 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MIPI 2022 Challenge on RGB+ToF Depth Completion: Dataset and Report
Sep 15, 2022

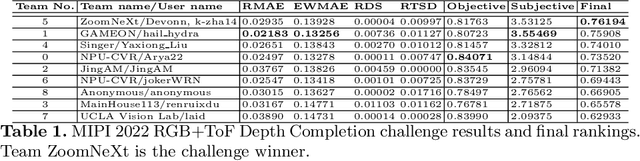
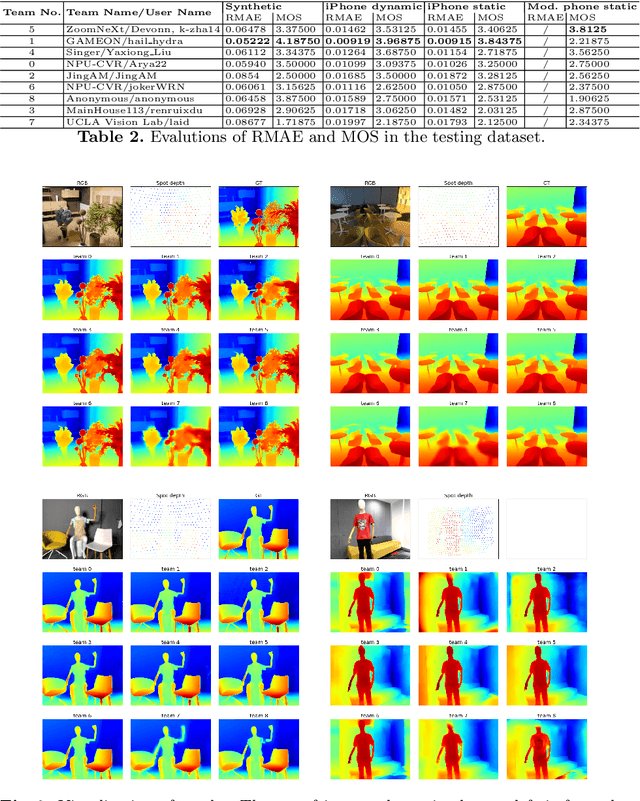
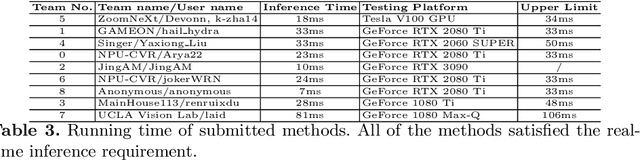
Developing and integrating advanced image sensors with novel algorithms in camera systems is prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGB+ToF Depth Completion, one of the five tracks, working on the fusion of RGB sensor and ToF sensor (with spot illumination) is introduced. The participants were provided with a new dataset called TetrasRGBD, which contains 18k pairs of high-quality synthetic RGB+Depth training data and 2.3k pairs of testing data from mixed sources. All the data are collected in an indoor scenario. We require that the running time of all methods should be real-time on desktop GPUs. The final results are evaluated using objective metrics and Mean Opinion Score (MOS) subjectively. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
LAFITE: Towards Language-Free Training for Text-to-Image Generation
Dec 13, 2021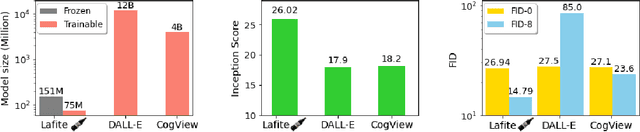
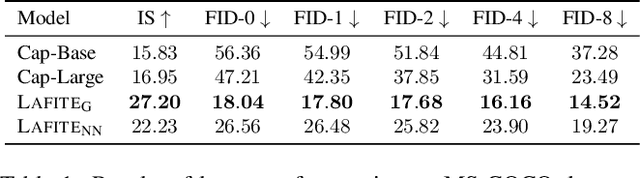
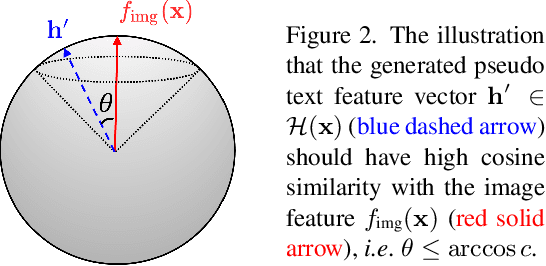
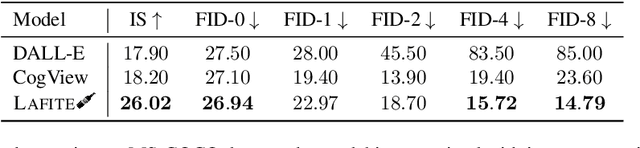
One of the major challenges in training text-to-image generation models is the need of a large number of high-quality image-text pairs. While image samples are often easily accessible, the associated text descriptions typically require careful human captioning, which is particularly time- and cost-consuming. In this paper, we propose the first work to train text-to-image generation models without any text data. Our method leverages the well-aligned multi-modal semantic space of the powerful pre-trained CLIP model: the requirement of text-conditioning is seamlessly alleviated via generating text features from image features. Extensive experiments are conducted to illustrate the effectiveness of the proposed