 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Instance Mixing across Domains in Aerial Segmentation
Oct 12, 2022
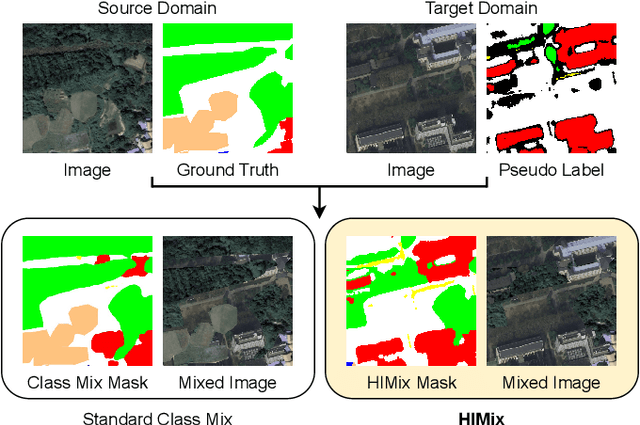
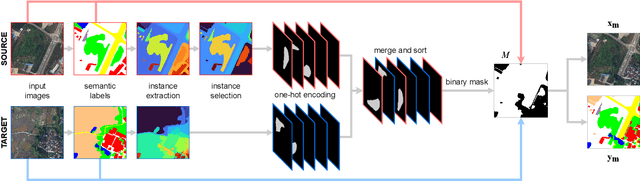

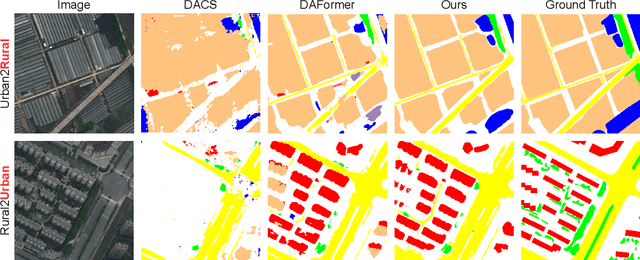
We investigate the task of unsupervised domain adaptation in aerial semantic segmentation and discover that the current state-of-the-art algorithms designed for autonomous driving based on domain mixing do not translate well to the aerial setting. This is due to two factors: (i) a large disparity in the extension of the semantic categories, which causes a domain imbalance in the mixed image, and (ii) a weaker structural consistency in aerial scenes than in driving scenes since the same scene might be viewed from different perspectives and there is no well-defined and repeatable structure of the semantic elements in the images. Our solution to these problems is composed of: (i) a new mixing strategy for aerial segmentation across domains called Hierarchical Instance Mixing (HIMix), which extracts a set of connected components from each semantic mask and mixes them according to a semantic hierarchy and, (ii) a twin-head architecture in which two separate segmentation heads are fed with variations of the same images in a contrastive fashion to produce finer segmentation maps. We conduct extensive experiments on the LoveDA benchmark, where our solution outperforms the current state-of-the-art.
Real Image Inversion via Segments
Oct 12, 2021



In this short report, we present a simple, yet effective approach to editing real images via generative adversarial networks (GAN). Unlike previous techniques, that treat all editing tasks as an operation that affects pixel values in the entire image in our approach we cut up the image into a set of smaller segments. For those segments corresponding latent codes of a generative network can be estimated with greater accuracy due to the lower number of constraints. When codes are altered by the user the content in the image is manipulated locally while the rest of it remains unaffected. Thanks to this property the final edited image better retains the original structures and thus helps to preserve natural look.
