 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fiducial Marker Detection in Multi-Viewpoint Point Cloud
Sep 02, 2022
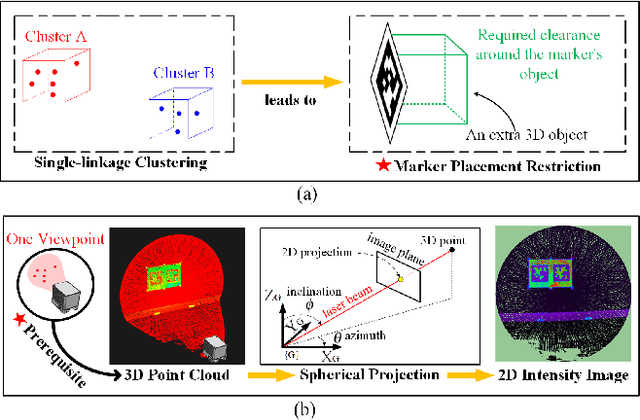
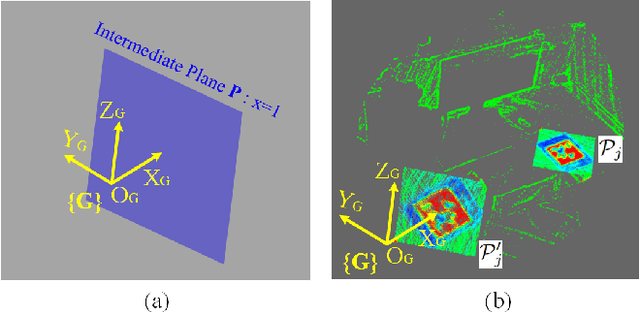
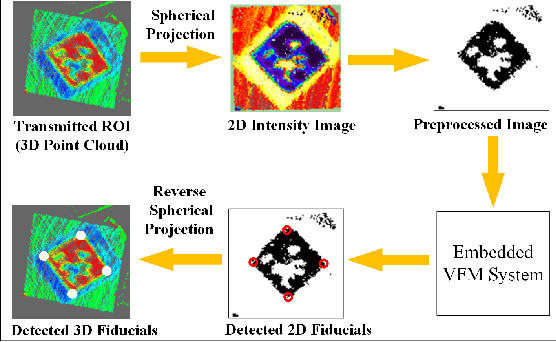
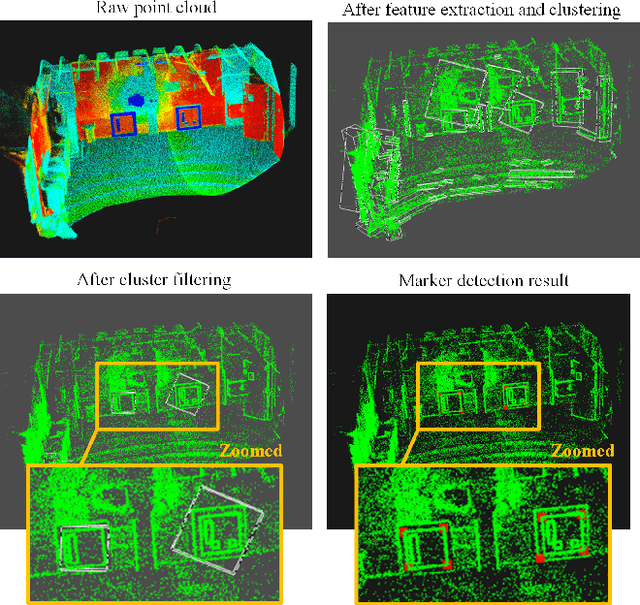
The existing LiDAR fiducial marker systems have usage restrictions. Especially, LiDARTag requires a specific marker placement and Intensity Image-based LiDAR Fiducial Marker demands that the point cloud is sampled from one viewpoint. As a result, with point clouds sampled from multiple viewpoints, fiducial marker detection remains an unsolved problem. In this letter, we develop a novel algorithm to detect the fiducial markers in the multi-viewpoint point cloud. The proposed algorithm includes two stages. First, Regions of Interest (ROIs) detection finds point clusters that could contain fiducial markers. Specifically, a method extracting the ROIs from the intensity perspective is introduced on account of the fact that from the spatial perspective, the markers, which are sheets of paper or thin boards, are non-distinguishable from the planes to which they are attached. Second, marker detection verifies if the candidate ROIs contain fiducial markers and outputs the ID numbers and vertices locations of the markers in the valid ROIs. In particular, the ROIs are transmitted to a predefined intermediate plane for the purpose of adopting a spherical projection to generate the intensity image, and then, marker detection is completed through the intensity image. Qualitative and quantitative experimental results are provided to validate the proposed algorithm. The codes and results are available at: https://github.com/York-SDCNLab/Marker?Detection-General
VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance
Apr 18, 2022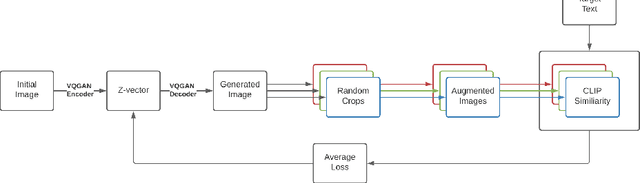
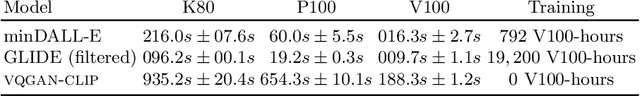


