 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Development of an algorithm for medical image segmentation of bone tissue in interaction with metallic implants
Apr 22, 2022
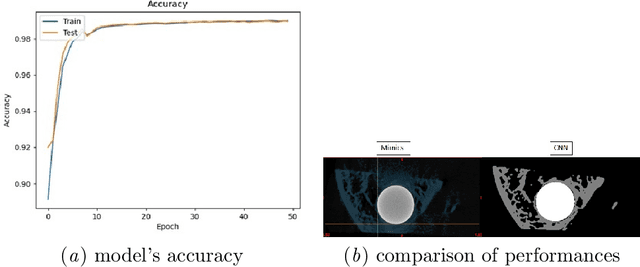
This preliminary study focuses on the development of a medical image segmentation algorithm based on artificial intelligence for calculating bone growth in contact with metallic implants. %as a result of the problem of estimating the growth of new bone tissue due to artifacts. %the presence of various types of distortions and errors, known as artifacts. Two databases consisting of computerized microtomography images have been used throughout this work: 100 images for training and 196 images for testing. Both bone and implant tissue were manually segmented in the training data set. The type of network constructed follows the U-Net architecture, a convolutional neural network explicitly used for medical image segmentation. In terms of network accuracy, the model reached around 98\%. Once the prediction was obtained from the new data set (test set), the total number of pixels belonging to bone tissue was calculated. This volume is around 15\% of the volume estimated by conventional techniques, which are usually overestimated. This method has shown its good performance and results, although it has a wide margin for improvement, modifying various parameters of the networks or using larger databases to improve training.
Multiple Convex Objects Image Segmentation via Proximal Alternating Direction Method of Multipliers
Mar 22, 2022
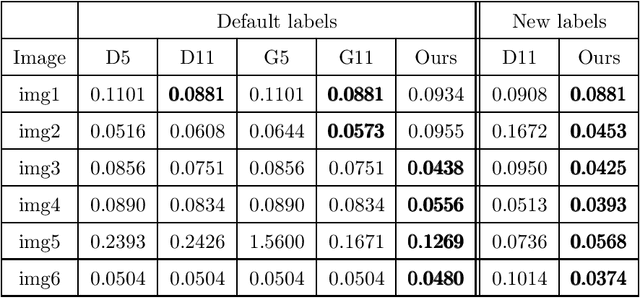

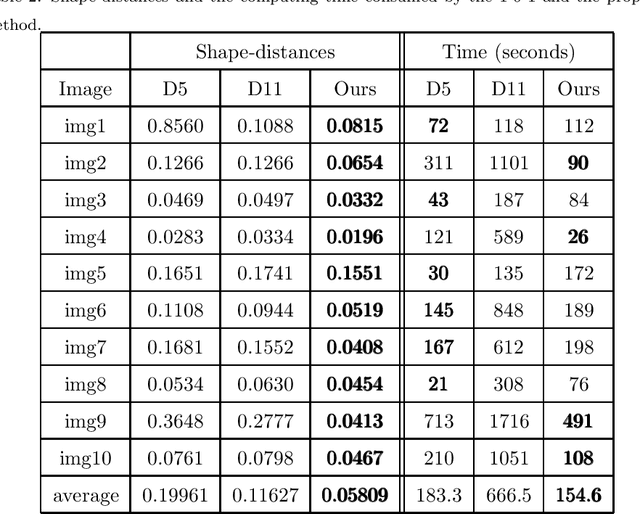
This paper focuses on the issue of image segmentation with convex shape prior. Firstly, we use binary function to represent convex object(s). The convex shape prior turns out to be a simple quadratic inequality constraint on the binary indicator function associated with each object. An image segmentation model incorporating convex shape prior into a probability-based method is proposed. Secondly, a new algorithm is designed to solve involved optimization problem, which is a challenging task because of the quadratic inequality constraint. To tackle this difficulty, we relax and linearize the quadratic inequality constraint to reduce it to solve a sequence of convex minimization problems. For each convex problem, an efficient proximal alternating direction method of multipliers is developed to solve it. The convergence of the algorithm follows some existing results in the optimization literature. Moreover, an interactive procedure is introduced to improve the accuracy of segmentation gradually. Numerical experiments on natural and medical images demonstrate that the proposed method is superior to some existing methods in terms of segmentation accuracy and computational time.
