 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic Image Cropping
Jul 15, 2021

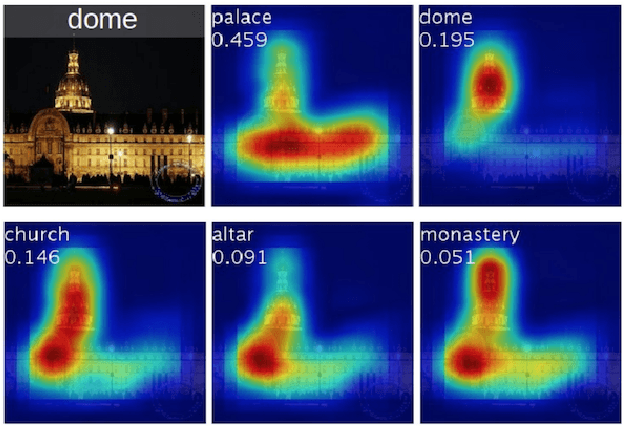

Automatic image cropping techniques are commonly used to enhance the aesthetic quality of an image; they do it by detecting the most beautiful or the most salient parts of the image and removing the unwanted content to have a smaller image that is more visually pleasing. In this thesis, I introduce an additional dimension to the problem of cropping, semantics. I argue that image cropping can also enhance the image's relevancy for a given entity by using the semantic information contained in the image. I call this problem, Semantic Image Cropping. To support my argument, I provide a new dataset containing 100 images with at least two different entities per image and four ground truth croppings collected using Amazon Mechanical Turk. I use this dataset to show that state-of-the-art cropping algorithms that only take into account aesthetics do not perform well in the problem of semantic image cropping. Additionally, I provide a new deep learning system that takes not just aesthetics but also semantics into account to generate image croppings, and I evaluate its performance using my new semantic cropping dataset, showing that using the semantic information of an image can help to produce better croppings.
Bayesian Regularization on Function Spaces via Q-Exponential Process
Oct 14, 2022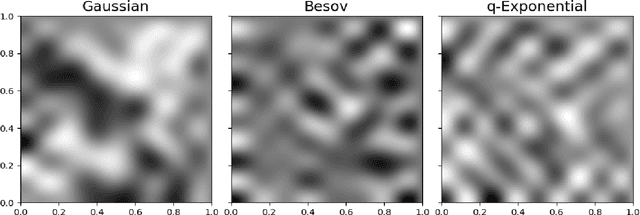
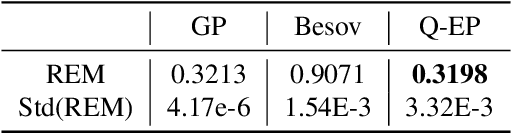
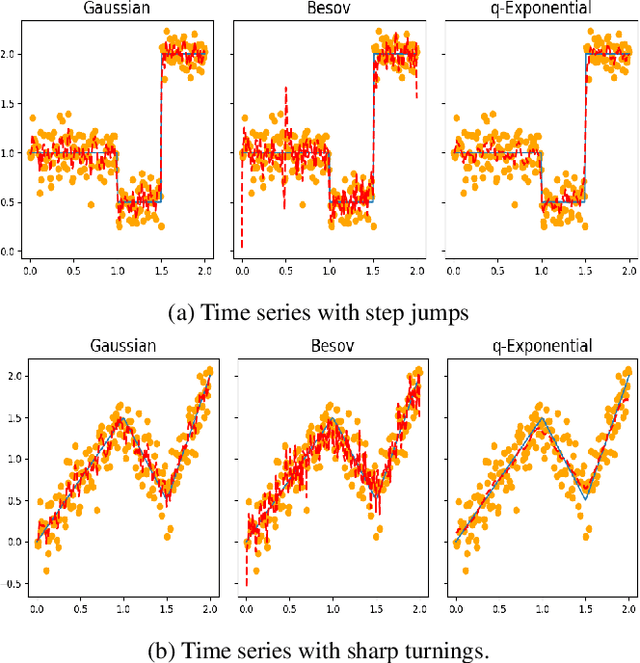
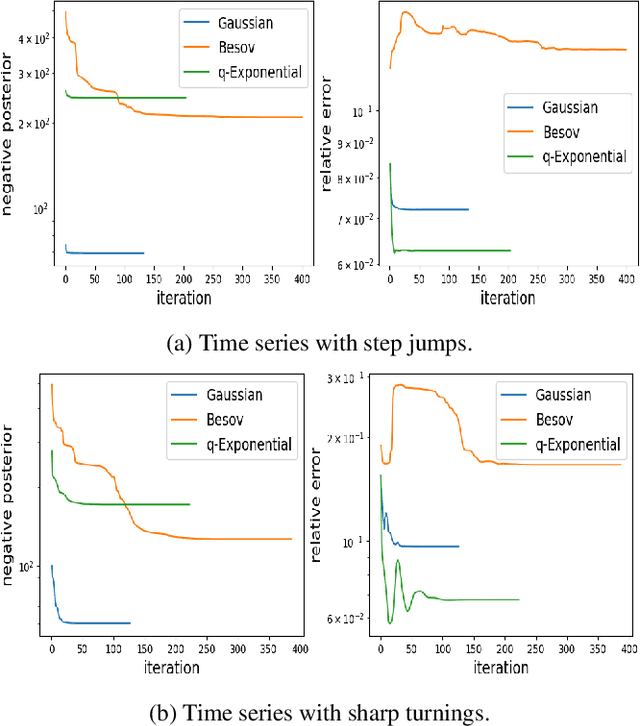
Regularization is one of the most important topics in optimization, statistics and machine learning. To get sparsity in estimating a parameter $u\in\mbR^d$, an $\ell_q$ penalty term, $\Vert u\Vert_q$, is usually added to the objective function. What is the probabilistic distribution corresponding to such $\ell_q$ penalty? What is the correct stochastic process corresponding to $\Vert u\Vert_q$ when we model functions $u\in L^q$? This is important for statistically modeling large dimensional objects, e.g. images, with penalty to preserve certainty properties, e.g. edges in the image. In this work, we generalize the $q$-exponential distribution (with density proportional to) $\exp{(- \half|u|^q)}$ to a stochastic process