Generating and editing images from open domain text prompts is a challenging task that heretofore has required expensive and specially trained models. We demonstrate a novel methodology for both tasks which is capable of producing images of high visual quality from text prompts of significant semantic complexity without any training by using a multimodal encoder to guide image generations. We demonstrate on a variety of tasks how using CLIP [37] to guide VQGAN [11] produces higher visual quality outputs than prior, less flexible approaches like DALL-E [38], GLIDE [33] and Open-Edit [24], despite not being trained for the tasks presented. Our code is available in a public repository.
Face recognition via compact second order image gradient orientations
Jan 23, 2022
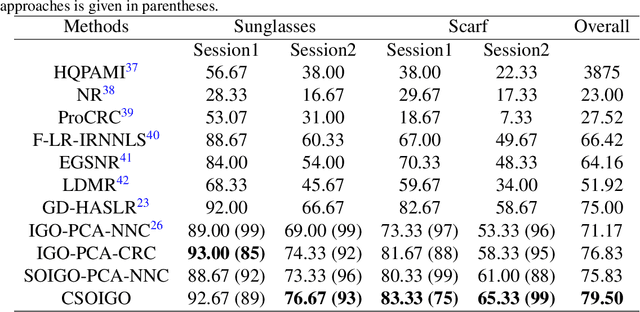

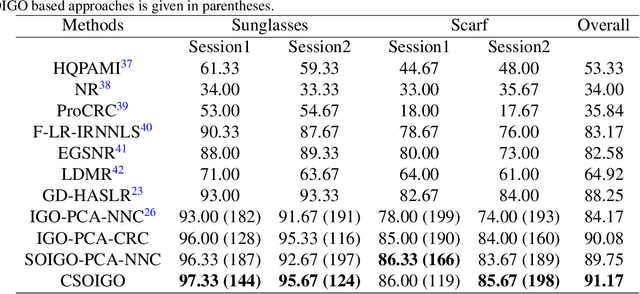
Conventional subspace learning approaches based on image gradient orientations only employ the first-order gradient information. However, recent researches on human vision system (HVS) uncover that the neural image is a landscape or a surface whose geometric properties can be captured through the second order gradient information. The second order image gradient orientations (SOIGO) can mitigate the adverse effect of noises in face images. To reduce the redundancy of SOIGO, we propose compact SOIGO (CSOIGO) by applying linear complex principal component analysis (PCA) in SOIGO. Combined with collaborative representation based classification (CRC) algorithm, the classification performance of CSOIGO is further enhanced. CSOIGO is evaluated under real-world disguise, synthesized occlusion and mixed variations. Experimental results indicate that the proposed method is superior to its competing approaches with few training samples, and even outperforms some prevailing deep neural network based approaches. The source code of CSOIGO is available at https://github.com/yinhefeng/SOIGO.
