 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Motion-related Artefact Classification Using Patch-based Ensemble and Transfer Learning in Cardiac MRI
Oct 14, 2022
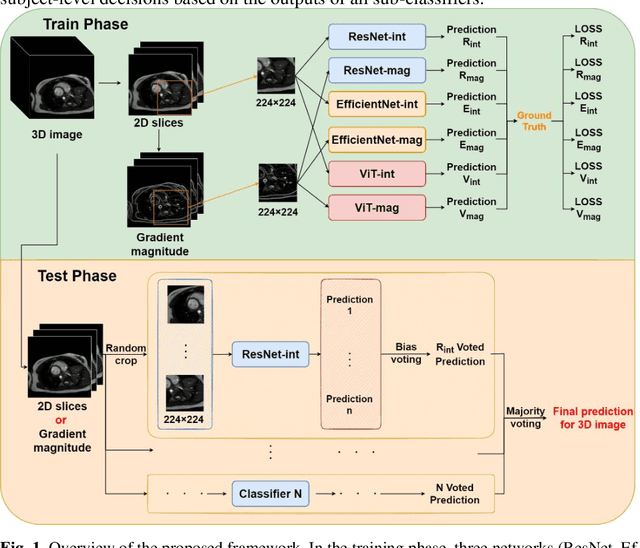
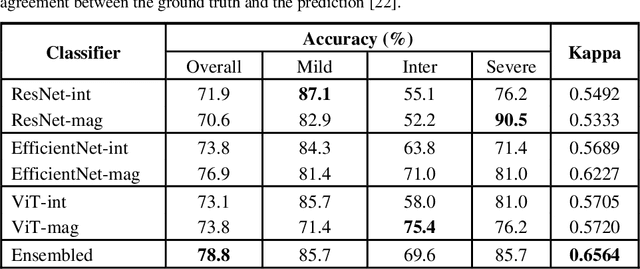
Cardiac Magnetic Resonance Imaging (MRI) plays an important role in the analysis of cardiac function. However, the acquisition is often accompanied by motion artefacts because of the difficulty of breath-hold, especially for acute symptoms patients. Therefore, it is essential to assess the quality of cardiac MRI for further analysis. Time-consuming manual-based classification is not conducive to the construction of an end-to-end computer aided diagnostic system. To overcome this problem, an automatic cardiac MRI quality estimation framework using ensemble and transfer learning is proposed in this work. Multiple pre-trained models were initialised and fine-tuned on 2-dimensional image patches sampled from the training data. In the model inference process, decisions from these models are aggregated to make a final prediction. The framework has been evaluated on CMRxMotion grand challenge (MICCAI 2022) dataset which is small, multi-class, and imbalanced. It achieved a classification accuracy of 78.8% and 70.0% on the training set (5-fold cross-validation) and a validation set, respectively. The final trained model was also evaluated on an independent test set by the CMRxMotion organisers, which achieved the classification accuracy of 72.5% and Cohen's Kappa of 0.6309 (ranked top 1 in this grand challenge). Our code is available on Github: https://github.com/ruizhe-l/CMRxMotion.
PTGCF: Printing Texture Guided Color Fusion for Impressionism Oil Painting Style Rendering
Jul 27, 2022


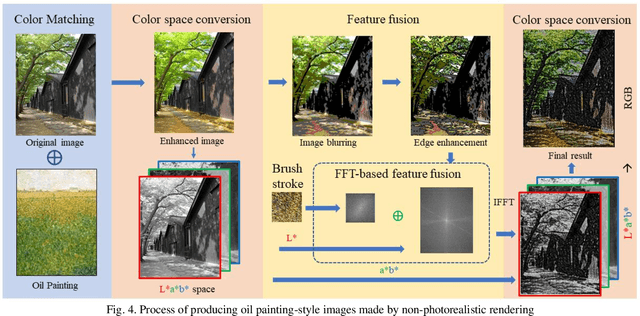
As a major branch of Non-Photorealistic Rendering (NPR), image stylization mainly uses the computer algorithms to render a photo into an artistic painting. Recent work has shown that the extraction of style information such as stroke texture and color of the target style image is the key to image stylization. Given its stroke texture and color characteristics, a new stroke rendering method is proposed, which fully considers the tonal characteristics and the representative color of the original oil painting, in order to fit the tone of the original oil painting image into the stylized image and make it close to the artist's creative effect. The experiments have validated the efficacy of the proposed model. This method would be more suitable for the works of pointillism painters with a relatively uniform sense of direction, especially for natural scenes. When the original painting brush strokes have a clearer sense of direction, using this method to simulate brushwork texture features can be less satisfactory.
