 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SegDiff: Image Segmentation with Diffusion Probabilistic Models
Dec 01, 2021
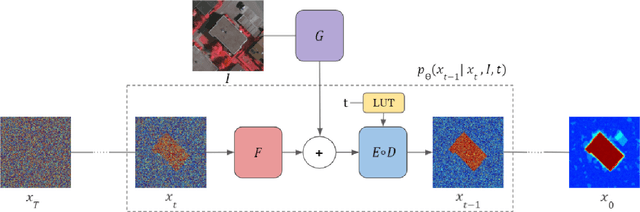
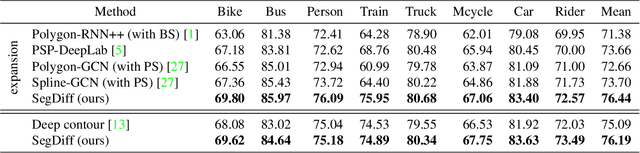

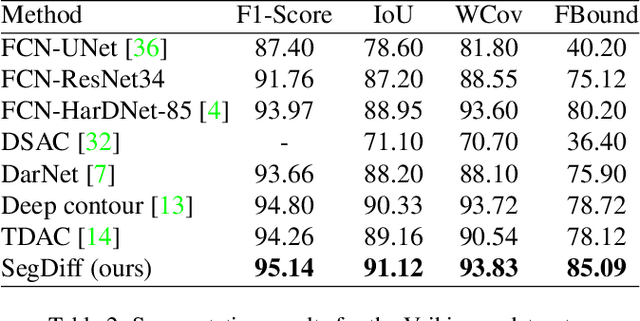
Diffusion Probabilistic Methods are employed for state-of-the-art image generation. In this work, we present a method for extending such models for performing image segmentation. The method learns end-to-end, without relying on a pre-trained backbone. The information in the input image and in the current estimation of the segmentation map is merged by summing the output of two encoders. Additional encoding layers and a decoder are then used to iteratively refine the segmentation map using a diffusion model. Since the diffusion model is probabilistic, it is applied multiple times and the results are merged into a final segmentation map. The new method obtains state-of-the-art results on the Cityscapes validation set, the Vaihingen building segmentation benchmark, and the MoNuSeg dataset.
Exploring Dual-task Correlation for Pose Guided Person Image Generation
Mar 06, 2022

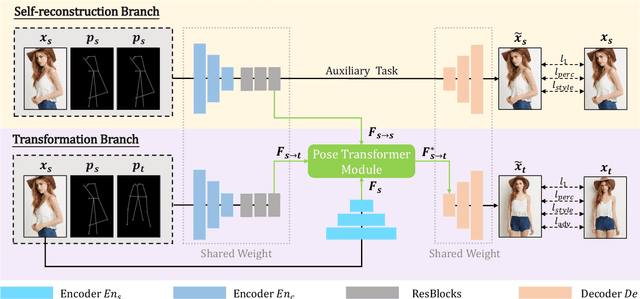
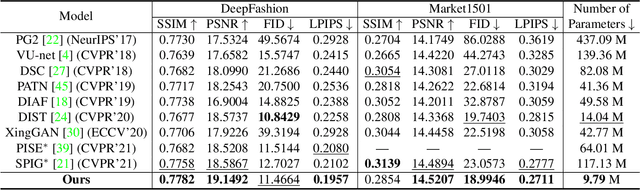
Pose Guided Person Image Generation (PGPIG) is the task of transforming a person image from the source pose to a given target pose. Most of the existing methods only focus on the ill-posed source-to-target task and fail to capture reasonable texture mapping. To address this problem, we propose a novel Dual-task Pose Transformer Network (DPTN), which introduces an auxiliary task (i.e., source-to-source task) and exploits the dual-task correlation to promote the performance of PGPIG. The DPTN is of a Siamese structure, containing a source-to-source self-reconstruction branch, and a transformation branch for source-to-target generation. By sharing partial weights between them, the knowledge learned by the source-to-source task can effectively assist the source-to-target learning. Furthermore, we bridge the two branches with a proposed Pose Transformer Module (PTM) to adaptively explore the correlation between features from dual tasks. Such correlation can establish the fine-grained mapping of all the pixels between the sources and the targets, and promote the source texture transmission to enhance the details of the generated target images. Extensive experiments show that our DPTN outperforms state-of-the-arts in terms of both PSNR and LPIPS. In addition, our DPTN only contains 9.79 million parameters, which is significantly smaller than other approaches. Our code is available at: https://github.com/PangzeCheung/Dual-task-Pose-Transformer-Network.
