 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Game-Theoretic Understanding of Misclassification
Oct 07, 2022
This paper analyzes various types of image misclassification from a game-theoretic view. Particularly, we consider the misclassification of clean, adversarial, and corrupted images and characterize it through the distribution of multi-order interactions. We discover that the distribution of multi-order interactions varies across the types of misclassification. For example, misclassified adversarial images have a higher strength of high-order interactions than correctly classified clean images, which indicates that adversarial perturbations create spurious features that arise from complex cooperation between pixels. By contrast, misclassified corrupted images have a lower strength of low-order interactions than correctly classified clean images, which indicates that corruptions break the local cooperation between pixels. We also provide the first analysis of Vision Transformers using interactions. We found that Vision Transformers show a different tendency in the distribution of interactions from that in CNNs, and this implies that they exploit the features that CNNs do not use for the prediction. Our study demonstrates that the recent game-theoretic analysis of deep learning models can be broadened to analyze various malfunctions of deep learning models including Vision Transformers by using the distribution, order, and sign of interactions.
Simulating single-photon detector array sensors for depth imaging
Oct 07, 2022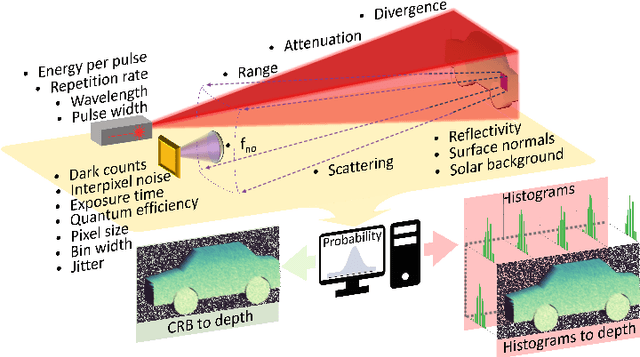
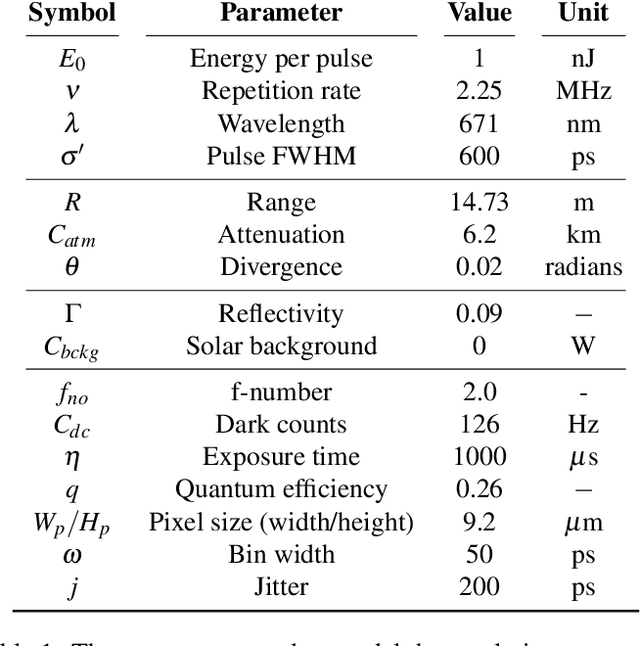
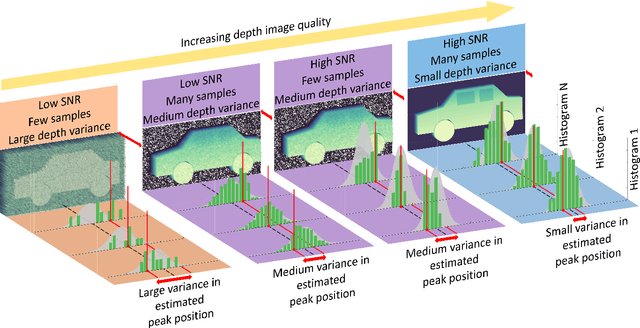
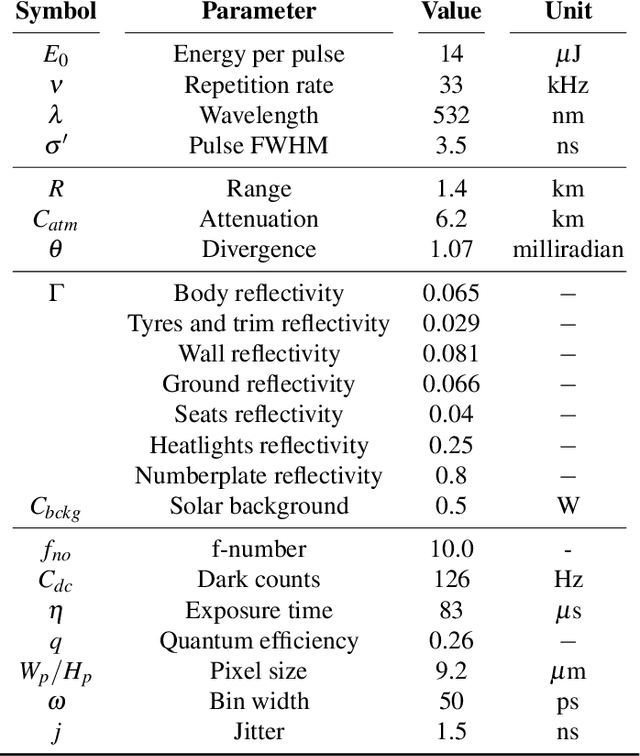