Leveraging in-domain supervision for unsupervised image-to-image translation tasks via multi-stream generators
Dec 30, 2021
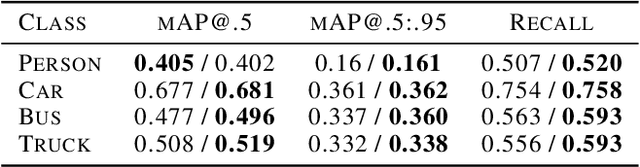


Supervision for image-to-image translation (I2I) tasks is hard to come by, but bears significant effect on the resulting quality. In this paper, we observe that for many Unsupervised I2I (UI2I) scenarios, one domain is more familiar than the other, and offers in-domain prior knowledge, such as semantic segmentation. We argue that for complex scenes, figuring out the semantic structure of the domain is hard, especially with no supervision, but is an important part of a successful I2I operation. We hence introduce two techniques to incorporate this invaluable in-domain prior knowledge for the benefit of translation quality: through a novel Multi-Stream generator architecture, and through a semantic segmentation-based regularization loss term. In essence, we propose splitting the input data according to semantic masks, explicitly guiding the network to different behavior for the different regions of the image. In addition, we propose training a semantic segmentation network along with the translation task, and to leverage this output as a loss term that improves robustness. We validate our approach on urban data, demonstrating superior quality in the challenging UI2I tasks of converting day images to night ones. In addition, we also demonstrate how reinforcing the target dataset with our augmented images improves the training of downstream tasks such as the classical detection one.
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
Dec 10, 2021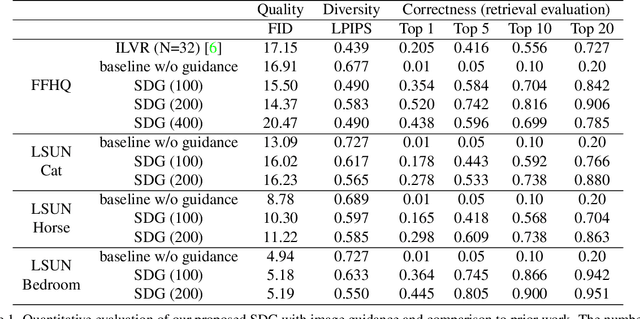
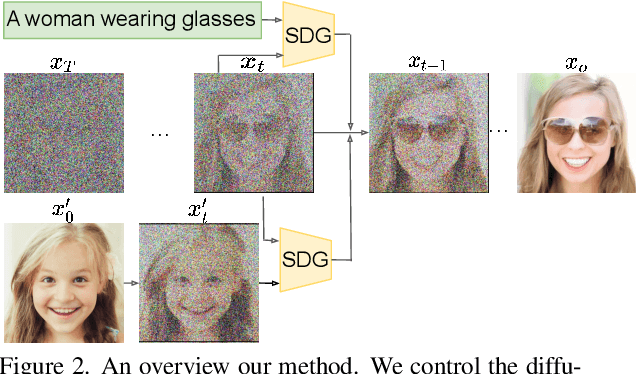
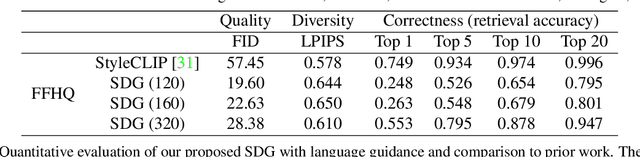

Controllable image synthesis models allow creation of diverse images based on text instructions or guidance from an example image. Recently, denoising diffusion probabilistic models have been shown to generate more realistic imagery than prior methods, and have been successfully demonstrated in unconditional and class-conditional settings. We explore fine-grained, continuous control of this model class, and introduce a novel unified framework for semantic diffusion guidance, which allows either language or image guidance, or both. Guidance is injected into a pretrained unconditional diffusion model using the gradient of image-text or image matching scores. We explore CLIP-based textual guidance as well as both content and style-based image guidance in a unified form. Our text-guided synthesis approach can be applied to datasets without associated text annotations. We conduct experiments on FFHQ and LSUN datasets, and show results on fine-grained text-guided image synthesis, synthesis of images related to a style or content example image, and examples with both textual and image guidance.
Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
Sep 28, 2022

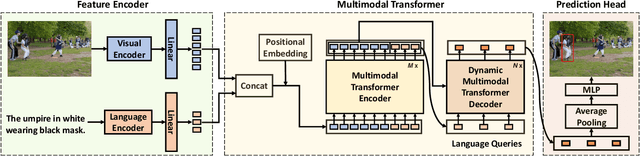
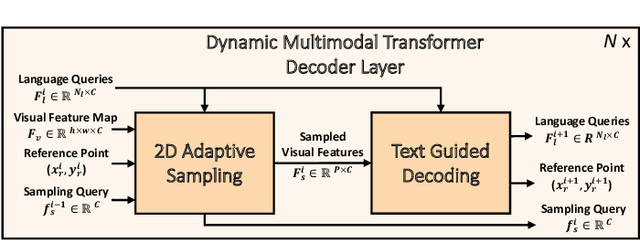
Multimodal transformer exhibits high capacity and flexibility to align image and text for visual grounding. However, the encoder-only grounding framework (e.g., TransVG) suffers from heavy computation due to the self-attention operation with quadratic time complexity. To address this issue, we present a new multimodal transformer architecture, coined as Dynamic MDETR, by decoupling the whole grounding process into encoding and decoding phases. The key observation is that there exists high spatial redundancy in images. Thus, we devise a new dynamic multimodal transformer decoder by exploiting this sparsity prior to speed up the visual grounding process. Specifically, our dynamic decoder is composed of a 2D adaptive sampling module and a text-guided decoding module. The sampling module aims to select these informative patches by predicting the offsets with respect to a reference point, while the decoding module works for extracting the grounded object information by performing cross attention between image features and text features. These two modules are stacked alternatively to gradually bridge the modality gap and iteratively refine the reference point of grounded object, eventually realizing the objective of visual grounding. Extensive experiments on five benchmarks demonstrate that our proposed Dynamic MDETR achieves competitive trade-offs between computation and accuracy. Notably, using only 9% feature points in the decoder, we can reduce ~44% GLOPs of the multimodal transformer, but still get higher accuracy than the encoder-only counterpart. In addition, to verify its generalization ability and scale up our Dynamic MDETR, we build the first one-stage CLIP empowered visual grounding framework, and achieve the state-of-the-art performance on these benchmarks.
