 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Computer Vision for Supporting Image Search
Nov 16, 2021
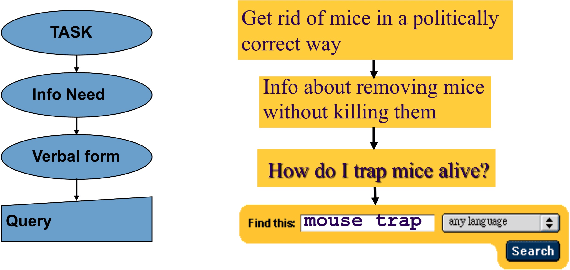
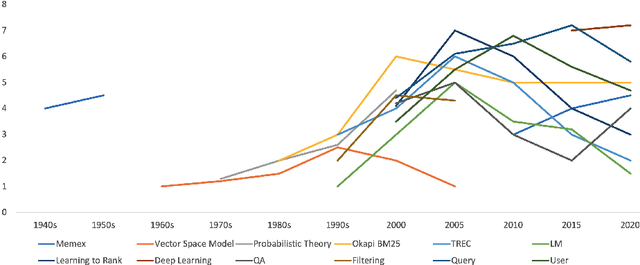
Computer vision and multimedia information processing have made extreme progress within the last decade and many tasks can be done with a level of accuracy as if done by humans, or better. This is because we leverage the benefits of huge amounts of data available for training, we have enormous computer processing available and we have seen the evolution of machine learning as a suite of techniques to process data and deliver accurate vision-based systems. What kind of applications do we use this processing for ? We use this in autonomous vehicle navigation or in security applications, searching CCTV for example, and in medical image analysis for healthcare diagnostics. One application which is not widespread is image or video search directly by users. In this paper we present the need for such image finding or re-finding by examining human memory and when it fails, thus motivating the need for a different approach to image search which is outlined, along with the requirements of computer vision to support it.
* 10 pages
Zero-Shot Sketch Based Image Retrieval using Graph Transformer
Jan 25, 2022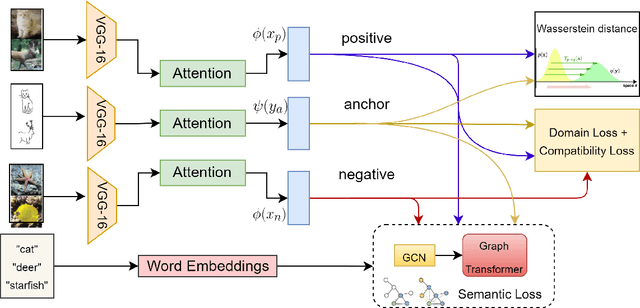
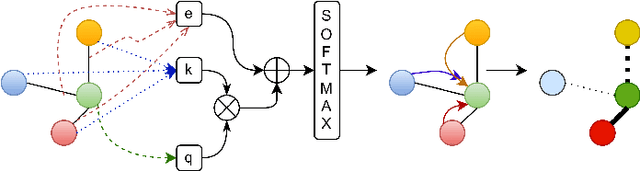

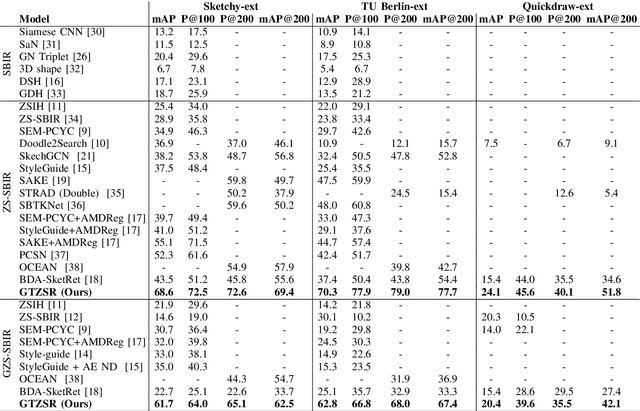
The performance of a zero-shot sketch-based image retrieval (ZS-SBIR) task is primarily affected by two challenges. The substantial domain gap between image and sketch features needs to be bridged, while at the same time the side information has to be chosen tactfully. Existing literature has shown that varying the semantic side information greatly affects the performance of ZS-SBIR. To this end, we propose a novel graph transformer based zero-shot sketch-based image retrieval (GTZSR) framework for solving ZS-SBIR tasks which uses a novel graph transformer to preserve the topology of the classes in the semantic space and propagates the context-graph of the classes within the embedding features of the visual space. To bridge the domain gap between the visual features, we propose minimizing the Wasserstein distance between images and sketches in a learned domain-shared space. We also propose a novel compatibility loss that further aligns the two visual domains by bridging the domain gap of one class with respect to the domain gap of all other classes in the training set. Experimental results obtained on the extended Sketchy, TU-Berlin, and QuickDraw datasets exhibit sharp improvements over the existing state-of-the-art methods in both ZS-SBIR and generalized ZS-SBIR.