named \emph{$Q$-exponential (Q-EP) process} that corresponds to the $L_q$ regularization of functions. The key step is to specify consistent multivariate $q$-exponential distributions by choosing from a large family of elliptic contour distributions. The work is closely related to Besov process which is usually defined by the expanded series. Q-EP can be regarded as a definition of Besov process with explicit probabilistic formulation and direct control on the correlation length. From the Bayesian perspective, Q-EP provides a flexible prior on functions with sharper penalty ($q<2$) than the commonly used Gaussian process (GP). We compare GP, Besov and Q-EP in modeling time series and reconstructing images and demonstrate the advantage of the proposed methodology.
Surface abnormality detection in medical and inspection systems using energy variations in co-occurrence matrixes
Oct 14, 2022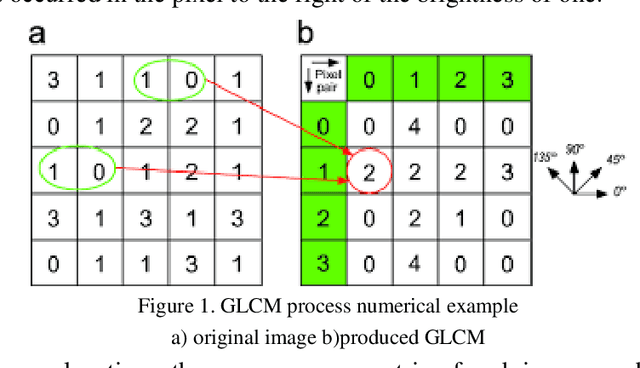


Detection of surface defects is one of the most important issues in the field of image processing and machine vision. In this article, a method for detecting surface defects based on energy changes in co-occurrence matrices is presented. The presented method consists of two stages of training and testing. In the training phase, the co-occurrence matrix operator is first applied on healthy images and then the amount of output energy is calculated. In the following, according to the changes in the amount of energy, a suitable feature vector is defined, and with the help of it, a suitable threshold for the health of the images is obtained. Then, in the test phase, with the help of the calculated quorum, the defective parts are distinguished from the healthy ones. In the results section, the mentioned method has been applied on stone and ceramic images and its detection accuracy has been calculated and compared with some previous methods. Among the advantages of the presented method, we can mention high accuracy, low calculations and compatibility with all types of levels due to the use of the training stage. The proposed approach can be used in medical applications to detect abnormalities such as diseases. So, the performance is evaluated on 2d-hela dataset to classify cell phenotypes. The proposed approach provides about 89.56 percent accuracy on 2d-hela.
