 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Increasing Model Generalizability for Unsupervised Domain Adaptation
Sep 29, 2022
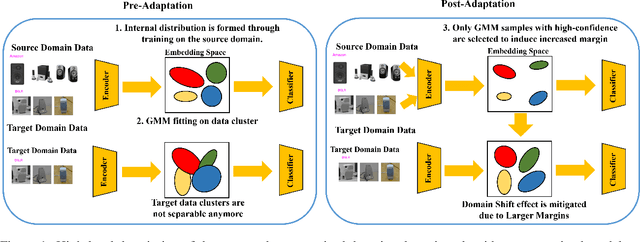


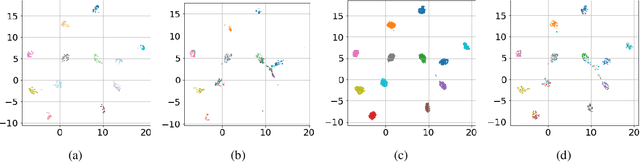
A dominant approach for addressing unsupervised domain adaptation is to map data points for the source and the target domains into an embedding space which is modeled as the output-space of a shared deep encoder. The encoder is trained to make the embedding space domain-agnostic to make a source-trained classifier generalizable on the target domain. A secondary mechanism to improve UDA performance further is to make the source domain distribution more compact to improve model generalizability. We demonstrate that increasing the interclass margins in the embedding space can help to develop a UDA algorithm with improved performance. We estimate the internally learned multi-modal distribution for the source domain, learned as a result of pretraining, and use it to increase the interclass class separation in the source domain to reduce the effect of domain shift. We demonstrate that using our approach leads to improved model generalizability on four standard benchmark UDA image classification datasets and compares favorably against exiting methods.
Adversarial Mutual Leakage Network for Cell Image Segmentation
Mar 20, 2022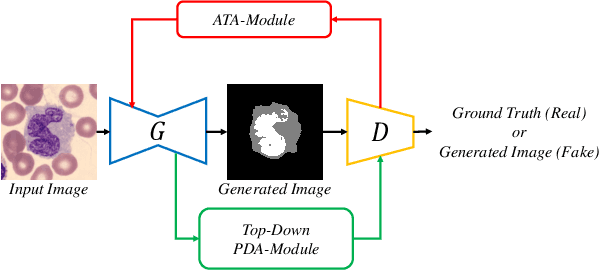
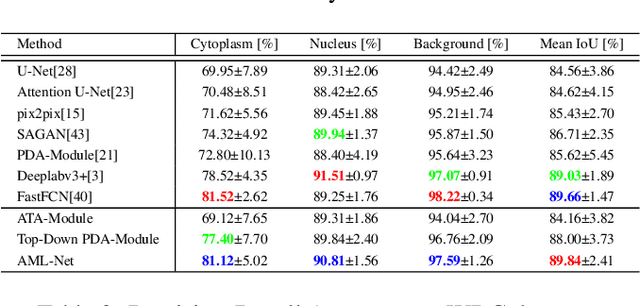
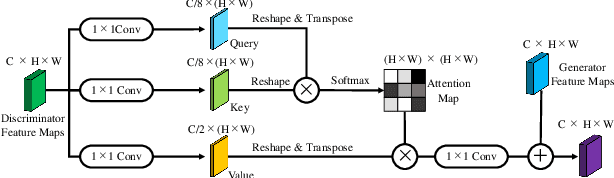
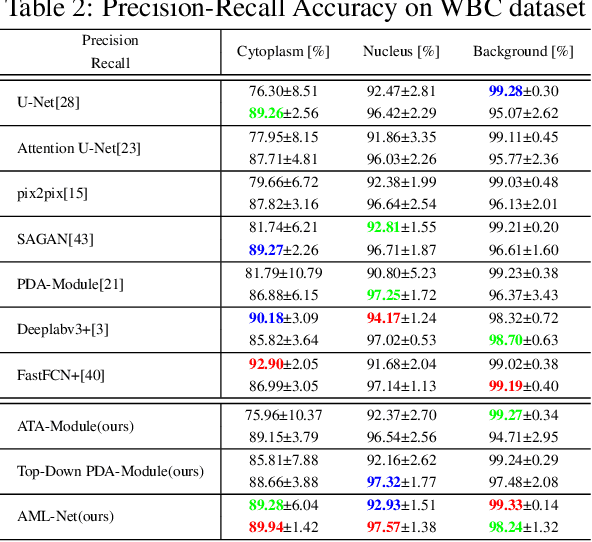
We propose three segmentation methods using GAN and information leakage between generator and discriminator. First, we propose an Adversarial Training Attention Module (ATA-Module) that uses an attention mechanism from the discriminator to the generator to enhance and leak important