 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detailed Annotations of Chest X-Rays via CT Projection for Report Understanding
Oct 07, 2022
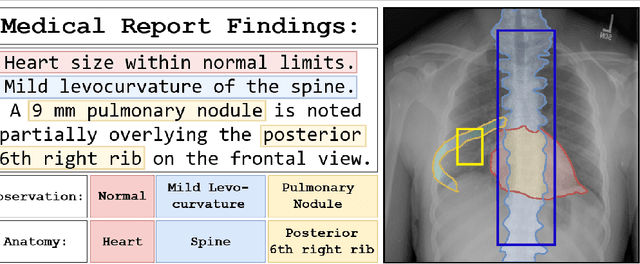
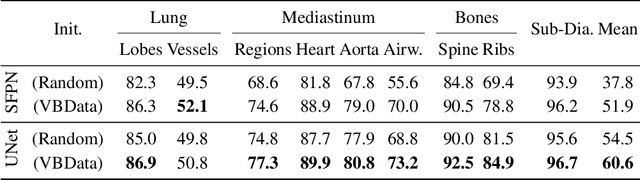
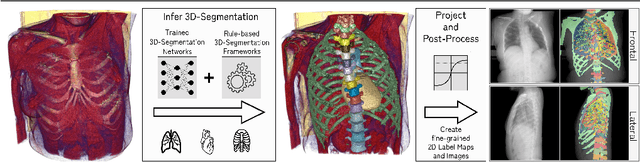
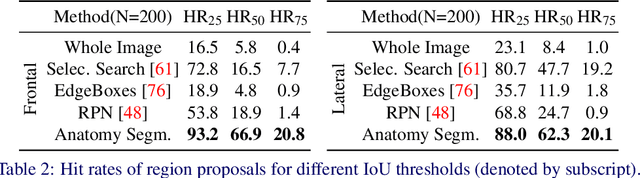
In clinical radiology reports, doctors capture important information about the patient's health status. They convey their observations from raw medical imaging data about the inner structures of a patient. As such, formulating reports requires medical experts to possess wide-ranging knowledge about anatomical regions with their normal, healthy appearance as well as the ability to recognize abnormalities. This explicit grasp on both the patient's anatomy and their appearance is missing in current medical image-processing systems as annotations are especially difficult to gather. This renders the models to be narrow experts e.g. for identifying specific diseases. In this work, we recover this missing link by adding human anatomy into the mix and enable the association of content in medical reports to their occurrence in associated imagery (medical phrase grounding). To exploit anatomical structures in this scenario, we present a sophisticated automatic pipeline to gather and integrate human bodily structures from computed tomography datasets, which we incorporate in our PAXRay: A Projected dataset for the segmentation of Anatomical structures in X-Ray data. Our evaluation shows that methods that take advantage of anatomical information benefit heavily in visually grounding radiologists' findings, as our anatomical segmentations allow for up to absolute 50% better grounding results on the OpenI dataset as compared to commonly used region proposals. The PAXRay dataset is available at https://constantinseibold.github.io/paxray/.
AutoML for Climate Change: A Call to Action
Oct 07, 2022

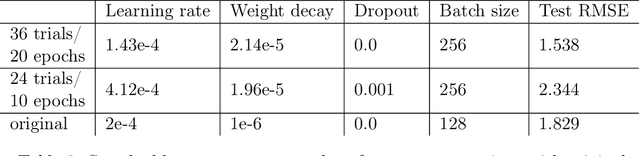

The challenge that climate change poses to humanity has spurred a rapidly developing field of artificial intelligence research focused on climate change applications. The climate change AI (CCAI) community works on a diverse, challenging set of problems which often involve physics-constrained ML or heterogeneous spatiotemporal data. It would be desirable to use automated machine learning (AutoML) techniques to automatically find high-performing architectures and hyperparameters for a given dataset. In this work, we benchmark popular AutoML libraries on three high-leverage CCAI applications: climate modeling, wind power forecasting, and catalyst discovery. We find that out-of-the-box AutoML libraries currently fail to meaningfully surpass the performance of human-designed CCAI models. However, we also identify a few key weaknesses, which stem from the fact that most AutoML techniques are tailored to computer vision and NLP applications. For example, while dozens of search spaces have been designed for image and language data, none have been designed for spatiotemporal data. Addressing these key weaknesses can lead to the discovery of novel architectures that yield substantial performance gains across numerous CCAI applications. Therefore, we present a call to action to the AutoML community, since there are a number of concrete, promising directions for future work in the space of AutoML for CCAI. We release our code and a list of resources at https://github.com/climate-change-automl/climate-change-automl.
