 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Creative Painting with Latent Diffusion Models
Sep 30, 2022
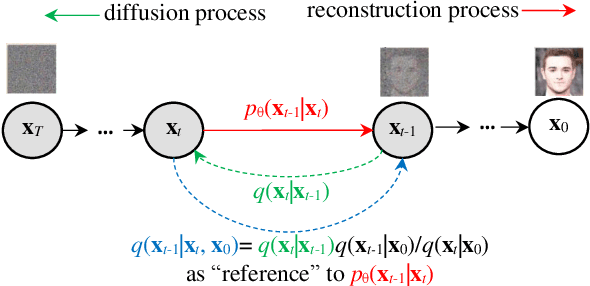
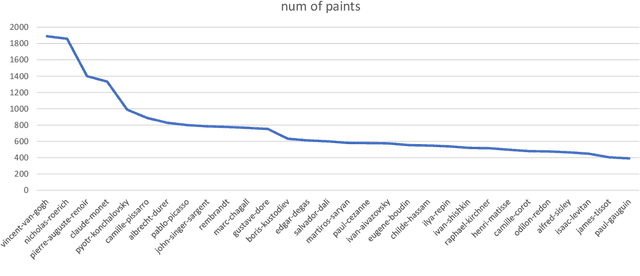
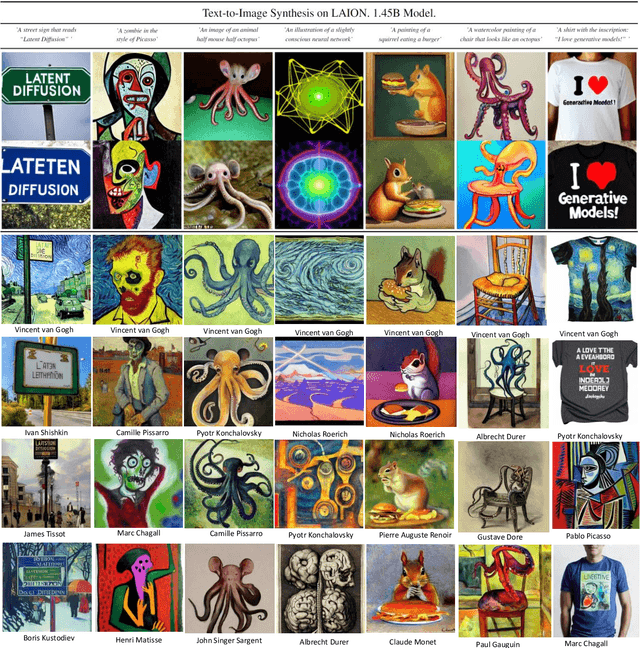
Artistic painting has achieved significant progress during recent years. Using an autoencoder to connect the original images with compressed latent spaces and a cross attention enhanced U-Net as the backbone of diffusion, latent diffusion models (LDMs) have achieved stable and high fertility image generation. In this paper, we focus on enhancing the creative painting ability of current LDMs in two directions, textual condition extension and model retraining with Wikiart dataset. Through textual condition extension, users' input prompts are expanded with rich contextual knowledge for deeper understanding and explaining the prompts. Wikiart dataset contains 80K famous artworks drawn during recent 400 years by more than 1,000 famous artists in rich styles and genres. Through the retraining, we are able to ask these artists to draw novel and creative painting on modern topics. Direct comparisons with the original model show that the creativity and artistry are enriched.
