 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BoostMIS: Boosting Medical Image Semi-supervised Learning with Adaptive Pseudo Labeling and Informative Active Annotation
Mar 21, 2022
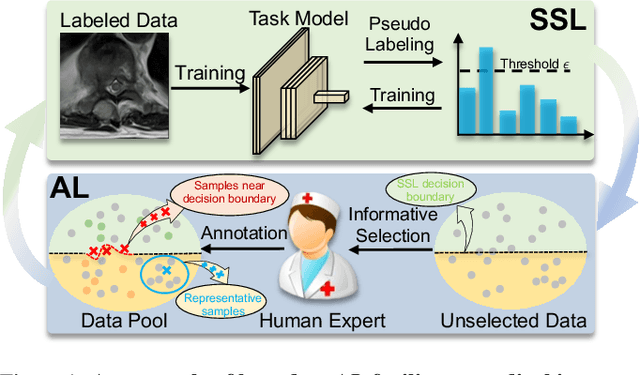
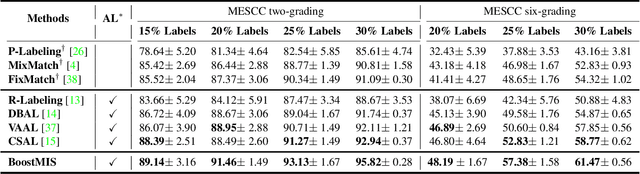
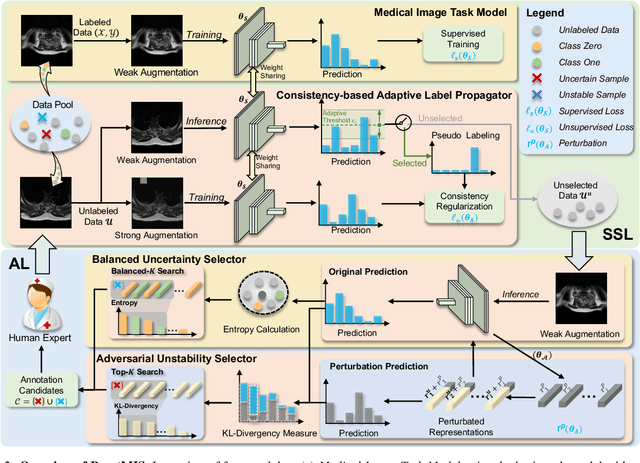
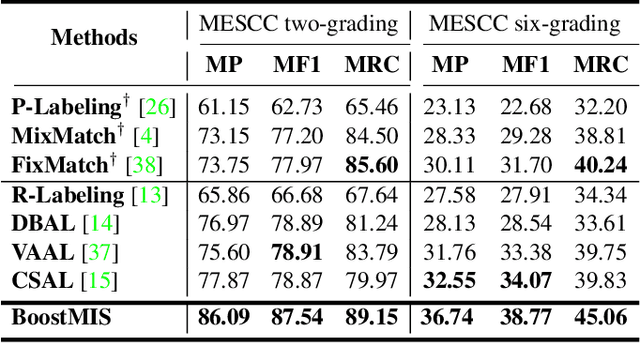
In this paper, we propose a novel semi-supervised learning (SSL) framework named BoostMIS that combines adaptive pseudo labeling and informative active annotation to unleash the potential of medical image SSL models: (1) BoostMIS can adaptively leverage the cluster assumption and consistency regularization of the unlabeled data according to the current learning status. This strategy can adaptively generate one-hot "hard" labels converted from task model predictions for better task model training. (2) For the unselected unlabeled images with low confidence, we introduce an Active learning (AL) algorithm to find the informative samples as the annotation candidates by exploiting virtual adversarial perturbation and model's density-aware entropy. These informative candidates are subsequently fed into the next training cycle for better SSL label propagation. Notably, the adaptive pseudo-labeling and informative active annotation form a learning closed-loop that are mutually collaborative to boost medical image SSL. To verify the effectiveness of the proposed method, we collected a metastatic epidural spinal cord compression (MESCC) dataset that aims to optimize MESCC diagnosis and classification for improved specialist referral and treatment. We conducted an extensive experimental study of BoostMIS on MESCC and another public dataset COVIDx. The experimental results verify our framework's effectiveness and generalisability for different medical image datasets with a significant improvement over various state-of-the-art methods.
