barometer, and windspeed sensor data. To highlight functionality, we demonstrate ROSgeoregistration for simulating Electro-Optical (EO) and Synthetic Aperture Radar (SAR) image sensors and an example use case for developing and evaluating image-based UAS position feedback, i.e., pose for image-based Guidance Navigation and Control (GNC) applications.
KiPA22 Report: U-Net with Contour Regularization for Renal Structures Segmentation
Aug 10, 2022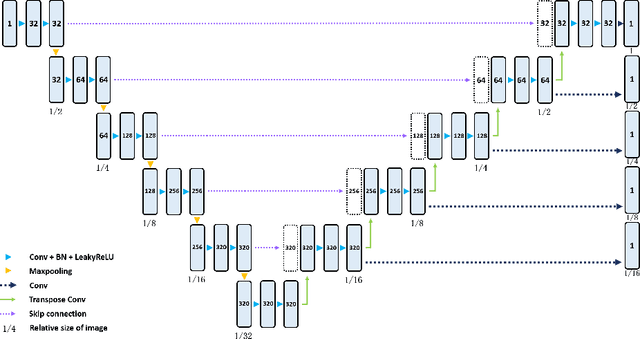
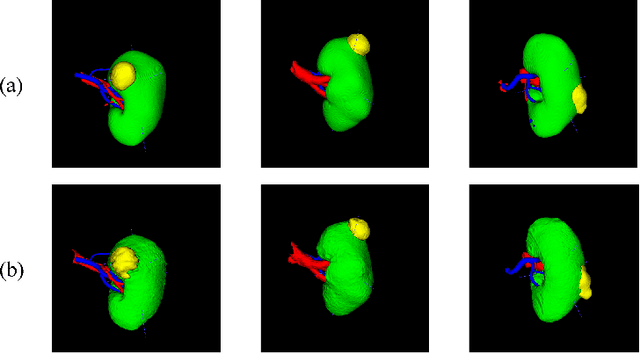

Three-dimensional (3D) integrated renal structures (IRS) segmentation is important in clinical practice. With the advancement of deep learning techniques, many powerful frameworks focusing on medical image segmentation are proposed. In this challenge, we utilized the nnU-Net framework, which is the state-of-the-art method for medical image segmentation. To reduce the outlier prediction for the tumor label, we combine contour regularization (CR) loss of the tumor label with Dice loss and cross-entropy loss to improve this phenomenon.
Understanding Attention for Vision-and-Language Tasks
Aug 17, 2022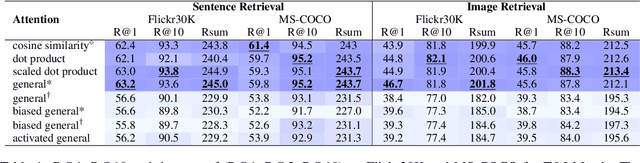
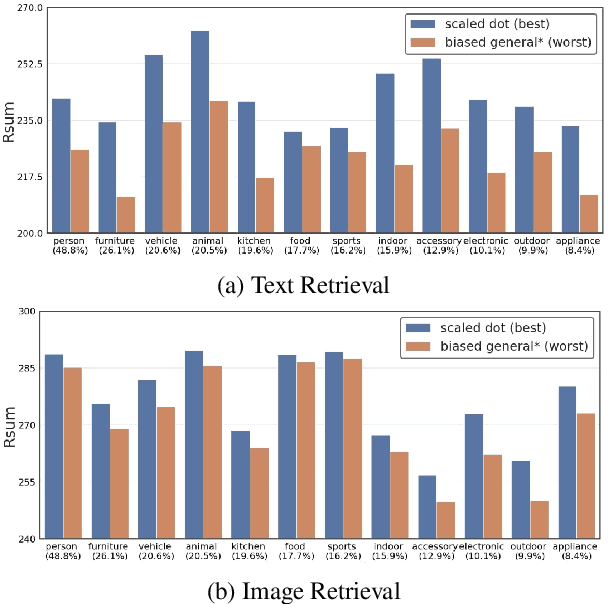
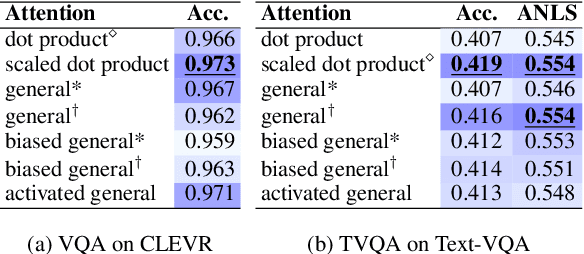
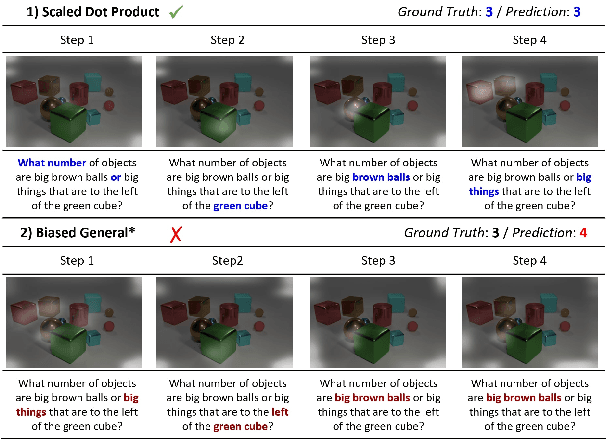
Attention mechanism has been used as an important component across Vision-and-Language(VL) tasks in order to bridge the semantic gap between visual and textual features. While attention has been widely used in VL tasks, it has not been examined the capability of different attention alignment calculation in bridging the semantic gap between visual and textual clues. In this research, we conduct a comprehensive analysis on understanding the role of attention alignment by looking into the attention score calculation methods and check how it actually represents the visual region's and textual token's significance for the global assessment. We also analyse the conditions which attention score calculation mechanism would be more (or less) interpretable, and which may impact the model performance on three different VL tasks, including visual