Advanced Deep Learning Architectures for Accurate Detection of Subsurface Tile Drainage Pipes from Remote Sensing Images
Oct 05, 2022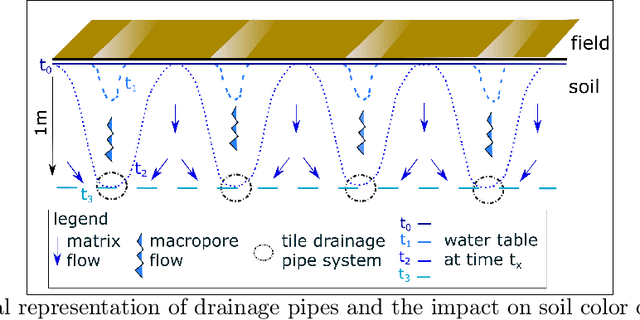
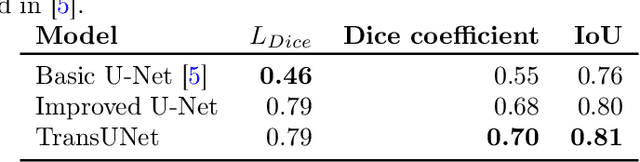
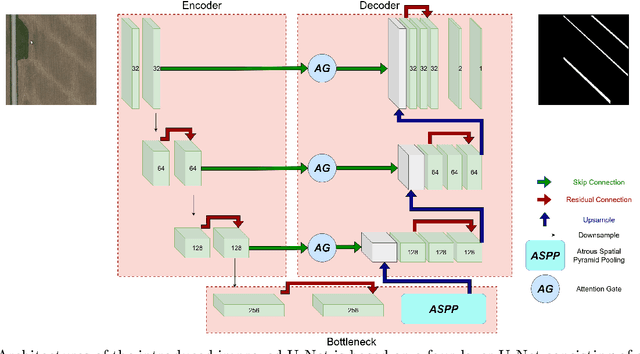
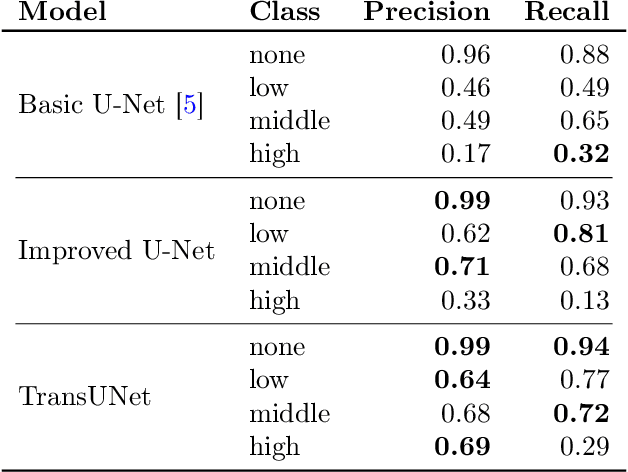
Subsurface tile drainage pipes provide agronomic, economic and environmental benefits. By lowering the water table of wet soils, they improve the aeration of plant roots and ultimately increase the productivity of farmland. They do however also provide an entryway of agrochemicals into subsurface water bodies and increase nutrition loss in soils. For maintenance and infrastructural development, accurate maps of tile drainage pipe locations and drained agricultural land are needed. However, these maps are often outdated or not present. Different remote sensing (RS) image processing techniques have been applied over the years with varying degrees of success to overcome these restrictions. Recent developments in deep learning (DL) techniques improve upon the conventional techniques with machine learning segmentation models. In this study, we introduce two DL-based models: i) improved U-Net architecture; and ii) Visual Transformer-based encoder-decoder in the framework of tile drainage pipe detection. Experimental results confirm the effectiveness of both models in terms of detection accuracy when compared to a basic U-Net architecture. Our code and models are publicly available at \url{https://git.tu-berlin.de/rsim/drainage-pipes-detection}.
