 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Clustering Method Based on Information Entropy Payload
Sep 13, 2022

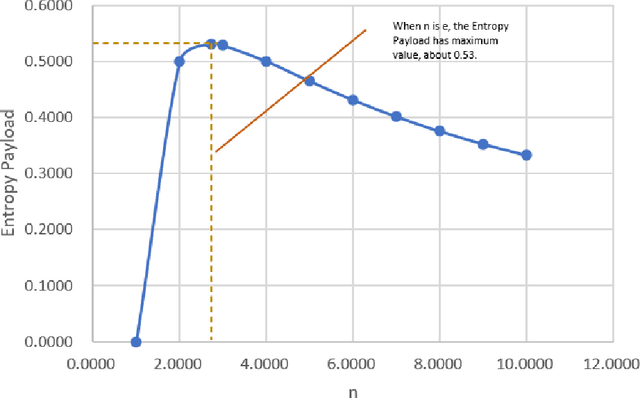

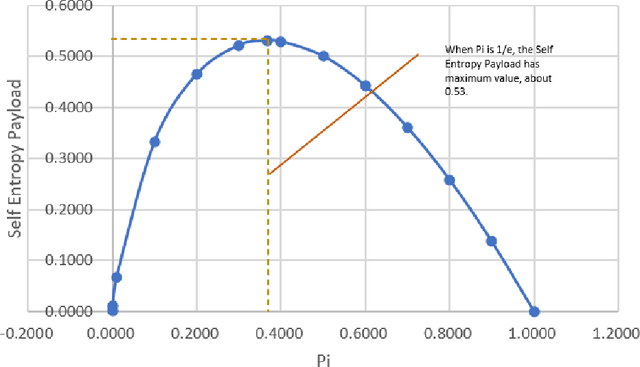
Existing clustering algorithms such as K-means often need to preset parameters such as the number of categories K, and such parameters may lead to the failure to output objective and consistent clustering results. This paper introduces a clustering method based on the information theory, by which clusters in the clustering result have maximum average information entropy (called entropy payload in this paper). This method can bring the following benefits: firstly, this method does not need to preset any super parameter such as category number or other similar thresholds, secondly, the clustering results have the maximum information expression efficiency. it can be used in image segmentation, object classification, etc., and could be the basis of unsupervised learning.
Medical Image Segmentation on MRI Images with Missing Modalities: A Review
Mar 11, 2022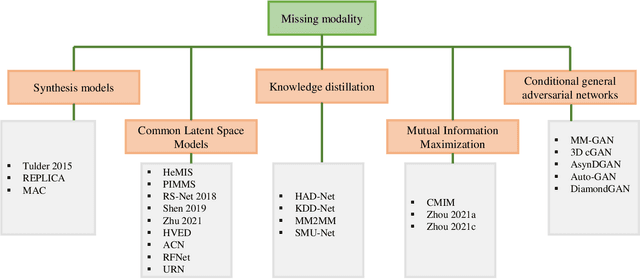
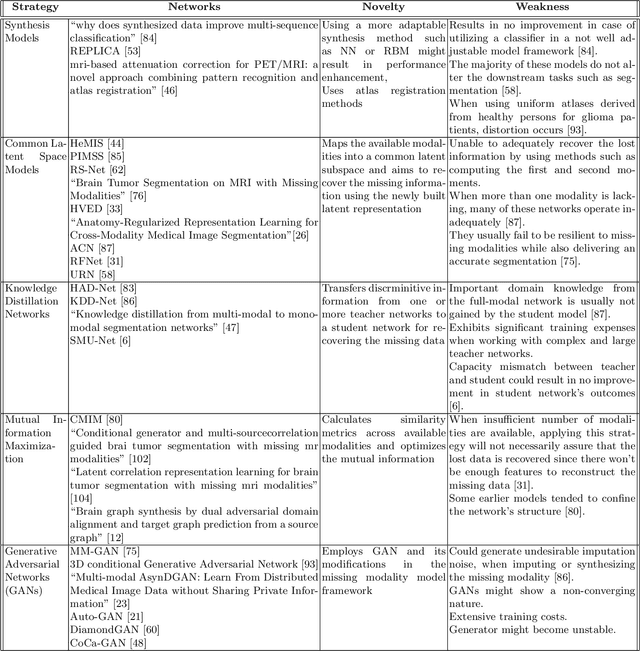
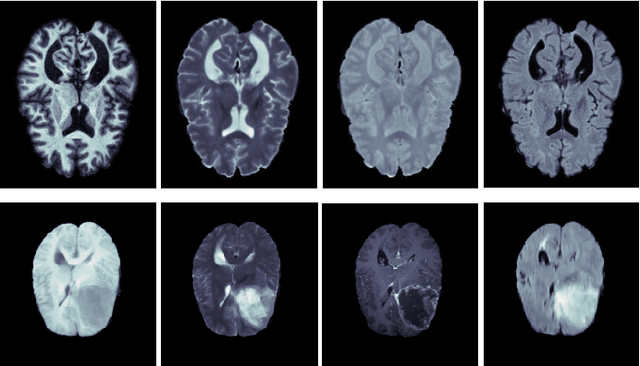
Dealing with missing modalities in Magnetic Resonance Imaging (MRI) and overcoming their negative repercussions is considered a hurdle in biomedical imaging. The combination of a specified set of modalities, which is selected depending on the scenario and anatomical part being scanned, will provide medical practitioners with full information about the region of interest in the human body, hence the missing MRI sequences should be reimbursed. The compensation of the adverse impact of losing useful information owing to the lack of one or more modalities is a well-known challenge in the field of computer vision, particularly for medical image processing tasks including tumour segmentation, tissue classification, and image generation. Various approaches have been developed over time to mitigate this problem's negative