 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data augmentation on-the-fly and active learning in data stream classification
Oct 13, 2022
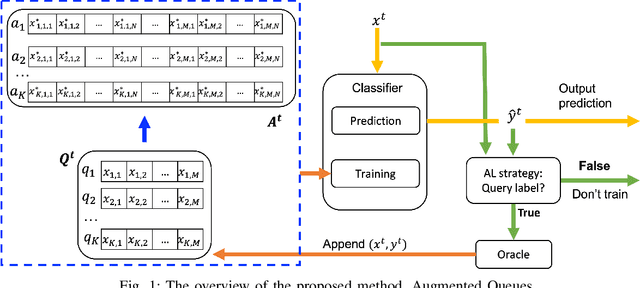
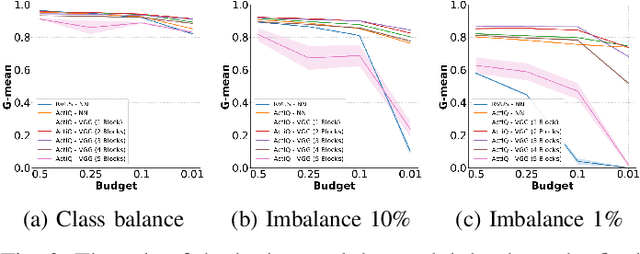
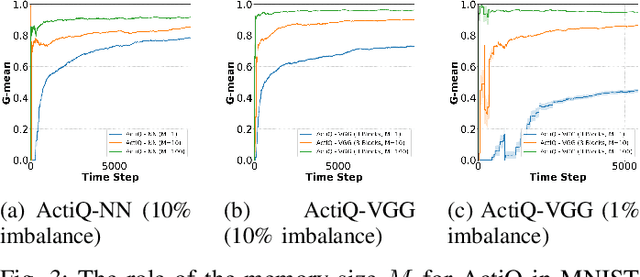
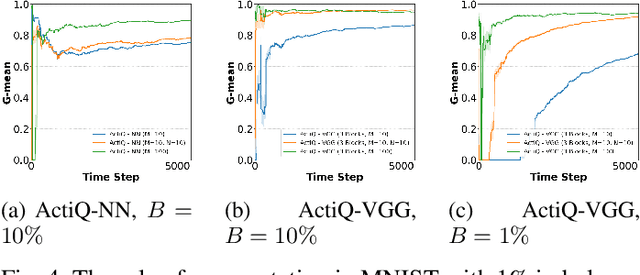
There is an emerging need for predictive models to be trained on-the-fly, since in numerous machine learning applications data are arriving in an online fashion. A critical challenge encountered is that of limited availability of ground truth information (e.g., labels in classification tasks) as new data are observed one-by-one online, while another significant challenge is that of class imbalance. This work introduces the novel Augmented Queues method, which addresses the dual-problem by combining in a synergistic manner online active learning, data augmentation, and a multi-queue memory to maintain separate and balanced queues for each class. We perform an extensive experimental study using image and time-series augmentations, in which we examine the roles of the active learning budget, memory size, imbalance level, and neural network type. We demonstrate two major advantages of Augmented Queues. First, it does not reserve additional memory space as the generation of synthetic data occurs only at training times. Second, learning models have access to more labelled data without the need to increase the active learning budget and / or the original memory size. Learning on-the-fly poses major challenges which, typically, hinder the deployment of learning models. Augmented Queues significantly improves the performance in terms of learning quality and speed. Our code is made publicly available.
