 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cluster and Aggregate: Face Recognition with Large Probe Set
Oct 19, 2022
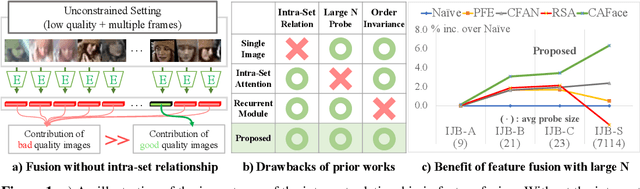
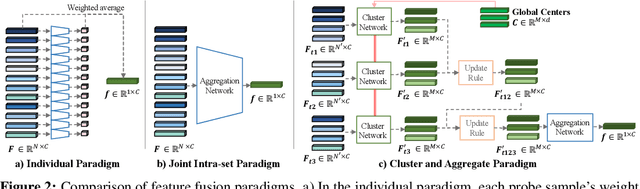
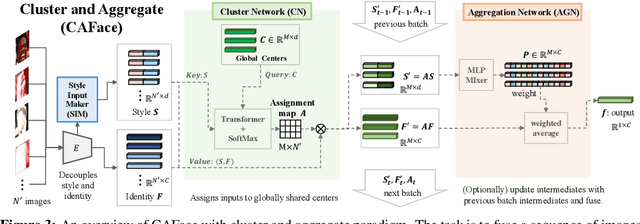

Feature fusion plays a crucial role in unconstrained face recognition where inputs (probes) comprise of a set of $N$ low quality images whose individual qualities vary. Advances in attention and recurrent modules have led to feature fusion that can model the relationship among the images in the input set. However, attention mechanisms cannot scale to large $N$ due to their quadratic complexity and recurrent modules suffer from input order sensitivity. We propose a two-stage feature fusion paradigm, Cluster and Aggregate, that can both scale to large $N$ and maintain the ability to perform sequential inference with order invariance. Specifically, Cluster stage is a linear assignment of $N$ inputs to $M$ global cluster centers, and Aggregation stage is a fusion over $M$ clustered features. The clustered features play an integral role when the inputs are sequential as they can serve as a summarization of past features. By leveraging the order-invariance of incremental averaging operation, we design an update rule that achieves batch-order invariance, which guarantees that the contributions of early image in the sequence do not diminish as time steps increase. Experiments on IJB-B and IJB-S benchmark datasets show the superiority of the proposed two-stage paradigm in unconstrained face recognition. Code and pretrained models are available in https://github.com/mk-minchul/caface
Training set cleansing of backdoor poisoning by self-supervised representation learning
Oct 19, 2022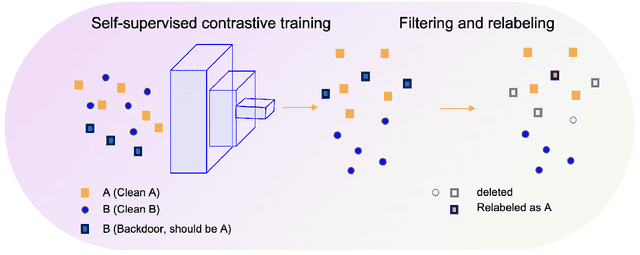
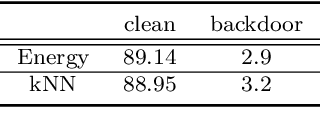
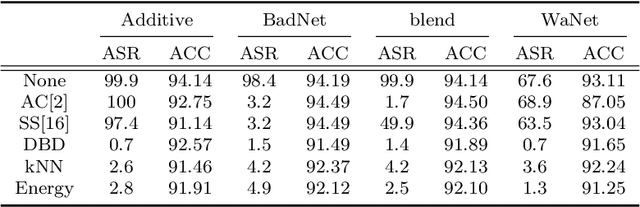
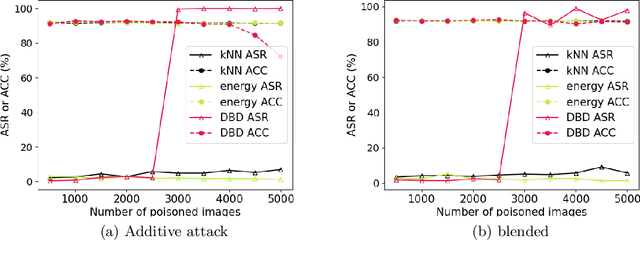
A backdoor or Trojan attack is an important type of data poisoning attack against deep neural network (DNN) classifiers, wherein the training dataset is poisoned with a small number of samples that each possess the backdoor pattern (usually a pattern that is either imperceptible or innocuous) and which are mislabeled to the attacker's target class. When trained on a backdoor-poisoned dataset, a