Prior-Aware Synthetic Data to the Rescue: Animal Pose Estimation with Very Limited Real Data
Aug 30, 2022
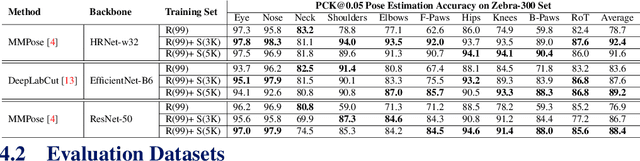
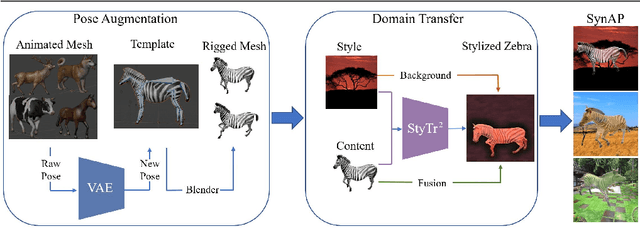
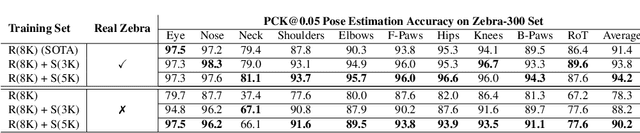
Accurately annotated image datasets are essential components for studying animal behaviors from their poses. Compared to the number of species we know and may exist, the existing labeled pose datasets cover only a small portion of them, while building comprehensive large-scale datasets is prohibitively expensive. Here, we present a very data efficient strategy targeted for pose estimation in quadrupeds that requires only a small amount of real images from the target animal. It is confirmed that fine-tuning a backbone network with pretrained weights on generic image datasets such as ImageNet can mitigate the high demand for target animal pose data and shorten the training time by learning the the prior knowledge of object segmentation and keypoint estimation in advance. However, when faced with serious data scarcity (i.e., $<10^2$ real images), the model performance stays unsatisfactory, particularly for limbs with considerable flexibility and several comparable parts. We therefore introduce a prior-aware synthetic animal data generation pipeline called PASyn to augment the animal pose data essential for robust pose estimation. PASyn generates a probabilistically-valid synthetic pose dataset, SynAP, through training a variational generative model on several animated 3D animal models. In addition, a style transfer strategy is utilized to blend the synthetic animal image into the real backgrounds. We evaluate the improvement made by our approach with three popular backbone networks and test their pose estimation accuracy on publicly available animal pose images as well as collected from real animals in a zoo.
Custom Structure Preservation in Face Aging
Jul 22, 2022
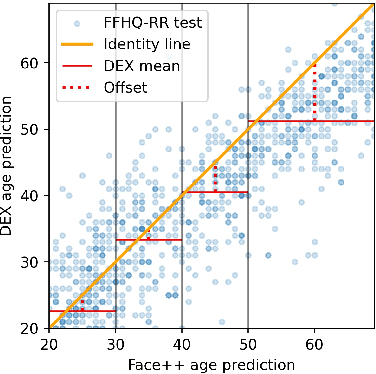
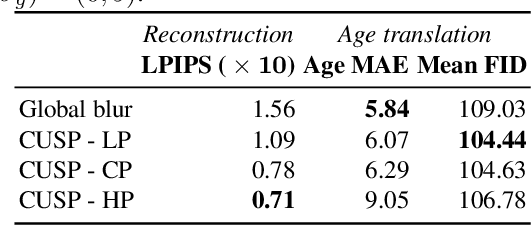
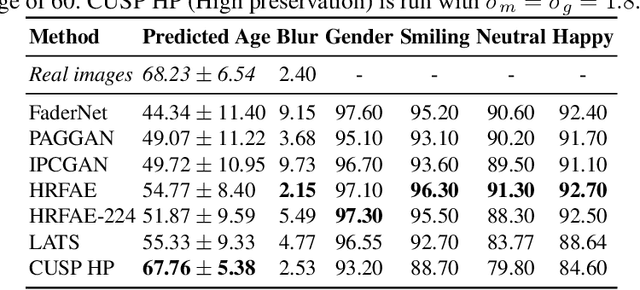
In this work, we propose a novel architecture for face age editing that can produce structural modifications while maintaining relevant details present in the original image. We disentangle the style and content of the input image and propose a new decoder network that adopts a style-based strategy to combine the style and content representations of the input image while conditioning the output on the target age. We go beyond existing aging methods allowing users to adjust the degree of structure preservation in the input image during inference. To this purpose, we introduce a masking mechanism, the CUstom Structure Preservation module, that distinguishes relevant regions in the input image from those that should be discarded. CUSP requires no additional supervision. Finally, our quantitative and qualitative analysis which include a user study, show that our method outperforms prior art and demonstrates the effectiveness of our strategy regarding image editing and adjustable structure preservation. Code and pretrained models are available at https://github.com/guillermogotre/CUSP.
