 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explainable Face Verification via Feature-Guided Gradient Backpropagation
Mar 07, 2024
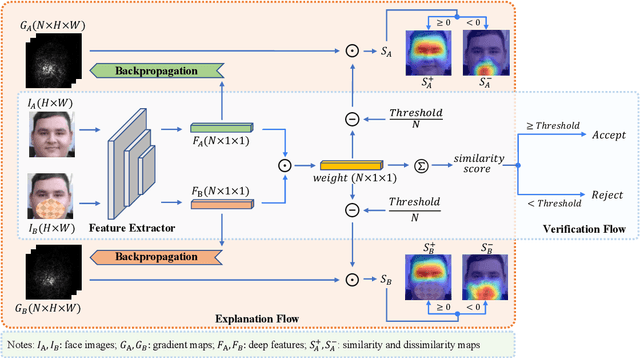
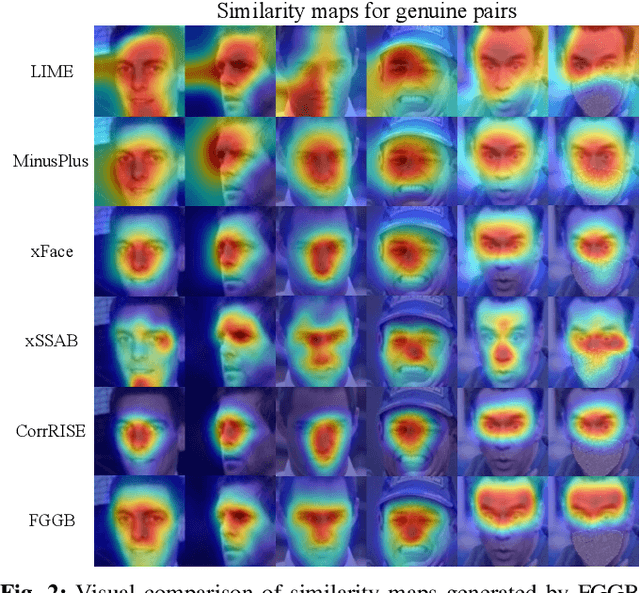
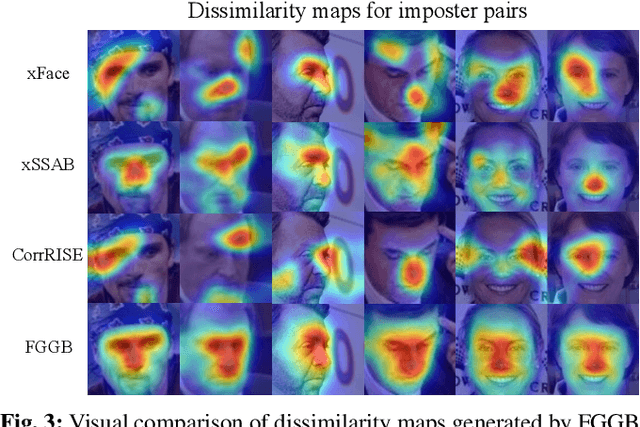
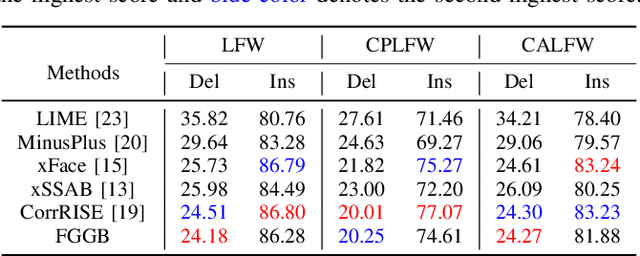
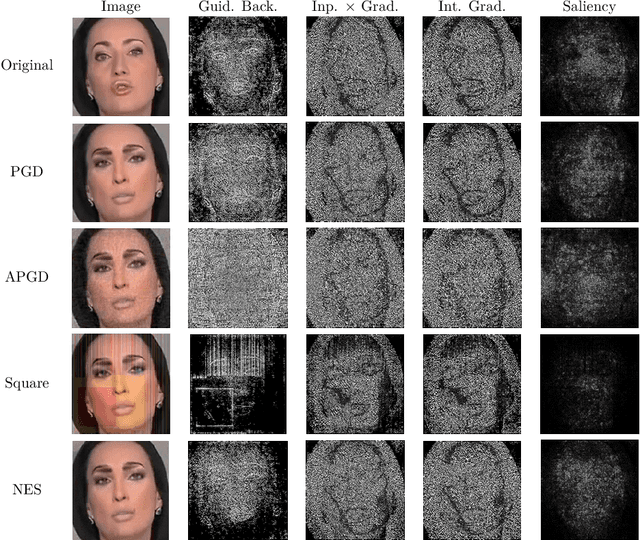
Recent years have witnessed significant advancement in face recognition (FR) techniques, with their applications widely spread in people's lives and security-sensitive areas. There is a growing need for reliable interpretations of decisions of such systems. Existing studies relying on various mechanisms have investigated the usage of saliency maps as an explanation approach, but suffer from different limitations. This paper first explores the spatial relationship between face image and its deep representation via gradient backpropagation. Then a new explanation approach FGGB has been conceived, which provides precise and insightful similarity and dissimilarity saliency maps to explain the "Accept" and "Reject" decision of an FR system. Extensive visual presentation and quantitative measurement have shown that FGGB achieves superior performance in both similarity and dissimilarity maps when compared to current state-of-the-art explainable face verification approaches.
