 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scalable Neural Video Representations with Learnable Positional Features
Oct 13, 2022

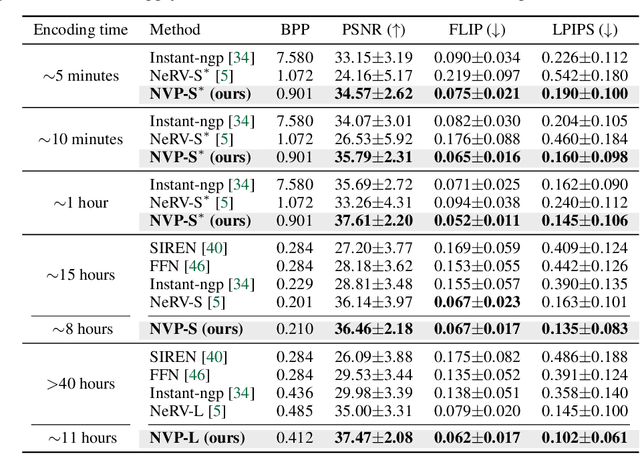
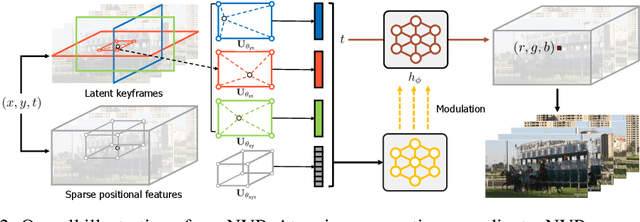

Succinct representation of complex signals using coordinate-based neural representations (CNRs) has seen great progress, and several recent efforts focus on extending them for handling videos. Here, the main challenge is how to (a) alleviate a compute-inefficiency in training CNRs to (b) achieve high-quality video encoding while (c) maintaining the parameter-efficiency. To meet all requirements (a), (b), and (c) simultaneously, we propose neural video representations with learnable positional features (NVP), a novel CNR by introducing "learnable positional features" that effectively amortize a video as latent codes. Specifically, we first present a CNR architecture based on designing 2D latent keyframes to learn the common video contents across each spatio-temporal axis, which dramatically improves all of those three requirements. Then, we propose to utilize existing powerful image and video codecs as a compute-/memory-efficient compression procedure of latent codes. We demonstrate the superiority of NVP on the popular UVG benchmark; compared with prior arts, NVP not only trains 2 times faster (less than 5 minutes) but also exceeds their encoding quality as 34.07$\rightarrow$34.57 (measured with the PSNR metric), even using $>$8 times fewer parameters. We also show intriguing properties of NVP, e.g., video inpainting, video frame interpolation, etc.
BoostMIS: Boosting Medical Image Semi-supervised Learning with Adaptive Pseudo Labeling and Informative Active Annotation
