 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MenuAI: Restaurant Food Recommendation System via a Transformer-based Deep Learning Model
Oct 15, 2022
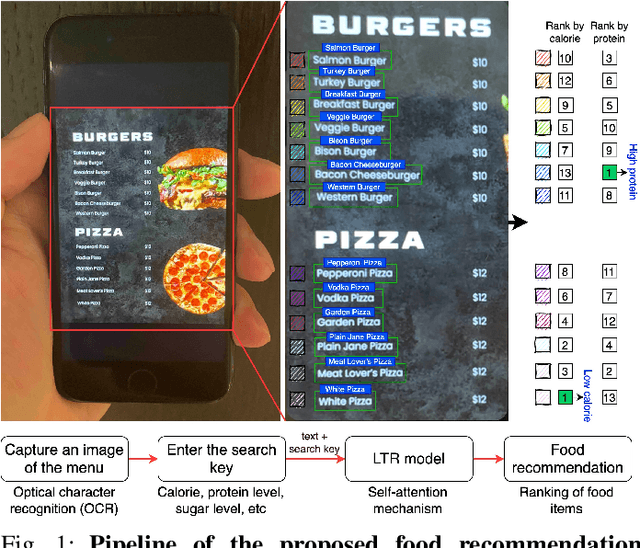
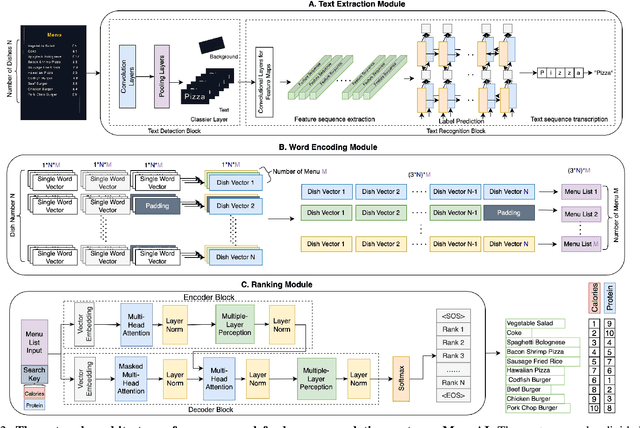
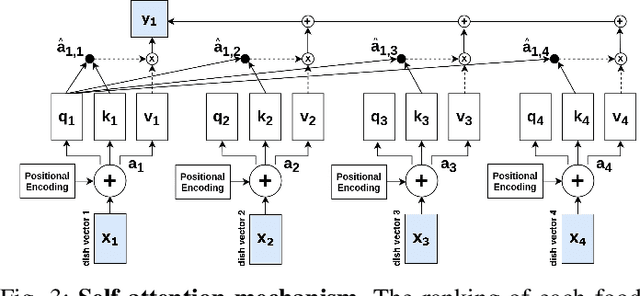
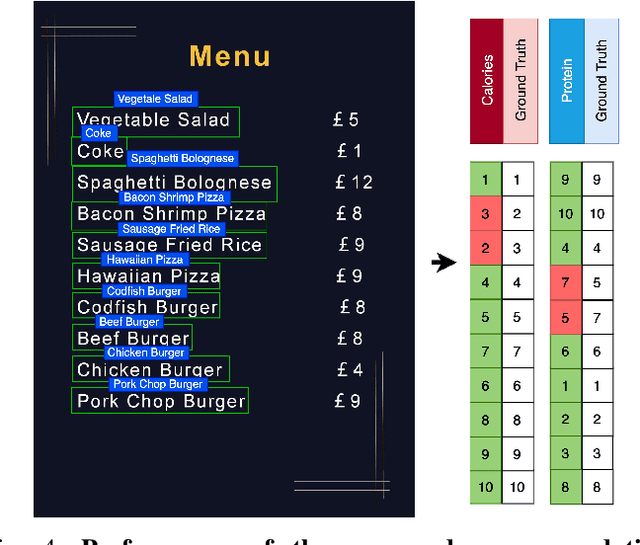
Food recommendation system has proven as an effective technology to provide guidance on dietary choices, and this is especially important for patients suffering from chronic diseases. Unlike other multimedia recommendations, such as books and movies, food recommendation task is highly relied on the context at the moment, since users' food preference can be highly dynamic over time. For example, individuals tend to eat more calories earlier in the day and eat a little less at dinner. However, there are still limited research works trying to incorporate both current context and nutritional knowledge for food recommendation. Thus, a novel restaurant food recommendation system is proposed in this paper to recommend food dishes to users according to their special nutritional needs. Our proposed system utilises Optical Character Recognition (OCR) technology and a transformer-based deep learning model, Learning to Rank (LTR) model, to conduct food recommendation. Given a single RGB image of the menu, the system is then able to rank the food dishes in terms of the input search key (e.g., calorie, protein level). Due to the property of the transformer, our system can also rank unseen food dishes. Comprehensive experiments are conducted to validate our methods on a self-constructed menu dataset, known as MenuRank dataset. The promising results, with accuracy ranging from 77.2% to 99.5%, have demonstrated the great potential of LTR model in addressing food recommendation problems.