* 11 pages
Zero-Shot Sketch Based Image Retrieval using Graph Transformer
Jan 25, 2022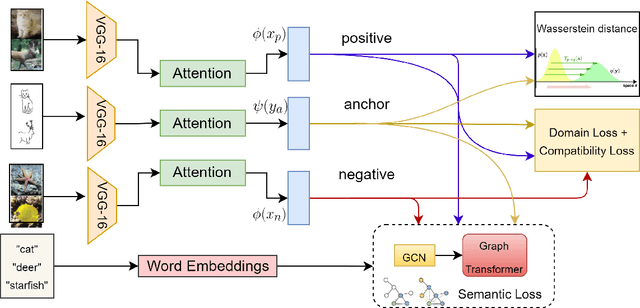
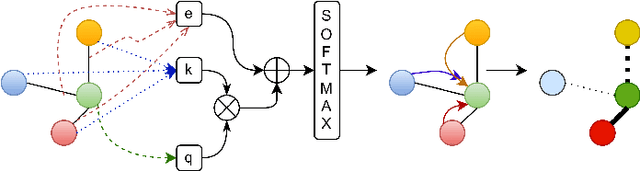

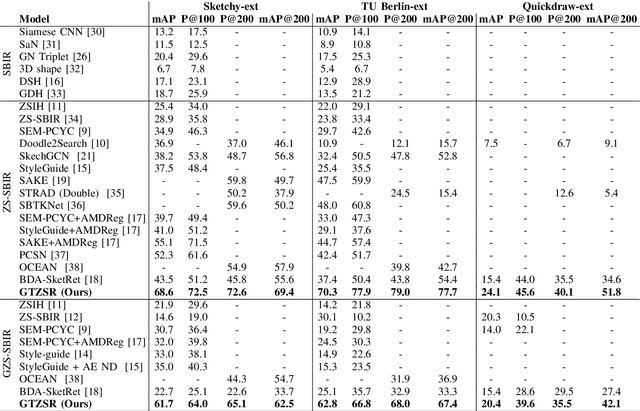
The performance of a zero-shot sketch-based image retrieval (ZS-SBIR) task is primarily affected by two challenges. The substantial domain gap between image and sketch features needs to be bridged, while at the same time the side information has to be chosen tactfully. Existing literature has shown that varying the semantic side information greatly affects the performance of ZS-SBIR. To this end, we propose a novel graph transformer based zero-shot sketch-based image retrieval (GTZSR) framework for solving ZS-SBIR tasks which uses a novel graph transformer to preserve the topology of the classes in the semantic space and propagates the context-graph of the classes within the embedding features of the visual space. To bridge the domain gap between the visual features, we propose minimizing the Wasserstein distance between images and sketches in a learned domain-shared space. We also propose a novel compatibility loss that further aligns the two visual domains by bridging the domain gap of one class with respect to the domain gap of all other classes in the training set. Experimental results obtained on the extended Sketchy, TU-Berlin, and QuickDraw datasets exhibit sharp improvements over the existing state-of-the-art methods in both ZS-SBIR and generalized ZS-SBIR.