Towards Better Semantic Understanding of Mobile Interfaces
Oct 06, 2022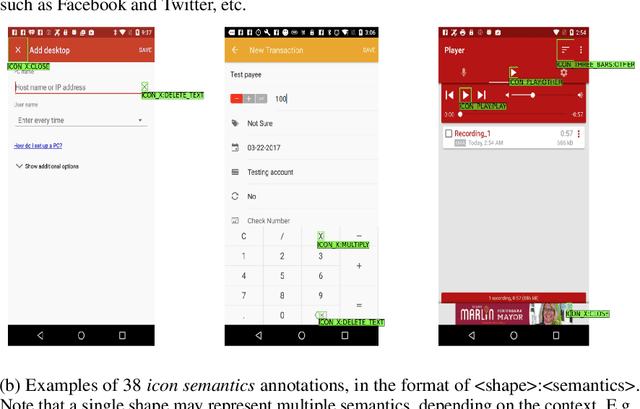

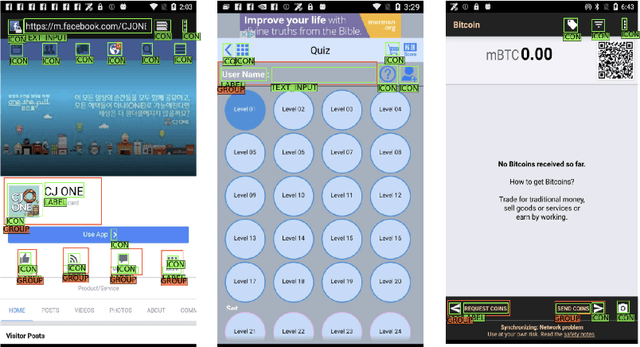

Improving the accessibility and automation capabilities of mobile devices can have a significant positive impact on the daily lives of countless users. To stimulate research in this direction, we release a human-annotated dataset with approximately 500k unique annotations aimed at increasing the understanding of the functionality of UI elements. This dataset augments images and view hierarchies from RICO, a large dataset of mobile UIs, with annotations for icons based on their shapes and semantics, and associations between different elements and their corresponding text labels, resulting in a significant increase in the number of UI elements and the categories assigned to them. We also release models using image-only and multimodal inputs; we experiment with various architectures and study the benefits of using multimodal inputs on the new dataset. Our models demonstrate strong performance on an evaluation set of unseen apps, indicating their generalizability to newer screens. These models, combined with the new dataset, can enable innovative functionalities like referring to UI elements by their labels, improved coverage and better semantics for icons etc., which would go a long way in making UIs more usable for everyone.