Instance-Dependent Noisy Label Learning via Graphical Modelling
Sep 02, 2022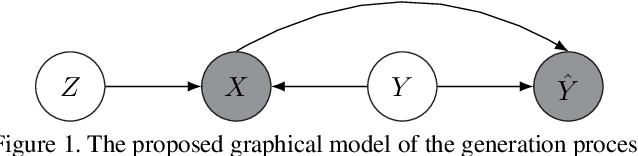
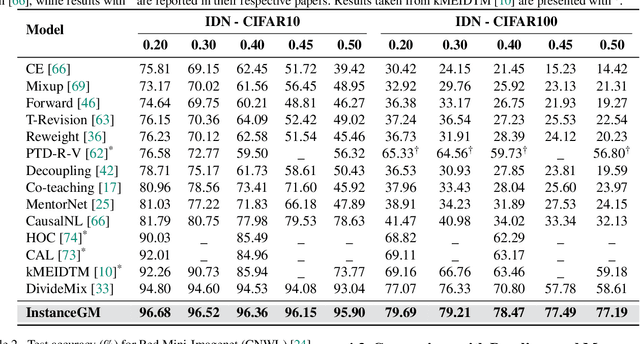
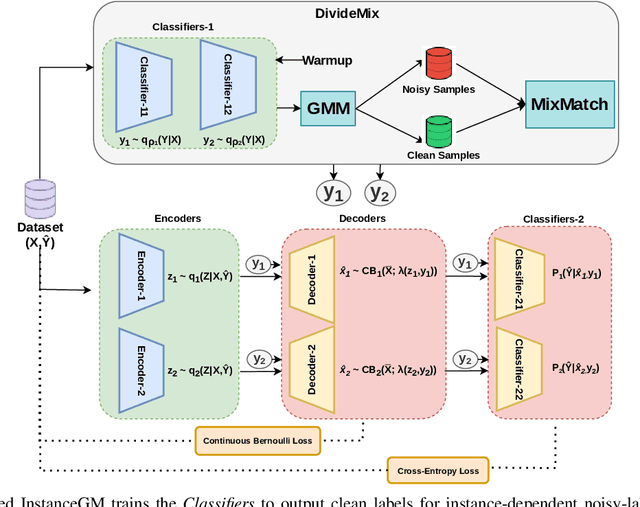
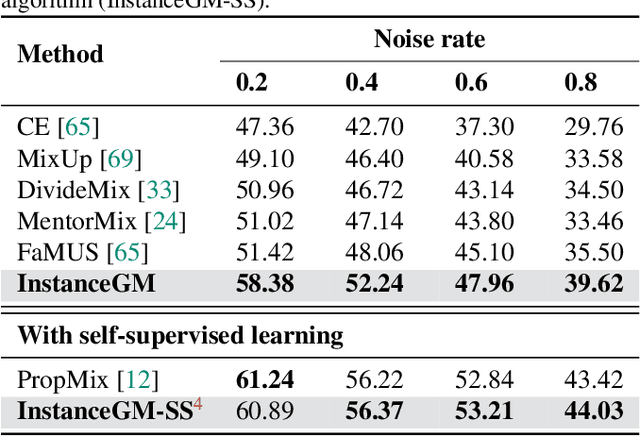
Noisy labels are unavoidable yet troublesome in the ecosystem of deep learning because models can easily overfit them. There are many types of label noise, such as symmetric, asymmetric and instance-dependent noise (IDN), with IDN being the only type that depends on image information. Such dependence on image information makes IDN a critical type of label noise to study, given that labelling mistakes are caused in large part by insufficient or ambiguous information about the visual classes present in images. Aiming to provide an effective technique to address IDN, we present a new graphical modelling approach called InstanceGM, that combines discriminative and generative models. The main contributions of InstanceGM are: i) the use of the continuous Bernoulli distribution to train the generative model, offering significant training advantages, and ii) the exploration of a state-of-the-art noisy-label discriminative classifier to generate clean labels from instance-dependent noisy-label samples. InstanceGM is competitive with current noisy-label learning approaches, particularly in IDN benchmarks using synthetic and real-world datasets, where our method shows better accuracy than the competitors in most experiments.