Tree-based Text-Vision BERT for Video Search in Baidu Video Advertising
Sep 19, 2022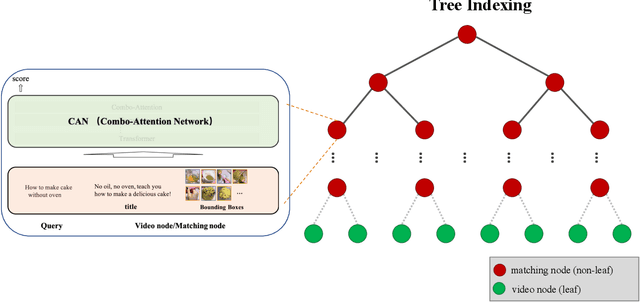
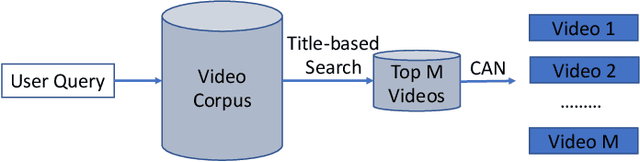
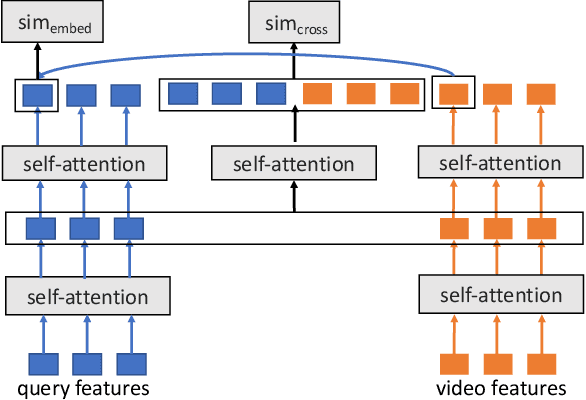

The advancement of the communication technology and the popularity of the smart phones foster the booming of video ads. Baidu, as one of the leading search engine companies in the world, receives billions of search queries per day. How to pair the video ads with the user search is the core task of Baidu video advertising. Due to the modality gap, the query-to-video retrieval is much more challenging than traditional query-to-document retrieval and image-to-image search. Traditionally, the query-to-video retrieval is tackled by the query-to-title retrieval, which is not reliable when the quality of tiles are not high. With the rapid progress achieved in computer vision and natural language processing in recent years, content-based search methods becomes promising for the query-to-video retrieval. Benefited from pretraining on large-scale datasets, some visionBERT methods based on cross-modal attention have achieved excellent performance in many vision-language tasks not only in academia but also in industry. Nevertheless, the expensive computation cost of cross-modal attention makes it impractical for large-scale search in industrial applications. In this work, we present a tree-based combo-attention network (TCAN) which has been recently launched in Baidu's dynamic video advertising platform. It provides a practical solution to deploy the heavy cross-modal attention for the large-scale query-to-video search. After launching tree-based combo-attention network, click-through rate gets improved by 2.29\% and conversion rate get improved by 2.63\%.
Adaptive Network Combination for Single-Image Reflection Removal: A Domain Generalization Perspective
Apr 04, 2022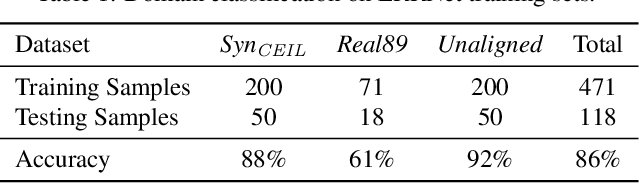
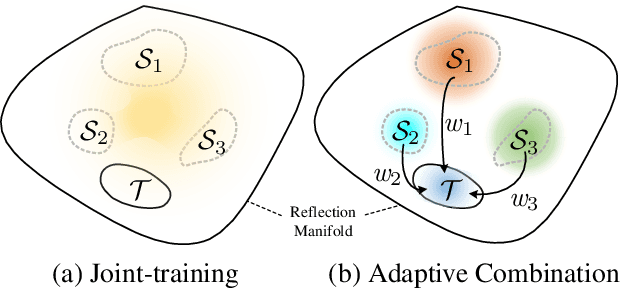
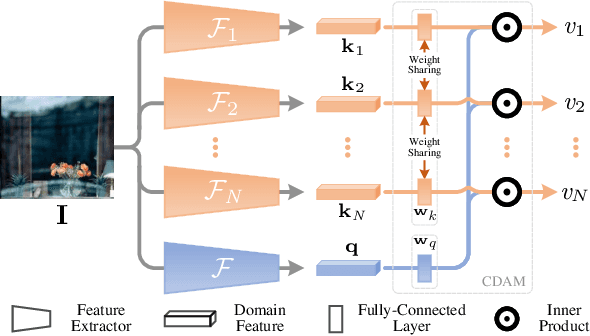

Recently, multiple synthetic and real-world datasets have been built to facilitate the training of deep single image reflection removal (SIRR) models. Meanwhile, diverse testing sets are also provided with different types of reflection and scenes. However, the non-negligible domain gaps between training and testing sets make it difficult to learn deep models generalizing well to testing