A new perspective on probabilistic image modeling
Mar 21, 2022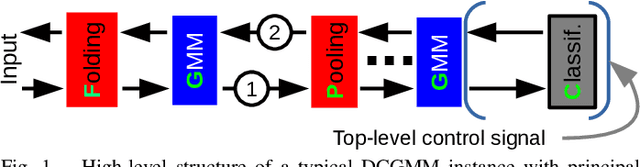
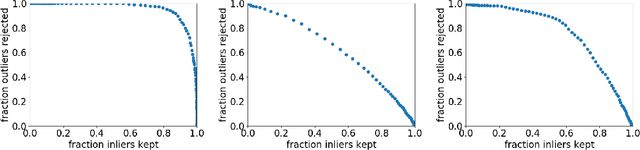

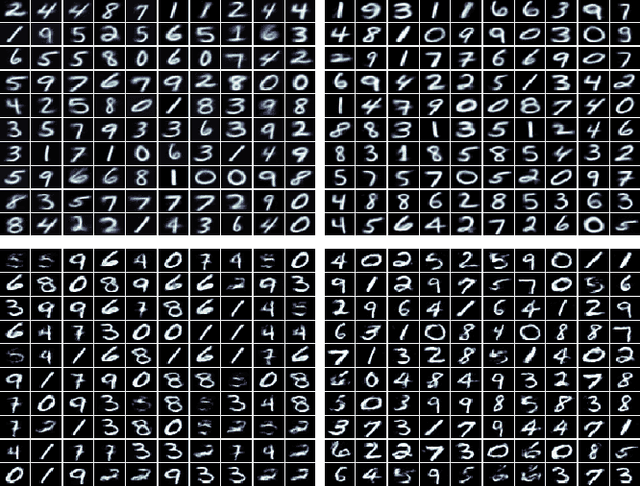
We present the Deep Convolutional Gaussian Mixture Model (DCGMM), a new probabilistic approach for image modeling capable of density estimation, sampling and tractable inference. DCGMM instances exhibit a CNN-like layered structure, in which the principal building blocks are convolutional Gaussian Mixture (cGMM) layers. A key innovation w.r.t. related models like sum-product networks (SPNs) and probabilistic circuits (PCs) is that each cGMM layer optimizes an independent loss function and therefore has an independent probabilistic interpretation. This modular approach permits intervening transformation layers to harness the full spectrum of (potentially non-invertible) mappings available to CNNs, e.g., max-pooling or half-convolutions. DCGMM sampling and inference are realized by a deep chain of hierarchical priors, where a sample generated by a given cGMM layer defines the parameters of sampling in the next-lower cGMM layer. For sampling through non-invertible transformation layers, we introduce a new gradient-based sharpening technique that exploits redundancy (overlap) in, e.g., half-convolutions. DCGMMs can be trained end-to-end by SGD from random initial conditions, much like CNNs. We show that DCGMMs compare favorably to several recent PC and SPN models in terms of inference, classification and sampling, the latter particularly for challenging datasets such as SVHN. We provide a public TF2 implementation.
