 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UGformer for Robust Left Atrium and Scar Segmentation Across Scanners
Oct 11, 2022

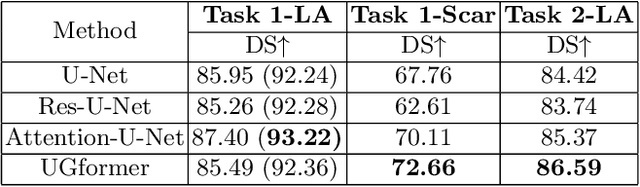
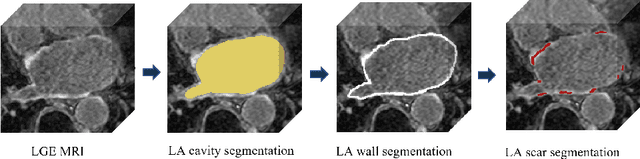
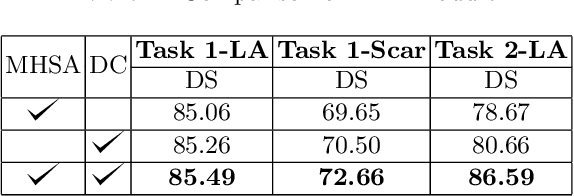
Thanks to the capacity for long-range dependencies and robustness to irregular shapes, vision transformers and deformable convolutions are emerging as powerful vision techniques of segmentation.Meanwhile, Graph Convolution Networks (GCN) optimize local features based on global topological relationship modeling. Particularly, they have been proved to be effective in addressing issues in medical imaging segmentation tasks including multi-domain generalization for low-quality images. In this paper, we present a novel, effective, and robust framework for medical image segmentation, namely, UGformer. It unifies novel transformer blocks, GCN bridges, and convolution decoders originating from U-Net to predict left atriums (LAs) and LA scars. We have identified two appealing findings of the proposed UGformer: 1). an enhanced transformer module with deformable convolutions to improve the blending of the transformer information with convolutional information and help predict irregular LAs and scar shapes. 2). Using a bridge incorporating GCN to further overcome the difficulty of capturing condition inconsistency across different Magnetic Resonance Images scanners with various inconsistent domain information. The proposed UGformer model exhibits outstanding ability to segment the left atrium and scar on the LAScarQS 2022 dataset, outperforming several recent state-of-the-arts.
Edge-Cloud Cooperation for DNN Inference via Reinforcement Learning and Supervised Learning
Oct 11, 2022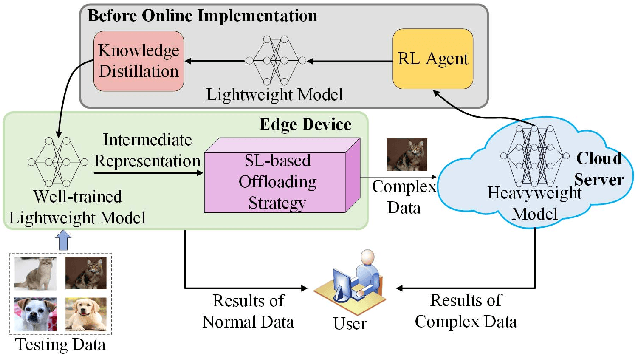
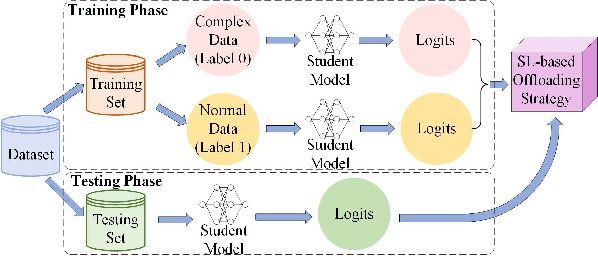
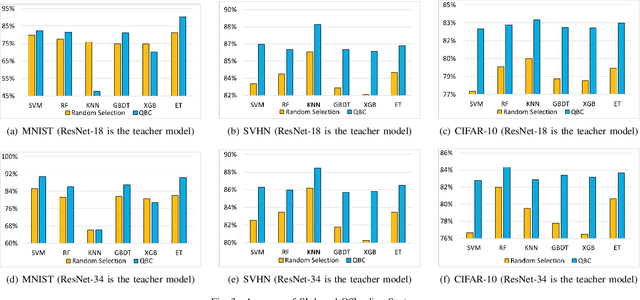
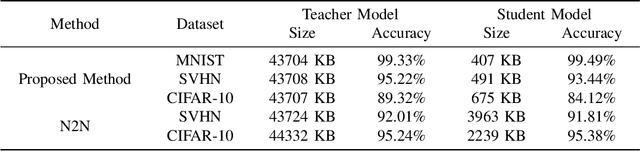
Deep Neural Networks (DNNs) have been widely applied in Internet of Things (IoT) systems for various tasks such as image classification and object detection. However, heavyweight DNN models can hardly be deployed on edge devices due to limited computational resources. In this paper, an edge-cloud cooperation framework is proposed to improve inference accuracy while maintaining low inference latency. To this end, we deploy a lightweight model on the edge and a heavyweight model on the cloud. A reinforcement learning (RL)-based DNN compression approach is used to generate the lightweight model suitable for the edge from the heavyweight model. Moreover, a supervised learning (SL)-based offloading strategy is applied to determine whether the sample should be processed on the edge or on the cloud. Our method is implemented on real hardware and tested on multiple datasets. The experimental results show that (1) The sizes of the lightweight models obtained by RL-based DNN compression are up to 87.6% smaller than those obtained by the baseline method; (2) SL-based offloading strategy makes correct offloading decisions in most cases; (3) Our method reduces up to 78.8% inference latency and achieves higher accuracy compared with the cloud-only strategy.
