 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Instance Mixing across Domains in Aerial Segmentation
Oct 12, 2022
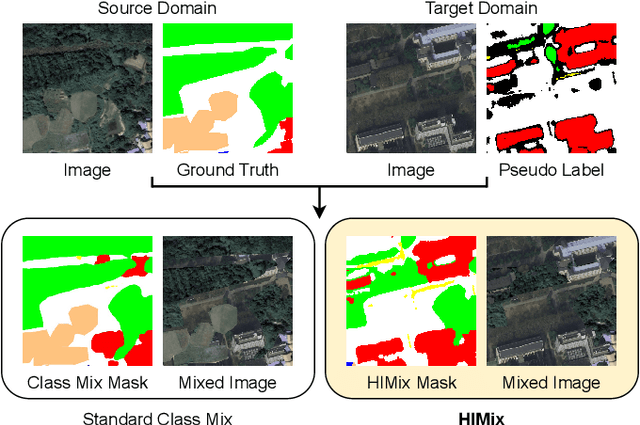
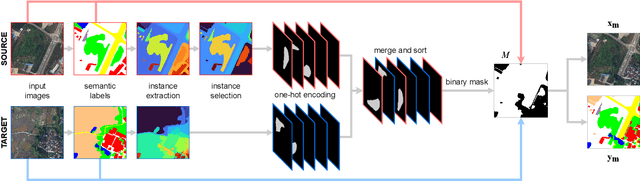

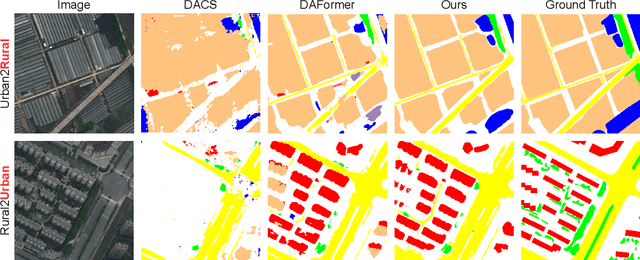
We investigate the task of unsupervised domain adaptation in aerial semantic segmentation and discover that the current state-of-the-art algorithms designed for autonomous driving based on domain mixing do not translate well to the aerial setting. This is due to two factors: (i) a large disparity in the extension of the semantic categories, which causes a domain imbalance in the mixed image, and (ii) a weaker structural consistency in aerial scenes than in driving scenes since the same scene might be viewed from different perspectives and there is no well-defined and repeatable structure of the semantic elements in the images. Our solution to these problems is composed of: (i) a new mixing strategy for aerial segmentation across domains called Hierarchical Instance Mixing (HIMix), which extracts a set of connected components from each semantic mask and mixes them according to a semantic hierarchy and, (ii) a twin-head architecture in which two separate segmentation heads are fed with variations of the same images in a contrastive fashion to produce finer segmentation maps. We conduct extensive experiments on the LoveDA benchmark, where our solution outperforms the current state-of-the-art.