Popeye: A Unified Visual-Language Model for Multi-Source Ship Detection from Remote Sensing Imagery
Mar 06, 2024
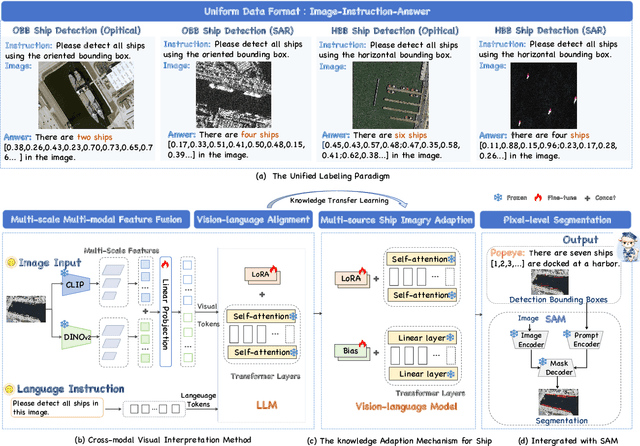

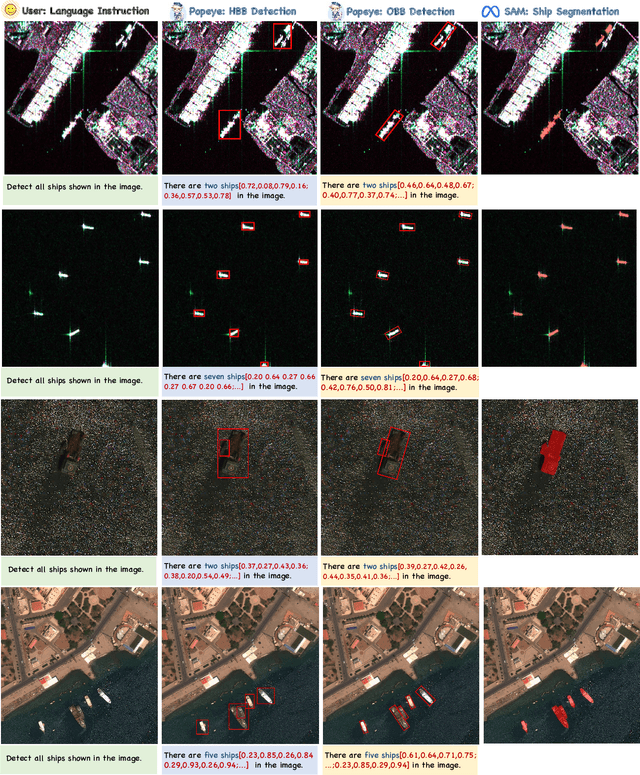
Ship detection needs to identify ship locations from remote sensing (RS) scenes. However, due to different imaging payloads, various appearances of ships, and complicated background interference from the bird's eye view, it is difficult to set up a unified paradigm for achieving multi-source ship detection. Therefore, in this article, considering that the large language models (LLMs) emerge the powerful generalization ability, a novel unified visual-language model called Popeye is proposed for multi-source ship detection from RS imagery. First, to bridge the interpretation gap between multi-source images for ship detection, a novel image-instruction-answer way is designed to integrate the various ship detection ways (e.g., horizontal bounding box (HBB), oriented bounding box (OBB)) into a unified labeling paradigm. Then, in view of this, a cross-modal image interpretation method is developed for the proposed Popeye to enhance interactive comprehension ability between visual and language content, which can be easily migrated into any multi-source ship detection task. Subsequently, owing to objective domain differences, a knowledge adaption mechanism is designed to adapt the pre-trained visual-language knowledge from the nature scene into the RS domain for multi-source ship detection. In addition, the segment anything model (SAM) is also seamlessly integrated into the proposed Popeye to achieve pixel-level ship segmentation without additional training costs. Finally, extensive experiments are conducted on the newly constructed instruction dataset named MMShip, and the results indicate that the proposed Popeye outperforms current specialist, open-vocabulary, and other visual-language models for zero-shot multi-source ship detection.