PriorNet: lesion segmentation in PET-CT including prior tumor appearance information
Oct 05, 2022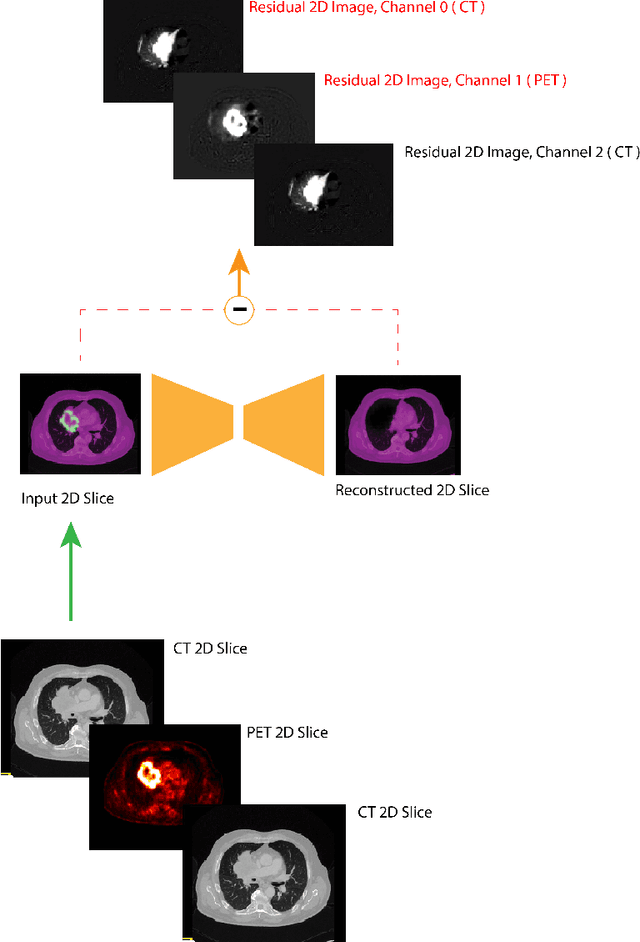
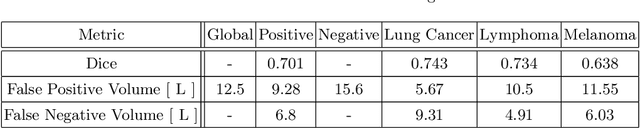
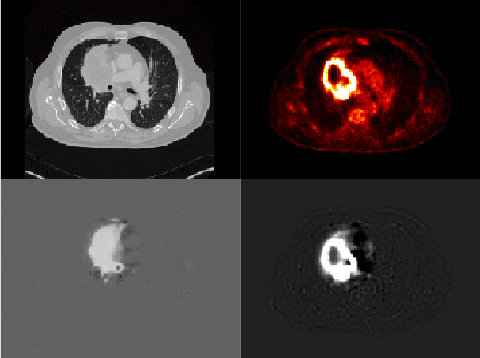
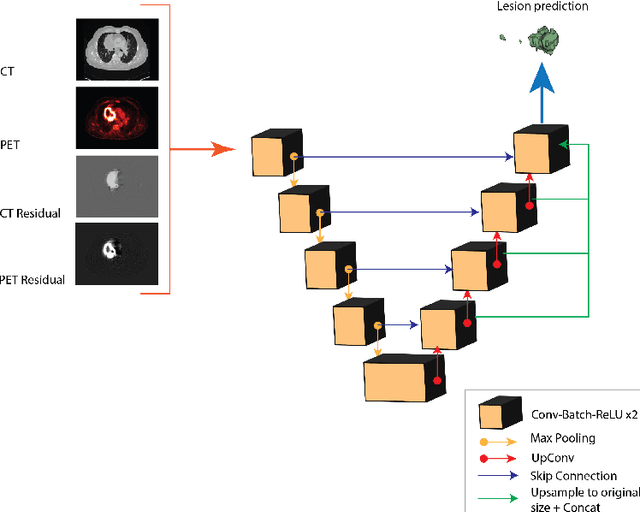
Tumor segmentation in PET-CT images is challenging due to the dual nature of the acquired information: low metabolic information in CT and low spatial resolution in PET. U-Net architecture is the most common and widely recognized approach when developing a fully automatic image segmentation method in the medical field. We proposed a two-step approach, aiming to refine and improve the segmentation performances of tumoral lesions in PET-CT. The first step generates a prior tumor appearance map from the PET-CT volumes, regarded as prior tumor information. The second step, consisting of a standard U-Net, receives the prior tumor appearance map and PET-CT images to generate the lesion mask. We evaluated the method on the 1014 cases available for the AutoPET 2022 challenge, and the results showed an average Dice score of 0.701 on the positive cases.
