 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recognition-Aware Learned Image Compression
Feb 01, 2022
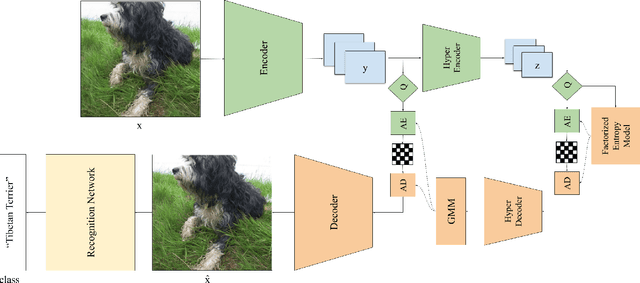
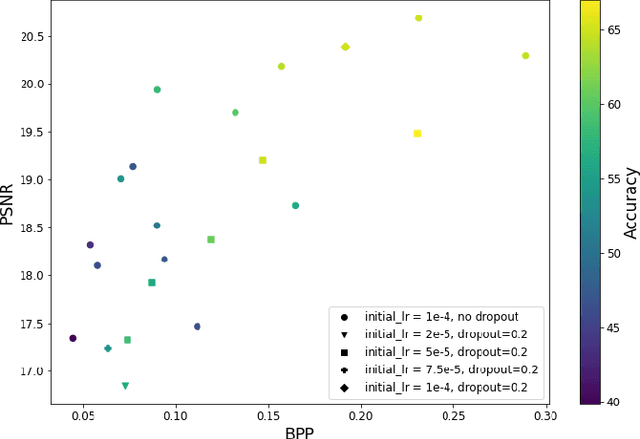

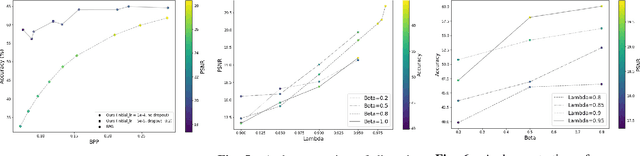
Learned image compression methods generally optimize a rate-distortion loss, trading off improvements in visual distortion for added bitrate. Increasingly, however, compressed imagery is used as an input to deep learning networks for various tasks such as classification, object detection, and superresolution. We propose a recognition-aware learned compression method, which optimizes a rate-distortion loss alongside a task-specific loss, jointly learning compression and recognition networks. We augment a hierarchical autoencoder-based compression network with an EfficientNet recognition model and use two hyperparameters to trade off between distortion, bitrate, and recognition performance. We characterize the classification accuracy of our proposed method as a function of bitrate and find that for low bitrates our method achieves as much as 26% higher recognition accuracy at equivalent bitrates compared to traditional methods such as Better Portable Graphics (BPG).
CheXRelNet: An Anatomy-Aware Model for Tracking Longitudinal Relationships between Chest X-Rays
Aug 08, 2022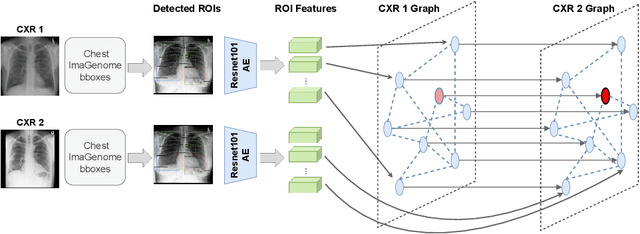
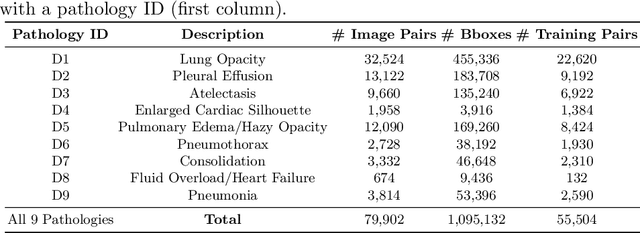
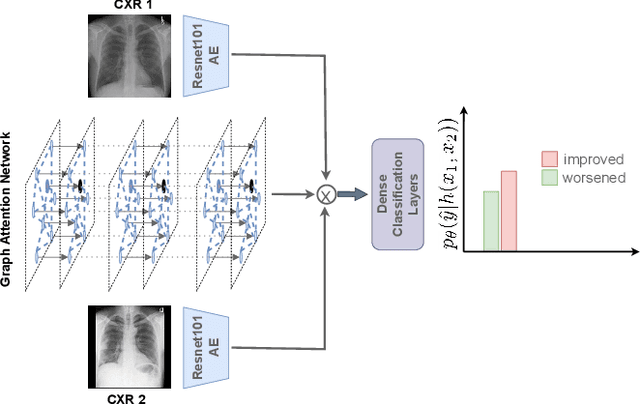
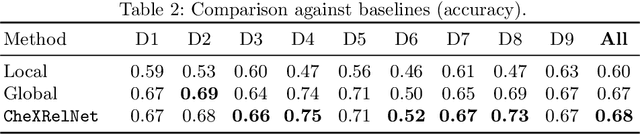
Despite the progress in utilizing deep learning to automate chest radiograph interpretation and disease diagnosis tasks, change between sequential Chest X-rays (CXRs) has received limited attention. Monitoring the progression of pathologies that are visualized through chest imaging poses several challenges in anatomical motion estimation and image registration, i.e., spatially aligning the two images and modeling temporal dynamics in change detection. In this work, we propose CheXRelNet, a neural model that can track longitudinal pathology