question answering, text-to-image generation, text-and-image matching (both sentence and image retrieval). Our analysis is the first of its kind and provides useful insights of the importance of each attention alignment score calculation when applied at the training phase of VL tasks, commonly ignored in attention-based cross modal models, and/or pretrained models.
Multistep Automated Data Labelling Procedure (MADLaP) for Thyroid Nodules on Ultrasound: An Artificial Intelligence Approach for Automating Image Annotation
Jun 28, 2022
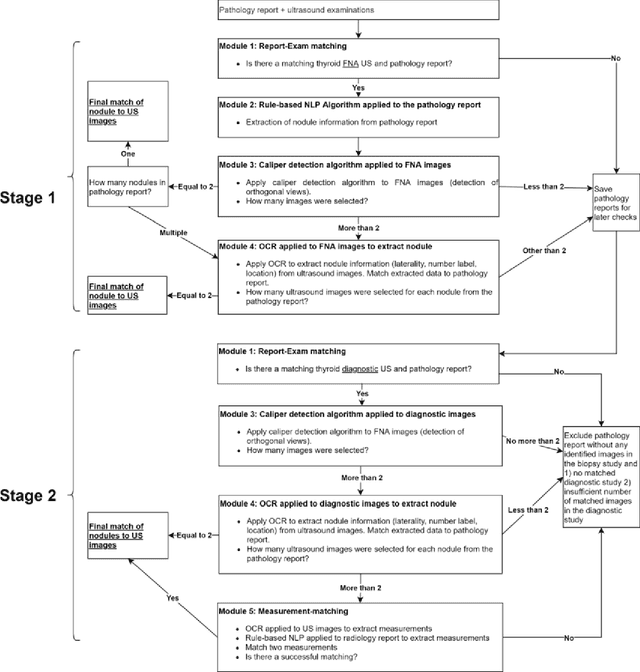


Machine learning (ML) for diagnosis of thyroid nodules on ultrasound is an active area of research. However, ML tools require large, well-labelled datasets, the curation of which is time-consuming and labor-intensive. The purpose of our study was to develop and test a deep-learning-based tool to facilitate and automate the data annotation process for thyroid nodules; we named our tool Multistep Automated Data Labelling Procedure (MADLaP). MADLaP was designed to take multiple inputs included pathology reports, ultrasound images, and radiology reports. Using multiple step-wise modules including rule-based natural language processing, deep-learning-based imaging segmentation, and optical character recognition, MADLaP automatically identified images of a specific thyroid nodule and correctly assigned a pathology label. The model was developed using a training set of 378 patients across our health system and tested on a separate set of 93 patients. Ground truths for both sets were selected by an experienced radiologist. Performance metrics including yield (how many labeled images the model produced) and accuracy (percentage correct) were measured using the test set. MADLaP achieved a yield of 63% and an accuracy of 83%. The yield progressively increased as the input data moved through each module, while accuracy peaked part way through. Error analysis showed that inputs from certain examination sites had lower accuracy (40%) than the other sites (90%, 100%). MADLaP successfully created curated datasets of labeled ultrasound images of thyroid nodules. While accurate, the relatively suboptimal yield of MADLaP exposed some challenges when trying to automatically label radiology images from heterogeneous sources. The complex task of image curation and annotation could be automated, allowing for enrichment of larger datasets for use in machine learning development.