Enhance the Visual Representation via Discrete Adversarial Training
Sep 16, 2022Adversarial Training (AT), which is commonly accepted as one of the most effective approaches defending against adversarial examples, can largely harm the standard performance, thus has limited usefulness on industrial-scale production and applications. Surprisingly, this phenomenon is totally opposite in Natural Language Processing (NLP) task, where AT can even benefit for generalization. We notice the merit of AT in NLP tasks could derive from the discrete and symbolic input space. For borrowing the advantage from NLP-style AT, we propose Discrete Adversarial Training (DAT). DAT leverages VQGAN to reform the image data to discrete text-like inputs, i.e. visual words. Then it minimizes the maximal risk on such discrete images with symbolic adversarial perturbations. We further give an explanation from the perspective of distribution to demonstrate the effectiveness of DAT. As a plug-and-play technique for enhancing the visual representation, DAT achieves significant improvement on multiple tasks including image classification, object detection and self-supervised learning. Especially, the model pre-trained with Masked Auto-Encoding (MAE) and fine-tuned by our DAT without extra data can get 31.40 mCE on ImageNet-C and 32.77% top-1 accuracy on Stylized-ImageNet, building the new state-of-the-art. The code will be available at https://github.com/alibaba/easyrobust.
Partitioning Image Representation in Contrastive Learning
Mar 20, 2022
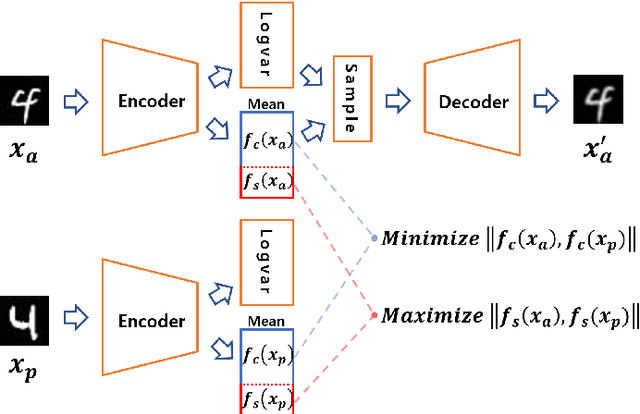
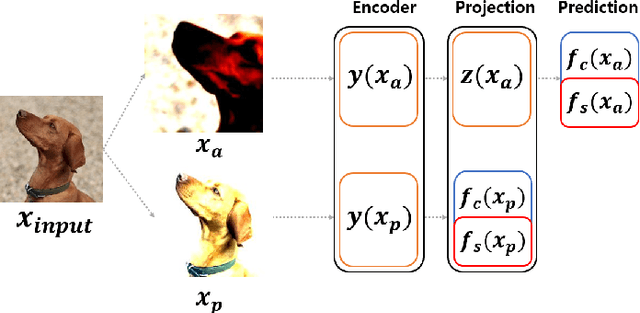
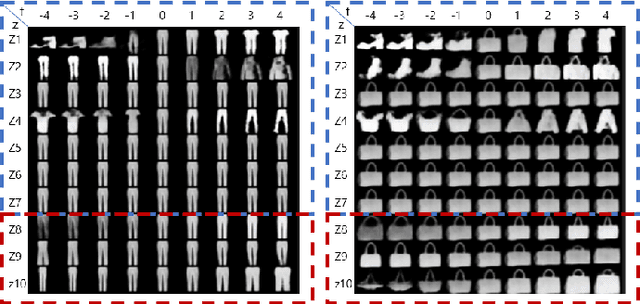
In contrastive learning in the image domain, the anchor and positive samples are forced to have as close representations as possible. However, forcing the two samples to have the same representation could be misleading because the data augmentation techniques make the two samples different. In this paper, we introduce a new representation, partitioned representation, which can learn both common and unique features of the anchor and positive samples in contrastive learning. The partitioned representation consists of two parts: the content part and the style part. The content part represents common features of the class, and the style part represents the own features of each sample, which can lead to the representation of the data augmentation method. We can achieve the partitioned representation simply by decomposing a loss function of contrastive learning into two terms on the two separate representations, respectively. To evaluate our representation with two parts, we take two framework models: Variational AutoEncoder (VAE) and BootstrapYour Own Latent(BYOL) to show the separability of content and style, and to confirm the generalization ability in classification, respectively. Based on the experiments, we show that our approach can separate two types of information in the VAE framework and outperforms the conventional BYOL in linear separability and a few-shot learning task as downstream tasks.