ExCon: Explanation-driven Supervised Contrastive Learning for Image Classification
Dec 10, 2021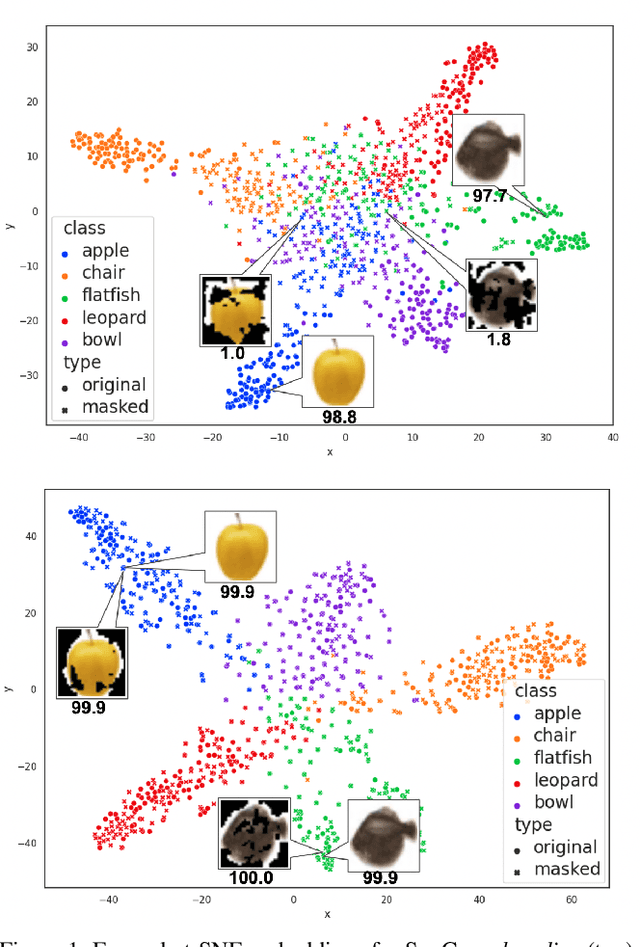
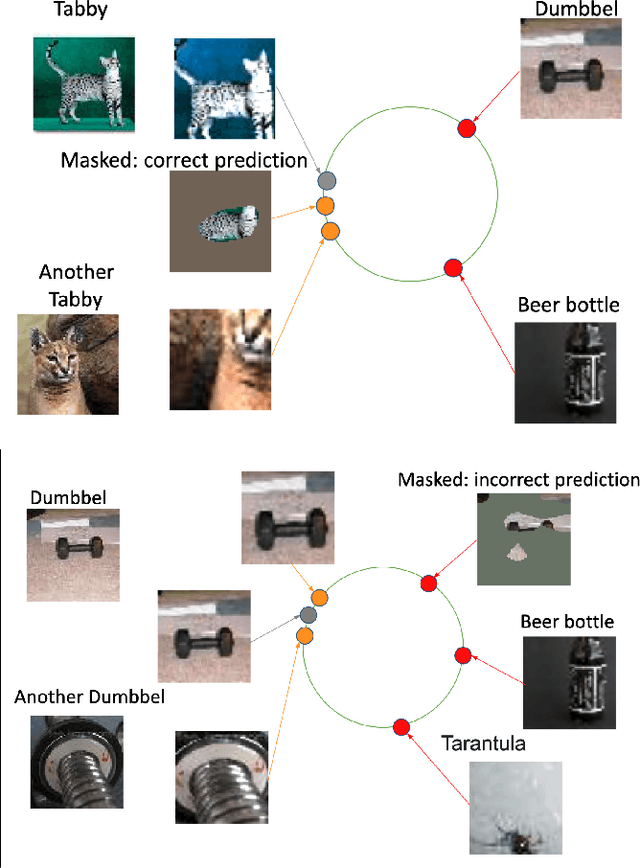
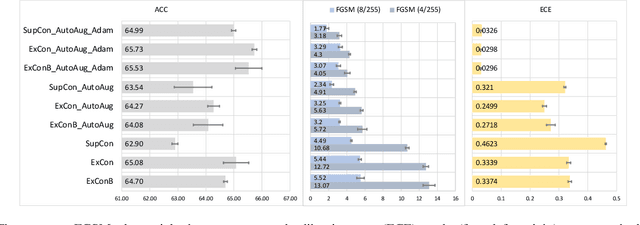
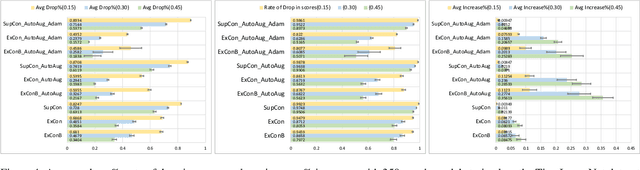
Contrastive learning has led to substantial improvements in the quality of learned embedding representations for tasks such as image classification. However, a key drawback of existing contrastive augmentation methods is that they may lead to the modification of the image content which can yield undesired alterations of its semantics. This can affect the performance of the model on downstream tasks. Hence, in this paper, we ask whether we can augment image data in contrastive learning such that the task-relevant semantic content of an image is preserved. For this purpose, we propose to leverage saliency-based explanation methods to create content-preserving masked augmentations for contrastive learning. Our novel explanation-driven supervised contrastive learning (ExCon) methodology critically serves the dual goals of encouraging nearby image embeddings to have similar content and explanation. To quantify the impact of ExCon, we conduct experiments on the CIFAR-100 and the Tiny ImageNet datasets. We demonstrate that ExCon outperforms vanilla supervised contrastive learning in terms of classification, explanation quality, adversarial robustness as well as calibration of probabilistic predictions of the model in the context of distributional shift.