Subject-Specific Lesion Generation and Pseudo-Healthy Synthesis for Multiple Sclerosis Brain Images
Aug 03, 2022
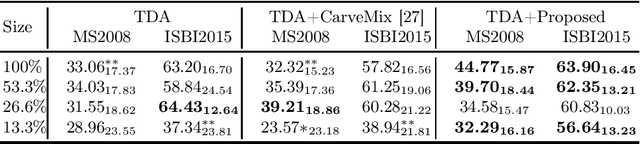
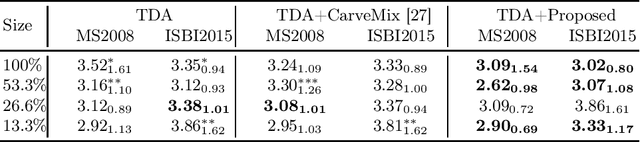
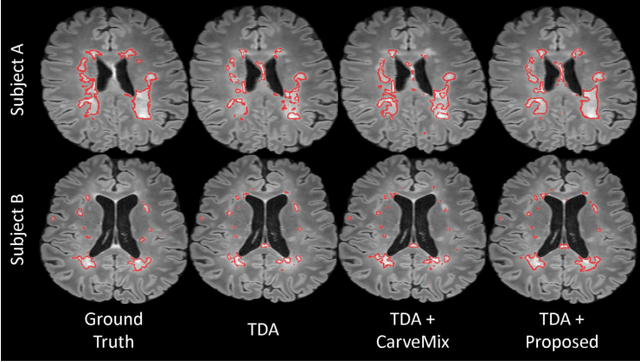
Understanding the intensity characteristics of brain lesions is key for defining image-based biomarkers in neurological studies and for predicting disease burden and outcome. In this work, we present a novel foreground-based generative method for modelling the local lesion characteristics that can both generate synthetic lesions on healthy images and synthesize subject-specific pseudo-healthy images from pathological images. Furthermore, the proposed method can be used as a data augmentation module to generate synthetic images for training brain image segmentation networks. Experiments on multiple sclerosis (MS) brain images acquired on magnetic resonance imaging (MRI) demonstrate that the proposed method can generate highly realistic pseudo-healthy and pseudo-pathological brain images. Data augmentation using the synthetic images improves the brain image segmentation performance compared to traditional data augmentation methods as well as a recent lesion-aware data augmentation technique, CarveMix. The code will be released at https://github.com/dogabasaran/lesion-synthesis.