Context-based Deep Learning Architecture with Optimal Integration Layer for Image Parsing
Apr 13, 2022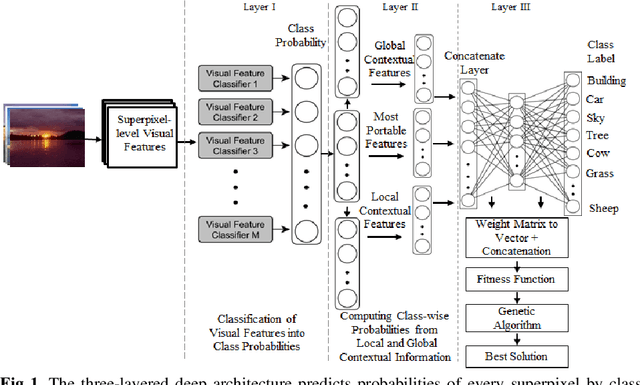
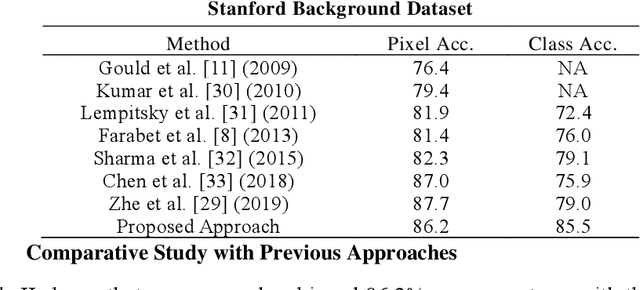
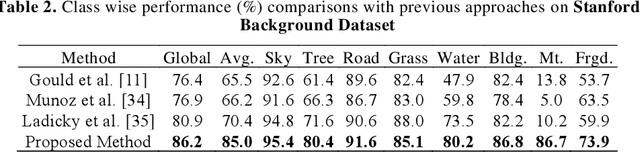
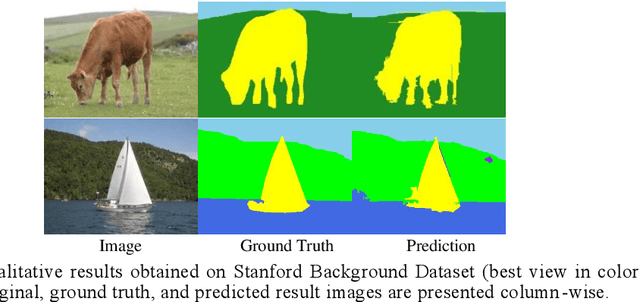
Deep learning models have been efficient lately on image parsing tasks. However, deep learning models are not fully capable of exploiting visual and contextual information simultaneously. The proposed three-layer context-based deep architecture is capable of integrating context explicitly with visual information. The novel idea here is to have a visual layer to learn visual characteristics from binary class-based learners, a contextual layer to learn context, and then an integration layer to learn from both via genetic algorithm-based optimal fusion to produce a final decision. The experimental outcomes when evaluated on benchmark datasets are promising. Further analysis shows that optimized network weights can improve performance and make stable predictions.
