 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Super-Resolution as Text-Guided Details Generation
Jul 14, 2022


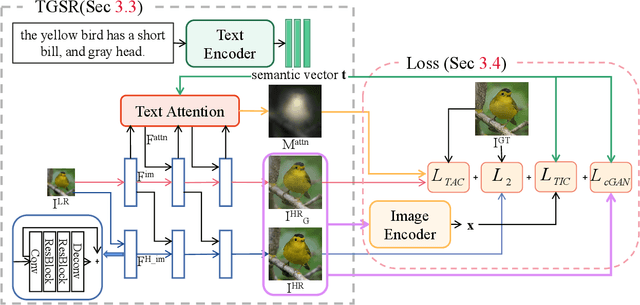
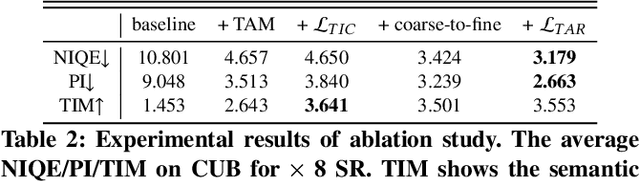
Deep neural networks have greatly promoted the performance of single image super-resolution (SISR). Conventional methods still resort to restoring the single high-resolution (HR) solution only based on the input of image modality. However, the image-level information is insufficient to predict adequate details and photo-realistic visual quality facing large upscaling factors (x8, x16). In this paper, we propose a new perspective that regards the SISR as a semantic image detail enhancement problem to generate semantically reasonable HR image that are faithful to the ground truth. To enhance the semantic accuracy and the visual quality of the reconstructed image, we explore the multi-modal fusion learning in SISR by proposing a Text-Guided Super-Resolution (TGSR) framework, which can effectively utilize the information from the text and image modalities. Different from existing methods, the proposed TGSR could generate HR image details that match the text descriptions through a coarse-to-fine process. Extensive experiments and ablation studies demonstrate the effect of the TGSR, which exploits the text reference to recover realistic images.
A Data Cube of Big Satellite Image Time-Series for Agriculture Monitoring
May 16, 2022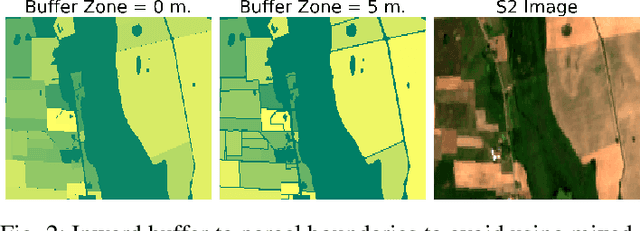

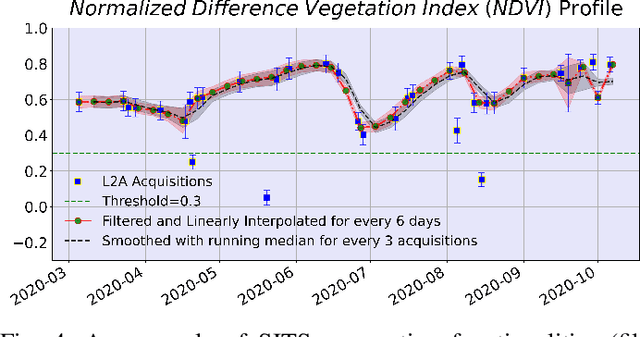
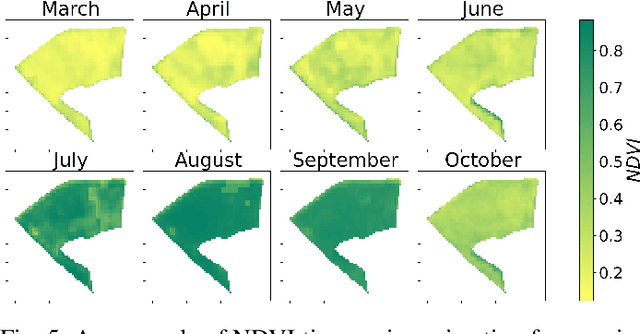
The modernization of the Common Agricultural Policy (CAP) requires the large scale and frequent monitoring of agricultural land. Towards this direction, the free and open satellite data (i.e., Sentinel missions) have been extensively used as the sources for the required high spatial and temporal resolution Earth observations. Nevertheless, monitoring the CAP at large scales constitutes a big data problem and puts a strain on CAP paying agencies that need to adapt fast in terms of infrastructure and know-how. Hence, there is a need for efficient and easy-to-use tools for the acquisition, storage, processing and exploitation of big satellite data. In this work, we present the Agriculture monitoring Data Cube (ADC), which is an automated, modular, end-to-end framework for discovering, pre-processing and indexing optical and Synthetic Aperture Radar (SAR) images into a multidimensional cube. We also offer a set of powerful tools on top of the ADC, including i) the generation of analysis-ready feature spaces of big satellite data to feed downstream machine learning tasks and ii) the support of Satellite Image Time-Series (SITS) analysis via services pertinent to the monitoring of the CAP (e.g., detecting trends and events, monitoring the growth status etc.). The knowledge extracted from the SITS analyses and the machine learning tasks returns to the data cube, building scalable country-specific knowledge bases that can efficiently answer complex and multi-faceted geospatial queries.