A New Image Codec Paradigm for Human and Machine Uses
Dec 19, 2021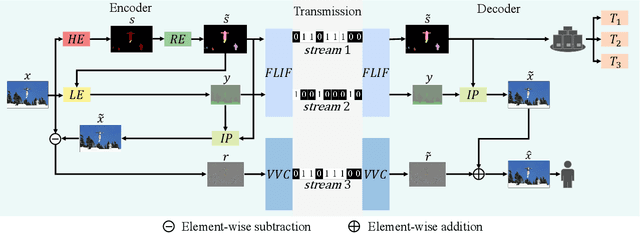
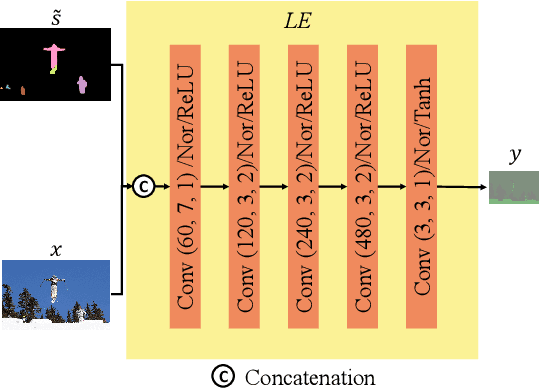
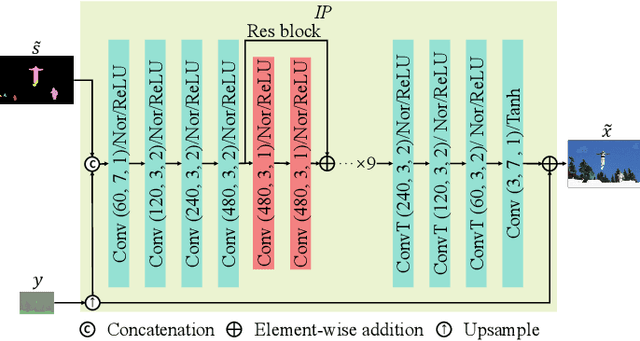
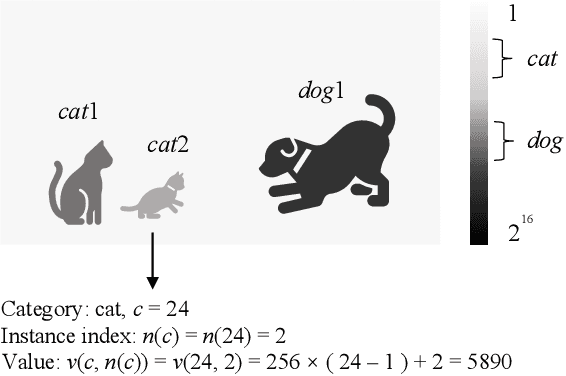
With the AI of Things (AIoT) development, a huge amount of visual data, e.g., images and videos, are produced in our daily work and life. These visual data are not only used for human viewing or understanding but also for machine analysis or decision-making, e.g., intelligent surveillance, automated vehicles, and many other smart city applications. To this end, a new image codec paradigm for both human and machine uses is proposed in this work. Firstly, the high-level instance segmentation map and the low-level signal features are extracted with neural networks. Then, the instance segmentation map is further represented as a profile with the proposed 16-bit gray-scale representation. After that, both 16-bit gray-scale profile and signal features are encoded with a lossless codec. Meanwhile, an image predictor is designed and trained to achieve the general-quality image reconstruction with the 16-bit gray-scale profile and signal features. Finally, the residual map between the original image and the predicted one is compressed with a lossy codec, used for high-quality image reconstruction. With such designs, on the one hand, we can achieve scalable image compression to meet the requirements of different human consumption; on the other hand, we can directly achieve several machine vision tasks at the decoder side with the decoded 16-bit gray-scale profile, e.g., object classification, detection, and segmentation. Experimental results show that the proposed codec achieves comparable results as most learning-based codecs and outperforms the traditional codecs (e.g., BPG and JPEG2000) in terms of PSNR and MS-SSIM for image reconstruction. At the same time, it outperforms the existing codecs in terms of the mAP for object detection and segmentation.
Strong Instance Segmentation Pipeline for MMSports Challenge
Sep 28, 2022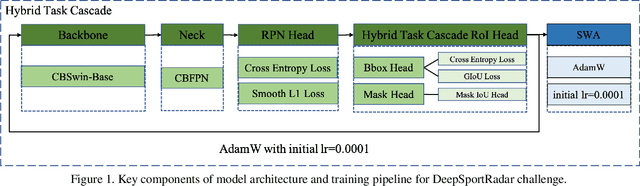

The goal of ACM MMSports2022 DeepSportRadar Instance Segmentation Challenge is to tackle the segmentation of individual humans including players, coaches and referees on a basketball court. And the main characteristics of this challenge are there is a high level of occlusions between players and the amount of data is quite limited. In order to address these problems, we designed a strong instance segmentation pipeline. Firstly, we employed a proper data augmentation strategy for this task mainly including photometric distortion transform and copy-paste strategy, which can generate more image instances with a wider distribution. Secondly, we employed a strong segmentation model, Hybrid Task Cascade based detector on the Swin-Base based CBNetV2 backbone, and we add MaskIoU head to HTCMaskHead that can simply and effectively improve the performance of instance segmentation. Finally, the SWA training strategy was applied to improve the performance further. Experimental results demonstrate the proposed pipeline can achieve a competitive result on the DeepSportRadar challenge, with 0.768AP@0.50:0.95 on the challenge set. Source code is available at https://github.com/YJingyu/Instanc_Segmentation_Pro.
