 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast and Memory-Efficient Network Towards Efficient Image Super-Resolution
Apr 18, 2022
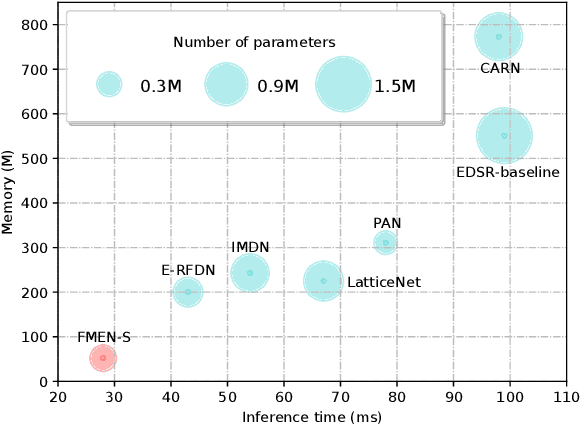

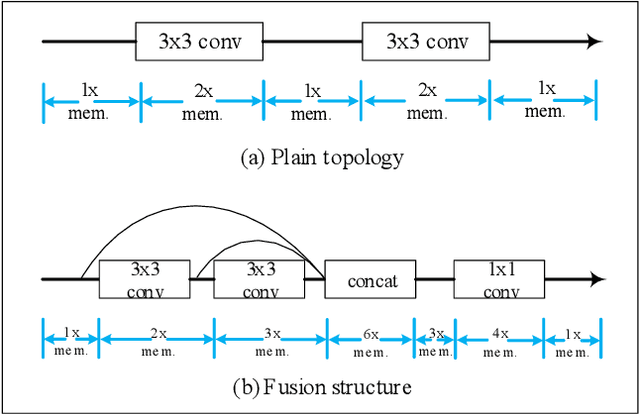
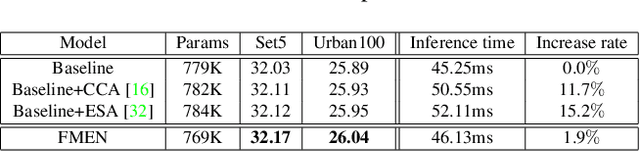
Runtime and memory consumption are two important aspects for efficient image super-resolution (EISR) models to be deployed on resource-constrained devices. Recent advances in EISR exploit distillation and aggregation strategies with plenty of channel split and concatenation operations to make full use of limited hierarchical features. In contrast, sequential network operations avoid frequently accessing preceding states and extra nodes, and thus are beneficial to reducing the memory consumption and runtime overhead. Following this idea, we design our lightweight network backbone by mainly stacking multiple highly optimized convolution and activation layers and decreasing the usage of feature fusion. We propose a novel sequential attention branch, where every pixel is assigned an important factor according to local and global contexts, to enhance high-frequency details. In addition, we tailor the residual block for EISR and propose an enhanced residual block (ERB) to further accelerate the network inference. Finally, combining all the above techniques, we construct a fast and memory-efficient network (FMEN) and its small version FMEN-S, which runs 33% faster and reduces 74% memory consumption compared with the state-of-the-art EISR model: E-RFDN, the champion in AIM 2020 efficient super-resolution challenge. Besides, FMEN-S achieves the lowest memory consumption and the second shortest runtime in NTIRE 2022 challenge on efficient super-resolution. Code is available at https://github.com/NJU-Jet/FMEN.