implications and this literature review goes through a significant number of the networks that seek to do so. The approaches reviewed in this work are reviewed in detail, including earlier techniques such as synthesis methods as well as later approaches that deploy deep learning, such as common latent space models, knowledge distillation networks, mutual information maximization, and generative adversarial networks (GANs). This work discusses the most important approaches that have been offered at the time of this writing, examining the novelty, strength, and weakness of each one. Furthermore, the most commonly used MRI datasets are highlighted and described. The main goal of this research is to offer a performance evaluation of missing modality compensating networks, as well as to outline future strategies for dealing with this issue.
Generative Steganography Network
Aug 14, 2022
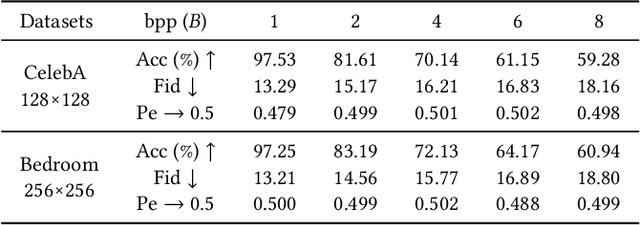
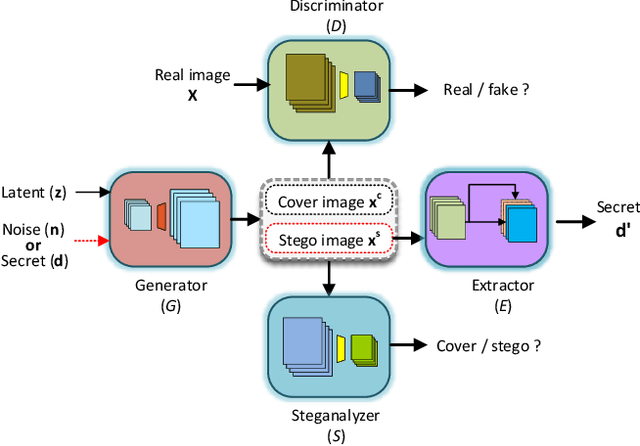
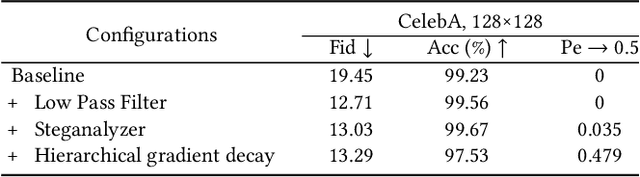
Steganography usually modifies cover media to embed secret data. A new steganographic approach called generative steganography (GS) has emerged recently, in which stego images (images containing secret data) are generated from secret data directly without cover media. However, existing GS schemes are often criticized for their poor performances. In this paper, we propose an advanced generative steganography network (GSN) that can generate realistic stego images without using cover images. We firstly introduce the mutual information mechanism in GS, which helps to achieve high secret extraction accuracy. Our model contains four sub-networks, i.e., an image generator ($G$), a discriminator ($D$), a steganalyzer ($S$), and a data extractor ($E$). $D$ and $S$ act as two adversarial discriminators to ensure the visual quality and security of generated stego images. $E$ is to extract the hidden secret from generated stego images. The generator $G$ is flexibly constructed to synthesize either cover