 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
IronDepth: Iterative Refinement of Single-View Depth using Surface Normal and its Uncertainty
Oct 07, 2022
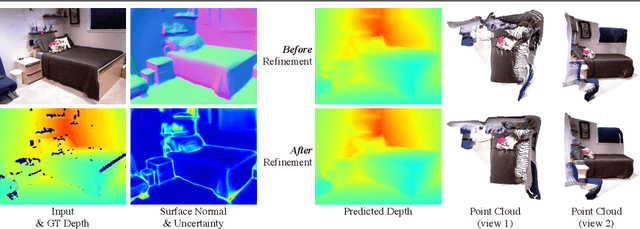
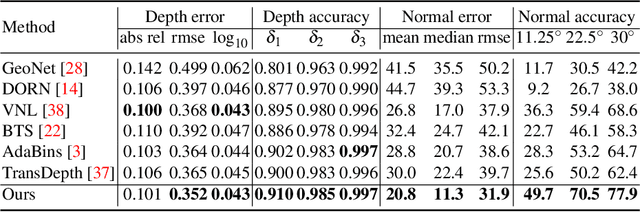
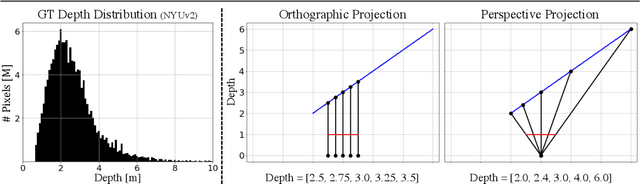
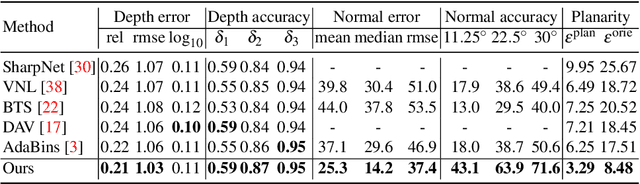
Single image surface normal estimation and depth estimation are closely related problems as the former can be calculated from the latter. However, the surface normals computed from the output of depth estimation methods are significantly less accurate than the surface normals directly estimated by networks. To reduce such discrepancy, we introduce a novel framework that uses surface normal and its uncertainty to recurrently refine the predicted depth-map. The depth of each pixel can be propagated to a query pixel, using the predicted surface normal as guidance. We thus formulate depth refinement as a classification of choosing the neighboring pixel to propagate from. Then, by propagating to sub-pixel points, we upsample the refined, low-resolution output. The proposed method shows state-of-the-art performance on NYUv2 and iBims-1 - both in terms of depth and normal. Our refinement module can also be attached to the existing depth estimation methods to improve their accuracy. We also show that our framework, only trained for depth estimation, can also be used for depth completion. The code is available at https://github.com/baegwangbin/IronDepth.
Atomized Deep Learning Models
Oct 07, 2022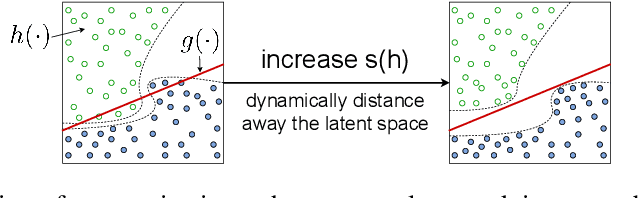
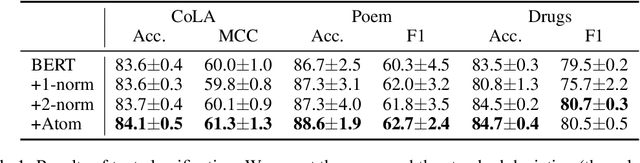
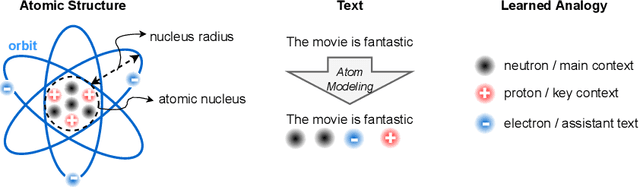
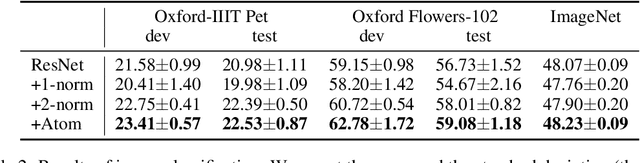
Deep learning models often tackle the intra-sample structure, such as the order of words in a sentence and pixels in an image, but have not pay much attention to the inter-sample relationship. In this paper, we show that explicitly modeling the inter-sample structure to be more discretized can potentially help model's expressivity. We propose a novel method, Atom Modeling, that can discretize a continuous latent space by drawing an analogy between a data point and an atom, which is naturally spaced away from other atoms with distances depending on their intra structures. Specifically, we model each data point as an atom composed of electrons, protons, and neutrons and minimize the potential energy caused by the interatomic force among data points. Through experiments with qualitative analysis in our proposed Atom Modeling on synthetic and real datasets, we find that Atom Modeling can improve the performance by maintaining the inter-sample relation and can capture an interpretable intra-sample relation by mapping each component in a data point to electron/proton/neutron.