* Keywords: incremental learning, active learning, data streams, class imbalance, neural networks
Cut-Paste Consistency Learning for Semi-Supervised Lesion Segmentation
Oct 01, 2022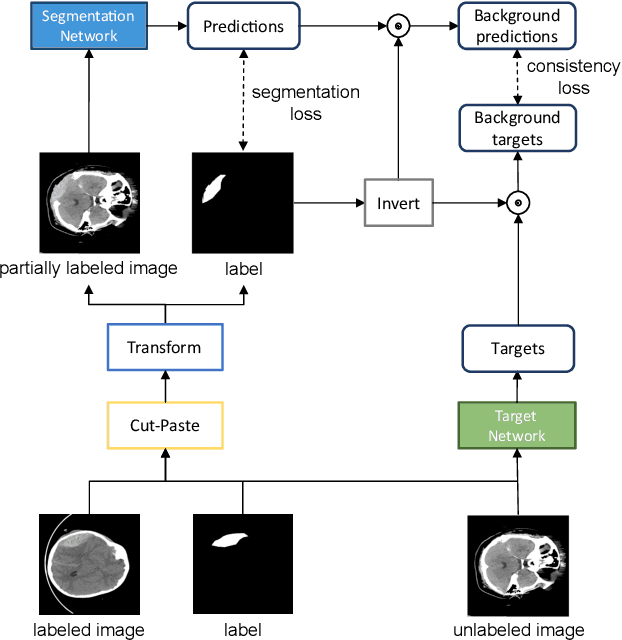
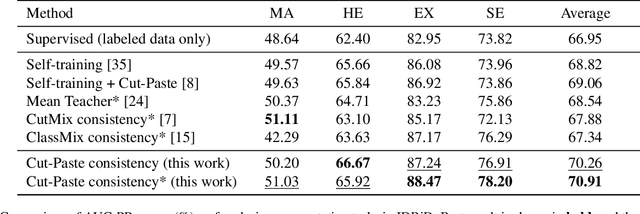
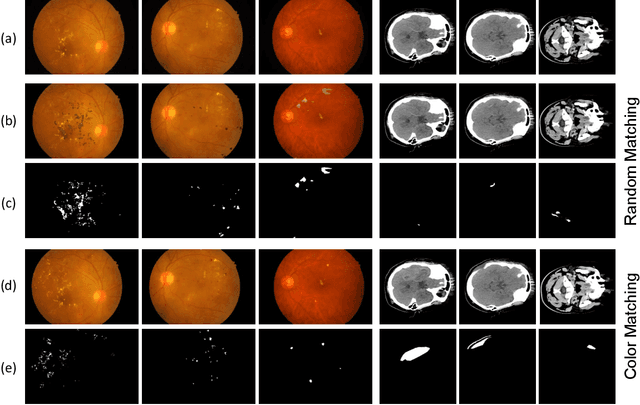
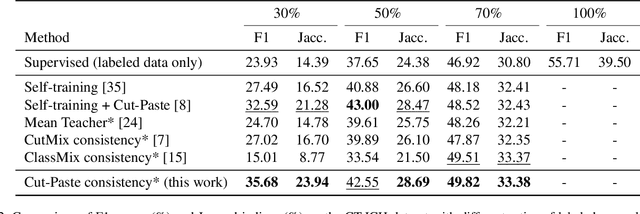
Semi-supervised learning has the potential to improve the data-efficiency of training data-hungry deep neural networks, which is especially important for medical image analysis tasks where labeled data is scarce. In this work, we present a simple semi-supervised learning method for lesion segmentation tasks based on the ideas of cut-paste augmentation and consistency regularization. By exploiting the mask information available in the labeled data, we synthesize partially labeled samples from the unlabeled images so that the usual supervised learning objective (e.g., binary cross entropy) can be applied. Additionally, we introduce a background consistency term to regularize the training on the unlabeled background regions of the synthetic images. We empirically verify the effectiveness of the proposed method on two public lesion segmentation datasets, including an eye fundus photograph dataset and a brain CT scan dataset. The experiment results indicate that our method achieves consistent and superior performance over other self-training and consistency-based methods without introducing sophisticated network components.
CrackSeg9k: A Collection and Benchmark for Crack Segmentation Datasets and Frameworks
Aug 27, 2022
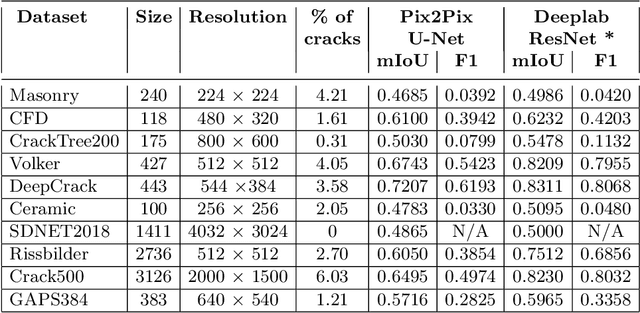

The detection of cracks is a crucial task in monitoring structural health and ensuring structural safety. The manual process of crack detection is time-consuming and subjective to the inspectors. Several researchers have tried tackling this problem using traditional Image Processing or learning-based techniques. However, their scope of work is limited to detecting cracks on a single type of surface (walls, pavements, glass, etc.). The metrics used to evaluate these methods are also varied across the literature, making it challenging to compare techniques. This paper addresses these problems by combining previously available datasets and unifying the annotations by tackling the inherent problems within each dataset, such as noise and distortions. We also present a pipeline that combines Image Processing and Deep Learning models. Finally, we benchmark the results of proposed models on these metrics on our new dataset and compare them with state-of-the-art models in the literature.
