 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
IDR: Self-Supervised Image Denoising via Iterative Data Refinement
Nov 29, 2021

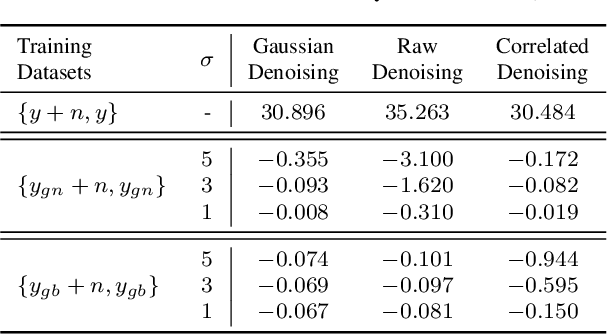
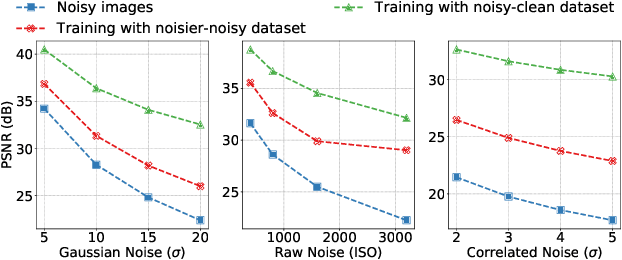
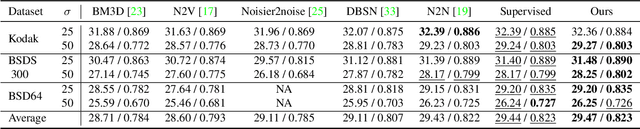
The lack of large-scale noisy-clean image pairs restricts supervised denoising methods' deployment in actual applications. While existing unsupervised methods are able to learn image denoising without ground-truth clean images, they either show poor performance or work under impractical settings (e.g., paired noisy images). In this paper, we present a practical unsupervised image denoising method to achieve state-of-the-art denoising performance. Our method only requires single noisy images and a noise model, which is easily accessible in practical raw image denoising. It performs two steps iteratively: (1) Constructing a noisier-noisy dataset with random noise from the noise model; (2) training a model on the noisier-noisy dataset and using the trained model to refine noisy images to obtain the targets used in the next round. We further approximate our full iterative method with a fast algorithm for more efficient training while keeping its original high performance. Experiments on real-world, synthetic, and correlated noise show that our proposed unsupervised denoising approach has superior performances over existing unsupervised methods and competitive performance with supervised methods. In addition, we argue that existing denoising datasets are of low quality and contain only a small number of scenes. To evaluate raw image denoising performance in real-world applications, we build a high-quality raw image dataset SenseNoise-500 that contains 500 real-life scenes. The dataset can serve as a strong benchmark for better evaluating raw image denoising. Code and dataset will be released at https://github.com/zhangyi-3/IDR
