 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Flexible Android Malware Detection Model based on Generative Adversarial Networks with Code Tensor
Oct 25, 2022
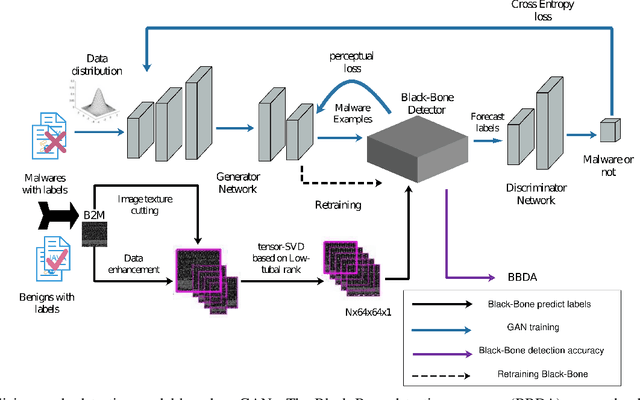

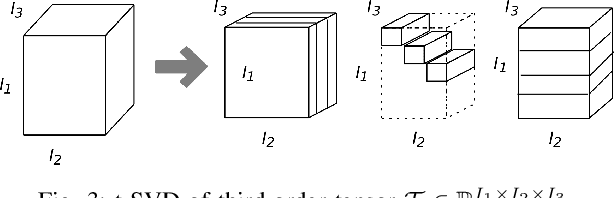
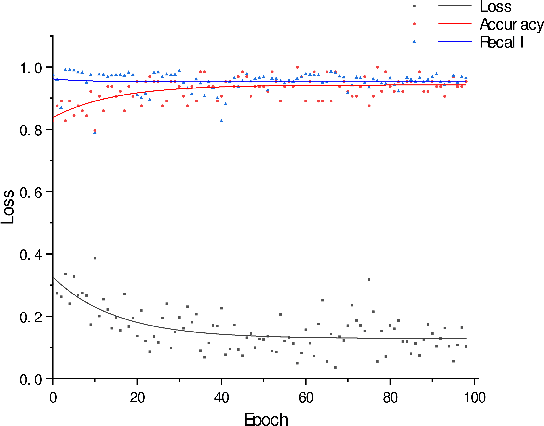
The behavior of malware threats is gradually increasing, heightened the need for malware detection. However, existing malware detection methods only target at the existing malicious samples, the detection of fresh malicious code and variants of malicious code is limited. In this paper, we propose a novel scheme that detects malware and its variants efficiently. Based on the idea of the generative adversarial networks (GANs), we obtain the `true' sample distribution that satisfies the characteristics of the real malware, use them to deceive the discriminator, thus achieve the defense against malicious code attacks and improve malware detection. Firstly, a new Android malware APK to image texture feature extraction segmentation method is proposed, which is called segment self-growing texture segmentation algorithm. Secondly, tensor singular value decomposition (tSVD) based on the low-tubal rank transforms malicious features with different sizes into a fixed third-order tensor uniformly, which is entered into the neural network for training and learning. Finally, a flexible Android malware detection model based on GANs with code tensor (MTFD-GANs) is proposed. Experiments show that the proposed model can generally surpass the traditional malware detection model, with a maximum improvement efficiency of 41.6\%. At the same time, the newly generated samples of the GANs generator greatly enrich the sample diversity. And retraining malware detector can effectively improve the detection efficiency and robustness of traditional models.