Mar 21, 2022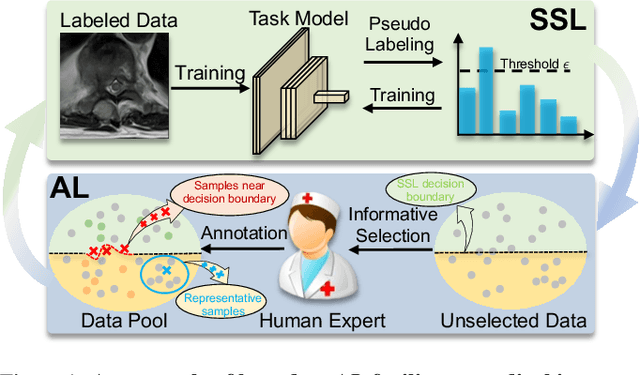
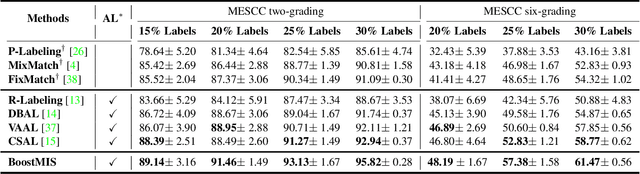
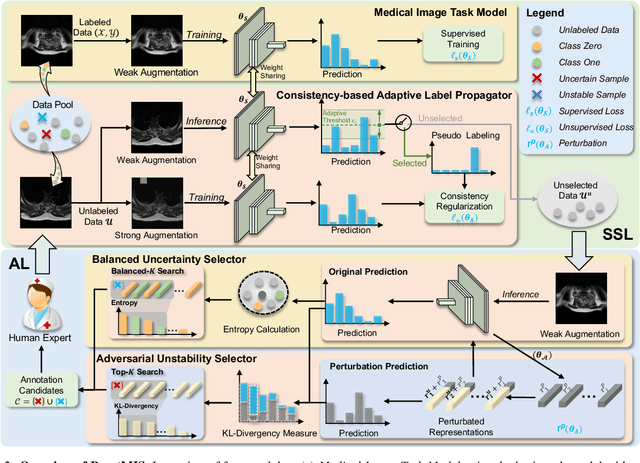
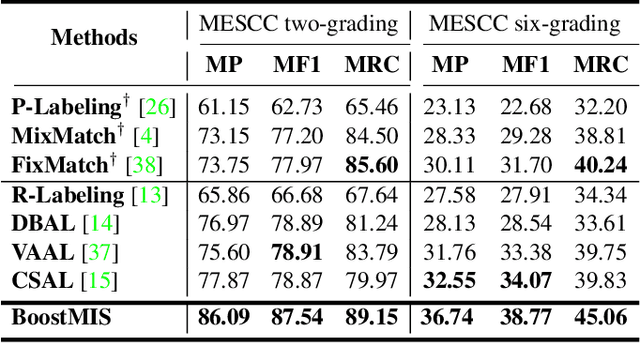
In this paper, we propose a novel semi-supervised learning (SSL) framework named BoostMIS that combines adaptive pseudo labeling and informative active annotation to unleash the potential of medical image SSL models: (1) BoostMIS can adaptively leverage the cluster assumption and consistency regularization of the unlabeled data according to the current learning status. This strategy can adaptively generate one-hot "hard" labels converted from task model predictions for better task model training. (2) For the unselected unlabeled images with low confidence, we introduce an Active learning (AL) algorithm to find the informative samples as the annotation candidates by exploiting virtual adversarial perturbation and model's density-aware entropy. These informative candidates are subsequently fed into the next training cycle for better SSL label propagation. Notably, the adaptive pseudo-labeling and informative active annotation form a learning closed-loop that are mutually collaborative to boost medical image SSL. To verify the effectiveness of the proposed method, we collected a metastatic epidural spinal cord compression (MESCC) dataset that aims to optimize MESCC diagnosis and classification for improved specialist referral and treatment. We conducted an extensive experimental study of BoostMIS on MESCC and another public dataset COVIDx. The experimental results verify our framework's effectiveness and generalisability for different medical image datasets with a significant improvement over various state-of-the-art methods.