Surrogate-based cross-correlation for particle image velocimetry
Dec 10, 2021
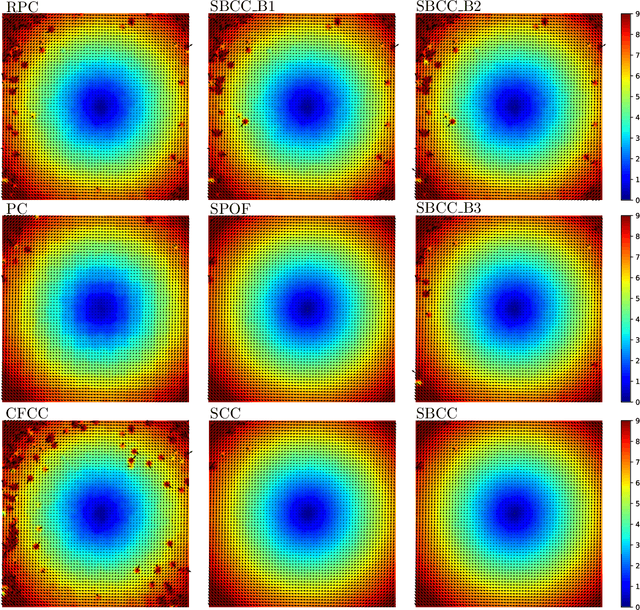
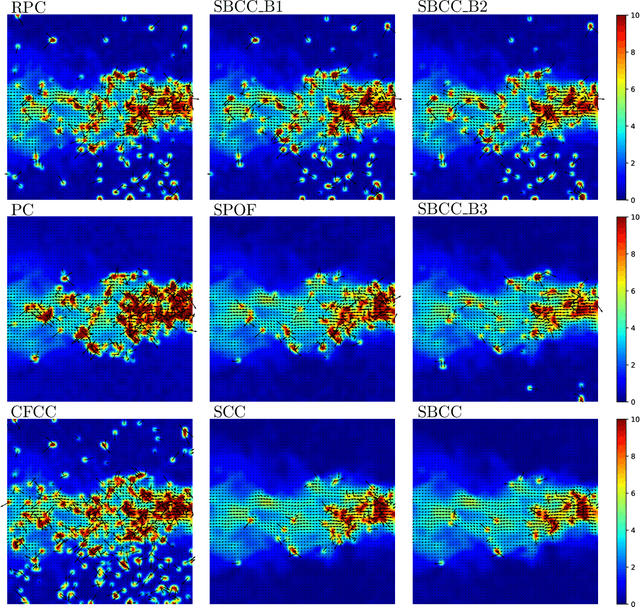
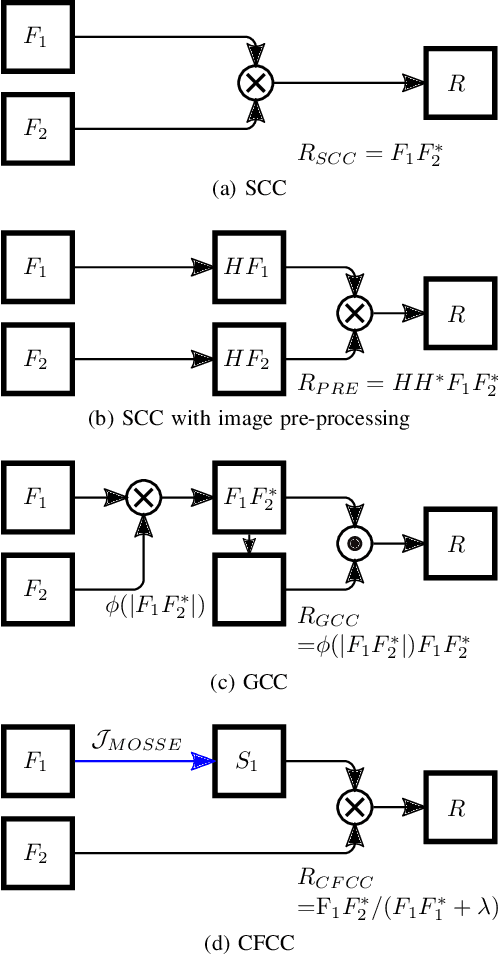
This paper presents a novel surrogate-based cross-correlation (SBCC) framework to improve the correlation performance between two image signals. The basic idea behind the SBCC is that an optimized surrogate filter/image, supplanting one original image, will produce a more robust and more accurate correlation signal. The cross-correlation estimation of the SBCC is formularized with an objective function composed of surrogate loss and correlation consistency loss. The closed-form solution provides an efficient estimation. To our surprise, the SBCC framework could provide an alternative view to explain a set of generalized cross-correlation (GCC) methods and comprehend the meaning of parameters. With the help of our SBCC framework, we further propose four new specific cross-correlation methods, and provide some suggestions for improving existing GCC methods. A noticeable fact is that the SBCC could enhance the correlation robustness by incorporating other negative context images. Considering the sub-pixel accuracy and robustness requirement of particle image velocimetry (PIV), the contribution of each term in the objective function is investigated with particles' images. Compared with the state-of-the-art baseline methods, the SBCC methods exhibit improved performance (accuracy and robustness) on the synthetic dataset and several challenging real experimental PIV cases.
