 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MACAB: Model-Agnostic Clean-Annotation Backdoor to Object Detection with Natural Trigger in Real-World
Sep 06, 2022
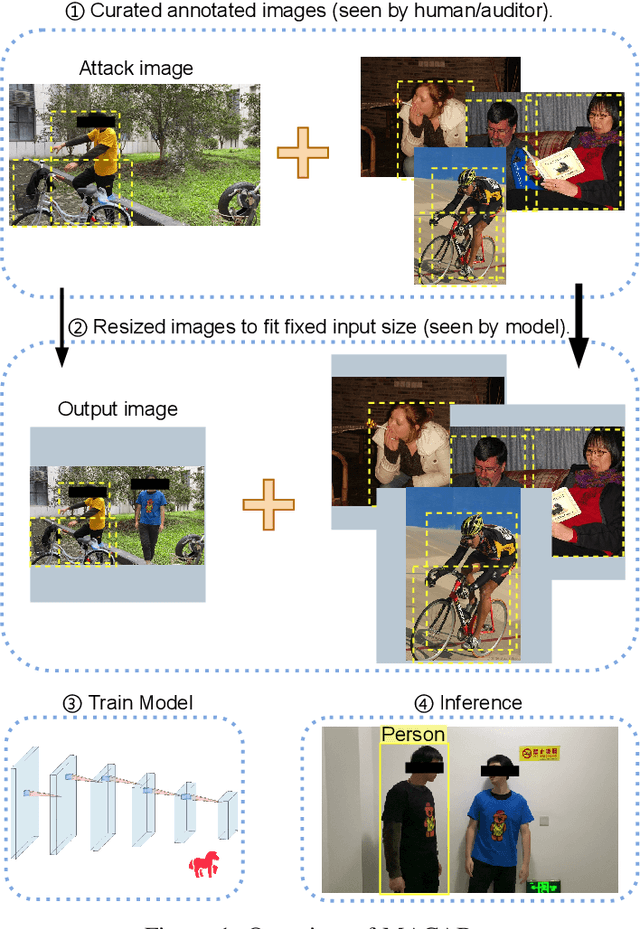
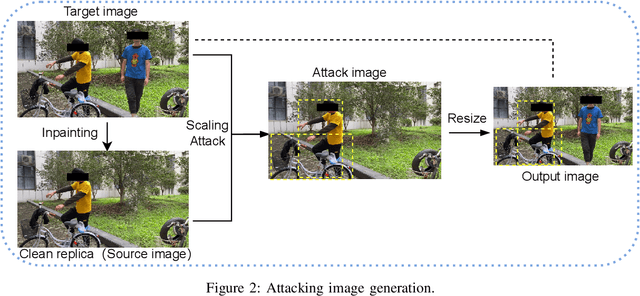


Object detection is the foundation of various critical computer-vision tasks such as segmentation, object tracking, and event detection. To train an object detector with satisfactory accuracy, a large amount of data is required. However, due to the intensive workforce involved with annotating large datasets, such a data curation task is often outsourced to a third party or relied on volunteers. This work reveals severe vulnerabilities of such data curation pipeline. We propose MACAB that crafts clean-annotated images to stealthily implant the backdoor into the object detectors trained on them even when the data curator can manually audit the images. We observe that the backdoor effect of both misclassification and the cloaking are robustly achieved in the wild when the backdoor is activated with inconspicuously natural physical triggers. Backdooring non-classification object detection with clean-annotation is challenging compared to backdooring existing image classification tasks with clean-label, owing to the complexity of having multiple objects within each frame, including victim and non-victim objects. The efficacy of the MACAB is ensured by constructively i abusing the image-scaling function used by the deep learning framework, ii incorporating the proposed adversarial clean image replica technique, and iii combining poison data selection criteria given constrained attacking budget. Extensive experiments demonstrate that MACAB exhibits more than 90% attack success rate under various real-world scenes. This includes both cloaking and misclassification backdoor effect even restricted with a small attack budget. The poisoned samples cannot be effectively identified by state-of-the-art detection techniques.The comprehensive video demo is at https://youtu.be/MA7L_LpXkp4, which is based on a poison rate of 0.14% for YOLOv4 cloaking backdoor and Faster R-CNN misclassification backdoor.