Towards a unified view of unsupervised non-local methods for image denoising: the NL-Ridge approach
Mar 01, 2022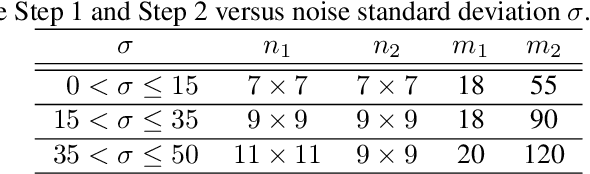

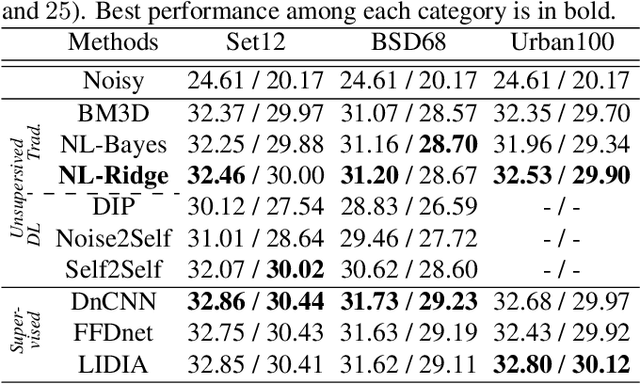
We propose a unified view of unsupervised non-local methods for image denoising that linearily combine noisy image patches. The best methods, established in different modeling and estimation frameworks, are two-step algorithms. Leveraging Stein's unbiased risk estimate (SURE) for the first step and the "internal adaptation", a concept borrowed from deep learning theory, for the second one, we show that our NL-Ridge approach enables to reconcile several patch aggregation methods for image denoising. In the second step, our closed-form aggregation weights are computed through multivariate Ridge regressions. Experiments on artificially noisy images demonstrate that NL-Ridge may outperform well established state-of-the-art unsupervised denoisers such as BM3D and NL-Bayes, as well as recent unsupervised deep learning methods, while being simpler conceptually.