Everything is There in Latent Space: Attribute Editing and Attribute Style Manipulation by StyleGAN Latent Space Exploration
Jul 20, 2022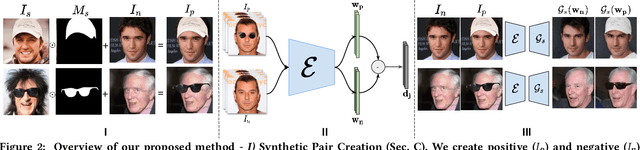
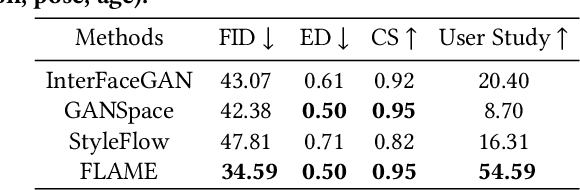
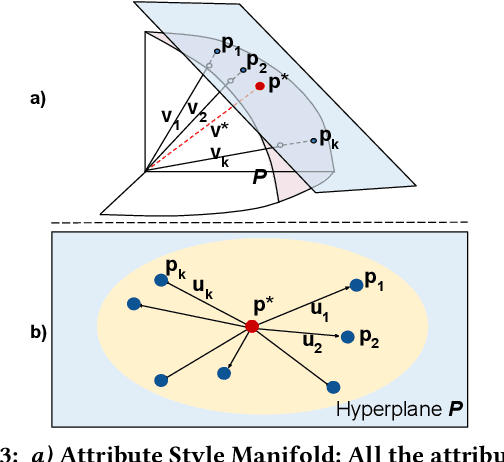
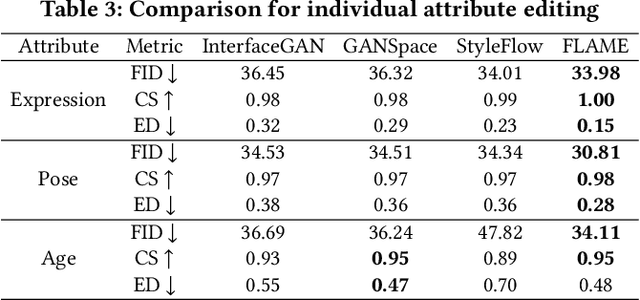
Unconstrained Image generation with high realism is now possible using recent Generative Adversarial Networks (GANs). However, it is quite challenging to generate images with a given set of attributes. Recent methods use style-based GAN models to perform image editing by leveraging the semantic hierarchy present in the layers of the generator. We present Few-shot Latent-based Attribute Manipulation and Editing (FLAME), a simple yet effective framework to perform highly controlled image editing by latent space manipulation. Specifically, we estimate linear directions in the latent space (of a pre-trained StyleGAN) that controls semantic attributes in the generated image. In contrast to previous methods that either rely on large-scale attribute labeled datasets or attribute classifiers, FLAME uses minimal supervision of a few curated image pairs to estimate disentangled edit directions. FLAME can perform both individual and sequential edits with high precision on a diverse set of images while preserving identity. Further, we propose a novel task of Attribute Style Manipulation to generate diverse styles for attributes such as eyeglass and hair. We first encode a set of synthetic images of the same identity but having different attribute styles in the latent space to estimate an attribute style manifold. Sampling a new latent from this manifold will result in a new attribute style in the generated image. We propose a novel sampling method to sample latent from the manifold, enabling us to generate a diverse set of attribute styles beyond the styles present in the training set. FLAME can generate diverse attribute styles in a disentangled manner. We illustrate the superior performance of FLAME against previous image editing methods by extensive qualitative and quantitative comparisons. FLAME also generalizes well on multiple datasets such as cars and churches.
Conviformers: Convolutionally guided Vision Transformer
Aug 28, 2022



Vision transformers are nowadays the de-facto choice for image classification tasks. There are two broad categories of classification tasks, fine-grained and coarse-grained. In fine-grained classification, the necessity is to discover subtle differences due to the high level of similarity between sub-classes. Such distinctions are often lost as we downscale the image to save the memory and computational cost associated with vision transformers (ViT). In this work, we present an in-depth analysis and describe the critical components for developing a system for the fine-grained categorization of plants from herbarium sheets. Our extensive experimental analysis indicated the need for a better augmentation technique and the ability of modern-day neural networks to handle higher dimensional images. We also introduce a convolutional transformer architecture called Conviformer which, unlike the popular Vision Transformer (ConViT), can handle higher resolution images without exploding memory and computational cost. We also introduce a novel, improved pre-processing technique called PreSizer to resize images better while preserving their original aspect ratios, which proved essential for classifying natural plants. With our simple yet effective approach, we achieved SoTA on Herbarium 202x and iNaturalist 2019 dataset.