A Superimposed Divide-and-Conquer Image Recognition Method for SEM Images of Nanoparticles on The Surface of Monocrystalline silicon with High Aggregation Degree
Jun 04, 2022


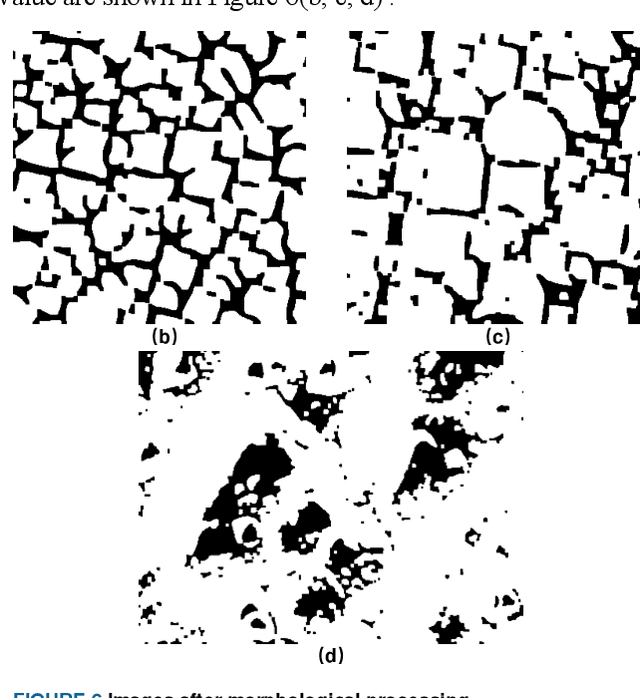
The nanoparticle size and distribution information in the SEM images of silicon crystals are generally counted by manual methods. The realization of automatic machine recognition is significant in materials science. This paper proposed a superposition partitioning image recognition method to realize automatic recognition and information statistics of silicon crystal nanoparticle SEM images. Especially for the complex and highly aggregated characteristics of silicon crystal particle size, an accurate recognition step and contour statistics method based on morphological processing are given. This method has technical reference value for the recognition of Monocrystalline silicon surface nanoparticle images under different SEM shooting conditions. Besides, it outperforms other methods in terms of recognition accuracy and algorithm efficiency.
A Smoothing and Thresholding Image Segmentation Framework with Weighted Anisotropic-Isotropic Total Variation
Feb 21, 2022
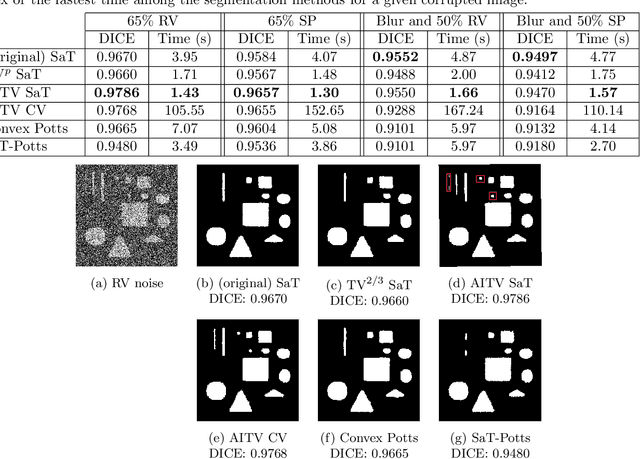

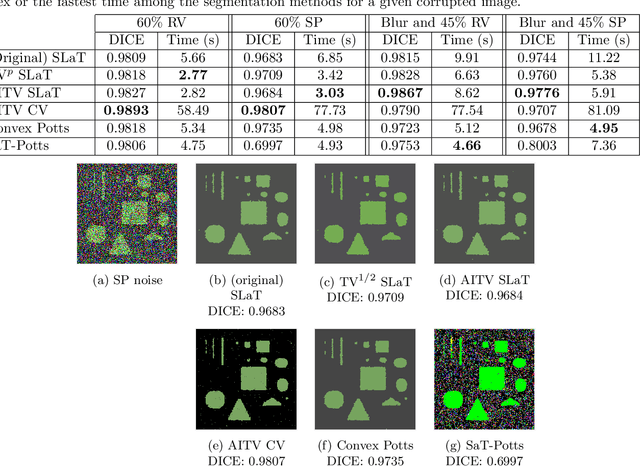
In this paper, we propose a multi-stage image segmentation framework that incorporates a weighted difference of anisotropic and isotropic total variation (AITV). The segmentation framework generally consists of two stages: smoothing and thresholding, thus referred to as SaT. In the first stage, a smoothed image is obtained by an AITV-regularized Mumford-Shah (MS) model, which can be solved efficiently by the alternating direction method of multipliers (ADMM) with a closed-form solution of a proximal operator of the $\ell_1 -\alpha \ell_2$ regularizer. Convergence of the ADMM algorithm is analyzed. In the second stage, we threshold the smoothed image by $k$-means clustering to obtain the final segmentation result. Numerical experiments demonstrate that the proposed segmentation