On Distillation of Guided Diffusion Models
Oct 06, 2022
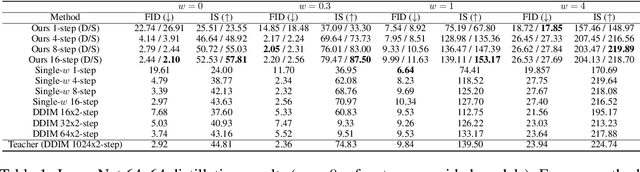
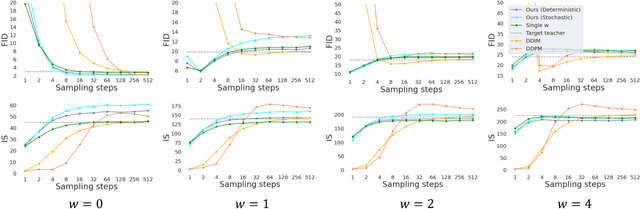
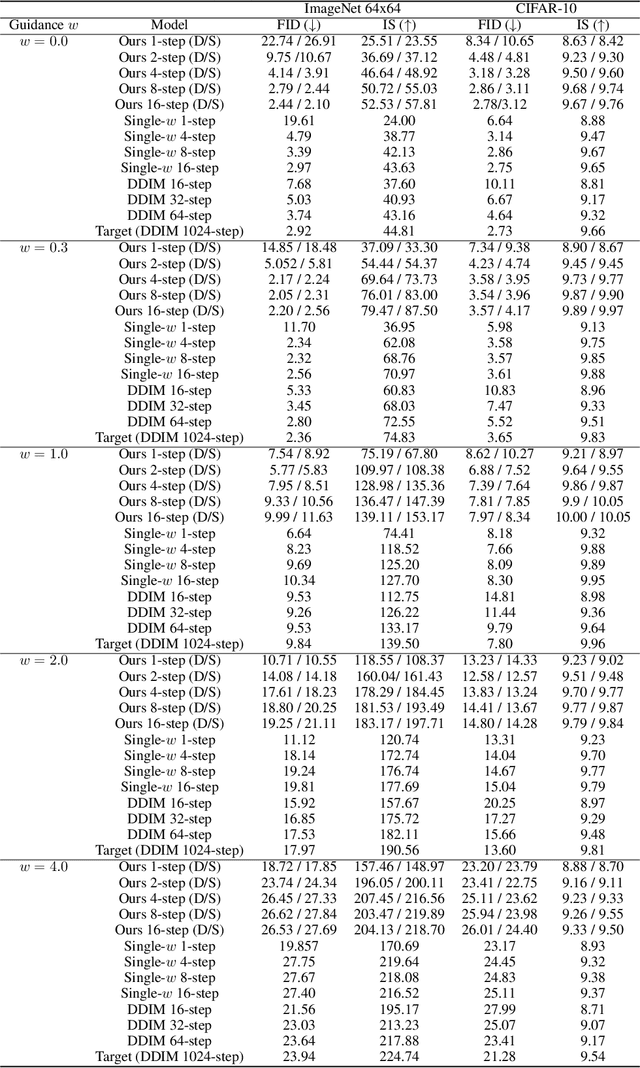
Classifier-free guided diffusion models have recently been shown to be highly effective at high-resolution image generation, and they have been widely used in large-scale diffusion frameworks including DALL-E 2, GLIDE and Imagen. However, a downside of classifier-free guided diffusion models is that they are computationally expensive at inference time since they require evaluating two diffusion models, a class-conditional model and an unconditional model, hundreds of times. To deal with this limitation, we propose an approach to distilling classifier-free guided diffusion models into models that are fast to sample from: Given a pre-trained classifier-free guided model, we first learn a single model to match the output of the combined conditional and unconditional models, and then progressively distill that model to a diffusion model that requires much fewer sampling steps. On ImageNet 64x64 and CIFAR-10, our approach is able to generate images visually comparable to that of the original model using as few as 4 sampling steps, achieving FID/IS scores comparable to that of the original model while being up to 256 times faster to sample from.
MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text
Oct 06, 2022

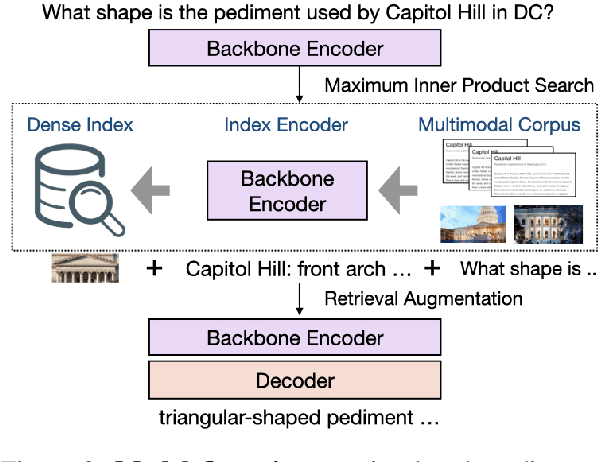
While language Models store a massive amount of world knowledge implicitly in their parameters, even very large models often fail to encode information about rare entities and events, while incurring huge computational costs. Recently, retrieval-augmented models, such as REALM, RAG, and RETRO, have incorporated world knowledge into language generation by leveraging an external non-parametric index and have demonstrated impressive performance with constrained model sizes. However, these methods are restricted to retrieving only textual knowledge, neglecting the ubiquitous amount of knowledge in other modalities like images -- much of which contains information not covered by any text. To address this limitation, we propose the first Multimodal Retrieval-Augmented Transformer (MuRAG), which accesses an external non-parametric multimodal memory to augment language generation. MuRAG is pre-trained with a mixture of large-scale image-text and text-only corpora using a joint contrastive and generative loss. We perform experiments on two different datasets that require retrieving and reasoning over both images and text to answer a given query: WebQA, and MultimodalQA. Our results show that MuRAG achieves state-of-the-art accuracy, outperforming existing models by 10-20\% absolute on both datasets and under both distractor and full-wiki settings.
Mask3D for 3D Semantic Instance Segmentation
Oct 06, 2022
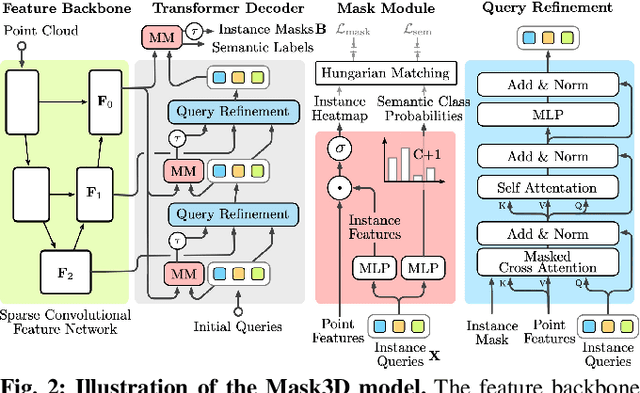
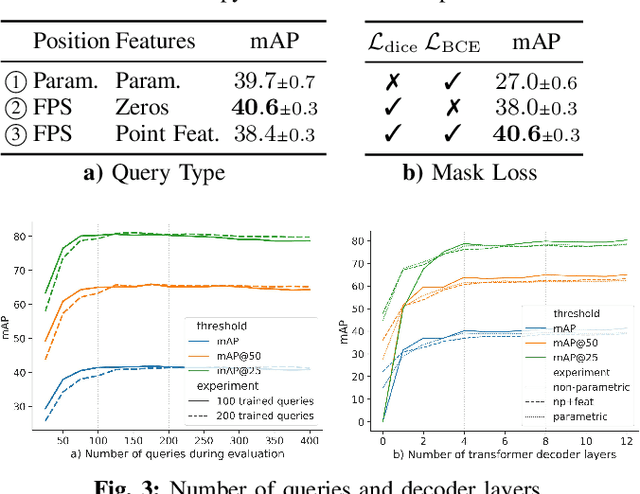
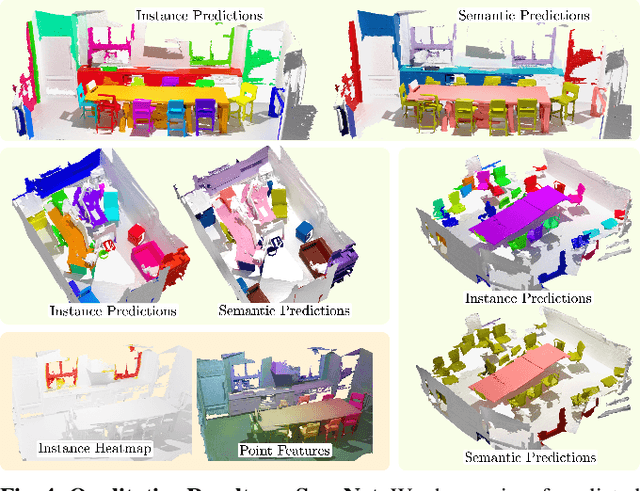
Modern 3D semantic instance segmentation approaches predominantly rely on specialized voting mechanisms followed by carefully designed geometric clustering techniques. Building on the successes of recent Transformer-based methods for object detection and image segmentation, we propose the first Transformer-based approach for 3D semantic instance segmentation. We show that we can leverage generic Transformer building blocks to directly predict instance masks from 3D point clouds. In our model called Mask3D each object instance is represented as an instance query. Using Transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. Mask3D has several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks. Mask3D sets a new state-of-the-art on ScanNet test (+6.2 mAP), S3DIS 6-fold (+10.1 mAP), STPLS3D (+11.2 mAP) and ScanNet200 test (+12.4 mAP).