ManiFest: Manifold Deformation for Few-shot Image Translation
Nov 26, 2021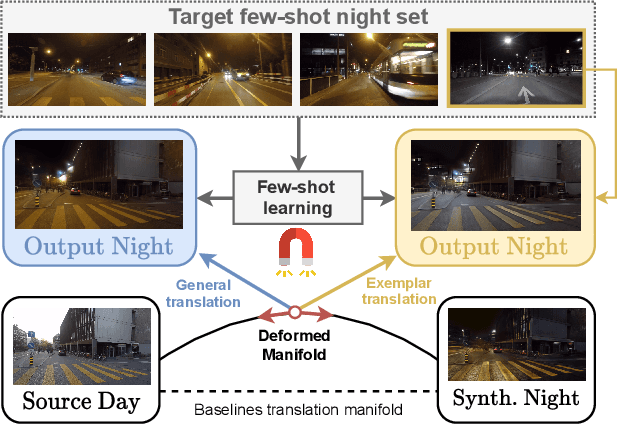
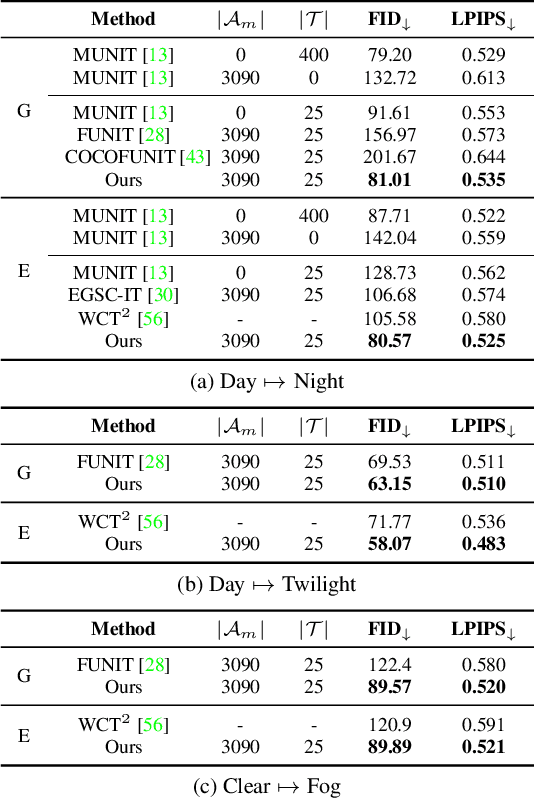
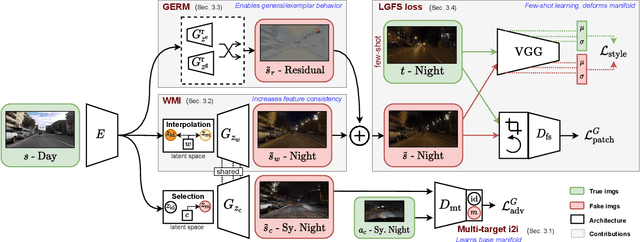
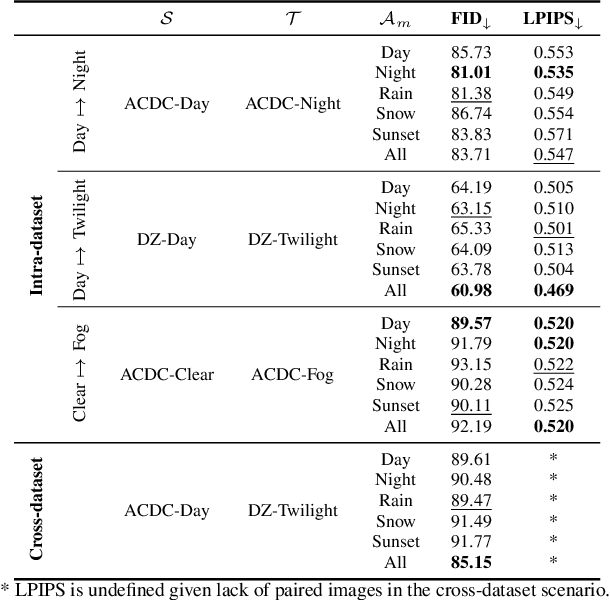
Most image-to-image translation methods require a large number of training images, which restricts their applicability. We instead propose ManiFest: a framework for few-shot image translation that learns a context-aware representation of a target domain from a few images only. To enforce feature consistency, our framework learns a style manifold between source and proxy anchor domains (assumed to be composed of large numbers of images). The learned manifold is interpolated and deformed towards the few-shot target domain via patch-based adversarial and feature statistics alignment losses. All of these components are trained simultaneously during a single end-to-end loop. In addition to the general few-shot translation task, our approach can alternatively be conditioned on a single exemplar image to reproduce its specific style. Extensive experiments demonstrate the efficacy of ManiFest on multiple tasks, outperforming the state-of-the-art on all metrics and in both the general- and exemplar-based scenarios. Our code will be open source.