method. We obtain state-of-the-art results in the standard text-to-image generation tasks. Importantly, the proposed language-free model outperforms most existing models trained with full image-text pairs. Furthermore, our method can be applied in fine-tuning pre-trained models, which saves both training time and cost in training text-to-image generation models. Our pre-trained model obtains competitive results in zero-shot text-to-image generation on the MS-COCO dataset, yet with around only 1% of the model size and training data size relative to the recently proposed large DALL-E model.
A deep learning network with differentiable dynamic programming for retina OCT surface segmentation
Oct 08, 2022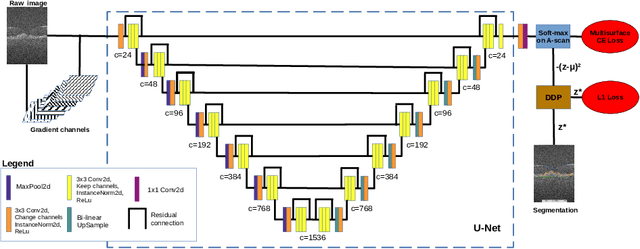
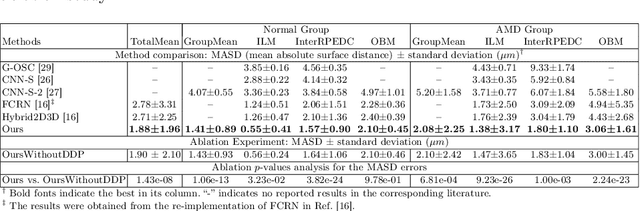
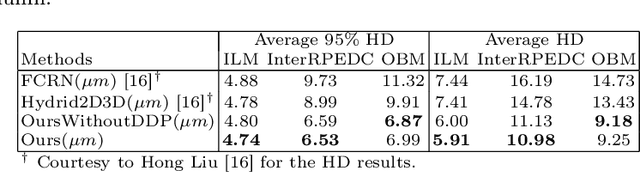
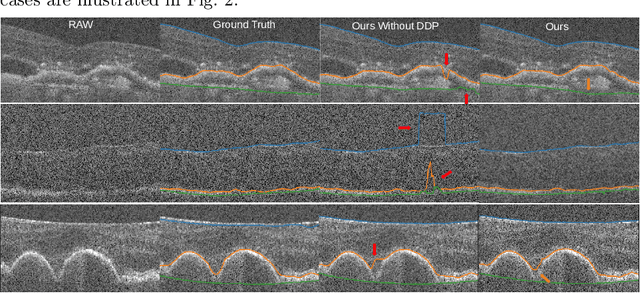
Multiple-surface segmentation in Optical Coherence Tomography (OCT) images is a challenge problem, further complicated by the frequent presence of weak image boundaries. Recently, many deep learning (DL) based methods have been developed for this task and yield remarkable performance. Unfortunately, due to the scarcity of training data in medical imaging, it is challenging for DL networks to learn the global structure of the target surfaces, including surface smoothness. To bridge this gap, this study proposes to seamlessly unify a U-Net for feature learning with a constrained differentiable dynamic programming module to achieve an end-to-end learning for retina OCT surface segmentation to explicitly enforce surface smoothness. It effectively utilizes the feedback from the downstream model optimization module to guide feature learning, yielding a better enforcement of global structures of the target surfaces. Experiments on Duke AMD (age-related macular degeneration) and JHU MS (multiple sclerosis) OCT datasets for retinal layer segmentation demonstrated very promising segmentation accuracy.