* 11 pages
IronDepth: Iterative Refinement of Single-View Depth using Surface Normal and its Uncertainty
Oct 07, 2022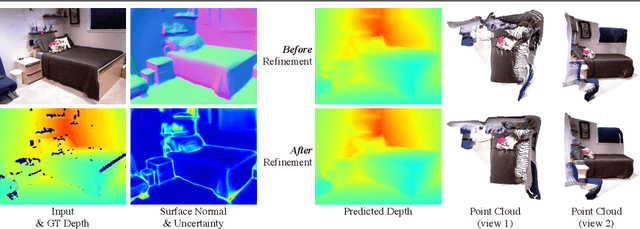
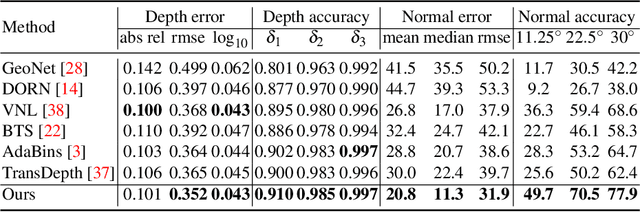
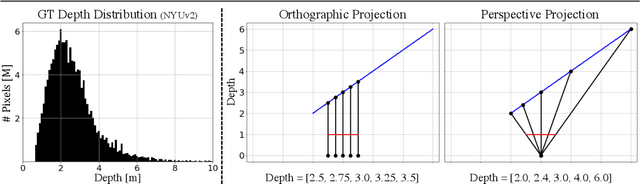
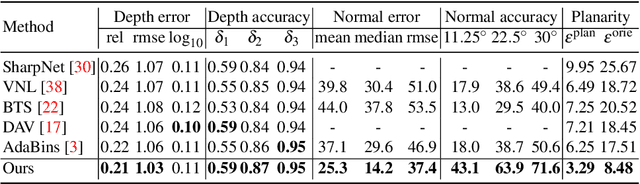
Single image surface normal estimation and depth estimation are closely related problems as the former can be calculated from the latter. However, the surface normals computed from the output of depth estimation methods are significantly less accurate than the surface normals directly estimated by networks. To reduce such discrepancy, we introduce a novel framework that uses surface normal and its uncertainty to recurrently refine the predicted depth-map. The depth of each pixel can be propagated to a query pixel, using the predicted surface normal as guidance. We thus formulate depth refinement as a classification of choosing the neighboring pixel to propagate from. Then, by propagating to sub-pixel points, we upsample the refined, low-resolution output. The proposed method shows state-of-the-art performance on NYUv2 and iBims-1 - both in terms of depth and normal. Our refinement module can also be attached to the existing depth estimation methods to improve their accuracy. We also show that our framework, only trained for depth estimation, can also be used for depth completion. The code is available at https://github.com/baegwangbin/IronDepth.
Atomized Deep Learning Models
Oct 07, 2022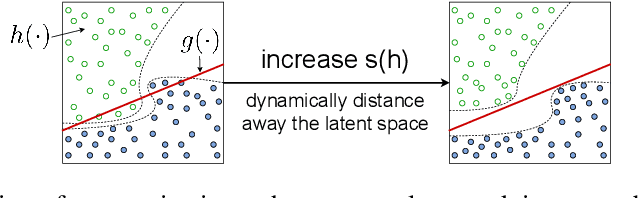
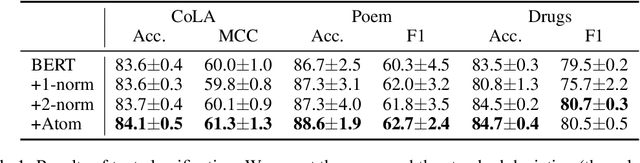
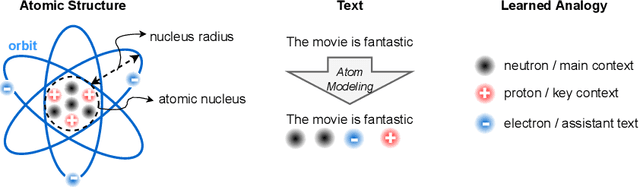
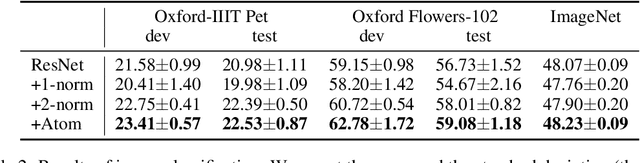
Deep learning models often tackle the intra-sample structure, such as the order of words in a sentence and pixels in an image, but have not pay much attention to the inter-sample relationship. In this paper, we show that explicitly modeling the inter-sample structure to be more discretized can potentially help model's expressivity. We propose a novel method, Atom Modeling, that can discretize a continuous latent space by drawing an analogy between a data point and an atom, which is naturally spaced away from other atoms with distances depending on their intra structures. Specifically, we model each data point as an atom composed of electrons, protons, and neutrons and minimize the potential energy caused by the interatomic force among data points. Through experiments with qualitative analysis in our proposed Atom Modeling on synthetic and real datasets, we find that Atom Modeling can improve the performance by maintaining the inter-sample relation and can capture an interpretable intra-sample relation by mapping each component in a data point to electron/proton/neutron.