Multi-image Super-resolution via Quality Map Associated Temporal Attention Network
Feb 26, 2022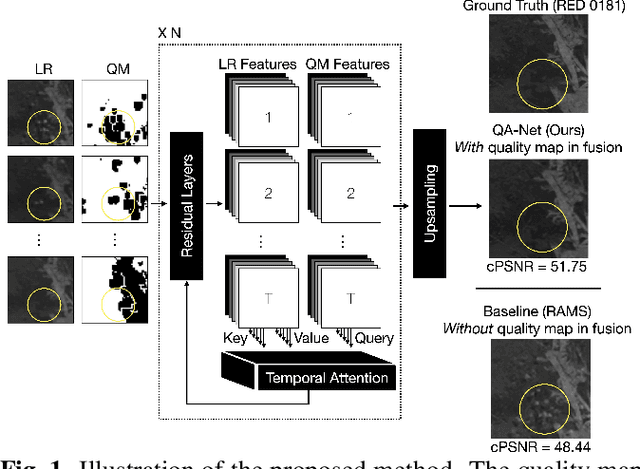
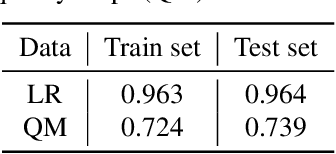

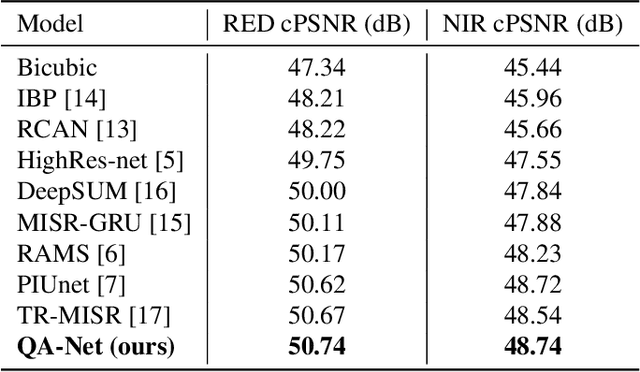
With the rising interest in deep learning-based methods in remote sensing, neural networks have made remarkable advancements in multi-image fusion and super-resolution. To fully exploit the advantages of multi-image super-resolution, temporal attention is crucial as it allows a model to focus on reliable features rather than noises. Despite the presence of quality maps (QMs) that indicate noises in images, most of the methods tested in the PROBA-V dataset have not been used QMs for temporal attention. We present a quality map associated temporal attention network (QA-Net), a novel method that incorporates QMs into both feature representation and fusion processes for the first time. Low-resolution features are temporally attended by QM features in repeated multi-head attention modules. The proposed method achieved state-of-the-art results in the PROBA-V dataset.
Prior-Aware Synthetic Data to the Rescue: Animal Pose Estimation with Very Limited Real Data
Aug 30, 2022
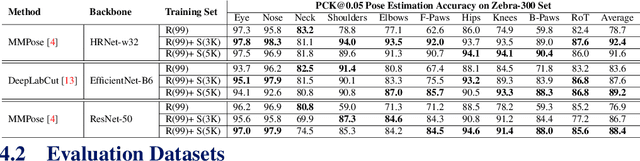
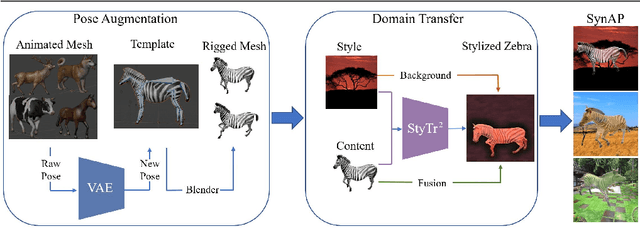
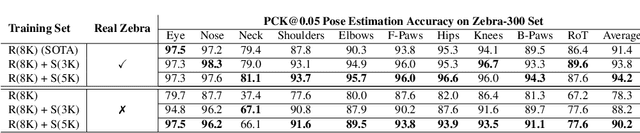
Accurately annotated image datasets are essential components for studying animal behaviors from their poses. Compared to the number of species we know and may exist, the existing labeled pose datasets cover only a small portion of them, while building comprehensive large-scale datasets is prohibitively expensive. Here, we present a very data efficient strategy targeted for pose estimation in quadrupeds that requires only a small amount of real images from the target animal. It is confirmed that fine-tuning a backbone network with pretrained weights on generic image datasets such as ImageNet can mitigate the high demand for target animal pose data and shorten the training time by learning the the prior knowledge of object segmentation and keypoint estimation in advance. However, when faced with serious data scarcity (i.e., $<10^2$ real images), the model performance stays unsatisfactory, particularly for limbs with considerable flexibility and several comparable parts. We therefore introduce a prior-aware synthetic animal data generation pipeline called PASyn to augment the animal pose data essential for robust pose estimation. PASyn generates a probabilistically-valid synthetic pose dataset, SynAP, through training a variational generative model on several animated 3D animal models. In addition, a style transfer strategy is utilized to blend the synthetic animal image into the real backgrounds. We evaluate the improvement made by our approach with three popular backbone networks and test their pose estimation accuracy on publicly available animal pose images as well as collected from real animals in a zoo.