Computer Vision for Supporting Image Search
Nov 16, 2021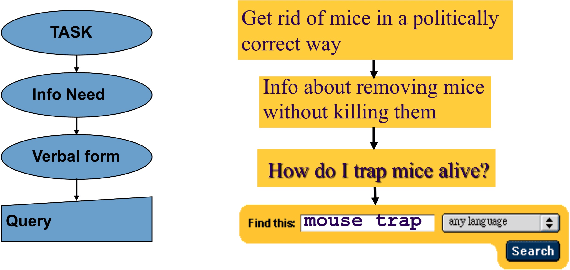
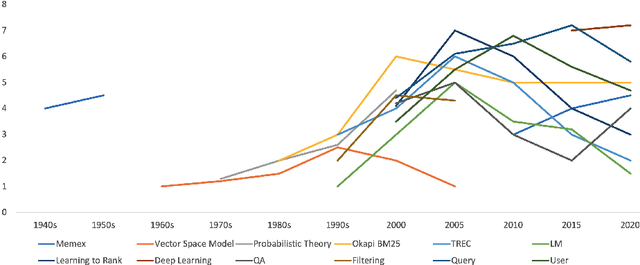
Computer vision and multimedia information processing have made extreme progress within the last decade and many tasks can be done with a level of accuracy as if done by humans, or better. This is because we leverage the benefits of huge amounts of data available for training, we have enormous computer processing available and we have seen the evolution of machine learning as a suite of techniques to process data and deliver accurate vision-based systems. What kind of applications do we use this processing for ? We use this in autonomous vehicle navigation or in security applications, searching CCTV for example, and in medical image analysis for healthcare diagnostics. One application which is not widespread is image or video search directly by users. In this paper we present the need for such image finding or re-finding by examining human memory and when it fails, thus motivating the need for a different approach to image search which is outlined, along with the requirements of computer vision to support it.
* 10 pages
CheXRelNet: An Anatomy-Aware Model for Tracking Longitudinal Relationships between Chest X-Rays
Aug 08, 2022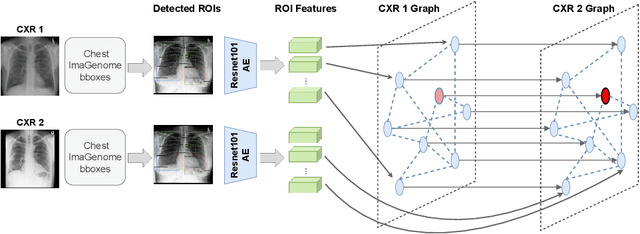
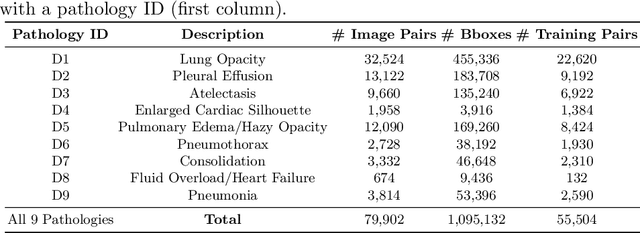
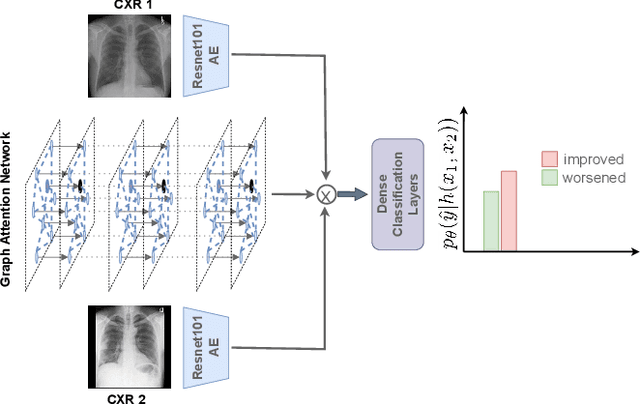
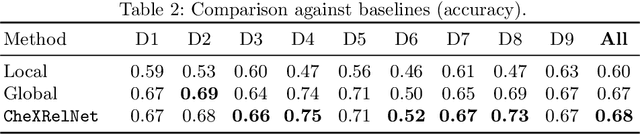
Despite the progress in utilizing deep learning to automate chest radiograph interpretation and disease diagnosis tasks, change between sequential Chest X-rays (CXRs) has received limited attention. Monitoring the progression of pathologies that are visualized through chest imaging poses several challenges in anatomical motion estimation and image registration, i.e., spatially aligning the two images and modeling temporal dynamics in change detection. In this work, we propose CheXRelNet, a neural model that can