change relations between two CXRs. CheXRelNet incorporates local and global visual features, utilizes inter-image and intra-image anatomical information, and learns dependencies between anatomical region attributes, to accurately predict disease change for a pair of CXRs. Experimental results on the Chest ImaGenome dataset show increased downstream performance compared to baselines. Code is available at https://github.com/PLAN-Lab/ChexRelNet
Attitude-Guided Loop Closure for Cameras with Negative Plane
Sep 12, 2022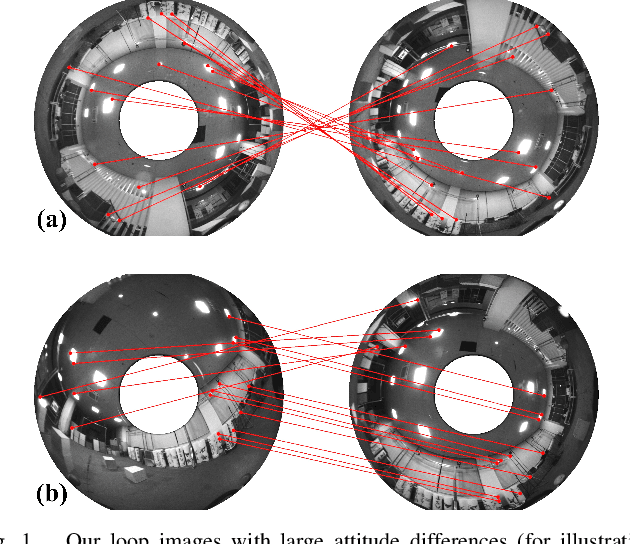

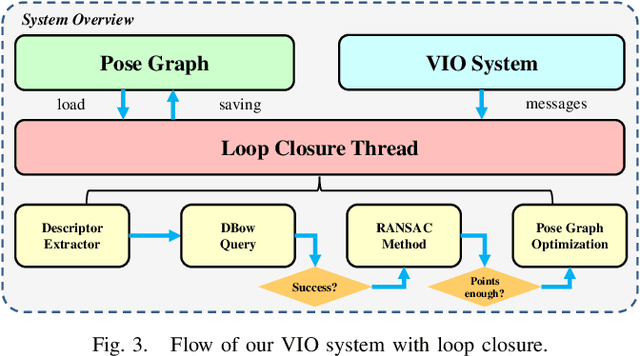

Loop closure is an important component of Simultaneous Localization and Mapping (SLAM) systems. Large Field-of-View (FoV) cameras have received extensive attention in the SLAM field as they can exploit more surrounding features on the panoramic image. In large-FoV VIO, for incorporating the informative cues located on the negative plane of the panoramic lens, image features are represented by a three-dimensional vector with a unit length. While the panoramic FoV is seemingly advantageous for loop closure, the benefits cannot easily be materialized under large-attitude-angle differences, where loop-closure frames can hardly be matched by existing methods. In this work, to fully unleash the potential of ultra-wide FoV, we propose to leverage the attitude information of a VIO system to guide the feature point detection of the loop closure. As loop closure on wide-FoV panoramic data further comes with a large number of outliers, traditional outlier rejection methods are not directly applicable. To tackle this issue, we propose a loop closure framework with a new outlier rejection method based on the unit length representation, to improve the accuracy of LF-VIO. On the public PALVIO dataset, a comprehensive set of experiments is carried out and the proposed LF-VIO-Loop outperforms state-of-the-art visual-inertial-odometry methods. Our code will be open-sourced at https://github.com/flysoaryun/LF-VIO-Loop.