or stego images with different inputs. It facilitates covert communication by concealing the function of generating stego images in a normal generator. A module named secret block is designed to hide secret data in the feature maps during image generation, with which high hiding capacity and image fidelity are achieved. In addition, a novel hierarchical gradient decay (HGD) skill is developed to resist steganalysis detection. Experiments demonstrate the superiority of our work over existing methods.
D3C2-Net: Dual-Domain Deep Convolutional Coding Network for Compressive Sensing
Jul 27, 2022

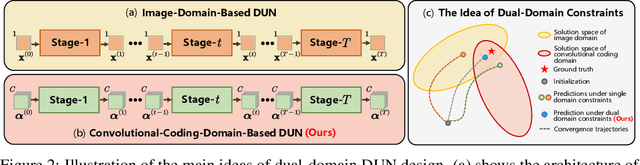
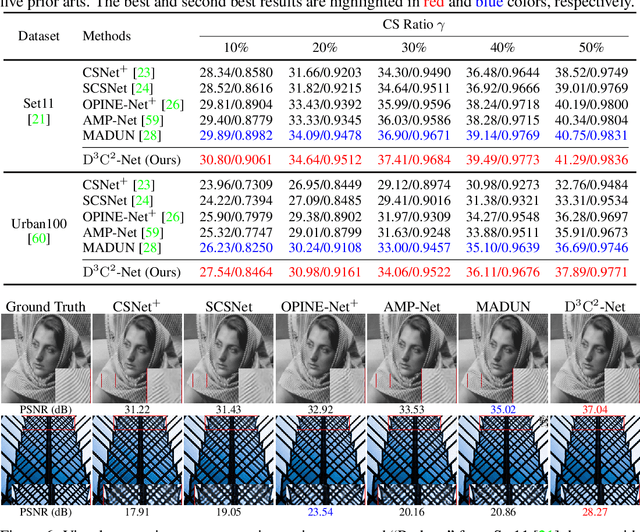
Mapping optimization algorithms into neural networks, deep unfolding networks (DUNs) have achieved impressive success in compressive sensing (CS). From the perspective of optimization, DUNs inherit a well-defined and interpretable structure from iterative steps. However, from the viewpoint of neural network design, most existing DUNs are inherently established based on traditional image-domain unfolding, which takes one-channel images as inputs and outputs between adjacent stages, resulting in insufficient information transmission capability and inevitable loss of the image details. In this paper, to break the above bottleneck, we first propose a generalized dual-domain optimization framework, which is general for inverse imaging and integrates the merits of both (1) image-domain and (2) convolutional-coding-domain priors to constrain the feasible region in the solution space. By unfolding the proposed framework into deep neural networks, we further design a novel Dual-Domain Deep Convolutional Coding Network (D3C2-Net) for CS imaging with the capability of transmitting high-throughput feature-level image representation through all the unfolded stages. Experiments on natural and MR images demonstrate that our D3C2-Net achieves higher performance and better accuracy-complexity trade-offs than other state-of-the-arts.
