 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
When do Convolutional Neural Networks Stop Learning?
Mar 04, 2024
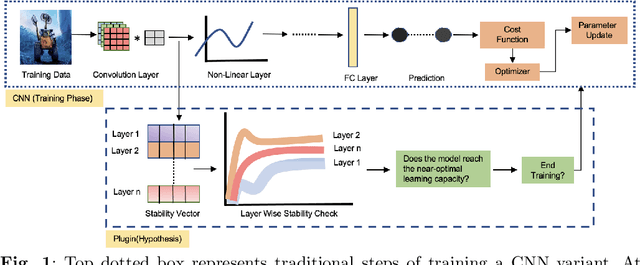
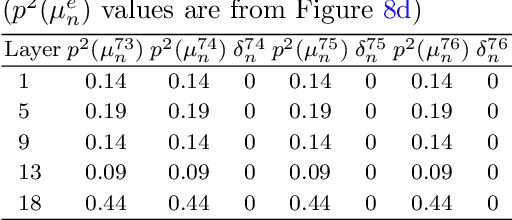
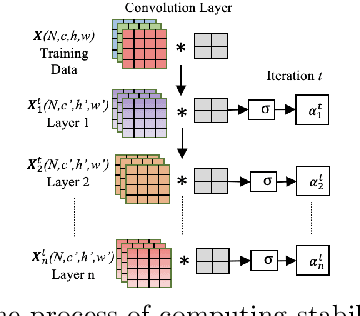
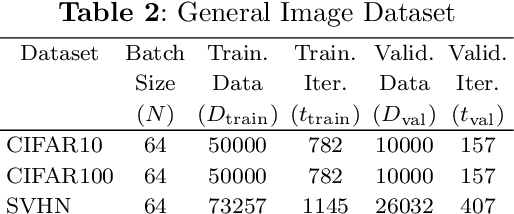
Convolutional Neural Networks (CNNs) have demonstrated outstanding performance in computer vision tasks such as image classification, detection, segmentation, and medical image analysis. In general, an arbitrary number of epochs is used to train such neural networks. In a single epoch, the entire training data -- divided by batch size -- are fed to the network. In practice, validation error with training loss is used to estimate the neural network's generalization, which indicates the optimal learning capacity of the network. Current practice is to stop training when the training loss decreases and the gap between training and validation error increases (i.e., the generalization gap) to avoid overfitting. However, this is a trial-and-error-based approach which raises a critical question: Is it possible to estimate when neural networks stop learning based on training data? This research work introduces a hypothesis that analyzes the data variation across all the layers of a CNN variant to anticipate its near-optimal learning capacity. In the training phase, we use our hypothesis to anticipate the near-optimal learning capacity of a CNN variant without using any validation data. Our hypothesis can be deployed as a plug-and-play to any existing CNN variant without introducing additional trainable parameters to the network. We test our hypothesis on six different CNN variants and three different general image datasets (CIFAR10, CIFAR100, and SVHN). The result based on these CNN variants and datasets shows that our hypothesis saves 58.49\% of computational time (on average) in training. We further conduct our hypothesis on ten medical image datasets and compared with the MedMNIST-V2 benchmark. Based on our experimental result, we save $\approx$ 44.1\% of computational time without losing accuracy against the MedMNIST-V2 benchmark.