Prototypical few-shot segmentation for cross-institution male pelvic structures with spatial registration
Sep 12, 2022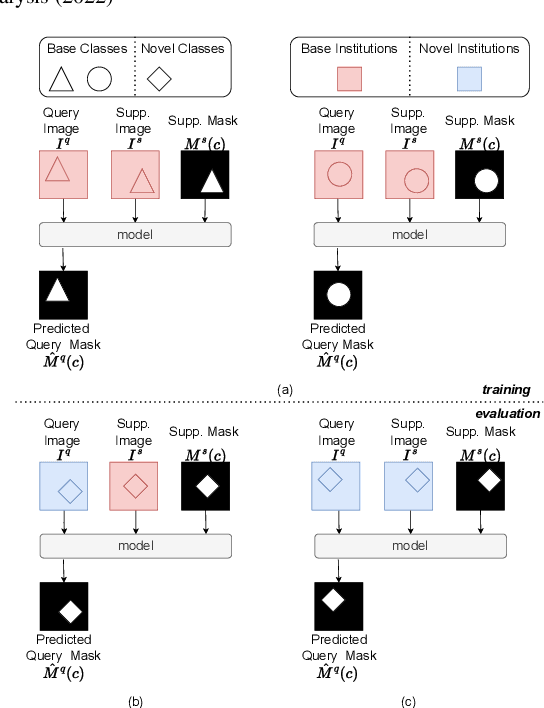

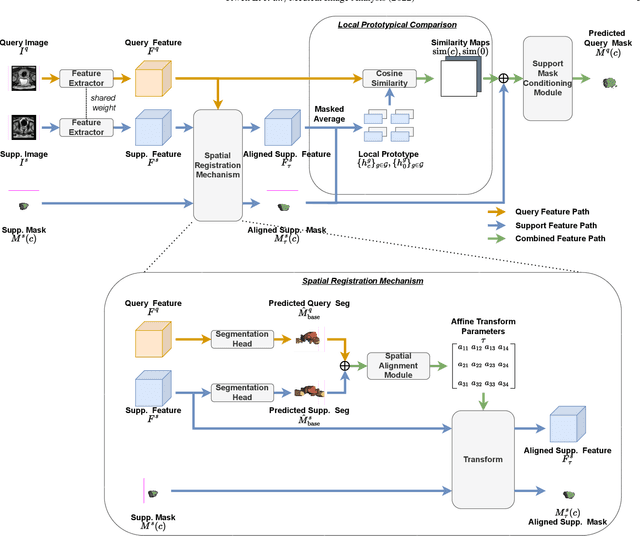

The prowess that makes few-shot learning desirable in medical image analysis is the efficient use of the support image data, which are labelled to classify or segment new classes, a task that otherwise requires substantially more training images and expert annotations. This work describes a fully 3D prototypical few-shot segmentation algorithm, such that the trained networks can be effectively adapted to clinically interesting structures that are absent in training, using only a few labelled images from a different institute. First, to compensate for the widely recognised spatial variability between institutions in episodic adaptation of novel classes, a novel spatial registration mechanism is integrated into prototypical learning, consisting of a segmentation head and an spatial alignment module. Second, to assist the training with observed imperfect alignment, support mask conditioning module is proposed to further utilise the annotation available from the support images. Extensive experiments are presented in an application of segmenting eight anatomical structures important for interventional planning, using a data set of 589 pelvic T2-weighted MR images, acquired at seven institutes. The results demonstrate the efficacy in each of the 3D formulation, the spatial registration, and the support mask conditioning, all of which made positive contributions independently or collectively. Compared with the previously proposed 2D alternatives, the few-shot segmentation performance was improved with statistical significance, regardless whether the support data come from the same or different institutes.