A Smoothing and Thresholding Image Segmentation Framework with Weighted Anisotropic-Isotropic Total Variation
Feb 21, 2022
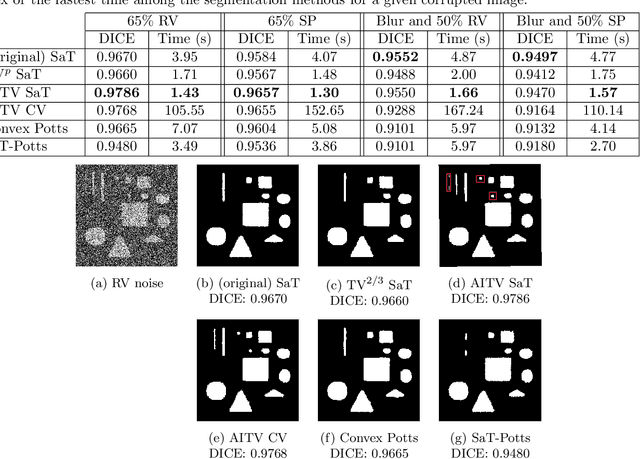

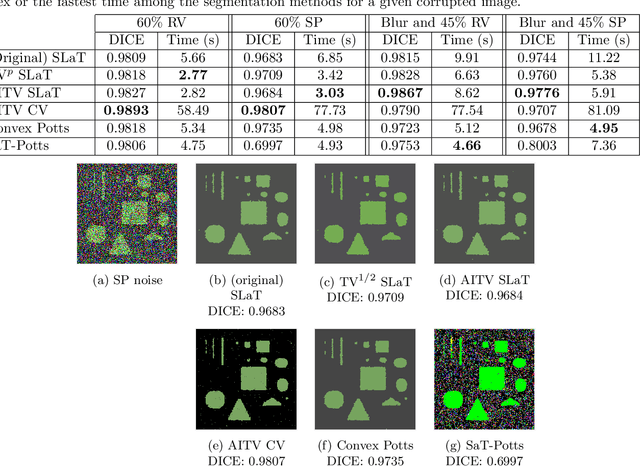
In this paper, we propose a multi-stage image segmentation framework that incorporates a weighted difference of anisotropic and isotropic total variation (AITV). The segmentation framework generally consists of two stages: smoothing and thresholding, thus referred to as SaT. In the first stage, a smoothed image is obtained by an AITV-regularized Mumford-Shah (MS) model, which can be solved efficiently by the alternating direction method of multipliers (ADMM) with a closed-form solution of a proximal operator of the $\ell_1 -\alpha \ell_2$ regularizer. Convergence of the ADMM algorithm is analyzed. In the second stage, we threshold the smoothed image by $k$-means clustering to obtain the final segmentation result. Numerical experiments demonstrate that the proposed segmentation framework is versatile for both grayscale and color images, efficient in producing high-quality segmentation results within a few seconds, and robust to input images that are corrupted with noise, blur, or both. We compare the AITV method with its original convex and nonconvex TV$^p (0<p<1)$ counterparts, showcasing the qualitative and quantitative advantages of our proposed method.