2nd Place Solution to Facebook AI Image Similarity Challenge Matching Track
Nov 15, 2021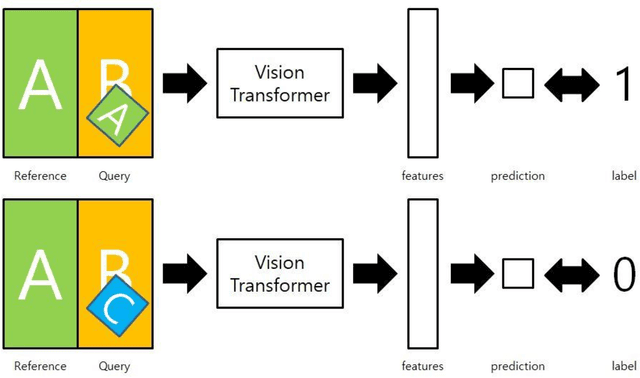
This paper presents the 2nd place solution to the Facebook AI Image Similarity Challenge : Matching Track on DrivenData. The solution is based on self-supervised learning, and Vision Transformer(ViT). The main breaktrough comes from concatenating query and reference image to form as one image and asking ViT to directly predict from the image if query image used reference image. The solution scored 0.8291 Micro-average Precision on the private leaderboard.
Maximal Independent Vertex Set applied to Graph Pooling
Aug 02, 2022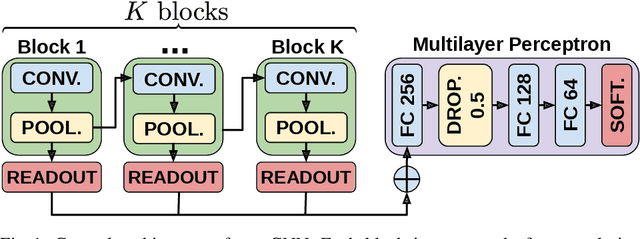
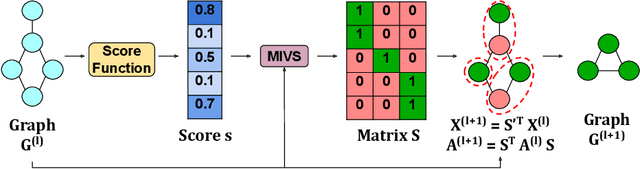

Convolutional neural networks (CNN) have enabled major advances in image classification through convolution and pooling. In particular, image pooling transforms a connected discrete grid into a reduced grid with the same connectivity and allows reduction functions to take into account all the pixels of an image. However, a pooling satisfying such properties does not exist for graphs. Indeed, some methods are based on a vertex selection step which induces an important loss of information. Other methods learn a fuzzy clustering of vertex sets which induces almost complete reduced graphs. We propose to overcome both problems using a new pooling method, named MIVSPool. This method is based on a selection of vertices called surviving vertices using a Maximal Independent Vertex Set (MIVS) and an assignment of the remaining vertices to the survivors. Consequently, our method does not discard any vertex information nor artificially increase the density of the graph. Experimental results show an increase in accuracy for graph classification on various standard datasets.
Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection
Oct 05, 2022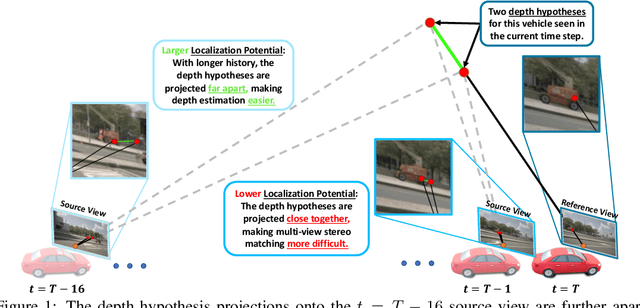
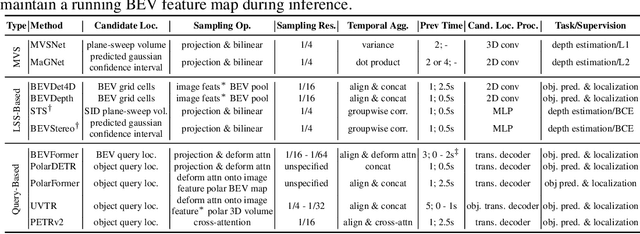
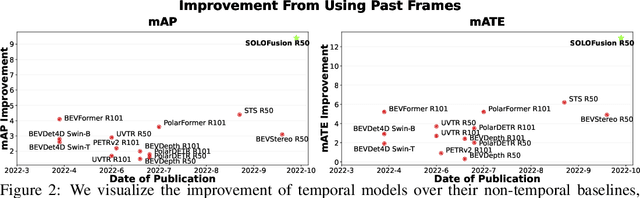
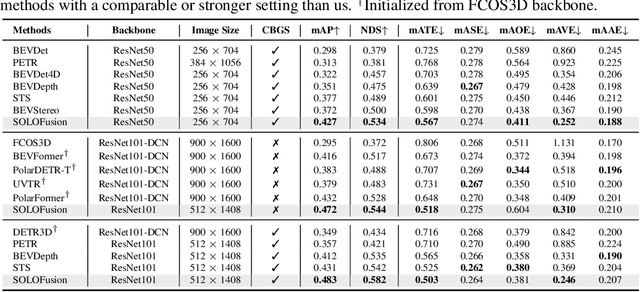
While recent camera-only 3D detection methods leverage multiple timesteps, the limited history they use significantly hampers the extent to which temporal fusion can improve object perception. Observing that existing works' fusion of multi-frame images are instances of temporal stereo matching, we find that performance is hindered by the interplay between 1) the low granularity of matching resolution and 2) the sub-optimal multi-view setup produced by limited history usage. Our theoretical and empirical analysis demonstrates that the optimal temporal difference between views varies significantly for different pixels and depths, making it necessary to fuse many timesteps over long-term history. Building on our investigation, we propose to generate a cost volume from a long history of image observations, compensating for the coarse but efficient matching resolution with a more optimal multi-view matching setup. Further, we augment the per-frame monocular depth predictions used for long-term, coarse matching with short-term, fine-grained matching and find that long and short term temporal fusion are highly complementary. While maintaining high efficiency, our framework sets new state-of-the-art on nuScenes, achieving first place on the test set and outperforming previous best art by 5.2% mAP and 3.7% NDS on the validation set. Code will be released $\href{https://github.com/Divadi/SOLOFusion}{here.}$
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Oct 05, 2022
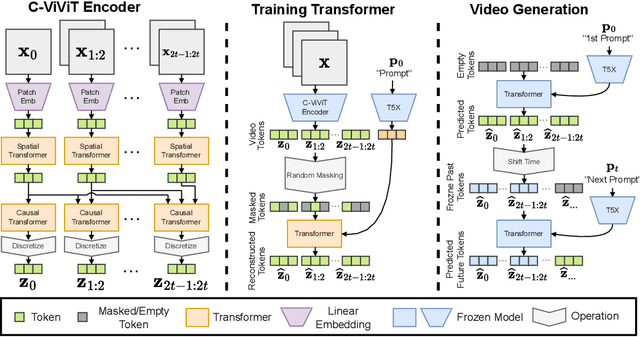


We present Phenaki, a model capable of realistic video synthesis, given a sequence of textual prompts. Generating videos from text is particularly challenging due to the computational cost, limited quantities of high quality text-video data and variable length of videos. To address these issues, we introduce a new model for learning video representation which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text we are using a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, we demonstrate how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to the previous video generation methods, Phenaki can generate arbitrary long videos conditioned on a sequence of prompts (i.e. time variable text or a story) in open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time variable prompts. In addition, compared to the per-frame baselines, the proposed video encoder-decoder computes fewer tokens per video but results in better spatio-temporal consistency.