Background Invariance Testing According to Semantic Proximity
Aug 19, 2022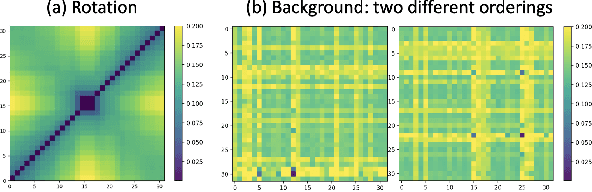
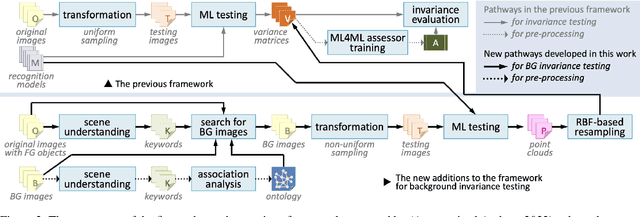

In many applications, machine learned (ML) models are required to hold some invariance qualities, such as rotation, size, intensity, and background invariance. Unlike many types of variance, the variants of background scenes cannot be ordered easily, which makes it difficult to analyze the robustness and biases of the models concerned. In this work, we present a technical solution for ordering background scenes according to their semantic proximity to a target image that contains a foreground object being tested. We make use of the results of object recognition as the semantic description of each image, and construct an ontology for storing knowledge about relationships among different objects using association analysis. This ontology enables (i) efficient and meaningful search for background scenes of different semantic distances to a target image, (ii) quantitative control of the distribution and sparsity of the sampled background scenes, and (iii) quality assurance using visual representations of invariance testing results (referred to as variance matrices). In this paper, we also report the training of an ML4ML assessor to evaluate the invariance quality of ML models automatically.
Arbitrary Style Transfer with Structure Enhancement by Combining the Global and Local Loss
Jul 23, 2022
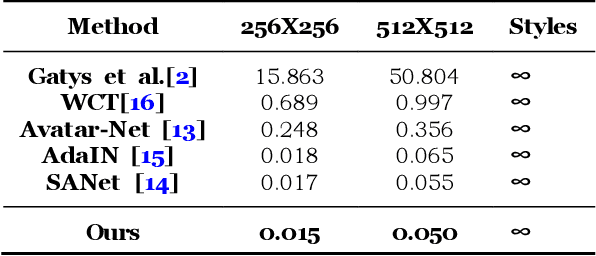
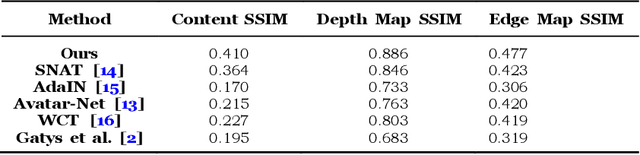
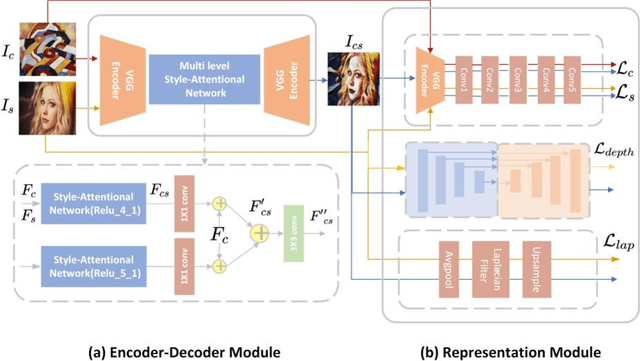
Arbitrary style transfer generates an artistic image which combines the structure of a content image and the artistic style of the artwork by using only one trained network. The image representation used in this method contains content structure representation and the style patterns representation, which is usually the features representation of high-level in the pre-trained classification networks. However, the traditional classification networks were designed for classification which usually focus on high-level features and ignore other features. As the result, the stylized images distribute style elements evenly throughout the image and make the overall image structure unrecognizable. To solve this problem, we introduce a novel arbitrary style transfer method with structure enhancement by combining the global and local loss. The local structure details are represented by Lapstyle and the global structure is controlled by the image depth. Experimental results demonstrate that our method can generate higher-quality images with impressive visual effects on several common datasets, comparing with other state-of-the-art methods.