framework is versatile for both grayscale and color images, efficient in producing high-quality segmentation results within a few seconds, and robust to input images that are corrupted with noise, blur, or both. We compare the AITV method with its original convex and nonconvex TV$^p (0<p<1)$ counterparts, showcasing the qualitative and quantitative advantages of our proposed method.
iSegFormer: Interactive Image Segmentation with Transformers
Dec 21, 2021
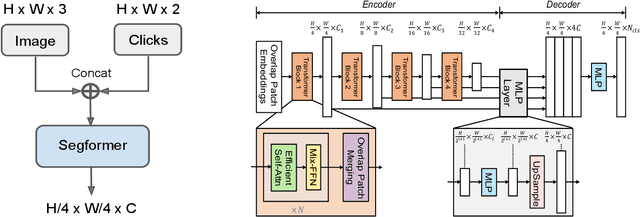
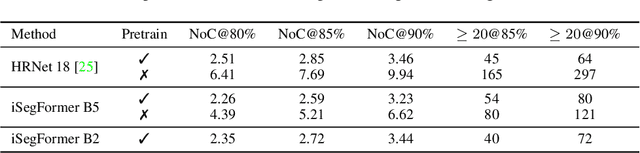

We propose iSegFormer, a novel transformer-based approach for interactive image segmentation. iSegFormer is built upon existing segmentation transformers with user clicks as an additional input, allowing users to interactively and iteratively refine the segmentation mask.
Teaching Where to Look: Attention Similarity Knowledge Distillation for Low Resolution Face Recognition
Sep 29, 2022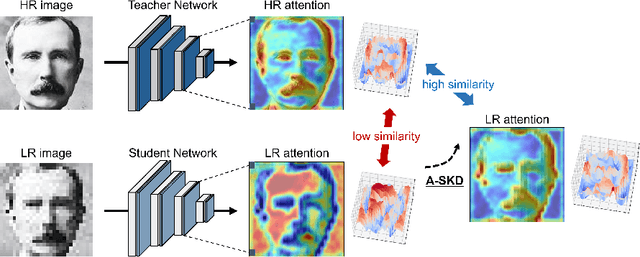
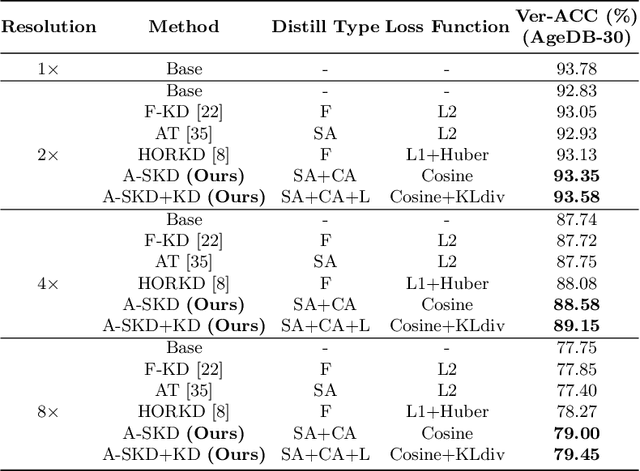

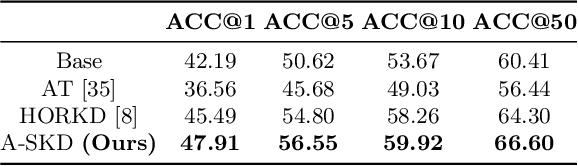
Deep learning has achieved outstanding performance for face recognition benchmarks, but performance reduces significantly for low resolution (LR) images. We propose an attention similarity knowledge distillation approach, which transfers attention maps obtained from a high resolution (HR) network as a teacher into an LR network as a student to boost LR recognition performance. Inspired by humans being able to approximate an object's region from an LR image based on prior knowledge obtained from HR images, we designed the knowledge distillation loss using the cosine similarity to make the student network's attention resemble the teacher network's attention. Experiments on various LR face related benchmarks confirmed the proposed method generally improved recognition performances on LR settings, outperforming state-of-the-art results by simply transferring well-constructed attention maps. The code and pretrained models are publicly available in the https://github.com/gist-ailab/teaching-where-to-look.