MaIL: A Unified Mask-Image-Language Trimodal Network for Referring Image Segmentation
Nov 21, 2021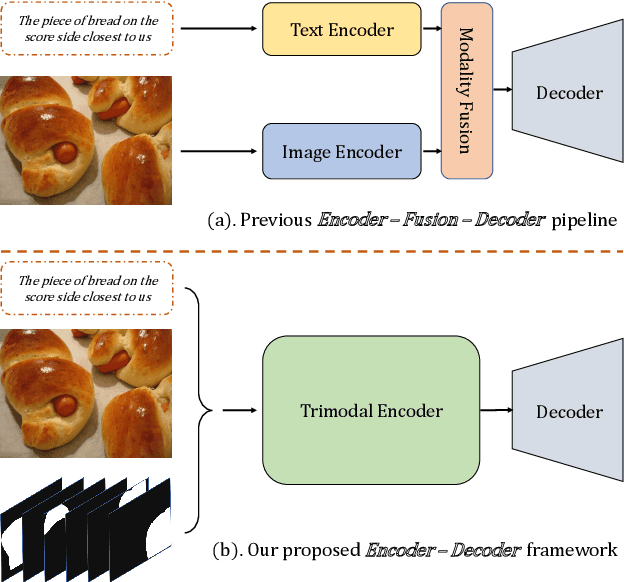
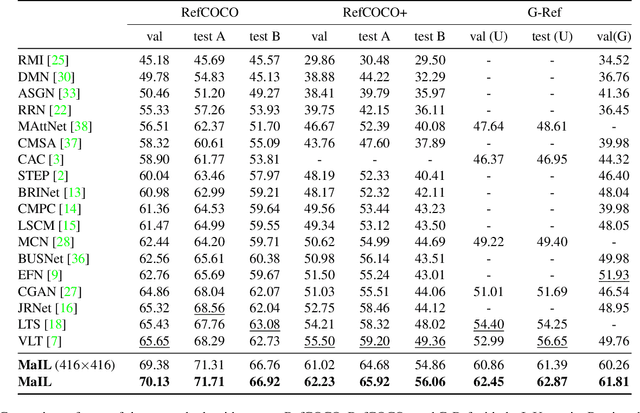
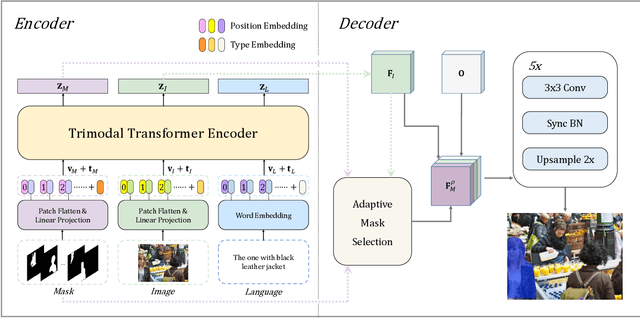
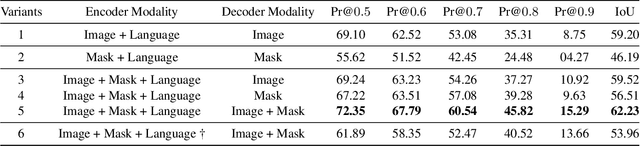
Referring image segmentation is a typical multi-modal task, which aims at generating a binary mask for referent described in given language expressions. Prior arts adopt a bimodal solution, taking images and languages as two modalities within an encoder-fusion-decoder pipeline. However, this pipeline is sub-optimal for the target task for two reasons. First, they only fuse high-level features produced by uni-modal encoders separately, which hinders sufficient cross-modal learning. Second, the uni-modal encoders are pre-trained independently, which brings inconsistency between pre-trained uni-modal tasks and the target multi-modal task. Besides, this pipeline often ignores or makes little use of intuitively beneficial instance-level features. To relieve these problems, we propose MaIL, which is a more concise encoder-decoder pipeline with a Mask-Image-Language trimodal encoder. Specifically, MaIL unifies uni-modal feature extractors and their fusion model into a deep modality interaction encoder, facilitating sufficient feature interaction across different modalities. Meanwhile, MaIL directly avoids the second limitation since no uni-modal encoders are needed anymore. Moreover, for the first time, we propose to introduce instance masks as an additional modality, which explicitly intensifies instance-level features and promotes finer segmentation results. The proposed MaIL set a new state-of-the-art on all frequently-used referring image segmentation datasets, including RefCOCO, RefCOCO+, and G-Ref, with significant gains, 3%-10% against previous best methods. Code will be released soon.