Class-Aware Visual Prompt Tuning for Vision-Language Pre-Trained Model
Aug 22, 2022
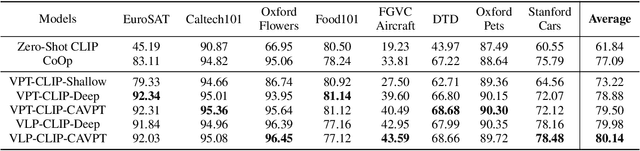
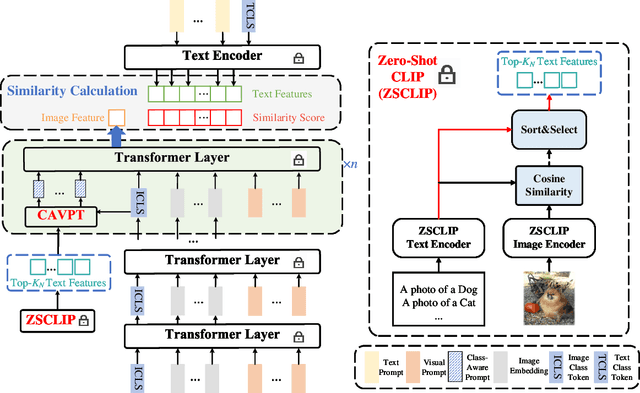

With the emergence of large pre-trained vison-language model like CLIP, transferrable representations can be adapted to a wide range of downstream tasks via prompt tuning. Prompt tuning tries to probe the beneficial information for downstream tasks from the general knowledge stored in both the image and text encoders of the pre-trained vision-language model. A recently proposed method named Context Optimization (CoOp) introduces a set of learnable vectors as text prompt from the language side, while tuning the text prompt alone can not affect the computed visual features of the image encoder, thus leading to sub-optimal. In this paper, we propose a dual modality prompt tuning paradigm through learning text prompts and visual prompts for both the text and image encoder simultaneously. In addition, to make the visual prompt concentrate more on the target visual concept, we propose Class-Aware Visual Prompt Tuning (CAVPT), which is generated dynamically by performing the cross attention between language descriptions of template prompts and visual class token embeddings. Our method provides a new paradigm for tuning the large pre-trained vision-language model and extensive experimental results on 8 datasets demonstrate the effectiveness of the proposed method. Our code is available in the supplementary materials.
Understanding the Influence of Receptive Field and Network Complexity in Neural-Network-Guided TEM Image Analysis
Apr 08, 2022
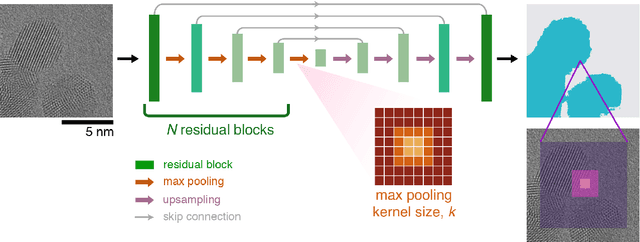

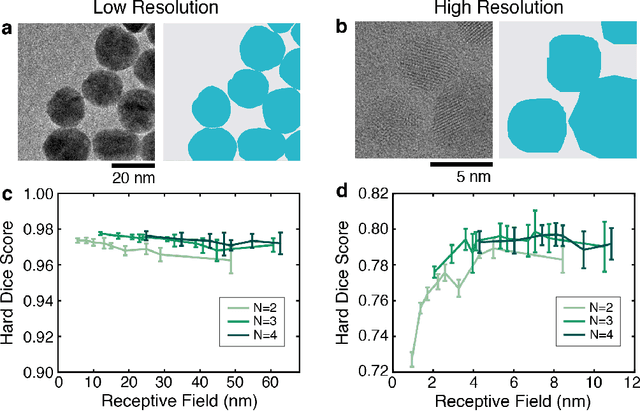
Trained neural networks are promising tools to analyze the ever-increasing amount of scientific image data, but it is unclear how to best customize these networks for the unique features in transmission electron micrographs. Here, we systematically examine how neural network architecture choices affect how neural networks