DNN behaves normally on most benign test samples but makes incorrect predictions to the target class when the test sample has the backdoor pattern incorporated (i.e., contains a backdoor trigger). Here we focus on image classification tasks and show that supervised training may build stronger association between the backdoor pattern and the associated target class than that between normal features and the true class of origin. By contrast, self-supervised representation learning ignores the labels of samples and learns a feature embedding based on images' semantic content. %We thus propose to use unsupervised representation learning to avoid emphasising backdoor-poisoned training samples and learn a similar feature embedding for samples of the same class. Using a feature embedding found by self-supervised representation learning, a data cleansing method, which combines sample filtering and re-labeling, is developed. Experiments on CIFAR-10 benchmark datasets show that our method achieves state-of-the-art performance in mitigating backdoor attacks.
Visualize Before You Write: Imagination-Guided Open-Ended Text Generation
Oct 07, 2022
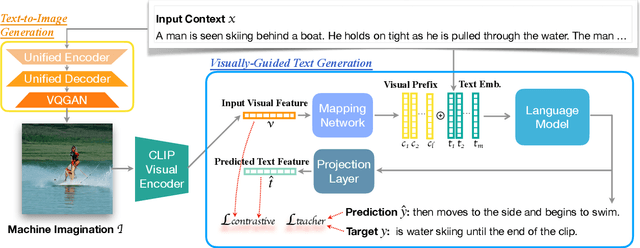
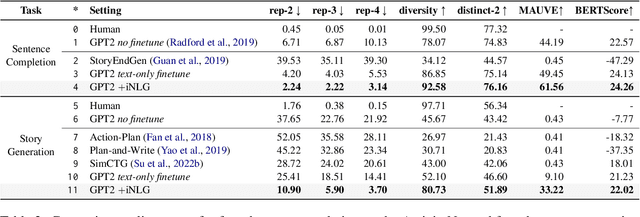
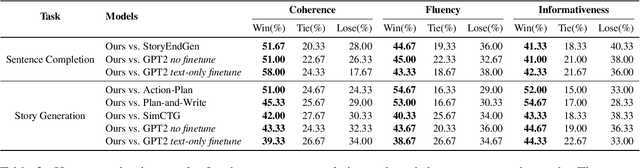
Recent advances in text-to-image synthesis make it possible to visualize machine imaginations for a given context. On the other hand, when generating text, human writers are gifted at creative visualization, which enhances their writings by forming imaginations as blueprints before putting down the stories in words. Inspired by such a cognitive process, we ask the natural question of whether we can endow machines with the same ability to utilize visual information and construct a general picture of the context to guide text generation. In this work, we propose iNLG that uses machine-generated images to guide language models (LM) in open-ended text generation. The experiments and analyses demonstrate the effectiveness of iNLG on open-ended text generation tasks, including text completion, story generation, and concept-to-text generation in few-shot scenarios. Both automatic metrics and human evaluations verify that the text snippets generated by our iNLG are coherent and informative while displaying minor degeneration.