Neural KEM: A Kernel Method with Deep Coefficient Prior for PET Image Reconstruction
Jan 05, 2022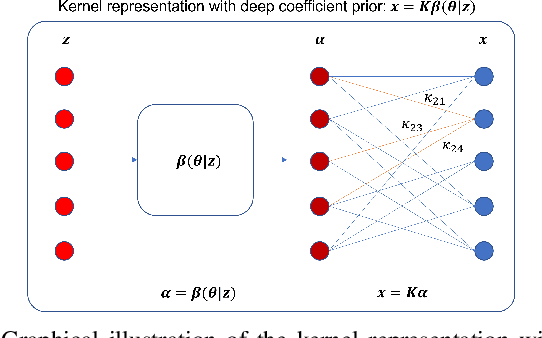
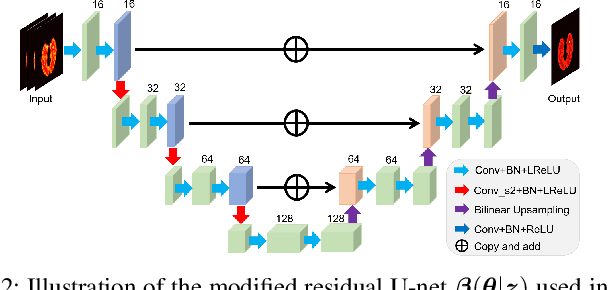
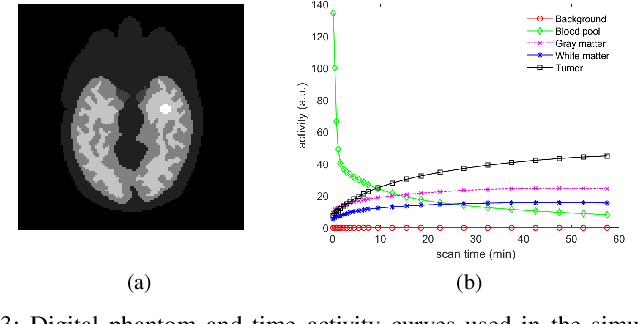
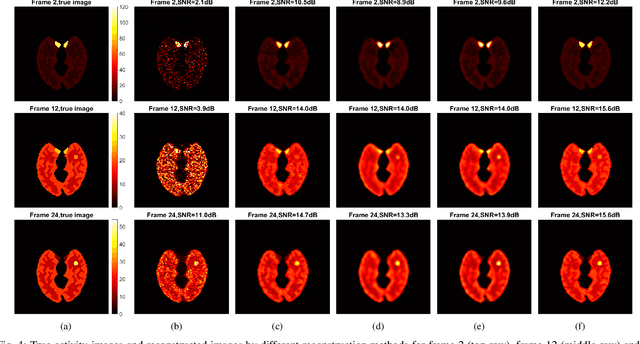
Image reconstruction of low-count positron emission tomography (PET) data is challenging. Kernel methods address the challenge by incorporating image prior information in the forward model of iterative PET image reconstruction. The kernelized expectation-maximization (KEM) algorithm has been developed and demonstrated to be effective and easy to implement. A common approach for a further improvement of the kernel method would be adding an explicit regularization, which however leads to a complex optimization problem. In this paper, we propose an implicit regularization for the kernel method by using a deep coefficient prior, which represents the kernel coefficient image in the PET forward model using a convolutional neural-network. To solve the maximum-likelihood neural network-based reconstruction problem, we apply the principle of optimization transfer to derive a neural KEM algorithm. Each iteration of the algorithm consists of two separate steps: a KEM step for image update from the projection data and a deep-learning step in the image domain for updating the kernel coefficient image using the neural network. This optimization algorithm is guaranteed to monotonically increase the data likelihood. The results from computer simulations and real patient data have demonstrated that the neural KEM can outperform existing KEM and deep image prior methods.