Self-adversarial Multi-scale Contrastive Learning for Semantic Segmentation of Thermal Facial Images
Sep 21, 2022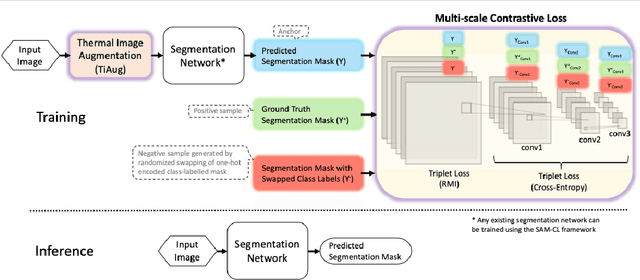
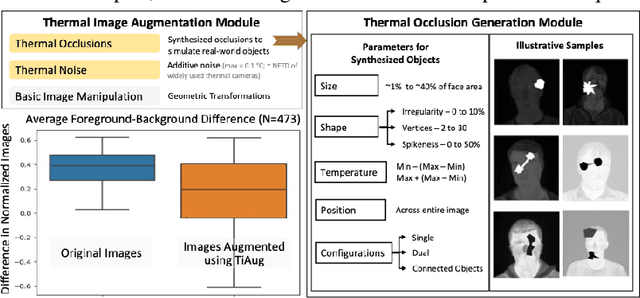
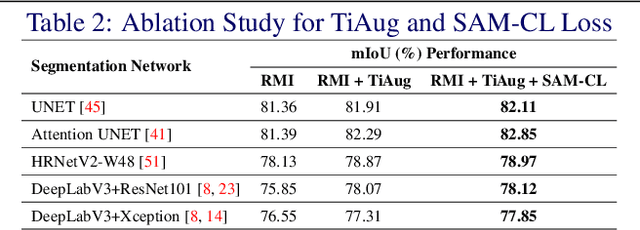
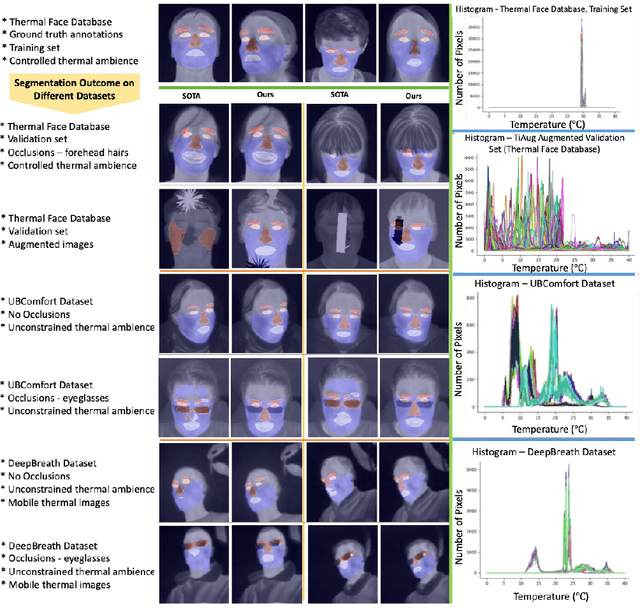
Reliable segmentation of thermal facial images in unconstrained settings such as thermal ambience and occlusions is challenging as facial features lack salience. Limited availability of datasets from such settings further makes it difficult to train segmentation networks. To address the challenge, we propose Self-Adversarial Multi-scale Contrastive Learning (SAM-CL) as a generic learning framework to train segmentation networks. SAM-CL framework constitutes SAM-CL loss function and a thermal image augmentation (TiAug) as a domain-specific augmentation technique to simulate unconstrained settings based upon existing datasets collected from controlled settings. We use the Thermal-Face-Database to demonstrate effectiveness of our approach. Experiments conducted on the existing segmentation networks- UNET, Attention-UNET, DeepLabV3 and HRNetv2 evidence the consistent performance gain from the SAM-CL framework. Further, we present a qualitative analysis with UBComfort and DeepBreath datasets to discuss how our proposed methods perform in handling unconstrained situations.