RestoreX-AI: A Contrastive Approach towards Guiding Image Restoration via Explainable AI Systems
Apr 03, 2022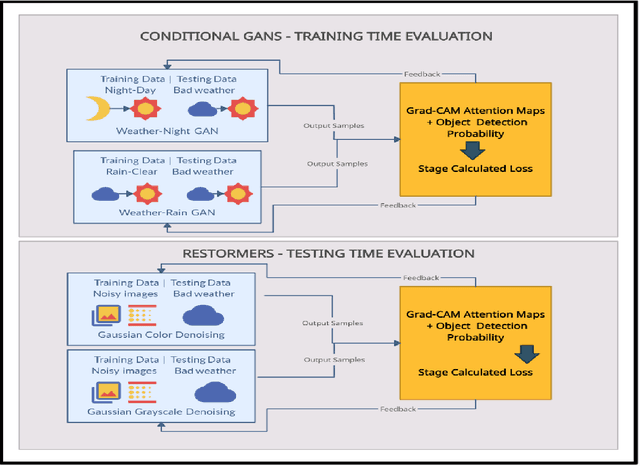
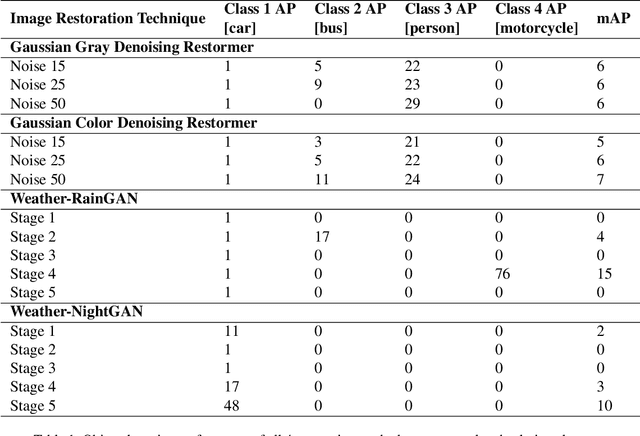


Modern applications such as self-driving cars and drones rely heavily upon robust object detection techniques. However, weather corruptions can hinder the object detectability and pose a serious threat to their navigation and reliability. Thus, there is a need for efficient denoising, deraining, and restoration techniques. Generative adversarial networks and transformers have been widely adopted for image restoration. However, the training of these methods is often unstable and time-consuming. Furthermore, when used for object detection (OD), the output images generated by these methods may provide unsatisfactory results despite image clarity. In this work, we propose a contrastive approach towards mitigating this problem, by evaluating images generated by restoration models during and post training. This approach leverages OD scores combined with attention maps for predicting the usefulness of restored images for the OD task. We conduct experiments using two novel use-cases of conditional GANs and two transformer methods that probe the robustness of the proposed approach on multi-weather corruptions in the OD task. Our approach achieves an averaged 178 percent increase in mAP between the input and restored images under adverse weather conditions like dust tornadoes and snowfall. We report unique cases where greater denoising does not improve OD performance and conversely where noisy generated images demonstrate good results. We conclude the need for explainability frameworks to bridge the gap between human and machine perception, especially in the context of robust object detection for autonomous vehicles.