Revisiting Rolling Shutter Bundle Adjustment: Toward Accurate and Fast Solution
Oct 10, 2022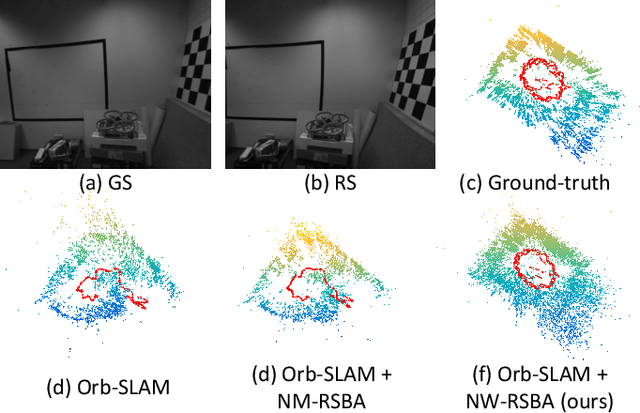
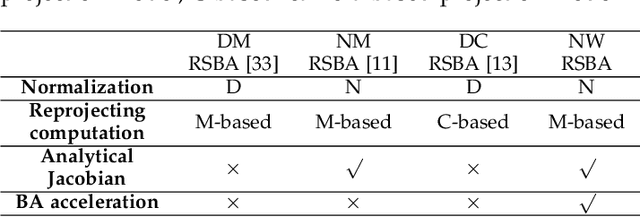
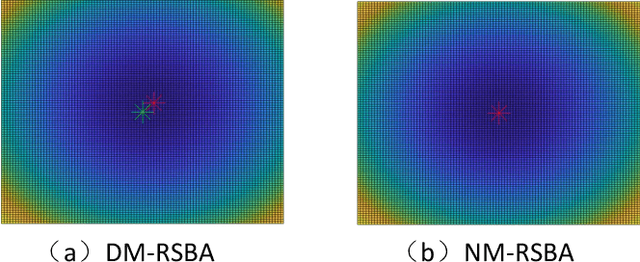
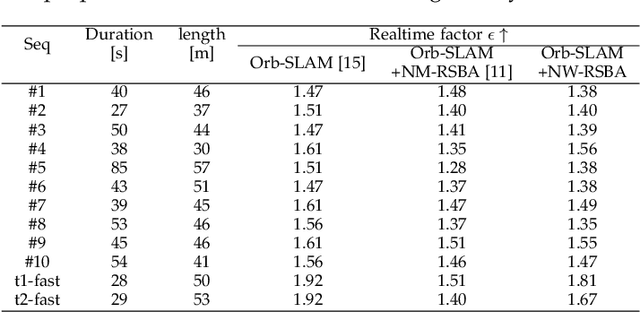
We propose a robust and fast bundle adjustment solution that estimates the 6-DoF pose of the camera and the geometry of the environment based on measurements from a rolling shutter (RS) camera. This tackles the challenges in the existing works, namely relying on additional sensors, high frame rate video as input, restrictive assumptions on camera motion, readout direction, and poor efficiency. To this end, we first investigate the influence of normalization to the image point on RSBA performance and show its better approximation in modelling the real 6-DoF camera motion. Then we present a novel analytical model for the visual residual covariance, which can be used to standardize the reprojection error during the optimization, consequently improving the overall accuracy. More importantly, the combination of normalization and covariance standardization weighting in RSBA (NW-RSBA) can avoid common planar degeneracy without needing to constrain the filming manner. Besides, we propose an acceleration strategy for NW-RSBA based on the sparsity of its Jacobian matrix and Schur complement. The extensive synthetic and real data experiments verify the effectiveness and efficiency of the proposed solution over the state-of-the-art works. We also demonstrate the proposed method can be easily implemented and plug-in famous GSSfM and GSSLAM systems as completed RSSfM and RSSLAM solutions.