Fully Transformer Network for Change Detection of Remote Sensing Images
Oct 03, 2022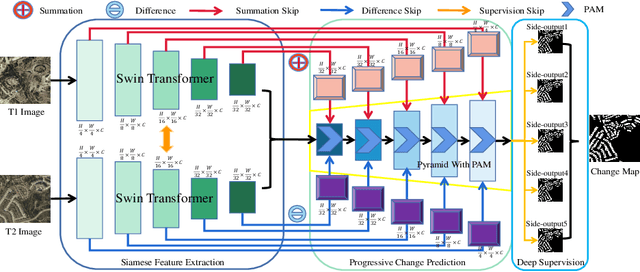
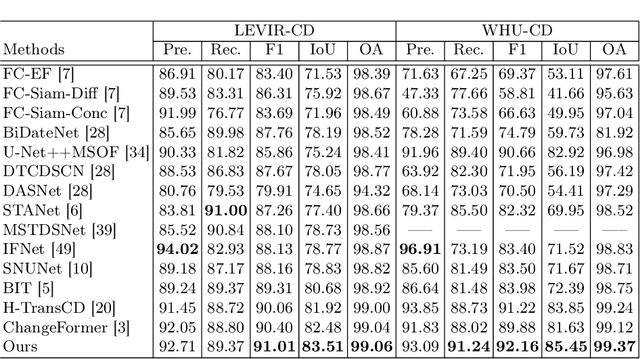
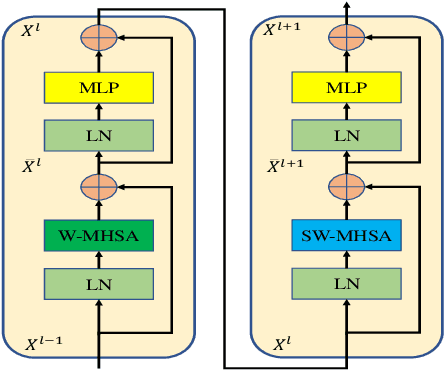
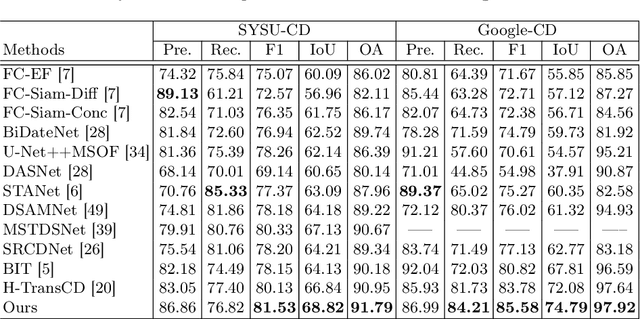
Recently, change detection (CD) of remote sensing images have achieved great progress with the advances of deep learning. However, current methods generally deliver incomplete CD regions and irregular CD boundaries due to the limited representation ability of the extracted visual features. To relieve these issues, in this work we propose a novel learning framework named Fully Transformer Network (FTN) for remote sensing image CD, which improves the feature extraction from a global view and combines multi-level visual features in a pyramid manner. More specifically, the proposed framework first utilizes the advantages of Transformers in long-range dependency modeling. It can help to learn more discriminative global-level features and obtain complete CD regions. Then, we introduce a pyramid structure to aggregate multi-level visual features from Transformers for feature enhancement. The pyramid structure grafted with a Progressive Attention Module (PAM) can improve the feature representation ability with additional interdependencies through channel attentions. Finally, to better train the framework, we utilize the deeply-supervised learning with multiple boundaryaware loss functions. Extensive experiments demonstrate that our proposed method achieves a new state-of-the-art performance on four public CD benchmarks. For model reproduction, the source code is released at https://github.com/AI-Zhpp/FTN.