XAI-Based Detection of Adversarial Attacks on Deepfake Detectors
Mar 05, 2024

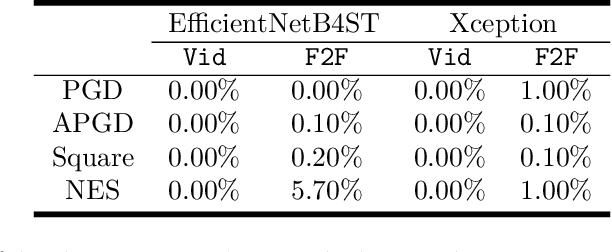
We introduce a novel methodology for identifying adversarial attacks on deepfake detectors using eXplainable Artificial Intelligence (XAI). In an era characterized by digital advancement, deepfakes have emerged as a potent tool, creating a demand for efficient detection systems. However, these systems are frequently targeted by adversarial attacks that inhibit their performance. We address this gap, developing a defensible deepfake detector by leveraging the power of XAI. The proposed methodology uses XAI to generate interpretability maps for a given method, providing explicit visualizations of decision-making factors within the AI models. We subsequently employ a pretrained feature extractor that processes both the input image and its corresponding XAI image. The feature embeddings extracted from this process are then used for training a simple yet effective classifier. Our approach contributes not only to the detection of deepfakes but also enhances the understanding of possible adversarial attacks, pinpointing potential vulnerabilities. Furthermore, this approach does not change the performance of the deepfake detector. The paper demonstrates promising results suggesting a potential pathway for future deepfake detection mechanisms. We believe this study will serve as a valuable contribution to the community, sparking much-needed discourse on safeguarding deepfake detectors.
Attention Guidance Mechanism for Handwritten Mathematical Expression Recognition
Mar 05, 2024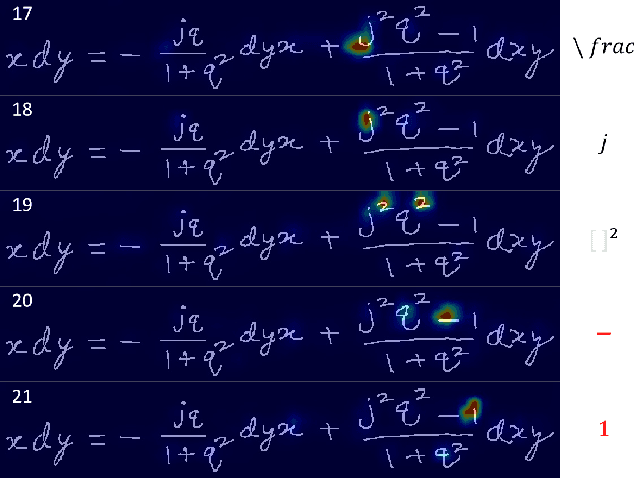
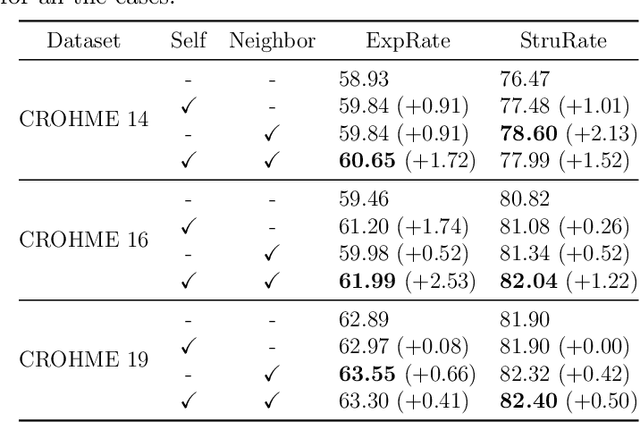
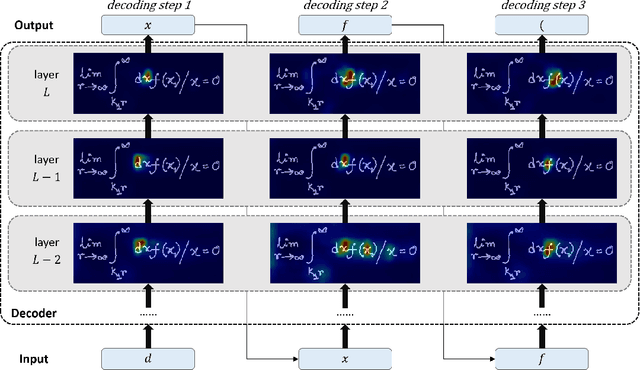
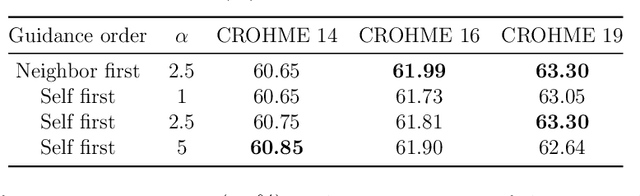
Handwritten mathematical expression recognition (HMER) is challenging in image-to-text tasks due to the complex layouts of mathematical expressions and suffers from problems including over-parsing and under-parsing. To solve these, previous HMER methods improve the attention mechanism by utilizing historical alignment information. However, this approach has limitations in addressing under-parsing since it cannot correct the erroneous attention on image areas that should be parsed at subsequent decoding steps. This faulty attention causes the attention module to incorporate future context into the current decoding step, thereby confusing the alignment process. To address this issue, we