Random Quantum Neural Networks (RQNN) for Noisy Image Recognition
Mar 03, 2022
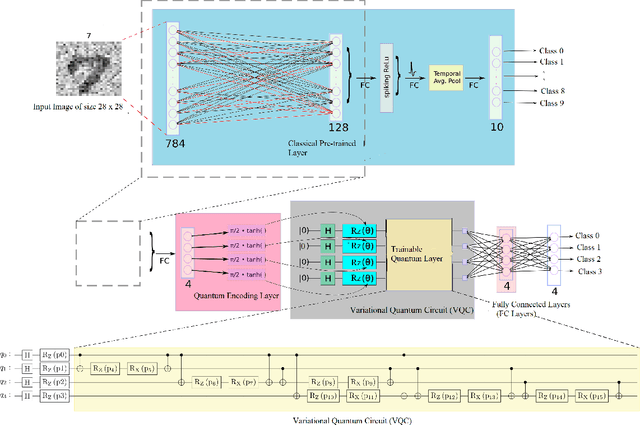
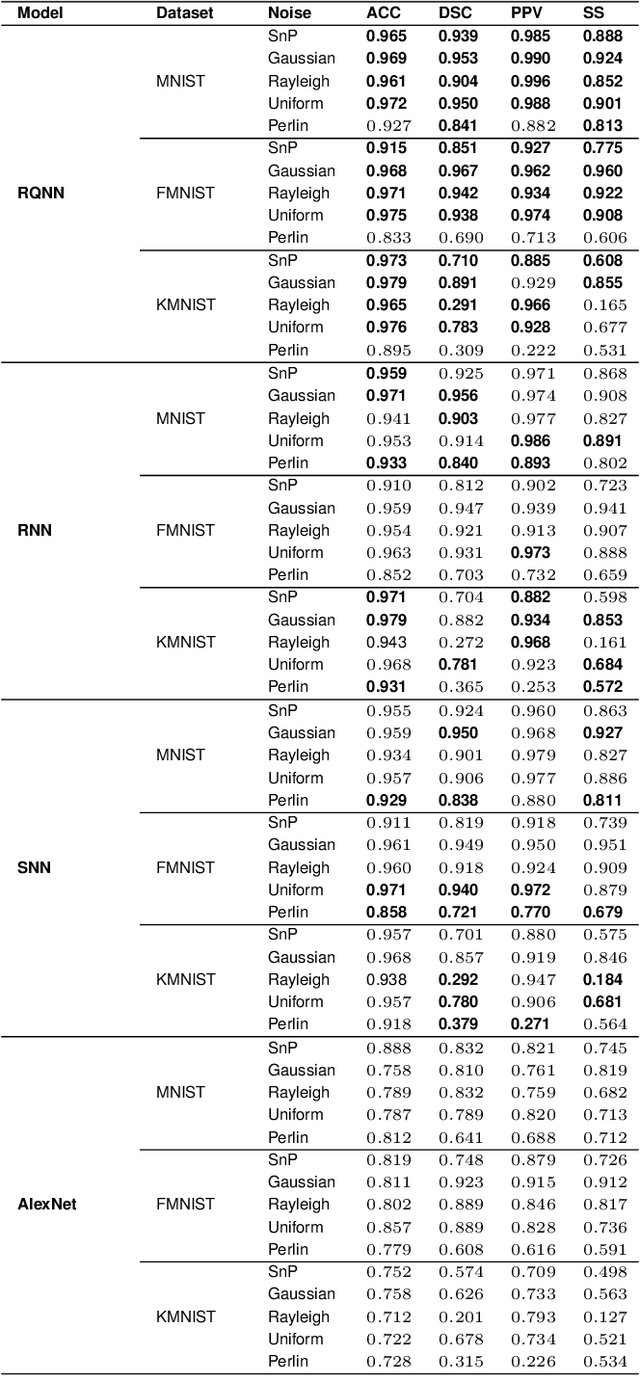
Classical Random Neural Networks (RNNs) have demonstrated effective applications in decision making, signal processing, and image recognition tasks. However, their implementation has been limited to deterministic digital systems that output probability distributions in lieu of stochastic behaviors of random spiking signals. We introduce the novel class of supervised Random Quantum Neural Networks (RQNNs) with a robust training strategy to better exploit the random nature of the spiking RNN. The proposed RQNN employs hybrid classical-quantum algorithms with superposition state and amplitude encoding features, inspired by quantum information theory and the brain's spatial-temporal stochastic spiking property of neuron information encoding. We have extensively validated our proposed RQNN model, relying on hybrid classical-quantum algorithms via the PennyLane Quantum simulator with a limited number of \emph{qubits}. Experiments on the MNIST, FashionMNIST, and KMNIST datasets demonstrate that the proposed RQNN model achieves an average classification accuracy of $94.9\%$. Additionally, the experimental findings illustrate the proposed RQNN's effectiveness and resilience in noisy settings, with enhanced image classification accuracy when compared to the classical counterparts (RNNs), classical Spiking Neural Networks (SNNs), and the classical convolutional neural network (AlexNet). Furthermore, the RQNN can deal with noise, which is useful for various applications, including computer vision in NISQ devices. The PyTorch code (https://github.com/darthsimpus/RQN) is made available on GitHub to reproduce the results reported in this manuscript.