Single-Photon Avalanche Detector (SPAD) arrays are a rapidly emerging technology. These multi-pixel sensors have single-photon sensitivities and pico-second temporal resolutions thus they can rapidly generate depth images with millimeter precision. Such sensors are a key enabling technology for future autonomous systems as they provide guidance and situational awareness. However, to fully exploit the capabilities of SPAD array sensors, it is crucial to establish the quality of depth images they are able to generate in a wide range of scenarios. Given a particular optical system and a finite image acquisition time, what is the best-case depth resolution and what are realistic images generated by SPAD arrays? In this work, we establish a robust yet simple numerical procedure that rapidly establishes the fundamental limits to depth imaging with SPAD arrays under real world conditions. Our approach accurately generates realistic depth images in a wide range of scenarios, allowing the performance of an optical depth imaging system to be established without the need for costly and laborious field testing. This procedure has applications in object detection and tracking for autonomous systems and could be easily extended to systems for underwater imaging or for imaging around corners.
Topology-Preserving Segmentation Network
Oct 07, 2022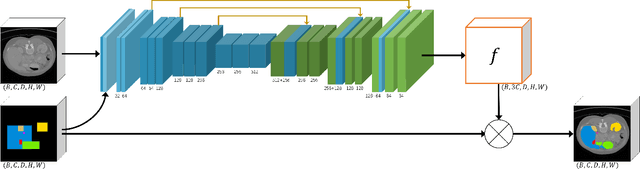
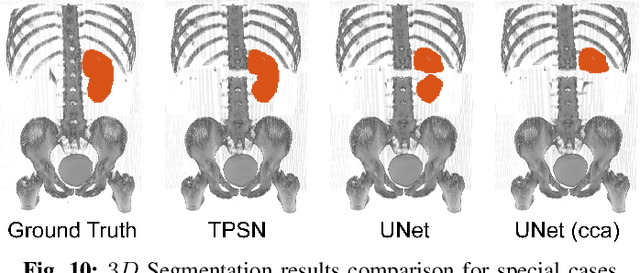
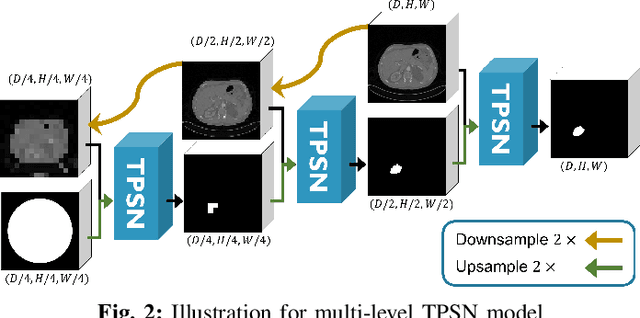
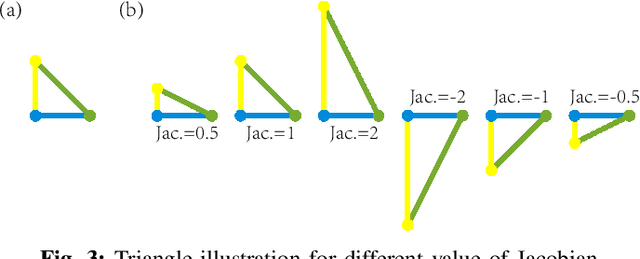
Medical image segmentation aims to automatically extract anatomical or pathological structures in the human body. Most objects or regions of interest are of similar patterns. For example, the relative location and the relative size of the lung and the kidney differ little among subjects. Incorporating these morphology rules as prior knowledge into the segmentation model is believed to be an effective way to enhance the accuracy of the segmentation