Image Reconstruction for MRI using Deep CNN Priors Trained without Groundtruth
Apr 10, 2022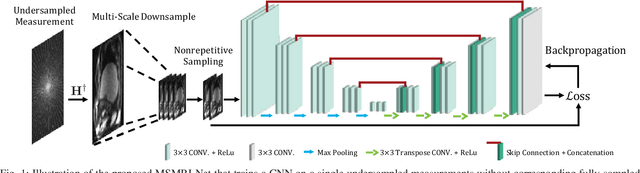
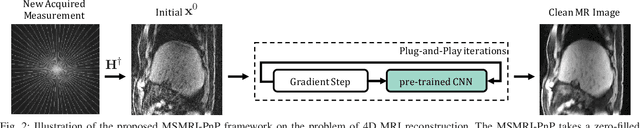
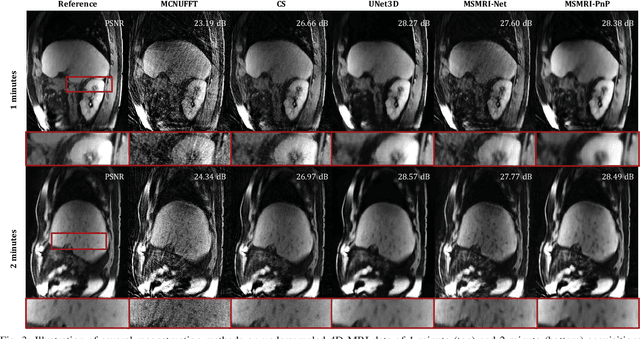
We propose a new plug-and-play priors (PnP) based MR image reconstruction method that systematically enforces data consistency while also exploiting deep-learning priors. Our prior is specified through a convolutional neural network (CNN) trained without any artifact-free ground truth to remove undersampling artifacts from MR images. The results on reconstructing free-breathing MRI data into ten respiratory phases show that the method can form high-quality 4D images from severely undersampled measurements corresponding to acquisitions of about 1 and 2 minutes in length. The results also highlight the competitive performance of the method compared to several popular alternatives, including the TGV regularization and traditional UNet3D.
Plausible May Not Be Faithful: Probing Object Hallucination in Vision-Language Pre-training
Oct 14, 2022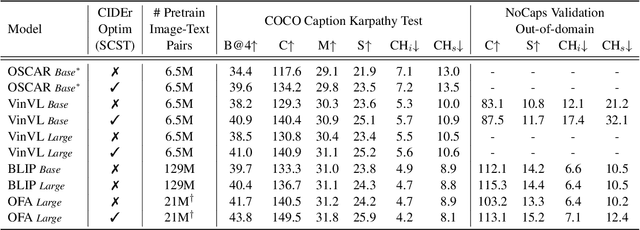

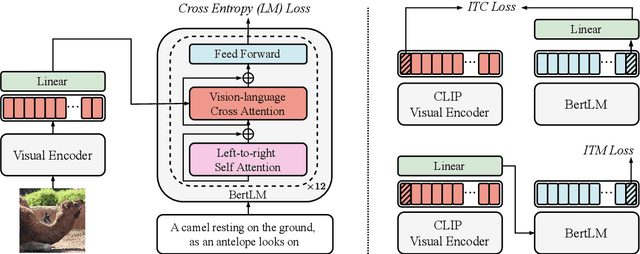
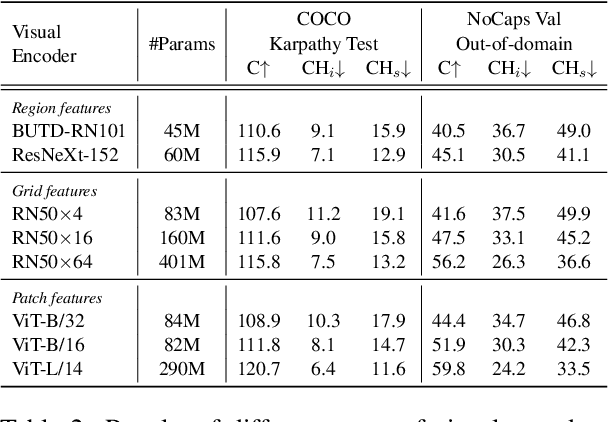
Large-scale vision-language pre-trained (VLP) models are prone to hallucinate non-existent visual objects when generating text based on visual information. In this paper, we exhaustively probe the object hallucination problem from three aspects. First, we examine various state-of-the-art VLP models, showing that models achieving better scores on standard metrics(e.g., BLEU-4, CIDEr) could hallucinate objects more frequently. Second, we investigate how different types of visual features in VLP influence hallucination, including region-based, grid-based, and patch-based. Surprisingly, we find that patch-based features perform the best and smaller patch resolution yields a non-trivial reduction in object hallucination. Third, we decouple various VLP objectives and demonstrate their effectiveness in alleviating object hallucination. Based on that, we propose a new pre-training loss, object masked language modeling, to further reduce object hallucination. We evaluate models on both COCO (in-domain) and NoCaps (out-of-domain) datasets with our improved CHAIR metric. Furthermore, we investigate the effects of various text decoding strategies and image augmentation methods on object hallucination.