Neural Clamping: Joint Input Perturbation and Temperature Scaling for Neural Network Calibration
Sep 23, 2022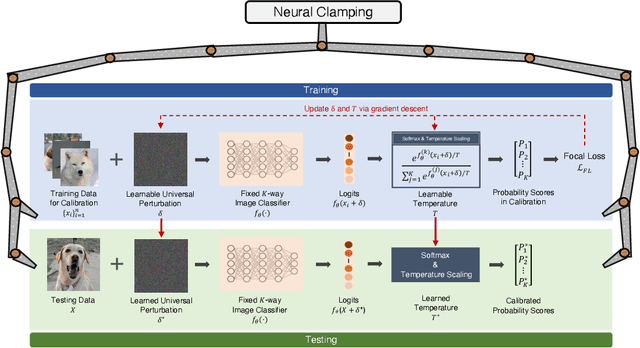
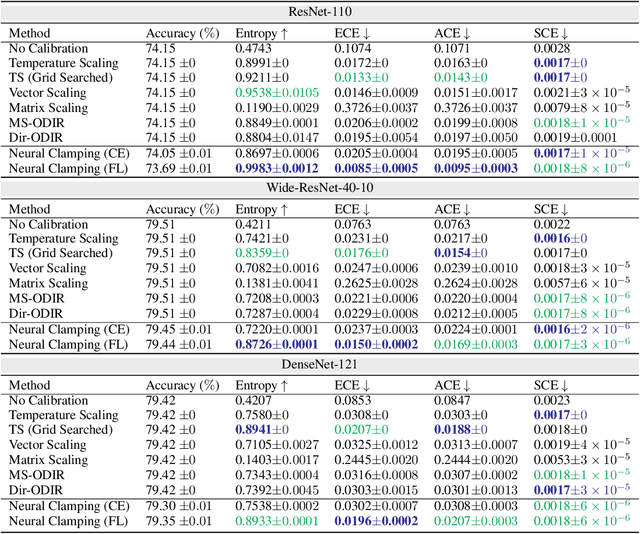
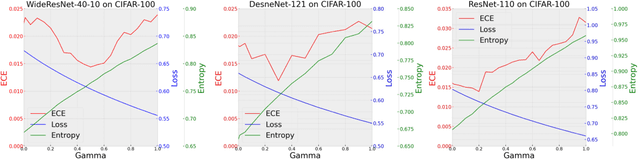
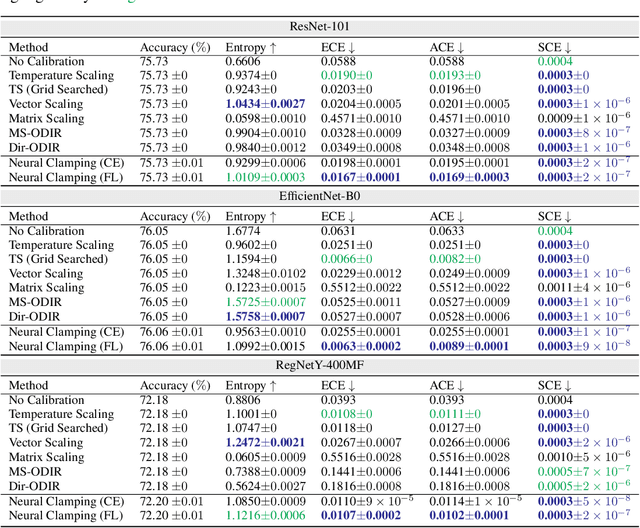
Neural network calibration is an essential task in deep learning to ensure consistency between the confidence of model prediction and the true correctness likelihood. In this paper, we propose a new post-processing calibration method called Neural Clamping, which employs a simple joint input-output transformation on a pre-trained classifier via a learnable universal input perturbation and an output temperature scaling parameter. Moreover, we provide theoretical explanations on why Neural Clamping is provably better than temperature scaling. Evaluated on CIFAR-100 and ImageNet image recognition datasets and a variety of deep neural network models, our empirical results show that Neural Clamping significantly outperforms state-of-the-art post-processing calibration methods.