track longitudinal pathology change relations between two CXRs. CheXRelNet incorporates local and global visual features, utilizes inter-image and intra-image anatomical information, and learns dependencies between anatomical region attributes, to accurately predict disease change for a pair of CXRs. Experimental results on the Chest ImaGenome dataset show increased downstream performance compared to baselines. Code is available at https://github.com/PLAN-Lab/ChexRelNet
Zero-Shot Sketch Based Image Retrieval using Graph Transformer
Jan 25, 2022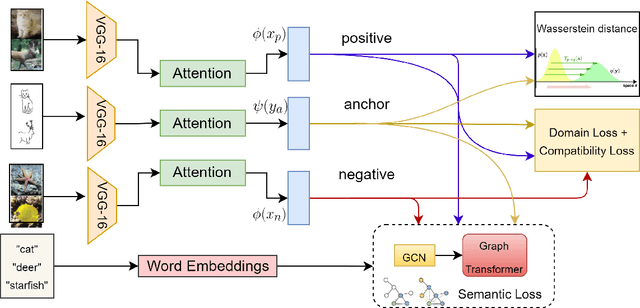
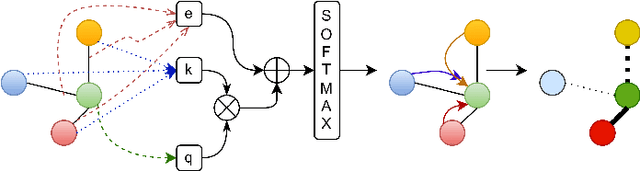

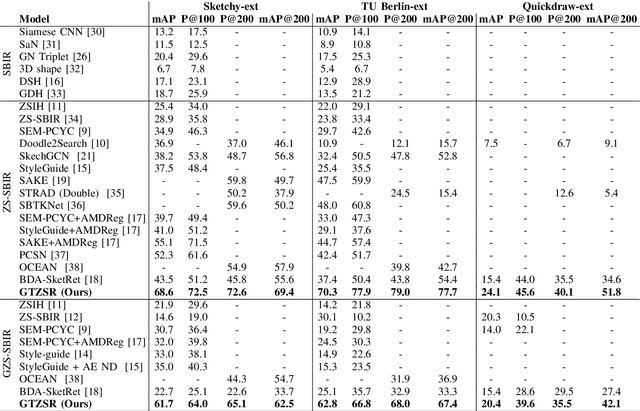
The performance of a zero-shot sketch-based image retrieval (ZS-SBIR) task is primarily affected by two challenges. The substantial domain gap between image and sketch features needs to be bridged, while at the same time the side information has to be chosen tactfully. Existing literature has shown that varying the semantic side information greatly affects the performance of ZS-SBIR. To this end, we propose a novel graph transformer based zero-shot sketch-based image retrieval (GTZSR) framework for solving ZS-SBIR tasks which uses a novel graph transformer to preserve the topology of the classes in the semantic space and propagates the context-graph of the classes within the embedding features of the visual space. To bridge the domain gap between the visual features, we propose minimizing the Wasserstein distance between images and sketches in a learned domain-shared space. We also propose a novel compatibility loss that further aligns the two visual domains by bridging the domain gap of one class with respect to the domain gap of all other classes in the training set. Experimental results obtained on the extended Sketchy, TU-Berlin, and QuickDraw datasets exhibit sharp improvements over the existing state-of-the-art methods in both ZS-SBIR and generalized ZS-SBIR.