Adaptive Network Combination for Single-Image Reflection Removal: A Domain Generalization Perspective
Apr 04, 2022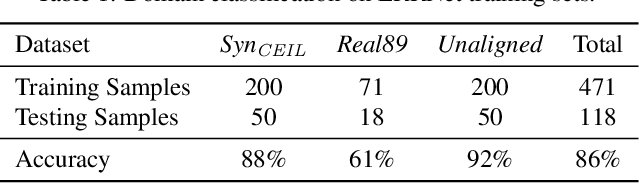
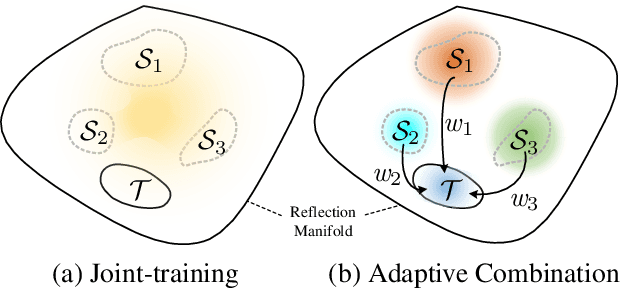
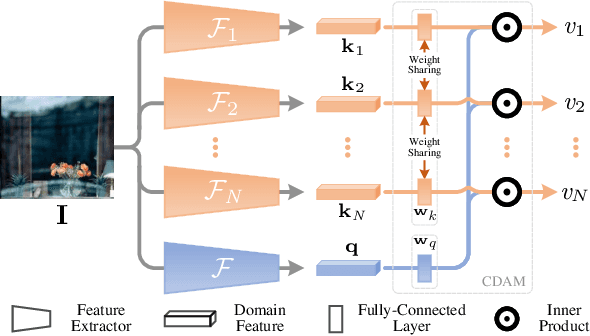

Recently, multiple synthetic and real-world datasets have been built to facilitate the training of deep single image reflection removal (SIRR) models. Meanwhile, diverse testing sets are also provided with different types of reflection and scenes. However, the non-negligible domain gaps between training and testing sets make it difficult to learn deep models generalizing well to testing images. The diversity of reflections and scenes further makes it a mission impossible to learn a single model being effective to all testing sets and real-world reflections. In this paper, we tackle these issues by learning SIRR models from a domain generalization perspective. Particularly, for each source set, a specific SIRR model is trained to serve as a domain expert of relevant reflection types. For a given reflection-contaminated image, we present a reflection type-aware weighting (RTAW) module to predict expert-wise weights. RTAW can then be incorporated with adaptive network combination (AdaNEC) for handling different reflection types and scenes, i.e., generalizing to unknown domains. Two representative AdaNEC methods, i.e., output fusion (OF) and network interpolation (NI), are provided by considering both adaptation levels and efficiency. For images from one source set, we train RTAW to only predict expert-wise weights of other domain experts for improving generalization ability, while the weights of all experts are predicted and employed during testing. An in-domain expert (IDE) loss is presented for training RTAW. Extensive experiments show the appealing performance gain of our AdaNEC on different state-of-the-art SIRR networks. Source code and pre-trained models will available at https://github.com/csmliu/AdaNEC.