Hiding Data in Colors: Secure and Lossless Deep Image Steganography via Conditional Invertible Neural Networks
Jan 19, 2022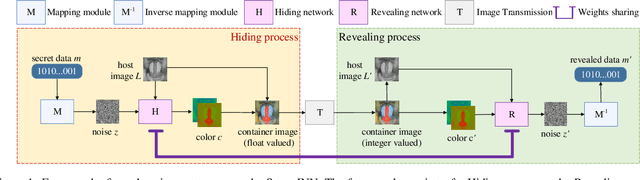
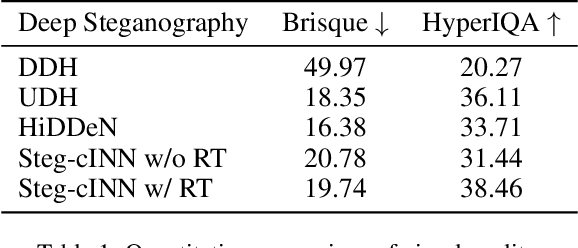
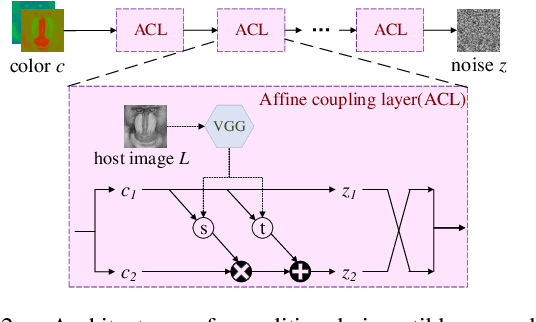
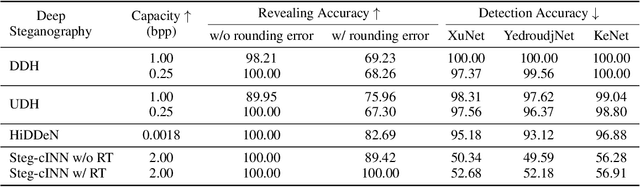
Deep image steganography is a data hiding technology that conceal data in digital images via deep neural networks. However, existing deep image steganography methods only consider the visual similarity of container images to host images, and neglect the statistical security (stealthiness) of container images. Besides, they usually hides data limited to image type and thus relax the constraint of lossless extraction. In this paper, we address the above issues in a unified manner, and propose deep image steganography that can embed data with arbitrary types into images for secure data hiding and lossless data revealing. First, we formulate the data hiding as an image colorization problem, in which the data is binarized and further mapped into the color information for a gray-scale host image. Second, we design a conditional invertible neural network which uses gray-scale image as prior to guide the color generation and perform data hiding in a secure way. Finally, to achieve lossless data revealing, we present a multi-stage training scheme to manage the data loss due to rounding errors between hiding and revealing processes. Extensive experiments demonstrate that the proposed method can perform secure data hiding by generating realism color images and successfully resisting the detection of steganalysis. Moreover, we can achieve 100% revealing accuracy in different scenarios, indicating the practical utility of our steganography in the real-world.