Computing Multiple Image Reconstructions with a Single Hypernetwork
Mar 16, 2022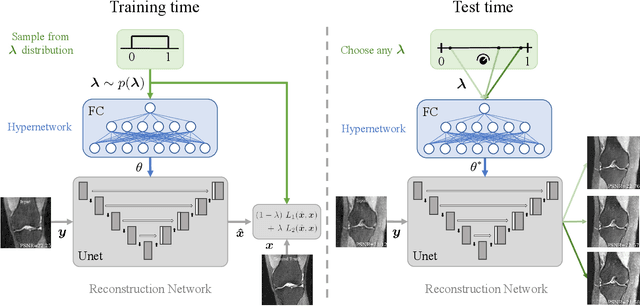

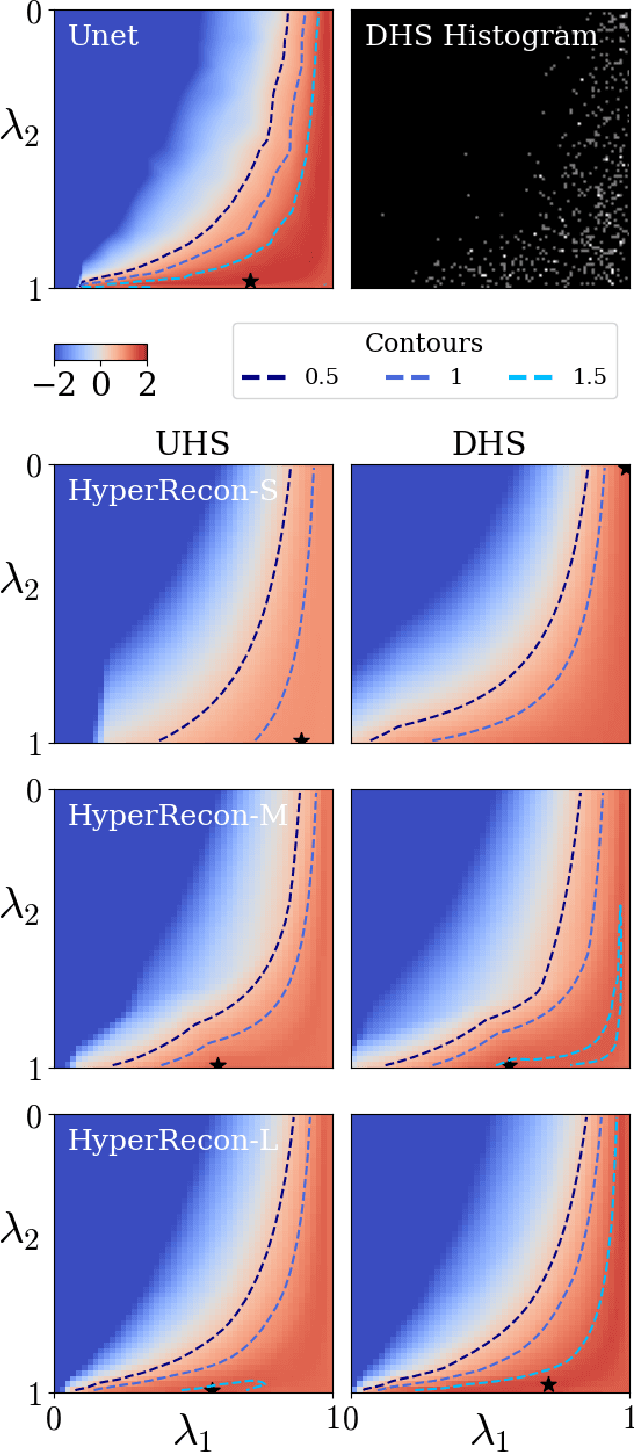
Deep learning based techniques achieve state-of-the-art results in a wide range of image reconstruction tasks like compressed sensing. These methods almost always have hyperparameters, such as the weight coefficients that balance the different terms in the optimized loss function. The typical approach is to train the model for a hyperparameter setting determined with some empirical or theoretical justification. Thus, at inference time, the model can only compute reconstructions corresponding to the pre-determined hyperparameter values. In this work, we present a hypernetwork-based approach, called HyperRecon, to train reconstruction models that are agnostic to hyperparameter settings. At inference time, HyperRecon can efficiently produce diverse reconstructions, which would each correspond to different hyperparameter values. In this framework, the user is empowered to select the most useful output(s) based on their own judgement. We demonstrate our method in compressed sensing, super-resolution and denoising tasks, using two large-scale and publicly-available MRI datasets. Our code is available at https://github.com/alanqrwang/hyperrecon.