information in the discriminator. ATA-Module transmits important information to the generator from the discriminator. Second, we propose a Top-Down Pixel-wise Difficulty Attention Module (Top-Down PDA-Module) that leaks an attention map based on pixel-wise difficulty in the generator to the discriminator. The generator trains to focus on pixel-wise difficulty, and the discriminator uses the difficulty information leaked from the generator for classification. Finally, we propose an Adversarial Mutual Leakage Network (AML-Net) that mutually leaks the information each other between the generator and the discriminator. By using the information of the other network, it is able to train more efficiently than ordinary segmentation models. Three proposed methods have been evaluated on two datasets for cell image segmentation. The experimental results show that the segmentation accuracy of AML-Net was much improved in comparison with conventional methods.
PS-NeRV: Patch-wise Stylized Neural Representations for Videos
Aug 07, 2022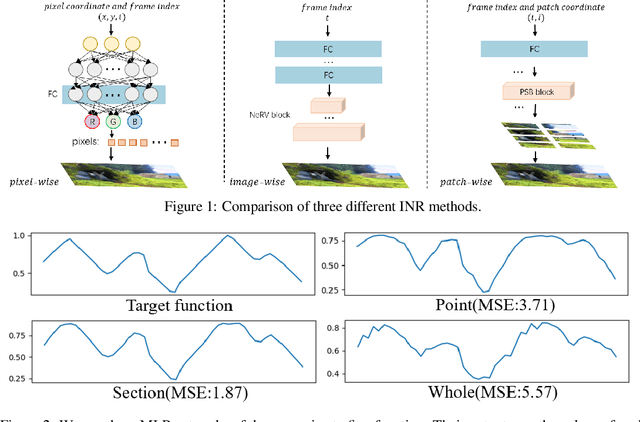
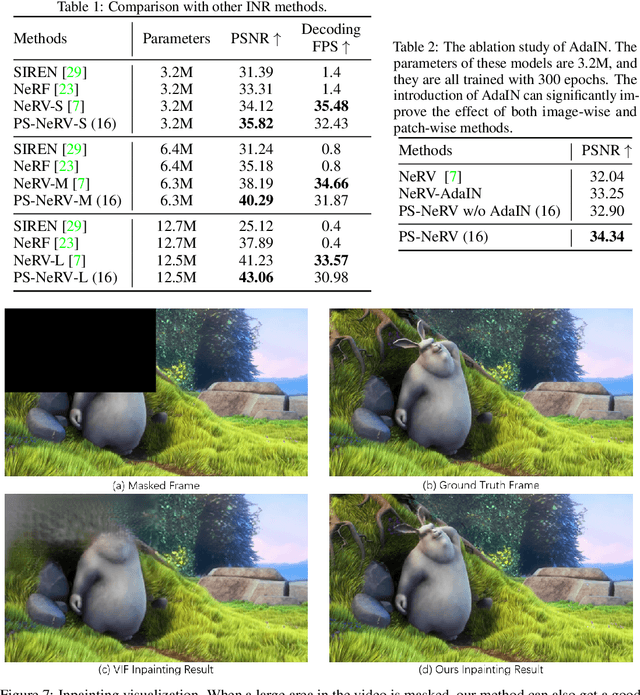
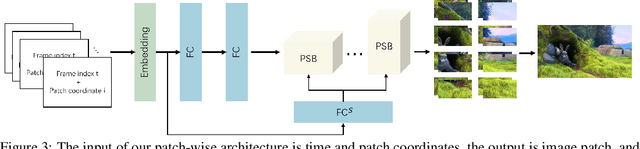
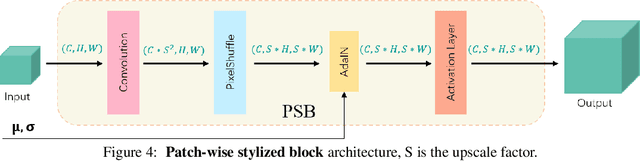
We study how to represent a video with implicit neural representations (INRs). Classical INRs methods generally utilize MLPs to map input coordinates to output pixels. While some recent works have tried to directly reconstruct the whole image with CNNs. However, we argue that both the above pixel-wise and image-wise strategies are not favorable to video data. Instead, we propose a patch-wise solution, PS-NeRV, which represents videos as a function of patches and the corresponding patch coordinate. It naturally inherits the advantages of image-wise methods, and achieves excellent reconstruction