segment, or pixel-wise separate, crystalline nanoparticles from amorphous background in transmission electron microscopy (TEM) images. We focus on decoupling the influence of receptive field, or the area of the input image that contributes to the output decision, from network complexity, which dictates the number of trainable parameters. We find that for low-resolution TEM images which rely on amplitude contrast to distinguish nanoparticles from background, the receptive field does not significantly influence segmentation performance. On the other hand, for high-resolution TEM images which rely on a combination of amplitude and phase contrast changes to identify nanoparticles, receptive field is a key parameter for increased performance, especially in images with minimal amplitude contrast. Our results provide insight and guidance as to how to adapt neural networks for applications with TEM datasets.
Can you recommend content to creatives instead of final consumers? A RecSys based on user's preferred visual styles
Aug 23, 2022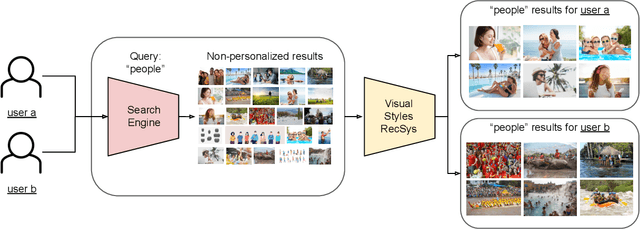


Providing meaningful recommendations in a content marketplace is challenging due to the fact that users are not the final content consumers. Instead, most users are creatives whose interests, linked to the projects they work on, change rapidly and abruptly. To address the challenging task of recommending images to content creators, we design a RecSys that learns visual styles preferences transversal to the semantics of the projects users work on. We analyze the challenges of the task compared to content-based recommendations driven by semantics, propose an evaluation setup, and explain its applications in a global image marketplace. This technical report is an extension of the paper "Learning Users' Preferred Visual Styles in an Image Marketplace", presented at ACM RecSys '22.
Attitude-Guided Loop Closure for Cameras with Negative Plane
Sep 12, 2022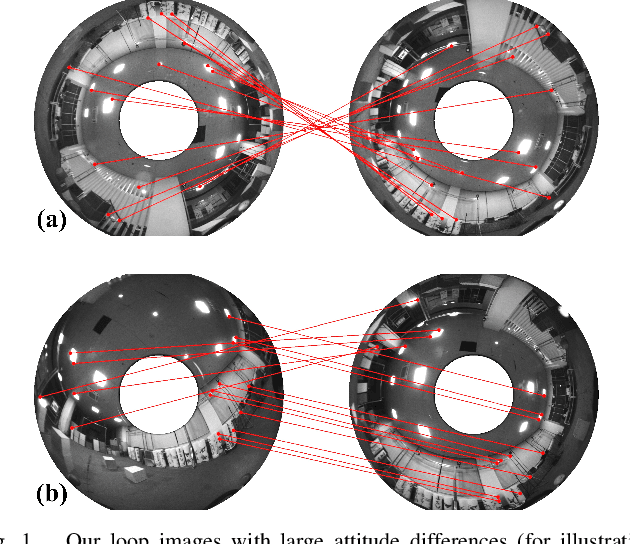

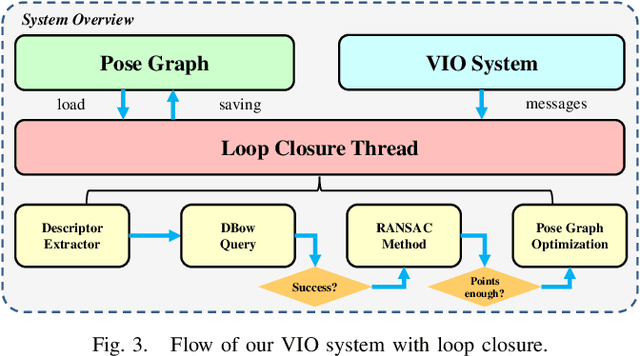