images. The diversity of reflections and scenes further makes it a mission impossible to learn a single model being effective to all testing sets and real-world reflections. In this paper, we tackle these issues by learning SIRR models from a domain generalization perspective. Particularly, for each source set, a specific SIRR model is trained to serve as a domain expert of relevant reflection types. For a given reflection-contaminated image, we present a reflection type-aware weighting (RTAW) module to predict expert-wise weights. RTAW can then be incorporated with adaptive network combination (AdaNEC) for handling different reflection types and scenes, i.e., generalizing to unknown domains. Two representative AdaNEC methods, i.e., output fusion (OF) and network interpolation (NI), are provided by considering both adaptation levels and efficiency. For images from one source set, we train RTAW to only predict expert-wise weights of other domain experts for improving generalization ability, while the weights of all experts are predicted and employed during testing. An in-domain expert (IDE) loss is presented for training RTAW. Extensive experiments show the appealing performance gain of our AdaNEC on different state-of-the-art SIRR networks. Source code and pre-trained models will available at https://github.com/csmliu/AdaNEC.
Towards a unified view of unsupervised non-local methods for image denoising: the NL-Ridge approach
Mar 01, 2022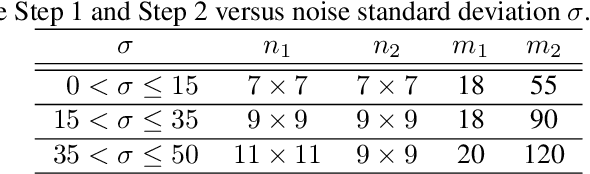

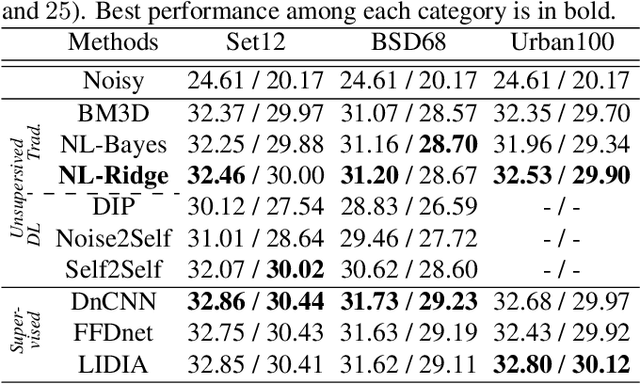
We propose a unified view of unsupervised non-local methods for image denoising that linearily combine noisy image patches. The best methods, established in different modeling and estimation frameworks, are two-step algorithms. Leveraging Stein's unbiased risk estimate (SURE) for the first step and the "internal adaptation", a concept borrowed from deep learning theory, for the second one, we show that our NL-Ridge approach enables to reconcile several patch aggregation methods for image denoising. In the second step, our closed-form aggregation weights are computed through multivariate Ridge regressions. Experiments on artificially noisy images demonstrate that NL-Ridge may outperform well established state-of-the-art unsupervised denoisers such as BM3D and NL-Bayes, as well as recent unsupervised deep learning methods, while being simpler conceptually.