Improving Deep Image Matting Via Local Smoothness Assumption
Dec 27, 2021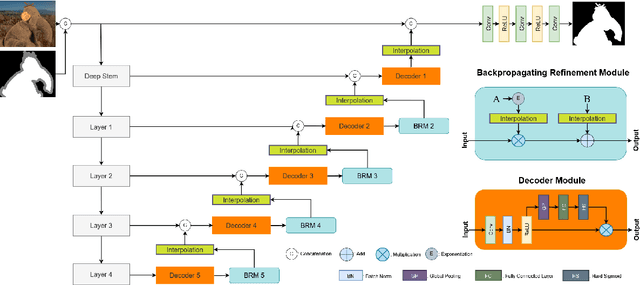
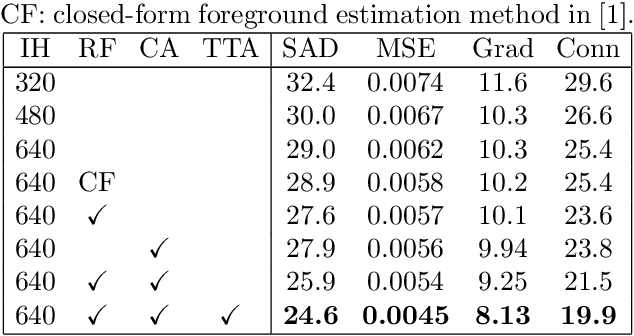

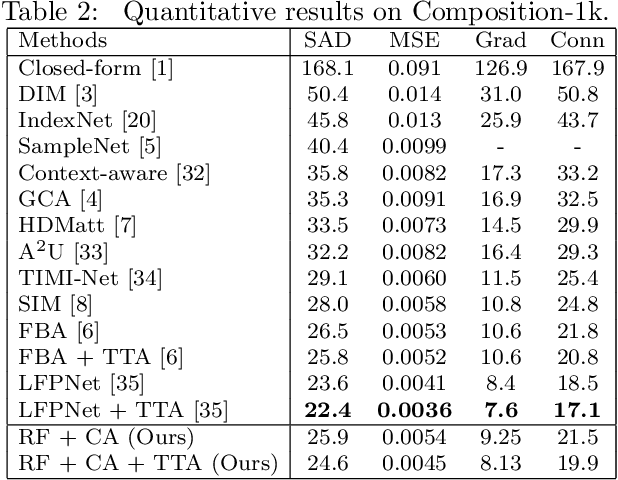
Natural image matting is a fundamental and challenging computer vision task. Conventionally, the problem is formulated as an underconstrained problem. Since the problem is ill-posed, further assumptions on the data distribution are required to make the problem well-posed. For classical matting methods, a commonly adopted assumption is the local smoothness assumption on foreground and background colors. However, the use of such assumptions was not systematically considered for deep learning based matting methods. In this work, we consider two local smoothness assumptions which can help improving deep image matting models. Based on the local smoothness assumptions, we propose three techniques, i.e., training set refinement, color augmentation and backpropagating refinement, which can improve the performance of the deep image matting model significantly. We conduct experiments to examine the effectiveness of the proposed algorithm. The experimental results show that the proposed method has favorable performance compared with existing matting methods.