Unsupervised Cross-Modality Domain Adaptation for Vestibular Schwannoma Segmentation and Koos Grade Prediction based on Semi-Supervised Contrastive Learning
Oct 09, 2022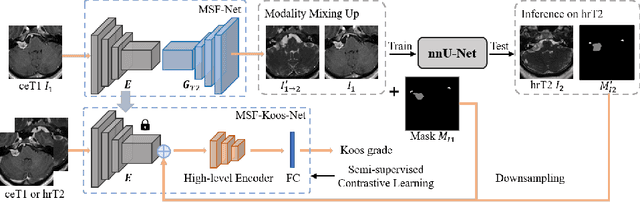

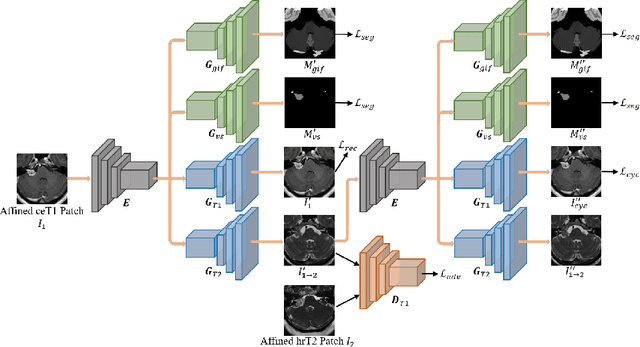
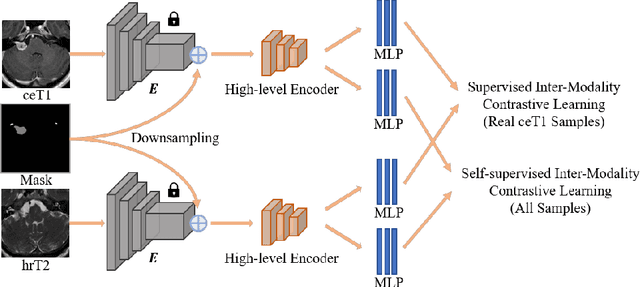
Domain adaptation has been widely adopted to transfer styles across multi-vendors and multi-centers, as well as to complement the missing modalities. In this challenge, we proposed an unsupervised domain adaptation framework for cross-modality vestibular schwannoma (VS) and cochlea segmentation and Koos grade prediction. We learn the shared representation from both ceT1 and hrT2 images and recover another modality from the latent representation, and we also utilize proxy tasks of VS segmentation and brain parcellation to restrict the consistency of image structures in domain adaptation. After generating missing modalities, the nnU-Net model is utilized for VS and cochlea segmentation, while a semi-supervised contrastive learning pre-train approach is employed to improve the model performance for Koos grade prediction. On CrossMoDA validation phase Leaderboard, our method received rank 4 in task1 with a mean Dice score of 0.8394 and rank 2 in task2 with Macro-Average Mean Square Error of 0.3941. Our code is available at https://github.com/fiy2W/cmda2022.superpolymerization.