Creative Painting with Latent Diffusion Models
Sep 30, 2022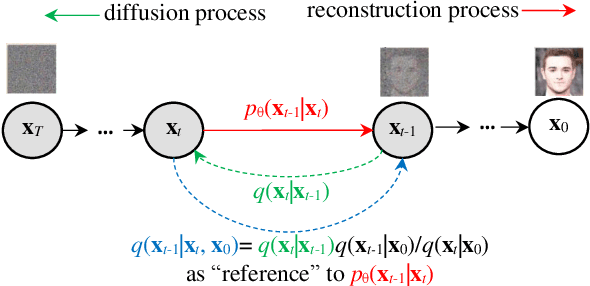
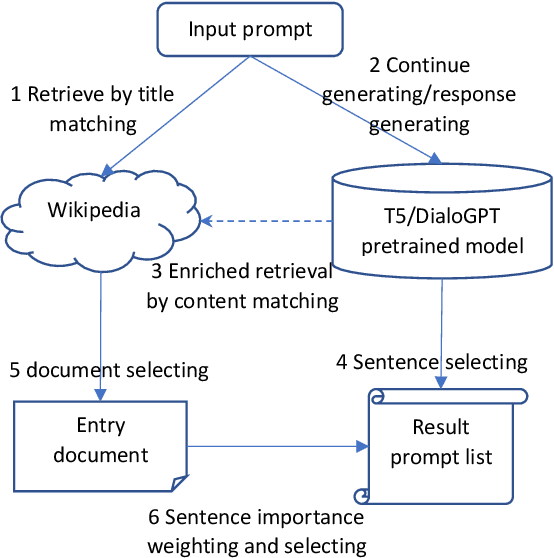
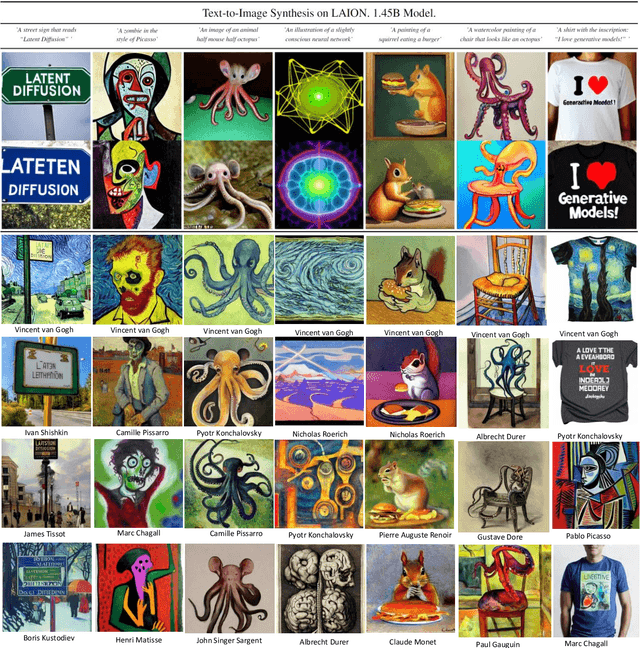
Artistic painting has achieved significant progress during recent years. Using an autoencoder to connect the original images with compressed latent spaces and a cross attention enhanced U-Net as the backbone of diffusion, latent diffusion models (LDMs) have achieved stable and high fertility image generation. In this paper, we focus on enhancing the creative painting ability of current LDMs in two directions, textual condition extension and model retraining with Wikiart dataset. Through textual condition extension, users' input prompts are expanded with rich contextual knowledge for deeper understanding and explaining the prompts. Wikiart dataset contains 80K famous artworks drawn during recent 400 years by more than 1,000 famous artists in rich styles and genres. Through the retraining, we are able to ask these artists to draw novel and creative painting on modern topics. Direct comparisons with the original model show that the creativity and artistry are enriched.
