 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HuPR: A Benchmark for Human Pose Estimation Using Millimeter Wave Radar
Oct 22, 2022



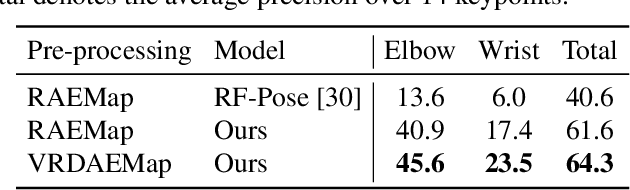
This paper introduces a novel human pose estimation benchmark, Human Pose with Millimeter Wave Radar (HuPR), that includes synchronized vision and radio signal components. This dataset is created using cross-calibrated mmWave radar sensors and a monocular RGB camera for cross-modality training of radar-based human pose estimation. There are two advantages of using mmWave radar to perform human pose estimation. First, it is robust to dark and low-light conditions. Second, it is not visually perceivable by humans and thus, can be widely applied to applications with privacy concerns, e.g., surveillance systems in patient rooms. In addition to the benchmark, we propose a cross-modality training framework that leverages the ground-truth 2D keypoints representing human body joints for training, which are systematically generated from the pre-trained 2D pose estimation network based on a monocular camera input image, avoiding laborious manual label annotation efforts. The framework consists of a new radar pre-processing method that better extracts the velocity information from radar data, Cross- and Self-Attention Module (CSAM), to fuse multi-scale radar features, and Pose Refinement Graph Convolutional Networks (PRGCN), to refine the predicted keypoint confidence heatmaps. Our intensive experiments on the HuPR benchmark show that the proposed scheme achieves better human pose estimation performance with only radar data, as compared to traditional pre-processing solutions and previous radio-frequency-based methods.
Federated Contrastive Learning for Volumetric Medical Image Segmentation
Apr 23, 2022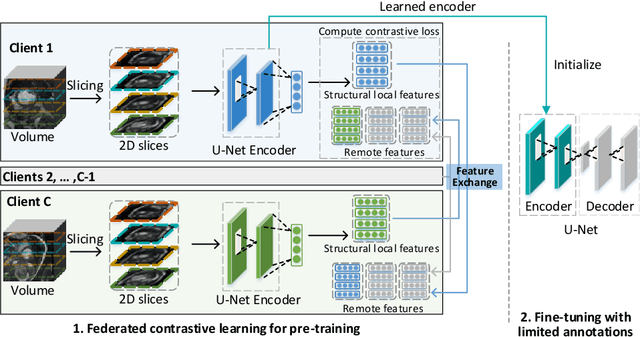
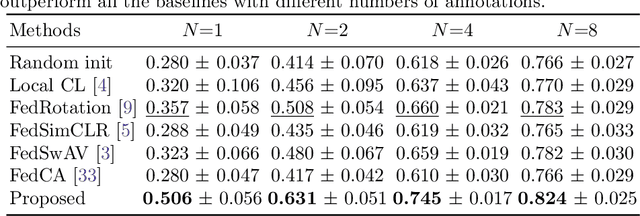
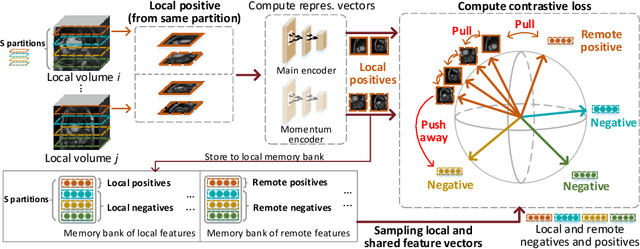

Supervised deep learning needs a large amount of labeled data to achieve high performance. However, in medical imaging analysis, each site may only have a limited amount of data and labels, which makes learning ineffective. Federated learning (FL) can help in this regard by learning a shared model while keeping training data local for privacy. Traditional FL requires fully-labeled data for training, which is inconvenient or sometimes infeasible to obtain due to high labeling cost and the requirement of expertise. Contrastive learning (CL), as a self-supervised learning approach, can effectively learn from unlabeled data to pre-train a neural network encoder, followed by fine-tuning for downstream tasks with limited annotations. However, when adopting CL in FL, the limited data diversity on each client makes federated contrastive learning (FCL) ineffective. In this work, we propose an FCL framework for volumetric medical image segmentation with limited annotations. More specifically, we exchange the features in the FCL pre-training process such that diverse contrastive data are provided to each site for effective local CL while keeping raw data private. Based on the exchanged features, global structural matching further leverages the structural similarity to align local features to the remote ones such that a unified feature space can be learned among different sites. Experiments on a cardiac MRI dataset show the proposed framework substantially improves the segmentation performance compared with state-of-the-art techniques.