Fine-grained Classification of Solder Joints with α-skew Jensen-Shannon Divergence
Sep 20, 2022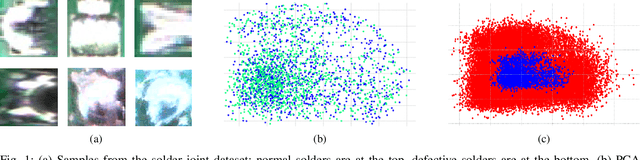
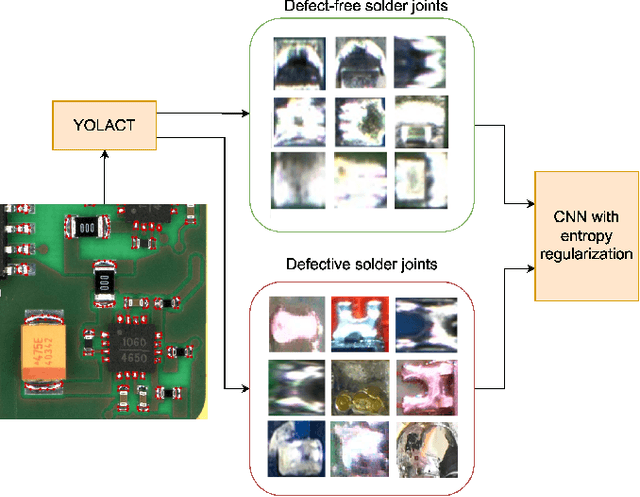
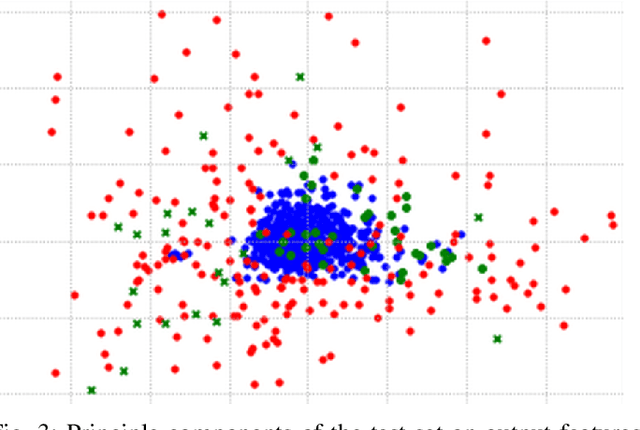
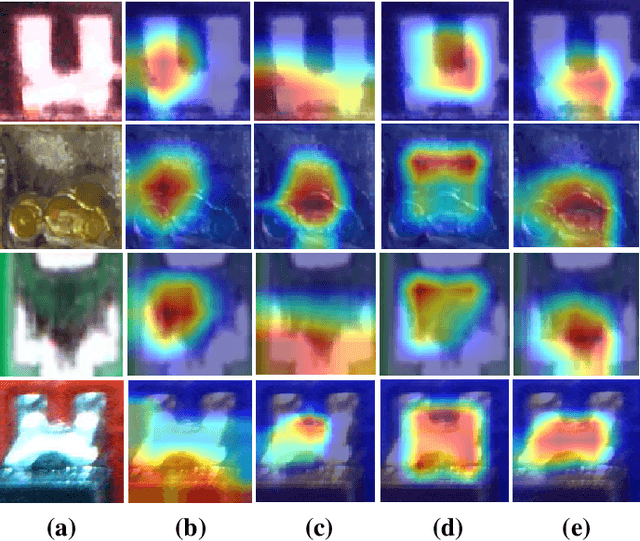
Solder joint inspection (SJI) is a critical process in the production of printed circuit boards (PCB). Detection of solder errors during SJI is quite challenging as the solder joints have very small sizes and can take various shapes. In this study, we first show that solders have low feature diversity, and that the SJI can be carried out as a fine-grained image classification task which focuses on hard-to-distinguish object classes. To improve the fine-grained classification accuracy, penalizing confident model predictions by maximizing entropy was found useful in the literature. Inline with this information, we propose using the {\alpha}-skew Jensen-Shannon divergence ({\alpha}-JS) for penalizing the confidence in model predictions. We compare the {\alpha}-JS regularization with both existing entropyregularization based methods and the methods based on attention mechanism, segmentation techniques, transformer models, and specific loss functions for fine-grained image classification tasks. We show that the proposed approach achieves the highest F1-score and competitive accuracy for different models in the finegrained solder joint classification task. Finally, we visualize the activation maps and show that with entropy-regularization, more precise class-discriminative regions are localized, which are also more resilient to noise. Code will be made available here upon acceptance.