Wheel Impact Test by Deep Learning: Prediction of Location and Magnitude of Maximum Stress
Oct 03, 2022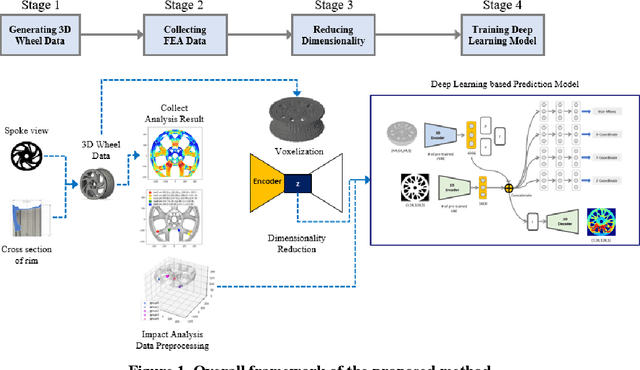
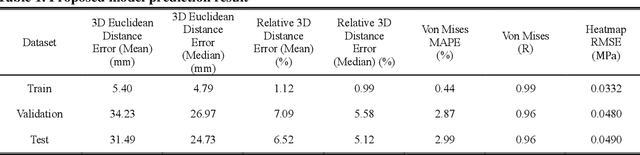
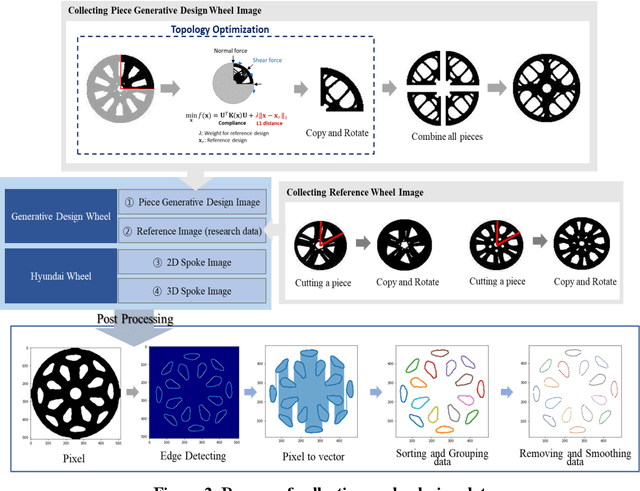
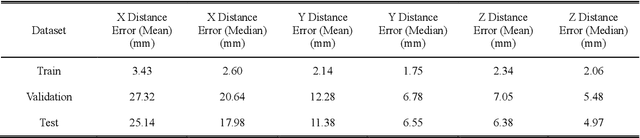
The impact performance of the wheel during wheel development must be ensured through a wheel impact test for vehicle safety. However, manufacturing and testing a real wheel take a significant amount of time and money because developing an optimal wheel design requires numerous iterative processes of modifying the wheel design and verifying the safety performance. Accordingly, the actual wheel impact test has been replaced by computer simulations, such as Finite Element Analysis (FEA), but it still requires high computational costs for modeling and analysis. Moreover, FEA experts are needed. This study presents an aluminum road wheel impact performance prediction model based on deep learning that replaces the computationally expensive and time-consuming 3D FEA. For this purpose, 2D disk-view wheel image data, 3D wheel voxel data, and barrier mass value used for wheel impact test are utilized as the inputs to predict the magnitude of maximum von Mises stress, corresponding location, and the stress distribution of 2D disk-view. The wheel impact performance prediction model can replace the impact test in the early wheel development stage by predicting the impact performance in real time and can be used without domain knowledge. The time required for the wheel development process can be shortened through this mechanism.