LSC-GAN: Latent Style Code Modeling for Continuous Image-to-image Translation
Oct 11, 2021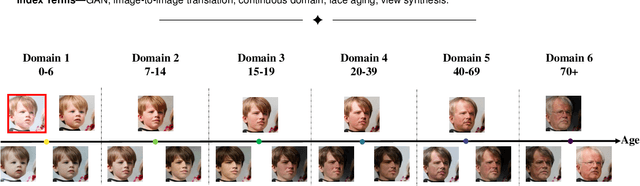

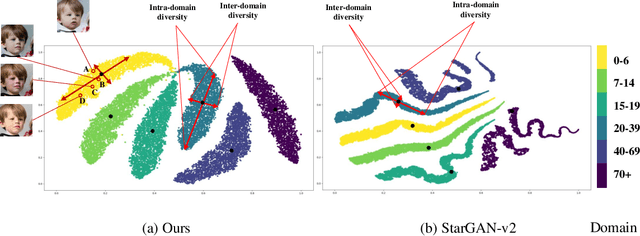
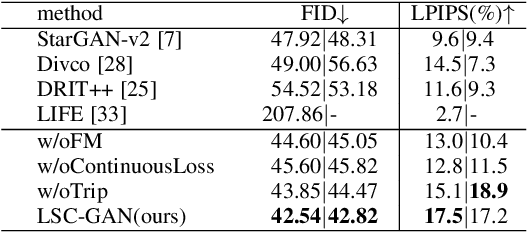
Image-to-image (I2I) translation is usually carried out among discrete domains. However, image domains, often corresponding to a physical value, are usually continuous. In other words, images gradually change with the value, and there exists no obvious gap between different domains. This paper intends to build the model for I2I translation among continuous varying domains. We first divide the whole domain coverage into discrete intervals, and explicitly model the latent style code for the center of each interval. To deal with continuous translation, we design the editing modules, changing the latent style code along two directions. These editing modules help to constrain the codes for domain centers during training, so that the model can better understand the relation among them. To have diverse results, the latent style code is further diversified with either the random noise or features from the reference image, giving the individual style code to the decoder for label-based or reference-based synthesis. Extensive experiments on age and viewing angle translation show that the proposed method can achieve high-quality results, and it is also flexible for users.