Knowledge Distillation approach towards Melanoma Detection
Oct 14, 2022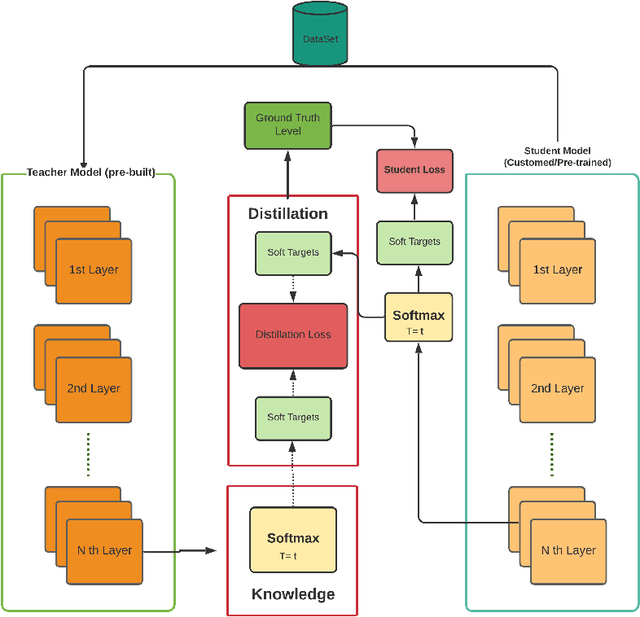
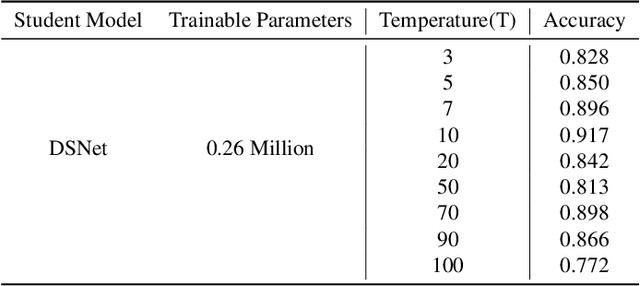

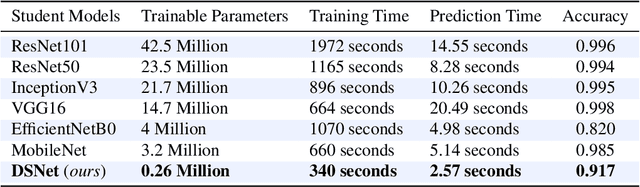
Melanoma is regarded as the most threatening among all skin cancers. There is a pressing need to build systems which can aid in the early detection of melanoma and enable timely treatment to patients. Recent methods are geared towards machine learning based systems where the task is posed as image recognition, tag dermoscopic images of skin lesions as melanoma or non-melanoma. Even though these methods show promising results in terms of accuracy, they are computationally quite expensive to train, that questions the ability of these models to be deployable in a clinical setting or memory constraint devices. To address this issue, we focus on building simple and performant models having few layers, less than ten compared to hundreds. As well as with fewer learnable parameters, 0.26 million (M) compared to 42.5M using knowledge distillation with the goal to detect melanoma from dermoscopic images. First, we train a teacher model using a ResNet-50 to detect melanoma. Using the teacher model, we train the student model known as Distilled Student Network (DSNet) which has around 0.26M parameters using knowledge distillation achieving an accuracy of 91.7%. We compare against ImageNet pre-trained models such MobileNet, VGG-16, Inception-V3, EfficientNet-B0, ResNet-50 and ResNet-101. We find that our approach works well in terms of inference runtime compared to other pre-trained models, 2.57 seconds compared to 14.55 seconds. We find that DSNet (0.26M parameters), which is 15 times smaller, consistently performs better than EfficientNet-B0 (4M parameters) in both melanoma and non-melanoma detection across Precision, Recall and F1 scores
Image Superresolution using Scale-Recurrent Dense Network
Jan 28, 2022


Recent advances in the design of convolutional neural network (CNN) have yielded significant improvements in the performance of image super-resolution (SR). The boost in performance can be attributed to the presence of residual or dense connections within the intermediate layers of these networks. The efficient combination of such connections can reduce the number of parameters drastically while maintaining the restoration quality. In this paper, we propose a scale recurrent SR architecture built upon units containing series of dense connections within a residual block (Residual Dense Blocks (RDBs)) that allow extraction of abundant local features from the image. Our scale recurrent design delivers competitive performance for higher scale factors while being parametrically more efficient as compared to current state-of-the-art approaches. To further improve the performance of our network, we employ multiple residual connections in intermediate layers (referred to as Multi-Residual Dense Blocks), which improves gradient propagation in existing layers. Recent works have discovered that conventional loss functions can guide a network to produce results which have high PSNRs but are perceptually inferior. We mitigate this issue by utilizing a Generative Adversarial Network (GAN) based framework and deep feature (VGG) losses to train our network. We experimentally demonstrate that different weighted combinations of the VGG loss and the adversarial loss enable our network outputs to traverse along the perception-distortion curve. The proposed networks perform favorably against existing methods, both perceptually and objectively (PSNR-based) with fewer parameters.