Compound Figure Separation of Biomedical Images: Mining Large Datasets for Self-supervised Learning
Aug 30, 2022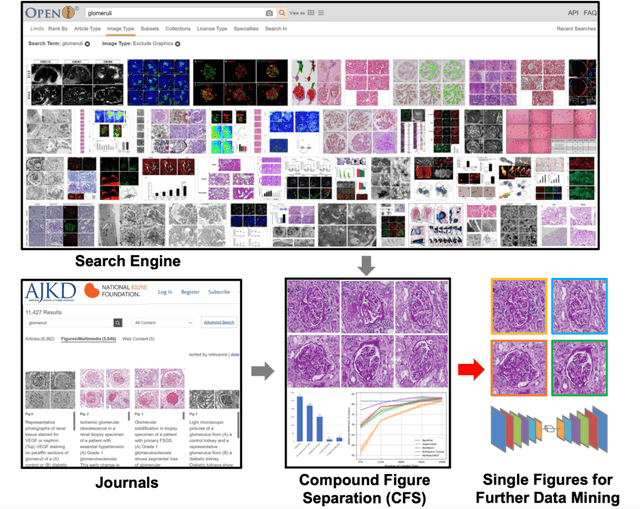
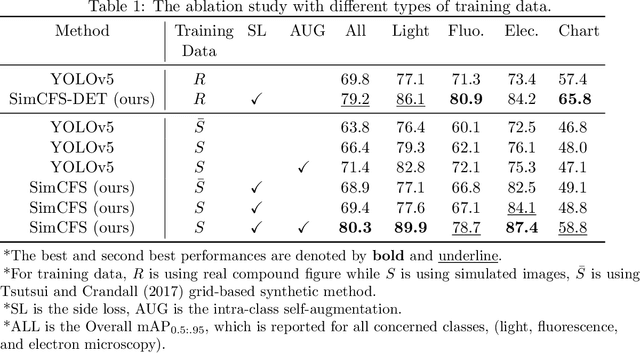
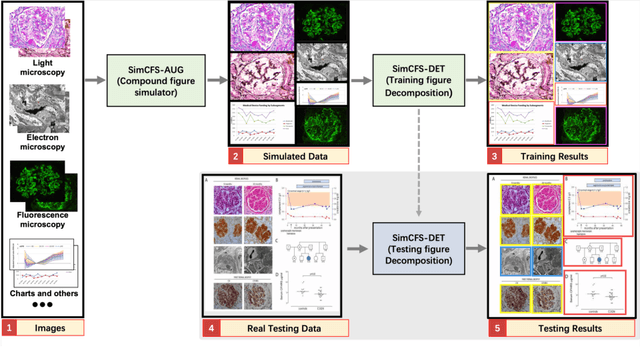
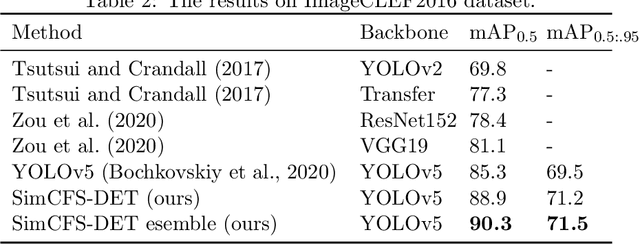
With the rapid development of self-supervised learning (e.g., contrastive learning), the importance of having large-scale images (even without annotations) for training a more generalizable AI model has been widely recognized in medical image analysis. However, collecting large-scale task-specific unannotated data at scale can be challenging for individual labs. Existing online resources, such as digital books, publications, and search engines, provide a new resource for obtaining large-scale images. However, published images in healthcare (e.g., radiology and pathology) consist of a considerable amount of compound figures with subplots. In order to extract and separate compound figures into usable individual images for downstream learning, we propose a simple compound figure separation (SimCFS) framework without using the traditionally required detection bounding box annotations, with a new loss function and a hard case simulation. Our technical contribution is four-fold: (1) we introduce a simulation-based training framework that minimizes the need for resource extensive bounding box annotations; (2) we propose a new side loss that is optimized for compound figure separation; (3) we propose an intra-class image augmentation method to simulate hard cases; and (4) to the best of our knowledge, this is the first study that evaluates the efficacy of leveraging self-supervised learning with compound image separation. From the results, the proposed SimCFS achieved state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The pretrained self-supervised learning model using large-scale mined figures improved the accuracy of downstream image classification tasks with a contrastive learning algorithm. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://www.melba-journal.org/papers/2022:025.html. arXiv admin note: substantial text overlap with arXiv:2107.08650