SimpleRecon: 3D Reconstruction Without 3D Convolutions
Aug 31, 2022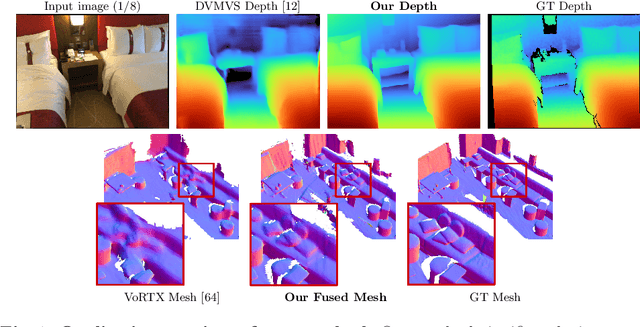
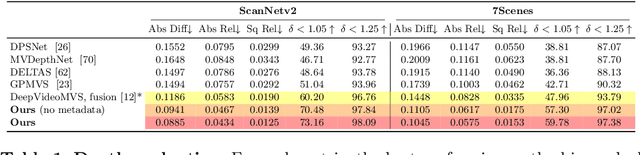
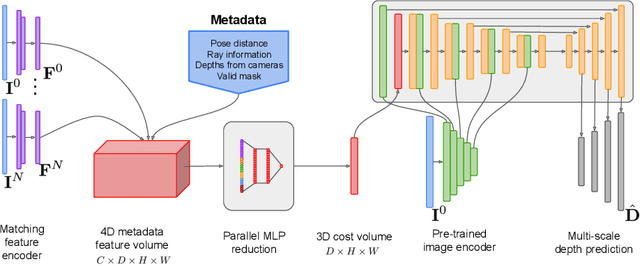
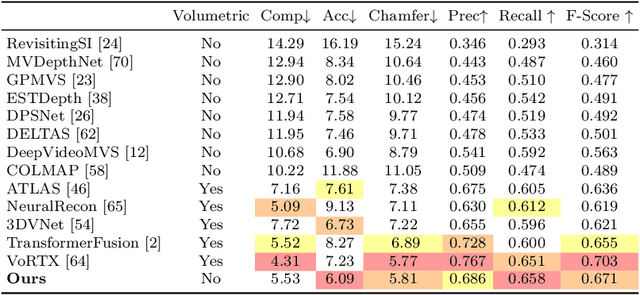
Traditionally, 3D indoor scene reconstruction from posed images happens in two phases: per-image depth estimation, followed by depth merging and surface reconstruction. Recently, a family of methods have emerged that perform reconstruction directly in final 3D volumetric feature space. While these methods have shown impressive reconstruction results, they rely on expensive 3D convolutional layers, limiting their application in resource-constrained environments. In this work, we instead go back to the traditional route, and show how focusing on high quality multi-view depth prediction leads to highly accurate 3D reconstructions using simple off-the-shelf depth fusion. We propose a simple state-of-the-art multi-view depth estimator with two main contributions: 1) a carefully-designed 2D CNN which utilizes strong image priors alongside a plane-sweep feature volume and geometric losses, combined with 2) the integration of keyframe and geometric metadata into the cost volume which allows informed depth plane scoring. Our method achieves a significant lead over the current state-of-the-art for depth estimation and close or better for 3D reconstruction on ScanNet and 7-Scenes, yet still allows for online real-time low-memory reconstruction. Code, models and results are available at https://nianticlabs.github.io/simplerecon
T$^2$LR-Net: An Unrolling Reconstruction Network Learning Transformed Tensor Low-Rank prior for Dynamic MR Imaging
Sep 08, 2022
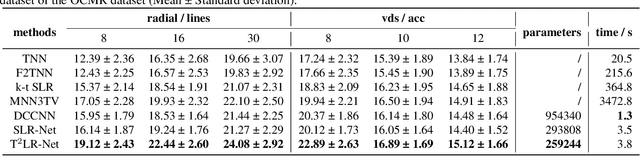
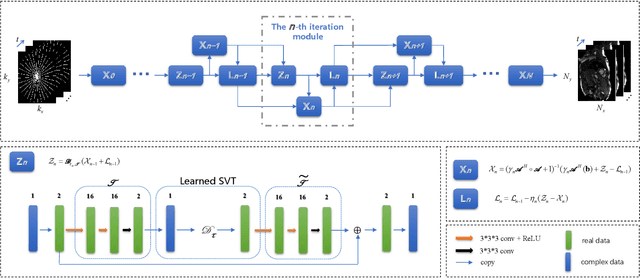
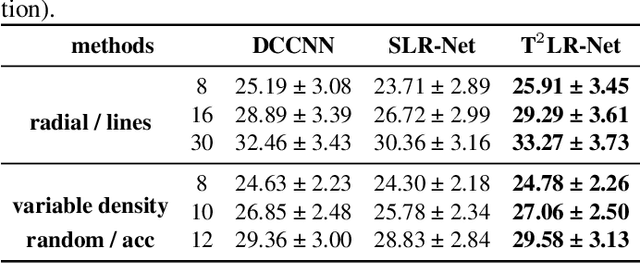
While the methods exploiting the tensor low-rank prior are booming in high-dimensional data processing and have obtained satisfying performance, their applications in dynamic magnetic resonance (MR) image reconstruction are limited. In this paper, we concentrate on the tensor singular value decomposition (t-SVD), which is based on the Fast Fourier Transform (FFT) and only provides the definite and limited tensor low-rank prior in the FFT domain, heavily reliant upon how closely the data and the FFT domain match up. By generalizing the FFT into an arbitrary unitary transformation of the transformed t-SVD and proposing the transformed