results. Motivated by this, we propose in this work the Topology-Preserving Segmentation Network (TPSN) which can predict segmentation masks with the same topology prescribed for specific tasks. TPSN is a deformation-based model that yields a deformation map through an encoder-decoder architecture to warp the template masks into a target shape approximating the region to segment. Comparing to the segmentation framework based on pixel-wise classification, deformation-based segmentation models that warp a template to enclose the regions are more convenient to enforce geometric constraints. In our framework, we carefully design the ReLU Jacobian regularization term to enforce the bijectivity of the deformation map. As such, the predicted mask by TPSN has the same topology as that of the template prior mask.
Multi-Frequency-Aware Patch Adversarial Learning for Neural Point Cloud Rendering
Oct 07, 2022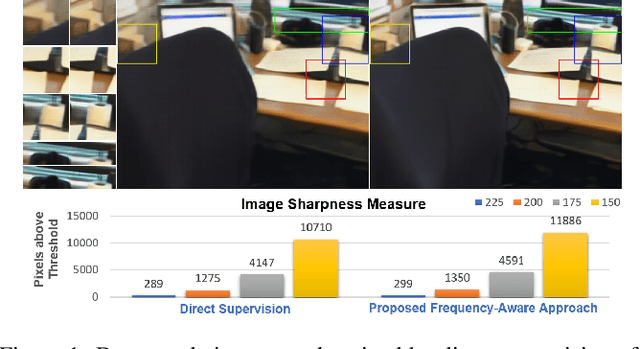
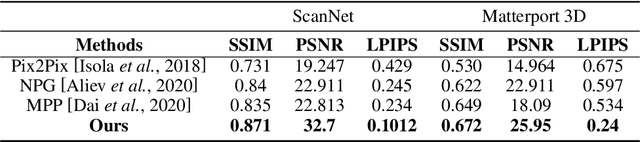
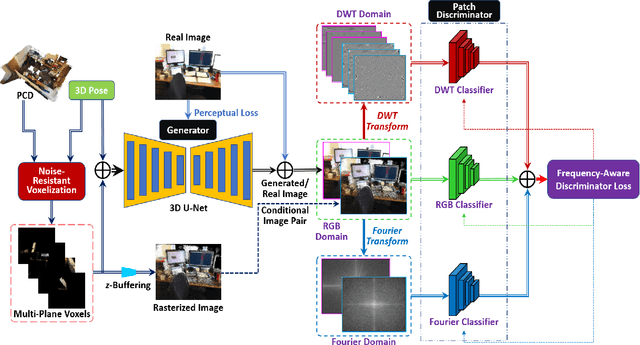
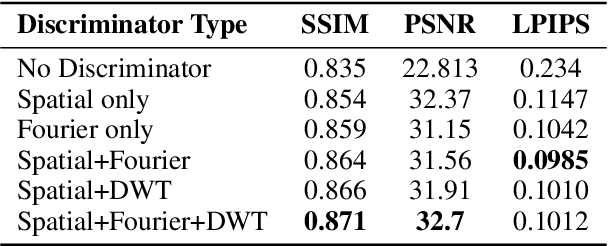
We present a neural point cloud rendering pipeline through a novel multi-frequency-aware patch adversarial learning framework. The proposed approach aims to improve the rendering realness by minimizing the spectrum discrepancy between real and synthesized images, especially on the high-frequency localized sharpness information which causes image blur visually. Specifically, a patch multi-discriminator scheme is proposed for the adversarial learning, which combines both spectral domain (Fourier Transform and Discrete Wavelet Transform) discriminators as well as the spatial (RGB) domain discriminator to force the generator to capture global and local spectral distributions of the real images. The proposed multi-discriminator scheme not only helps to improve rendering