Adversarial Defense via Image Denoising with Chaotic Encryption
Mar 19, 2022

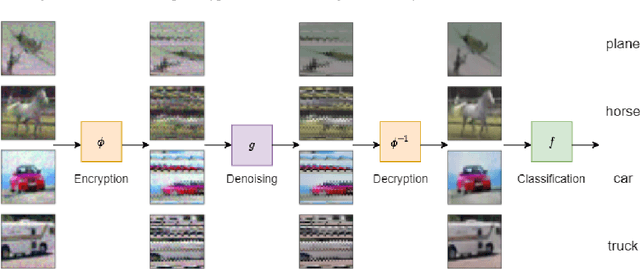
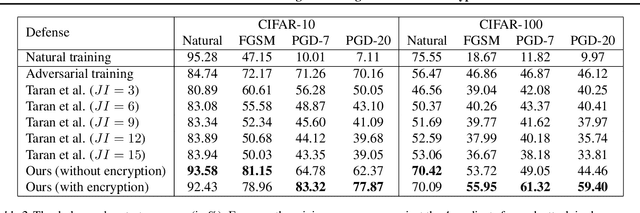
In the literature on adversarial examples, white box and black box attacks have received the most attention. The adversary is assumed to have either full (white) or no (black) access to the defender's model. In this work, we focus on the equally practical gray box setting, assuming an attacker has partial information. We propose a novel defense that assumes everything but a private key will be made available to the attacker. Our framework uses an image denoising procedure coupled with encryption via a discretized Baker map. Extensive testing against adversarial images (e.g. FGSM, PGD) crafted using various gradients shows that our defense achieves significantly better results on CIFAR-10 and CIFAR-100 than the state-of-the-art gray box defenses in both natural and adversarial accuracy.
Multi-Modal Fusion by Meta-Initialization
Oct 10, 2022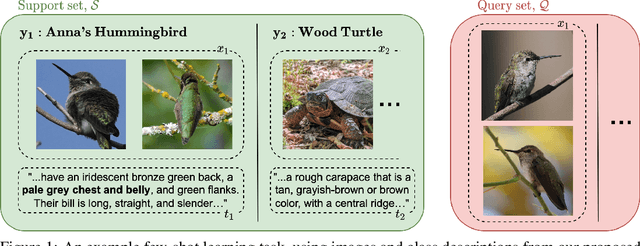
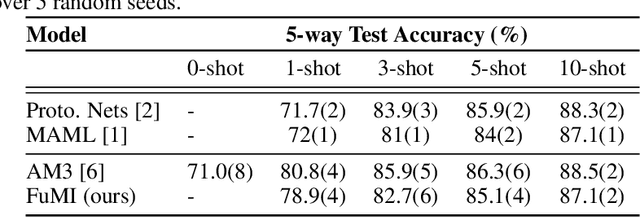
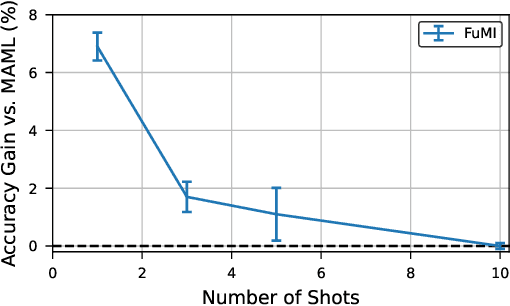
When experience is scarce, models may have insufficient information to adapt to a new task. In this case, auxiliary information - such as a textual description of the task - can enable improved task inference and adaptation. In this work, we propose an extension to the Model-Agnostic Meta-Learning algorithm (MAML), which allows the model to adapt using auxiliary information as well as task experience. Our method, Fusion by Meta-Initialization (FuMI), conditions the model initialization on auxiliary information using a hypernetwork, rather than learning a single, task-agnostic initialization. Furthermore, motivated by the shortcomings of existing multi-modal few-shot learning benchmarks, we constructed iNat-Anim - a large-scale image classification dataset with succinct and visually pertinent textual class descriptions. On iNat-Anim, FuMI significantly outperforms uni-modal baselines such as MAML in the few-shot regime. The code for this project and a dataset exploration tool for iNat-Anim are publicly available at https://github.com/s-a-malik/multi-few .