Rethinking cluster-conditioned diffusion models
Mar 01, 2024
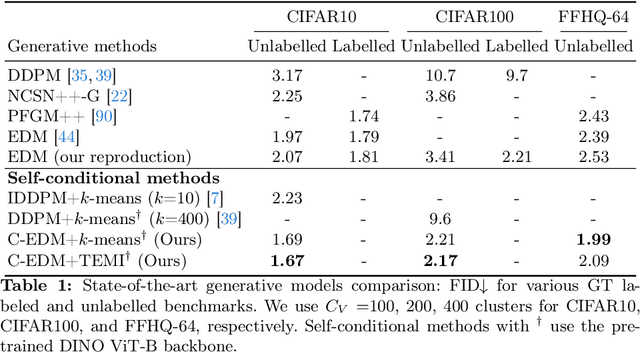
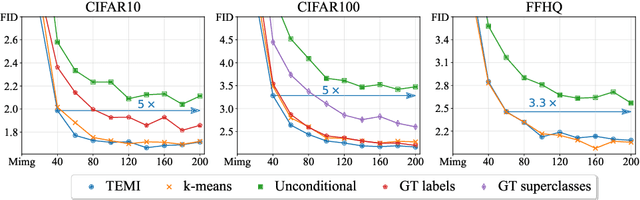
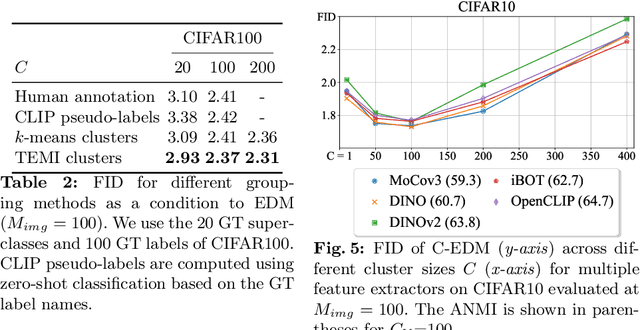
We present a comprehensive experimental study on image-level conditioning for diffusion models using cluster assignments. We elucidate how individual components regarding image clustering impact image synthesis across three datasets. By combining recent advancements from image clustering and diffusion models, we show that, given the optimal cluster granularity with respect to image synthesis (visual groups), cluster-conditioning can achieve state-of-the-art FID (i.e. 1.67, 2.17 on CIFAR10 and CIFAR100 respectively), while attaining a strong training sample efficiency. Finally, we propose a novel method to derive an upper cluster bound that reduces the search space of the visual groups using solely feature-based clustering. Unlike existing approaches, we find no significant connection between clustering and cluster-conditional image generation. The code and cluster assignments will be released.
Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Mar 04, 2024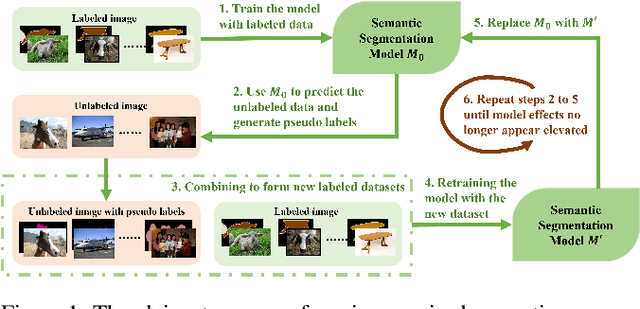
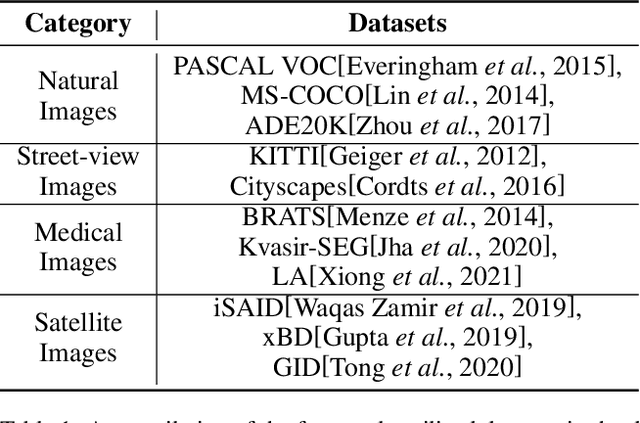
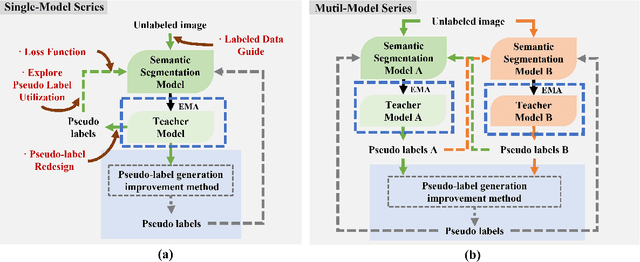
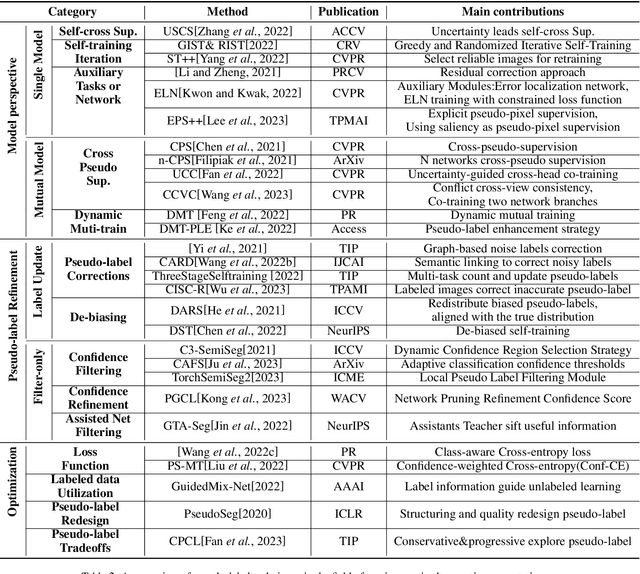
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.