Bench-Marking And Improving Arabic Automatic Image Captioning Through The Use Of Multi-Task Learning Paradigm
Feb 11, 2022

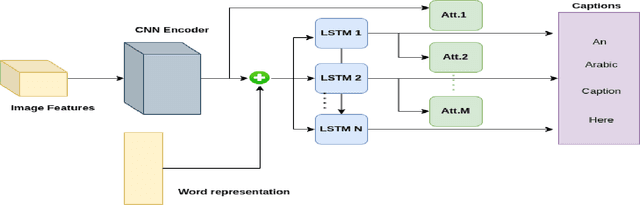
The continuous increase in the use of social media and the visual content on the internet have accelerated the research in computer vision field in general and the image captioning task in specific. The process of generating a caption that best describes an image is a useful task for various applications such as it can be used in image indexing and as a hearing aid for the visually impaired. In recent years, the image captioning task has witnessed remarkable advances regarding both datasets and architectures, and as a result, the captioning quality has reached an astounding performance. However, the majority of these advances especially in datasets are targeted for English, which left other languages such as Arabic lagging behind. Although Arabic language, being spoken by more than 450 million people and being the most growing language on the internet, lacks the fundamental pillars it needs to advance its image captioning research, such as benchmarks or unified datasets. This works is an attempt to expedite the synergy in this task by providing unified datasets and benchmarks, while also exploring methods and techniques that could enhance the performance of Arabic image captioning. The use of multi-task learning is explored, alongside exploring various word representations and different features. The results showed that the use of multi-task learning and pre-trained word embeddings noticeably enhanced the quality of image captioning, however the presented results shows that Arabic captioning still lags behind when compared to the English language. The used dataset and code are available at this link.
Fine-Grained Semantically Aligned Vision-Language Pre-Training
Aug 04, 2022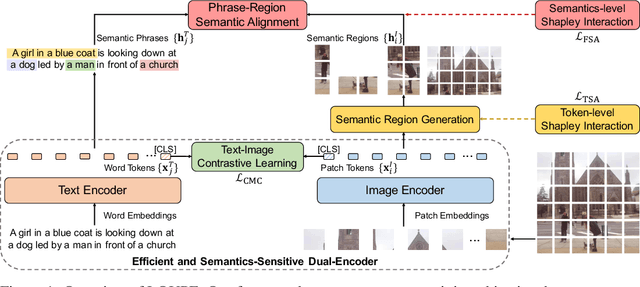
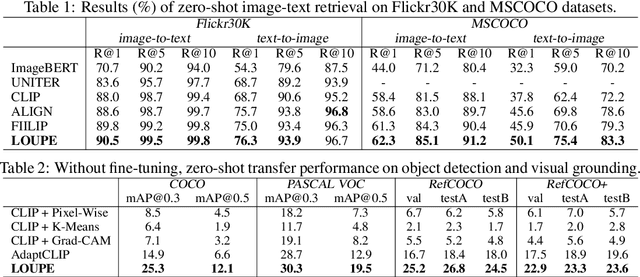
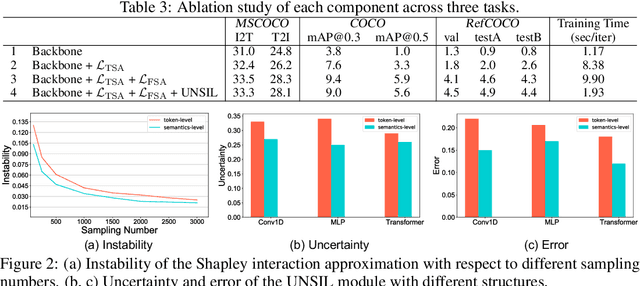

Large-scale vision-language pre-training has shown impressive advances in a wide range of downstream tasks. Existing methods mainly model the cross-modal alignment by the similarity of the global representations of images and texts, or advanced cross-modal attention upon image and text features. However, they fail to explicitly learn the fine-grained semantic alignment between visual regions and textual phrases, as only global image-text alignment information is available. In this paper, we introduce LOUPE, a fine-grained semantically aLigned visiOn-langUage PrE-training framework, which learns fine-grained semantic alignment from the novel perspective of game-theoretic interactions. To efficiently compute the game-theoretic interactions, we further propose an uncertainty-aware neural Shapley interaction learning module. Experiments show that LOUPE achieves state-of-the-art on image-text retrieval benchmarks. Without any object-level human annotations and fine-tuning, LOUPE achieves competitive performance on object detection and visual grounding. More importantly, LOUPE opens a new promising direction of learning fine-grained semantics from large-scale raw image-text pairs.