EmbryosFormer: Deformable Transformer and Collaborative Encoding-Decoding for Embryos Stage Development Classification
Oct 07, 2022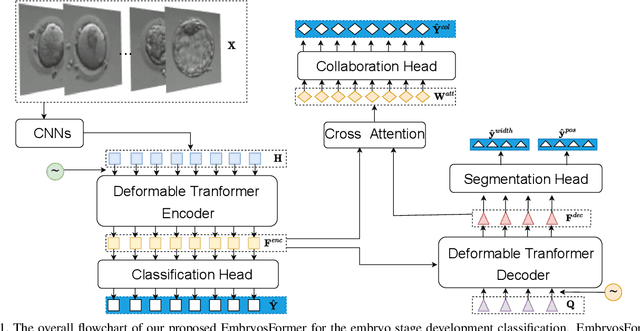

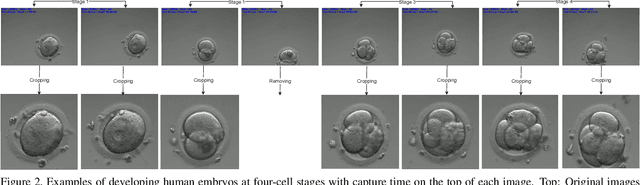
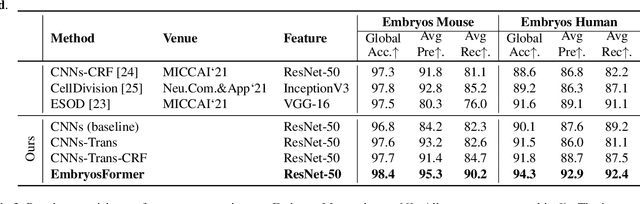
The timing of cell divisions in early embryos during the In-Vitro Fertilization (IVF) process is a key predictor of embryo viability. However, observing cell divisions in Time-Lapse Monitoring (TLM) is a time-consuming process and highly depends on experts. In this paper, we propose EmbryosFormer, a computational model to automatically detect and classify cell divisions from original time-lapse images. Our proposed network is designed as an encoder-decoder deformable transformer with collaborative heads. The transformer contracting path predicts per-image labels and is optimized by a classification head. The transformer expanding path models the temporal coherency between embryo images to ensure monotonic non-decreasing constraint and is optimized by a segmentation head. Both contracting and expanding paths are synergetically learned by a collaboration head. We have benchmarked our proposed EmbryosFormer on two datasets: a public dataset with mouse embryos with 8-cell stage and an in-house dataset with human embryos with 4-cell stage. Source code: https://github.com/UARK-AICV/Embryos.
Computational imaging with the human brain
Oct 07, 2022
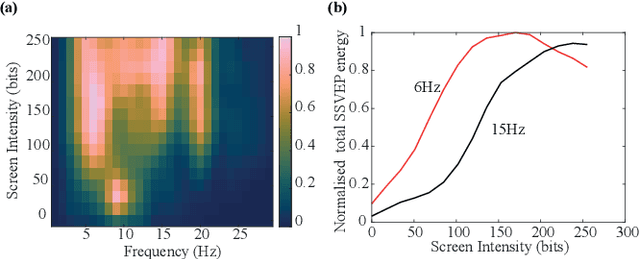


Brain-computer interfaces (BCIs) are enabling a range of new possibilities and routes for augmenting human capability. Here, we propose BCIs as a route towards forms of computation, i.e. computational imaging, that blend the brain with external silicon processing. We demonstrate ghost imaging of a hidden scene using the human visual system that is combined with an adaptive computational imaging scheme. This is achieved through a projection pattern `carving' technique that relies on real-time feedback from the brain to modify patterns at the light projector, thus enabling more efficient and higher resolution imaging. This brain-computer connectivity demonstrates a form of augmented human computation that could in the future extend the sensing range of human vision and provide new approaches to the study of the neurophysics of human perception. As an example, we illustrate a simple experiment whereby image reconstruction quality is affected by simultaneous conscious processing and readout of the perceived light intensities.