Asymmetric Student-Teacher Networks for Industrial Anomaly Detection
Oct 18, 2022
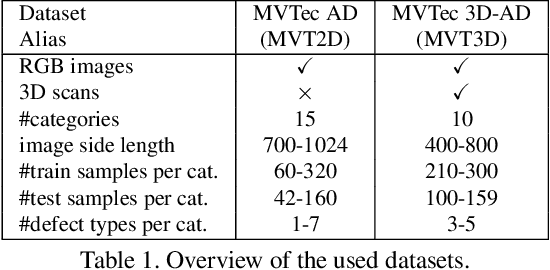
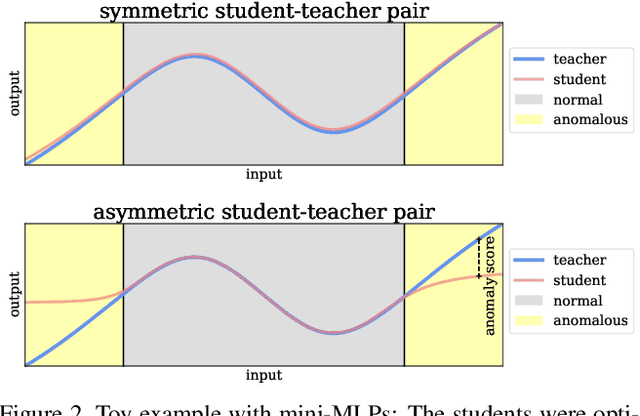
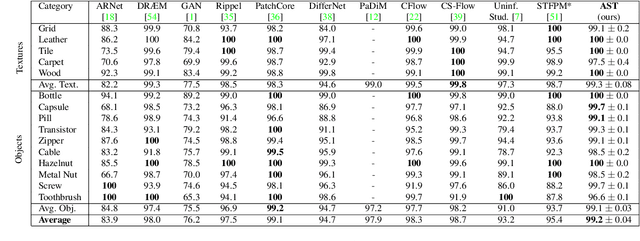
Industrial defect detection is commonly addressed with anomaly detection (AD) methods where no or only incomplete data of potentially occurring defects is available. This work discovers previously unknown problems of student-teacher approaches for AD and proposes a solution, where two neural networks are trained to produce the same output for the defect-free training examples. The core assumption of student-teacher networks is that the distance between the outputs of both networks is larger for anomalies since they are absent in training. However, previous methods suffer from the similarity of student and teacher architecture, such that the distance is undesirably small for anomalies. For this reason, we propose asymmetric student-teacher networks (AST). We train a normalizing flow for density estimation as a teacher and a conventional feed-forward network as a student to trigger large distances for anomalies: The bijectivity of the normalizing flow enforces a divergence of teacher outputs for anomalies compared to normal data. Outside the training distribution the student cannot imitate this divergence due to its fundamentally different architecture. Our AST network compensates for wrongly estimated likelihoods by a normalizing flow, which was alternatively used for anomaly detection in previous work. We show that our method produces state-of-the-art results on the two currently most relevant defect detection datasets MVTec AD and MVTec 3D-AD regarding image-level anomaly detection on RGB and 3D data.