MaIL: A Unified Mask-Image-Language Trimodal Network for Referring Image Segmentation
Nov 25, 2021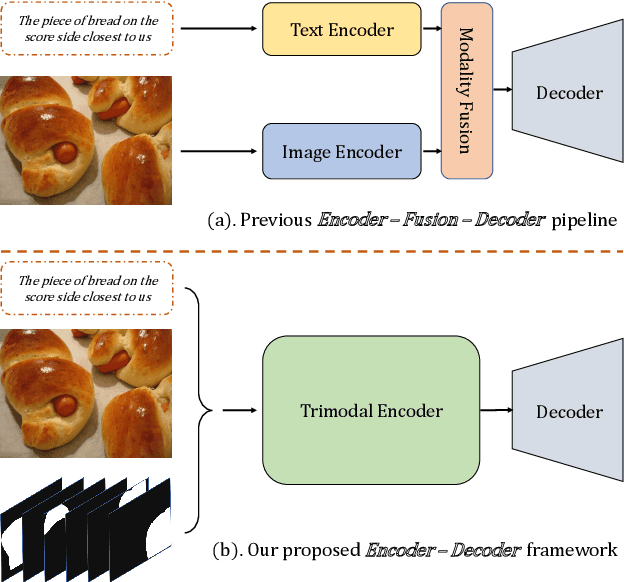
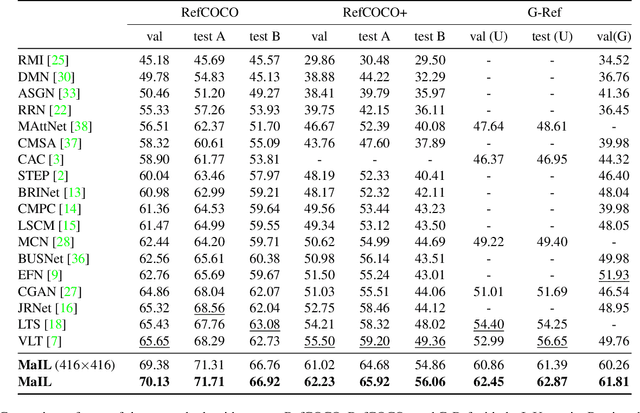
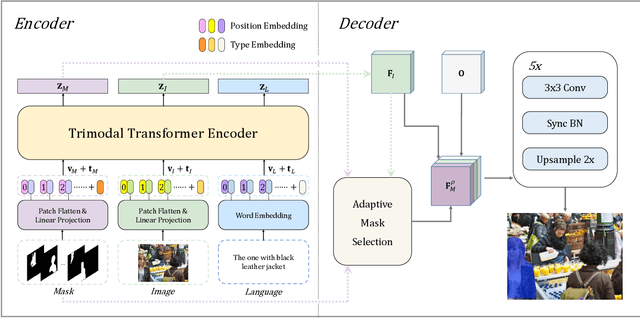
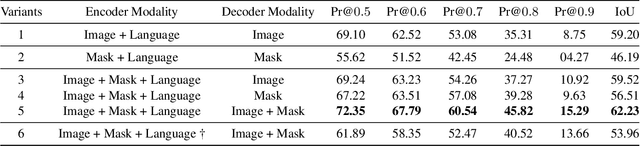
Referring image segmentation is a typical multi-modal task, which aims at generating a binary mask for referent described in given language expressions. Prior arts adopt a bimodal solution, taking images and languages as two modalities within an encoder-fusion-decoder pipeline. However, this pipeline is sub-optimal for the target task for two reasons. First, they only fuse high-level features produced by uni-modal encoders separately, which hinders sufficient cross-modal learning. Second, the uni-modal encoders are pre-trained independently, which brings inconsistency between pre-trained uni-modal tasks and the target multi-modal task. Besides, this pipeline often ignores or makes little use of intuitively beneficial instance-level features. To relieve these problems, we propose MaIL, which is a more concise encoder-decoder pipeline with a Mask-Image-Language trimodal encoder. Specifically, MaIL unifies uni-modal feature extractors and their fusion model into a deep modality interaction encoder, facilitating sufficient feature interaction across different modalities. Meanwhile, MaIL directly avoids the second limitation since no uni-modal encoders are needed anymore. Moreover, for the first time, we propose to introduce instance masks as an additional modality, which explicitly intensifies instance-level features and promotes finer segmentation results. The proposed MaIL set a new state-of-the-art on all frequently-used referring image segmentation datasets, including RefCOCO, RefCOCO+, and G-Ref, with significant gains, 3%-10% against previous best methods. Code will be released soon.