CALIP: Zero-Shot Enhancement of CLIP with Parameter-free Attention
Sep 28, 2022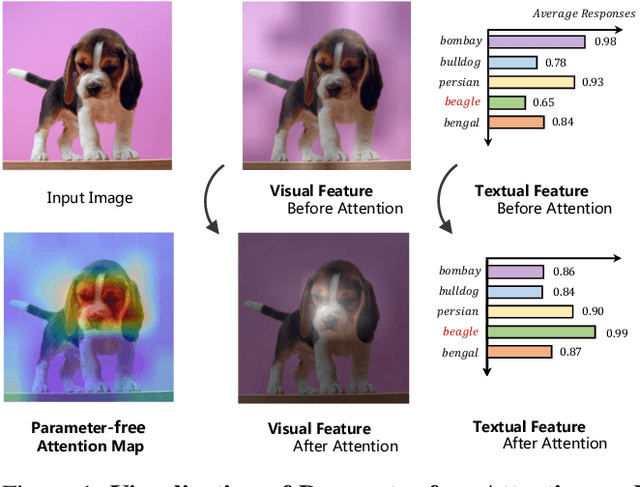
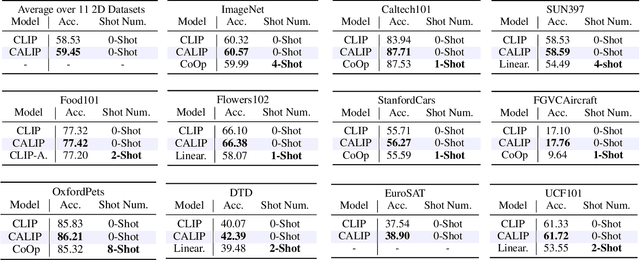
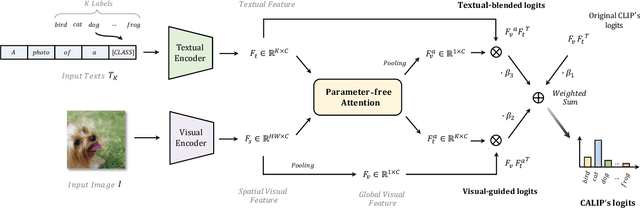

Contrastive Language-Image Pre-training (CLIP) has been shown to learn visual representations with great transferability, which achieves promising accuracy for zero-shot classification. To further improve its downstream performance, existing works propose additional learnable modules upon CLIP and fine-tune them by few-shot training sets. However, the resulting extra training cost and data requirement severely hinder the efficiency for model deployment and knowledge transfer. In this paper, we introduce a free-lunch enhancement method, CALIP, to boost CLIP's zero-shot performance via a parameter-free Attention module. Specifically, we guide visual and textual representations to interact with each other and explore cross-modal informative features via attention. As the pre-training has largely reduced the embedding distances between two modalities, we discard all learnable parameters in the attention and bidirectionally update the multi-modal features, enabling the whole process to be parameter-free and training-free. In this way, the images are blended with textual-aware signals and the text representations become visual-guided for better adaptive zero-shot alignment. We evaluate CALIP on various benchmarks of 14 datasets for both 2D image and 3D point cloud few-shot classification, showing consistent zero-shot performance improvement over CLIP. Based on that, we further insert a small number of linear layers in CALIP's attention module and verify our robustness under the few-shot settings, which also achieves leading performance compared to existing methods. Those extensive experiments demonstrate the superiority of our approach for efficient enhancement of CLIP.