Not All Errors are Equal: Learning Text Generation Metrics using Stratified Error Synthesis
Oct 10, 2022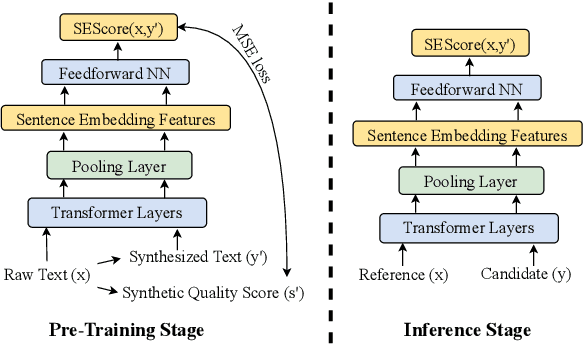


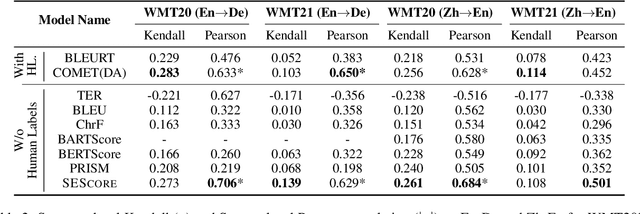
Is it possible to build a general and automatic natural language generation (NLG) evaluation metric? Existing learned metrics either perform unsatisfactorily or are restricted to tasks where large human rating data is already available. We introduce SESCORE, a model-based metric that is highly correlated with human judgements without requiring human annotation, by utilizing a novel, iterative error synthesis and severity scoring pipeline. This pipeline applies a series of plausible errors to raw text and assigns severity labels by simulating human judgements with entailment. We evaluate SESCORE against existing metrics by comparing how their scores correlate with human ratings. SESCORE outperforms all prior unsupervised metrics on multiple diverse NLG tasks including machine translation, image captioning, and WebNLG text generation. For WMT 20/21 En-De and Zh-En, SESCORE improve the average Kendall correlation with human judgement from 0.154 to 0.195. SESCORE even achieves comparable performance to the best supervised metric COMET, despite receiving no human-annotated training data.
DeepFGS: Fine-Grained Scalable Coding for Learned Image Compression
Jan 04, 2022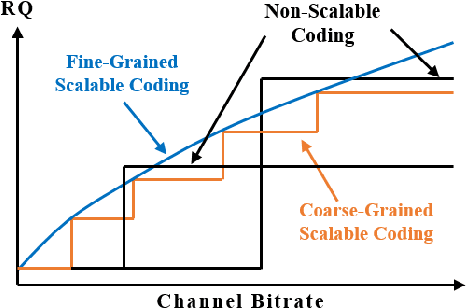

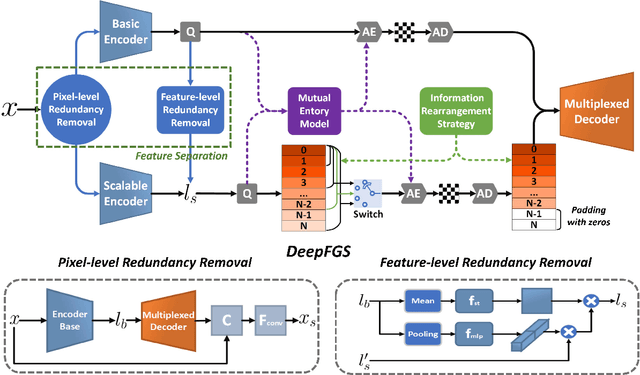
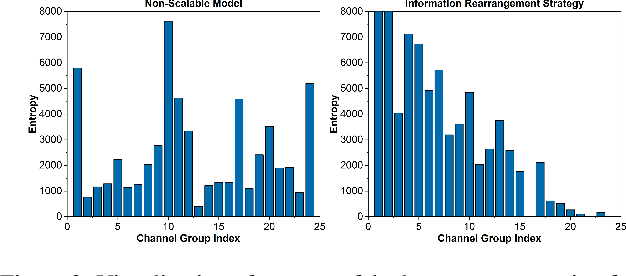
Scalable coding, which can adapt to channel bandwidth variation, performs well in today's complex network environment. However, the existing scalable compression methods face two challenges: reduced compression performance and insufficient scalability. In this paper, we propose the first learned fine-grained scalable image compression model (DeepFGS) to overcome the above two shortcomings. Specifically, we introduce a feature separation backbone to divide the image information into basic and scalable features, then redistribute the features channel by channel through an information rearrangement strategy. In this way, we can generate a continuously scalable bitstream via one-pass encoding. In addition, we reuse the decoder to reduce the parameters and computational complexity of DeepFGS. Experiments demonstrate that our DeepFGS outperforms all learning-based scalable image compression models and conventional scalable image codecs in PSNR and MS-SSIM metrics. To the best of our knowledge, our DeepFGS is the first exploration of learned fine-grained scalable coding, which achieves the finest scalability compared with learning-based methods.