tensor nuclear norm (TTNN), we introduce a flexible model based on TTNN with the ability to exploit the tensor low-rank prior of a transformed domain in a larger transformation space and elaborately design an iterative optimization algorithm based on the alternating direction method of multipliers (ADMM), which is further unrolled into a model-based deep unrolling reconstruction network to learn the transformed tensor low-rank prior (T$^2$LR-Net). The convolutional neural network (CNN) is incorporated within the T$^2$LR-Net to learn the best-matched transform from the dynamic MR image dataset. The unrolling reconstruction network also provides a new perspective on the low-rank prior utilization by exploiting the low-rank prior in the CNN-extracted feature domain. Experimental results on two cardiac cine MR datasets demonstrate that the proposed framework can provide improved recovery results compared with the state-of-the-art optimization-based and unrolling network-based methods.
NeurIPS'22 Cross-Domain MetaDL competition: Design and baseline results
Aug 31, 2022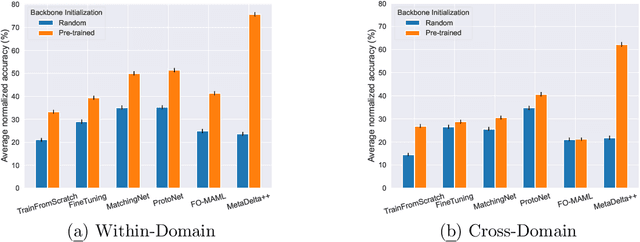

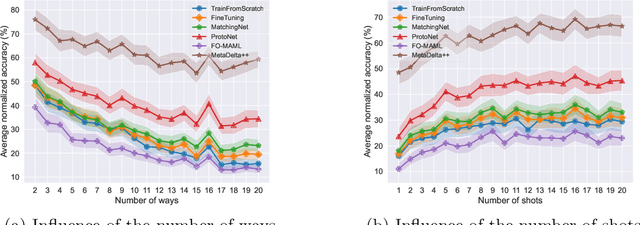

We present the design and baseline results for a new challenge in the ChaLearn meta-learning series, accepted at NeurIPS'22, focusing on "cross-domain" meta-learning. Meta-learning aims to leverage experience gained from previous tasks to solve new tasks efficiently (i.e., with better performance, little training data, and/or modest computational resources). While previous challenges in the series focused on within-domain few-shot learning problems, with the aim of learning efficiently N-way k-shot tasks (i.e., N class classification problems with k training examples), this competition challenges the participants to solve "any-way" and "any-shot" problems drawn from various domains (healthcare, ecology, biology, manufacturing, and others), chosen for their humanitarian and societal impact. To that end, we created Meta-Album, a meta-dataset of 40 image classification datasets from 10 domains, from which we carve out tasks with any number of "ways" (within the range 2-20) and any number of "shots" (within the range 1-20). The competition is with code submission, fully blind-tested on the CodaLab challenge platform. The code of the winners will be open-sourced, enabling the deployment of automated machine learning solutions for few-shot image classification across several domains.