Fast and High-Quality Image Denoising via Malleable Convolutions
Jan 04, 2022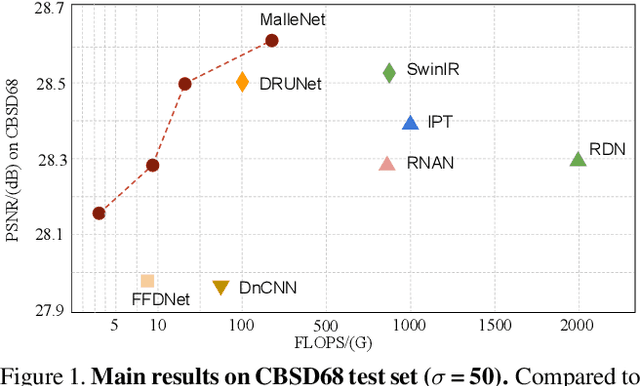
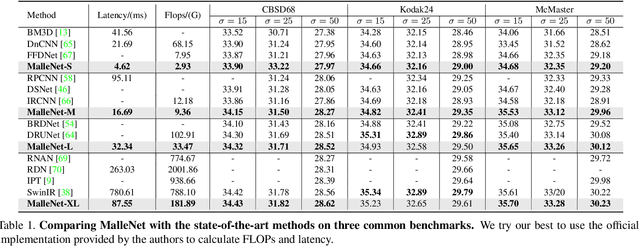
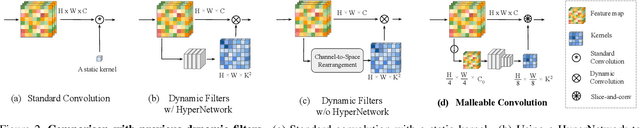
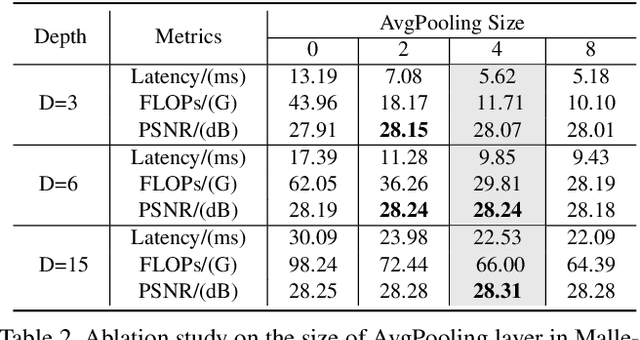
Many image processing networks apply a single set of static convolutional kernels across the entire input image, which is sub-optimal for natural images, as they often consist of heterogeneous visual patterns. Recent works in classification, segmentation, and image restoration have demonstrated that dynamic kernels outperform static kernels at modeling local image statistics. However, these works often adopt per-pixel convolution kernels, which introduce high memory and computation costs. To achieve spatial-varying processing without significant overhead, we present Malleable Convolution (MalleConv), as an efficient variant of dynamic convolution. The weights of MalleConv are dynamically produced by an efficient predictor network capable of generating content-dependent outputs at specific spatial locations. Unlike previous works, MalleConv generates a much smaller set of spatially-varying kernels from input, which enlarges the network's receptive field and significantly reduces computational and memory costs. These kernels are then applied to a full-resolution feature map through an efficient slice-and-conv operator with minimum memory overhead. We further build an efficient denoising network using MalleConv, coined as MalleNet. It achieves high quality results without very deep architecture, e.g., reaching 8.91x faster speed compared to the best performed denoising algorithms (SwinIR), while maintaining similar performance. We also show that a single MalleConv added to a standard convolution-based backbone can contribute significantly to reducing the computational cost or boosting image quality at a similar cost. Project page: https://yifanjiang.net/MalleConv.html