performance with fast decoding speed. The whole method includes conventional modules, like positional embedding, MLPs and CNNs, while also introduces AdaIN to enhance intermediate features. These simple yet essential changes could help the network easily fit high-frequency details. Extensive experiments have demonstrated its effectiveness in several video-related tasks, such as video compression and video inpainting.
Look where you look! Saliency-guided Q-networks for visual RL tasks
Sep 29, 2022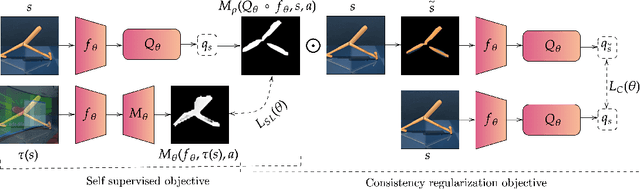
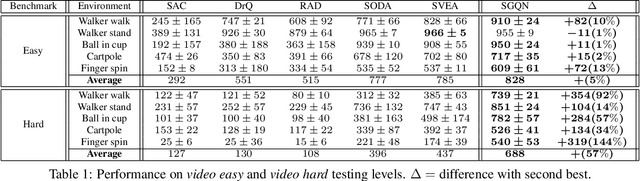

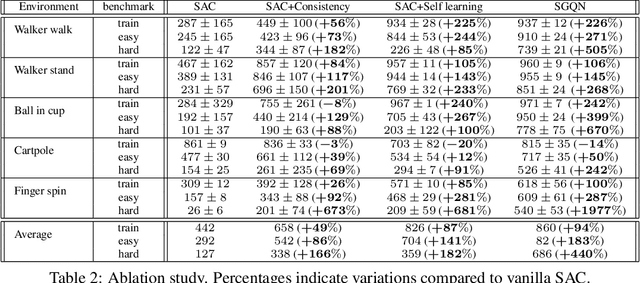
Deep reinforcement learning policies, despite their outstanding efficiency in simulated visual control tasks, have shown disappointing ability to generalize across disturbances in the input training images. Changes in image statistics or distracting background elements are pitfalls that prevent generalization and real-world applicability of such control policies. We elaborate on the intuition that a good visual policy should be able to identify which pixels are important for its decision, and preserve this identification of important sources of information across images. This implies that training of a policy with small generalization gap should focus on such important pixels and ignore the others. This leads to the introduction of saliency-guided Q-networks (SGQN), a generic method for visual reinforcement learning, that is compatible with any value function learning method. SGQN vastly improves the generalization capability of Soft Actor-Critic agents and outperforms existing stateof-the-art methods on the Deepmind Control Generalization benchmark, setting a new reference in terms of training efficiency, generalization gap, and policy interpretability.