Diffusion Model Based Visual Compensation Guidance and Visual Difference Analysis for No-Reference Image Quality Assessment
Feb 22, 2024Existing free-energy guided No-Reference Image Quality Assessment (NR-IQA) methods still suffer from finding a balance between learning feature information at the pixel level of the image and capturing high-level feature information and the efficient utilization of the obtained high-level feature information remains a challenge. As a novel class of state-of-the-art (SOTA) generative model, the diffusion model exhibits the capability to model intricate relationships, enabling a comprehensive understanding of images and possessing a better learning of both high-level and low-level visual features. In view of these, we pioneer the exploration of the diffusion model into the domain of NR-IQA. Firstly, we devise a new diffusion restoration network that leverages the produced enhanced image and noise-containing images, incorporating nonlinear features obtained during the denoising process of the diffusion model, as high-level visual information. Secondly, two visual evaluation branches are designed to comprehensively analyze the obtained high-level feature information. These include the visual compensation guidance branch, grounded in the transformer architecture and noise embedding strategy, and the visual difference analysis branch, built on the ResNet architecture and the residual transposed attention block. Extensive experiments are conducted on seven public NR-IQA datasets, and the results demonstrate that the proposed model outperforms SOTA methods for NR-IQA.
Noise Level Adaptive Diffusion Model for Robust Reconstruction of Accelerated MRI
Mar 08, 2024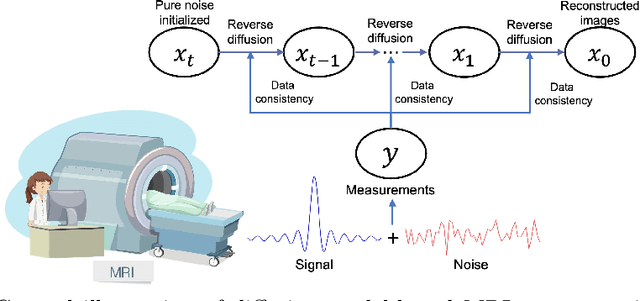
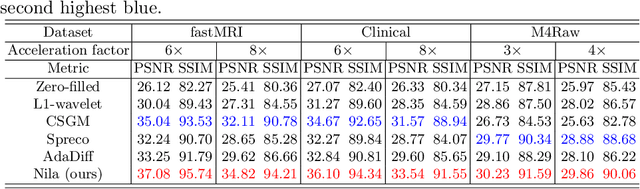
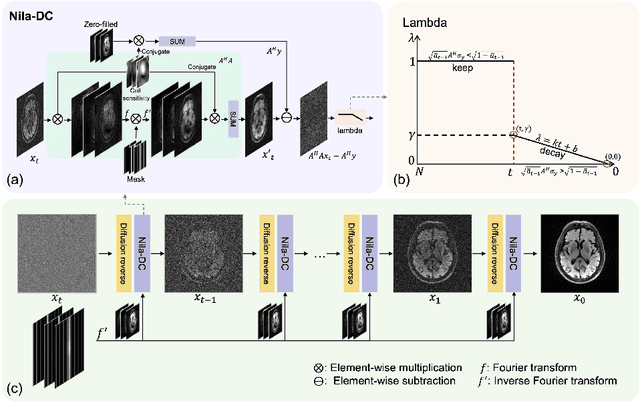
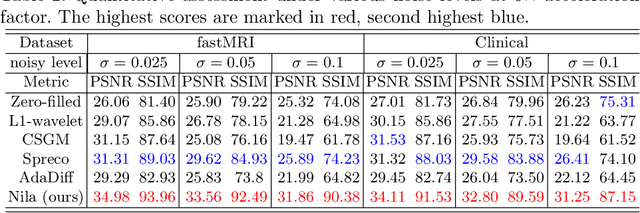
In general, diffusion model-based MRI reconstruction methods incrementally remove artificially added noise while imposing data consistency to reconstruct the underlying images. However, real-world MRI acquisitions already contain inherent noise due to thermal fluctuations. This phenomenon is particularly notable when using ultra-fast, high-resolution imaging sequences for advanced research, or using low-field systems favored by low- and middle-income countries. These common scenarios can lead to sub-optimal performance or complete failure of existing diffusion model-based reconstruction techniques. Specifically, as the artificially added noise is gradually removed, the inherent MRI noise becomes increasingly pronounced, making the actual noise level inconsistent with the predefined denoising schedule and consequently inaccurate image reconstruction. To tackle this problem, we propose a posterior sampling strategy with a novel NoIse Level Adaptive Data Consistency (Nila-DC) operation. Extensive experiments are conducted on two public datasets and an in-house clinical dataset with field strength ranging from 0.3T to 3T, showing that our method surpasses the state-of-the-art MRI reconstruction methods, and is highly robust against various noise levels. The code will be released after review.