Image Forgery Detection with Interpretability
Feb 02, 2022
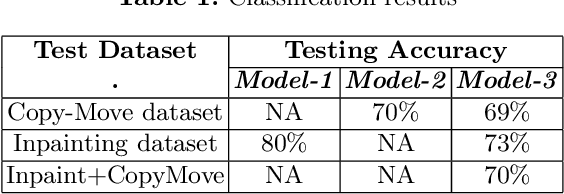


In this work, we present a learning based method focusing on the convolutional neural network (CNN) architecture to detect these forgeries. We consider the detection of both copy-move forgeries and inpainting based forgeries. For these, we synthesize our own large dataset. In addition to classification, the focus is also on interpretability of the forgery detection. As the CNN classification yields the image-level label, it is important to understand if forged region has indeed contributed to the classification. For this purpose, we demonstrate using the Grad-CAM heatmap, that in various correctly classified examples, that the forged region is indeed the region contributing to the classification. Interestingly, this is also applicable for small forged regions, as is depicted in our results. Such an analysis can also help in establishing the reliability of the classification.
Toward Fast, Flexible, and Robust Low-Light Image Enhancement
Apr 21, 2022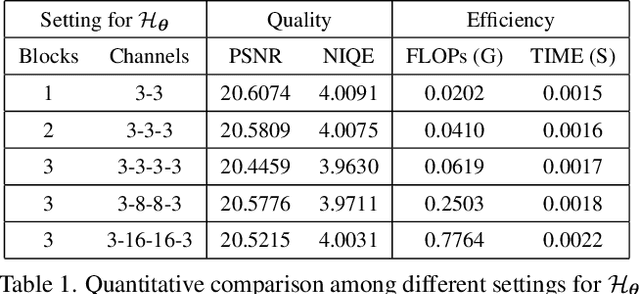
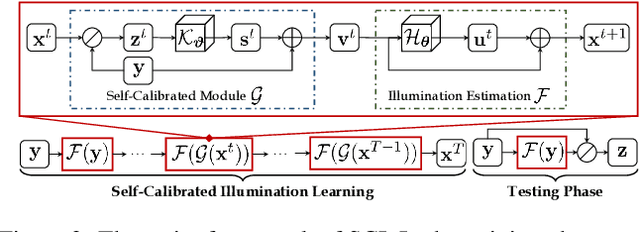
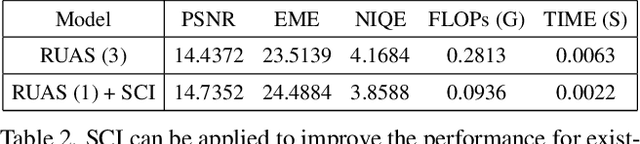

Existing low-light image enhancement techniques are mostly not only difficult to deal with both visual quality and computational efficiency but also commonly invalid in unknown complex scenarios. In this paper, we develop a new Self-Calibrated Illumination (SCI) learning framework for fast, flexible, and robust brightening images in real-world low-light scenarios. To be specific, we establish a cascaded illumination learning process with weight sharing to handle this task. Considering the computational burden of the cascaded pattern, we construct the self-calibrated module which realizes the convergence between results of each stage, producing the gains that only use the single basic block for inference (yet has not been exploited in previous works), which drastically diminishes computation cost. We then define the unsupervised training loss to elevate the model capability that can adapt to general scenes. Further, we make comprehensive explorations to excavate SCI's inherent properties (lacking in existing works) including operation-insensitive adaptability (acquiring stable performance under the settings of different simple operations) and model-irrelevant generality (can be applied to illumination-based existing works to improve performance). Finally, plenty of experiments and ablation studies fully indicate our superiority in both quality and efficiency. Applications on low-light face detection and nighttime semantic segmentation fully reveal the latent practical values for SCI. The source code is available at https://github.com/vis-opt-group/SCI.