Two-Stream UNET Networks for Semantic Segmentation in Medical Images
Jul 27, 2022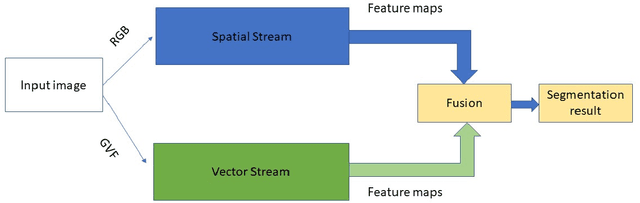

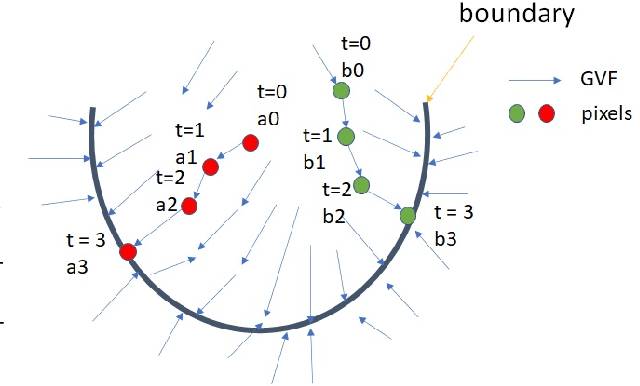
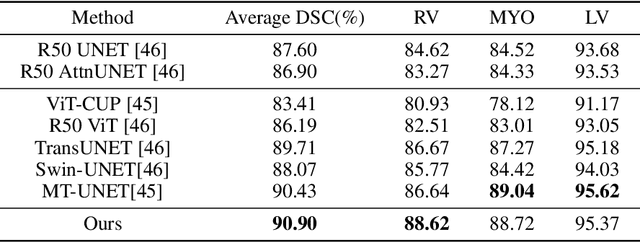
Recent advances of semantic image segmentation greatly benefit from deeper and larger Convolutional Neural Network (CNN) models. Compared to image segmentation in the wild, properties of both medical images themselves and of existing medical datasets hinder training deeper and larger models because of overfitting. To this end, we propose a novel two-stream UNET architecture for automatic end-to-end medical image segmentation, in which intensity value and gradient vector flow (GVF) are two inputs for each stream, respectively. We demonstrate that two-stream CNNs with more low-level features greatly benefit semantic segmentation for imperfect medical image datasets. Our proposed two-stream networks are trained and evaluated on the popular medical image segmentation benchmarks, and the results are competitive with the state of the art. The code will be released soon.