Semi-Autoregressive Image Captioning
Oct 13, 2021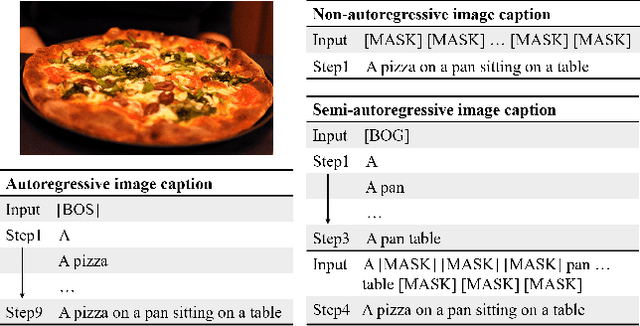
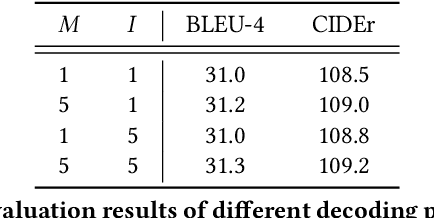
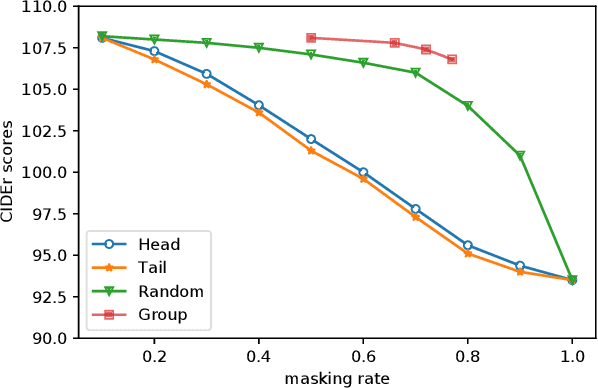
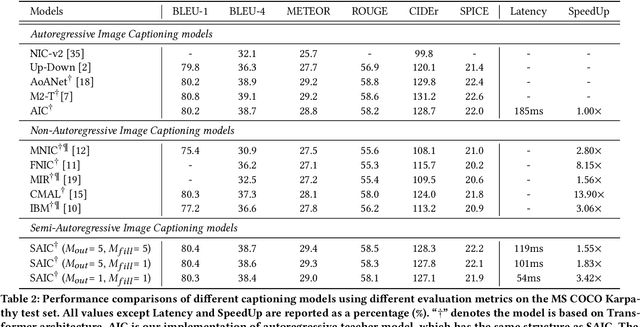
Current state-of-the-art approaches for image captioning typically adopt an autoregressive manner, i.e., generating descriptions word by word, which suffers from slow decoding issue and becomes a bottleneck in real-time applications. Non-autoregressive image captioning with continuous iterative refinement, which eliminates the sequential dependence in a sentence generation, can achieve comparable performance to the autoregressive counterparts with a considerable acceleration. Nevertheless, based on a well-designed experiment, we empirically proved that iteration times can be effectively reduced when providing sufficient prior knowledge for the language decoder. Towards that end, we propose a novel two-stage framework, referred to as Semi-Autoregressive Image Captioning (SAIC), to make a better trade-off between performance and speed. The proposed SAIC model maintains autoregressive property in global but relieves it in local. Specifically, SAIC model first jumpily generates an intermittent sequence in an autoregressive manner, that is, it predicts the first word in every word group in order. Then, with the help of the partially deterministic prior information and image features, SAIC model non-autoregressively fills all the skipped words with one iteration. Experimental results on the MS COCO benchmark demonstrate that our SAIC model outperforms the preceding non-autoregressive image captioning models while obtaining a competitive inference speedup. Code is available at https://github.com/feizc/SAIC.