How does fake news use a thumbnail? CLIP-based Multimodal Detection on the Unrepresentative News Image
Apr 12, 2022
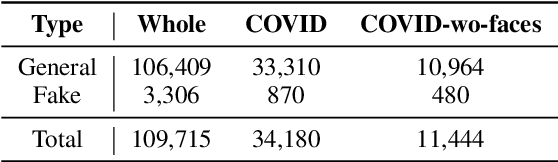
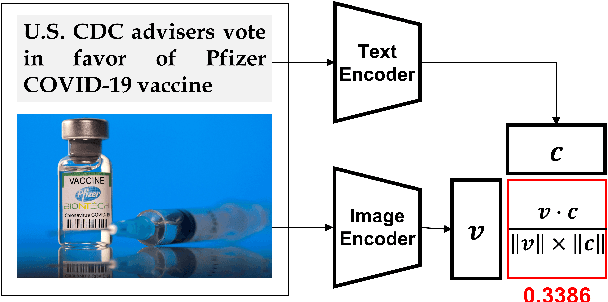
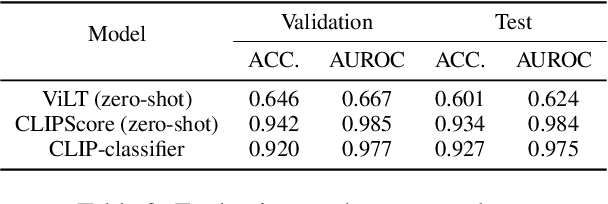
This study investigates how fake news uses a thumbnail for a news article with a focus on whether a news article's thumbnail represents the news content correctly. A news article shared with an irrelevant thumbnail can mislead readers into having a wrong impression of the issue, especially in social media environments where users are less likely to click the link and consume the entire content. We propose to capture the degree of semantic incongruity in the multimodal relation by using the pretrained CLIP representation. From a source-level analysis, we found that fake news employs a more incongruous image to the main content than general news. Going further, we attempted to detect news articles with image-text incongruity. Evaluation experiments suggest that CLIP-based methods can successfully detect news articles in which the thumbnail is semantically irrelevant to news text. This study contributes to the research by providing a novel view on tackling online fake news and misinformation. Code and datasets are available at https://github.com/ssu-humane/fake-news-thumbnail.
Exploring the combination of deep-learning based direct segmentation and deformable image registration for cone-beam CT based auto-segmentation for adaptive radiotherapy
Jun 07, 2022
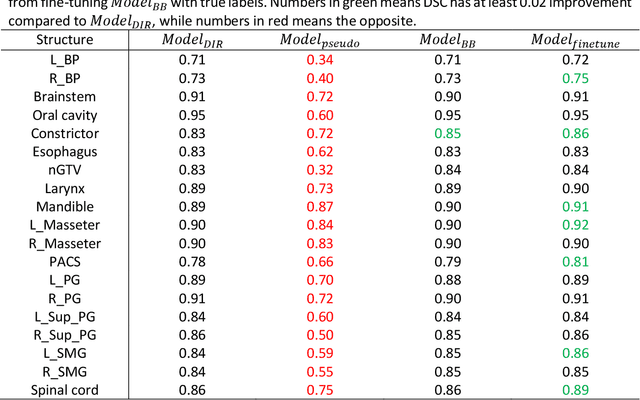
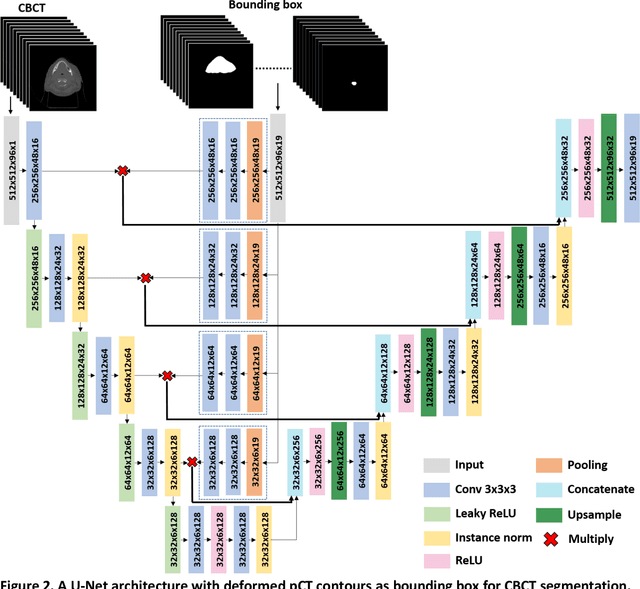
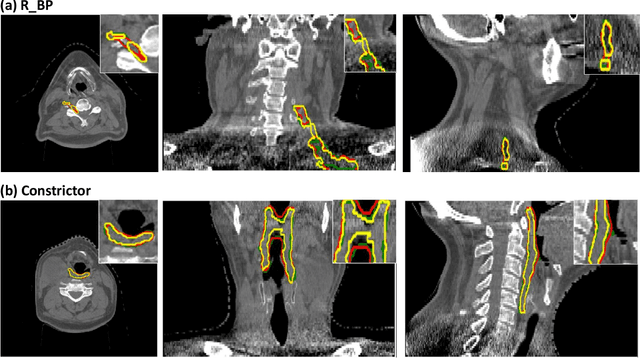
CBCT-based online adaptive radiotherapy (ART) calls for accurate auto-segmentation models to reduce the time cost for physicians to edit contours, since the patient is immobilized on the treatment table waiting for treatment to start. However, auto-segmentation of CBCT images is a difficult task, majorly due to low image quality and lack of true labels for training a deep learning (DL) model. Meanwhile CBCT auto-segmentation in ART is a unique task compared to other segmentation problems, where manual contours on planning CT (pCT) are available. To make use of this prior knowledge, we propose to combine deformable image registration (DIR) and direct segmentation (DS) on CBCT for head and neck patients. First, we use deformed pCT contours derived from multiple DIR methods between pCT and CBCT as pseudo labels for training. Second, we use deformed pCT contours as bounding box to constrain the region of interest for DS. Meanwhile deformed pCT contours