A Split Semantic Detection Algorithm for Psychological Sandplay Image
Mar 02, 2022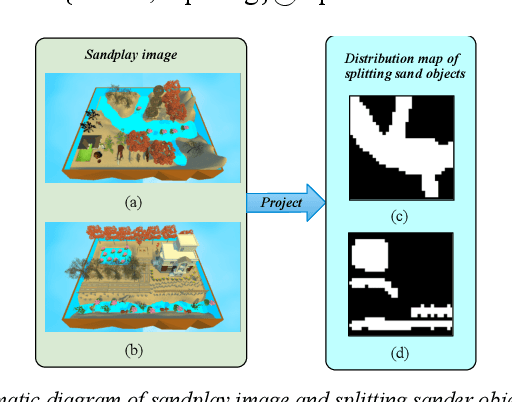

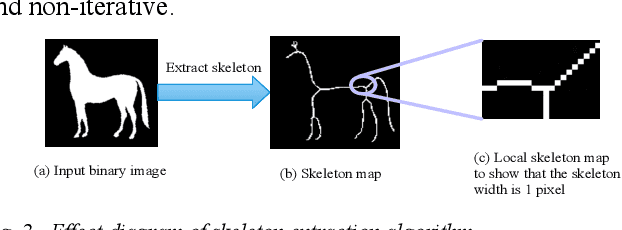

Psychological sandplay, as an important psychological analysis tool, is a visual scene constructed by the tester selecting and placing sand objects (e.g., sand, river, human figures, animals, vegetation, buildings, etc.). As the projection of the tester's inner world, it contains high-level semantic information reflecting the tester's thoughts and feelings. Most of the existing computer vision technologies focus on the objective basic semantics (e.g., object's name, attribute, boundingbox, etc.) in the natural image, while few related works pay attention to the subjective psychological semantics (e.g., emotion, thoughts, feelings, etc.) in the artificial image. We take the latter semantics as the research object, take "split" (a common psychological semantics reflecting the inner integration of testers) as the research goal, and use the method of machine learning to realize the automatic detection of split semantics, so as to explore the application of machine learning in the detection of subjective psychological semantics of sandplay images. To this end, we present a feature dimensionality reduction and extraction algorithm to obtain a one-dimensional vector representing the split feature, and build the split semantic detector based on Multilayer Perceptron network to get the detection results. Experimental results on the real sandplay datasets show the effectiveness of our proposed algorithm.
Style Transfer of Black and White Silhouette Images using CycleGAN and a Randomly Generated Dataset
Aug 03, 2022



CycleGAN can be used to transfer an artistic style to an image. It does not require pairs of source and stylized images to train a model. Taking this advantage, we propose using randomly generated data to train a machine learning model that can transfer traditional art style to a black and white silhouette image. The result is noticeably better than the previous neural style transfer methods. However, there are some areas for improvement, such as removing artifacts and spikes from the transformed image.
Unsupervised confidence for LiDAR depth maps and applications
Oct 06, 2022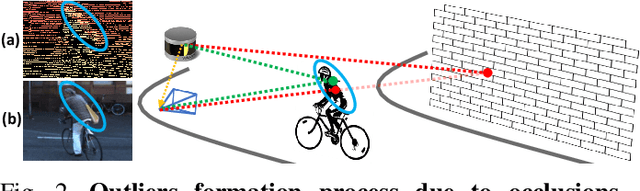
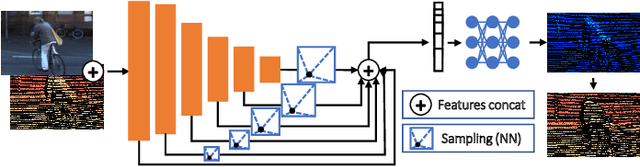

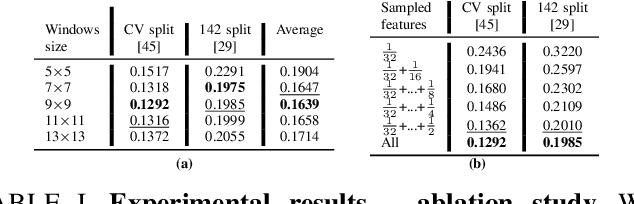
Depth perception is pivotal in many fields, such as robotics and autonomous driving, to name a few. Consequently, depth sensors such as LiDARs rapidly spread in many applications. The 3D point clouds generated by these sensors must often be coupled with an RGB camera to understand the framed scene semantically. Usually, the former is projected over the camera image plane, leading to a sparse depth map. Unfortunately, this process, coupled with the intrinsic issues affecting all the depth sensors, yields noise and gross outliers in the final output. Purposely, in this paper, we propose an effective unsupervised framework aimed at explicitly addressing this issue by learning to estimate the confidence of the LiDAR sparse depth map and thus allowing for filtering out the outliers. Experimental results on the KITTI dataset highlight that our framework excels for this purpose. Moreover, we demonstrate how this achievement can improve a wide range of tasks.