propose an attention guidance mechanism to explicitly suppress attention weights in irrelevant areas and enhance the appropriate ones, thereby inhibiting access to information outside the intended context. Depending on the type of attention guidance, we devise two complementary approaches to refine attention weights: self-guidance that coordinates attention of multiple heads and neighbor-guidance that integrates attention from adjacent time steps. Experiments show that our method outperforms existing state-of-the-art methods, achieving expression recognition rates of 60.75% / 61.81% / 63.30% on the CROHME 2014/ 2016/ 2019 datasets.
Automatic Detection and Classification of Corona Infection (COVID-19) from X-ray Images Using Convolution Neural Network
Mar 09, 2024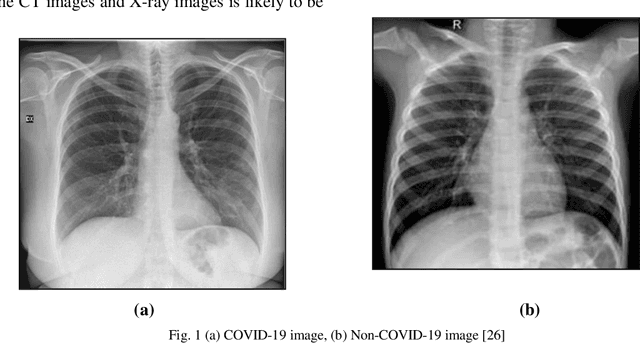
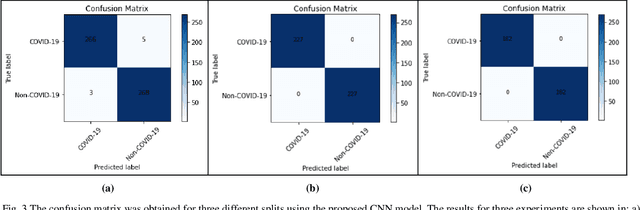
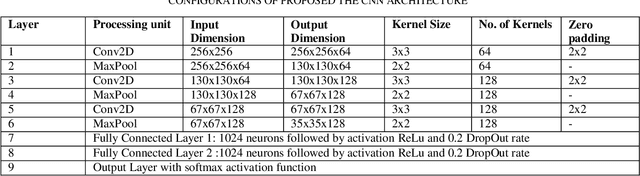

The novel coronavirus universally known as the COVID-19 outbreak arises at the end of 2019 in one of the East Asian countries and it is subjected to widespread discussion and debate. There are almost 200 countries affected across the globe by COVID-19 and it has ruined many lives and the global economy. The virus is spreading very rapidly at the pace of around 10 fold in less than a month. Also, in the case of COVID- 19 it is critical to detect the infection as it employs various symptoms which may differ from person to person. Hence, diagnosis in starting stage and treatment are very much important for such type of infectious disease. The chest x-ray is one of the primary techniques among blood tests and Computed Tomography contributes a major role in the early diagnosis of COVID-19. There is a rising need for automated and auxiliary diagnostic tools for early diagnosis, as there are no accurate and truthful automated tool kits on hand. In this research study, we have designed a Convolution Neural Network architecture a deep net for the classification of x-ray images of chest among two classes: COVID-19 or Non-COVID- 19 infection. The anticipated model is expected to provide accurate diagnostic results and produced classification accuracy of 99%, 100%, and 100% with 70%-30%,75%-25% and 80%-20% train-test data split respectively, for the binary classification of the x-ray image to be COVID-19 or Non-COVID-19 infection category. We have designed the CNN with optimized parameters with 3 convolution layers and optimized number of filters in each layer.