Differentially Private Diffusion Models
Oct 18, 2022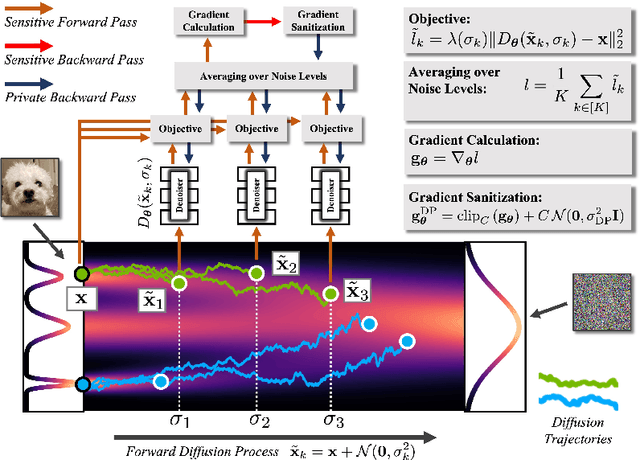
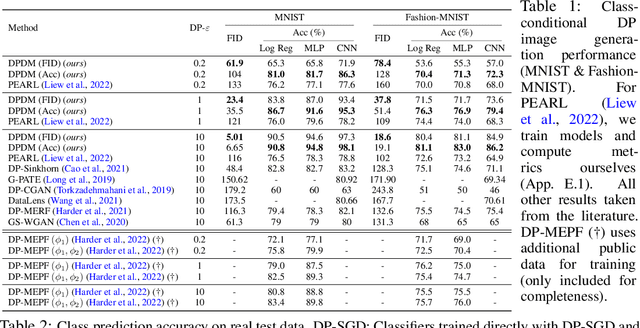
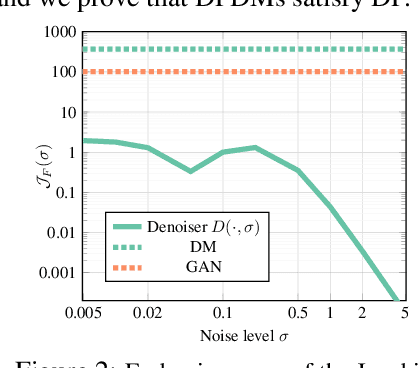
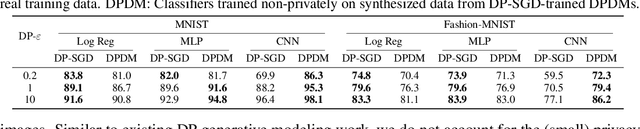
While modern machine learning models rely on increasingly large training datasets, data is often limited in privacy-sensitive domains. Generative models trained with differential privacy (DP) on sensitive data can sidestep this challenge, providing access to synthetic data instead. However, training DP generative models is highly challenging due to the noise injected into training to enforce DP. We propose to leverage diffusion models (DMs), an emerging class of deep generative models, and introduce Differentially Private Diffusion Models (DPDMs), which enforce privacy using differentially private stochastic gradient descent (DP-SGD). We motivate why DP-SGD is well suited for training DPDMs, and thoroughly investigate the DM parameterization and the sampling algorithm, which turn out to be crucial ingredients in DPDMs. Furthermore, we propose noise multiplicity, a simple yet powerful modification of the DM training objective tailored to the DP setting to boost performance. We validate our novel DPDMs on widely-used image generation benchmarks and achieve state-of-the-art (SOTA) performance by large margins. For example, on MNIST we improve the SOTA FID from 48.4 to 5.01 and downstream classification accuracy from 83.2% to 98.1% for the privacy setting DP-$(\varepsilon{=}10, \delta{=}10^{-5})$. Moreover, on standard benchmarks, classifiers trained on DPDM-generated synthetic data perform on par with task-specific DP-SGD-trained classifiers, which has not been demonstrated before for DP generative models. Project page and code: https://nv-tlabs.github.io/DPDM.