TranSiam: Fusing Multimodal Visual Features Using Transformer for Medical Image Segmentation
Apr 26, 2022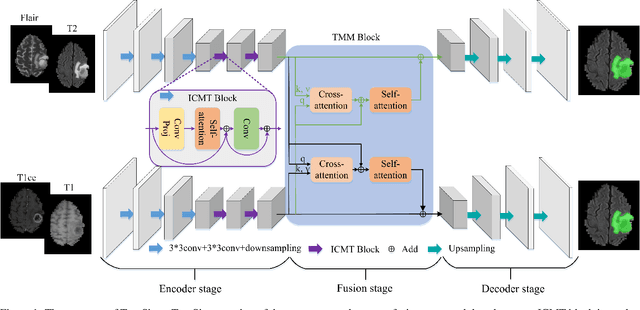
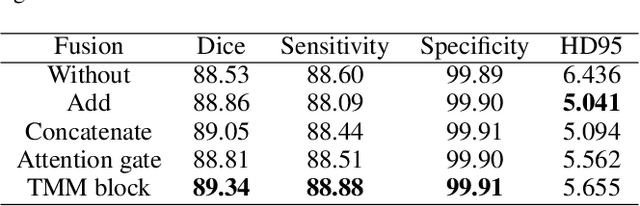
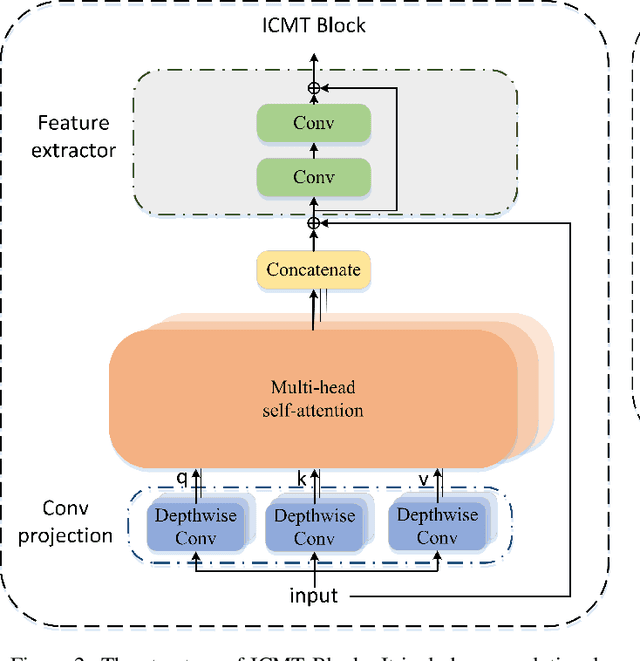
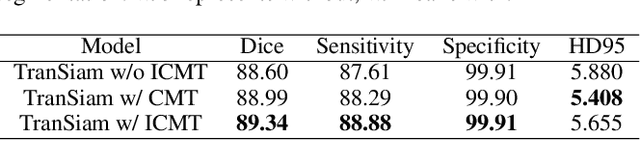
Automatic segmentation of medical images based on multi-modality is an important topic for disease diagnosis. Although the convolutional neural network (CNN) has been proven to have excellent performance in image segmentation tasks, it is difficult to obtain global information. The lack of global information will seriously affect the accuracy of the segmentation results of the lesion area. In addition, there are visual representation differences between multimodal data of the same patient. These differences will affect the results of the automatic segmentation methods. To solve these problems, we propose a segmentation method suitable for multimodal medical images that can capture global information, named TranSiam. TranSiam is a 2D dual path network that extracts features of different modalities. In each path, we utilize convolution to extract detailed information in low level stage, and design a ICMT block to extract global information in high level stage. ICMT block embeds convolution in the transformer, which can extract global information while retaining spatial and detailed information. Furthermore, we design a novel fusion mechanism based on cross attention and selfattention, called TMM block, which can effectively fuse features between different modalities. On the BraTS 2019 and BraTS 2020 multimodal datasets, we have a significant improvement in accuracy over other popular methods.