IntereStyle: Encoding an Interest Region for Robust StyleGAN Inversion
Sep 22, 2022
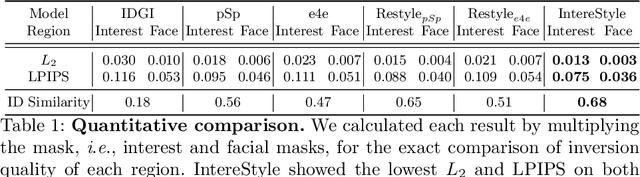

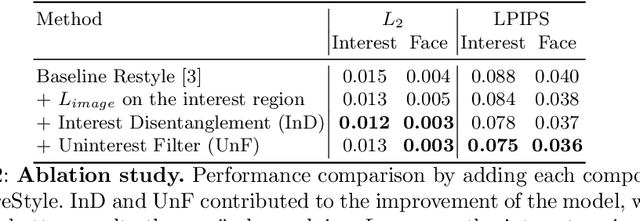
Recently, manipulation of real-world images has been highly elaborated along with the development of Generative Adversarial Networks (GANs) and corresponding encoders, which embed real-world images into the latent space. However, designing encoders of GAN still remains a challenging task due to the trade-off between distortion and perception. In this paper, we point out that the existing encoders try to lower the distortion not only on the interest region, e.g., human facial region but also on the uninterest region, e.g., background patterns and obstacles. However, most uninterest regions in real-world images are located at out-of-distribution (OOD), which are infeasible to be ideally reconstructed by generative models. Moreover, we empirically find that the uninterest region overlapped with the interest region can mangle the original feature of the interest region, e.g., a microphone overlapped with a facial region is inverted into the white beard. As a result, lowering the distortion of the whole image while maintaining the perceptual quality is very challenging. To overcome this trade-off, we propose a simple yet effective encoder training scheme, coined IntereStyle, which facilitates encoding by focusing on the interest region. IntereStyle steers the encoder to disentangle the encodings of the interest and uninterest regions. To this end, we filter the information of the uninterest region iteratively to regulate the negative impact of the uninterest region. We demonstrate that IntereStyle achieves both lower distortion and higher perceptual quality compared to the existing state-of-the-art encoders. Especially, our model robustly conserves features of the original images, which shows the robust image editing and style mixing results. We will release our code with the pre-trained model after the review.
Target and Task specific Source-Free Domain Adaptive Image Segmentation
Mar 29, 2022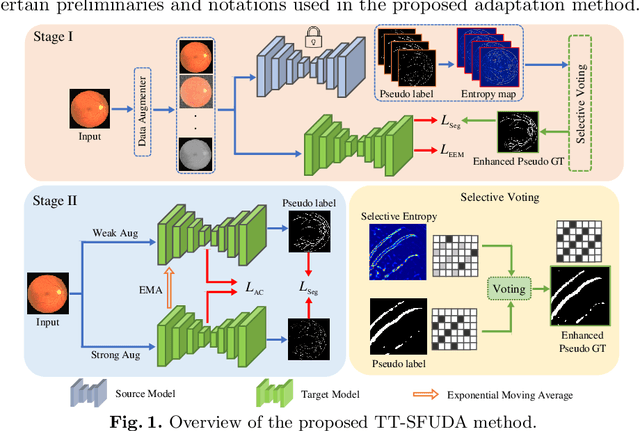
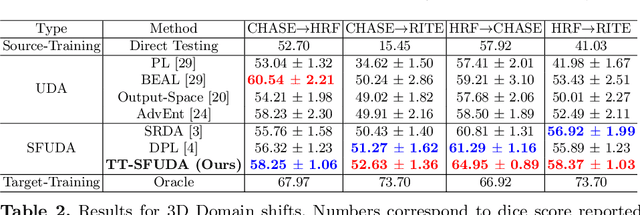

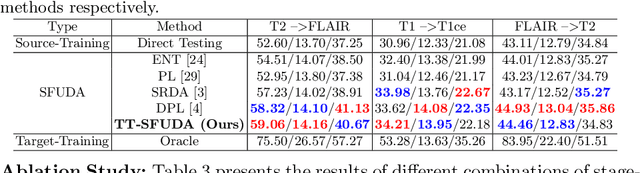
Solving the domain shift problem during inference is essential in medical imaging as most deep-learning based solutions suffer from it. In practice, domain shifts are tackled by performing Unsupervised Domain Adaptation (UDA), where a model is adapted to an unlabeled target domain by leveraging the labelled source domain. In medical scenarios, the data comes with huge privacy concerns making it difficult to apply standard UDA techniques. Hence, a closer clinical setting is Source-Free UDA (SFUDA), where we have access to source trained model but not the source data during adaptation. Methods trying to solve SFUDA typically address the domain shift using pseudo-label based self-training techniques. However, due to domain shift, these pseudo-labels are usually of high entropy and denoising them still does not make them perfect labels to supervise the model. Therefore, adapting the source model with noisy pseudo labels reduces its segmentation capability while addressing the domain shift. To this end, we propose a two-stage approach for source-free domain adaptive image segmentation: 1) Target-specific adaptation followed by 2) Task-specific adaptation. In the first stage, we focus on generating target-specific pseudo labels while suppressing high entropy regions by proposing an Ensemble Entropy Minimization loss. We also introduce a selective voting strategy to enhance pseudo-label generation. In the second stage, we focus on adapting the network for task-specific representation by using a teacher-student self-training approach based on augmentation-guided consistency. We evaluate our proposed method on both 2D fundus datasets and 3D MRI volumes across 7 different domain shifts where we achieve better performance than recent UDA and SF-UDA methods for medical image segmentation. Code is available at https://github.com/Vibashan/tt-sfuda.