realness, but also enhance the convergence speed and stability of adversarial learning. Moreover, we introduce a noise-resistant voxelisation approach by utilizing both the appearance distance and spatial distance to exclude the spatial outlier points caused by depth noise. Our entire architecture is fully differentiable and can be learned in an end-to-end fashion. Extensive experiments show that our method produces state-of-the-art results for neural point cloud rendering by a significant margin. Our source code will be made public at a later date.
Image-based Detection of Surface Defects in Concrete during Construction
Aug 03, 2022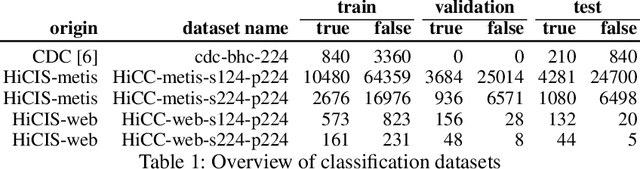
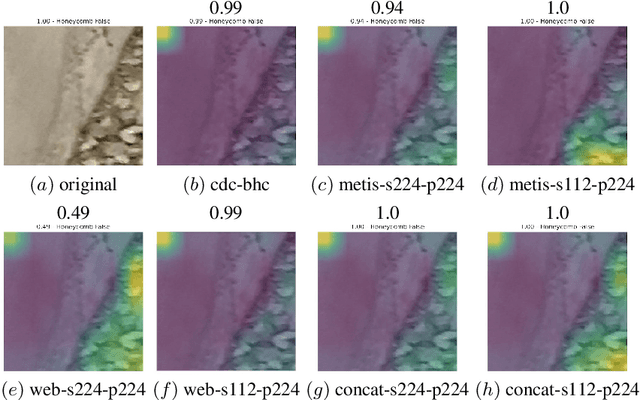


Defects increase the cost and duration of construction projects. Automating defect detection would reduce documentation efforts that are necessary to decrease the risk of defects delaying construction projects. Since concrete is a widely used construction material, this work focuses on detecting honeycombs, a substantial defect in concrete structures that may even affect structural integrity. First, images were compared that were either scraped from the web or obtained from actual practice. The results demonstrate that web images represent just a selection of honeycombs and do not capture the complete variance. Second, Mask R-CNN and EfficientNet-B0 were trained for honeycomb detection to evaluate instance segmentation and patch-based classification, respectively achieving 47.7% precision and 34.2% recall as well as 68.5% precision and 55.7% recall. Although the performance of those models is not sufficient for completely automated defect detection, the models could be used for active learning integrated into defect documentation systems. In conclusion, CNNs can assist detecting honeycombs in concrete.