WAD-CMSN: Wasserstein Distance based Cross-Modal Semantic Network for Zero-Shot Sketch-Based Image Retrieval
Feb 11, 2022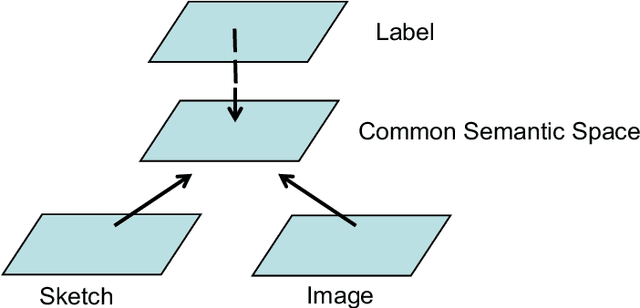
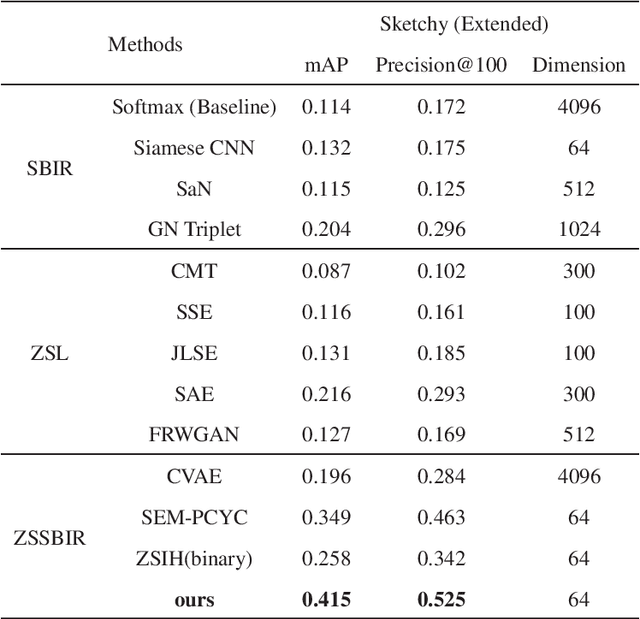
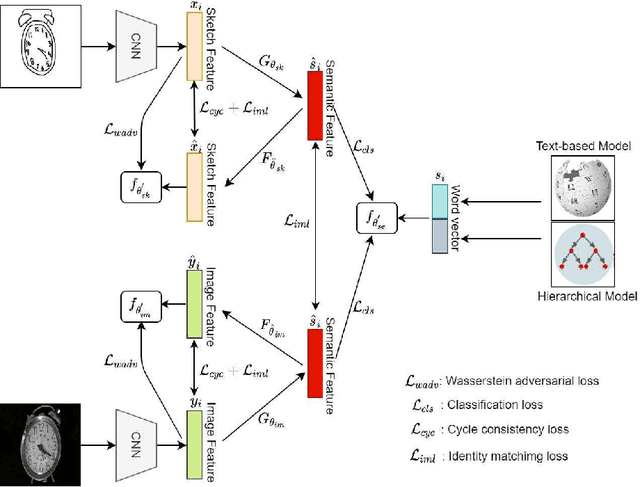
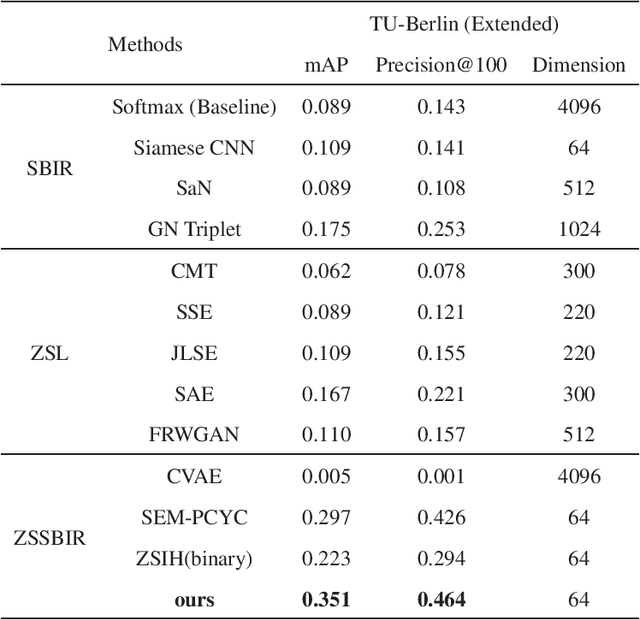
Zero-shot sketch-based image retrieval (ZSSBIR), as a popular studied branch of computer vision, attracts wide attention recently. Unlike sketch-based image retrieval (SBIR), the main aim of ZSSBIR is to retrieve natural images given free hand-drawn sketches that may not appear during training. Previous approaches used semantic aligned sketch-image pairs or utilized memory expensive fusion layer for projecting the visual information to a low dimensional subspace, which ignores the significant heterogeneous cross-domain discrepancy between highly abstract sketch and relevant image. This may yield poor performance in the training phase. To tackle this issue and overcome this drawback, we propose a Wasserstein distance based cross-modal semantic network (WAD-CMSN) for ZSSBIR. Specifically, it first projects the visual information of each branch (sketch, image) to a common low dimensional semantic subspace via Wasserstein distance in an adversarial training manner. Furthermore, identity matching loss is employed to select useful features, which can not only capture complete semantic knowledge, but also alleviate the over-fitting phenomenon caused by the WAD-CMSN model. Experimental results on the challenging Sketchy (Extended) and TU-Berlin (Extended) datasets indicate the effectiveness of the proposed WAD-CMSN model over several competitors.