Mapping the ocular surface from monocular videos with an application to dry eye disease grading
Sep 05, 2022With a prevalence of 5 to 50%, Dry Eye Disease (DED) is one of the leading reasons for ophthalmologist consultations. The diagnosis and quantification of DED usually rely on ocular surface analysis through slit-lamp examinations. However, evaluations are subjective and non-reproducible. To improve the diagnosis, we propose to 1) track the ocular surface in 3-D using video recordings acquired during examinations, and 2) grade the severity using registered frames. Our registration method uses unsupervised image-to-depth learning. These methods learn depth from lights and shadows and estimate pose based on depth maps. However, DED examinations undergo unresolved challenges including a moving light source, transparent ocular tissues, etc. To overcome these and estimate the ego-motion, we implement joint CNN architectures with multiple losses incorporating prior known information, namely the shape of the eye, through semantic segmentation as well as sphere fitting. The achieved tracking errors outperform the state-of-the-art, with a mean Euclidean distance as low as 0.48% of the image width on our test set. This registration improves the DED severity classification by a 0.20 AUC difference. The proposed approach is the first to address DED diagnosis with supervision from monocular videos
Application of Transfer Learning and Ensemble Learning in Image-level Classification for Breast Histopathology
Apr 18, 2022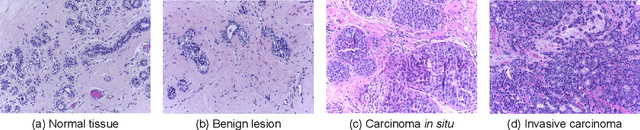

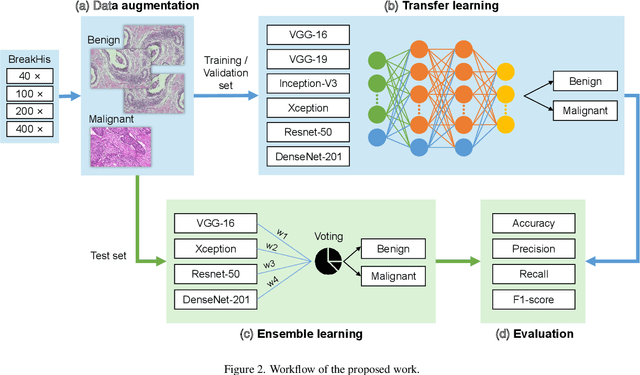
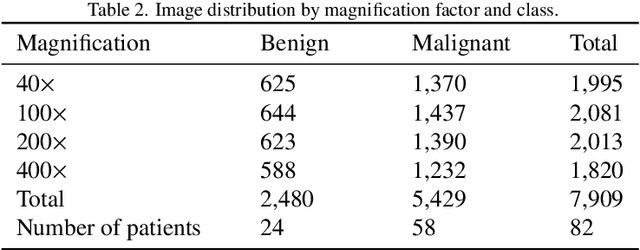
Background: Breast cancer has the highest prevalence in women globally. The classification and diagnosis of breast cancer and its histopathological images have always been a hot spot of clinical concern. In Computer-Aided Diagnosis (CAD), traditional classification models mostly use a single network to extract features, which has significant limitations. On the other hand, many networks are trained and optimized on patient-level datasets, ignoring the application of lower-level data labels. Method: This paper proposes a deep ensemble model based on image-level labels for the binary classification of benign and malignant lesions of breast histopathological images. First, the BreakHis dataset is randomly divided into a training, validation and test set. Then, data augmentation techniques are used to balance the number of benign and malignant samples. Thirdly, considering the performance of transfer learning and the complementarity between each network, VGG-16, Xception, Resnet-50, DenseNet-201 are selected as the base classifiers. Result: In the ensemble network model with accuracy as the weight, the image-level binary classification achieves an accuracy of $98.90\%$. In order to verify the capabilities of our method, the latest Transformer and Multilayer Perception (MLP) models have been experimentally compared on the same dataset. Our model wins with a $5\%-20\%$ advantage, emphasizing the ensemble model's far-reaching significance in classification tasks. Conclusion: This research focuses on improving the model's classification performance with an ensemble algorithm. Transfer learning plays an essential role in small datasets, improving training speed and accuracy. Our model has outperformed many existing approaches in accuracy, providing a method for the field of auxiliary medical diagnosis.