NeurSF: Neural Shading Field for Image Harmonization
Dec 04, 2021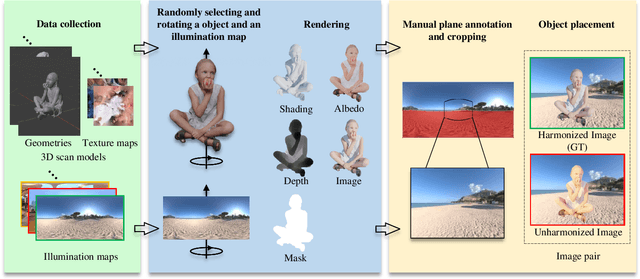

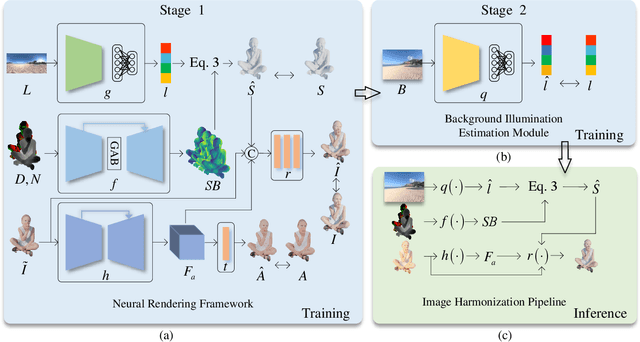
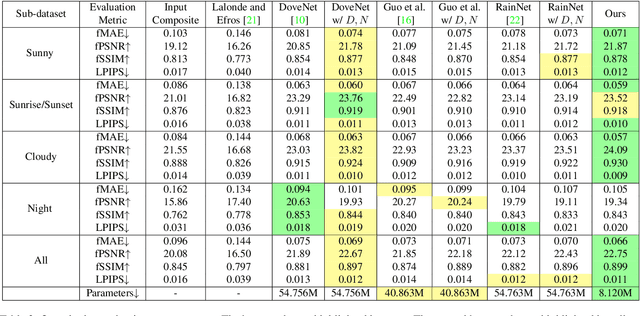
Image harmonization aims at adjusting the appearance of the foreground to make it more compatible with the background. Due to a lack of understanding of the background illumination direction, existing works are incapable of generating a realistic foreground shading. In this paper, we decompose the image harmonization into two sub-problems: 1) illumination estimation of background images and 2) rendering of foreground objects. Before solving these two sub-problems, we first learn a direction-aware illumination descriptor via a neural rendering framework, of which the key is a Shading Module that decomposes the shading field into multiple shading components given depth information. Then we design a Background Illumination Estimation Module to extract the direction-aware illumination descriptor from the background. Finally, the illumination descriptor is used in conjunction with the neural rendering framework to generate the harmonized foreground image containing a novel harmonized shading. Moreover, we construct a photo-realistic synthetic image harmonization dataset that contains numerous shading variations by image-based lighting. Extensive experiments on this dataset demonstrate the effectiveness of the proposed method. Our dataset and code will be made publicly available.
DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection
Sep 20, 2022

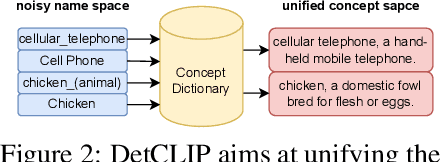

Open-world object detection, as a more general and challenging goal, aims to recognize and localize objects described by arbitrary category names. The recent work GLIP formulates this problem as a grounding problem by concatenating all category names of detection datasets into sentences, which leads to inefficient interaction between category names. This paper presents DetCLIP, a paralleled visual-concept pre-training method for open-world detection by resorting to knowledge enrichment from a designed concept dictionary. To achieve better learning efficiency, we propose a novel paralleled concept formulation that extracts concepts separately to better utilize heterogeneous datasets (i.e., detection, grounding, and image-text pairs) for training. We further design a concept dictionary~(with descriptions) from various online sources and detection datasets to provide prior knowledge for each concept. By enriching the concepts with their descriptions, we explicitly build the relationships among various concepts to facilitate the open-domain learning. The proposed concept dictionary is further used to provide sufficient negative concepts for the construction of the word-region alignment loss\, and to complete labels for objects with missing descriptions in captions of image-text pair data. The proposed framework demonstrates strong zero-shot detection performances, e.g., on the LVIS dataset, our DetCLIP-T outperforms GLIP-T by 9.9% mAP and obtains a 13.5% improvement on rare categories compared to the fully-supervised model with the same backbone as ours.
K-space and Image Domain Collaborative Energy based Model for Parallel MRI Reconstruction
Mar 21, 2022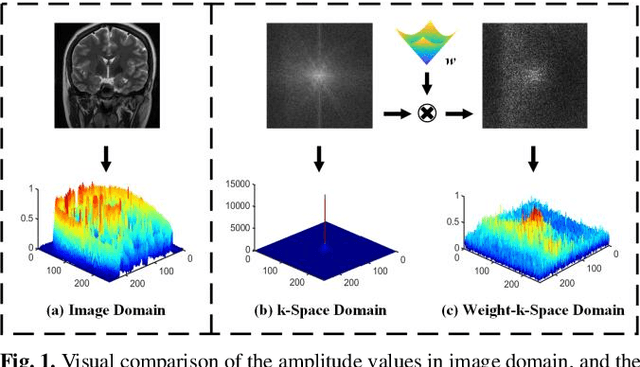
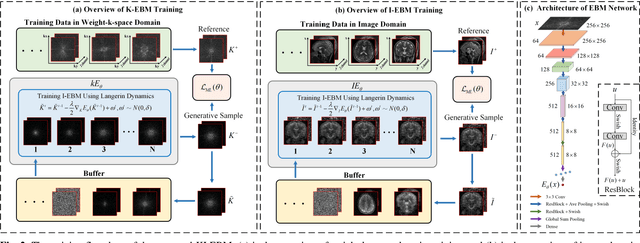
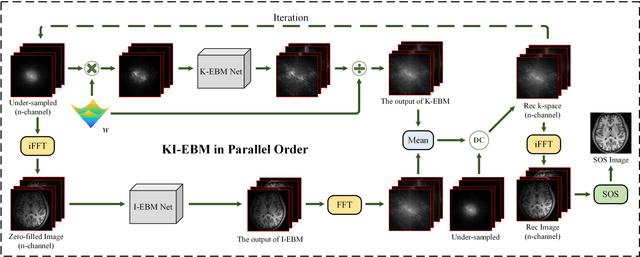
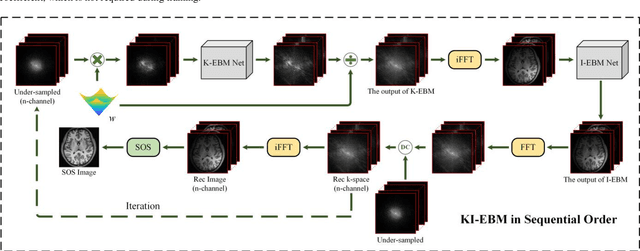
Decreasing magnetic resonance (MR) image acquisition times can potentially make MR examinations more accessible. Prior arts including the deep learning models have been devoted to solving the problem of long MRI imaging time. Recently, deep generative models have exhibited great potentials in algorithm robustness and usage flexibility. Nevertheless, no existing such schemes that can be learned or employed directly to the k-space measurement. Furthermore, how do the deep generative models work well in hybrid domain is also worth to be investigated. In this work, by taking advantage of the deep en-ergy-based models, we propose a k-space and image domain collaborative generative model to comprehensively estimate the MR data from under-sampled measurement. Experimental comparisons with the state-of-the-arts demonstrated that the proposed hybrid method has less error in reconstruction and is more stable under different acceleration factors.