Efficient Perception, Planning, and Control Algorithms for Vision-Based Automated Vehicles
Sep 15, 2022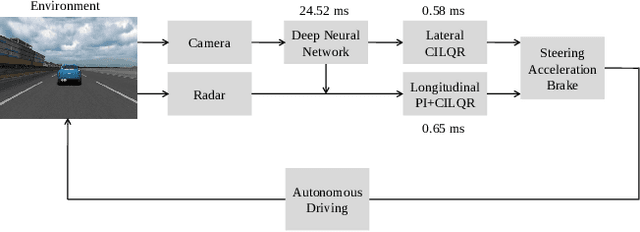
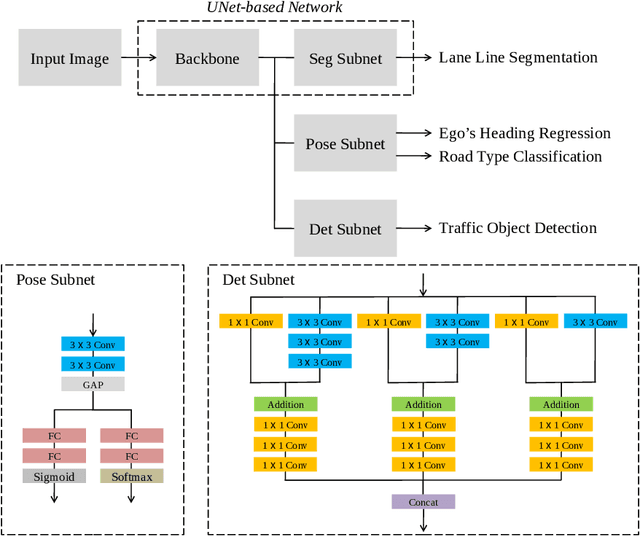

Owing to resource limitations, efficient computation systems have long been a critical demand for those designing autonomous vehicles. Additionally, sensor cost and size restrict the development of self-driving cars. This paper presents an efficient framework for the operation of vision-based automatic vehicles; a front-facing camera and a few inexpensive radars are the required sensors for driving environment perception. The proposed algorithm comprises a multi-task UNet (MTUNet) network for extracting image features and constrained iterative linear quadratic regulator (CILQR) modules for rapid lateral and longitudinal motion planning. The MTUNet is designed to simultaneously solve lane line segmentation, ego vehicle heading angle regression, road type classification, and traffic object detection tasks at an approximate speed of 40 FPS when an RGB image of size 228 x 228 is fed into it. The CILQR algorithms then take processed MTUNet outputs and radar data as their input to produce driving commands for lateral and longitudinal vehicle automation guidance; both optimal control problems can be solved within 1 ms. The proposed CILQR controllers are shown to be more efficient than the sequential quadratic programming (SQP) methods and can collaborate with the MTUNet to drive a car autonomously in unseen simulation environments for lane-keeping and car-following maneuvers. Our experiments demonstrate that the proposed autonomous driving system is applicable to modern automobiles.