Revisiting Global Statistics Aggregation for Improving Image Restoration
Dec 20, 2021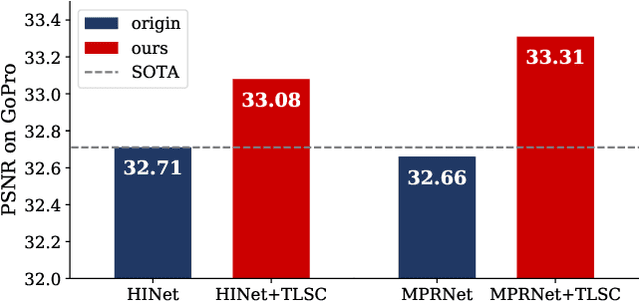
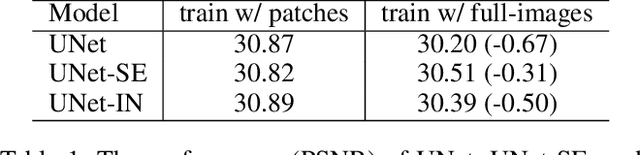
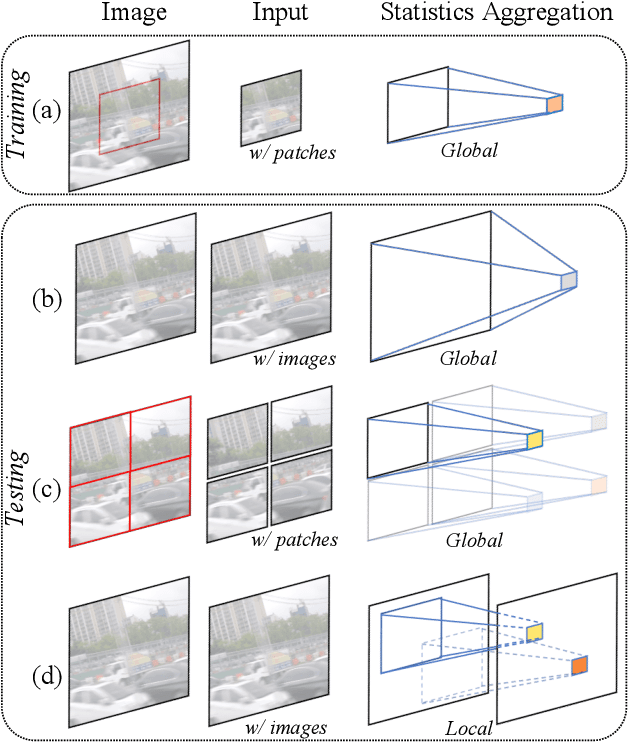
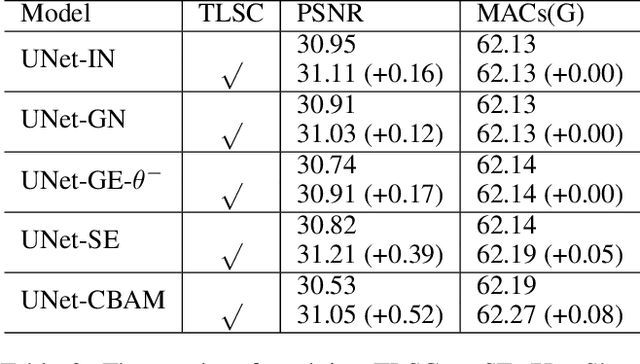
Global spatial statistics, which are aggregated along entire spatial dimensions, are widely used in top-performance image restorers. For example, mean, variance in Instance Normalization (IN) which is adopted by HINet, and global average pooling (i.e. mean) in Squeeze and Excitation (SE) which is applied to MPRNet. This paper first shows that statistics aggregated on the patches-based/entire-image-based feature in the training/testing phase respectively may distribute very differently and lead to performance degradation in image restorers. It has been widely overlooked by previous works. To solve this issue, we propose a simple approach, Test-time Local Statistics Converter (TLSC), that replaces the region of statistics aggregation operation from global to local, only in the test time. Without retraining or finetuning, our approach significantly improves the image restorer's performance. In particular, by extending SE with TLSC to the state-of-the-art models, MPRNet boost by 0.65 dB in PSNR on GoPro dataset, achieves 33.31 dB, exceeds the previous best result 0.6 dB. In addition, we simply apply TLSC to the high-level vision task, i.e. semantic segmentation, and achieves competitive results. Extensive quantity and quality experiments are conducted to demonstrate TLSC solves the issue with marginal costs while significant gain. The code is available at https://github.com/megvii-research/tlsc.
Compliance Challenges in Forensic Image Analysis Under the Artificial Intelligence Act
Mar 01, 2022In many applications of forensic image analysis, state-of-the-art results are nowadays achieved with machine learning methods. However, concerns about their reliability and opaqueness raise the question whether such methods can be used in criminal investigations. So far, this question of legal compliance has hardly been discussed, also because legal regulations for machine learning