Model-Based Image Signal Processors via Learnable Dictionaries
Jan 10, 2022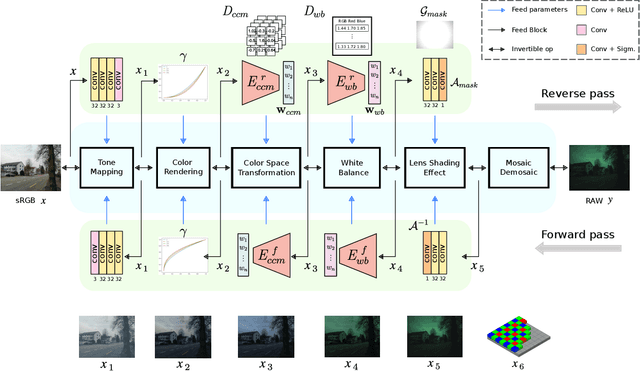
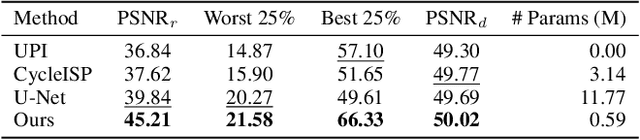
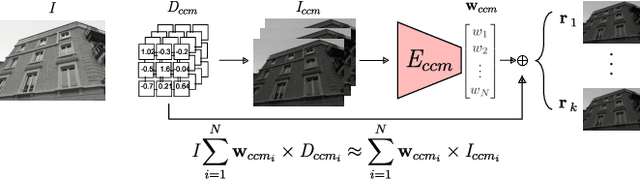
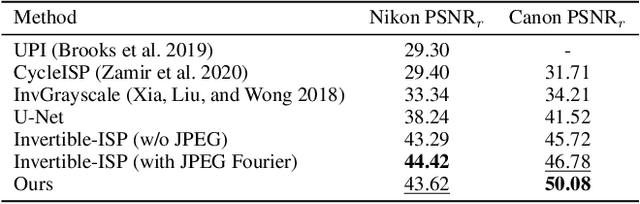
Digital cameras transform sensor RAW readings into RGB images by means of their Image Signal Processor (ISP). Computational photography tasks such as image denoising and colour constancy are commonly performed in the RAW domain, in part due to the inherent hardware design, but also due to the appealing simplicity of noise statistics that result from the direct sensor readings. Despite this, the availability of RAW images is limited in comparison with the abundance and diversity of available RGB data. Recent approaches have attempted to bridge this gap by estimating the RGB to RAW mapping: handcrafted model-based methods that are interpretable and controllable usually require manual parameter fine-tuning, while end-to-end learnable neural networks require large amounts of training data, at times with complex training procedures, and generally lack interpretability and parametric control. Towards addressing these existing limitations, we present a novel hybrid model-based and data-driven ISP that builds on canonical ISP operations and is both learnable and interpretable. Our proposed invertible model, capable of bidirectional mapping between RAW and RGB domains, employs end-to-end learning of rich parameter representations, i.e. dictionaries, that are free from direct parametric supervision and additionally enable simple and plausible data augmentation. We evidence the value of our data generation process by extensive experiments under both RAW image reconstruction and RAW image denoising tasks, obtaining state-of-the-art performance in both. Additionally, we show that our ISP can learn meaningful mappings from few data samples, and that denoising models trained with our dictionary-based data augmentation are competitive despite having only few or zero ground-truth labels.