DiffClass: Diffusion-Based Class Incremental Learning
Mar 08, 2024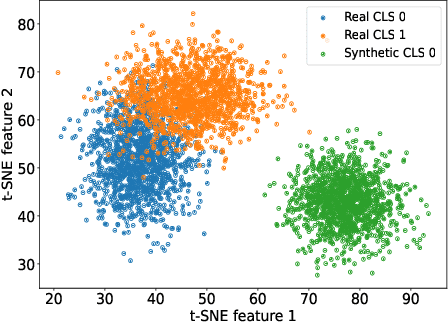
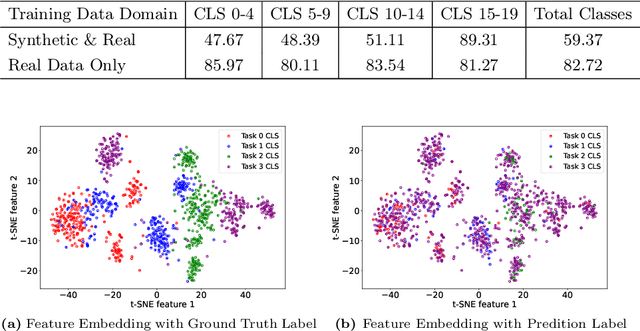
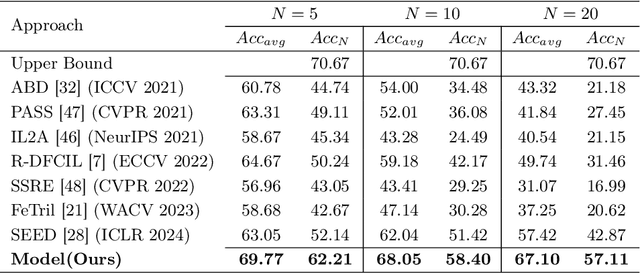
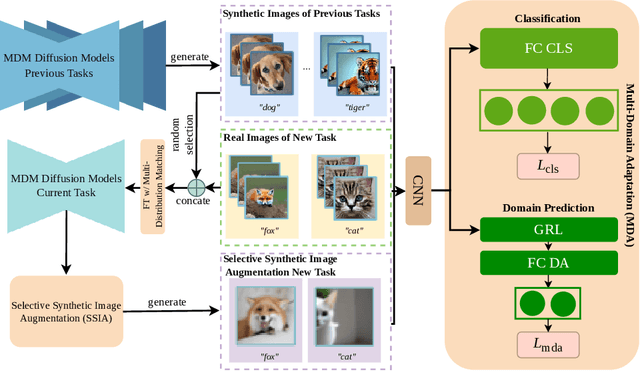
Class Incremental Learning (CIL) is challenging due to catastrophic forgetting. On top of that, Exemplar-free Class Incremental Learning is even more challenging due to forbidden access to previous task data. Recent exemplar-free CIL methods attempt to mitigate catastrophic forgetting by synthesizing previous task data. However, they fail to overcome the catastrophic forgetting due to the inability to deal with the significant domain gap between real and synthetic data. To overcome these issues, we propose a novel exemplar-free CIL method. Our method adopts multi-distribution matching (MDM) diffusion models to unify quality and bridge domain gaps among all domains of training data. Moreover, our approach integrates selective synthetic image augmentation (SSIA) to expand the distribution of the training data, thereby improving the model's plasticity and reinforcing the performance of our method's ultimate component, multi-domain adaptation (MDA). With the proposed integrations, our method then reformulates exemplar-free CIL into a multi-domain adaptation problem to implicitly address the domain gap problem to enhance model stability during incremental training. Extensive experiments on benchmark class incremental datasets and settings demonstrate that our method excels previous exemplar-free CIL methods and achieves state-of-the-art performance.