A Survey on Deep learning based Document Image Enhancement
Dec 06, 2021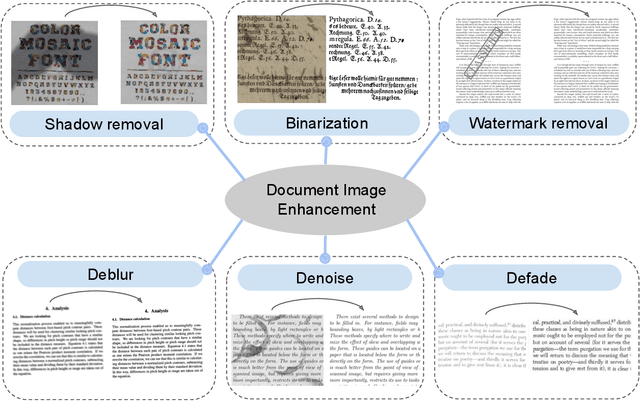
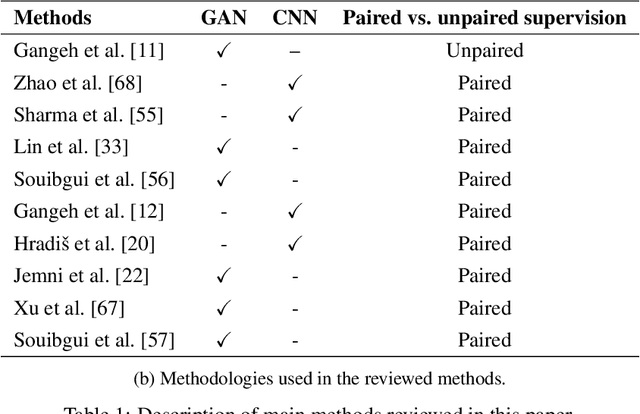


Digitized documents such as scientific articles, tax forms, invoices, contract papers, and historic texts, are widely used nowadays. These images could be degraded or damaged due to various reasons including poor lighting conditions when capturing the image, shadow while scanning them, distortion like noise and blur, aging, ink stain, bleed through, watermark, stamp, etc. Document image enhancement and restoration play a crucial role in many automated document analysis and recognition tasks, such as content extraction using optical character recognition (OCR). With recent advances in deep learning, many methods are proposed to enhance the quality of these document images. In this paper, we review deep learning-based methods, datasets, and metrics for different document image enhancement problems. We provide a comprehensive overview of deep learning-based methods for six different document image enhancement tasks, including binarization, debluring, denoising, defading, watermark removal, and shadow removal. We summarize the main state-of-the-art works for each task and discuss their features, challenges, and limitations. We introduce multiple document image enhancement tasks that have received no to little attention, including over and under exposure correction and bleed-through removal, and identify several other promising research directions and opportunities for future research.