Unsupervised Object Representation Learning using Translation and Rotation Group Equivariant VAE
Oct 24, 2022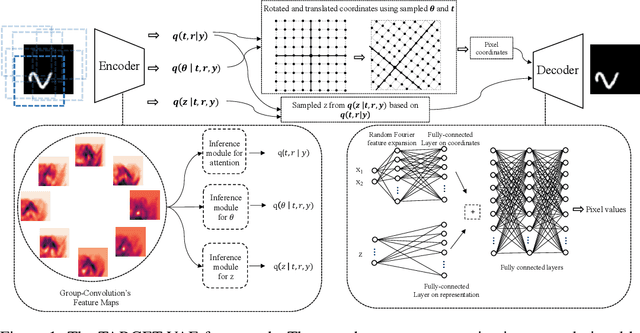
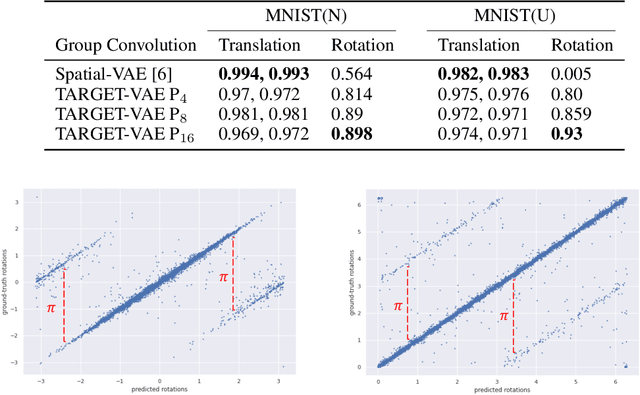
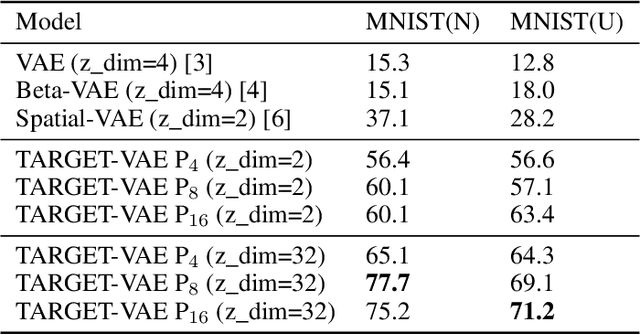
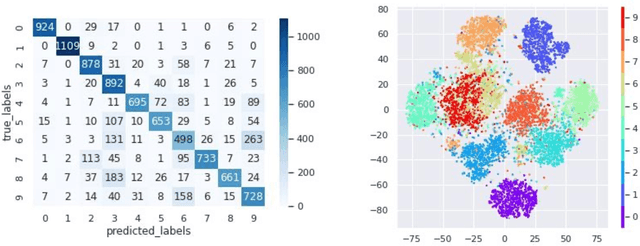
In many imaging modalities, objects of interest can occur in a variety of locations and poses (i.e. are subject to translations and rotations in 2d or 3d), but the location and pose of an object does not change its semantics (i.e. the object's essence). That is, the specific location and rotation of an airplane in satellite imagery, or the 3d rotation of a chair in a natural image, or the rotation of a particle in a cryo-electron micrograph, do not change the intrinsic nature of those objects. Here, we consider the problem of learning semantic representations of objects that are invariant to pose and location in a fully unsupervised manner. We address shortcomings in previous approaches to this problem by introducing TARGET-VAE, a translation and rotation group-equivariant variational autoencoder framework. TARGET-VAE combines three core innovations: 1) a rotation and translation group-equivariant encoder architecture, 2) a structurally disentangled distribution over latent rotation, translation, and a rotation-translation-invariant semantic object representation, which are jointly inferred by the approximate inference network, and 3) a spatially equivariant generator network. In comprehensive experiments, we show that TARGET-VAE learns disentangled representations without supervision that significantly improve upon, and avoid the pathologies of, previous methods. When trained on images highly corrupted by rotation and translation, the semantic representations learned by TARGET-VAE are similar to those learned on consistently posed objects, dramatically improving clustering in the semantic latent space. Furthermore, TARGET-VAE is able to perform remarkably accurate unsupervised pose and location inference. We expect methods like TARGET-VAE will underpin future approaches for unsupervised object generation, pose prediction, and object detection.