On effects of Knowledge Distillation on Transfer Learning
Oct 18, 2022
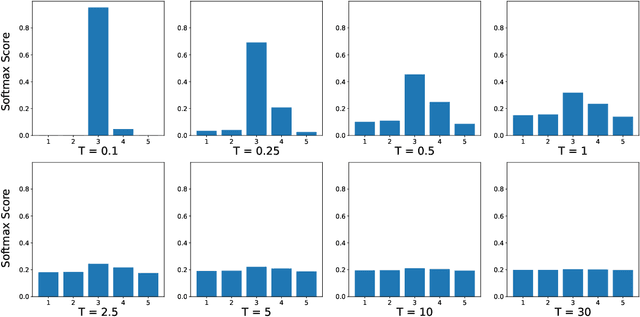

Knowledge distillation is a popular machine learning technique that aims to transfer knowledge from a large 'teacher' network to a smaller 'student' network and improve the student's performance by training it to emulate the teacher. In recent years, there has been significant progress in novel distillation techniques that push performance frontiers across multiple problems and benchmarks. Most of the reported work focuses on achieving state-of-the-art results on the specific problem. However, there has been a significant gap in understanding the process and how it behaves under certain training scenarios. Similarly, transfer learning (TL) is an effective technique in training neural networks on a limited dataset faster by reusing representations learned from a different but related problem. Despite its effectiveness and popularity, there has not been much exploration of knowledge distillation on transfer learning. In this thesis, we propose a machine learning architecture we call TL+KD that combines knowledge distillation with transfer learning; we then present a quantitative and qualitative comparison of TL+KD with TL in the domain of image classification. Through this work, we show that using guidance and knowledge from a larger teacher network during fine-tuning, we can improve the student network to achieve better validation performances like accuracy. We characterize the improvement in the validation performance of the model using a variety of metrics beyond just accuracy scores, and study its performance in scenarios such as input degradation.
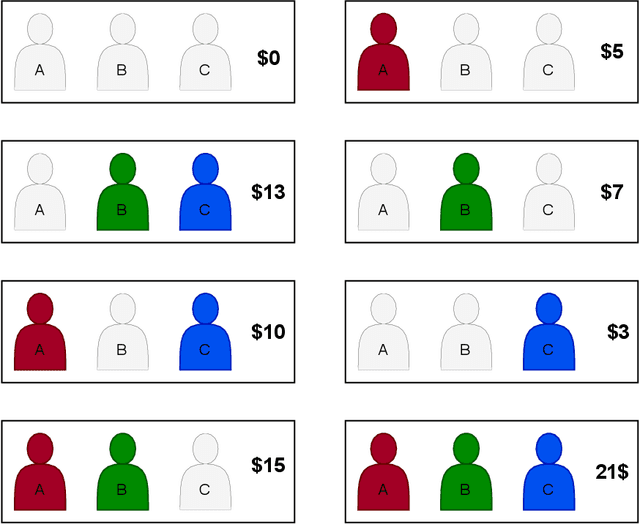