A GPU-accelerated Algorithm for Distinct Discriminant Canonical Correlation Network
Sep 26, 2022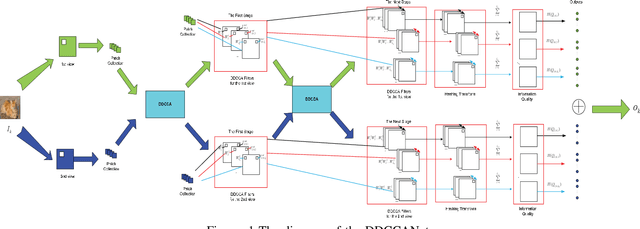

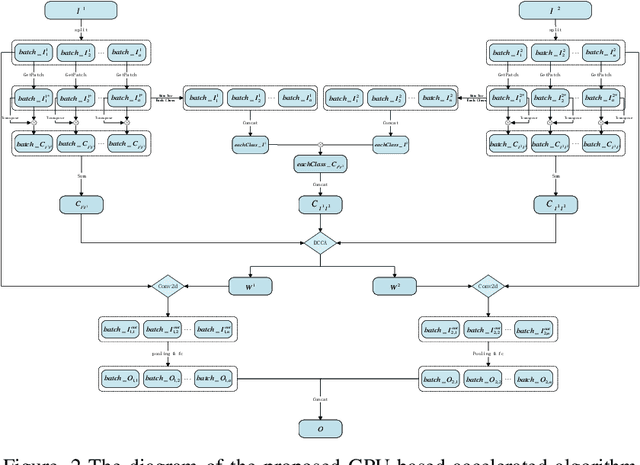
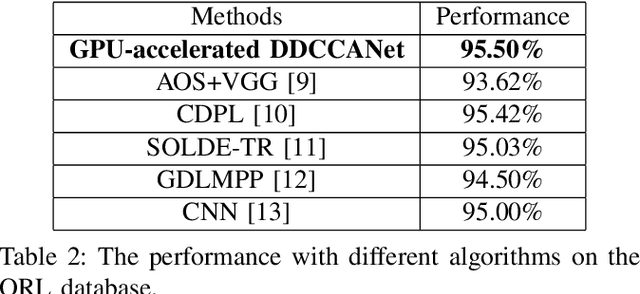
Currently, deep neural networks (DNNs)-based models have drawn enormous attention and have been utilized to different domains widely. However, due to the data-driven nature, the DNN models may generate unsatisfying performance on the small scale data sets. To address this problem, a distinct discriminant canonical correlation network (DDCCANet) is proposed to generate the deep-level feature representation, producing improved performance on image classification. However, the DDCCANet model was originally implemented on a CPU with computing time on par with state-of-the-art DNN models running on GPUs. In this paper, a GPU-based accelerated algorithm is proposed to further optimize the DDCCANet algorithm. As a result, not only is the performance of DDCCANet guaranteed, but also greatly shortens the calculation time, making the model more applicable in real tasks. To demonstrate the effectiveness of the proposed accelerated algorithm, we conduct experiments on three database with different scales. Experimental results validate the superiority of the proposed accelerated algorithm on given examples.
Semi-supervised Medical Image Segmentation via Geometry-aware Consistency Training
Feb 12, 2022
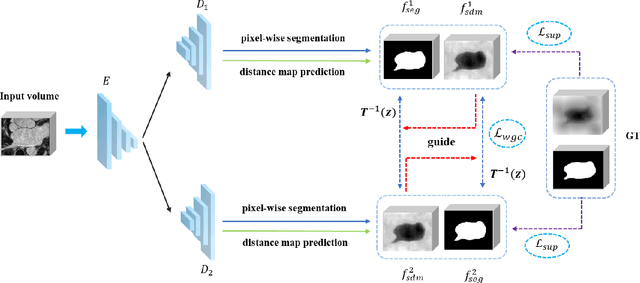
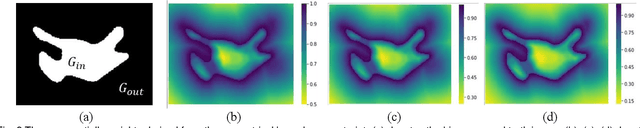
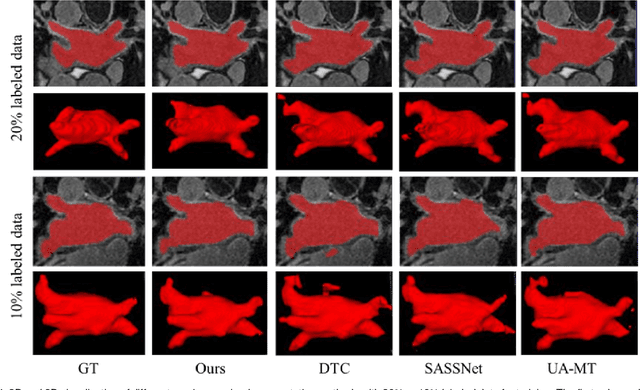
The performance of supervised deep learning methods for medical image segmentation is often limited by the scarcity of labeled data. As a promising research direction, semi-supervised learning addresses this dilemma by leveraging unlabeled data information to assist the learning process. In this paper, a novel geometry-aware semi-supervised learning framework is proposed for medical image segmentation, which is a consistency-based method. Considering that the hard-to-segment regions are mainly located