Grounded Language-Image Pre-training
Dec 07, 2021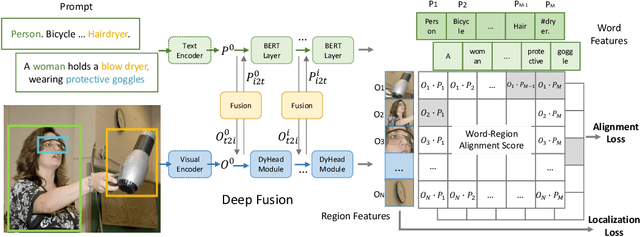
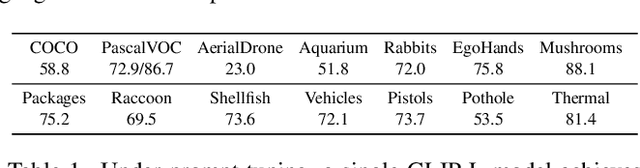
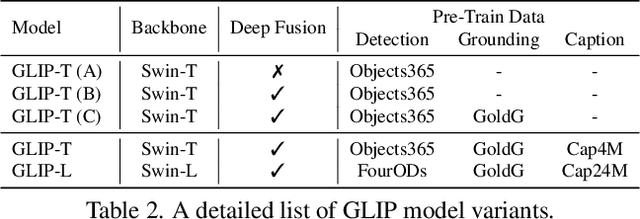
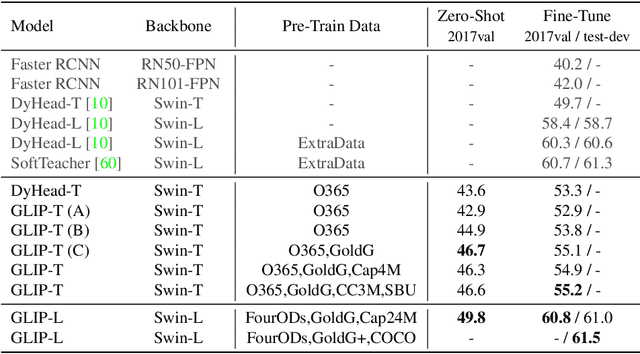
This paper presents a grounded language-image pre-training (GLIP) model for learning object-level, language-aware, and semantic-rich visual representations. GLIP unifies object detection and phrase grounding for pre-training. The unification brings two benefits: 1) it allows GLIP to learn from both detection and grounding data to improve both tasks and bootstrap a good grounding model; 2) GLIP can leverage massive image-text pairs by generating grounding boxes in a self-training fashion, making the learned representation semantic-rich. In our experiments, we pre-train GLIP on 27M grounding data, including 3M human-annotated and 24M web-crawled image-text pairs. The learned representations demonstrate strong zero-shot and few-shot transferability to various object-level recognition tasks. 1) When directly evaluated on COCO and LVIS (without seeing any images in COCO during pre-training), GLIP achieves 49.8 AP and 26.9 AP, respectively, surpassing many supervised baselines. 2) After fine-tuned on COCO, GLIP achieves 60.8 AP on val and 61.5 AP on test-dev, surpassing prior SoTA. 3) When transferred to 13 downstream object detection tasks, a 1-shot GLIP rivals with a fully-supervised Dynamic Head. Code will be released at https://github.com/microsoft/GLIP.