Compliance Challenges in Forensic Image Analysis Under the Artificial Intelligence Act
Mar 01, 2022In many applications of forensic image analysis, state-of-the-art results are nowadays achieved with machine learning methods. However, concerns about their reliability and opaqueness raise the question whether such methods can be used in criminal investigations. So far, this question of legal compliance has hardly been discussed, also because legal regulations for machine learning methods were not defined explicitly. To this end, the European Commission recently proposed the artificial intelligence (AI) act, a regulatory framework for the trustworthy use of AI. Under the draft AI act, high-risk AI systems for use in law enforcement are permitted but subject to compliance with mandatory requirements. In this paper, we review why the use of machine learning in forensic image analysis is classified as high-risk. We then summarize the mandatory requirements for high-risk AI systems and discuss these requirements in light of two forensic applications, license plate recognition and deep fake detection. The goal of this paper is to raise awareness of the upcoming legal requirements and to point out avenues for future research.
TypoSwype: An Imaging Approach to Detect Typo-Squatting
Sep 02, 2022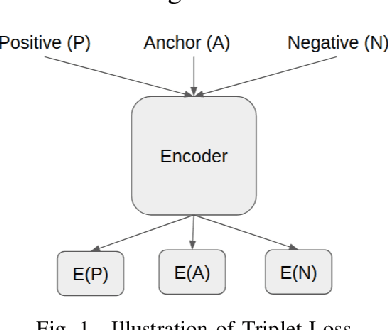
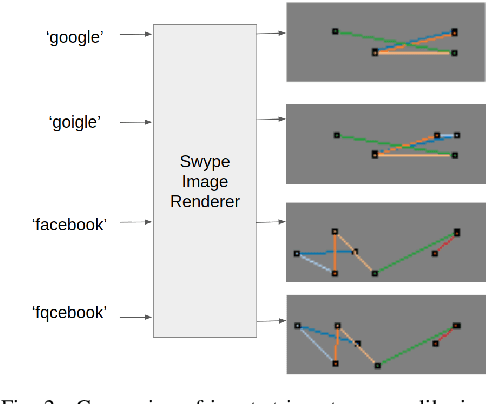
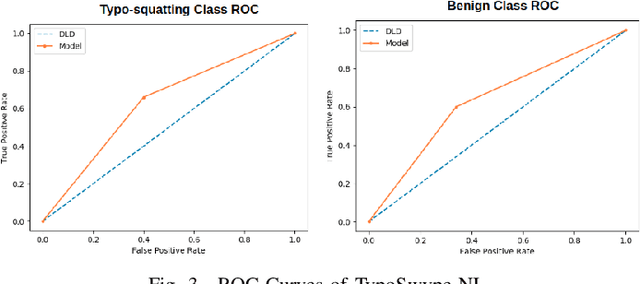

Typo-squatting domains are a common cyber-attack technique. It involves utilising domain names, that exploit possible typographical errors of commonly visited domains, to carry out malicious activities such as phishing, malware installation, etc. Current approaches typically revolve around string comparison algorithms like the Demaru-Levenschtein Distance (DLD) algorithm. Such techniques do not take into account keyboard distance, which researchers find to have a strong correlation with typical typographical errors and are trying to take account of. In this paper, we present the TypoSwype framework which converts strings to images that take into account keyboard location innately. We also show how modern state of the art image recognition techniques involving Convolutional Neural Networks, trained via either Triplet Loss or NT-Xent Loss, can be applied to learn a mapping to a lower dimensional space where distances correspond to image, and equivalently, textual similarity. Finally, we also demonstrate our method's ability to improve typo-squatting detection over the widely used DLD algorithm, while maintaining the classification accuracy as to which domain the input domain was attempting to typo-squat.