Finding Waldo: Towards Efficient Exploration of NeRF Scene Spaces
Mar 08, 2024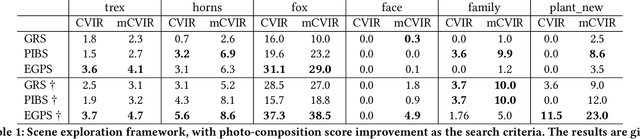

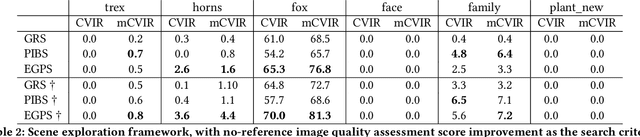

Neural Radiance Fields (NeRF) have quickly become the primary approach for 3D reconstruction and novel view synthesis in recent years due to their remarkable performance. Despite the huge interest in NeRF methods, a practical use case of NeRFs has largely been ignored; the exploration of the scene space modelled by a NeRF. In this paper, for the first time in the literature, we propose and formally define the scene exploration framework as the efficient discovery of NeRF model inputs (i.e. coordinates and viewing angles), using which one can render novel views that adhere to user-selected criteria. To remedy the lack of approaches addressing scene exploration, we first propose two baseline methods called Guided-Random Search (GRS) and Pose Interpolation-based Search (PIBS). We then cast scene exploration as an optimization problem, and propose the criteria-agnostic Evolution-Guided Pose Search (EGPS) for efficient exploration. We test all three approaches with various criteria (e.g. saliency maximization, image quality maximization, photo-composition quality improvement) and show that our EGPS performs more favourably than other baselines. We finally highlight key points and limitations, and outline directions for future research in scene exploration.
PIPsUS: Self-Supervised Dense Point Tracking in Ultrasound
Mar 08, 2024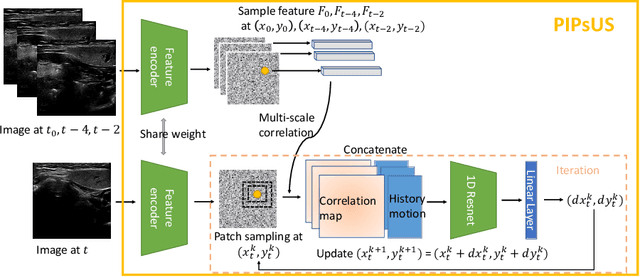
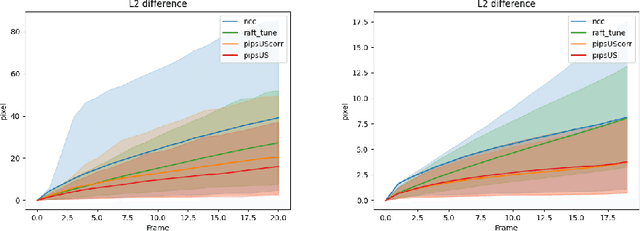
Finding point-level correspondences is a fundamental problem in ultrasound (US), since it can enable US landmark tracking for intraoperative image guidance in different surgeries, including head and neck. Most existing US tracking methods, e.g., those based on optical flow or feature matching, were initially designed for RGB images before being applied to US. Therefore domain shift can impact their performance. Training could be supervised by ground-truth correspondences, but these are expensive to acquire in US. To solve these problems, we propose a self-supervised pixel-level tracking model called PIPsUS. Our model can track an arbitrary number of points in one forward pass and exploits temporal information by considering multiple, instead of just consecutive, frames. We developed a new self-supervised training strategy that utilizes a long-term point-tracking model trained for RGB images as a teacher to guide the model to learn realistic motions and use data augmentation to enforce tracking from US appearance. We evaluate our method on neck and oral US and echocardiography, showing higher point tracking accuracy when compared with fast normalized cross-correlation and tuned optical flow. Code will be available once the paper is accepted.