Offline Handwritten Amharic Character Recognition Using Few-shot Learning
Oct 01, 2022
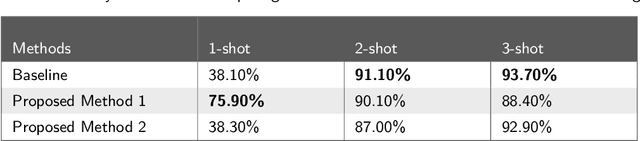
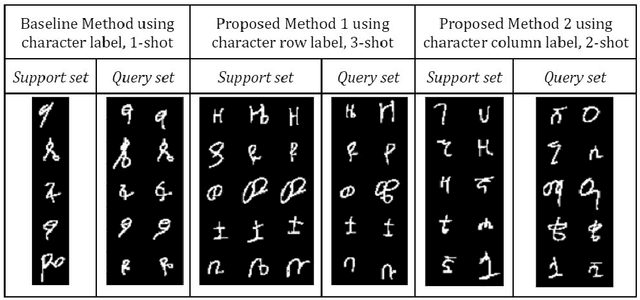
Few-shot learning is an important, but challenging problem of machine learning aimed at learning from only fewer labeled training examples. It has become an active area of research due to deep learning requiring huge amounts of labeled dataset, which is not feasible in the real world. Learning from a few examples is also an important attempt towards learning like humans. Few-shot learning has proven a very good promise in different areas of machine learning applications, particularly in image classification. As it is a recent technique, most researchers focus on understanding and solving the issues related to its concept by focusing only on common image datasets like Mini-ImageNet and Omniglot. Few-shot learning also opens an opportunity to address low resource languages like Amharic. In this study, offline handwritten Amharic character recognition using few-shot learning is addressed. Particularly, prototypical networks, the popular and simpler type of few-shot learning, is implemented as a baseline. Using the opportunities explored in the nature of Amharic alphabet having row-wise and column-wise similarities, a novel way of augmenting the training episodes is proposed. The experimental results show that the proposed method outperformed the baseline method. This study has implemented few-shot learning for Amharic characters for the first time. More importantly, the findings of the study open new ways of examining the influence of training episodes in few-shot learning, which is one of the important issues that needs exploration. The datasets used for this study are collected from native Amharic language writers using an Android App developed as a part of this study.
DevNet: Self-supervised Monocular Depth Learning via Density Volume Construction
Sep 20, 2022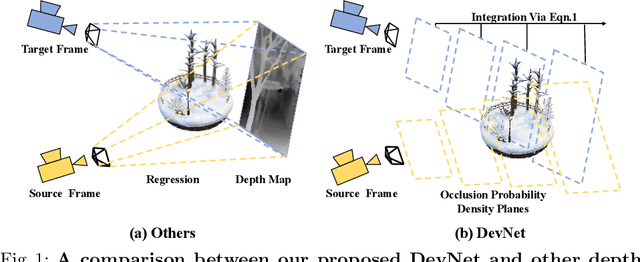
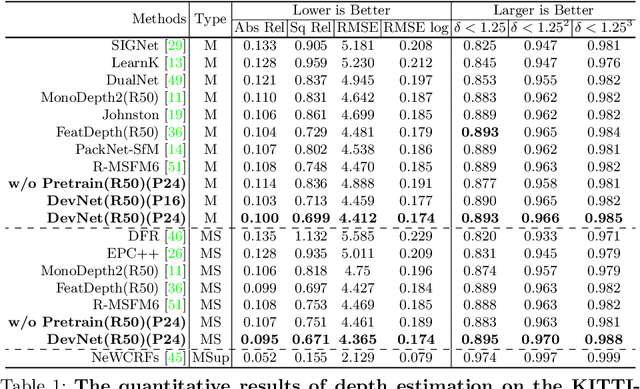
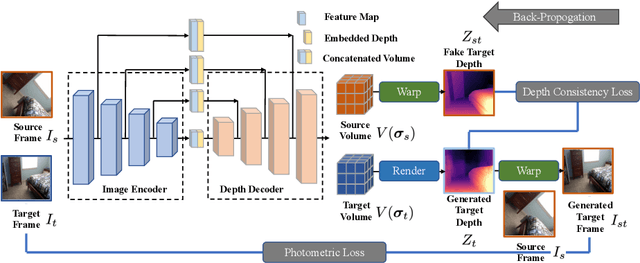

Self-supervised depth learning from monocular images normally relies on the 2D pixel-wise photometric relation between temporally adjacent image frames. However, they neither fully exploit the 3D point-wise geometric correspondences, nor effectively tackle the ambiguities in the photometric warping caused by occlusions or illumination inconsistency. To address these problems, this work proposes Density Volume Construction Network (DevNet), a novel self-supervised monocular depth learning framework, that can consider 3D spatial information, and exploit stronger geometric constraints among adjacent camera frustums. Instead of directly regressing the pixel value from a single image, our DevNet divides the camera frustum into multiple parallel planes and predicts the pointwise occlusion probability density on each plane. The final depth map is generated by integrating the density along corresponding rays. During the training process, novel regularization strategies and loss functions are introduced to mitigate photometric ambiguities and overfitting. Without obviously enlarging model parameters size or running time, DevNet outperforms several representative baselines on both the KITTI-2015 outdoor dataset and NYU-V2 indoor dataset. In particular, the root-mean-square-deviation is reduced by around 4% with DevNet on both KITTI-2015 and NYU-V2 in the task of depth estimation. Code is available at https://github.com/gitkaichenzhou/DevNet.