USIS: Unsupervised Semantic Image Synthesis
Sep 29, 2021
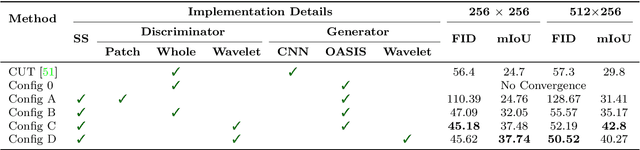

Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a photorealistic image is synthesized from a segmentation mask. SIS has mostly been addressed as a supervised problem. However, state-of-the-art methods depend on a huge amount of labeled data and cannot be applied in an unpaired setting. On the other hand, generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and feed them to traditional convolutional networks, which then learn correspondences in appearance instead of semantic content. In this initial work, we propose a new Unsupervised paradigm for Semantic Image Synthesis (USIS) as a first step towards closing the performance gap between paired and unpaired settings. Notably, the framework deploys a SPADE generator that learns to output images with visually separable semantic classes using a self-supervised segmentation loss. Furthermore, in order to match the color and texture distribution of real images without losing high-frequency information, we propose to use whole image wavelet-based discrimination. We test our methodology on 3 challenging datasets and demonstrate its ability to generate multimodal photorealistic images with an improved quality in the unpaired setting.
Visual Language Maps for Robot Navigation
Oct 17, 2022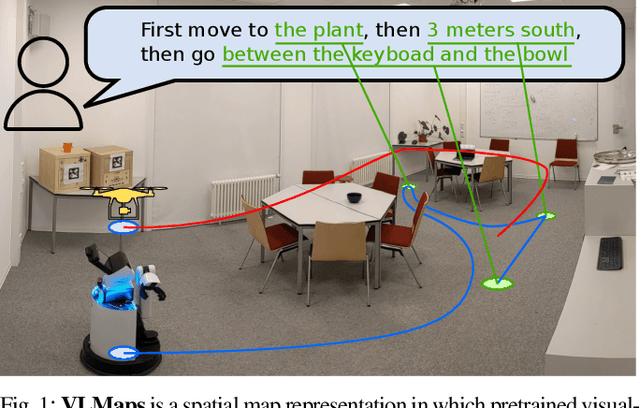

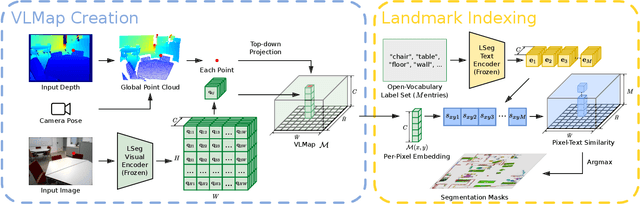

Grounding language to the visual observations of a navigating agent can be performed using off-the-shelf visual-language models pretrained on Internet-scale data (e.g., image captions). While this is useful for matching images to natural language descriptions of object goals, it remains disjoint from the process of mapping the environment, so that it lacks the spatial precision of classic geometric maps. To address this problem, we propose VLMaps, a spatial map representation that directly fuses pretrained visual-language features with a 3D reconstruction of the physical world. VLMaps can be autonomously built from video feed on robots using standard exploration approaches and enables natural language indexing of the map without additional labeled data. Specifically, when combined with large language models (LLMs), VLMaps can be used to (i) translate natural language commands into a sequence of open-vocabulary navigation goals (which, beyond prior work, can be spatial by construction, e.g., "in between the sofa and TV" or "three meters to the right of the chair") directly localized in the map, and (ii) can be shared among multiple robots with different embodiments to generate new obstacle maps on-the-fly (by using a list of obstacle categories). Extensive experiments carried out in simulated and real world environments show that VLMaps enable navigation according to more complex language instructions than existing methods. Videos are available at https://vlmaps.github.io.