KiPA22 Report: U-Net with Contour Regularization for Renal Structures Segmentation
Aug 10, 2022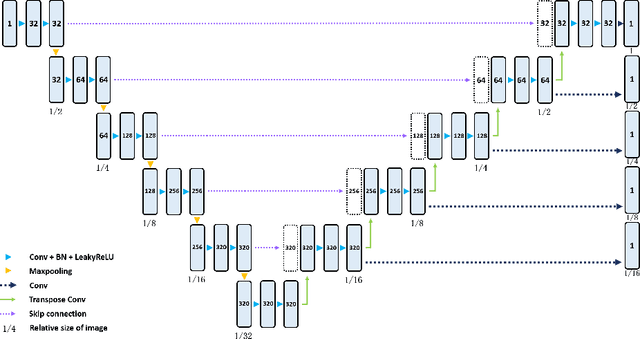
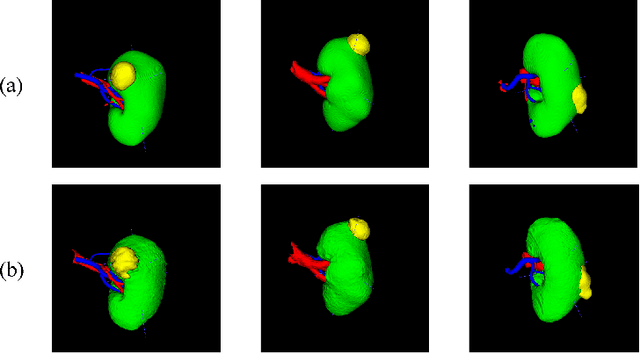

Three-dimensional (3D) integrated renal structures (IRS) segmentation is important in clinical practice. With the advancement of deep learning techniques, many powerful frameworks focusing on medical image segmentation are proposed. In this challenge, we utilized the nnU-Net framework, which is the state-of-the-art method for medical image segmentation. To reduce the outlier prediction for the tumor label, we combine contour regularization (CR) loss of the tumor label with Dice loss and cross-entropy loss to improve this phenomenon.
TVLT: Textless Vision-Language Transformer
Sep 28, 2022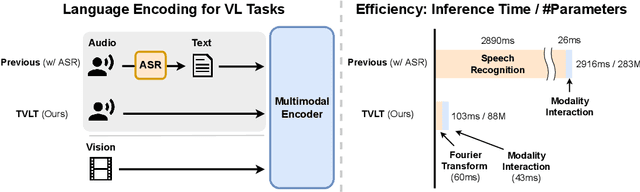
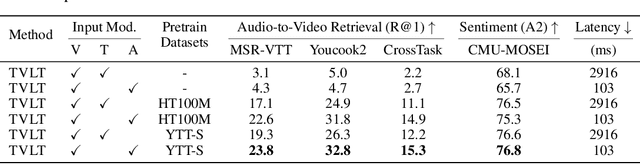

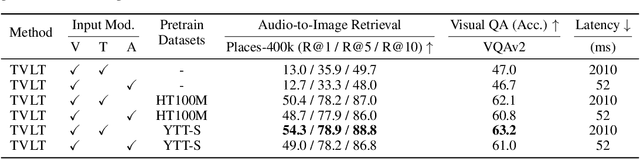
In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart, on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text. Our code and checkpoints are available at: https://github.com/zinengtang/TVLT
An evaluation of U-Net in Renal Structure Segmentation
Sep 06, 2022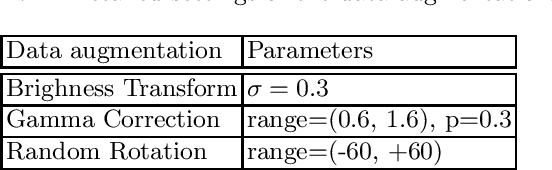
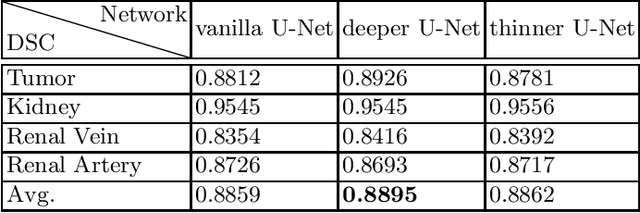
Renal structure segmentation from computed tomography angiography~(CTA) is essential for many computer-assisted renal cancer treatment applications. Kidney PArsing~(KiPA 2022) Challenge aims to build a fine-grained multi-structure dataset and improve the segmentation of multiple renal structures. Recently, U-Net has dominated the medical image segmentation. In the KiPA challenge, we evaluated several U-Net variants and selected the best models for the final submission.