Differentiable Mathematical Programming for Object-Centric Representation Learning
Oct 05, 2022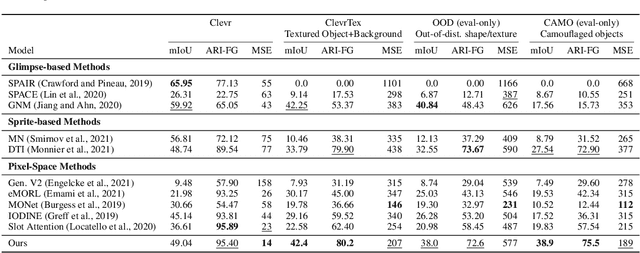

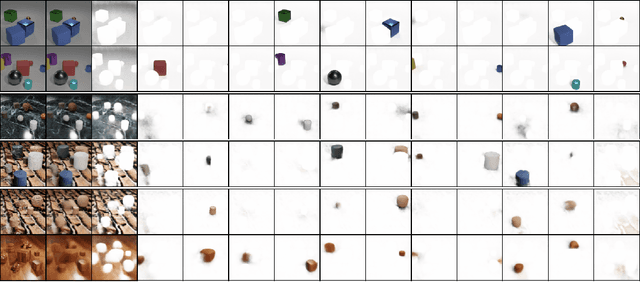
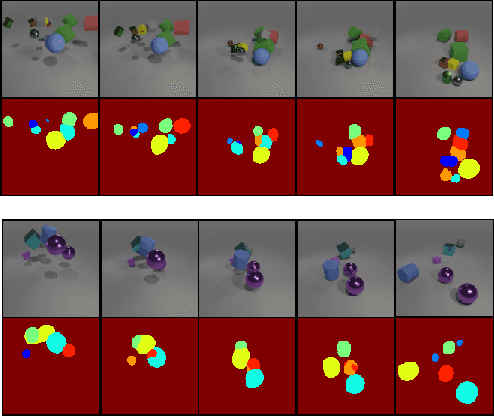
We propose topology-aware feature partitioning into $k$ disjoint partitions for given scene features as a method for object-centric representation learning. To this end, we propose to use minimum $s$-$t$ graph cuts as a partitioning method which is represented as a linear program. The method is topologically aware since it explicitly encodes neighborhood relationships in the image graph. To solve the graph cuts our solution relies on an efficient, scalable, and differentiable quadratic programming approximation. Optimizations specific to cut problems allow us to solve the quadratic programs and compute their gradients significantly more efficiently compared with the general quadratic programming approach. Our results show that our approach is scalable and outperforms existing methods on object discovery tasks with textured scenes and objects.