Towards Understanding and Harnessing the Effect of Image Transformation in Adversarial Detection
Jan 07, 2022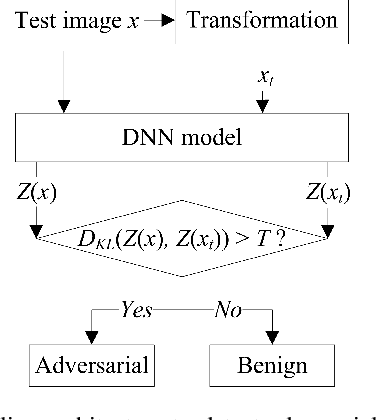
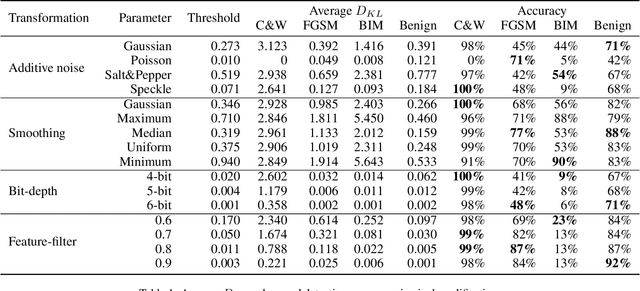
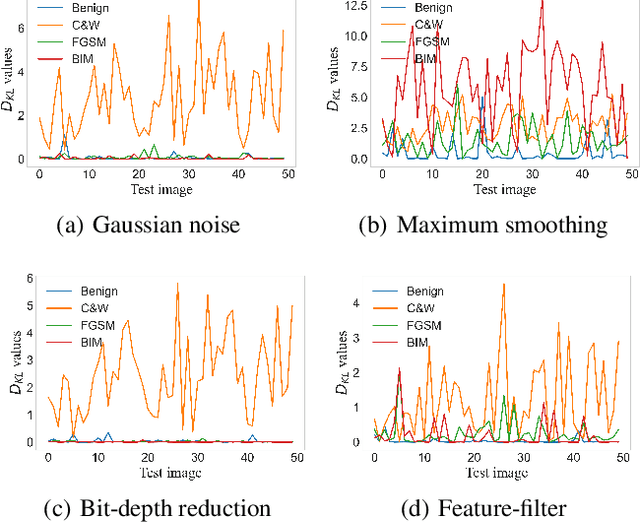
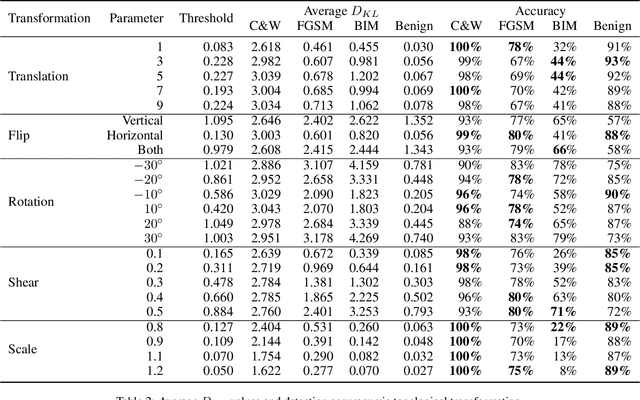
Deep neural networks (DNNs) are threatened by adversarial examples. Adversarial detection, which distinguishes adversarial images from benign images, is fundamental for robust DNN-based services. Image transformation is one of the most effective approaches to detect adversarial examples. During the last few years, a variety of image transformations have been studied and discussed to design reliable adversarial detectors. In this paper, we systematically synthesize the recent progress on adversarial detection via image transformations with a novel classification method. Then, we conduct extensive experiments to test the detection performance of image transformations against state-of-the-art adversarial attacks. Furthermore, we reveal that each individual transformation is not capable of detecting adversarial examples in a robust way, and propose a DNN-based approach referred to as AdvJudge, which combines scores of 9 image transformations. Without knowing which individual scores are misleading or not misleading, AdvJudge can make the right judgment, and achieve a significant improvement in detection accuracy. We claim that AdvJudge is a more effective adversarial detector than those based on an individual image transformation.