HORIZON: A High-Resolution Panorama Synthesis Framework
Oct 10, 2022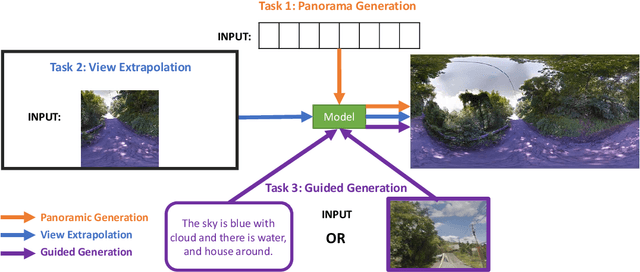
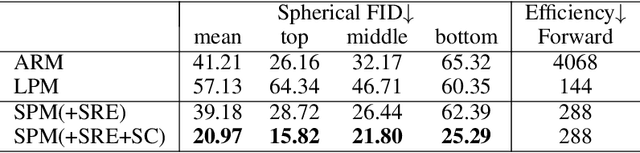
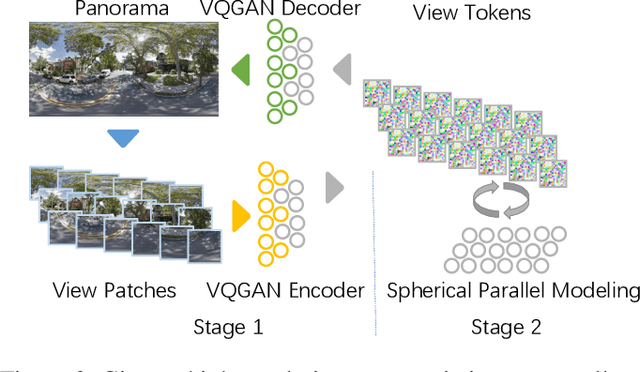

Panorama synthesis aims to generate a visual scene with all 360-degree views and enables an immersive virtual world. If the panorama synthesis process can be semantically controlled, we can then build an interactive virtual world and form an unprecedented human-computer interaction experience. Existing panoramic synthesis methods mainly focus on dealing with the inherent challenges brought by panoramas' spherical structure such as the projection distortion and the in-continuity problem when stitching edges, but is hard to effectively control semantics. The recent success of visual synthesis like DALL.E generates promising 2D flat images with semantic control, however, it is hard to directly be applied to panorama synthesis which inevitably generates distorted content. Besides, both of the above methods can not effectively synthesize high-resolution panoramas either because of quality or inference speed. In this work, we propose a new generation framework for high-resolution panorama images. The contributions include 1) alleviating the spherical distortion and edge in-continuity problem through spherical modeling, 2) supporting semantic control through both image and text hints, and 3) effectively generating high-resolution panoramas through parallel decoding. Our experimental results on a large-scale high-resolution Street View dataset validated the superiority of our approach quantitatively and qualitatively.