Few-Shot Learning Meets Transformer: Unified Query-Support Transformers for Few-Shot Classification
Aug 26, 2022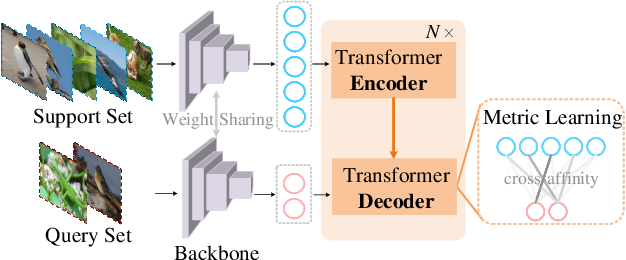
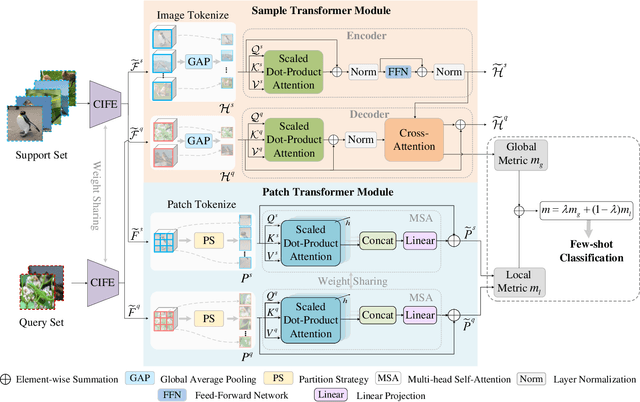
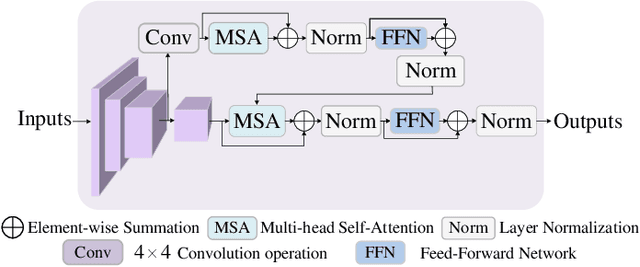
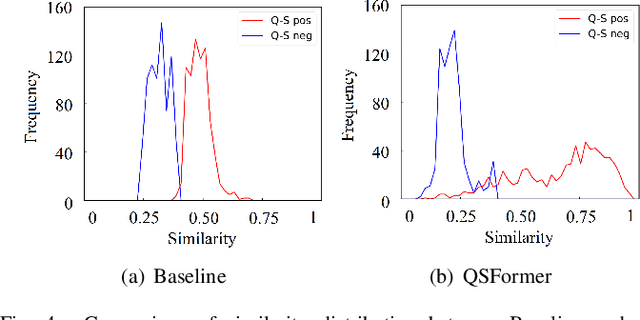
Few-shot classification which aims to recognize unseen classes using very limited samples has attracted more and more attention. Usually, it is formulated as a metric learning problem. The core issue of few-shot classification is how to learn (1) consistent representations for images in both support and query sets and (2) effective metric learning for images between support and query sets. In this paper, we show that the two challenges can be well modeled simultaneously via a unified Query-Support TransFormer (QSFormer) model. To be specific,the proposed QSFormer involves global query-support sample Transformer (sampleFormer) branch and local patch Transformer (patchFormer) learning branch. sampleFormer aims to capture the dependence of samples in support and query sets for image representation. It adopts the Encoder, Decoder and Cross-Attention to respectively model the Support, Query (image) representation and Metric learning for few-shot classification task. Also, as a complementary to global learning branch, we adopt a local patch Transformer to extract structural representation for each image sample by capturing the long-range dependence of local image patches. In addition, a novel Cross-scale Interactive Feature Extractor (CIFE) is proposed to extract and fuse multi-scale CNN features as an effective backbone module for the proposed few-shot learning method. All modules are integrated into a unified framework and trained in an end-to-end manner. Extensive experiments on four popular datasets demonstrate the effectiveness and superiority of the proposed QSFormer.