Deep Learning based pipeline for anomaly detection and quality enhancement in industrial binder jetting processes
Sep 23, 2022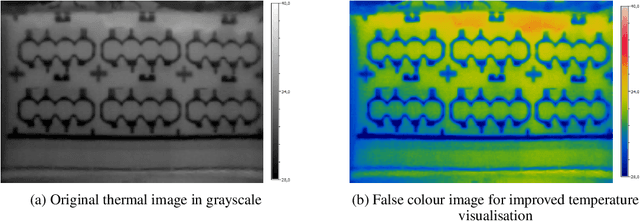


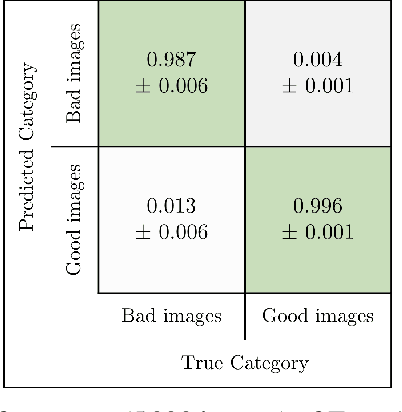
Anomaly detection describes methods of finding abnormal states, instances or data points that differ from a normal value space. Industrial processes are a domain where predicitve models are needed for finding anomalous data instances for quality enhancement. A main challenge, however, is absence of labels in this environment. This paper contributes to a data-centric way of approaching artificial intelligence in industrial production. With a use case from additive manufacturing for automotive components we present a deep-learning-based image processing pipeline. Additionally, we integrate the concept of domain randomisation and synthetic data in the loop that shows promising results for bridging advances in deep learning and its application to real-world, industrial production processes.
Asymmetric Student-Teacher Networks for Industrial Anomaly Detection
Oct 18, 2022
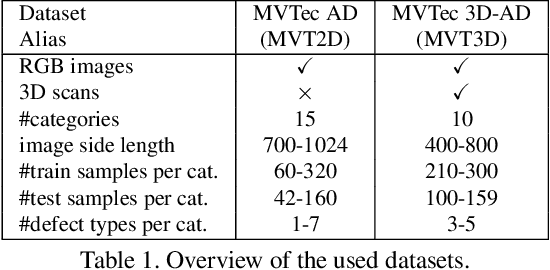
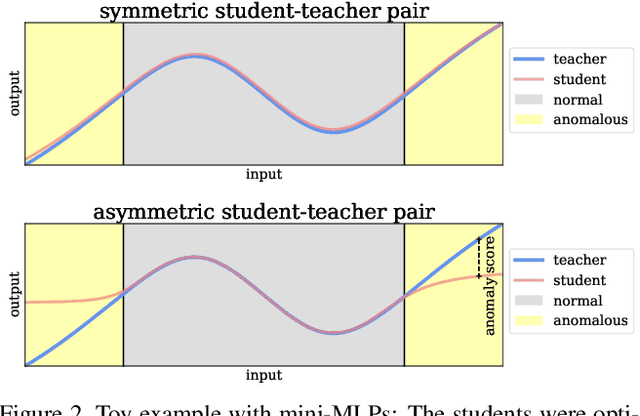
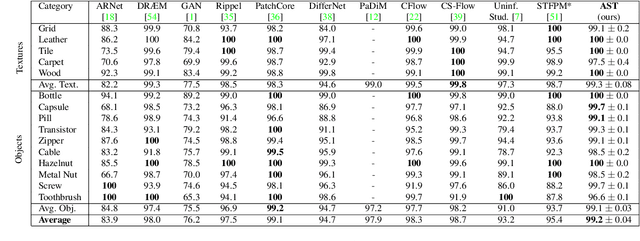
Industrial defect detection is commonly addressed with anomaly detection (AD) methods where no or only incomplete data of potentially occurring defects is available. This work discovers previously unknown problems of student-teacher approaches for AD and proposes a solution, where two neural networks are trained to produce the same output for the defect-free training examples. The core assumption of student-teacher networks is that the distance between the outputs of both networks is larger for anomalies since they are absent in training. However, previous methods suffer from the similarity of student and teacher architecture, such that the distance is undesirably small for anomalies. For this reason, we propose asymmetric student-teacher networks (AST). We train a normalizing flow for density estimation as a teacher and a conventional feed-forward network as a student to trigger large distances for anomalies: The bijectivity of the normalizing flow enforces a divergence of teacher outputs for anomalies compared to normal data. Outside the training distribution the student cannot imitate this divergence due to its fundamentally different architecture. Our AST network compensates for wrongly estimated likelihoods by a normalizing flow, which was alternatively used for anomaly detection in previous work. We show that our method produces state-of-the-art results on the two currently most relevant defect detection datasets MVTec AD and MVTec 3D-AD regarding image-level anomaly detection on RGB and 3D data.