around the object boundary, we introduce an auxiliary prediction task to learn the global geometric information. Based on the geometric constraint, the ambiguous boundary regions are emphasized through an exponentially weighted strategy for the model training to better exploit both labeled and unlabeled data. In addition, a dual-view network is designed to perform segmentation from different perspectives and reduce the prediction uncertainty. The proposed method is evaluated on the public left atrium benchmark dataset and improves fully supervised method by 8.7% in Dice with 10% labeled images, while 4.3% with 20% labeled images. Meanwhile, our framework outperforms six state-of-the-art semi-supervised segmentation methods.
OL-DN: Online learning based dual-domain network for HEVC intra frame quality enhancement
Aug 09, 2022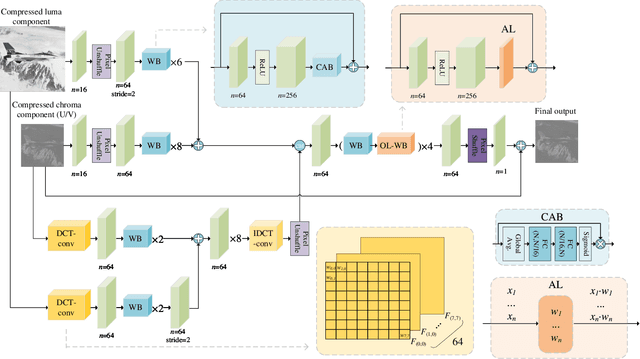
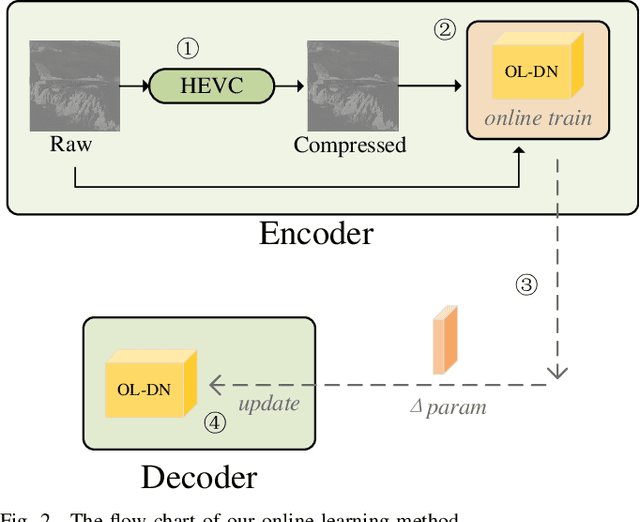
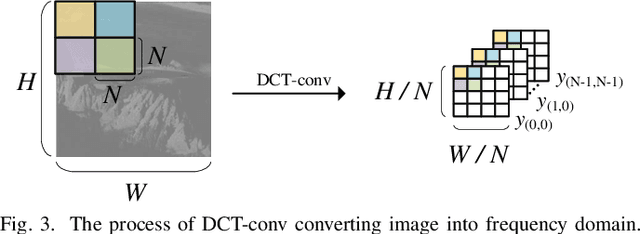

Convolution neural network (CNN) based methods offer effective solutions for enhancing the quality of compressed image and video. However, these methods ignore using the raw data to enhance the quality. In this paper, we adopt the raw data in the quality enhancement for the HEVC intra-coded image by proposing an online learning-based method. When quality enhancement is demanded, we online train our proposed model at encoder side and then use the parameters to update the model of decoder side. This method not only improves model performance, but also makes one model adoptable to multiple coding scenarios. Besides, quantization error in discrete cosine transform (DCT) coefficients is the root cause of various HEVC compression artifacts. Thus, we combine frequency domain priors to assist image reconstruction. We design a DCT based convolution layer, to produce DCT coefficients that are suitable for CNN learning. Experimental results show that our proposed online learning based dual-domain network (OL-DN) has achieved superior performance, compared with the state-of-the-art methods.