Highly Accurate Dichotomous Image Segmentation
Mar 08, 2022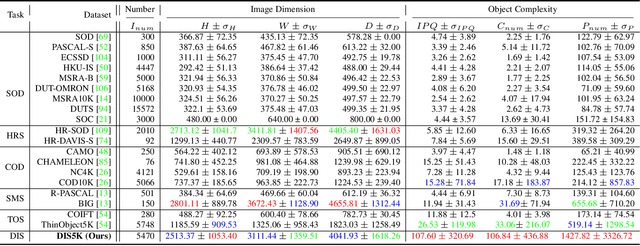
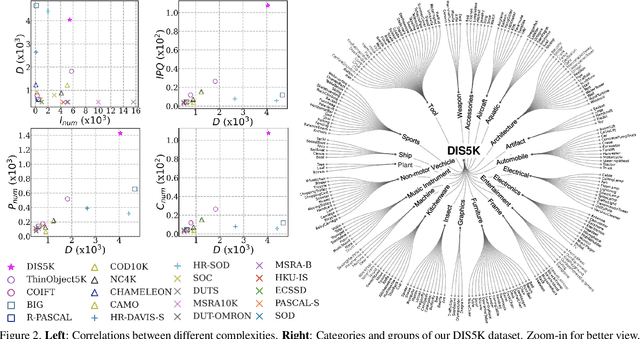
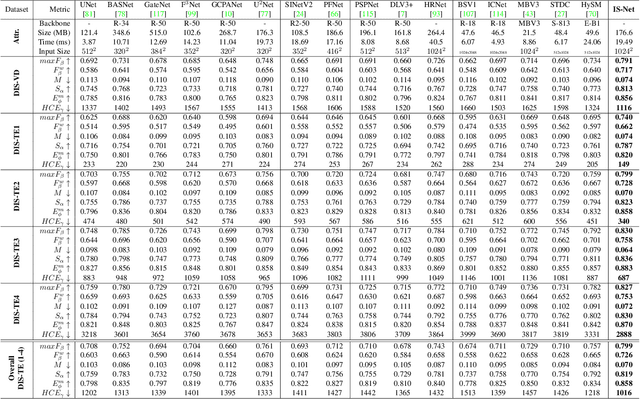

We present a systematic study on a new task called dichotomous image segmentation (DIS), which aims to segment highly accurate objects from natural images. To this end, we collected the first large-scale dataset, called DIS5K, which contains 5,470 high-resolution (e.g., 2K, 4K or larger) images covering camouflaged, salient, or meticulous objects in various backgrounds. All images are annotated with extremely fine-grained labels. In addition, we introduce a simple intermediate supervision baseline (IS-Net) using both feature-level and mask-level guidance for DIS model training. Without tricks, IS-Net outperforms various cutting-edge baselines on the proposed DIS5K, making it a general self-learned supervision network that can help facilitate future research in DIS. Further, we design a new metric called human correction efforts (HCE) which approximates the number of mouse clicking operations required to correct the false positives and false negatives. HCE is utilized to measure the gap between models and real-world applications and thus can complement existing metrics. Finally, we conduct the largest-scale benchmark, evaluating 16 representative segmentation models, providing a more insightful discussion regarding object complexities, and showing several potential applications (e.g., background removal, art design, 3D reconstruction). Hoping these efforts can open up promising directions for both academic and industries. We will release our DIS5K dataset, IS-Net baseline, HCE metric, and the complete benchmark results.