End-to-End Human Instance Matting
Mar 03, 2024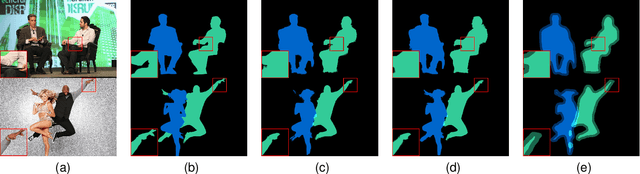
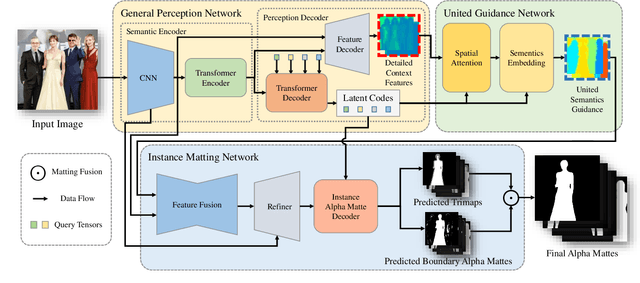
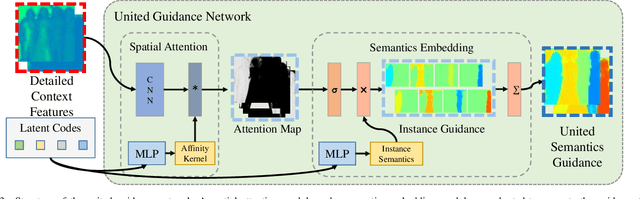
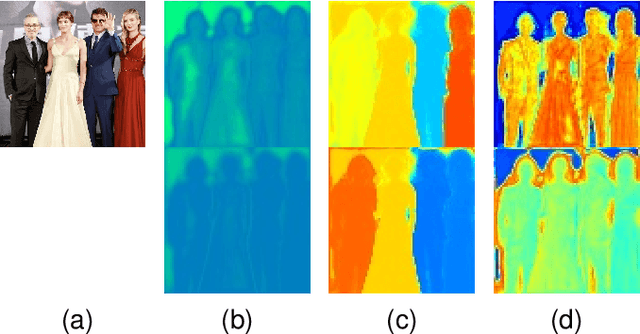
Human instance matting aims to estimate an alpha matte for each human instance in an image, which is extremely challenging and has rarely been studied so far. Despite some efforts to use instance segmentation to generate a trimap for each instance and apply trimap-based matting methods, the resulting alpha mattes are often inaccurate due to inaccurate segmentation. In addition, this approach is computationally inefficient due to multiple executions of the matting method. To address these problems, this paper proposes a novel End-to-End Human Instance Matting (E2E-HIM) framework for simultaneous multiple instance matting in a more efficient manner. Specifically, a general perception network first extracts image features and decodes instance contexts into latent codes. Then, a united guidance network exploits spatial attention and semantics embedding to generate united semantics guidance, which encodes the locations and semantic correspondences of all instances. Finally, an instance matting network decodes the image features and united semantics guidance to predict all instance-level alpha mattes. In addition, we construct a large-scale human instance matting dataset (HIM-100K) comprising over 100,000 human images with instance alpha matte labels. Experiments on HIM-100K demonstrate the proposed E2E-HIM outperforms the existing methods on human instance matting with 50% lower errors and 5X faster speed (6 instances in a 640X640 image). Experiments on the PPM-100, RWP-636, and P3M datasets demonstrate that E2E-HIM also achieves competitive performance on traditional human matting.