Sub-aperture SAR Imaging with Uncertainty Quantification
Aug 25, 2022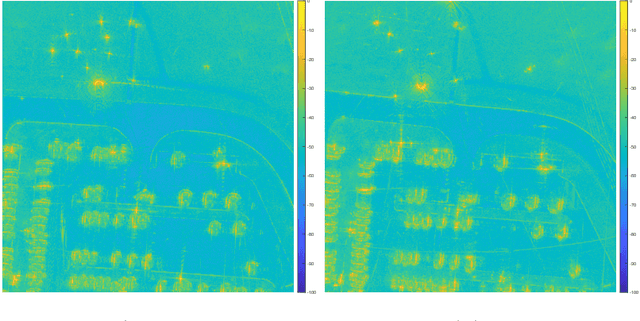
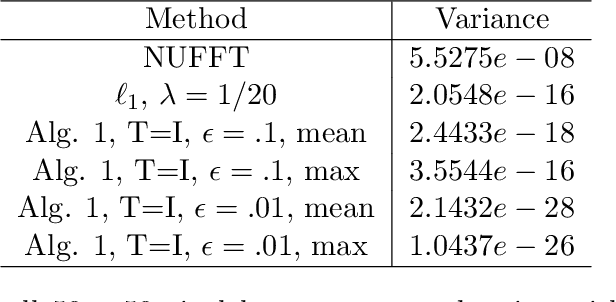
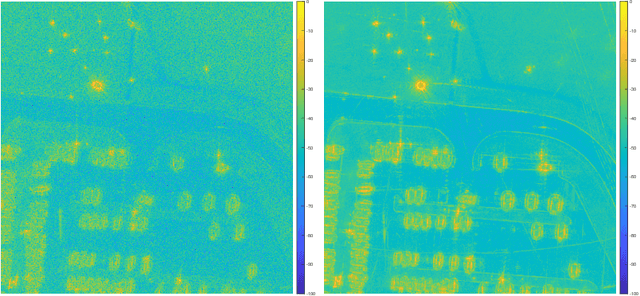
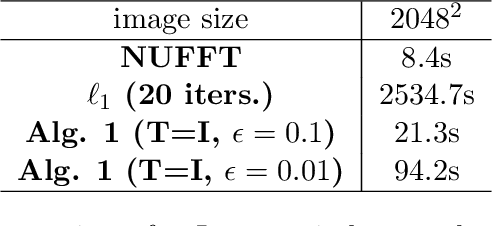
In the problem of spotlight mode airborne synthetic aperture radar (SAR) image formation, it is well-known that data collected over a wide azimuthal angle violate the isotropic scattering property typically assumed. Many techniques have been proposed to account for this issue, including both full-aperture and sub-aperture methods based on filtering, regularized least squares, and Bayesian methods. A full-aperture method that uses a hierarchical Bayesian prior to incorporate appropriate speckle modeling and reduction was recently introduced to produce samples of the posterior density rather than a single image estimate. This uncertainty quantification information is more robust as it can generate a variety of statistics for the scene. As proposed, the method was not well-suited for large problems, however, as the sampling was inefficient. Moreover, the method was not explicitly designed to mitigate the effects of the faulty isotropic scattering assumption. In this work we therefore propose a new sub-aperture SAR imaging method that uses a sparse Bayesian learning-type algorithm to more efficiently produce approximate posterior densities for each sub-aperture window. These estimates may be useful in and of themselves, or when of interest, the statistics from these distributions can be combined to form a composite image. Furthermore, unlike the often-employed lp-regularized least squares methods, no user-defined parameters are required. Application-specific adjustments are made to reduce the typically burdensome runtime and storage requirements so that appropriately large images can be generated. Finally, this paper focuses on incorporating these techniques into SAR image formation process. That is, for the problem starting with SAR phase history data, so that no additional processing errors are incurred.
Low-Dose CT Using Denoising Diffusion Probabilistic Model for 20$\times$ Speedup
Sep 29, 2022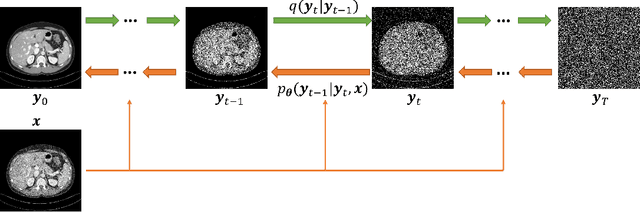
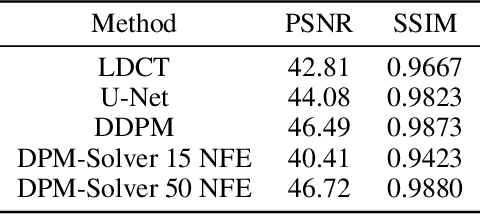
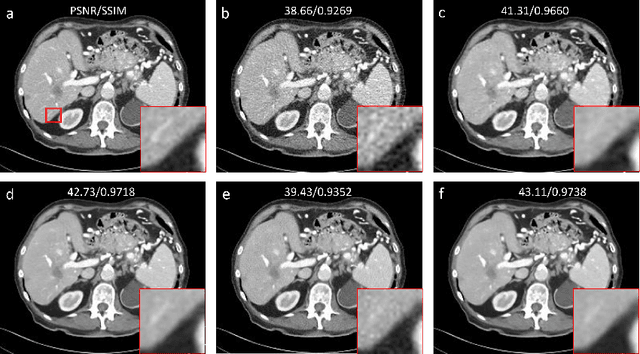

Low-dose computed tomography (LDCT) is an important topic in the field of radiology over the past decades. LDCT reduces ionizing radiation-induced patient health risks but it also results in a low signal-to-noise ratio (SNR) and a potential compromise in the diagnostic performance. In this paper, to improve the LDCT denoising performance, we introduce the conditional denoising diffusion probabilistic model (DDPM) and show encouraging results with a high computational efficiency. Specifically, given the high sampling cost of the original DDPM model, we adapt the fast ordinary differential equation (ODE) solver for a much-improved sampling efficiency. The experiments show that the accelerated DDPM can achieve 20x speedup without compromising image quality.