Depth Is All You Need for Monocular 3D Detection
Oct 05, 2022

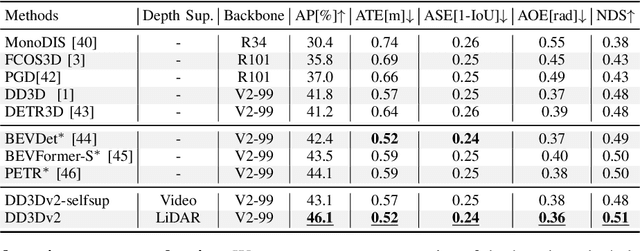
A key contributor to recent progress in 3D detection from single images is monocular depth estimation. Existing methods focus on how to leverage depth explicitly, by generating pseudo-pointclouds or providing attention cues for image features. More recent works leverage depth prediction as a pretraining task and fine-tune the depth representation while training it for 3D detection. However, the adaptation is insufficient and is limited in scale by manual labels. In this work, we propose to further align depth representation with the target domain in unsupervised fashions. Our methods leverage commonly available LiDAR or RGB videos during training time to fine-tune the depth representation, which leads to improved 3D detectors. Especially when using RGB videos, we show that our two-stage training by first generating pseudo-depth labels is critical because of the inconsistency in loss distribution between the two tasks. With either type of reference data, our multi-task learning approach improves over the state of the art on both KITTI and NuScenes, while matching the test-time complexity of its single task sub-network.
GMFIM: A Generative Mask-guided Facial Image Manipulation Model for Privacy Preservation
Jan 10, 2022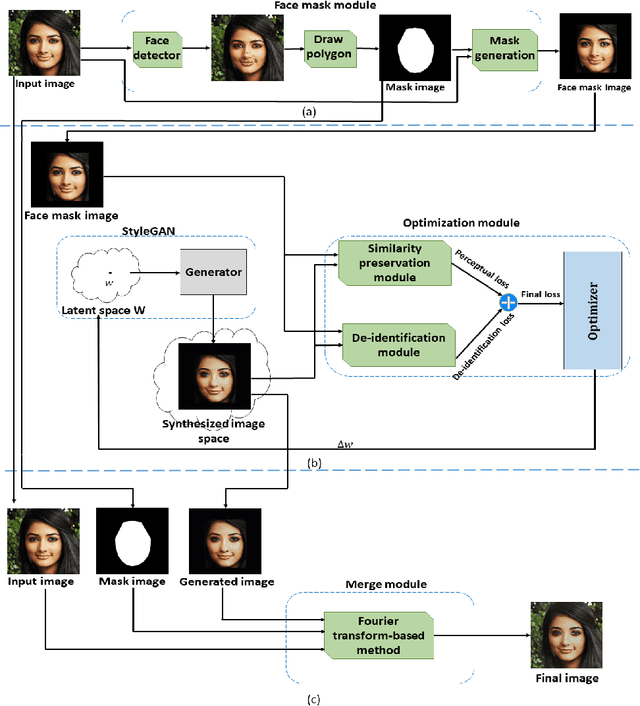



The use of social media websites and applications has become very popular and people share their photos on these networks. Automatic recognition and tagging of people's photos on these networks has raised privacy preservation issues and users seek methods for hiding their identities from these algorithms. Generative adversarial networks (GANs) are shown to be very powerful in generating face images in high diversity and also in editing face images. In this paper, we propose a Generative Mask-guided Face Image Manipulation (GMFIM) model based on GANs to apply imperceptible editing to the input face image to preserve the privacy of the person in the image. Our model consists of three main components: a) the face mask module to cut the face area out of the input image and omit the background, b) the GAN-based optimization module for manipulating the face image and hiding the identity and, c) the merge module for combining the background of the input image and the manipulated de-identified face image. Different criteria are considered in the loss function of the optimization step to produce high-quality images that are as similar as possible to the input image while they cannot be recognized by AFR systems. The results of the experiments on different datasets show that our model can achieve better performance against automated face recognition systems in comparison to the state-of-the-art methods and it catches a higher attack success rate in most experiments from a total of 18. Moreover, the generated images of our proposed model have the highest quality and are more pleasing to human eyes.