DenseTact 2.0: Optical Tactile Sensor for Shape and Force Reconstruction
Sep 21, 2022
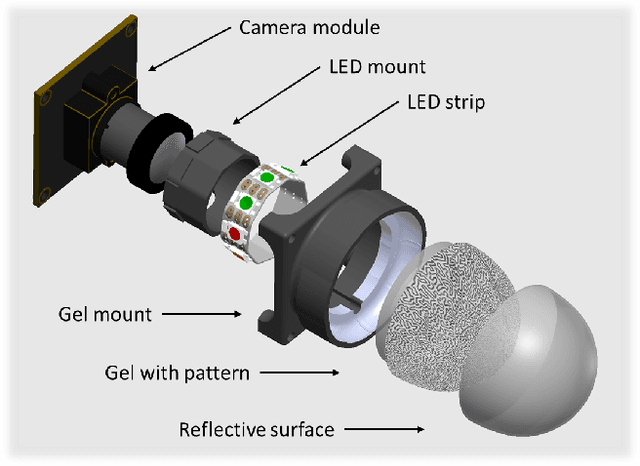
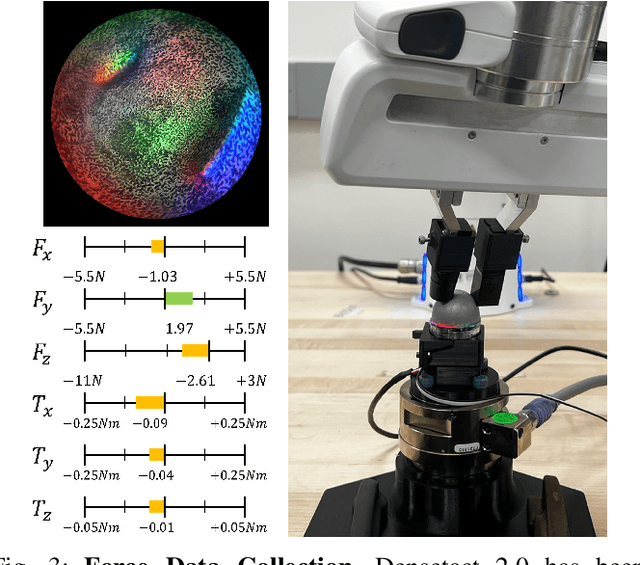
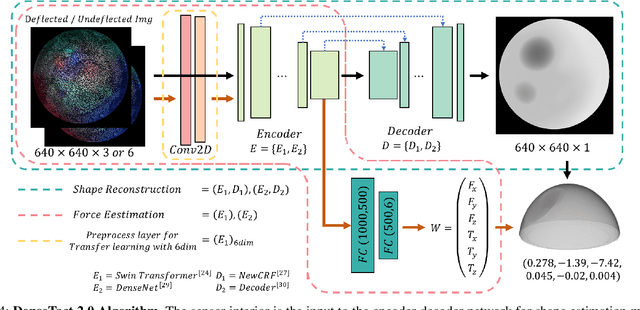
Collaborative robots stand to have an immense impact both on human welfare in domestic service applications and industrial superiority in advanced manufacturing requires dexterous assembly. The outstanding challenge is providing robotic fingertips with a physical design that makes them adept at performing dexterous tasks that require high-resolution, calibrated shape reconstruction and force sensing. In this work, we present DenseTact 2.0, an optical-tactile sensor capable of visualizing the deformed surface of a soft fingertip and using that image in a neural network to perform both calibrated shape reconstruction and 6-axis wrench estimation. We demonstrate the sensor accuracy of 0.3633mm per pixel for shape reconstruction, 0.410N for forces, 0.387mmNm for torques, and the ability to calibrate new fingers through transfer learning, achieving comparable performance that trained more than four times faster with only 12% of the dataset size.