Loop closure is an important component of Simultaneous Localization and Mapping (SLAM) systems. Large Field-of-View (FoV) cameras have received extensive attention in the SLAM field as they can exploit more surrounding features on the panoramic image. In large-FoV VIO, for incorporating the informative cues located on the negative plane of the panoramic lens, image features are represented by a three-dimensional vector with a unit length. While the panoramic FoV is seemingly advantageous for loop closure, the benefits cannot easily be materialized under large-attitude-angle differences, where loop-closure frames can hardly be matched by existing methods. In this work, to fully unleash the potential of ultra-wide FoV, we propose to leverage the attitude information of a VIO system to guide the feature point detection of the loop closure. As loop closure on wide-FoV panoramic data further comes with a large number of outliers, traditional outlier rejection methods are not directly applicable. To tackle this issue, we propose a loop closure framework with a new outlier rejection method based on the unit length representation, to improve the accuracy of LF-VIO. On the public PALVIO dataset, a comprehensive set of experiments is carried out and the proposed LF-VIO-Loop outperforms state-of-the-art visual-inertial-odometry methods. Our code will be open-sourced at https://github.com/flysoaryun/LF-VIO-Loop.
Prototypical few-shot segmentation for cross-institution male pelvic structures with spatial registration
Sep 12, 2022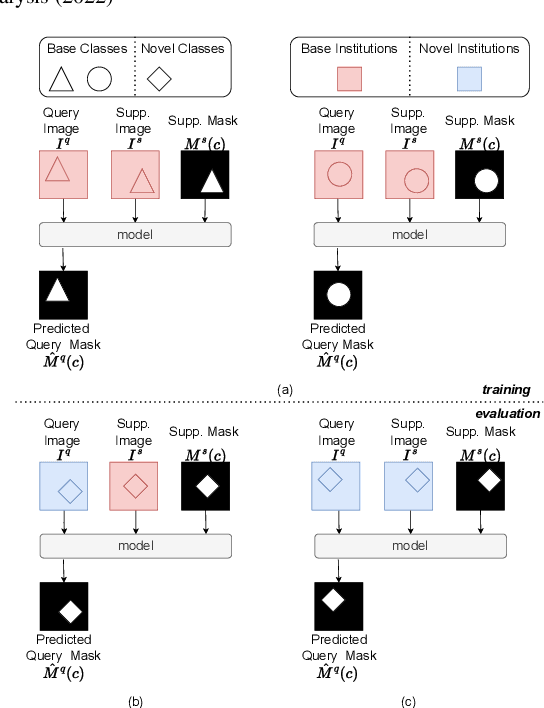

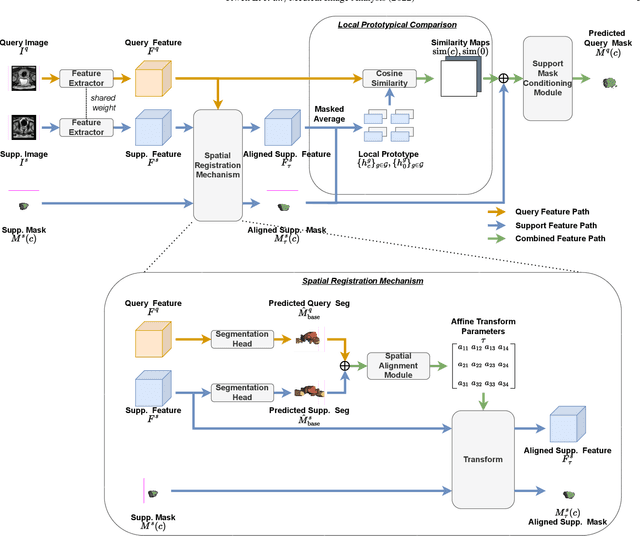

The prowess that makes few-shot learning desirable in medical image analysis is the efficient use of the support image data, which are labelled to classify or segment new classes, a task that otherwise requires substantially more training images and expert annotations. This work describes a fully 3D prototypical few-shot segmentation algorithm, such that the trained networks can be effectively