Class-Aware Generative Adversarial Transformers for Medical Image Segmentation
Jan 28, 2022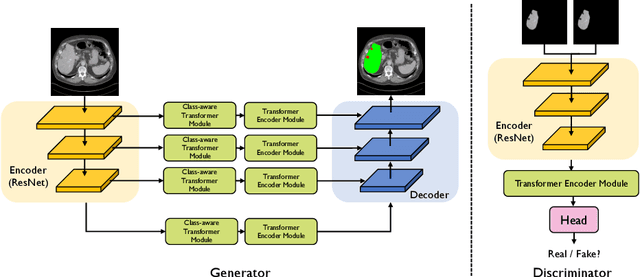
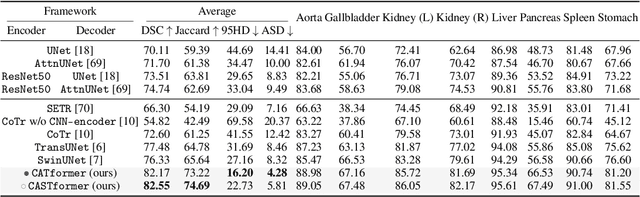
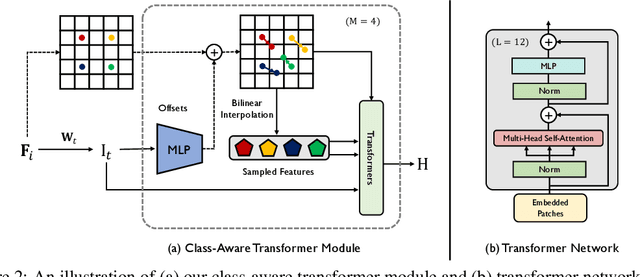
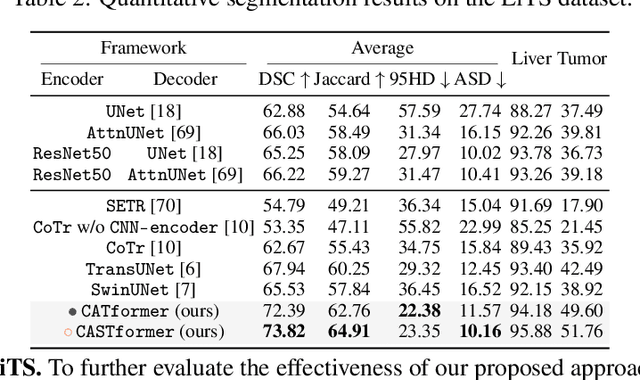
Transformers have made remarkable progress towards modeling long-range dependencies within the medical image analysis domain. However, current transformer-based models suffer from several disadvantages: (1) existing methods fail to capture the important features of the images due to the naive tokenization scheme; (2) the models suffer from information loss because they only consider single-scale feature representations; and (3) the segmentation label maps generated by the models are not accurate enough without considering rich semantic contexts and anatomical textures. In this work, we present CA-GANformer, a novel type of generative adversarial transformers, for medical image segmentation. First, we take advantage of the pyramid structure to construct multi-scale representations and handle multi-scale variations. We then design a novel class-aware transformer module to better learn the discriminative regions of objects with semantic structures. Lastly, we utilize an adversarial training strategy that boosts segmentation accuracy and correspondingly allows a transformer-based discriminator to capture high-level semantically correlated contents and low-level anatomical features. Our experiments demonstrate that CA-GANformer dramatically outperforms previous state-of-the-art transformer-based approaches on three benchmarks, obtaining 2.54%-5.88% absolute improvements in Dice over previous models. Further qualitative experiments provide a more detailed picture of the model's inner workings, shed light on the challenges in improved transparency, and demonstrate that transfer learning can greatly improve performance and reduce the size of medical image datasets in training, making CA-GANformer a strong starting point for downstream medical image analysis tasks. Codes and models will be available to the public.