Universal Efficient Variable-rate Neural Image Compression
Nov 18, 2021
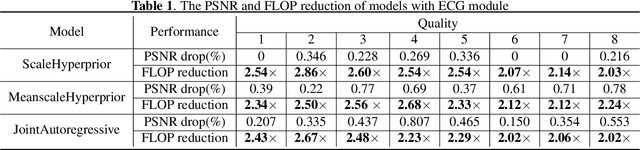
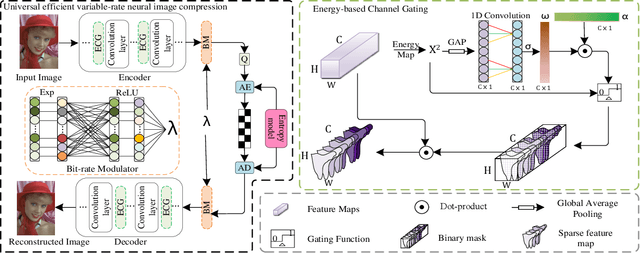
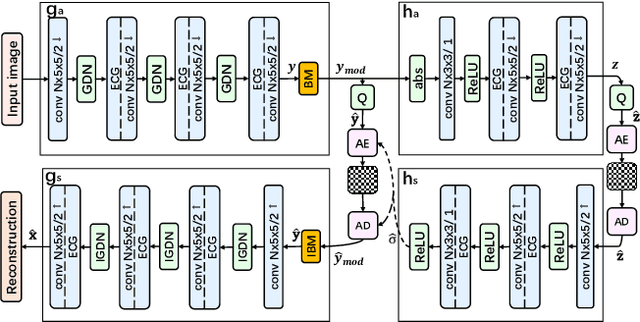
Recently, Learning-based image compression has reached comparable performance with traditional image codecs(such as JPEG, BPG, WebP). However, computational complexity and rate flexibility are still two major challenges for its practical deployment. To tackle these problems, this paper proposes two universal modules named Energy-based Channel Gating(ECG) and Bit-rate Modulator(BM), which can be directly embedded into existing end-to-end image compression models. ECG uses dynamic pruning to reduce FLOPs for more than 50\% in convolution layers, and a BM pair can modulate the latent representation to control the bit-rate in a channel-wise manner. By implementing these two modules, existing learning-based image codecs can obtain ability to output arbitrary bit-rate with a single model and reduced computation.
A reconstruction method for binary limited-data tomography using a dictionary-based sparse shape recovery
Aug 14, 2022


Binary tomography is concerned with reconstructing a binary image from a very small number or other limited CT projection data. This problem itself not only possesses several medical imaging applications but also can be considered a model of general inverse problems to recover the object shape from limited measured data. Several approaches such as the Mumford-Shah method and various level-set methods have been investigated, but most of them lead to a non-convex optimization due to the difficulty to handle the binary constraint. We propose a new method based on a convex optimization inspired by dictionary-based shape recovery. In the proposed method, the object boundary of the binary image is represented by a level set of linear combinations of basis vectors in the dictionary. Using the dictionary, the object boundary is reconstructed by finding weights of the linear combination that best match the measured data. We create the dictionary by using the Gaussian radial basis function (GRBF). More concretely, we use Gaussian functions as a basis function placed at sparse grid points to represent the parametric level-set function and provide more flexibility in the binary representation of the reconstructed image. The simulation results of CT image reconstruction from only four projection data demonstrate that the proposed method can recover the object boundary more accurately compared with other competitive methods. The significance of our approach is the formulation with a tractable convex program while keeping moderate mathematical rigorousness.