Confidence estimation of classification based on the distribution of the neural network output layer
Oct 18, 2022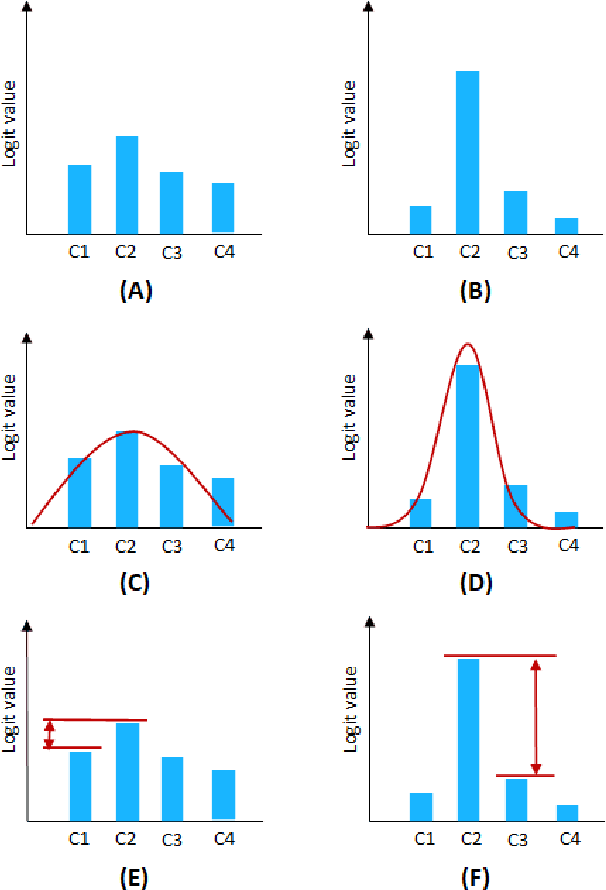
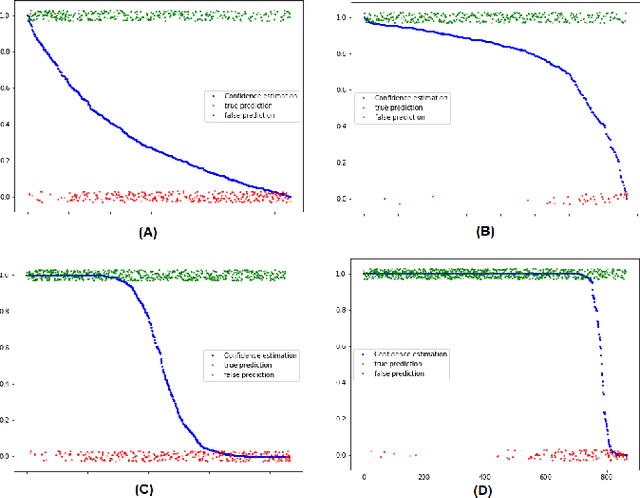
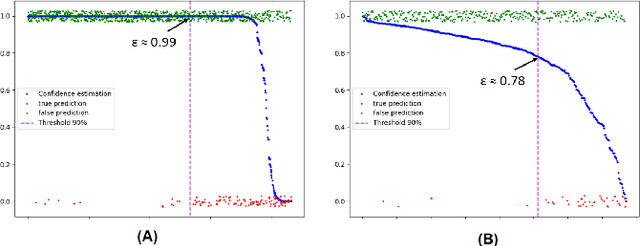
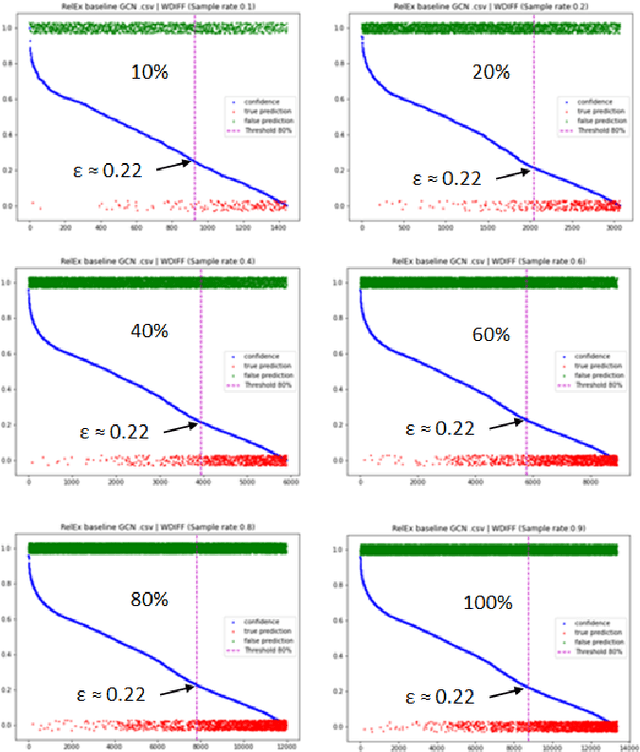
One of the most common problems preventing the application of prediction models in the real world is lack of generalization: The accuracy of models, measured in the benchmark does repeat itself on future data, e.g. in the settings of real business. There is relatively little methods exist that estimate the confidence of prediction models. In this paper, we propose novel methods that, given a neural network classification model, estimate uncertainty of particular predictions generated by this model. Furthermore, we propose a method that, given a model and a confidence level, calculates a threshold that separates prediction generated by this model into two subsets, one of them meets the given confidence level. In contrast to other methods, the proposed methods do not require any changes on existing neural networks, because they simply build on the output logit layer of a common neural network. In particular, the methods infer the confidence of a particular prediction based on the distribution of the logit values corresponding to this prediction. The proposed methods constitute a tool that is recommended for filtering predictions in the process of knowledge extraction, e.g. based on web scrapping, where predictions subsets are identified that maximize the precision on cost of the recall, which is less important due to the availability of data. The method has been tested on different tasks including relation extraction, named entity recognition and image classification to show the significant increase of accuracy achieved.