Improving Deep Image Matting Via Local Smoothness Assumption
Dec 27, 2021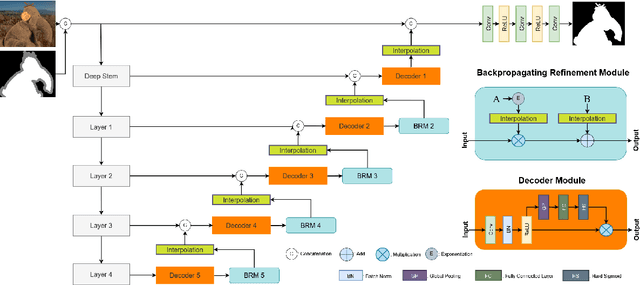
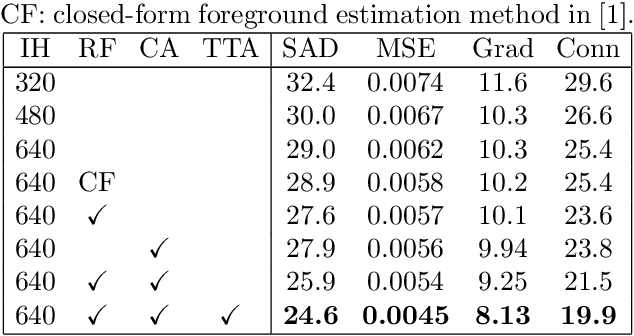

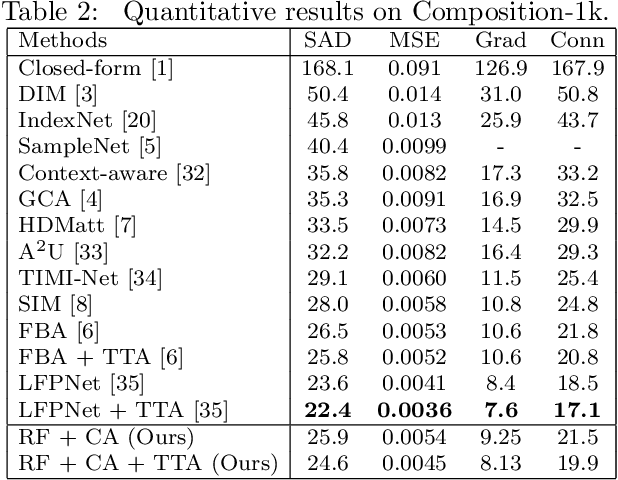
Natural image matting is a fundamental and challenging computer vision task. Conventionally, the problem is formulated as an underconstrained problem. Since the problem is ill-posed, further assumptions on the data distribution are required to make the problem well-posed. For classical matting methods, a commonly adopted assumption is the local smoothness assumption on foreground and background colors. However, the use of such assumptions was not systematically considered for deep learning based matting methods. In this work, we consider two local smoothness assumptions which can help improving deep image matting models. Based on the local smoothness assumptions, we propose three techniques, i.e., training set refinement, color augmentation and backpropagating refinement, which can improve the performance of the deep image matting model significantly. We conduct experiments to examine the effectiveness of the proposed algorithm. The experimental results show that the proposed method has favorable performance compared with existing matting methods.
Semi-supervised Semantic Segmentation with Mutual Knowledge Distillation
Aug 30, 2022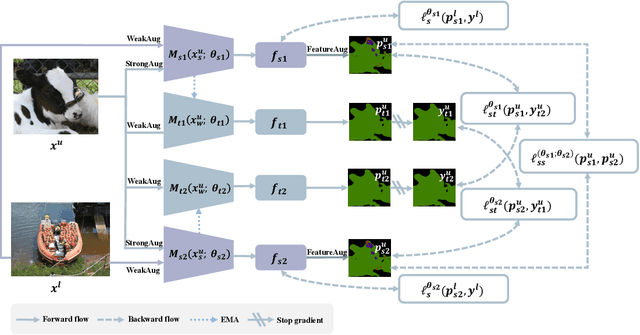
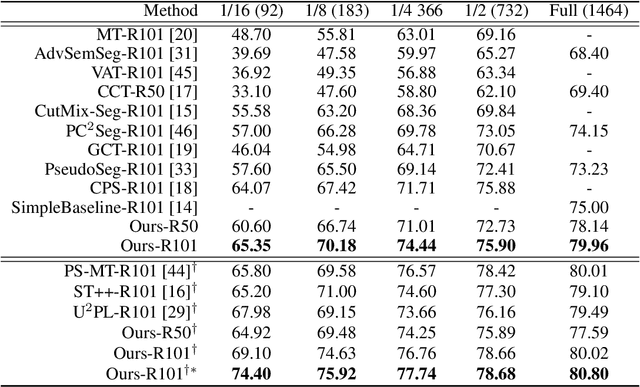
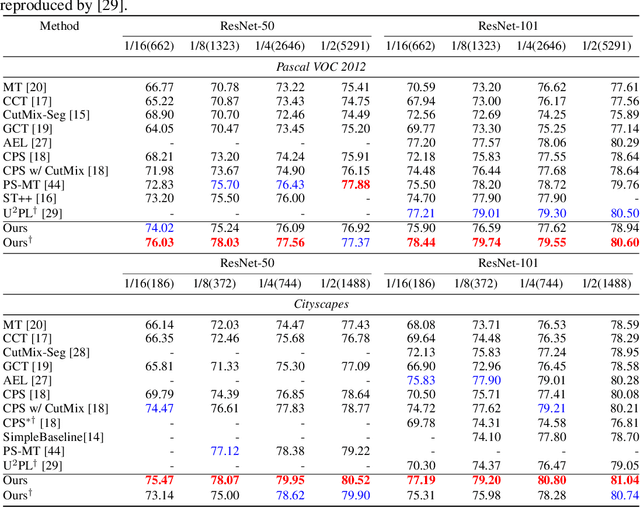

Consistency regularization has been widely studied in recent semi-supervised semantic segmentation methods. Remarkable performance has been achieved, benefiting from image, feature, and network perturbations. To make full use of these perturbations, in this work, we propose a new consistency regularization framework called mutual knowledge distillation (MKD). We innovatively introduce two auxiliary mean-teacher models based on the consistency regularization method. More specifically, we use the pseudo label generated by one mean teacher to supervise the other student network to achieve a mutual knowledge distillation between two branches. In addition to using image-level strong and weak augmentation, we also employ feature augmentation considering implicit semantic distributions to add further perturbations to the students. The proposed framework significantly increases the diversity of the training samples. Extensive experiments on public benchmarks show that our framework outperforms previous state-of-the-art(SOTA) methods under various semi-supervised settings. Code is available at: https://github.com/jianlong-yuan/semi-mmseg.
Self-Ensembling Vision Transformer (SEViT) for Robust Medical Image Classification
Aug 04, 2022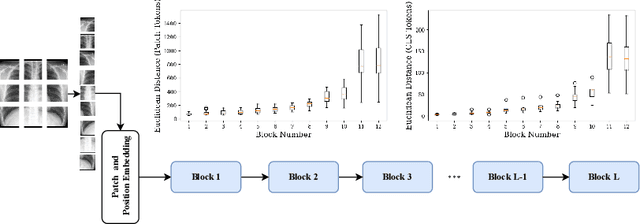

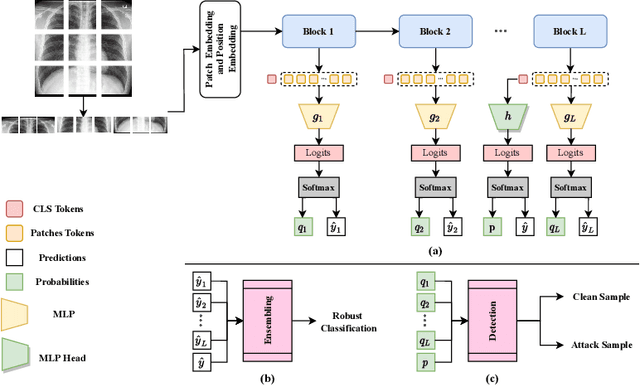
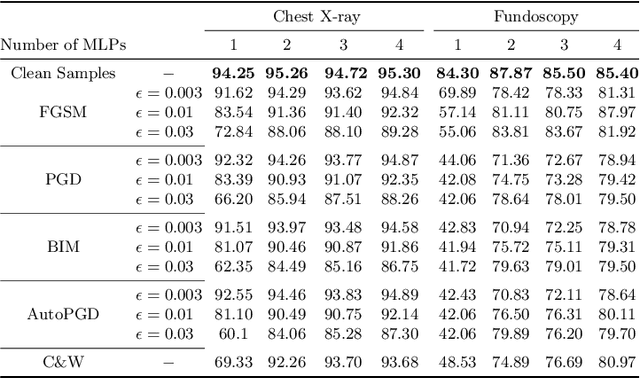
Vision Transformers (ViT) are competing to replace Convolutional Neural Networks (CNN) for various computer vision tasks in medical imaging such as classification and segmentation. While the vulnerability of CNNs to adversarial attacks is a well-known problem, recent works have shown that ViTs are also susceptible to such attacks and suffer significant performance degradation under attack. The vulnerability of ViTs to carefully engineered adversarial samples raises serious concerns about their safety in clinical settings. In this paper, we propose a novel self-ensembling method to enhance the robustness of ViT in the presence of adversarial attacks. The proposed Self-Ensembling Vision Transformer (SEViT) leverages the fact that feature representations learned by initial blocks of a ViT are