CAB: Comprehensive Attention Benchmarking on Long Sequence Modeling
Oct 19, 2022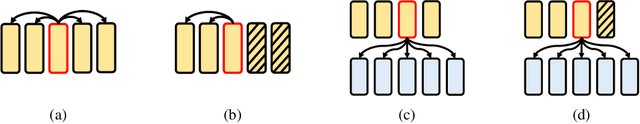
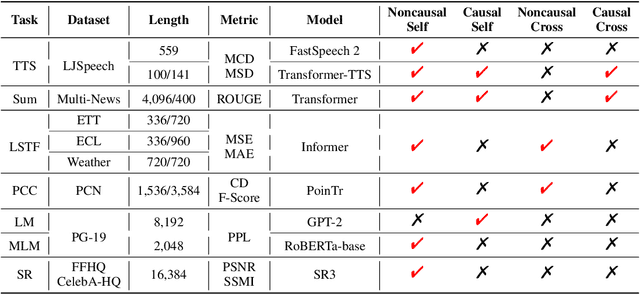
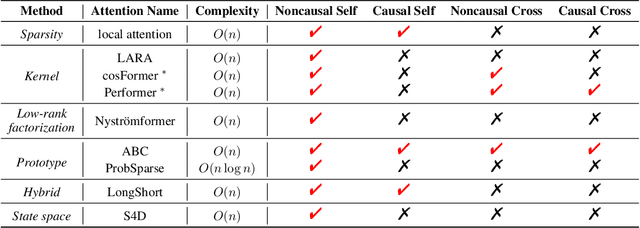
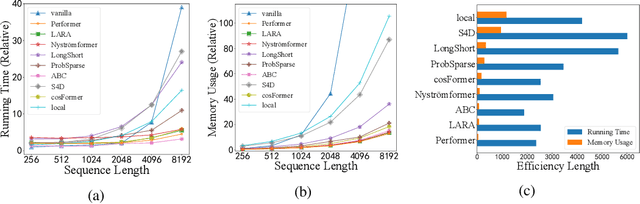
Transformer has achieved remarkable success in language, image, and speech processing. Recently, various efficient attention architectures have been proposed to improve transformer's efficiency while largely preserving its efficacy, especially in modeling long sequences. A widely-used benchmark to test these efficient methods' capability on long-range modeling is Long Range Arena (LRA). However, LRA only focuses on the standard bidirectional (or noncausal) self attention, and completely ignores cross attentions and unidirectional (or causal) attentions, which are equally important to downstream applications. Although designing cross and causal variants of an attention method is straightforward for vanilla attention, it is often challenging for efficient attentions with subquadratic time and memory complexity. In this paper, we propose Comprehensive Attention Benchmark (CAB) under a fine-grained attention taxonomy with four distinguishable attention patterns, namely, noncausal self, causal self, noncausal cross, and causal cross attentions. CAB collects seven real-world tasks from different research areas to evaluate efficient attentions under the four attention patterns. Among these tasks, CAB validates efficient attentions in eight backbone networks to show their generalization across neural architectures. We conduct exhaustive experiments to benchmark the performances of nine widely-used efficient attention architectures designed with different philosophies on CAB. Extensive experimental results also shed light on the fundamental problems of efficient attentions, such as efficiency length against vanilla attention, performance consistency across attention patterns, the benefit of attention mechanisms, and interpolation/extrapolation on long-context language modeling.