Explainable Face Verification via Feature-Guided Gradient Backpropagation
Mar 07, 2024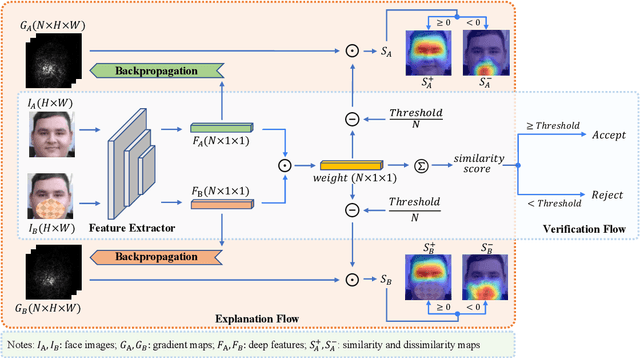
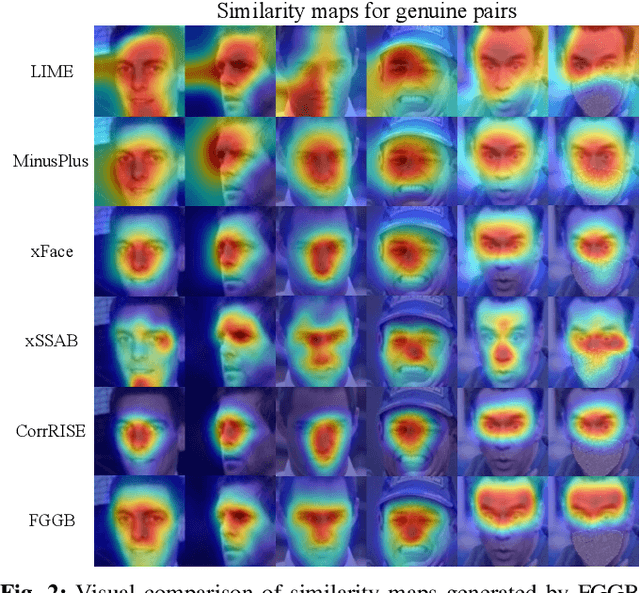
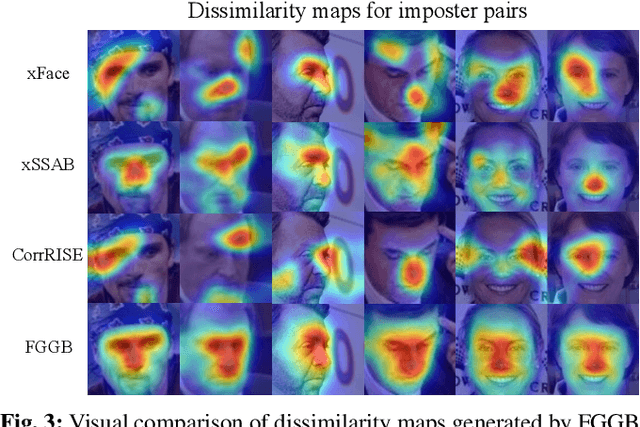
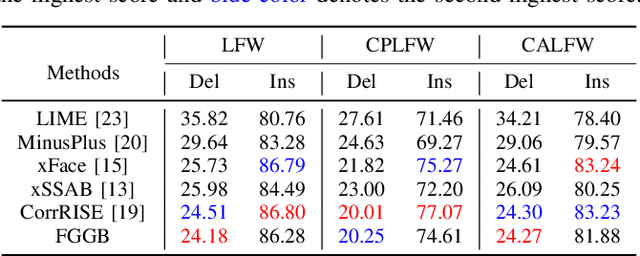
Recent years have witnessed significant advancement in face recognition (FR) techniques, with their applications widely spread in people's lives and security-sensitive areas. There is a growing need for reliable interpretations of decisions of such systems. Existing studies relying on various mechanisms have investigated the usage of saliency maps as an explanation approach, but suffer from different limitations. This paper first explores the spatial relationship between face image and its deep representation via gradient backpropagation. Then a new explanation approach FGGB has been conceived, which provides precise and insightful similarity and dissimilarity saliency maps to explain the "Accept" and "Reject" decision of an FR system. Extensive visual presentation and quantitative measurement have shown that FGGB achieves superior performance in both similarity and dissimilarity maps when compared to current state-of-the-art explainable face verification approaches.