Intelligent Masking: Deep Q-Learning for Context Encoding in Medical Image Analysis
Apr 04, 2022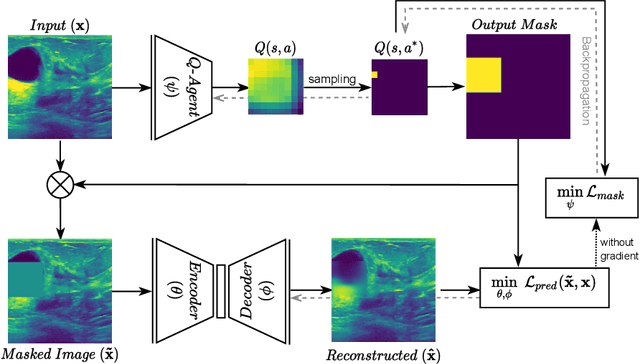
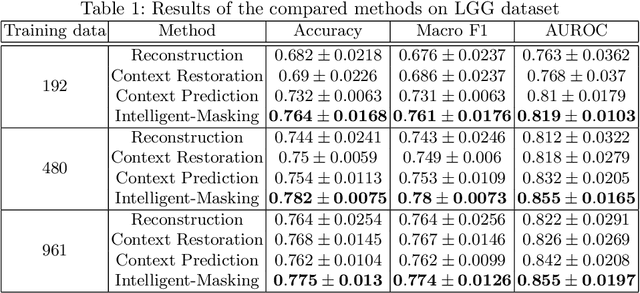
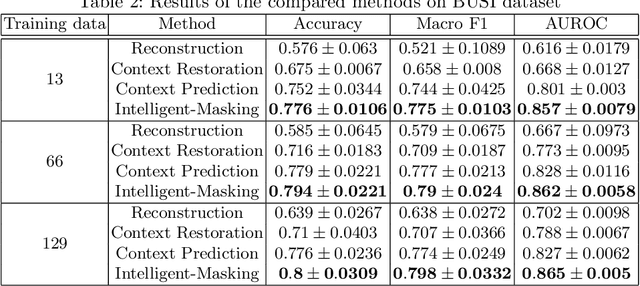
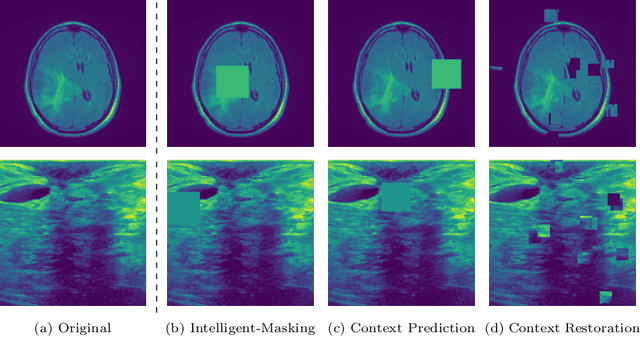
The need for a large amount of labeled data in the supervised setting has led recent studies to utilize self-supervised learning to pre-train deep neural networks using unlabeled data. Many self-supervised training strategies have been investigated especially for medical datasets to leverage the information available in the much fewer unlabeled data. One of the fundamental strategies in image-based self-supervision is context prediction. In this approach, a model is trained to reconstruct the contents of an arbitrary missing region of an image based on its surroundings. However, the existing methods adopt a random and blind masking approach by focusing uniformly on all regions of the images. This approach results in a lot of unnecessary network updates that cause the model to forget the rich extracted features. In this work, we develop a novel self-supervised approach that occludes targeted regions to improve the pre-training procedure. To this end, we propose a reinforcement learning-based agent which learns to intelligently mask input images through deep Q-learning. We show that training the agent against the prediction model can significantly improve the semantic features extracted for downstream classification tasks. We perform our experiments on two public datasets for diagnosing breast cancer in the ultrasound images and detecting lower-grade glioma with MR images. In our experiments, we show that our novel masking strategy advances the learned features according to the performance on the classification task in terms of accuracy, macro F1, and AUROC.