Tampered VAE for Improved Satellite Image Time Series Classification
Mar 30, 2022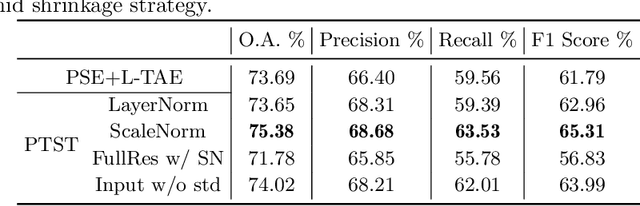
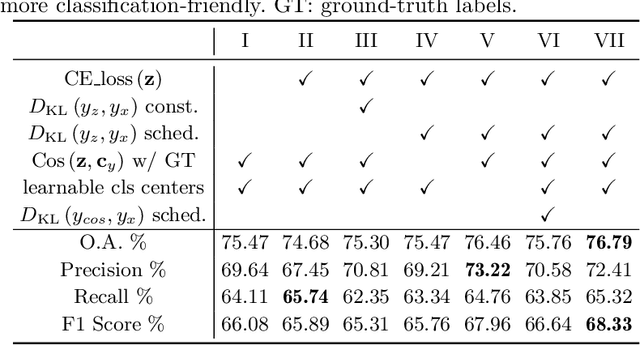
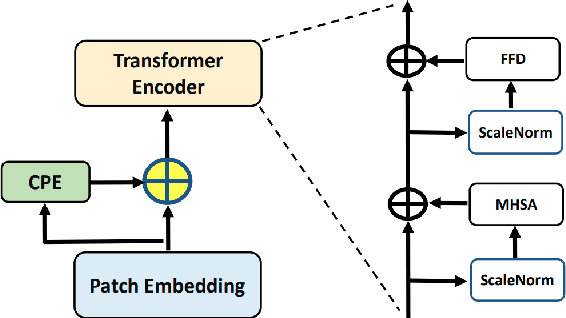
The unprecedented availability of spatial and temporal high-resolution satellite image time series (SITS) for crop type mapping is believed to necessitate deep learning architectures to accommodate challenges arising from both dimensions. Recent state-of-the-art deep learning models have shown promising results by stacking spatial and temporal encoders. However, we present a Pyramid Time-Series Transformer (PTST) that operates solely on the temporal dimension, i.e., neglecting the spatial dimension, can produce superior results with a drastic reduction in GPU memory consumption and easy extensibility. Furthermore, we augment it to perform semi-supervised learning by proposing a classification-friendly VAE framework that introduces clustering mechanisms into latent space and can promote linear separability therein. Consequently, a few principal axes of the latent space can explain the majority of variance in raw data. Meanwhile, the VAE framework with proposed tweaks can maintain competitive classification performance as its purely discriminative counterpart when only $40\%$ of labelled data is used. We hope the proposed framework can serve as a baseline for crop classification with SITS for its modularity and simplicity.