adapted to clinically interesting structures that are absent in training, using only a few labelled images from a different institute. First, to compensate for the widely recognised spatial variability between institutions in episodic adaptation of novel classes, a novel spatial registration mechanism is integrated into prototypical learning, consisting of a segmentation head and an spatial alignment module. Second, to assist the training with observed imperfect alignment, support mask conditioning module is proposed to further utilise the annotation available from the support images. Extensive experiments are presented in an application of segmenting eight anatomical structures important for interventional planning, using a data set of 589 pelvic T2-weighted MR images, acquired at seven institutes. The results demonstrate the efficacy in each of the 3D formulation, the spatial registration, and the support mask conditioning, all of which made positive contributions independently or collectively. Compared with the previously proposed 2D alternatives, the few-shot segmentation performance was improved with statistical significance, regardless whether the support data come from the same or different institutes.
CheXRelNet: An Anatomy-Aware Model for Tracking Longitudinal Relationships between Chest X-Rays
Aug 08, 2022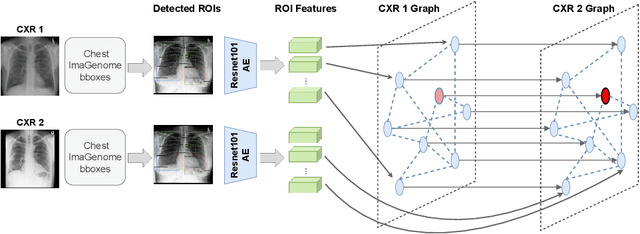
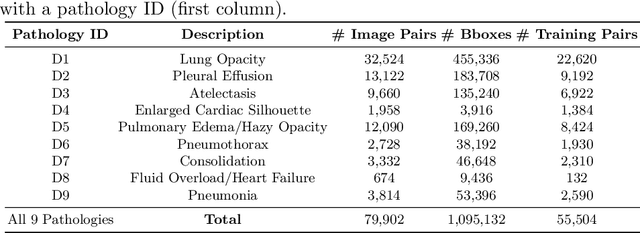
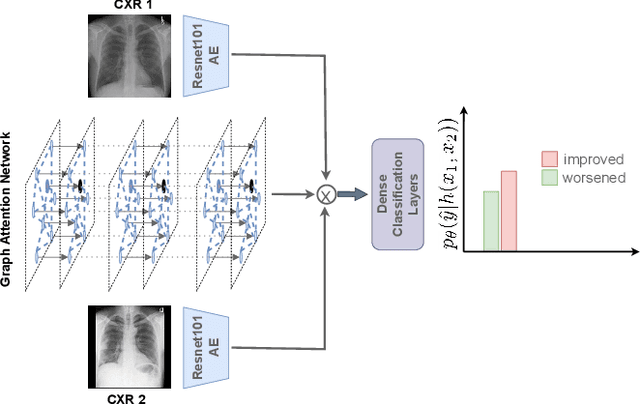
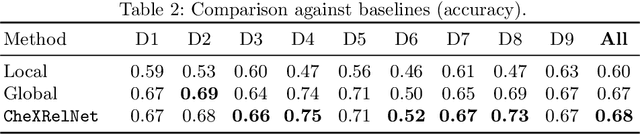
Despite the progress in utilizing deep learning to automate chest radiograph interpretation and disease diagnosis tasks, change between sequential Chest X-rays (CXRs) has received limited attention. Monitoring the progression of pathologies that are visualized through chest imaging poses several challenges in anatomical motion estimation and image registration, i.e., spatially aligning the two images and modeling temporal dynamics in change detection. In this work, we propose CheXRelNet, a neural model that can track longitudinal