USIS: Unsupervised Semantic Image Synthesis
Sep 29, 2021
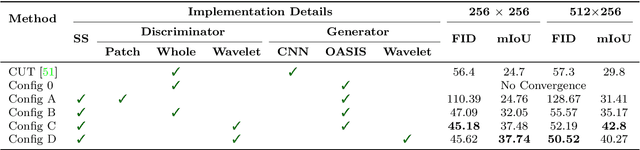
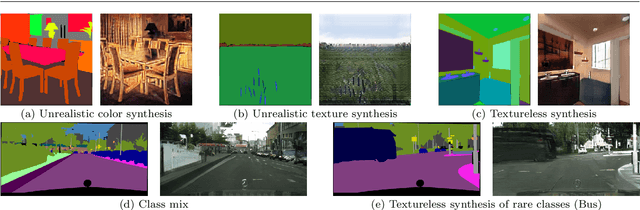

Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a photorealistic image is synthesized from a segmentation mask. SIS has mostly been addressed as a supervised problem. However, state-of-the-art methods depend on a huge amount of labeled data and cannot be applied in an unpaired setting. On the other hand, generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and feed them to traditional convolutional networks, which then learn correspondences in appearance instead of semantic content. In this initial work, we propose a new Unsupervised paradigm for Semantic Image Synthesis (USIS) as a first step towards closing the performance gap between paired and unpaired settings. Notably, the framework deploys a SPADE generator that learns to output images with visually separable semantic classes using a self-supervised segmentation loss. Furthermore, in order to match the color and texture distribution of real images without losing high-frequency information, we propose to use whole image wavelet-based discrimination. We test our methodology on 3 challenging datasets and demonstrate its ability to generate multimodal photorealistic images with an improved quality in the unpaired setting.
gSwin: Gated MLP Vision Model with Hierarchical Structure of Shifted Window
Aug 24, 2022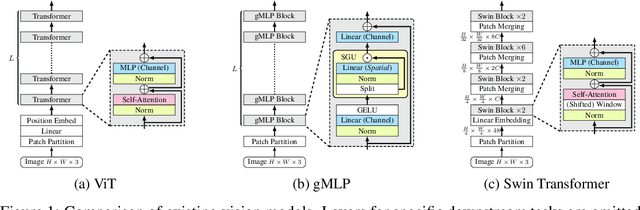
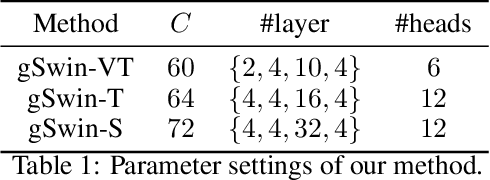
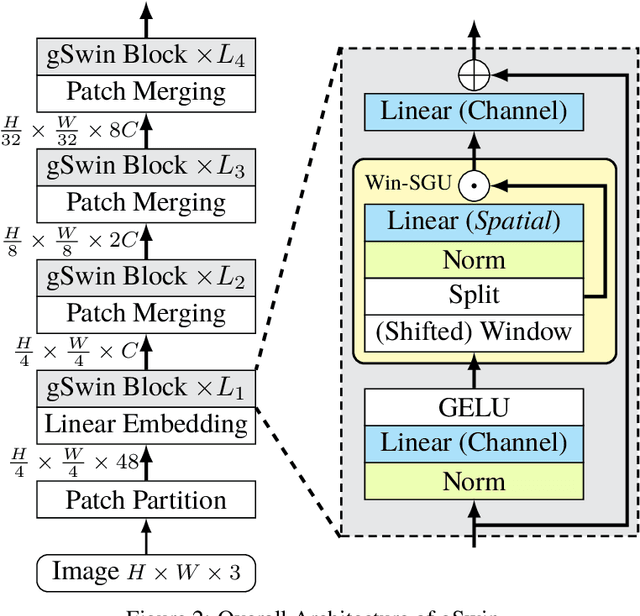
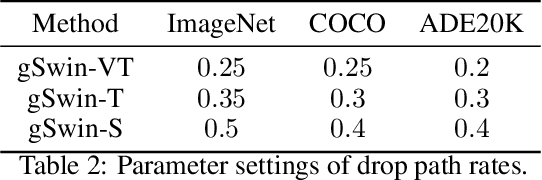
Following the success in language domain, the self-attention mechanism (transformer) is adopted in the vision domain and achieving great success recently. Additionally, as another stream, multi-layer perceptron (MLP) is also explored in the vision domain. These architectures, other than traditional CNNs, have been attracting attention recently, and many methods have been proposed. As one that combines parameter efficiency and performance with locality and hierarchy in image recognition, we propose gSwin, which merges the two streams; Swin Transformer and (multi-head) gMLP. We showed that our gSwin can achieve better accuracy on three vision tasks, image classification, object detection and semantic segmentation, than Swin Transformer, with smaller model size.