Challenges of Adversarial Image Augmentations
Nov 24, 2021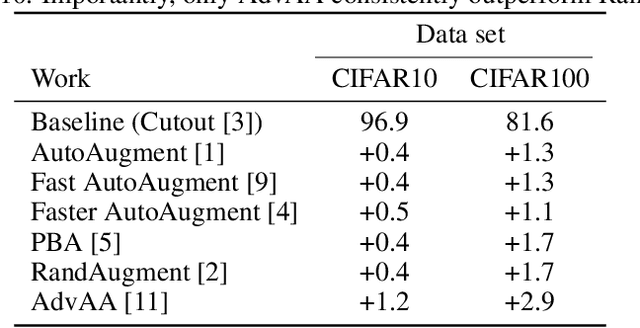
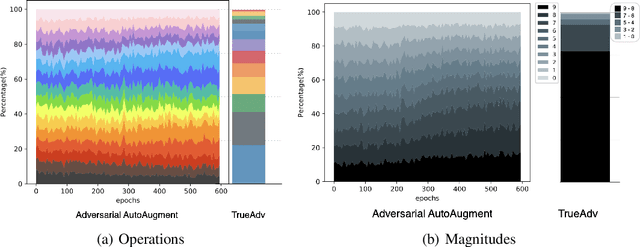


Image augmentations applied during training are crucial for the generalization performance of image classifiers. Therefore, a large body of research has focused on finding the optimal augmentation policy for a given task. Yet, RandAugment [2], a simple random augmentation policy, has recently been shown to outperform existing sophisticated policies. Only Adversarial AutoAugment (AdvAA) [11], an approach based on the idea of adversarial training, has shown to be better than RandAugment. In this paper, we show that random augmentations are still competitive compared to an optimal adversarial approach, as well as to simple curricula, and conjecture that the success of AdvAA is due to the stochasticity of the policy controller network, which introduces a mild form of curriculum.
An Overview of Compressible and Learnable Image Transformation with Secret Key and Its Applications
Jan 26, 2022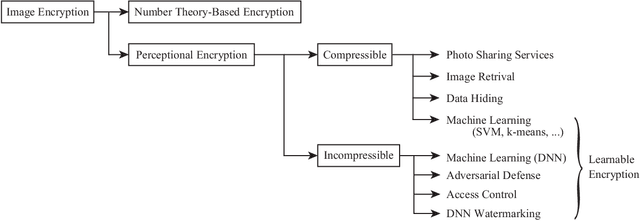

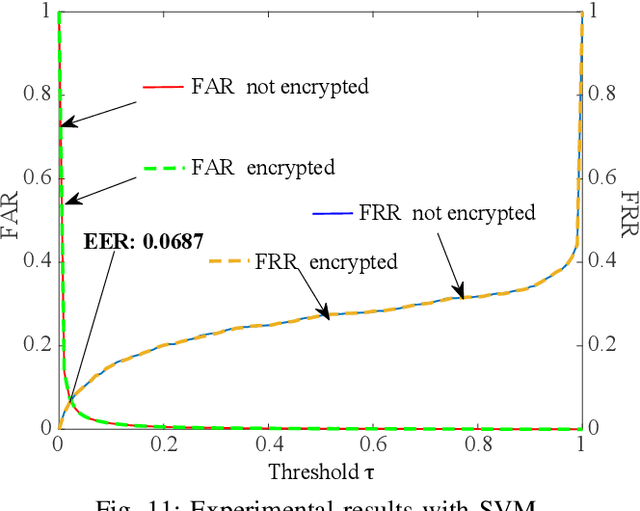

This article presents an overview of image transformation with a secret key and its applications. Image transformation with a secret key enables us not only to protect visual information on plain images but also to embed unique features controlled with a key into images. In addition, numerous encryption methods can generate encrypted images that are compressible and learnable for machine learning. Various applications of such transformation have been developed by using these properties. In this paper, we focus on a class of image transformation referred to as learnable image encryption, which is applicable to privacy-preserving machine learning and adversarially robust defense. Detailed descriptions of both transformation algorithms and performances are provided. Moreover, we discuss robustness against various attacks.