Keypoint-GraspNet: Keypoint-based 6-DoF Grasp Generation from the Monocular RGB-D input
Sep 19, 2022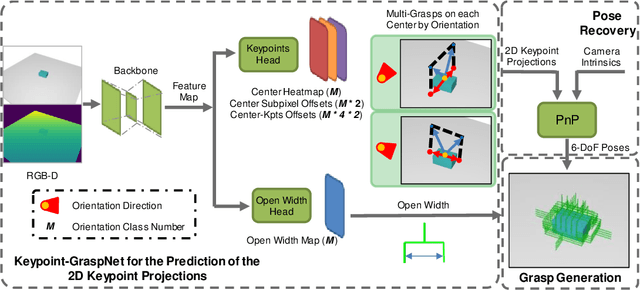
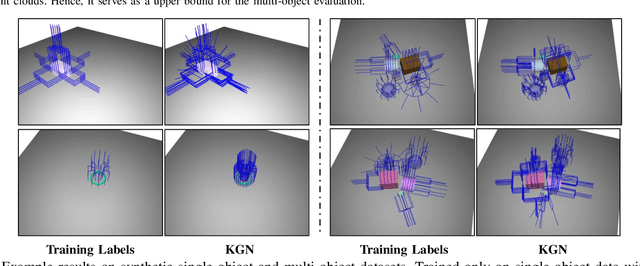
Great success has been achieved in the 6-DoF grasp learning from the point cloud input, yet the computational cost due to the point set orderlessness remains a concern. Alternatively, we explore the grasp generation from the RGB-D input in this paper. The proposed solution, Keypoint-GraspNet, detects the projection of the gripper keypoints in the image space and then recover the SE(3) poses with a PnP algorithm. A synthetic dataset based on the primitive shape and the grasp family is constructed to examine our idea. Metric-based evaluation reveals that our method outperforms the baselines in terms of the grasp proposal accuracy, diversity, and the time cost. Finally, robot experiments show high success rate, demonstrating the potential of the idea in the real-world applications.
Low rank prior and l0 norm to remove impulse noise in images
Sep 12, 2022
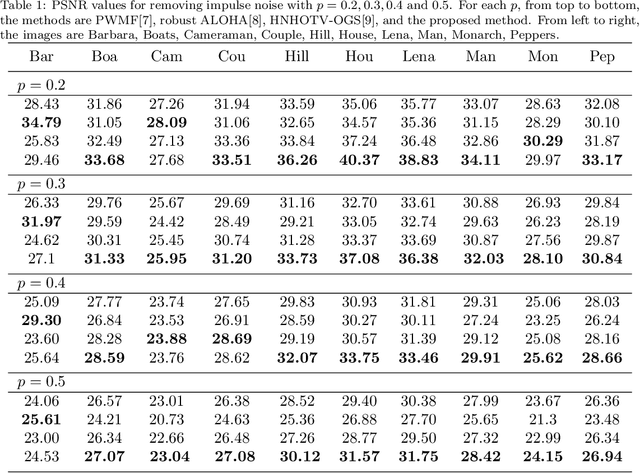
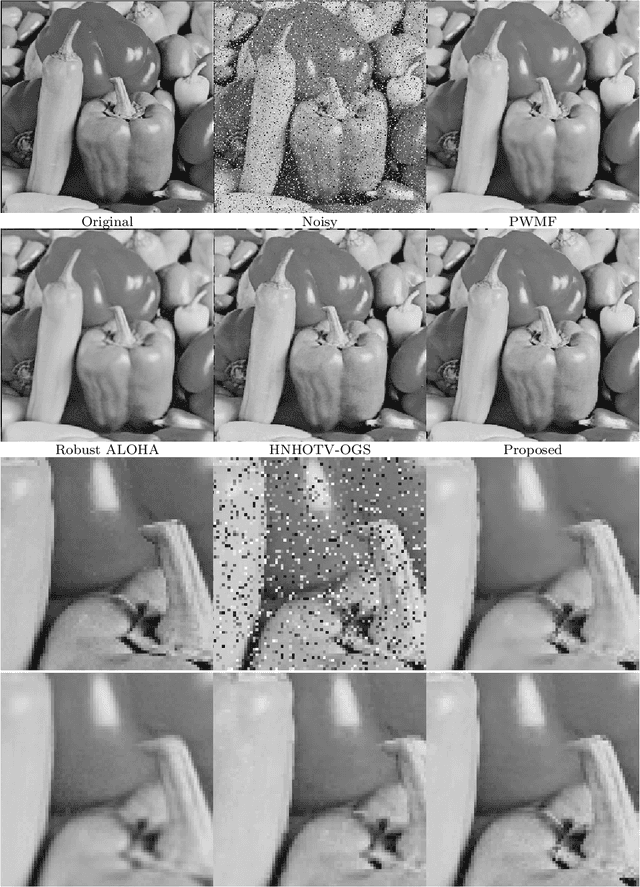

Patch-based low rank is an important prior assumption for image processing. Moreover, according to our calculation, the optimization of l0 norm corresponds to the maximum likelihood estimation under random-valued impulse noise. In this article, we thus combine exact rank and l0 norm for removing the noise. It is solved formally using the alternating direction method of multipliers (ADMM), with our previous patch-based