Variational Bayes for robust radar single object tracking
Sep 28, 2022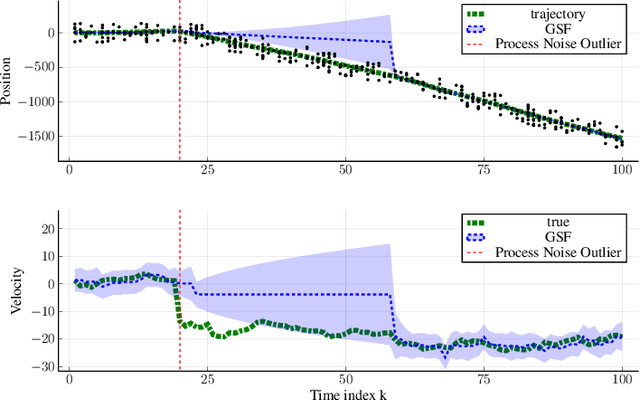
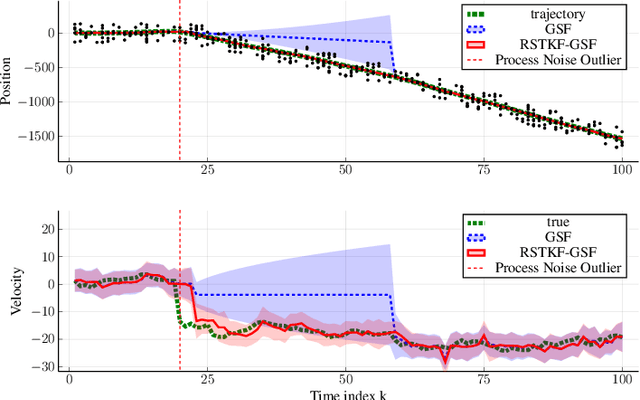
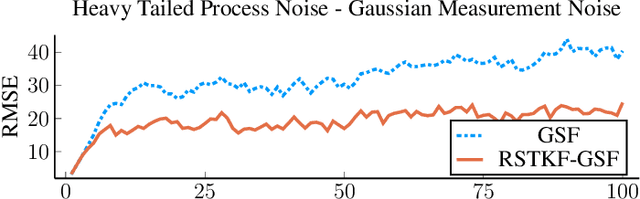
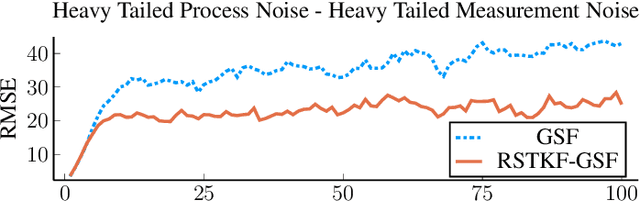
We address object tracking by radar and the robustness of the current state-of-the-art methods to process outliers. The standard tracking algorithms extract detections from radar image space to use it in the filtering stage. Filtering is performed by a Kalman filter, which assumes Gaussian distributed noise. However, this assumption does not account for large modeling errors and results in poor tracking performance during abrupt motions. We take the Gaussian Sum Filter (single-object variant of the Multi Hypothesis Tracker) as our baseline and propose a modification by modelling process noise with a distribution that has heavier tails than a Gaussian. Variational Bayes provides a fast, computationally cheap inference algorithm. Our simulations show that - in the presence of process outliers - the robust tracker outperforms the Gaussian Sum filter when tracking single objects.