Enhanced Image Reconstruction From Quarter Sampling Measurements Using An Adapted Very Deep Super Resolution Network
Mar 01, 2022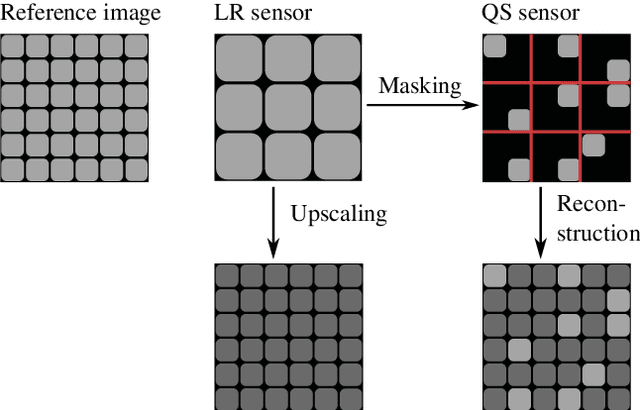

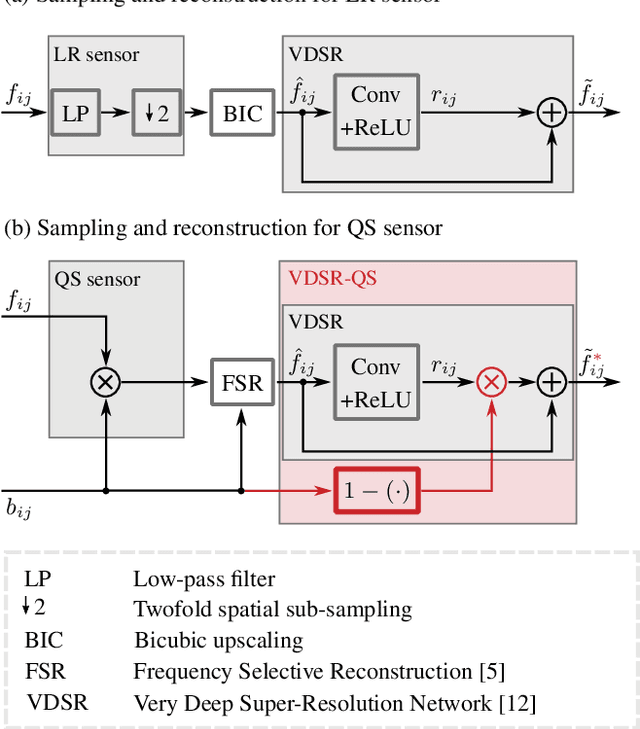

Quarter sampling is a novel sensor concept that enables the acquisition of higher resolution images without increasing the number of pixels. This is achieved by covering three quarters of each pixel of a low-resolution sensor such that only one quadrant of the sensor area of each pixel is sensitive to light. By randomly masking different parts, effectively a non-regular sampling of a higher resolution image is performed. Combining a properly designed mask and a high-quality reconstruction algorithm, a higher image quality can be achieved than using a low-resolution sensor and subsequent upsampling. For the latter case, the image quality can be enhanced using super resolution algorithms. Recently, algorithms based on machine learning such as the Very Deep Super Resolution network (VDSR) proofed to be successful for this task. In this work, we transfer the concepts of VDSR to the special case of quarter sampling. Besides adapting the network layout to take advantage of the case of quarter sampling, we introduce a novel data augmentation technique enabled by quarter sampling. Altogether, using the quarter sampling sensor, the image quality in terms of PSNR can be increased by +0.67 dB for the Urban 100 dataset compared to using a low-resolution sensor with VDSR.
Learning Token-based Representation for Image Retrieval
Dec 12, 2021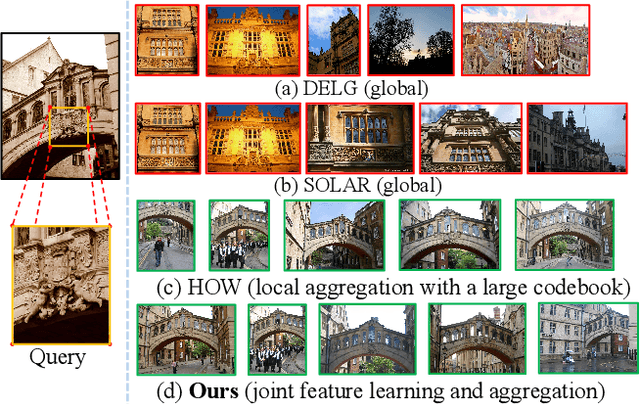
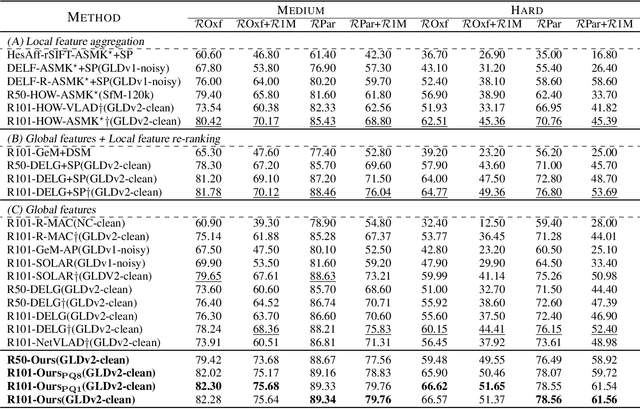
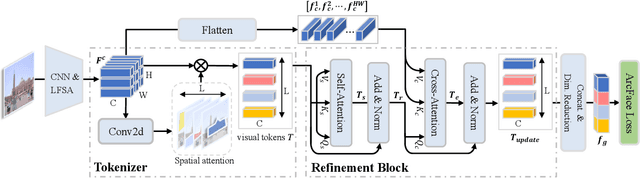
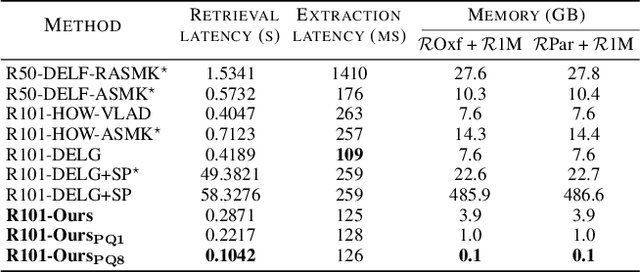