Image-to-Video Re-Identification via Mutual Discriminative Knowledge Transfer
Jan 21, 2022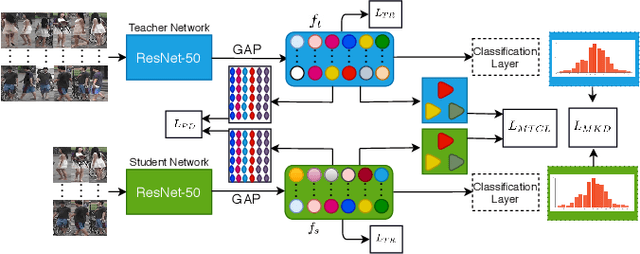
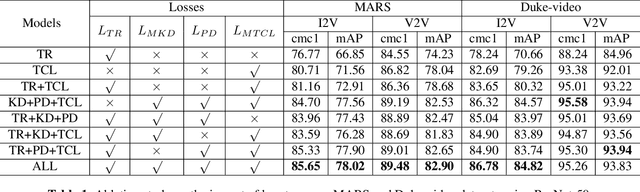
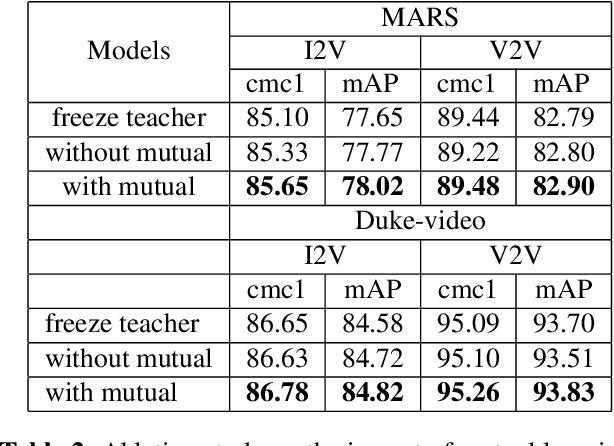
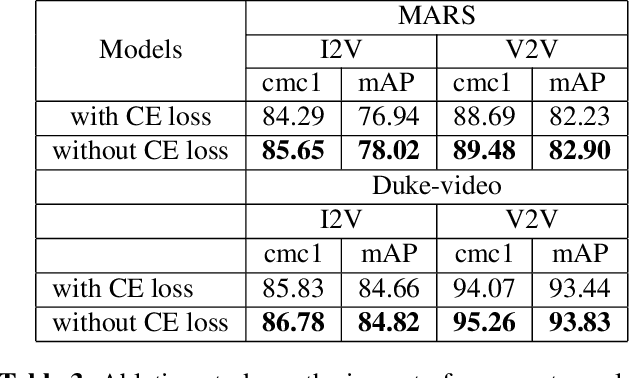
The gap in representations between image and video makes Image-to-Video Re-identification (I2V Re-ID) challenging, and recent works formulate this problem as a knowledge distillation (KD) process. In this paper, we propose a mutual discriminative knowledge distillation framework to transfer a video-based richer representation to an image based representation more effectively. Specifically, we propose the triplet contrast loss (TCL), a novel loss designed for KD. During the KD process, the TCL loss transfers the local structure, exploits the higher order information, and mitigates the misalignment of the heterogeneous output of teacher and student networks. Compared with other losses for KD, the proposed TCL loss selectively transfers the local discriminative features from teacher to student, making it effective in the ReID. Besides the TCL loss, we adopt mutual learning to regularize both the teacher and student networks training. Extensive experiments demonstrate the effectiveness of our method on the MARS, DukeMTMC-VideoReID and VeRi-776 benchmarks.