IDEA: Increasing Text Diversity via Online Multi-Label Recognition for Vision-Language Pre-training
Jul 12, 2022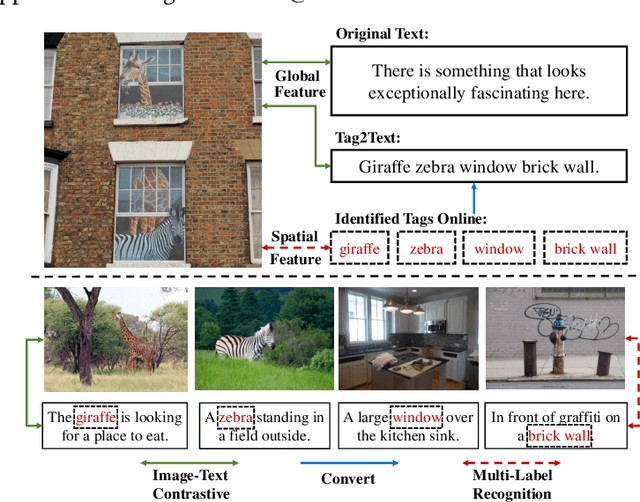
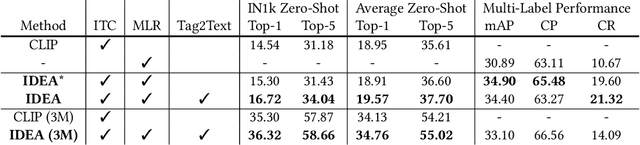
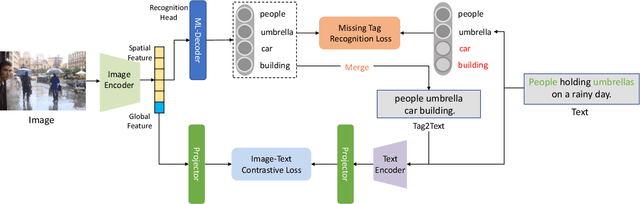
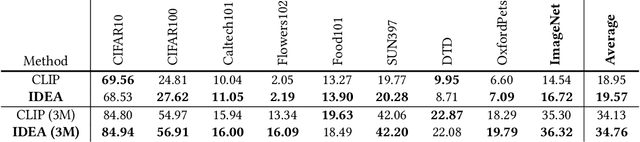
Vision-Language Pre-training (VLP) with large-scale image-text pairs has demonstrated superior performance in various fields. However, the image-text pairs co-occurrent on the Internet typically lack explicit alignment information, which is suboptimal for VLP. Existing methods proposed to adopt an off-the-shelf object detector to utilize additional image tag information. However, the object detector is time-consuming and can only identify the pre-defined object categories, limiting the model capacity. Inspired by the observation that the texts incorporate incomplete fine-grained image information, we introduce IDEA, which stands for increasing text diversity via online multi-label recognition for VLP. IDEA shows that multi-label learning with image tags extracted from the texts can be jointly optimized during VLP. Moreover, IDEA can identify valuable image tags online to provide more explicit textual supervision. Comprehensive experiments demonstrate that IDEA can significantly boost the performance on multiple downstream datasets with a small extra computational cost.