weighted filter (PWMF) producing initial images. Since this model is not convex, we consider it as a Plug-and-Play ADMM, and do not discuss theoretical convergence properties. Experiments show that this method has very good performance, especially for weak or medium contrast images.
On the Road to Online Adaptation for Semantic Image Segmentation
Mar 30, 2022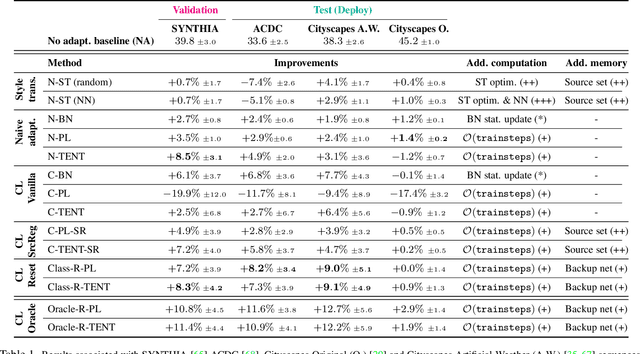
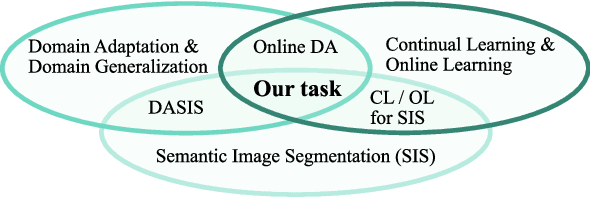

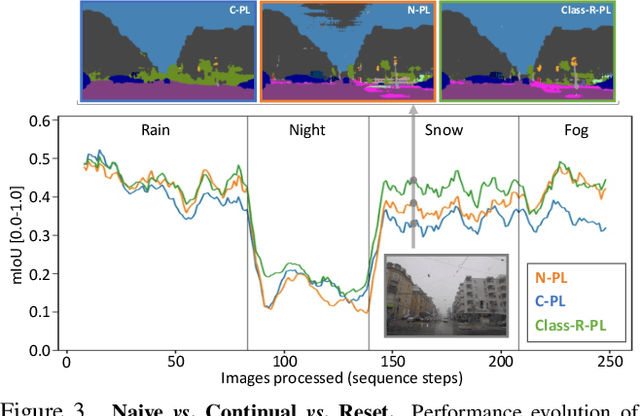
We propose a new problem formulation and a corresponding evaluation framework to advance research on unsupervised domain adaptation for semantic image segmentation. The overall goal is fostering the development of adaptive learning systems that will continuously learn, without supervision, in ever-changing environments. Typical protocols that study adaptation algorithms for segmentation models are limited to few domains, adaptation happens offline, and human intervention is generally required, at least to annotate data for hyper-parameter tuning. We argue that such constraints are incompatible with algorithms that can continuously adapt to different real-world situations. To address this, we propose a protocol where models need to learn online, from sequences of temporally correlated images, requiring continuous, frame-by-frame adaptation. We accompany this new protocol with a variety of baselines to tackle the proposed formulation, as well as an extensive analysis of their behaviors, which can serve as a starting point for future research.