Custom Structure Preservation in Face Aging
Jul 22, 2022
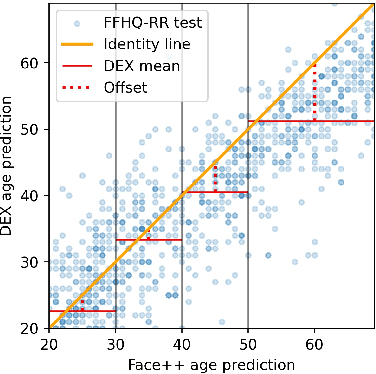
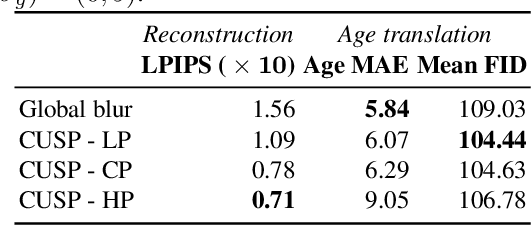
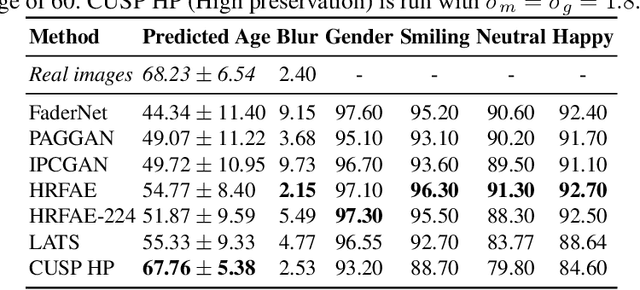
In this work, we propose a novel architecture for face age editing that can produce structural modifications while maintaining relevant details present in the original image. We disentangle the style and content of the input image and propose a new decoder network that adopts a style-based strategy to combine the style and content representations of the input image while conditioning the output on the target age. We go beyond existing aging methods allowing users to adjust the degree of structure preservation in the input image during inference. To this purpose, we introduce a masking mechanism, the CUstom Structure Preservation module, that distinguishes relevant regions in the input image from those that should be discarded. CUSP requires no additional supervision. Finally, our quantitative and qualitative analysis which include a user study, show that our method outperforms prior art and demonstrates the effectiveness of our strategy regarding image editing and adjustable structure preservation. Code and pretrained models are available at https://github.com/guillermogotre/CUSP.
Shuffle Instances-based Vision Transformer for Pancreatic Cancer ROSE Image Classification
Aug 14, 2022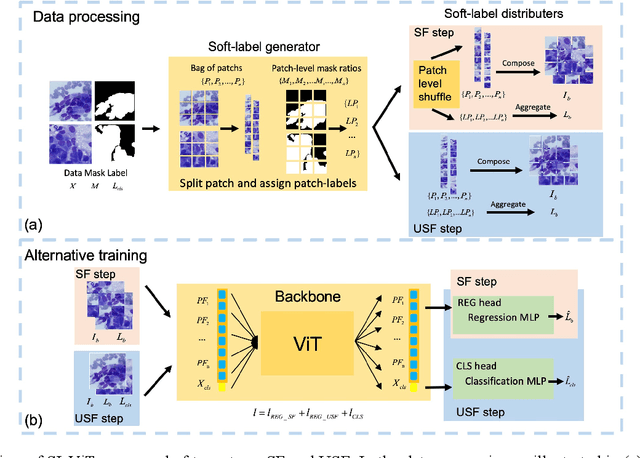
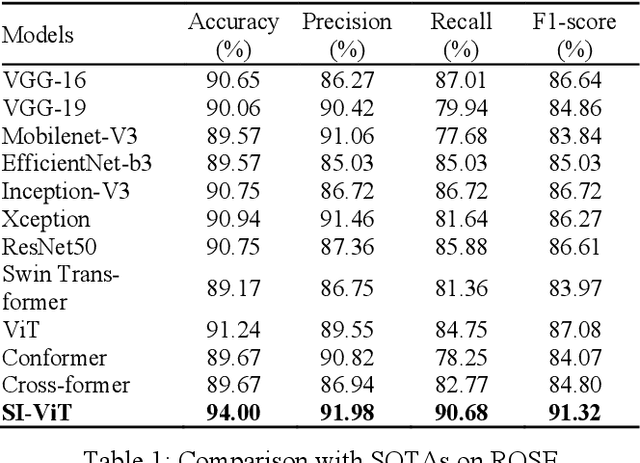
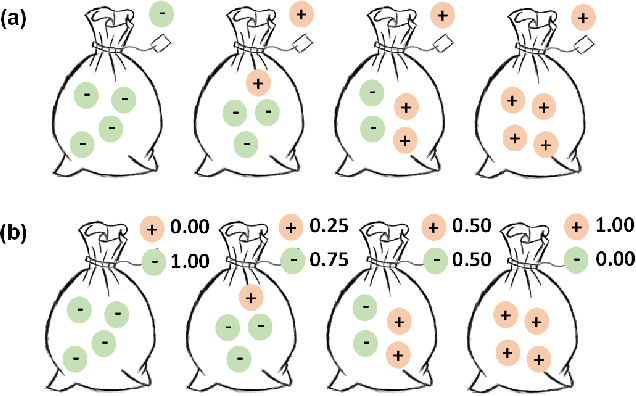
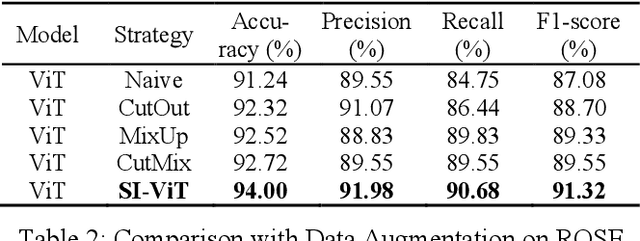
The rapid on-site evaluation (ROSE) technique can signifi-cantly accelerate the diagnosis of pancreatic cancer by im-mediately analyzing the fast-stained cytopathological images. Computer-aided diagnosis (CAD) can potentially address the shortage of pathologists in ROSE. However, the cancerous patterns vary significantly between different samples, making the CAD task extremely challenging. Besides, the ROSE images have complicated perturbations regarding color distribution, brightness, and contrast due to different staining qualities and various acquisition device types. To address these challenges, we proposed a shuffle instances-based Vision Transformer (SI-ViT) approach, which can reduce the perturbations and enhance the modeling among the instances. With the regrouped bags of shuffle instances and their bag-level soft labels, the approach utilizes a regression head to make the model focus on the cells rather than various perturbations. Simultaneously, combined with a classification head, the model can effectively identify the general distributive patterns among different instances. The results demonstrate significant improvements in the classification accuracy with more accurate attention regions, indicating that the diverse patterns of ROSE images are effectively extracted, and the complicated perturbations are significantly reduced. It also suggests that the SI-ViT has excellent potential in analyzing cytopathological images. The code and experimental results are available at https://github.com/sagizty/MIL-SI.