In image retrieval, deep local features learned in a data-driven manner have been demonstrated effective to improve retrieval performance. To realize efficient retrieval on large image database, some approaches quantize deep local features with a large codebook and match images with aggregated match kernel. However, the complexity of these approaches is non-trivial with large memory footprint, which limits their capability to jointly perform feature learning and aggregation. To generate compact global representations while maintaining regional matching capability, we propose a unified framework to jointly learn local feature representation and aggregation. In our framework, we first extract deep local features using CNNs. Then, we design a tokenizer module to aggregate them into a few visual tokens, each corresponding to a specific visual pattern. This helps to remove background noise, and capture more discriminative regions in the image. Next, a refinement block is introduced to enhance the visual tokens with self-attention and cross-attention. Finally, different visual tokens are concatenated to generate a compact global representation. The whole framework is trained end-to-end with image-level labels. Extensive experiments are conducted to evaluate our approach, which outperforms the state-of-the-art methods on the Revisited Oxford and Paris datasets.
Misspecified Phase Retrieval with Generative Priors
Oct 11, 2022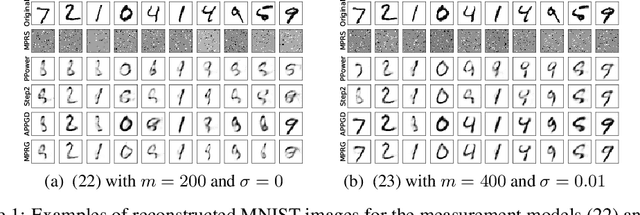
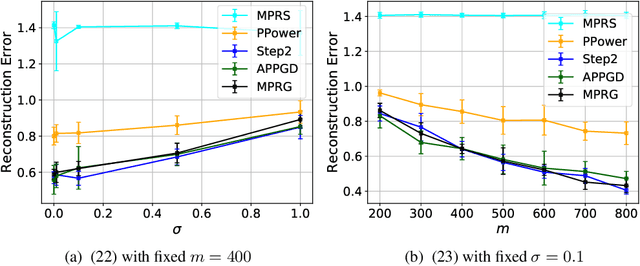
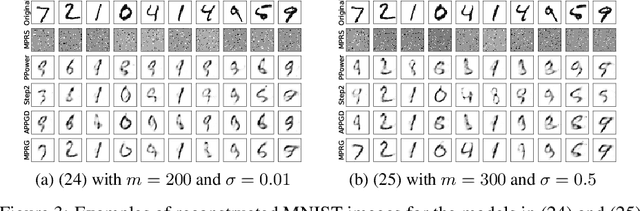
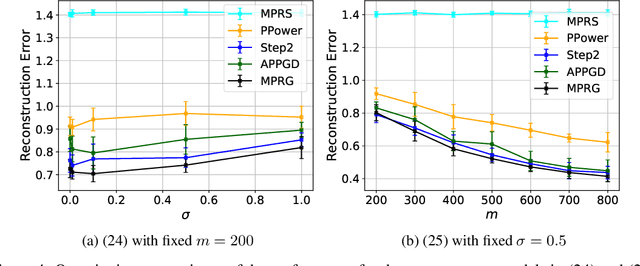
In this paper, we study phase retrieval under model misspecification and generative priors. In particular, we aim to estimate an $n$-dimensional signal $\mathbf{x}$ from $m$ i.i.d.~realizations of the single index model $y = f(\mathbf{a}^T\mathbf{x})$, where $f$ is an unknown and possibly random nonlinear link function and $\mathbf{a} \in \mathbb{R}^n$ is a standard Gaussian vector. We make the assumption $\mathrm{Cov}[y,(\mathbf{a}^T\mathbf{x})^2] \ne 0$, which corresponds to the misspecified phase retrieval problem. In addition, the underlying signal $\mathbf{x}$ is assumed to lie in the range of an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs. We propose a two-step approach, for which