relatively unaffected by adversarial perturbations. Learning multiple classifiers based on these intermediate feature representations and combining these predictions with that of the final ViT classifier can provide robustness against adversarial attacks. Measuring the consistency between the various predictions can also help detect adversarial samples. Experiments on two modalities (chest X-ray and fundoscopy) demonstrate the efficacy of SEViT architecture to defend against various adversarial attacks in the gray-box (attacker has full knowledge of the target model, but not the defense mechanism) setting. Code: https://github.com/faresmalik/SEViT
Creative Painting with Latent Diffusion Models
Sep 30, 2022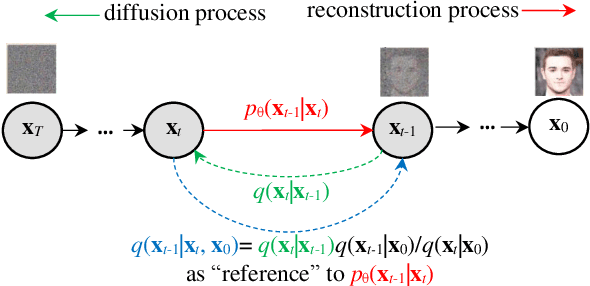
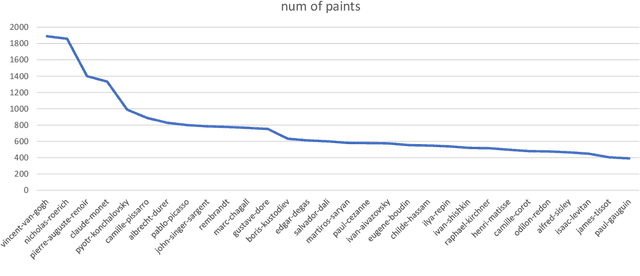
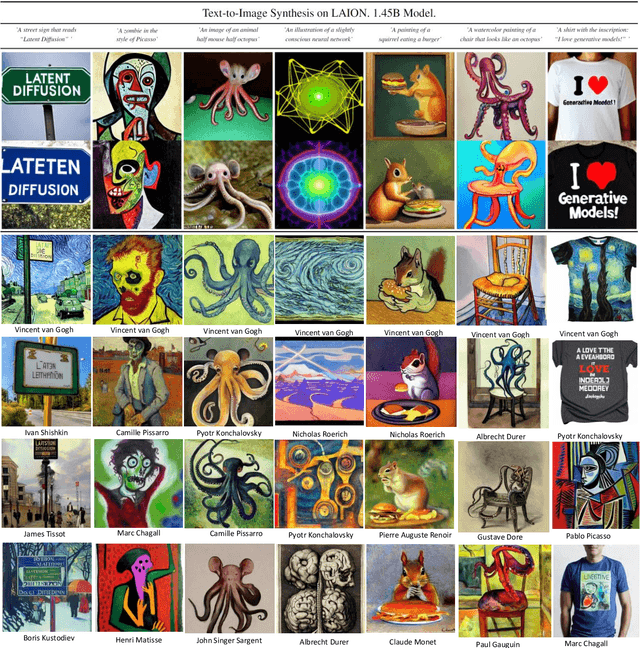
Artistic painting has achieved significant progress during recent years. Using an autoencoder to connect the original images with compressed latent spaces and a cross attention enhanced U-Net as the backbone of diffusion, latent diffusion models (LDMs) have achieved stable and high fertility image generation. In this paper, we focus on enhancing the creative painting ability of current LDMs in two directions, textual condition extension and model retraining with Wikiart dataset. Through textual condition extension, users' input prompts are expanded with rich contextual knowledge for deeper understanding and explaining the prompts. Wikiart dataset contains 80K famous artworks drawn during recent 400 years by more than 1,000 famous artists in rich styles and genres. Through the retraining, we are able to ask these artists to draw novel and creative painting on modern topics. Direct comparisons with the original model show that the creativity and artistry are enriched.