4D Unsupervised Object Discovery
Oct 10, 2022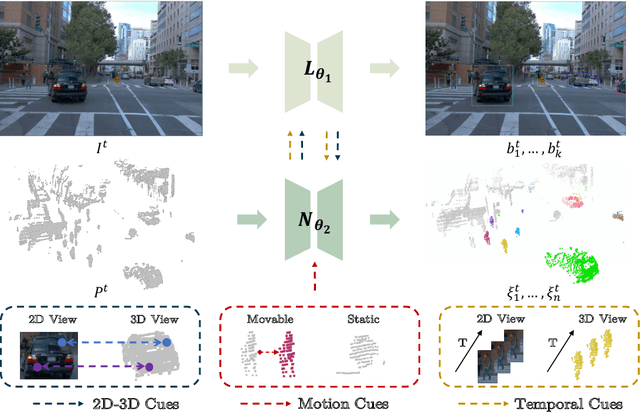
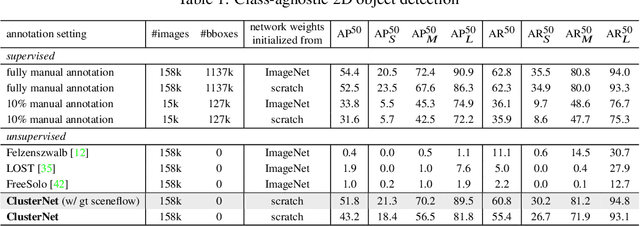

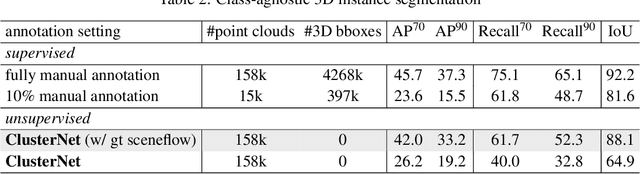
Object discovery is a core task in computer vision. While fast progresses have been made in supervised object detection, its unsupervised counterpart remains largely unexplored. With the growth of data volume, the expensive cost of annotations is the major limitation hindering further study. Therefore, discovering objects without annotations has great significance. However, this task seems impractical on still-image or point cloud alone due to the lack of discriminative information. Previous studies underlook the crucial temporal information and constraints naturally behind multi-modal inputs. In this paper, we propose 4D unsupervised object discovery, jointly discovering objects from 4D data -- 3D point clouds and 2D RGB images with temporal information. We present the first practical approach for this task by proposing a ClusterNet on 3D point clouds, which is jointly iteratively optimized with a 2D localization network. Extensive experiments on the large-scale Waymo Open Dataset suggest that the localization network and ClusterNet achieve competitive performance on both class-agnostic 2D object detection and 3D instance segmentation, bridging the gap between unsupervised methods and full supervised ones. Codes and models will be made available at https://github.com/Robertwyq/LSMOL.