Fine-Grained Semantically Aligned Vision-Language Pre-Training
Aug 04, 2022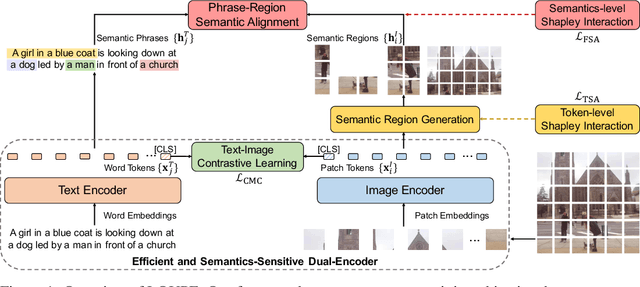
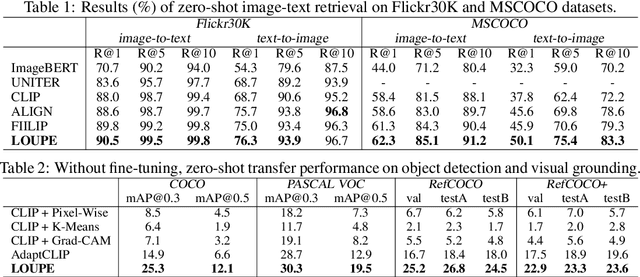
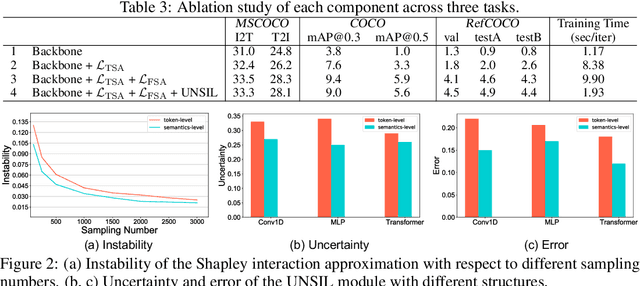

Large-scale vision-language pre-training has shown impressive advances in a wide range of downstream tasks. Existing methods mainly model the cross-modal alignment by the similarity of the global representations of images and texts, or advanced cross-modal attention upon image and text features. However, they fail to explicitly learn the fine-grained semantic alignment between visual regions and textual phrases, as only global image-text alignment information is available. In this paper, we introduce LOUPE, a fine-grained semantically aLigned visiOn-langUage PrE-training framework, which learns fine-grained semantic alignment from the novel perspective of game-theoretic interactions. To efficiently compute the game-theoretic interactions, we further propose an uncertainty-aware neural Shapley interaction learning module. Experiments show that LOUPE achieves state-of-the-art on image-text retrieval benchmarks. Without any object-level human annotations and fine-tuning, LOUPE achieves competitive performance on object detection and visual grounding. More importantly, LOUPE opens a new promising direction of learning fine-grained semantics from large-scale raw image-text pairs.
2-speed network ensemble for efficient classification of incremental land-use/land-cover satellite image chips
Mar 15, 2022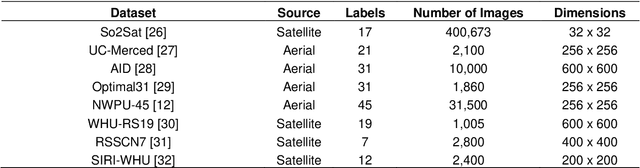
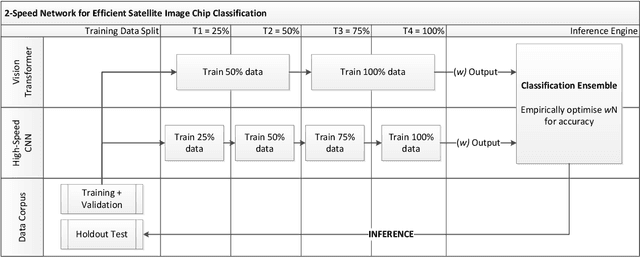


The ever-growing volume of satellite imagery data presents a challenge for industry and governments making data-driven decisions based on the timely analysis of very large data sets. Commonly used deep learning algorithms for automatic classification of satellite images are time and resource-intensive to train. The cost of retraining in the context of Big Data presents a practical challenge when new image data and/or classes are added to a training corpus. Recognizing the need for an adaptable, accurate, and scalable satellite image chip classification scheme, in this research we present an ensemble of: i) a slow to train but high accuracy vision transformer; and ii) a fast to train, low-parameter convolutional neural network. The vision transformer model provides a scalable and accurate foundation model. The high-speed CNN provides an efficient means of incorporating newly labelled data into analysis, at the expense of lower accuracy. To simulate incremental data, the very large (~400,000 images) So2Sat LCZ42 satellite image chip dataset is divided into four intervals, with the high-speed CNN retrained every interval and the vision transformer trained every half interval. This experimental setup mimics an increase in data volume and diversity over time. For the task of automated land-cover/land-use classification, the ensemble models for each data increment outperform each of the component models, with best accuracy of 65% against a holdout test partition of the So2Sat dataset. The proposed ensemble and staggered training schedule provide a scalable and cost-effective satellite image classification scheme that is optimized to process very large volumes of satellite data.