FreDSNet: Joint Monocular Depth and Semantic Segmentation with Fast Fourier Convolutions
Oct 04, 2022
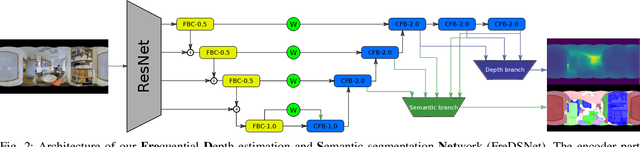


In this work we present FreDSNet, a deep learning solution which obtains semantic 3D understanding of indoor environments from single panoramas. Omnidirectional images reveal task-specific advantages when addressing scene understanding problems due to the 360-degree contextual information about the entire environment they provide. However, the inherent characteristics of the omnidirectional images add additional problems to obtain an accurate detection and segmentation of objects or a good depth estimation. To overcome these problems, we exploit convolutions in the frequential domain obtaining a wider receptive field in each convolutional layer. These convolutions allow to leverage the whole context information from omnidirectional images. FreDSNet is the first network that jointly provides monocular depth estimation and semantic segmentation from a single panoramic image exploiting fast Fourier convolutions. Our experiments show that FreDSNet has similar performance as specific state of the art methods for semantic segmentation and depth estimation. FreDSNet code is publicly available in https://github.com/Sbrunoberenguel/FreDSNet
Mind The Gap: Alleviating Local Imbalance for Unsupervised Cross-Modality Medical Image Segmentation
May 24, 2022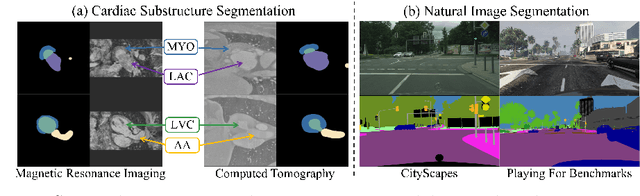
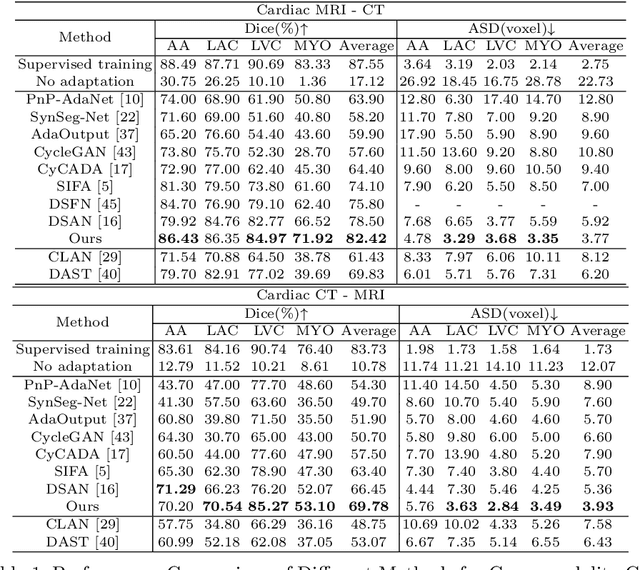

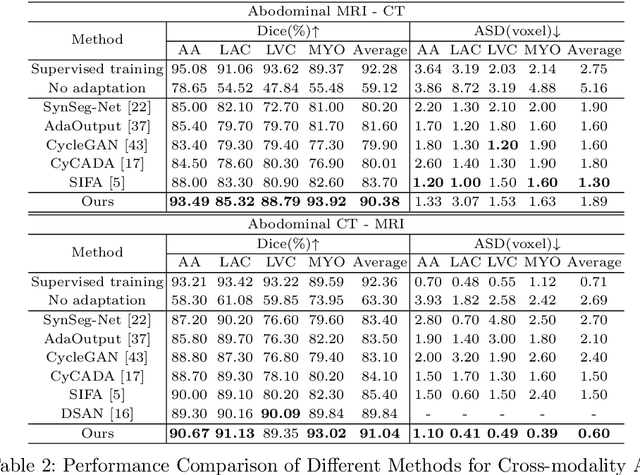
Unsupervised cross-modality medical image adaptation aims to alleviate the severe domain gap between different imaging modalities without using the target domain label. A key in this campaign relies upon aligning the distributions of source and target domain. One common attempt is to enforce the global alignment between two domains, which, however, ignores the fatal local-imbalance domain gap problem, i.e., some local features with larger domain gap are harder to transfer. Recently, some methods conduct alignment focusing on local regions to improve the efficiency of model learning. While this operation may cause a deficiency of critical information from contexts. To tackle this limitation, we propose a novel strategy to alleviate the domain gap imbalance considering the characteristics of medical images, namely Global-Local Union Alignment. Specifically, a feature-disentanglement style-transfer module first synthesizes the target-like source-content images to reduce the global domain gap. Then, a local feature mask is integrated to reduce the 'inter-gap' for local features by prioritizing those discriminative features with larger domain gap. This combination of global and local alignment can precisely localize the crucial regions in segmentation target while preserving the overall semantic consistency. We conduct a series of experiments with two cross-modality adaptation tasks, i,e. cardiac substructure and abdominal multi-organ segmentation. Experimental results indicate that our method exceeds the SOTA methods by 3.92% Dice score in MRI-CT cardiac segmentation and 3.33% in the reverse direction.