Exploring Dual-task Correlation for Pose Guided Person Image Generation
Mar 06, 2022

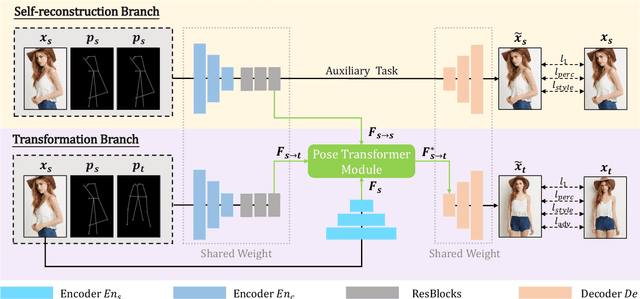
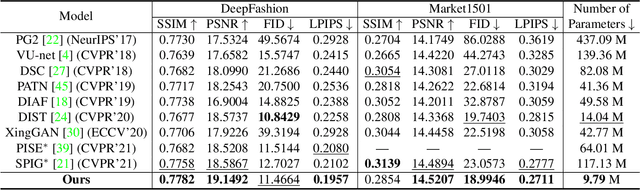
Pose Guided Person Image Generation (PGPIG) is the task of transforming a person image from the source pose to a given target pose. Most of the existing methods only focus on the ill-posed source-to-target task and fail to capture reasonable texture mapping. To address this problem, we propose a novel Dual-task Pose Transformer Network (DPTN), which introduces an auxiliary task (i.e., source-to-source task) and exploits the dual-task correlation to promote the performance of PGPIG. The DPTN is of a Siamese structure, containing a source-to-source self-reconstruction branch, and a transformation branch for source-to-target generation. By sharing partial weights between them, the knowledge learned by the source-to-source task can effectively assist the source-to-target learning. Furthermore, we bridge the two branches with a proposed Pose Transformer Module (PTM) to adaptively explore the correlation between features from dual tasks. Such correlation can establish the fine-grained mapping of all the pixels between the sources and the targets, and promote the source texture transmission to enhance the details of the generated target images. Extensive experiments show that our DPTN outperforms state-of-the-arts in terms of both PSNR and LPIPS. In addition, our DPTN only contains 9.79 million parameters, which is significantly smaller than other approaches. Our code is available at: https://github.com/PangzeCheung/Dual-task-Pose-Transformer-Network.
Depth Is All You Need for Monocular 3D Detection
Oct 05, 2022
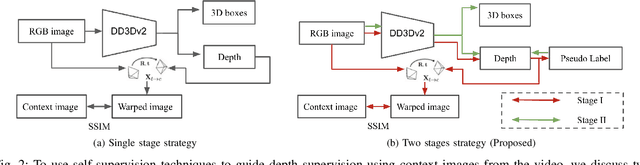

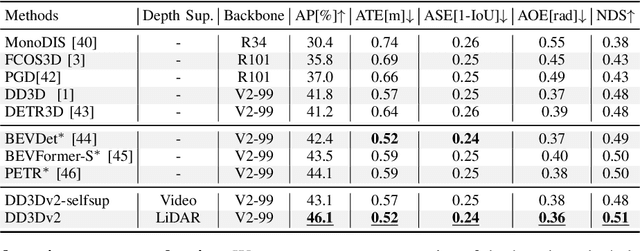
A key contributor to recent progress in 3D detection from single images is monocular depth estimation. Existing methods focus on how to leverage depth explicitly, by generating pseudo-pointclouds or providing attention cues for image features. More recent works leverage depth prediction as a pretraining task and fine-tune the depth representation while training it for 3D detection. However, the adaptation is insufficient and is limited in scale by manual labels. In this work, we propose to further align depth representation with the target domain in unsupervised fashions. Our methods leverage commonly available LiDAR or RGB videos during training time to fine-tune the depth representation, which leads to improved 3D detectors. Especially when using RGB videos, we show that our two-stage training by first generating pseudo-depth labels is critical because of the inconsistency in loss distribution between the two tasks. With either type of reference data, our multi-task learning approach improves over the state of the art on both KITTI and NuScenes, while matching the test-time complexity of its single task sub-network.