Factorisation-based Image Labelling
Nov 19, 2021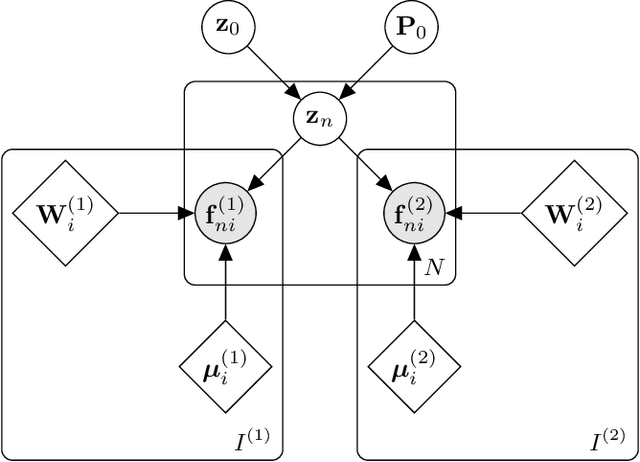
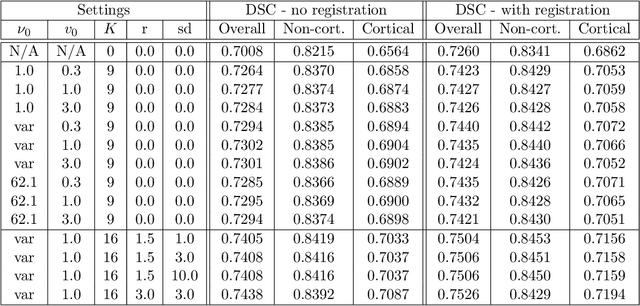
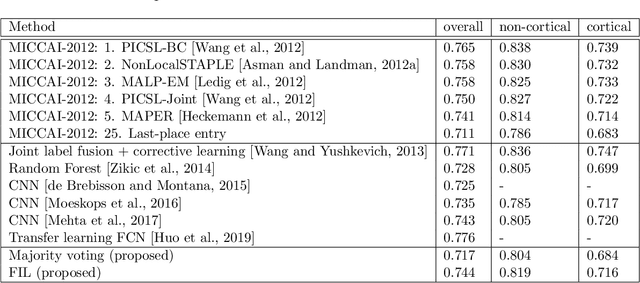
Segmentation of brain magnetic resonance images (MRI) into anatomical regions is a useful task in neuroimaging. Manual annotation is time consuming and expensive, so having a fully automated and general purpose brain segmentation algorithm is highly desirable. To this end, we propose a patched-based label propagation approach based on a generative model with latent variables. Once trained, our Factorisation-based Image Labelling (FIL) model is able to label target images with a variety of image contrasts. We compare the effectiveness of our proposed model against the state-of-the-art using data from the MICCAI 2012 Grand Challenge and Workshop on Multi-Atlas Labeling. As our approach is intended to be general purpose, we also assess how well it can handle domain shift by labelling images of the same subjects acquired with different MR contrasts.