pathology change relations between two CXRs. CheXRelNet incorporates local and global visual features, utilizes inter-image and intra-image anatomical information, and learns dependencies between anatomical region attributes, to accurately predict disease change for a pair of CXRs. Experimental results on the Chest ImaGenome dataset show increased downstream performance compared to baselines. Code is available at https://github.com/PLAN-Lab/ChexRelNet
An Unsupervised Cross-Modal Hashing Method Robust to Noisy Training Image-Text Correspondences in Remote Sensing
Feb 26, 2022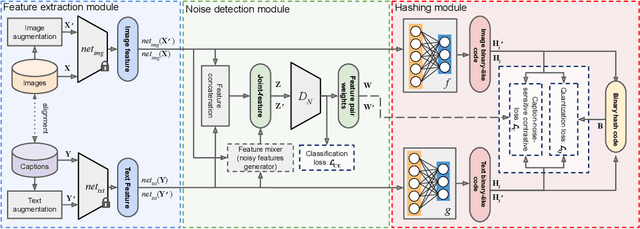
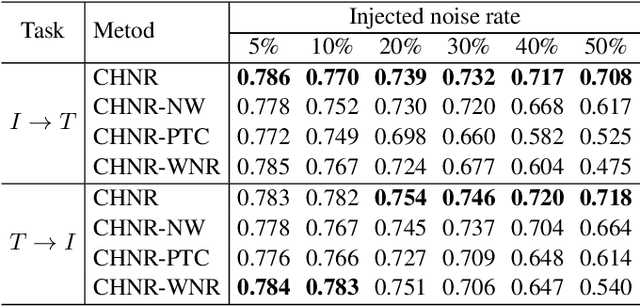
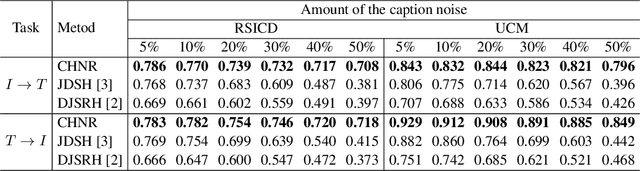
The development of accurate and scalable cross-modal image-text retrieval methods, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., remote sensing image) has attracted great attention in remote sensing (RS). Most of the existing methods assume that a reliable multi-modal training set with accurately matched text-image pairs is existing. However, this assumption may not always hold since the multi-modal training sets may include noisy pairs (i.e., textual descriptions/captions associated to training images can be noisy), distorting the learning process of the retrieval methods. To address this problem, we propose a novel unsupervised cross-modal hashing method robust to the noisy image-text correspondences (CHNR). CHNR consists of three modules: 1) feature extraction module, which extracts feature representations of image-text pairs; 2) noise detection module, which detects potential noisy correspondences; and 3) hashing module that generates cross-modal binary hash codes. The proposed CHNR includes two training phases: i) meta-learning phase that uses a small portion of clean (i.e., reliable) data to train the noise detection module in an adversarial fashion; and ii) the main training phase for which the trained noise detection module is used to identify noisy correspondences while the hashing module is trained on the noisy multi-modal training set. Experimental results show that the proposed CHNR outperforms state-of-the-art methods. Our code is publicly available at https://git.tu-berlin.de/rsim/chnr