STSC-SNN: Spatio-Temporal Synaptic Connection with Temporal Convolution and Attention for Spiking Neural Networks
Oct 11, 2022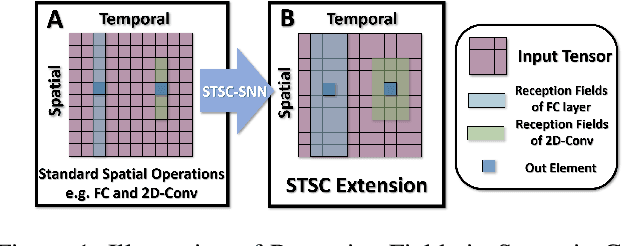
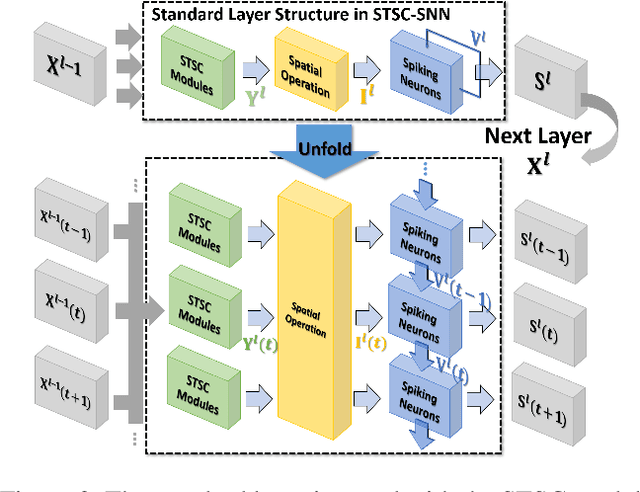
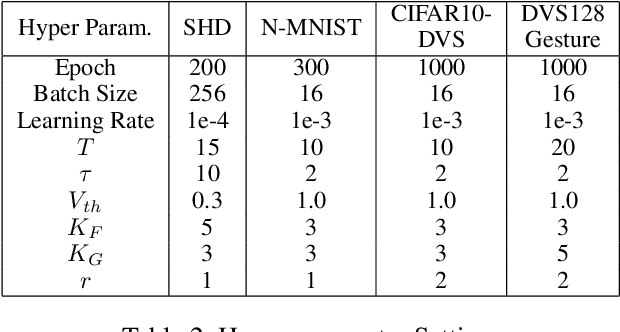
Spiking Neural Networks (SNNs), as one of the algorithmic models in neuromorphic computing, have gained a great deal of research attention owing to temporal information processing capability, low power consumption, and high biological plausibility. The potential to efficiently extract spatio-temporal features makes it suitable for processing the event streams. However, existing synaptic structures in SNNs are almost full-connections or spatial 2D convolution, neither of which can extract temporal dependencies adequately. In this work, we take inspiration from biological synapses and propose a spatio-temporal synaptic connection SNN (STSC-SNN) model, to enhance the spatio-temporal receptive fields of synaptic connections, thereby establishing temporal dependencies across layers. Concretely, we incorporate temporal convolution and attention mechanisms to implement synaptic filtering and gating functions. We show that endowing synaptic models with temporal dependencies can improve the performance of SNNs on classification tasks. In addition, we investigate the impact of performance vias varied spatial-temporal receptive fields and reevaluate the temporal modules in SNNs. Our approach is tested on neuromorphic datasets, including DVS128 Gesture (gesture recognition), N-MNIST, CIFAR10-DVS (image classification), and SHD (speech digit recognition). The results show that the proposed model outperforms the state-of-the-art accuracy on nearly all datasets.