Infrared and Visible Image Fusion via Interactive Compensatory Attention Adversarial Learning
Mar 29, 2022

The existing generative adversarial fusion methods generally concatenate source images and extract local features through convolution operation, without considering their global characteristics, which tends to produce an unbalanced result and is biased towards the infrared image or visible image. Toward this end, we propose a novel end-to-end mode based on generative adversarial training to achieve better fusion balance, termed as \textit{interactive compensatory attention fusion network} (ICAFusion). In particular, in the generator, we construct a multi-level encoder-decoder network with a triple path, and adopt infrared and visible paths to provide additional intensity and gradient information. Moreover, we develop interactive and compensatory attention modules to communicate their pathwise information, and model their long-range dependencies to generate attention maps, which can more focus on infrared target perception and visible detail characterization, and further increase the representation power for feature extraction and feature reconstruction. In addition, dual discriminators are designed to identify the similar distribution between fused result and source images, and the generator is optimized to produce a more balanced result. Extensive experiments illustrate that our ICAFusion obtains superior fusion performance and better generalization ability, which precedes other advanced methods in the subjective visual description and objective metric evaluation. Our codes will be public at \url{https://github.com/Zhishe-Wang/ICAFusion}
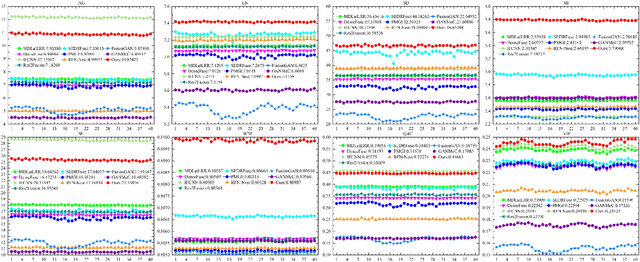
Deep Counterfactual Estimation with Categorical Background Variables
Oct 13, 2022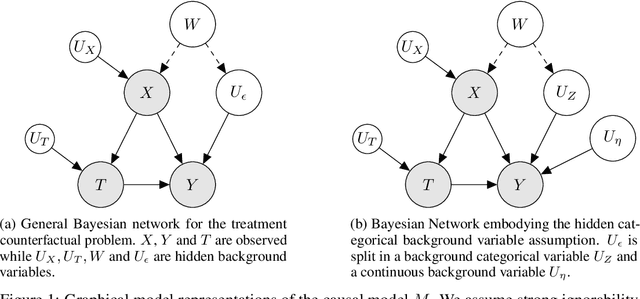
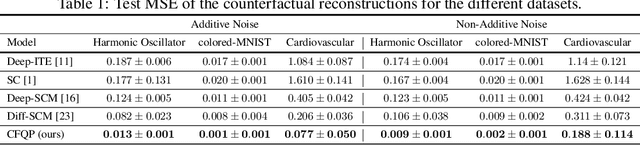
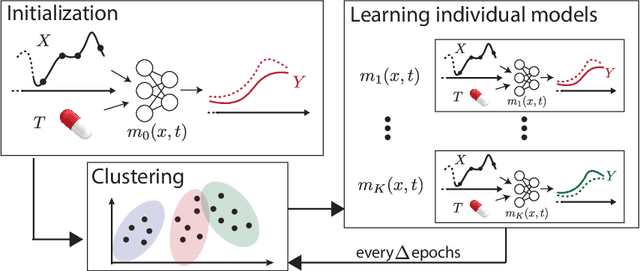
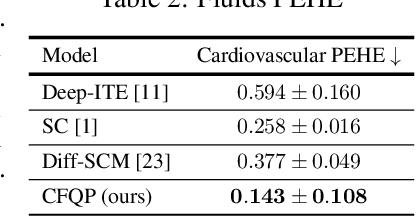
Referred to as the third rung of the causal inference ladder, counterfactual queries typically ask the "What if ?" question retrospectively. The standard approach to estimate counterfactuals resides in using a structural equation model that accurately reflects the underlying data generating process. However, such models are seldom available in practice and one usually wishes to infer them from observational data alone. Unfortunately, the correct structural equation model is in general not identifiable from the observed factual distribution. Nevertheless, in this work, we show that under the assumption that the main latent contributors to the treatment responses are categorical, the counterfactuals can be still reliably predicted. Building upon this assumption, we introduce CounterFactual Query Prediction (CFQP), a novel method to infer counterfactuals from continuous observations when the background variables are categorical. We show that our method significantly outperforms previously available deep-learning-based counterfactual methods, both theoretically and empirically on time series and image data. Our code is available at https://github.com/edebrouwer/cfqp.