Regularized directional representations for medical image registration
Nov 30, 2021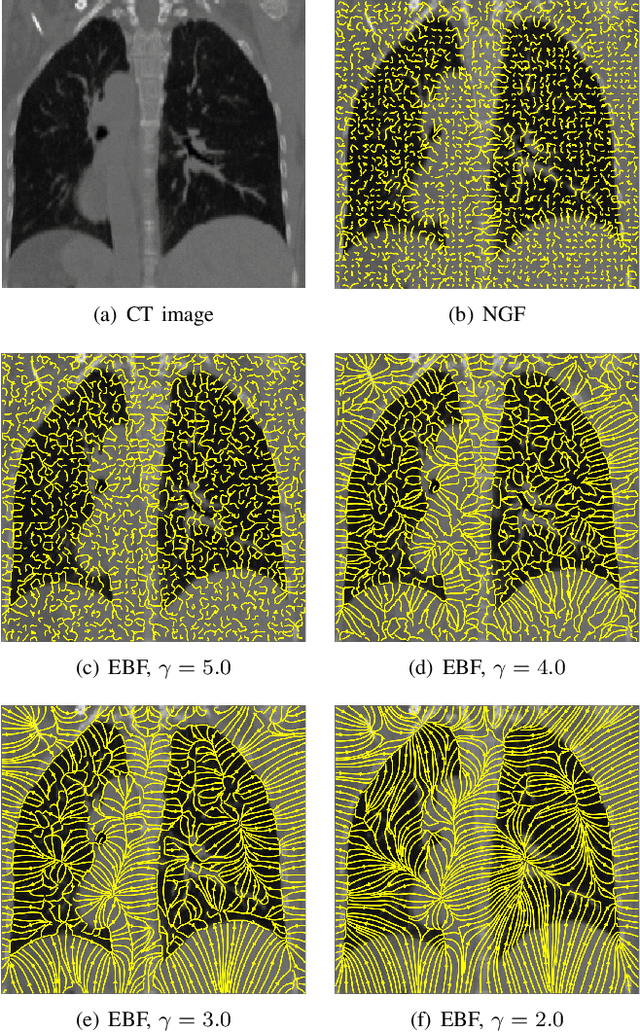
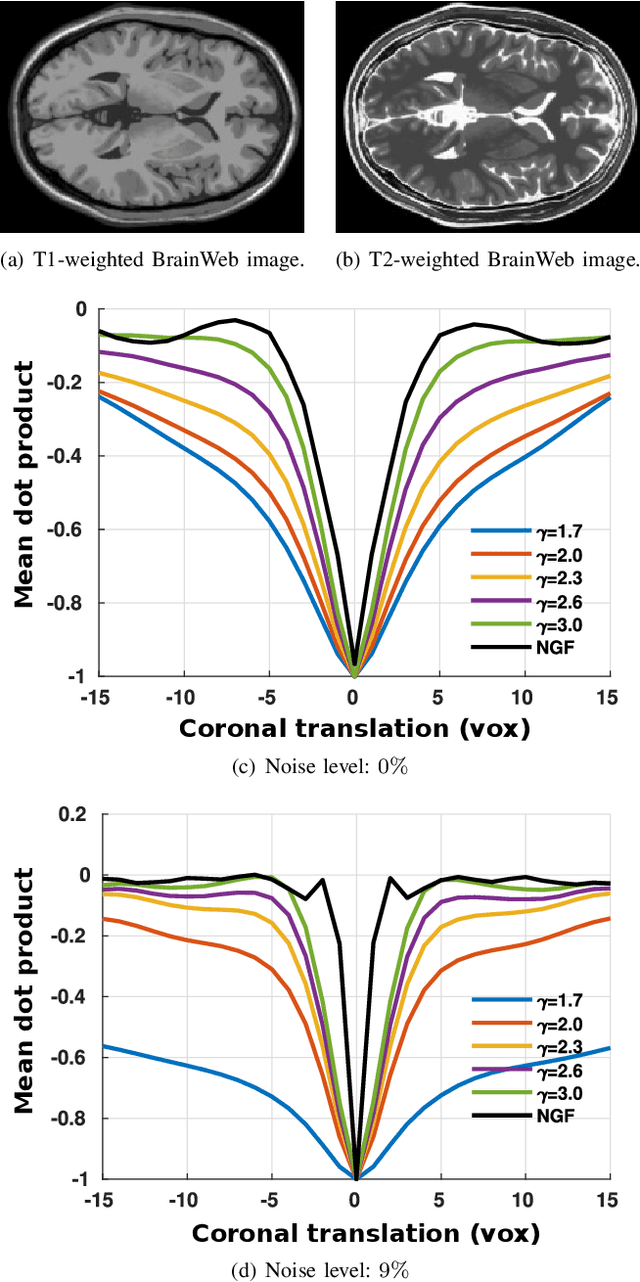
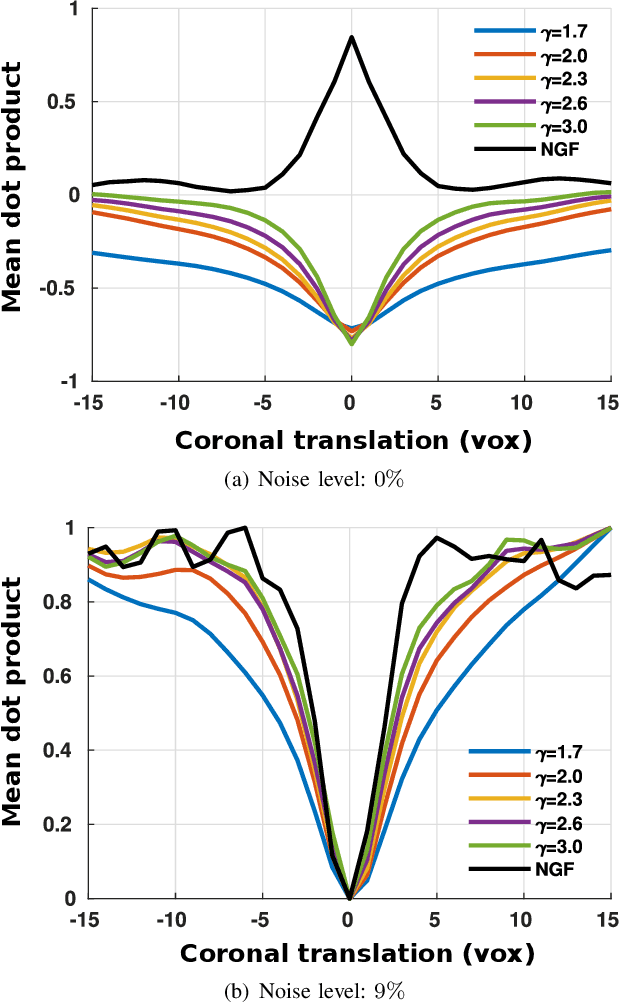
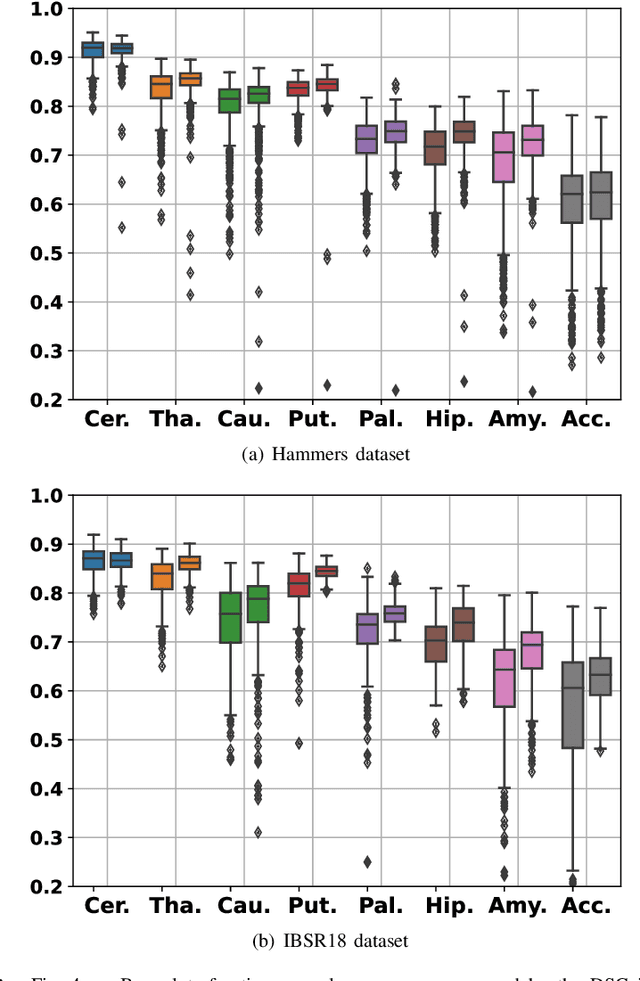
In image registration, many efforts have been devoted to the development of alternatives to the popular normalized mutual information criterion. Concurrently to these efforts, an increasing number of works have demonstrated that substantial gains in registration accuracy can also be achieved by aligning structural representations of images rather than images themselves. Following this research path, we propose a new method for mono- and multimodal image registration based on the alignment of regularized vector fields derived from structural information such as gradient vector flow fields, a technique we call \textit{vector field similarity}. Our approach can be combined in a straightforward fashion with any existing registration framework by substituting vector field similarity to intensity-based registration. In our experiments, we show that the proposed approach compares favourably with conventional image alignment on several public image datasets using a diversity of imaging modalities and anatomical locations.