Differentially Private Diffusion Models
Oct 18, 2022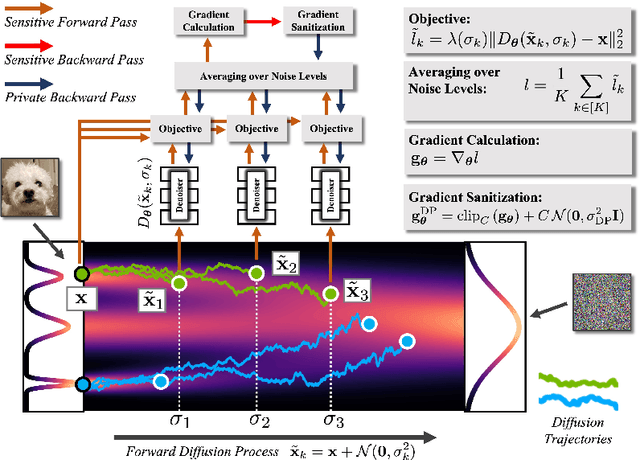
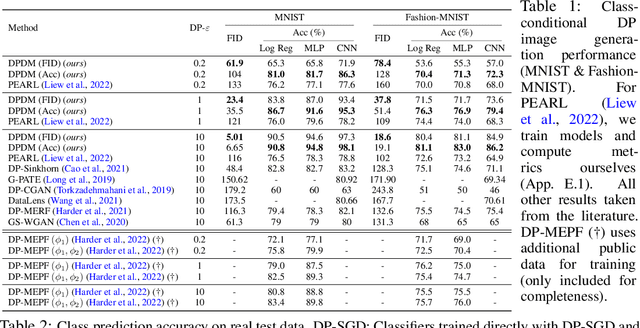
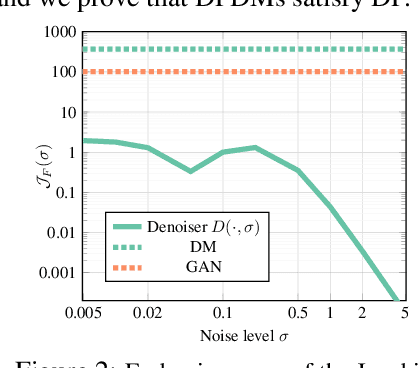
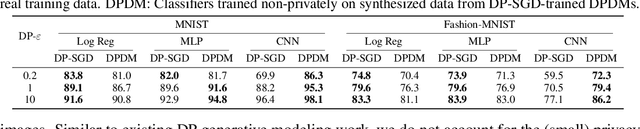
While modern machine learning models rely on increasingly large training datasets, data is often limited in privacy-sensitive domains. Generative models trained with differential privacy (DP) on sensitive data can sidestep this challenge, providing access to synthetic data instead. However, training DP generative models is highly challenging due to the noise injected into training to enforce DP. We propose to leverage diffusion models (DMs), an emerging class of deep generative models, and introduce Differentially Private Diffusion Models (DPDMs), which enforce privacy using differentially private stochastic gradient descent (DP-SGD). We motivate why DP-SGD is well suited for training DPDMs, and thoroughly investigate the DM parameterization and the sampling algorithm, which turn out to be crucial ingredients in DPDMs. Furthermore, we propose noise multiplicity, a simple yet powerful modification of the DM training objective tailored to the DP setting to boost performance. We validate our novel DPDMs on widely-used image generation benchmarks and achieve state-of-the-art (SOTA) performance by large margins. For example, on MNIST we improve the SOTA FID from 48.4 to 5.01 and downstream classification accuracy from 83.2% to 98.1% for the privacy setting DP-$(\varepsilon{=}10, \delta{=}10^{-5})$. Moreover, on standard benchmarks, classifiers trained on DPDM-generated synthetic data perform on par with task-specific DP-SGD-trained classifiers, which has not been demonstrated before for DP generative models. Project page and code: https://nv-tlabs.github.io/DPDM.