the first step plays the role of spectral initialization and the second step refines the estimated vector produced by the first step iteratively. We show that both steps enjoy a statistical rate of order $\sqrt{(k\log L)\cdot (\log m)/m}$ under suitable conditions. Experiments on image datasets are performed to demonstrate that our approach performs on par with or even significantly outperforms several competing methods.
UGformer for Robust Left Atrium and Scar Segmentation Across Scanners
Oct 11, 2022
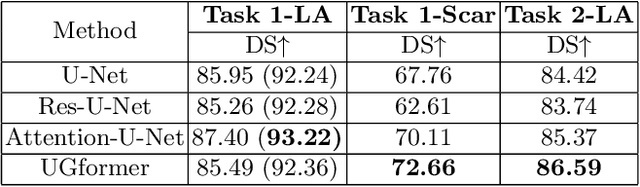
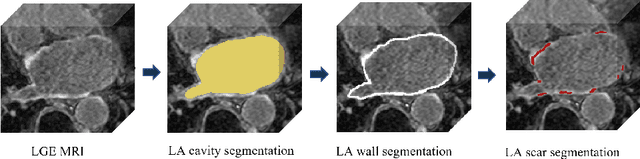
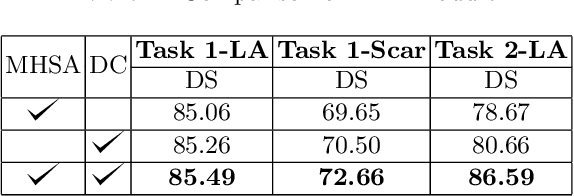
Thanks to the capacity for long-range dependencies and robustness to irregular shapes, vision transformers and deformable convolutions are emerging as powerful vision techniques of segmentation.Meanwhile, Graph Convolution Networks (GCN) optimize local features based on global topological relationship modeling. Particularly, they have been proved to be effective in addressing issues in medical imaging segmentation tasks including multi-domain generalization for low-quality images. In this paper, we present a novel, effective, and robust framework for medical image segmentation, namely, UGformer. It unifies novel transformer blocks, GCN bridges, and convolution decoders originating from U-Net to predict left atriums (LAs) and LA scars. We have identified two appealing findings of the proposed UGformer: 1). an enhanced transformer module with deformable convolutions to improve the blending of the transformer information with convolutional information and help predict irregular LAs and scar shapes. 2). Using a bridge incorporating GCN to further overcome the difficulty of capturing condition inconsistency across different Magnetic Resonance Images scanners with various inconsistent domain information. The proposed UGformer model exhibits outstanding ability to segment the left atrium and scar on the LAScarQS 2022 dataset, outperforming several recent state-of-the-arts.