Continual Learning for Class- and Domain-Incremental Semantic Segmentation
Sep 16, 2022
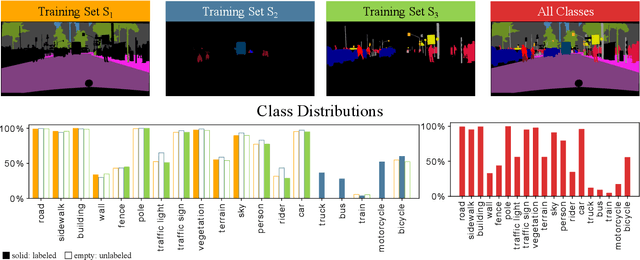
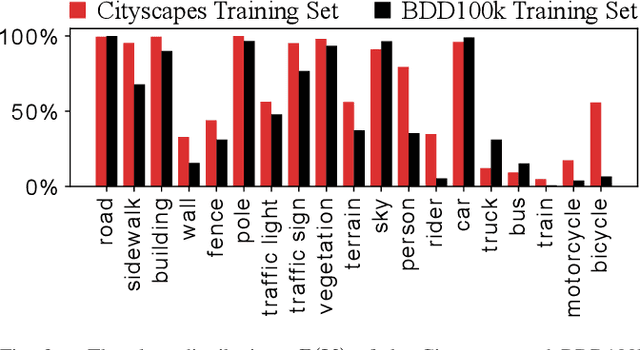
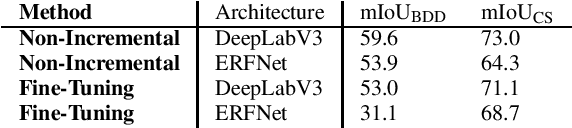
The field of continual deep learning is an emerging field and a lot of progress has been made. However, concurrently most of the approaches are only tested on the task of image classification, which is not relevant in the field of intelligent vehicles. Only recently approaches for class-incremental semantic segmentation were proposed. However, all of those approaches are based on some form of knowledge distillation. At the moment there are no investigations on replay-based approaches that are commonly used for object recognition in a continual setting. At the same time while unsupervised domain adaption for semantic segmentation gained a lot of traction, investigations regarding domain-incremental learning in an continual setting is not well-studied. Therefore, the goal of our work is to evaluate and adapt established solutions for continual object recognition to the task of semantic segmentation and to provide baseline methods and evaluation protocols for the task of continual semantic segmentation. We firstly introduce evaluation protocols for the class- and domain-incremental segmentation and analyze selected approaches. We show that the nature of the task of semantic segmentation changes which methods are most effective in mitigating forgetting compared to image classification. Especially, in class-incremental learning knowledge distillation proves to be a vital tool, whereas in domain-incremental learning replay methods are the most effective method.
Text-to-Audio Grounding Based Novel Metric for Evaluating Audio Caption Similarity
Oct 03, 2022
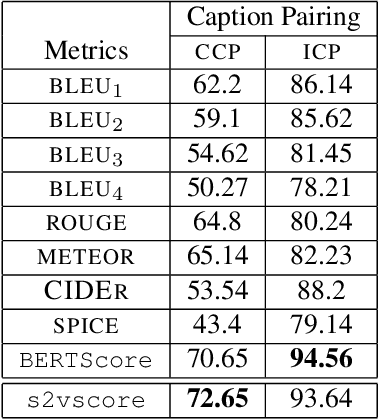
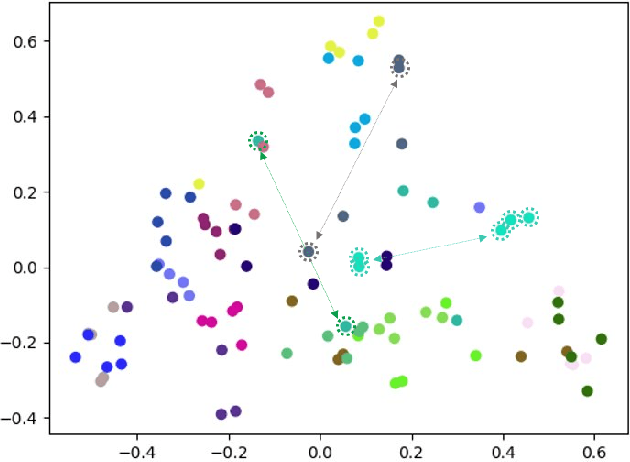
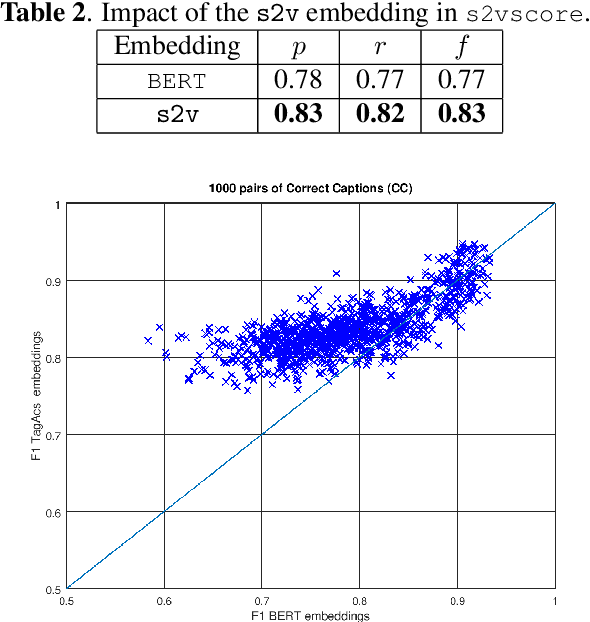