are used as pseudo labels for training, but are generated from different DIR algorithms from bounding box. Third, we fine-tune the model with bounding box on true labels. We found that DS on CBCT trained with pseudo labels and without utilizing any prior knowledge has very poor segmentation performance compared to DIR-only segmentation. However, adding deformed pCT contours as bounding box in the DS network can dramatically improve segmentation performance, comparable to DIR-only segmentation. The DS model with bounding box can be further improved by fine-tuning it with some real labels. Experiments showed that 7 out of 19 structures have at least 0.2 dice similarity coefficient increase compared to DIR-only segmentation. Utilizing deformed pCT contours as pseudo labels for training and as bounding box for shape and location feature extraction in a DS model is a good way to combine DIR and DS.
Efficient Perception, Planning, and Control Algorithms for Vision-Based Automated Vehicles
Sep 15, 2022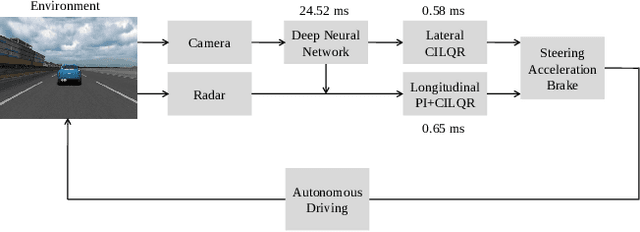
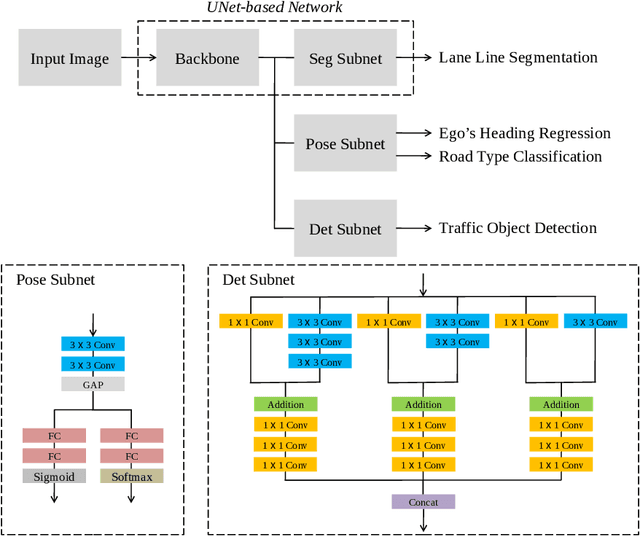

Owing to resource limitations, efficient computation systems have long been a critical demand for those designing autonomous vehicles. Additionally, sensor cost and size restrict the development of self-driving cars. This paper presents an efficient framework for the operation of vision-based automatic vehicles; a front-facing camera and a few inexpensive radars are the required sensors for driving environment perception. The proposed algorithm comprises a multi-task UNet (MTUNet) network for extracting image features and constrained iterative linear quadratic regulator (CILQR) modules for rapid lateral and longitudinal motion planning. The MTUNet is designed to simultaneously solve lane line segmentation, ego vehicle heading angle regression, road type classification, and traffic object detection tasks at an approximate speed of 40 FPS when an RGB image of size 228 x 228 is fed into it. The CILQR algorithms then take processed MTUNet outputs and radar data as their input to produce driving commands for lateral and longitudinal vehicle automation guidance; both optimal control problems can be solved within 1 ms. The proposed CILQR controllers are shown to be more efficient than the sequential quadratic programming (SQP) methods and can collaborate with the MTUNet to drive a car autonomously in unseen simulation environments for lane-keeping and car-following maneuvers. Our experiments demonstrate that the proposed autonomous driving system is applicable to modern automobiles.