Scaling Up Vision-Language Pre-training for Image Captioning
Nov 24, 2021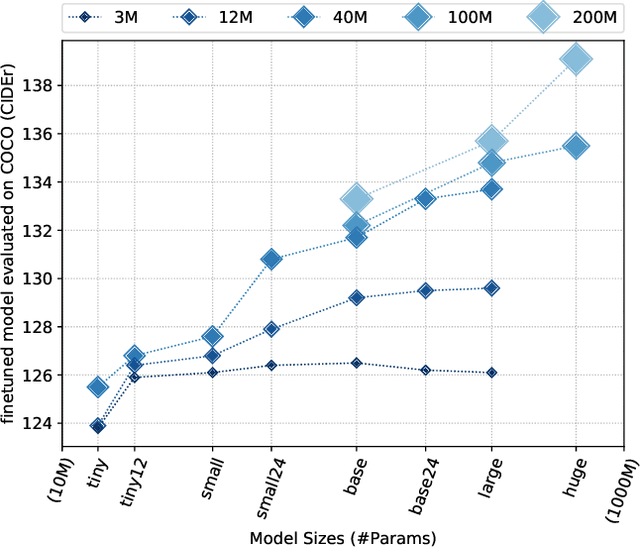

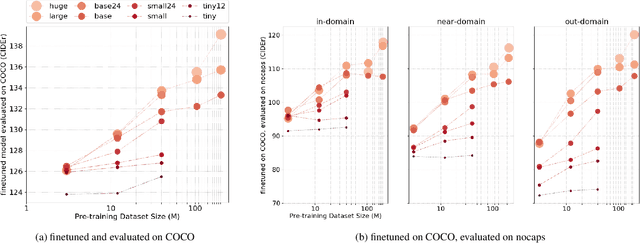
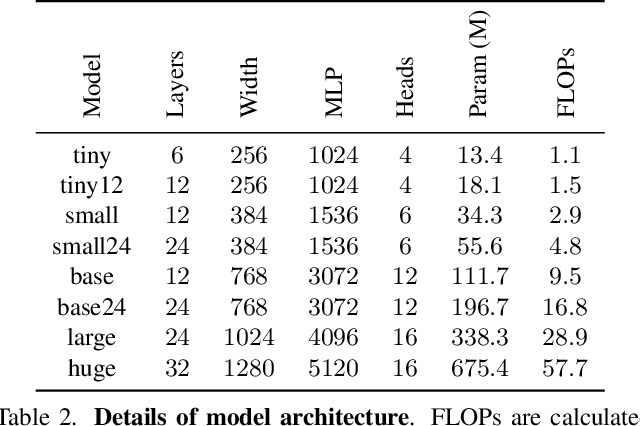
In recent years, we have witnessed significant performance boost in the image captioning task based on vision-language pre-training (VLP). Scale is believed to be an important factor for this advance. However, most existing work only focuses on pre-training transformers with moderate sizes (e.g., 12 or 24 layers) on roughly 4 million images. In this paper, we present LEMON, a LargE-scale iMage captiONer, and provide the first empirical study on the scaling behavior of VLP for image captioning. We use the state-of-the-art VinVL model as our reference model, which consists of an image feature extractor and a transformer model, and scale the transformer both up and down, with model sizes ranging from 13 to 675 million parameters. In terms of data, we conduct experiments with up to 200 million image-text pairs which are automatically collected from web based on the alt attribute of the image (dubbed as ALT200M). Extensive analysis helps to characterize the performance trend as the model size and the pre-training data size increase. We also compare different training recipes, especially for training on large-scale noisy data. As a result, LEMON achieves new state of the arts on several major image captioning benchmarks, including COCO Caption, nocaps, and Conceptual Captions. We also show LEMON can generate captions with long-tail visual concepts when used in a zero-shot manner.