Preservation of High Frequency Content for Deep Learning-Based Medical Image Classification
May 08, 2022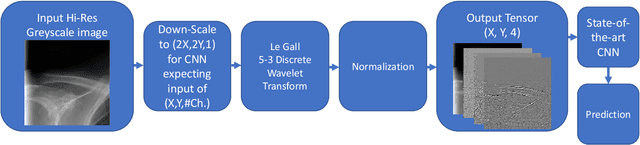
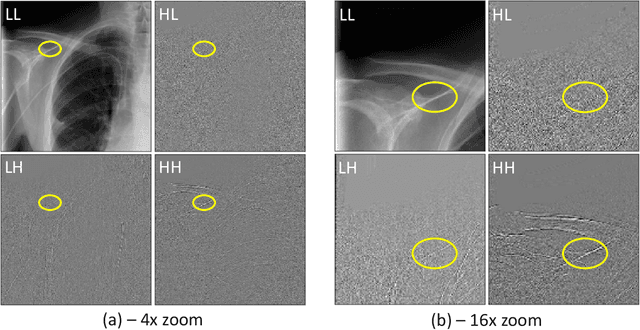
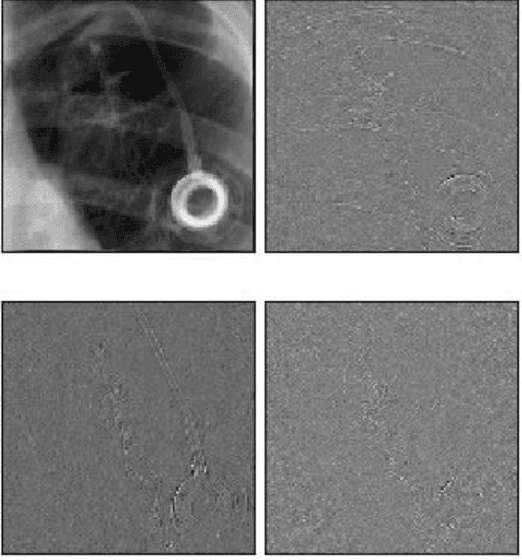
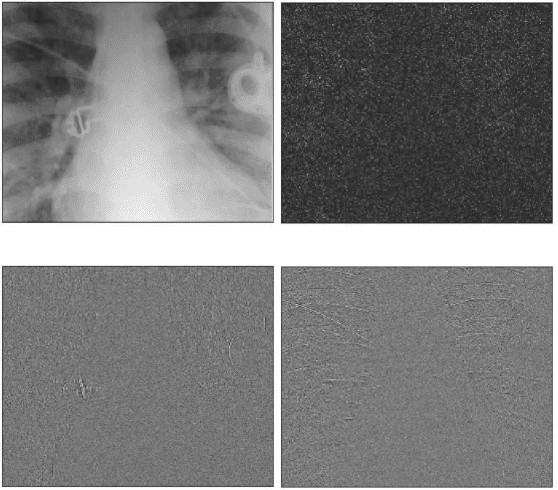
Chest radiographs are used for the diagnosis of multiple critical illnesses (e.g., Pneumonia, heart failure, lung cancer), for this reason, systems for the automatic or semi-automatic analysis of these data are of particular interest. An efficient analysis of large amounts of chest radiographs can aid physicians and radiologists, ultimately allowing for better medical care of lung-, heart- and chest-related conditions. We propose a novel Discrete Wavelet Transform (DWT)-based method for the efficient identification and encoding of visual information that is typically lost in the down-sampling of high-resolution radiographs, a common step in computer-aided diagnostic pipelines. Our proposed approach requires only slight modifications to the input of existing state-of-the-art Convolutional Neural Networks (CNNs), making it easily applicable to existing image classification frameworks. We show that the extra high-frequency components offered by our method increased the classification performance of several CNNs in benchmarks employing the NIH Chest-8 and ImageNet-2017 datasets. Based on our results we hypothesize that providing frequency-specific coefficients allows the CNNs to specialize in the identification of structures that are particular to a frequency band, ultimately increasing classification performance, without an increase in computational load. The implementation of our work is available at github.com/DeclanMcIntosh/LeGallCuda.
* Published in 2021 18th Conference on Robots and Vision (CRV). 8 pages with referances