TRADE: Object Tracking with 3D Trajectory and Ground Depth Estimates for UAVs
Oct 07, 2022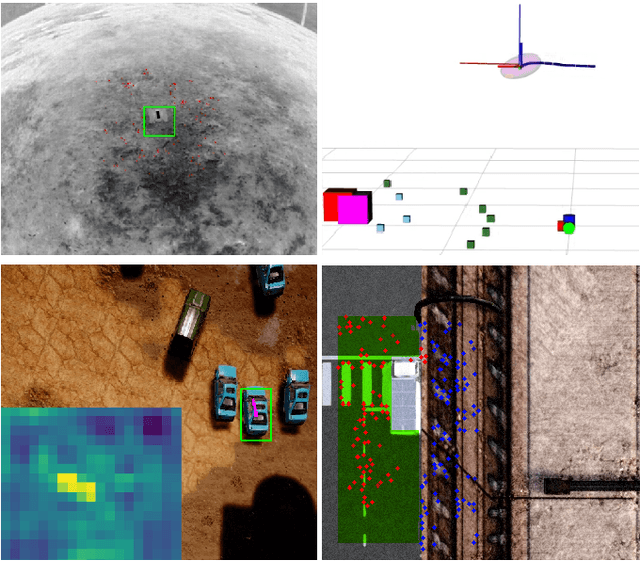
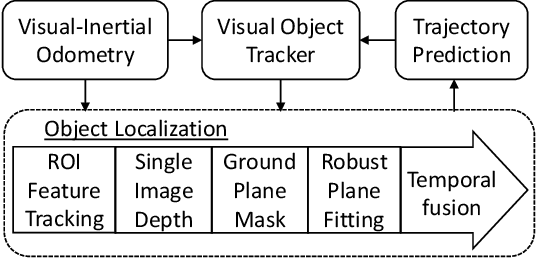
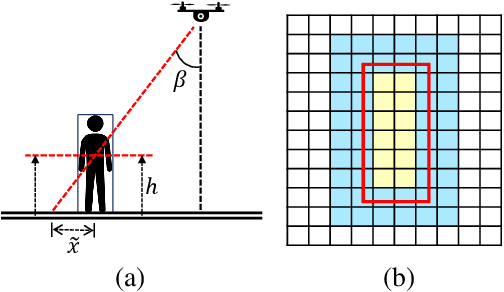

We propose TRADE for robust tracking and 3D localization of a moving target in cluttered environments, from UAVs equipped with a single camera. Ultimately TRADE enables 3d-aware target following. Tracking-by-detection approaches are vulnerable to target switching, especially between similar objects. Thus, TRADE predicts and incorporates the target 3D trajectory to select the right target from the tracker's response map. Unlike static environments, depth estimation of a moving target from a single camera is a ill-posed problem. Therefore we propose a novel 3D localization method for ground targets on complex terrain. It reasons about scene geometry by combining ground plane segmentation, depth-from-motion and single-image depth estimation. The benefits of using TRADE are demonstrated as tracking robustness and depth accuracy on several dynamic scenes simulated in this work. Additionally, we demonstrate autonomous target following using a thermal camera by running TRADE on a quadcopter's board computer.