Popeye: A Unified Visual-Language Model for Multi-Source Ship Detection from Remote Sensing Imagery
Mar 06, 2024
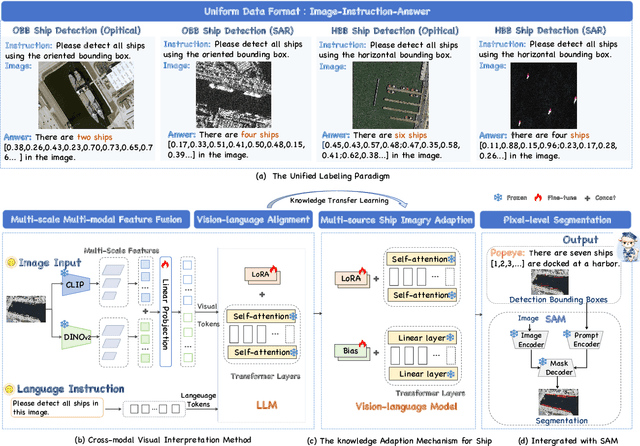

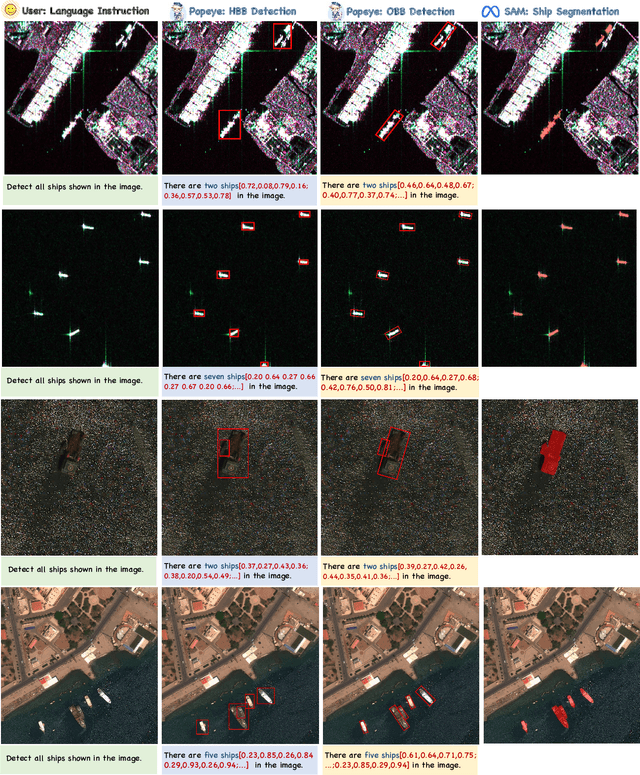
Ship detection needs to identify ship locations from remote sensing (RS) scenes. However, due to different imaging payloads, various appearances of ships, and complicated background interference from the bird's eye view, it is difficult to set up a unified paradigm for achieving multi-source ship detection. Therefore, in this article, considering that the large language models (LLMs) emerge the powerful generalization ability, a novel unified visual-language model called Popeye is proposed for multi-source ship detection from RS imagery. First, to bridge the interpretation gap between multi-source images for ship detection, a novel image-instruction-answer way is designed to integrate the various ship detection ways (e.g., horizontal bounding box (HBB), oriented bounding box (OBB)) into a unified labeling paradigm. Then, in view of this, a cross-modal image interpretation method is developed for the proposed Popeye to enhance interactive comprehension ability between visual and language content, which can be easily migrated into any multi-source ship detection task. Subsequently, owing to objective domain differences, a knowledge adaption mechanism is designed to adapt the pre-trained visual-language knowledge from the nature scene into the RS domain for multi-source ship detection. In addition, the segment anything model (SAM) is also seamlessly integrated into the proposed Popeye to achieve pixel-level ship segmentation without additional training costs. Finally, extensive experiments are conducted on the newly constructed instruction dataset named MMShip, and the results indicate that the proposed Popeye outperforms current specialist, open-vocabulary, and other visual-language models for zero-shot multi-source ship detection.