Underwater Ranker: Learn Which Is Better and How to Be Better
Aug 14, 2022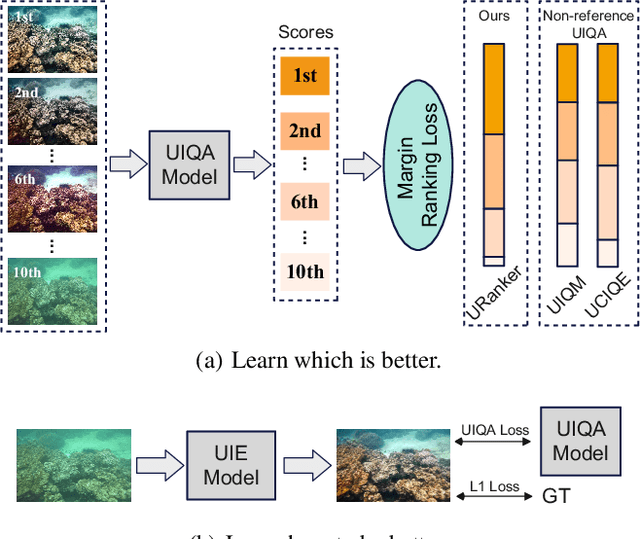
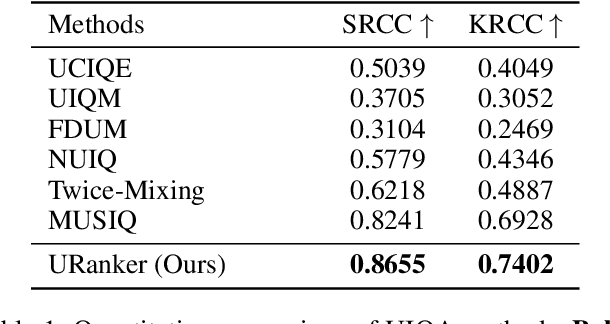

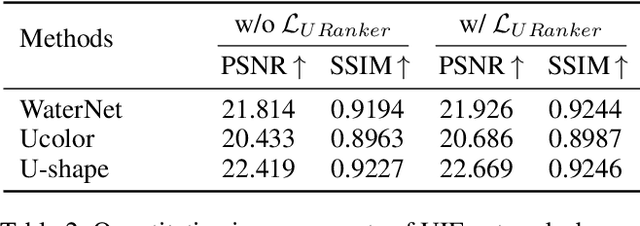
In this paper, we present a ranking-based underwater image quality assessment (UIQA) method, abbreviated as URanker. The URanker is built on the efficient conv-attentional image Transformer. In terms of underwater images, we specially devise (1) the histogram prior that embeds the color distribution of an underwater image as histogram token to attend global degradation and (2) the dynamic cross-scale correspondence to model local degradation. The final prediction depends on the class tokens from different scales, which comprehensively considers multi-scale dependencies. With the margin ranking loss, our URanker can accurately rank the order of underwater images of the same scene enhanced by different underwater image enhancement (UIE) algorithms according to their visual quality. To achieve that, we also contribute a dataset, URankerSet, containing sufficient results enhanced by different UIE algorithms and the corresponding perceptual rankings, to train our URanker. Apart from the good performance of URanker, we found that a simple U-shape UIE network can obtain promising performance when it is coupled with our pre-trained URanker as additional supervision. In addition, we also propose a normalization tail that can significantly improve the performance of UIE networks. Extensive experiments demonstrate the state-of-the-art performance of our method. The key designs of our method are discussed. We will release our dataset and code.