Face Shape-Guided Deep Feature Alignment for Face Recognition Robust to Face Misalignment
Sep 15, 2022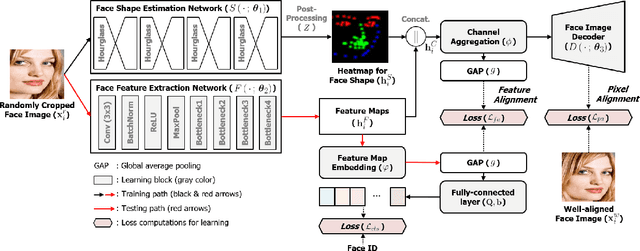
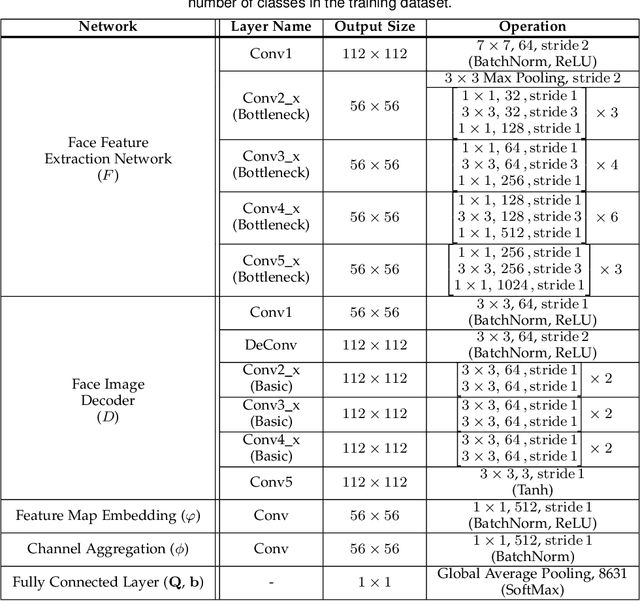
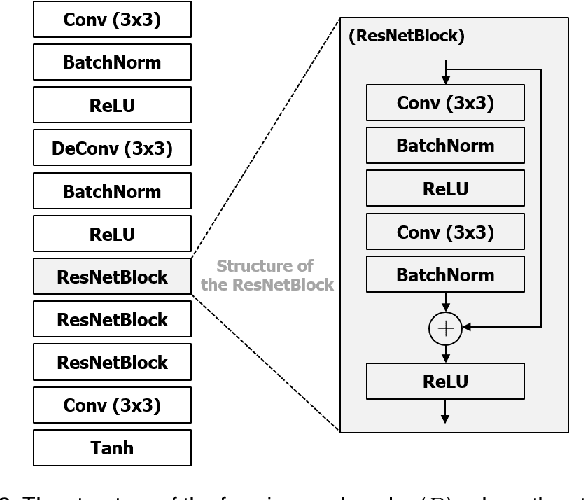
For the past decades, face recognition (FR) has been actively studied in computer vision and pattern recognition society. Recently, due to the advances in deep learning, the FR technology shows high performance for most of the benchmark datasets. However, when the FR algorithm is applied to a real-world scenario, the performance has been known to be still unsatisfactory. This is mainly attributed to the mismatch between training and testing sets. Among such mismatches, face misalignment between training and testing faces is one of the factors that hinder successful FR. To address this limitation, we propose a face shape-guided deep feature alignment framework for FR robust to the face misalignment. Based on a face shape prior (e.g., face keypoints), we train the proposed deep network by introducing alignment processes, i.e., pixel and feature alignments, between well-aligned and misaligned face images. Through the pixel alignment process that decodes the aggregated feature extracted from a face image and face shape prior, we add the auxiliary task to reconstruct the well-aligned face image. Since the aggregated features are linked to the face feature extraction network as a guide via the feature alignment process, we train the robust face feature to the face misalignment. Even if the face shape estimation is required in the training stage, the additional face alignment process, which is usually incorporated in the conventional FR pipeline, is not necessarily needed in the testing phase. Through the comparative experiments, we validate the effectiveness of the proposed method for the face misalignment with the FR datasets.