A Spatiotemporal Illumination Model for 3D Image Fusion in Optical Coherence Tomography
Feb 19, 2024Optical coherence tomography (OCT) is a non-invasive, micrometer-scale imaging modality that has become a clinical standard in ophthalmology. By raster-scanning the retina, sequential cross-sectional image slices are acquired to generate volumetric data. In-vivo imaging suffers from discontinuities between slices that show up as motion and illumination artifacts. We present a new illumination model that exploits continuity in orthogonally raster-scanned volume data. Our novel spatiotemporal parametrization adheres to illumination continuity both temporally, along the imaged slices, as well as spatially, in the transverse directions. Yet, our formulation does not make inter-slice assumptions, which could have discontinuities. This is the first optimization of a 3D inverse model in an image reconstruction context in OCT. Evaluation in 68 volumes from eyes with pathology showed reduction of illumination artifacts in 88\% of the data, and only 6\% showed moderate residual illumination artifacts. The method enables the use of forward-warped motion corrected data, which is more accurate, and enables supersampling and advanced 3D image reconstruction in OCT.
Asphalt Concrete Characterization Using Digital Image Correlation: A Systematic Review of Best Practices, Applications, and Future Vision
Feb 26, 2024Digital Image Correlation (DIC) is an optical technique that measures displacement and strain by tracking pattern movement in a sequence of captured images during testing. DIC has gained recognition in asphalt pavement engineering since the early 2000s. However, users often perceive the DIC technique as an out-of-box tool and lack a thorough understanding of its operational and measurement principles. This article presents a state-of-art review of DIC as a crucial tool for laboratory testing of asphalt concrete (AC), primarily focusing on the widely utilized 2D-DIC and 3D-DIC techniques. To address frequently asked questions from users, the review thoroughly examines the optimal methods for preparing speckle patterns, configuring single-camera or dual-camera imaging systems, conducting DIC analyses, and exploring various applications. Furthermore, emerging DIC methodologies such as Digital Volume Correlation and deep-learning-based DIC are introduced, highlighting their potential for future applications in pavement engineering. The article also provides a comprehensive and reliable flowchart for implementing DIC in AC characterization. Finally, critical directions for future research are presented.
Spatiotemporal Pooling on Appropriate Topological Maps Represented as Two-Dimensional Images for EEG Classification
Mar 07, 2024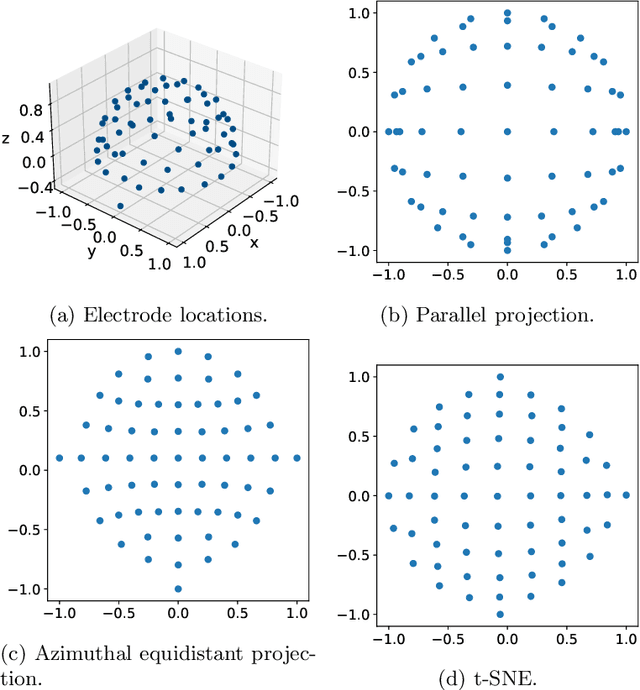

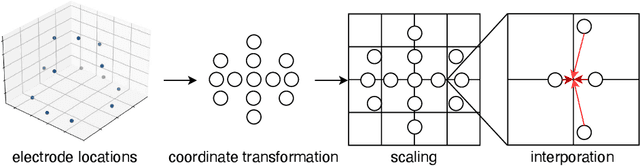
Motor imagery classification based on electroencephalography (EEG) signals is one of the most important brain-computer interface applications, although it needs further improvement. Several methods have attempted to obtain useful information from EEG signals by using recent deep learning techniques such as transformers. To improve the classification accuracy, this study proposes a novel EEG-based motor imagery classification method with three key features: generation of a topological map represented as a two-dimensional image from EEG signals with coordinate transformation based on t-SNE, use of the InternImage to extract spatial features, and use of spatiotemporal pooling inspired by PoolFormer to exploit spatiotemporal information concealed in a sequence of EEG images. Experimental results using the PhysioNet EEG Motor Movement/Imagery dataset showed that the proposed method achieved the best classification accuracy of 88.57%, 80.65%, and 70.17% on two-, three-, and four-class motor imagery tasks in cross-individual validation.
OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on
Mar 07, 2024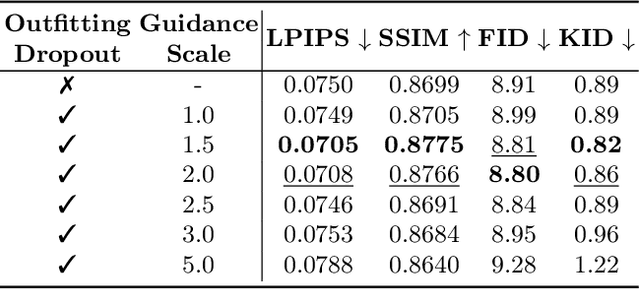
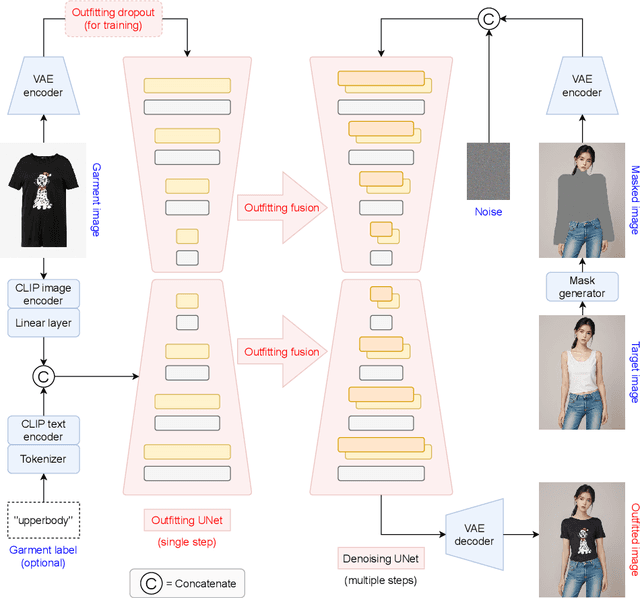
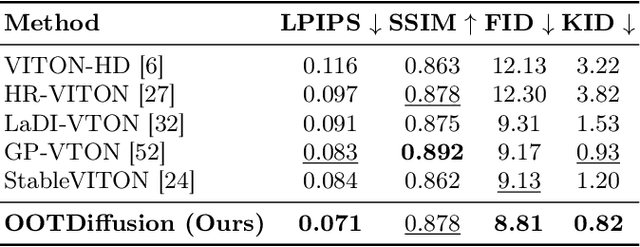

We present OOTDiffusion, a novel network architecture for realistic and controllable image-based virtual try-on (VTON). We leverage the power of pretrained latent diffusion models, designing an outfitting UNet to learn the garment detail features. Without a redundant warping process, the garment features are precisely aligned with the target human body via the proposed outfitting fusion in the self-attention layers of the denoising UNet. In order to further enhance the controllability, we introduce outfitting dropout to the training process, which enables us to adjust the strength of the garment features through classifier-free guidance. Our comprehensive experiments on the VITON-HD and Dress Code datasets demonstrate that OOTDiffusion efficiently generates high-quality try-on results for arbitrary human and garment images, which outperforms other VTON methods in both realism and controllability, indicating an impressive breakthrough in virtual try-on. Our source code is available at https://github.com/levihsu/OOTDiffusion.