Efficient Subgraph Isomorphism using Graph Topology
Sep 15, 2022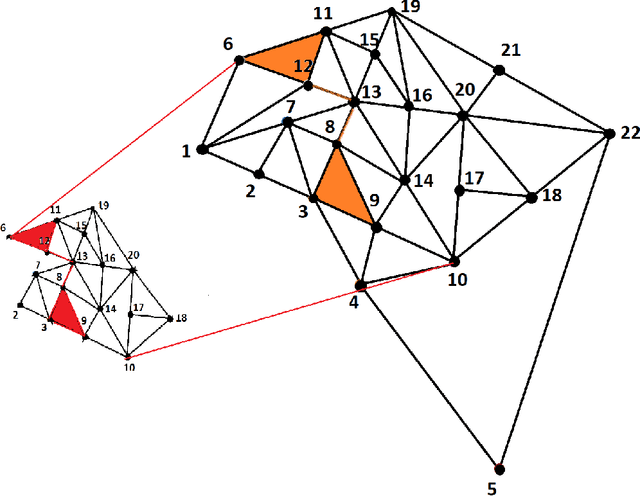
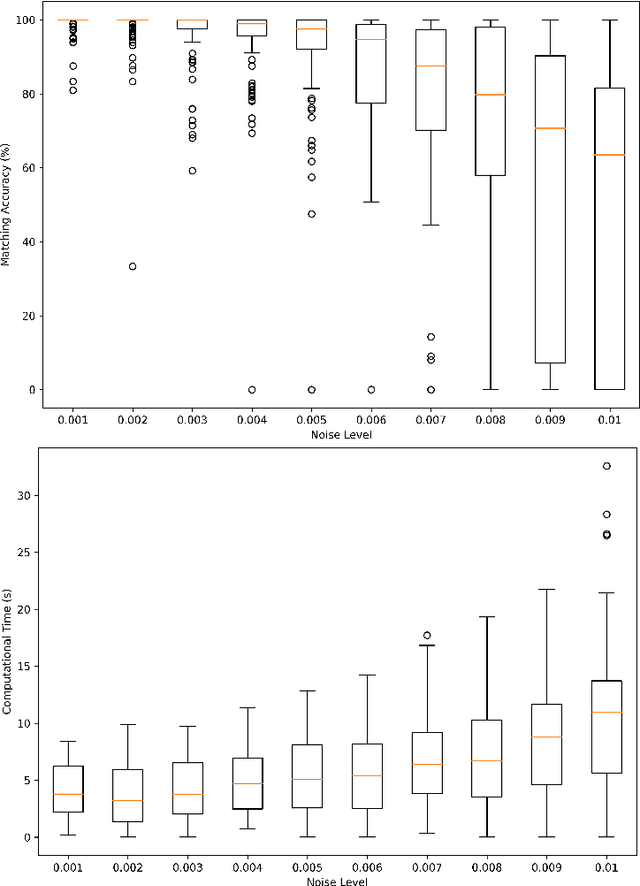

Subgraph isomorphism or subgraph matching is generally considered as an NP-complete problem, made more complex in practical applications where the edge weights take real values and are subject to measurement noise and possible anomalies. To the best of our knowledge, almost all subgraph matching methods utilize node labels to perform node-node matching. In the absence of such labels (in applications such as image matching and map matching among others), these subgraph matching methods do not work. We propose a method for identifying the node correspondence between a subgraph and a full graph in the inexact case without node labels in two steps - (a) extract the minimal unique topology preserving subset from the subgraph and find its feasible matching in the full graph, and (b) implement a consensus-based algorithm to expand the matched node set by pairing unique paths based on boundary commutativity. Going beyond the existing subgraph matching approaches, the proposed method is shown to have realistically sub-linear computational efficiency, robustness to random measurement noise, and good statistical properties. Our method is also readily applicable to the exact matching case without loss of generality. To demonstrate the effectiveness of the proposed method, a simulation and a case study is performed on the Erdos-Renyi random graphs and the image-based affine covariant features dataset respectively.