Scaling & Shifting Your Features: A New Baseline for Efficient Model Tuning
Oct 17, 2022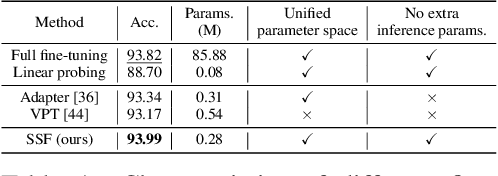
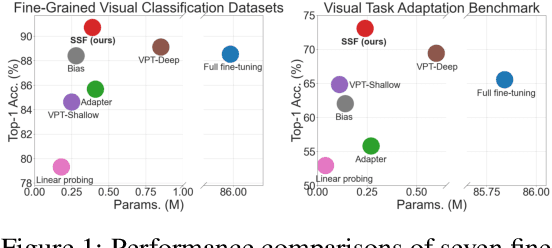
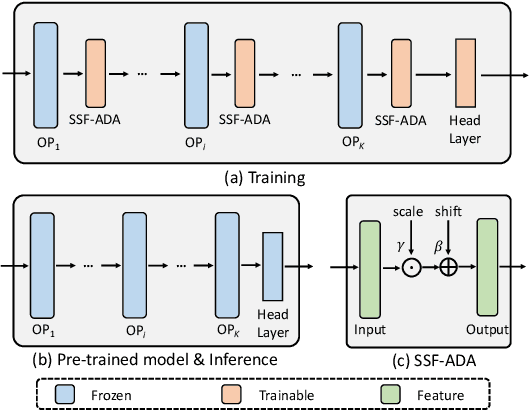

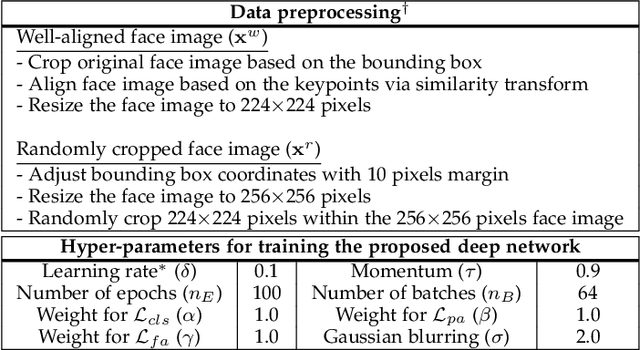
Existing fine-tuning methods either tune all parameters of the pre-trained model (full fine-tuning), which is not efficient, or only tune the last linear layer (linear probing), which suffers a significant accuracy drop compared to the full fine-tuning. In this paper, we propose a new parameter-efficient fine-tuning method termed as SSF, representing that researchers only need to Scale and Shift the deep Features extracted by a pre-trained model to catch up with the performance of full fine-tuning. In this way, SSF also surprisingly outperforms other parameter-efficient fine-tuning approaches even with a smaller number of tunable parameters. Furthermore, different from some existing parameter-efficient fine-tuning methods (e.g., Adapter or VPT) that introduce the extra parameters and computational cost in the training and inference stages, SSF only adds learnable parameters during the training stage, and these additional parameters can be merged into the original pre-trained model weights via re-parameterization in the inference phase. With the proposed SSF, our model obtains 2.46% (90.72% vs. 88.54%) and 11.48% (73.10% vs. 65.57%) performance improvement on FGVC and VTAB-1k in terms of Top-1 accuracy compared to the full fine-tuning but only fine-tuning about 0.3M parameters. We also conduct amounts of experiments in various model families (CNNs, Transformers, and MLPs) and datasets. Results on 26 image classification datasets in total and 3 robustness & out-of-distribution datasets show the effectiveness of SSF. Code is available at https://github.com/dongzelian/SSF.