Edge-Cloud Cooperation for DNN Inference via Reinforcement Learning and Supervised Learning
Oct 11, 2022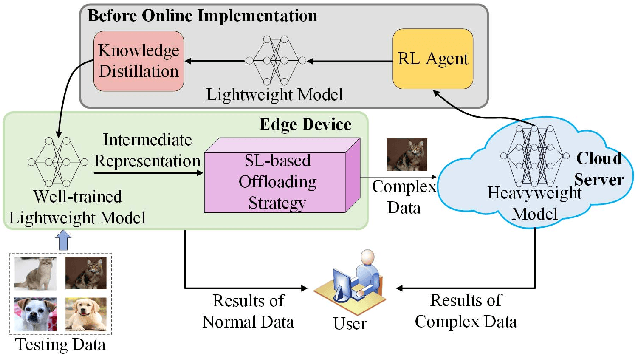
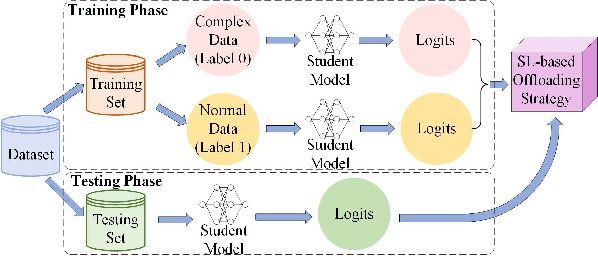
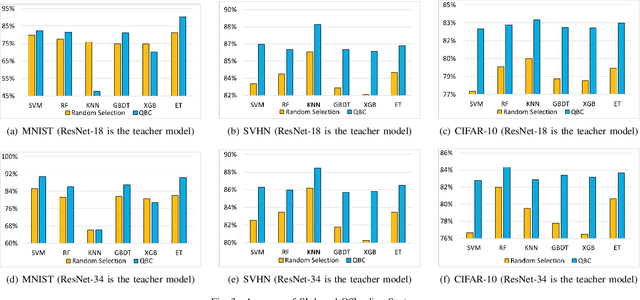
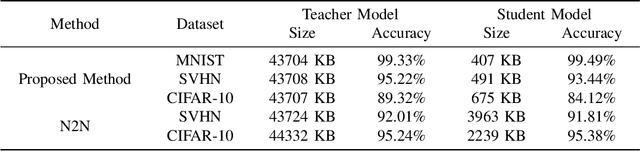
Deep Neural Networks (DNNs) have been widely applied in Internet of Things (IoT) systems for various tasks such as image classification and object detection. However, heavyweight DNN models can hardly be deployed on edge devices due to limited computational resources. In this paper, an edge-cloud cooperation framework is proposed to improve inference accuracy while maintaining low inference latency. To this end, we deploy a lightweight model on the edge and a heavyweight model on the cloud. A reinforcement learning (RL)-based DNN compression approach is used to generate the lightweight model suitable for the edge from the heavyweight model. Moreover, a supervised learning (SL)-based offloading strategy is applied to determine whether the sample should be processed on the edge or on the cloud. Our method is implemented on real hardware and tested on multiple datasets. The experimental results show that (1) The sizes of the lightweight models obtained by RL-based DNN compression are up to 87.6% smaller than those obtained by the baseline method; (2) SL-based offloading strategy makes correct offloading decisions in most cases; (3) Our method reduces up to 78.8% inference latency and achieves higher accuracy compared with the cloud-only strategy.