A Survey on Training Challenges in Generative Adversarial Networks for Biomedical Image Analysis
Jan 19, 2022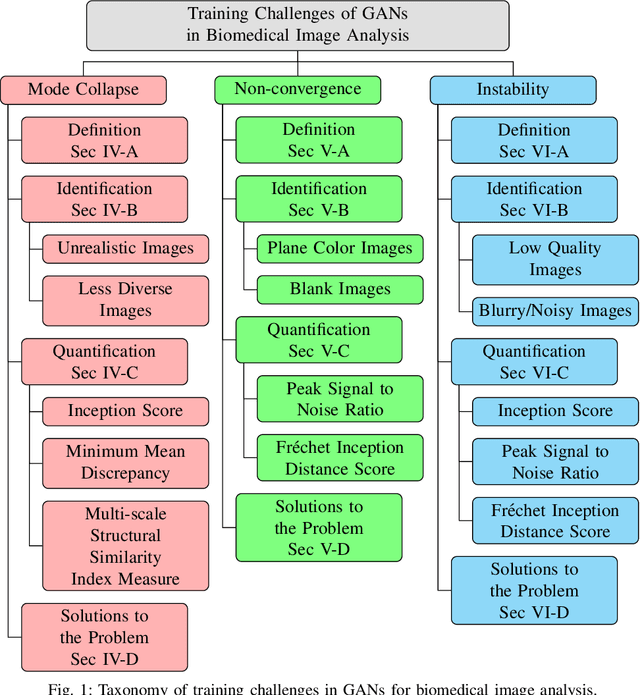
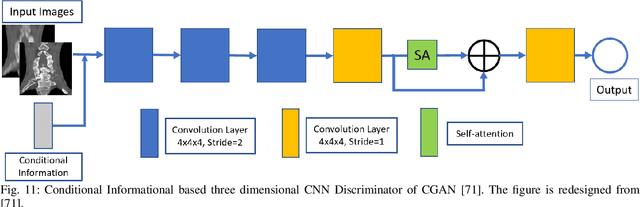
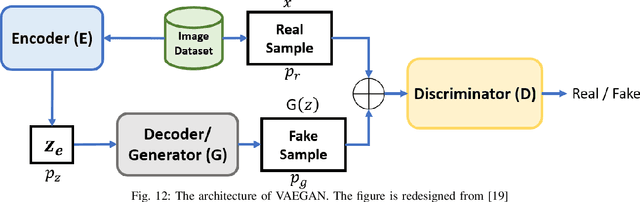
In biomedical image analysis, the applicability of deep learning methods is directly impacted by the quantity of image data available. This is due to deep learning models requiring large image datasets to provide high-level performance. Generative Adversarial Networks (GANs) have been widely utilized to address data limitations through the generation of synthetic biomedical images. GANs consist of two models. The generator, a model that learns how to produce synthetic images based on the feedback it receives. The discriminator, a model that classifies an image as synthetic or real and provides feedback to the generator. Throughout the training process, a GAN can experience several technical challenges that impede the generation of suitable synthetic imagery. First, the mode collapse problem whereby the generator either produces an identical image or produces a uniform image from distinct input features. Second, the non-convergence problem whereby the gradient descent optimizer fails to reach a Nash equilibrium. Thirdly, the vanishing gradient problem whereby unstable training behavior occurs due to the discriminator achieving optimal classification performance resulting in no meaningful feedback being provided to the generator. These problems result in the production of synthetic imagery that is blurry, unrealistic, and less diverse. To date, there has been no survey article outlining the impact of these technical challenges in the context of the biomedical imagery domain. This work presents a review and taxonomy based on solutions to the training problems of GANs in the biomedical imaging domain. This survey highlights important challenges and outlines future research directions about the training of GANs in the domain of biomedical imagery.