Explanation Uncertainty with Decision Boundary Awareness
Oct 05, 2022
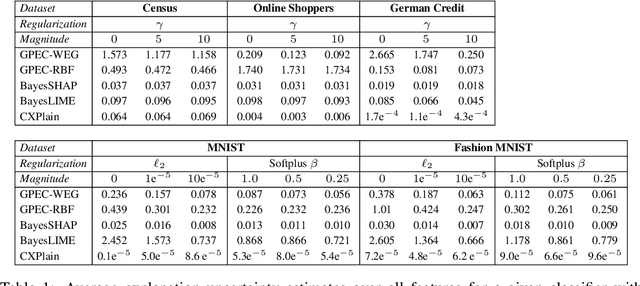
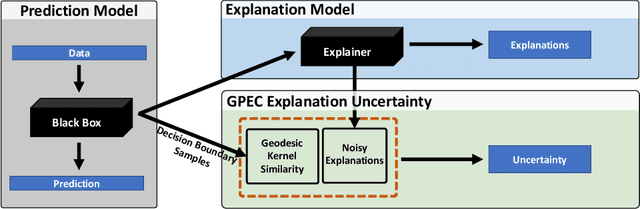
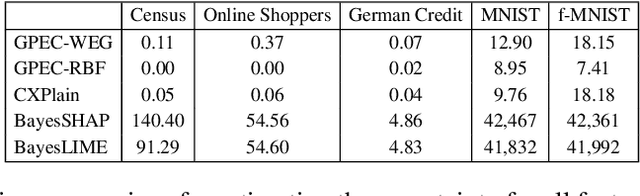
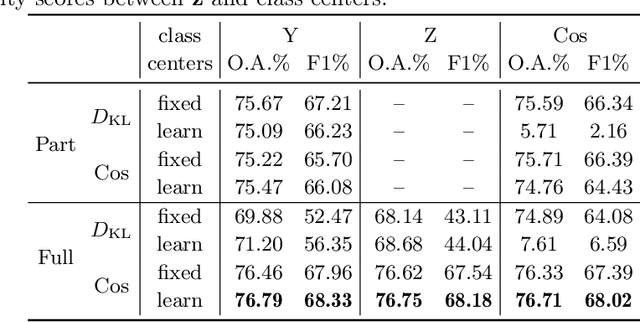
Post-hoc explanation methods have become increasingly depended upon for understanding black-box classifiers in high-stakes applications, precipitating a need for reliable explanations. While numerous explanation methods have been proposed, recent works have shown that many existing methods can be inconsistent or unstable. In addition, high-performing classifiers are often highly nonlinear and can exhibit complex behavior around the decision boundary, leading to brittle or misleading local explanations. Therefore, there is an impending need to quantify the uncertainty of such explanation methods in order to understand when explanations are trustworthy. We introduce a novel uncertainty quantification method parameterized by a Gaussian Process model, which combines the uncertainty approximation of existing methods with a novel geodesic-based similarity which captures the complexity of the target black-box decision boundary. The proposed framework is highly flexible; it can be used with any black-box classifier and feature attribution method to amortize uncertainty estimates for explanations. We show theoretically that our proposed geodesic-based kernel similarity increases with the complexity of the decision boundary. Empirical results on multiple tabular and image datasets show that our decision boundary-aware uncertainty estimate improves understanding of explanations as compared to existing methods.