Fast and High-Quality Image Denoising via Malleable Convolutions
Jan 02, 2022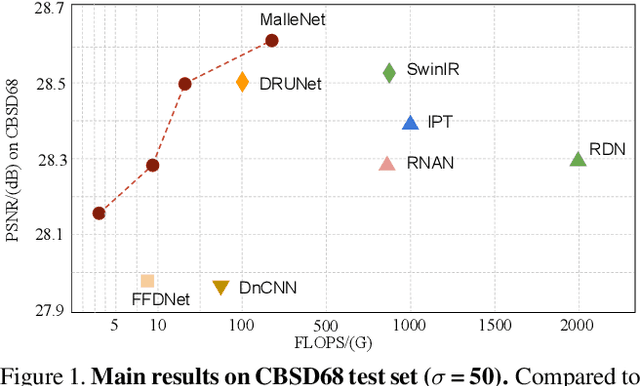
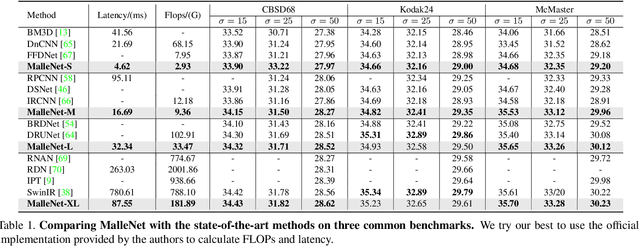
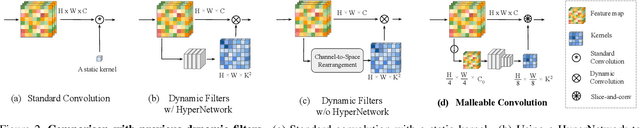
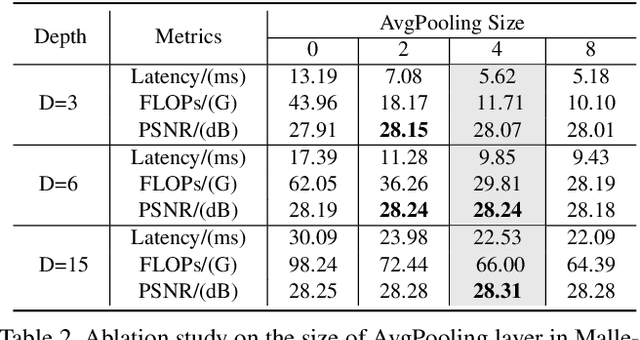
Many image processing networks apply a single set of static convolutional kernels across the entire input image, which is sub-optimal for natural images, as they often consist of heterogeneous visual patterns. Recent work in classification, segmentation, and image restoration has demonstrated that dynamic kernels outperform static kernels at modeling local image statistics. However, these works often adopt per-pixel convolution kernels, which introduce high memory and computation costs. To achieve spatial-varying processing without significant overhead, we present \textbf{Malle}able \textbf{Conv}olution (\textbf{MalleConv}), as an efficient variant of dynamic convolution. The weights of \ours are dynamically produced by an efficient predictor network capable of generating content-dependent outputs at specific spatial locations. Unlike previous works, \ours generates a much smaller set of spatially-varying kernels from input, which enlarges the network's receptive field and significantly reduces computational and memory costs. These kernels are then applied to a full-resolution feature map through an efficient slice-and-conv operator with minimum memory overhead. We further build a efficient denoising network using MalleConv, coined as \textbf{MalleNet}. It achieves high quality results without very deep architecture, \eg, it is 8.91$\times$ faster than the best performed denoising algorithms (SwinIR), while maintaining similar performance. We also show that a single \ours added to a standard convolution-based backbones can contribute significantly reduce the computational cost or boost image quality at similar cost. Project page: https://yifanjiang.net/MalleConv.html
Large-scale Bilingual Language-Image Contrastive Learning
Mar 28, 2022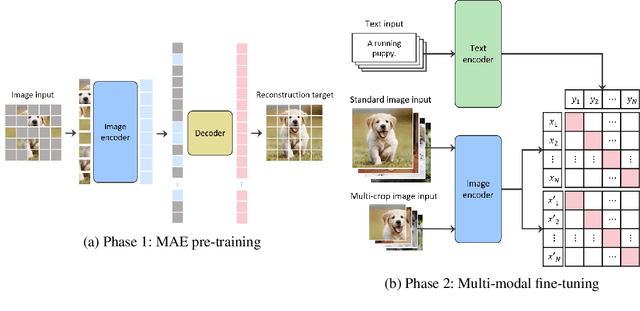
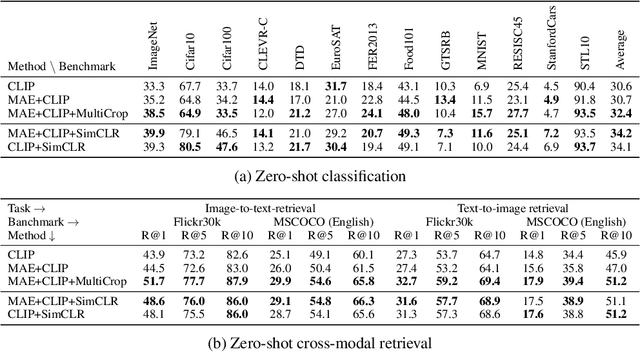
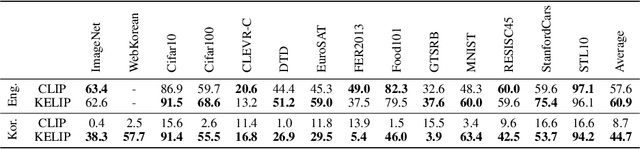
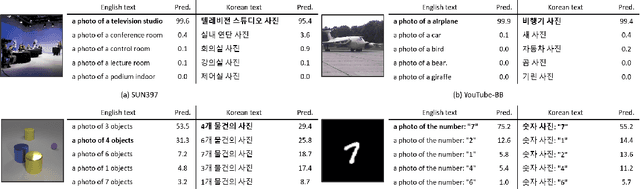