methods were not defined explicitly. To this end, the European Commission recently proposed the artificial intelligence (AI) act, a regulatory framework for the trustworthy use of AI. Under the draft AI act, high-risk AI systems for use in law enforcement are permitted but subject to compliance with mandatory requirements. In this paper, we review why the use of machine learning in forensic image analysis is classified as high-risk. We then summarize the mandatory requirements for high-risk AI systems and discuss these requirements in light of two forensic applications, license plate recognition and deep fake detection. The goal of this paper is to raise awareness of the upcoming legal requirements and to point out avenues for future research.
LSC-GAN: Latent Style Code Modeling for Continuous Image-to-image Translation
Oct 11, 2021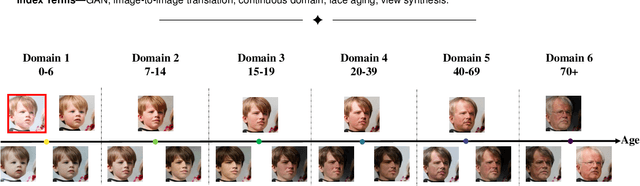

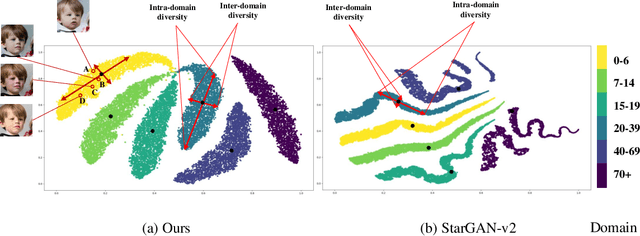
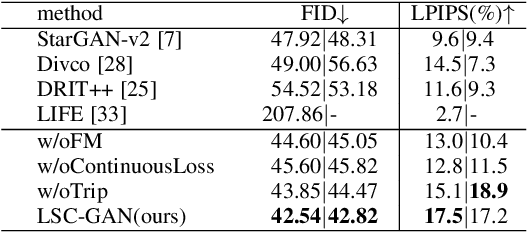
Image-to-image (I2I) translation is usually carried out among discrete domains. However, image domains, often corresponding to a physical value, are usually continuous. In other words, images gradually change with the value, and there exists no obvious gap between different domains. This paper intends to build the model for I2I translation among continuous varying domains. We first divide the whole domain coverage into discrete intervals, and explicitly model the latent style code for the center of each interval. To deal with continuous translation, we design the editing modules, changing the latent style code along two directions. These editing modules help to constrain the codes for domain centers during training, so that the model can better understand the relation among them. To have diverse results, the latent style code is further diversified with either the random noise or features from the reference image, giving the individual style code to the decoder for label-based or reference-based synthesis. Extensive experiments on age and viewing angle translation show that the proposed method can achieve high-quality results, and it is also flexible for users.