Blind Image Super Resolution with Semantic-Aware Quantized Texture Prior
Feb 26, 2022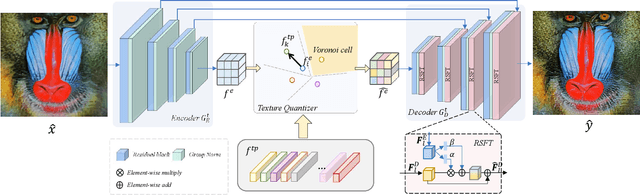
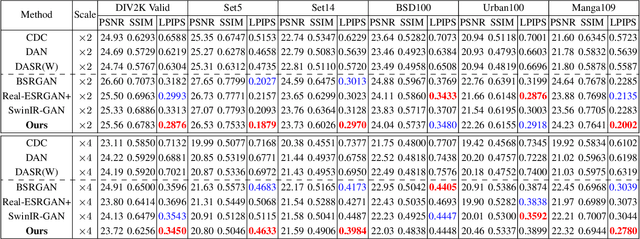
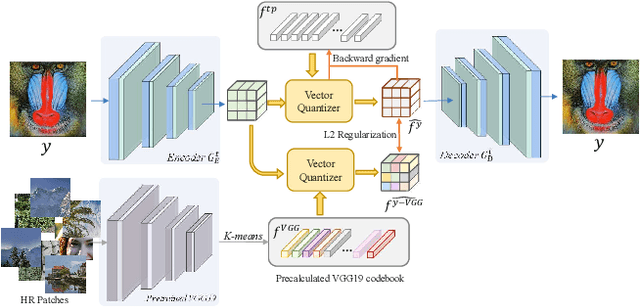

A key challenge of blind image super resolution is to recover realistic textures for low-resolution images with unknown degradations. Most recent works completely rely on the generative ability of GANs, which are difficult to train. Other methods resort to high-resolution image references that are usually not available. In this work, we propose a novel framework, denoted as QuanTexSR, to restore realistic textures with the Quantized Texture Priors encoded in Vector Quantized GAN. The QuanTexSR generates textures by aligning the textureless content features to the quantized feature vectors, i.e., a pretrained feature codebook. Specifically, QuanTexSR formulates the texture generation as a feature matching problem between textureless features and a pretrained feature codebook. The final textures are then generated by the quantized features from the codebook. Since features in the codebook have shown the ability to generate natural textures in the pretrain stage, QuanTexSR can generate rich and realistic textures with the pretrained codebook as texture priors. Moreover, we propose a semantic regularization technique that regularizes the pre-training of the codebook using clusters of features extracted from the pretrained VGG19 network. This further improves texture generation with semantic context. Experiments demonstrate that the proposed QuanTexSR can generate competitive or better textures than previous approaches. Code will be made publicly available.
A New Scheme for Image Compression and Encryption Using ECIES, Henon Map, and AEGAN
Aug 24, 2022


Providing security in the transmission of images and other multimedia data has become one of the most important scientific and practical issues. In this paper, a method for compressing and encryption images is proposed, which can safely transmit images in low-bandwidth data transmission channels. At first, using the autoencoding generative adversarial network (AEGAN) model, the images are mapped to a vector in the latent space with low dimensions. In the next step, the obtained vector is encrypted using public key encryption methods. In the proposed method, Henon chaotic map is used for permutation, which makes information transfer more secure. To evaluate the results of the proposed scheme, three criteria SSIM, PSNR, and execution time have been used.