Automatic Audio Captioning (AAC) refers to the task of translating an audio sample into a natural language (NL) text that describes the audio events, source of the events and their relationships. Unlike NL text generation tasks, which rely on metrics like BLEU, ROUGE, METEOR based on lexical semantics for evaluation, the AAC evaluation metric requires an ability to map NL text (phrases) that correspond to similar sounds in addition lexical semantics. Current metrics used for evaluation of AAC tasks lack an understanding of the perceived properties of sound represented by text. In this paper, wepropose a novel metric based on Text-to-Audio Grounding (TAG), which is, useful for evaluating cross modal tasks like AAC. Experiments on publicly available AAC data-set shows our evaluation metric to perform better compared to existing metrics used in NL text and image captioning literature.
Feature Embedding by Template Matching as a ResNet Block
Oct 03, 2022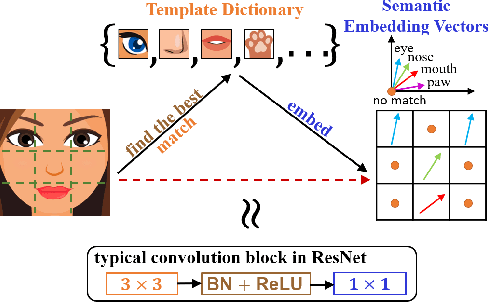
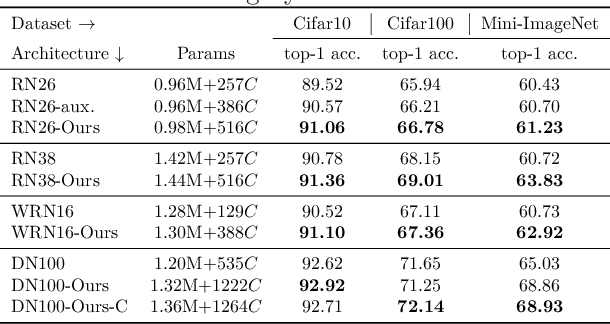
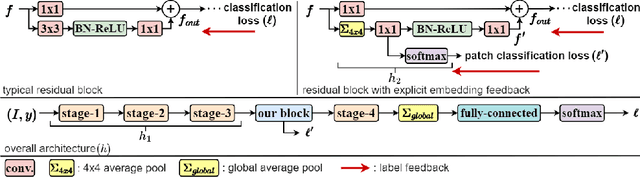
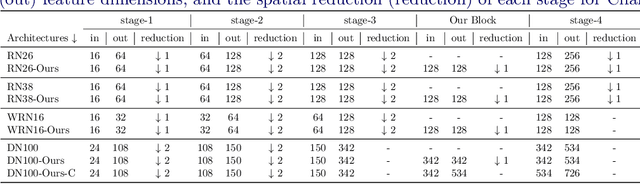
Convolution blocks serve as local feature extractors and are the key to success of the neural networks. To make local semantic feature embedding rather explicit, we reformulate convolution blocks as feature selection according to the best matching kernel. In this manner, we show that typical ResNet blocks indeed perform local feature embedding via template matching once batch normalization (BN) followed by a rectified linear unit (ReLU) is interpreted as arg-max optimizer. Following this perspective, we tailor a residual block that explicitly forces semantically meaningful local feature embedding through using label information. Specifically, we assign a feature vector to each local region according to the classes that the corresponding region matches. We evaluate our method on three popular benchmark datasets with several architectures for image classification and consistently show that our approach substantially improves the performance of the baseline architectures.