On Benefits and Challenges of Conditional Interframe Video Coding in Light of Information Theory
Oct 14, 2022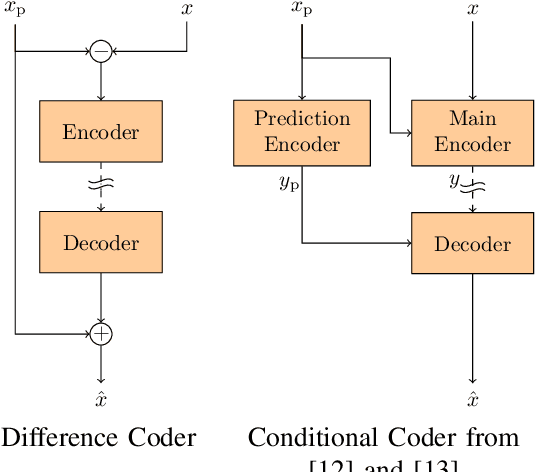
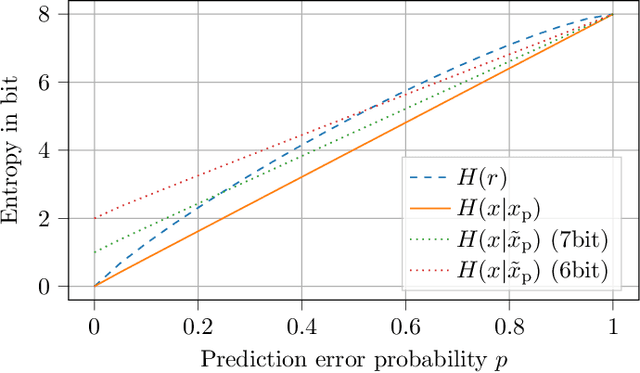
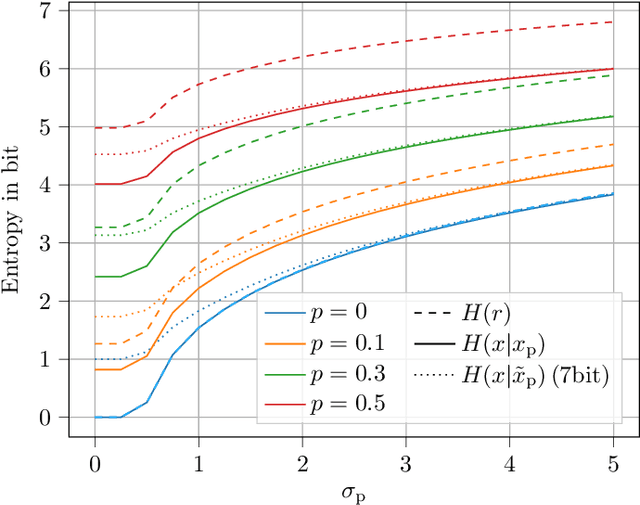

The rise of variational autoencoders for image and video compression has opened the door to many elaborate coding techniques. One example here is the possibility of conditional interframe coding. Here, instead of transmitting the residual between the original frame and the predicted frame (often obtained by motion compensation), the current frame is transmitted under the condition of knowing the prediction signal. In practice, conditional coding can be straightforwardly implemented using a conditional autoencoder, which has also shown good results in recent works. In this paper, we provide an information theoretical analysis of conditional coding for inter frames and show in which cases gains compared to traditional residual coding can be expected. We also show the effect of information bottlenecks which can occur in practical video coders in the prediction signal path due to the network structure, as a consequence of the data-processing theorem or due to quantization. We demonstrate that conditional coding has theoretical benefits over residual coding but that there are cases in which the benefits are quickly canceled by small information bottlenecks of the prediction signal.