On effects of Knowledge Distillation on Transfer Learning
Oct 18, 2022
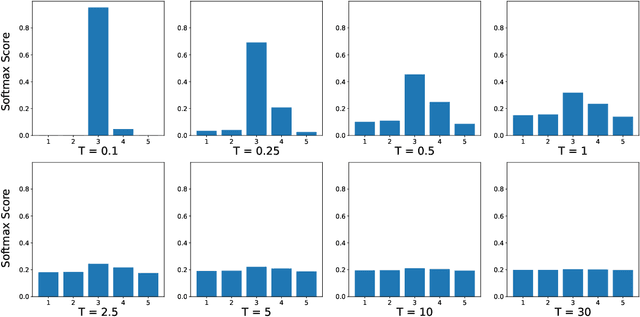

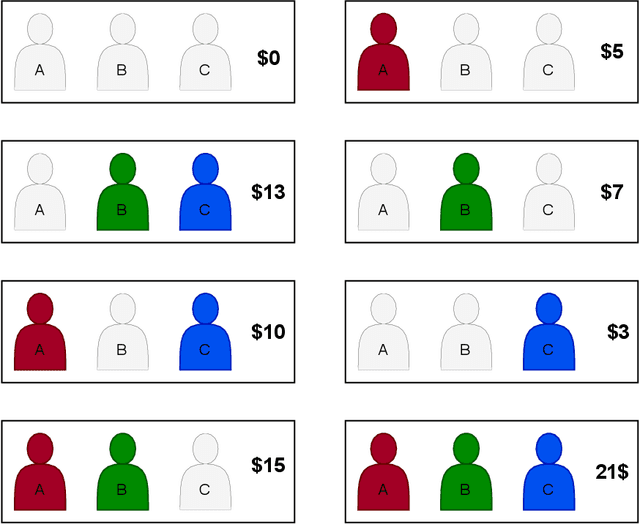
Knowledge distillation is a popular machine learning technique that aims to transfer knowledge from a large 'teacher' network to a smaller 'student' network and improve the student's performance by training it to emulate the teacher. In recent years, there has been significant progress in novel distillation techniques that push performance frontiers across multiple problems and benchmarks. Most of the reported work focuses on achieving state-of-the-art results on the specific problem. However, there has been a significant gap in understanding the process and how it behaves under certain training scenarios. Similarly, transfer learning (TL) is an effective technique in training neural networks on a limited dataset faster by reusing representations learned from a different but related problem. Despite its effectiveness and popularity, there has not been much exploration of knowledge distillation on transfer learning. In this thesis, we propose a machine learning architecture we call TL+KD that combines knowledge distillation with transfer learning; we then present a quantitative and qualitative comparison of TL+KD with TL in the domain of image classification. Through this work, we show that using guidance and knowledge from a larger teacher network during fine-tuning, we can improve the student network to achieve better validation performances like accuracy. We characterize the improvement in the validation performance of the model using a variety of metrics beyond just accuracy scores, and study its performance in scenarios such as input degradation.