A Comprehensive Survey with Quantitative Comparison of Image Analysis Methods for Microorganism Biovolume Measurements
Feb 18, 2022

With the acceleration of urbanization and living standards, microorganisms play increasingly important roles in industrial production, bio-technique, and food safety testing. Microorganism biovolume measurements are one of the essential parts of microbial analysis. However, traditional manual measurement methods are time-consuming and challenging to measure the characteristics precisely. With the development of digital image processing techniques, the characteristics of the microbial population can be detected and quantified. The changing trend can be adjusted in time and provided a basis for the improvement. The applications of the microorganism biovolume measurement method have developed since the 1980s. More than 60 articles are reviewed in this study, and the articles are grouped by digital image segmentation methods with periods. This study has high research significance and application value, which can be referred to microbial researchers to have a comprehensive understanding of microorganism biovolume measurements using digital image analysis methods and potential applications.
Image Compressed Sensing Using Non-local Neural Network
Dec 07, 2021
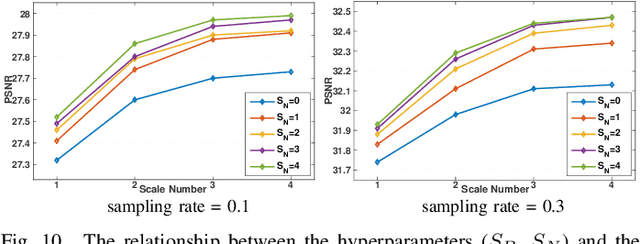

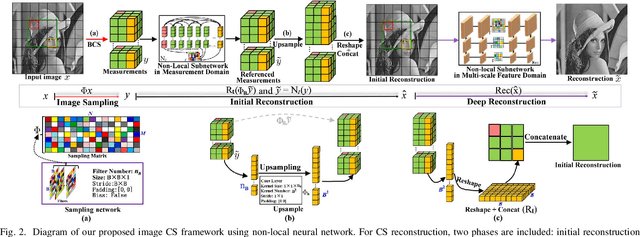
Deep network-based image Compressed Sensing (CS) has attracted much attention in recent years. However, the existing deep network-based CS schemes either reconstruct the target image in a block-by-block manner that leads to serious block artifacts or train the deep network as a black box that brings about limited insights of image prior knowledge. In this paper, a novel image CS framework using non-local neural network (NL-CSNet) is proposed, which utilizes the non-local self-similarity priors with deep network to improve the reconstruction quality. In the proposed NL-CSNet, two non-local subnetworks are constructed for utilizing the non-local self-similarity priors in the measurement domain and the multi-scale feature domain respectively. Specifically, in the subnetwork of measurement domain, the long-distance dependencies between the measurements of different image blocks are established for better initial reconstruction. Analogically, in the subnetwork of multi-scale feature domain, the affinities between the dense feature representations are explored in the multi-scale space for deep reconstruction. Furthermore, a novel loss function is developed to enhance the coupling between the non-local representations, which also enables an end-to-end training of NL-CSNet. Extensive experiments manifest that NL-CSNet outperforms existing state-of-the-art CS methods, while maintaining fast computational speed.