This paper is a technical report to share our experience and findings building a Korean and English bilingual multimodal model. While many of the multimodal datasets focus on English and multilingual multimodal research uses machine-translated texts, employing such machine-translated texts is limited to describing unique expressions, cultural information, and proper noun in languages other than English. In this work, we collect 1.1 billion image-text pairs (708 million Korean and 476 million English) and train a bilingual multimodal model named KELIP. We introduce simple yet effective training schemes, including MAE pre-training and multi-crop augmentation. Extensive experiments demonstrate that a model trained with such training schemes shows competitive performance in both languages. Moreover, we discuss multimodal-related research questions: 1) strong augmentation-based methods can distract the model from learning proper multimodal relations; 2) training multimodal model without cross-lingual relation can learn the relation via visual semantics; 3) our bilingual KELIP can capture cultural differences of visual semantics for the same meaning of words; 4) a large-scale multimodal model can be used for multimodal feature analogy. We hope that this work will provide helpful experience and findings for future research. We provide an open-source pre-trained KELIP.
Learn from Unpaired Data for Image Restoration: A Variational Bayes Approach
Apr 21, 2022



Collecting paired training data is difficult in practice, but the unpaired samples broadly exist. Current approaches aim at generating synthesized training data from the unpaired samples by exploring the relationship between the corrupted and clean data. This work proposes LUD-VAE, a deep generative method to learn the joint probability density function from data sampled from marginal distributions. Our approach is based on a carefully designed probabilistic graphical model in which the clean and corrupted data domains are conditionally independent. Using variational inference, we maximize the evidence lower bound (ELBO) to estimate the joint probability density function. Furthermore, we show that the ELBO is computable without paired samples under the inference invariant assumption. This property provides the mathematical rationale of our approach in the unpaired setting. Finally, we apply our method to real-world image denoising and super-resolution tasks and train the models using the synthetic data generated by the LUD-VAE. Experimental results validate the advantages of our method over other learnable approaches.