Graph Perceiver IO: A General Architecture for Graph Structured Data
Sep 14, 2022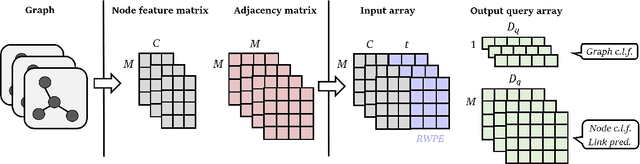
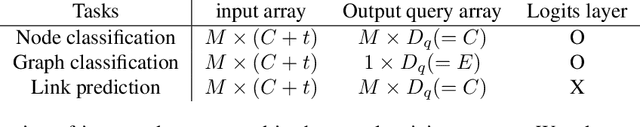
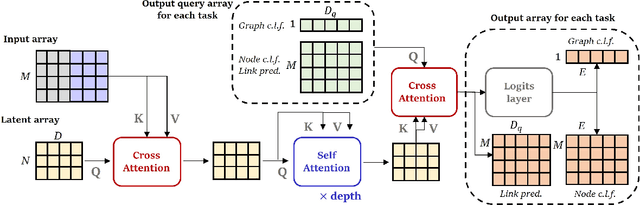
Multimodal machine learning has been widely studied for the development of general intelligence. Recently, the remarkable multimodal algorithms, the Perceiver and Perceiver IO, show competitive results for diverse dataset domains and tasks. However, recent works, Perceiver and Perceiver IO, have focused on heterogeneous modalities, including image, text, and speech, and there are few research works for graph structured datasets. A graph is one of the most generalized dataset structures, and we can represent the other dataset, including images, text, and speech, as graph structured data. A graph has an adjacency matrix different from other dataset domains such as text and image, and it is not trivial to handle the topological information, relational information, and canonical positional information. In this study, we provide a Graph Perceiver IO, the Perceiver IO for the graph structured dataset. We keep the main structure of the Graph Perceiver IO as the Perceiver IO because the Perceiver IO already handles the diverse dataset well, except for the graph structured dataset. The Graph Perceiver IO is a general method, and it can handle diverse datasets such as graph structured data as well as text and images. Comparing the graph neural networks, the Graph Perceiver IO requires a lower complexity, and it can incorporate the local and global information efficiently. We show that Graph Perceiver IO shows competitive results for diverse graph-related tasks, including node classification, graph classification, and link prediction.
WSSAMNet: Weakly Supervised Semantic Attentive Medical Image Registration Network
Mar 05, 2022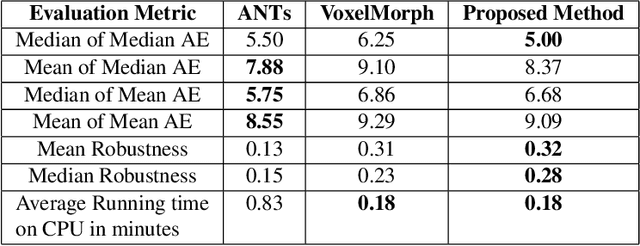
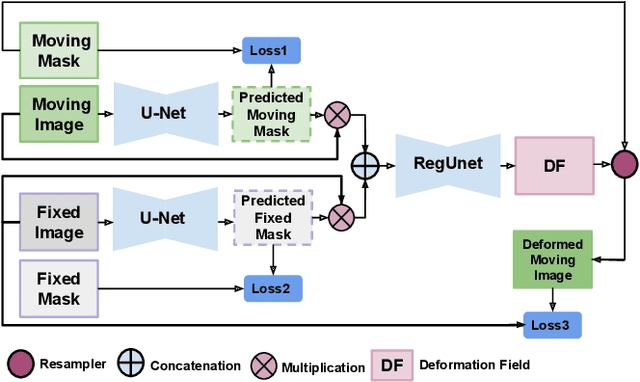
We present WSSAMNet, a weakly supervised method for medical image registration. Ours is a two step method, with the first step being the computation of segmentation masks of the fixed and moving volumes. These masks are then used to attend to the input volume, which are then provided as inputs to a registration network in the second step. The registration network computes the deformation field to perform the alignment between the fixed and the moving volumes. We study the effectiveness of our technique on the BraTSReg challenge data against ANTs and VoxelMorph, where we demonstrate that our method performs competitively.