Deep Joint Source-Channel and Encryption Coding: Secure Semantic Communications
Aug 19, 2022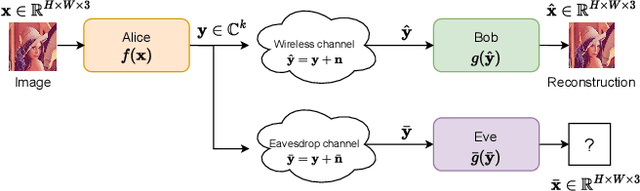
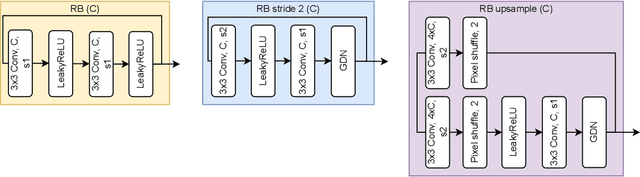
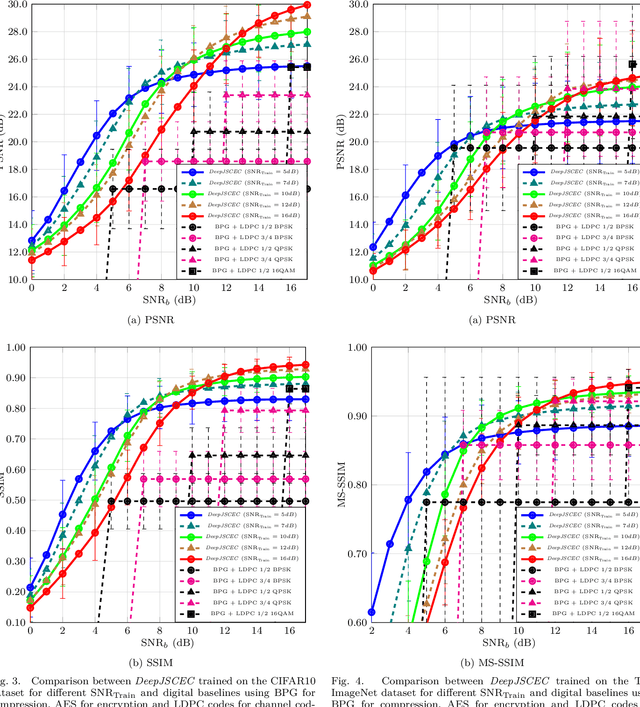
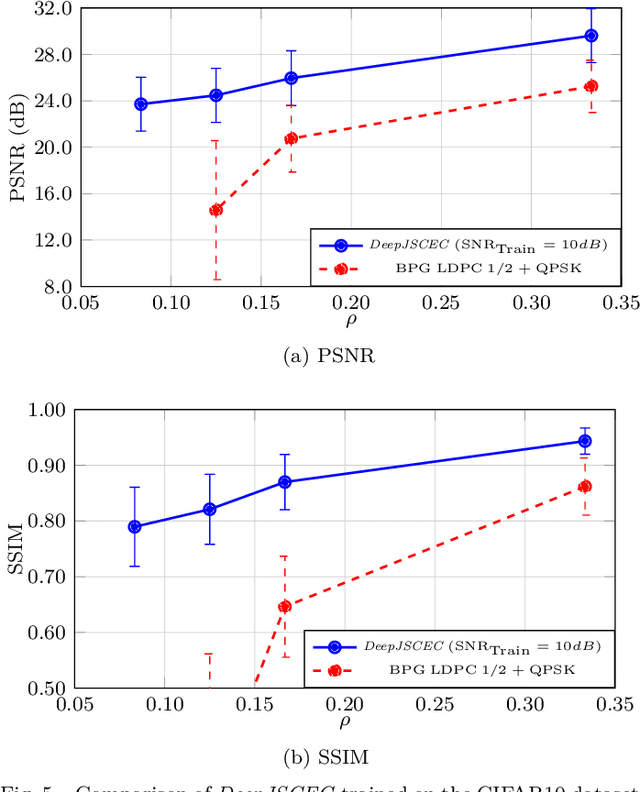
Deep learning driven joint source-channel coding (JSCC) for wireless image or video transmission, also called DeepJSCC, has been a topic of interest recently with very promising results. The idea is to map similar source samples to nearby points in the channel input space such that, despite the noise introduced by the channel, the input can be recovered with minimal distortion. In DeepJSCC, this is achieved by an autoencoder architecture with a non-trainable channel layer between the encoder and decoder. DeepJSCC has many favorable properties, such as better end-to-end distortion performance than its separate source and channel coding counterpart as well as graceful degradation with respect to channel quality. However, due to the inherent correlation between the source sample and channel input, DeepJSCC is vulnerable to eavesdropping attacks. In this paper, we propose the first DeepJSCC scheme for wireless image transmission that is secure against eavesdroppers, called DeepJSCEC. DeepJSCEC not only preserves the favorable properties of DeepJSCC, it also provides security against chosen-plaintext attacks from the eavesdropper, without the need to make assumptions about the eavesdropper's channel condition, or its intended use of the intercepted signal. Numerical results show that DeepJSCEC achieves similar or better image quality than separate source coding using BPG compression, AES encryption, and LDPC codes for channel coding, while preserving the graceful degradation of image quality with respect to channel quality. We also show that the proposed encryption method is problem agnostic, meaning it can be applied to other end-to-end JSCC problems, such as remote classification, without modification. Given the importance of security in modern wireless communication systems, we believe this work brings DeepJSCC schemes much closer to adoption in practice.