Unsupervised Dense Nuclei Detection and Segmentation with Prior Self-activation Map For Histology Images
Oct 14, 2022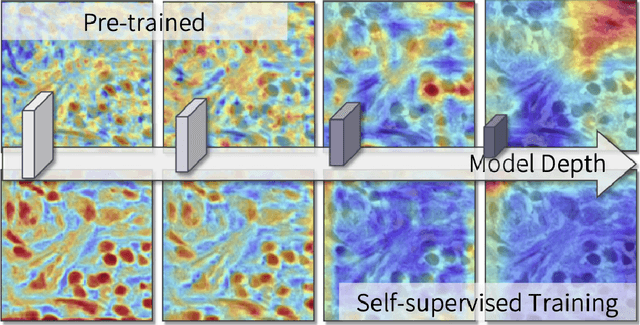
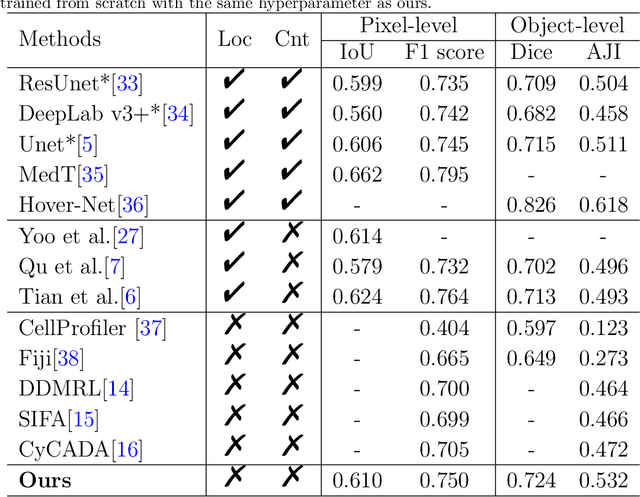
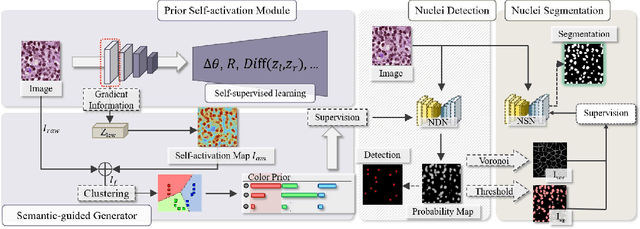

The success of supervised deep learning models in medical image segmentation relies on detailed annotations. However, labor-intensive manual labeling is costly and inefficient, especially in dense object segmentation. To this end, we propose a self-supervised learning based approach with a Prior Self-activation Module (PSM) that generates self-activation maps from the input images to avoid labeling costs and further produce pseudo masks for the downstream task. To be specific, we firstly train a neural network using self-supervised learning and utilize the gradient information in the shallow layers of the network to generate self-activation maps. Afterwards, a semantic-guided generator is then introduced as a pipeline to transform visual representations from PSM to pixel-level semantic pseudo masks for downstream tasks. Furthermore, a two-stage training module, consisting of a nuclei detection network and a nuclei segmentation network, is adopted to achieve the final segmentation. Experimental results show the effectiveness on two public pathological datasets. Compared with other fully-supervised and weakly-supervised methods, our method can achieve competitive performance without any manual annotations.