* 14 pages, 11 figures, 7 tables
Large-Scale Open-Set Classification Protocols for ImageNet
Oct 18, 2022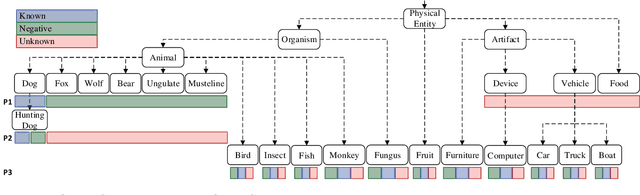

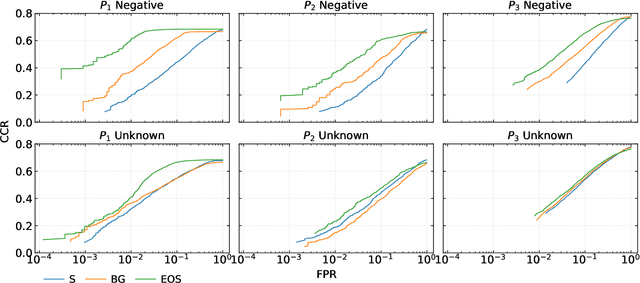
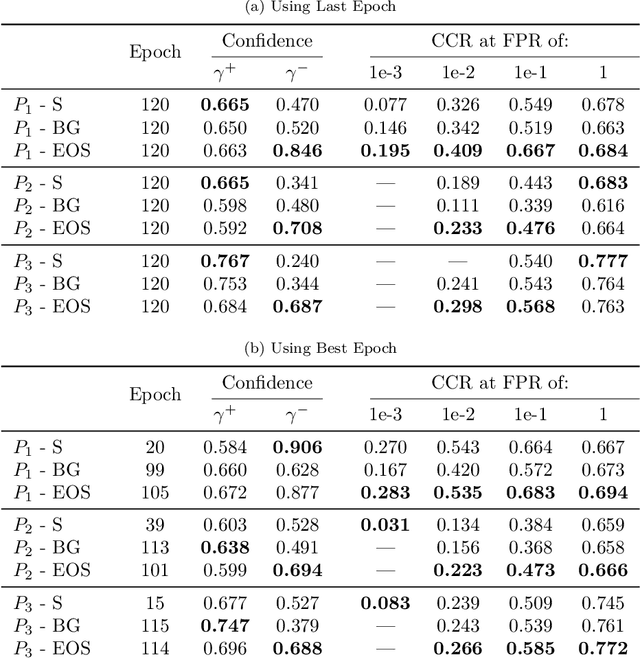
Open-Set Classification (OSC) intends to adapt closed-set classification models to real-world scenarios, where the classifier must correctly label samples of known classes while rejecting previously unseen unknown samples. Only recently, research started to investigate on algorithms that are able to handle these unknown samples correctly. Some of these approaches address OSC by including into the training set negative samples that a classifier learns to reject, expecting that these data increase the robustness of the classifier on unknown classes. Most of these approaches are evaluated on small-scale and low-resolution image datasets like MNIST, SVHN or CIFAR, which makes it difficult to assess their applicability to the real world, and to compare them among each other. We propose three open-set protocols that provide rich datasets of natural images with different levels of similarity between known and unknown classes. The protocols consist of subsets of ImageNet classes selected to provide training and testing data closer to real-world scenarios. Additionally, we propose a new validation metric that can be employed to assess whether the training of deep learning models addresses both the classification of known samples and the rejection of unknown samples. We use the protocols to compare the performance of two baseline open-set algorithms to the standard SoftMax baseline and find that the algorithms work well on negative samples that have been seen during training, and partially on out-of-distribution detection tasks, but drop performance in the presence of samples from previously unseen unknown classes.