PHTrans: Parallelly Aggregating Global and Local Representations for Medical Image Segmentation
Mar 09, 2022
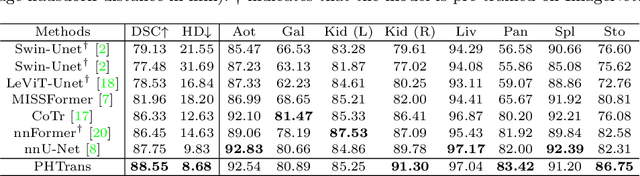

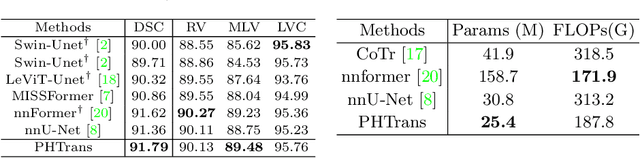
The success of Transformer in computer vision has attracted increasing attention in the medical imaging community. Especially for medical image segmentation, many excellent hybrid architectures based on convolutional neural networks (CNNs) and Transformer have been presented and achieve impressive performance. However, most of these methods, which embed modular Transformer into CNNs, struggle to reach their full potential. In this paper, we propose a novel hybrid architecture for medical image segmentation called PHTrans, which parallelly hybridizes Transformer and CNN in main building blocks to produce hierarchical representations from global and local features and adaptively aggregate them, aiming to fully exploit their strengths to obtain better segmentation performance. Specifically, PHTrans follows the U-shaped encoder-decoder design and introduces the parallel hybird module in deep stages, where convolution blocks and the modified 3D Swin Transformer learn local features and global dependencies separately, then a sequence-to-volume operation unifies the dimensions of the outputs to achieve feature aggregation. Extensive experimental results on both Multi-Atlas Labeling Beyond the Cranial Vault and Automated Cardiac Diagnosis Challeng datasets corroborate its effectiveness, consistently outperforming state-of-the-art methods.
Multi-Representation Adaptation Network for Cross-domain Image Classification
Jan 04, 2022
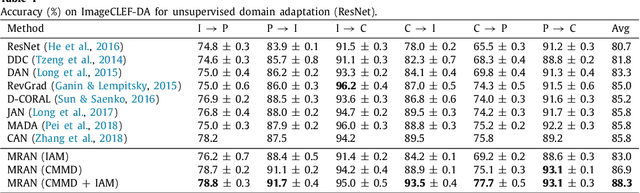
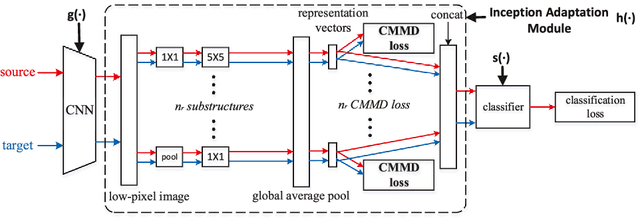
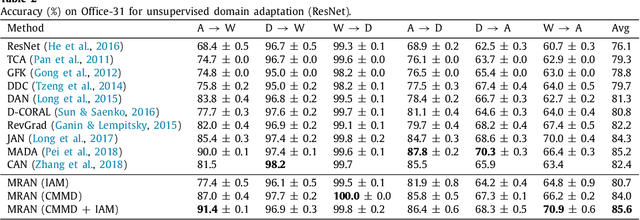
In image classification, it is often expensive and time-consuming to acquire sufficient labels. To solve this problem, domain adaptation often provides an attractive option given a large amount of labeled data from a similar nature but different domain. Existing approaches mainly align the distributions of representations extracted by a single structure and the representations may only contain partial information, e.g., only contain part of the saturation, brightness, and hue information. Along this line, we propose Multi-Representation Adaptation which can dramatically improve the classification accuracy for cross-domain image classification and specially aims to align the distributions of multiple representations extracted by a hybrid structure named Inception Adaptation Module (IAM). Based on this, we present Multi-Representation Adaptation Network (MRAN) to accomplish the cross-domain image classification task via multi-representation alignment which can capture the information from different aspects. In addition, we extend Maximum Mean Discrepancy (MMD) to compute the adaptation loss. Our approach can be easily implemented by extending most feed-forward models with IAM, and the network can be trained efficiently via back-propagation. Experiments conducted on three benchmark image datasets demonstrate the effectiveness of MRAN. The code has been available at https://github.com/easezyc/deep-transfer-learning.