Efficient Subgraph Isomorphism using Graph Topology
Sep 15, 2022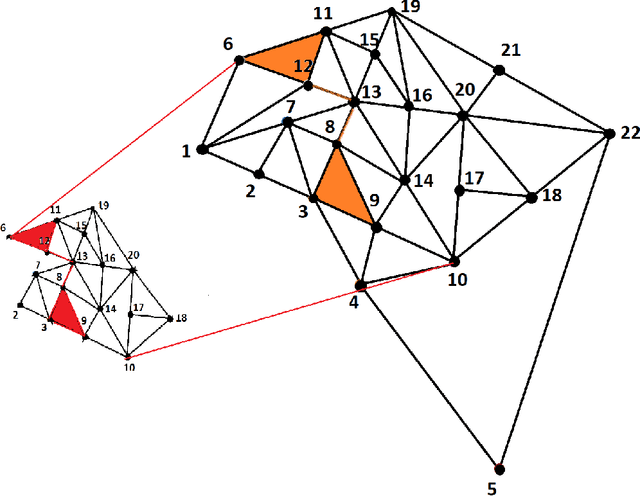
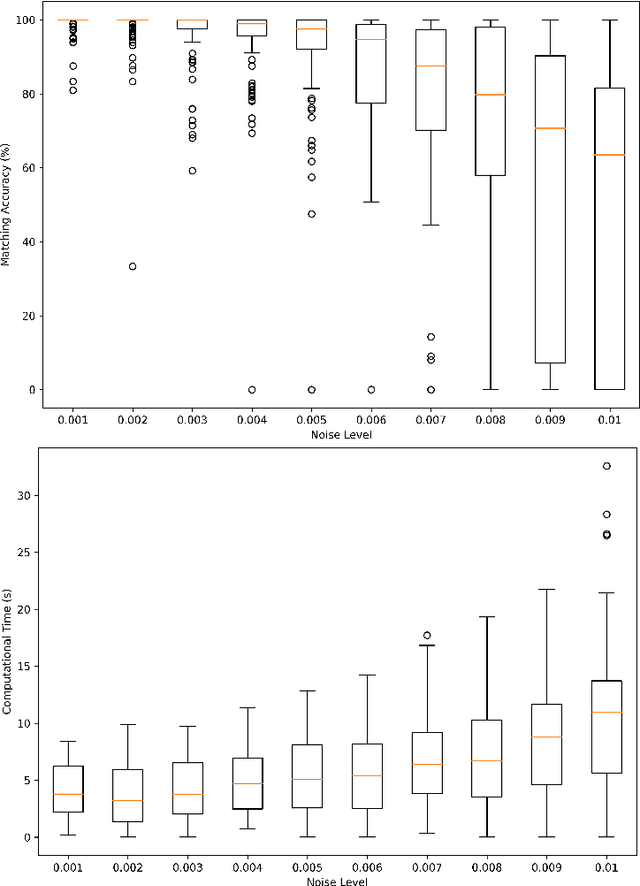

Subgraph isomorphism or subgraph matching is generally considered as an NP-complete problem, made more complex in practical applications where the edge weights take real values and are subject to measurement noise and possible anomalies. To the best of our knowledge, almost all subgraph matching methods utilize node labels to perform node-node matching. In the absence of such labels (in applications such as image matching and map matching among others), these subgraph matching methods do not work. We propose a method for identifying the node correspondence between a subgraph and a full graph in the inexact case without node labels in two steps - (a) extract the minimal unique topology preserving subset from the subgraph and find its feasible matching in the full graph, and (b) implement a consensus-based algorithm to expand the matched node set by pairing unique paths based on boundary commutativity. Going beyond the existing subgraph matching approaches, the proposed method is shown to have realistically sub-linear computational efficiency, robustness to random measurement noise, and good statistical properties. Our method is also readily applicable to the exact matching case without loss of generality. To demonstrate the effectiveness of the proposed method, a simulation and a case study is performed on the Erdos-Renyi random graphs and the image-based affine covariant features dataset respectively.