Prototypical few-shot segmentation for cross-institution male pelvic structures with spatial registration
Sep 13, 2022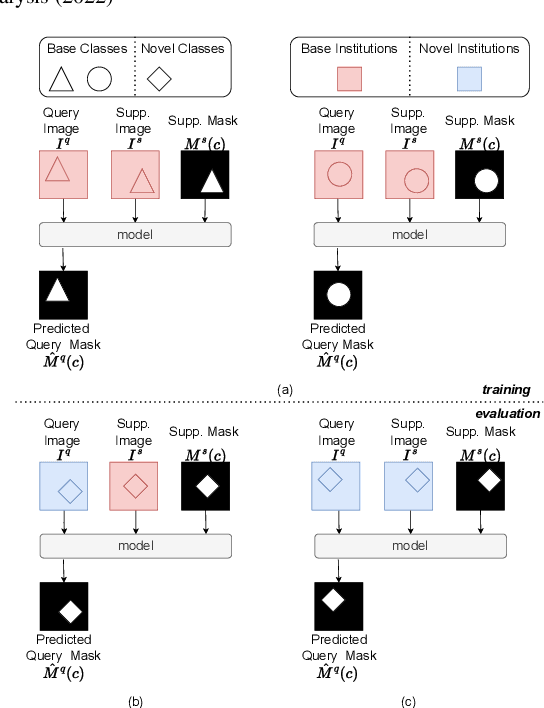

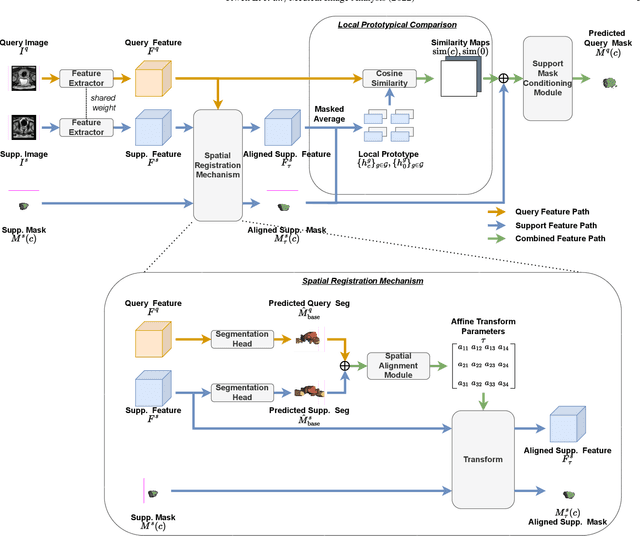

The prowess that makes few-shot learning desirable in medical image analysis is the efficient use of the support image data, which are labelled to classify or segment new classes, a task that otherwise requires substantially more training images and expert annotations. This work describes a fully 3D prototypical few-shot segmentation algorithm, such that the trained networks can be effectively adapted to clinically interesting structures that are absent in training, using only a few labelled images from a different institute. First, to compensate for the widely recognised spatial variability between institutions in episodic adaptation of novel classes, a novel spatial registration mechanism is integrated into prototypical learning, consisting of a segmentation head and an spatial alignment module. Second, to assist the training with observed imperfect alignment, support mask conditioning module is proposed to further utilise the annotation available from the support images. Extensive experiments are presented in an application of segmenting eight anatomical structures important for interventional planning, using a data set of 589 pelvic T2-weighted MR images, acquired at seven institutes. The results demonstrate the efficacy in each of the 3D formulation, the spatial registration, and the support mask conditioning, all of which made positive contributions independently or collectively. Compared with the previously proposed 2D alternatives, the few-shot segmentation performance was improved with statistical significance, regardless whether the support data come from the same or different institutes.