Dual Adversarial Adaptation for Cross-Device Real-World Image Super-Resolution
May 07, 2022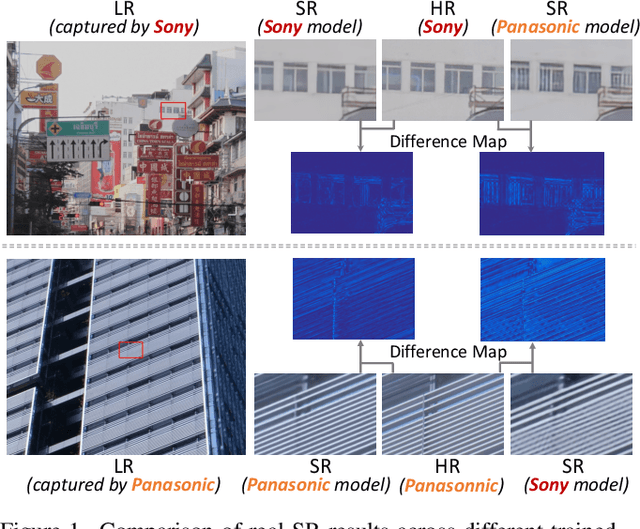
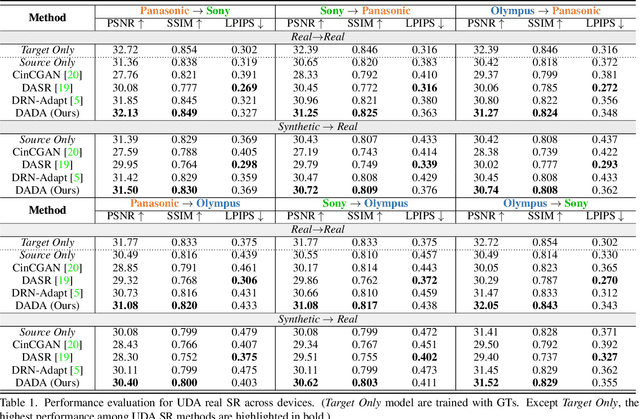
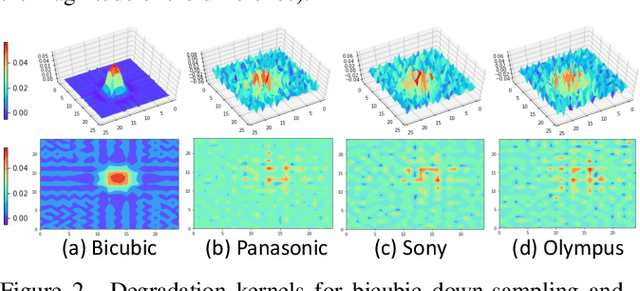
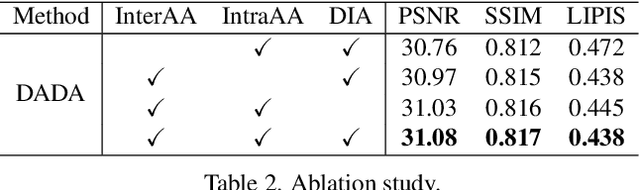
Due to the sophisticated imaging process, an identical scene captured by different cameras could exhibit distinct imaging patterns, introducing distinct proficiency among the super-resolution (SR) models trained on images from different devices. In this paper, we investigate a novel and practical task coded cross-device SR, which strives to adapt a real-world SR model trained on the paired images captured by one camera to low-resolution (LR) images captured by arbitrary target devices. The proposed task is highly challenging due to the absence of paired data from various imaging devices. To address this issue, we propose an unsupervised domain adaptation mechanism for real-world SR, named Dual ADversarial Adaptation (DADA), which only requires LR images in the target domain with available real paired data from a source camera. DADA employs the Domain-Invariant Attention (DIA) module to establish the basis of target model training even without HR supervision. Furthermore, the dual framework of DADA facilitates an Inter-domain Adversarial Adaptation (InterAA) in one branch for two LR input images from two domains, and an Intra-domain Adversarial Adaptation (IntraAA) in two branches for an LR input image. InterAA and IntraAA together improve the model transferability from the source domain to the target. We empirically conduct experiments under six Real to Real adaptation settings among three different cameras, and achieve superior performance compared with existing state-of-the-art approaches. We also evaluate the proposed DADA to address the adaptation to the video camera, which presents a promising research topic to promote the wide applications of real-world super-resolution. Our source code is publicly available at https://github.com/lonelyhope/DADA.git.