Creative Painting with Latent Diffusion Models
Sep 29, 2022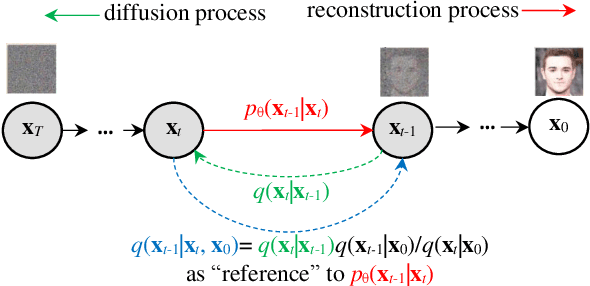
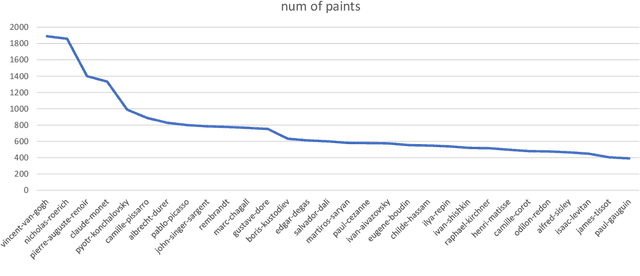
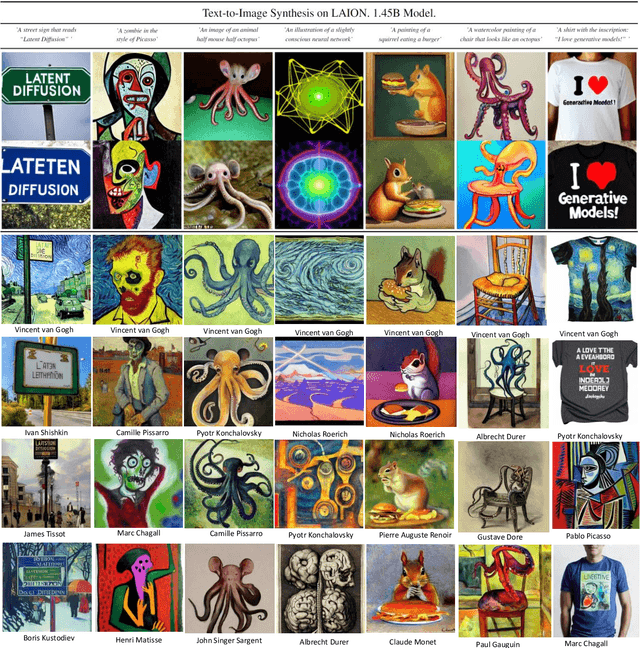
Artistic painting has achieved significant progress during recent years by applying hundreds of GAN variants. However, adversarial training has been reported to be notoriously unstable and can lead to mode collapse. Recently, diffusion models have achieved GAN-level sample quality without adversarial training. Using autoencoders to project the original images into compressed latent spaces and cross attention enhanced U-Net as the backbone of diffusion, latent diffusion models have achieved stable and high fertility image generation. In this paper, we focus on enhancing the creative painting ability of current latent diffusion models in two directions, textual condition extension and model retraining with Wikiart dataset. Through textual condition extension, users' input prompts are expanded in temporal and spacial directions for deeper understanding and explaining the prompts. Wikiart dataset contains 80K famous artworks drawn during recent 400 years by more than 1,000 famous artists in rich styles and genres. Through the retraining, we are able to ask these artists to draw novel and creative painting on modern topics.