Validation and Generalizability of Self-Supervised Image Reconstruction Methods for Undersampled MRI
Jan 29, 2022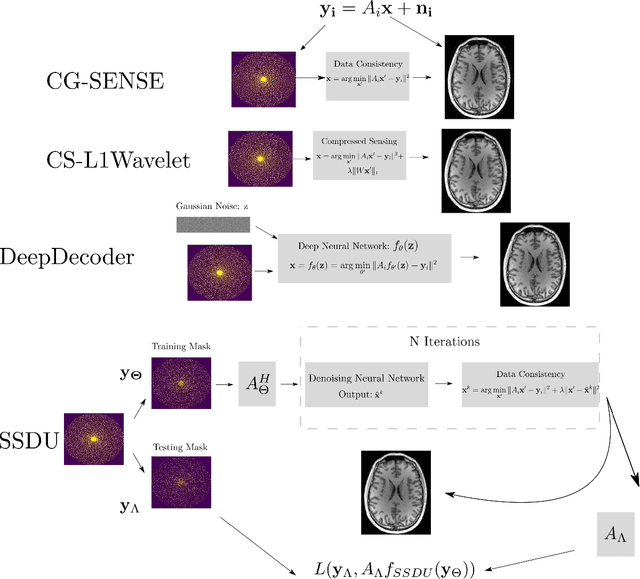
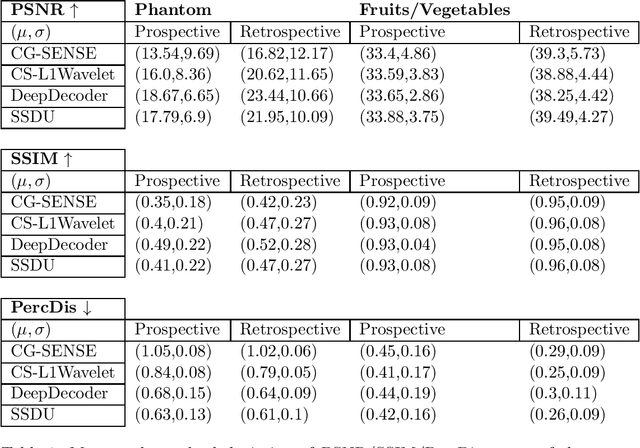

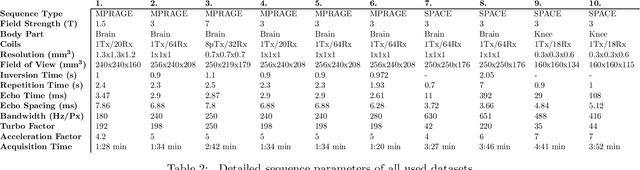
Purpose: To investigate aspects of the validation of self-supervised algorithms for reconstruction of undersampled MR images: quantitative evaluation of prospective reconstructions, potential differences between prospective and retrospective reconstructions, suitability of commonly used quantitative metrics, and generalizability. Theory and Methods: Two self-supervised algorithms based on self-supervised denoising and neural network image priors were investigated. These methods are compared to a least squares fitting and a compressed sensing reconstruction using in-vivo and phantom data. Their generalizability was tested with prospectively under-sampled data from experimental conditions different to the training. Results: Prospective reconstructions can exhibit significant distortion relative to retrospective reconstructions/ground truth. Pixel-wise quantitative metrics may not capture differences in perceptual quality accurately, in contrast to a perceptual metric. All methods showed potential for generalization; generalizability is more affected by changes in anatomy/contrast than other changes. No-reference image metrics correspond well with human rating of image quality for studying generalizability. Compressed Sensing and learned denoising perform similarly well on all data. Conclusion: Self-supervised methods show promising results for accelerating image reconstruction in clinical routines. Nonetheless, more work is required to investigate standardized methods to validate reconstruction algorithms for future clinical use.