Semi-Autoregressive Image Captioning
Oct 13, 2021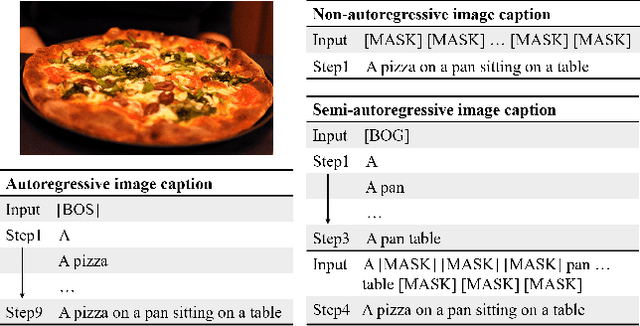
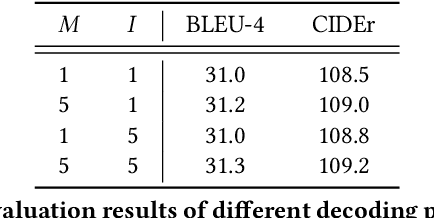
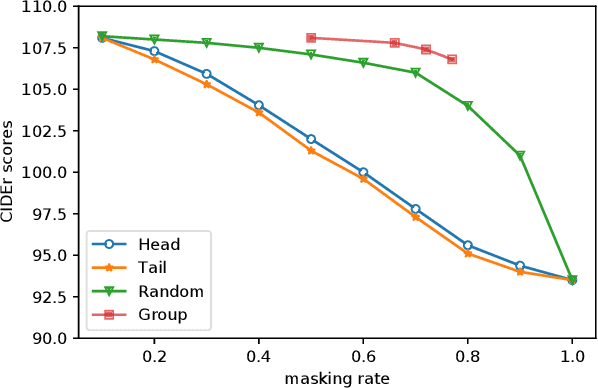
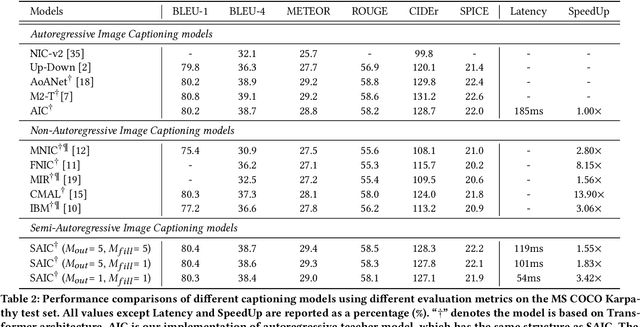
Current state-of-the-art approaches for image captioning typically adopt an autoregressive manner, i.e., generating descriptions word by word, which suffers from slow decoding issue and becomes a bottleneck in real-time applications. Non-autoregressive image captioning with continuous iterative refinement, which eliminates the sequential dependence in a sentence generation, can achieve comparable performance to the autoregressive counterparts with a considerable acceleration. Nevertheless, based on a well-designed experiment, we empirically proved that iteration times can be effectively reduced when providing sufficient prior knowledge for the language decoder. Towards that end, we propose a novel two-stage framework, referred to as Semi-Autoregressive Image Captioning (SAIC), to make a better trade-off between performance and speed. The proposed SAIC model maintains autoregressive property in global but relieves it in local. Specifically, SAIC model first jumpily generates an intermittent sequence in an autoregressive manner, that is, it predicts the first word in every word group in order. Then, with the help of the partially deterministic prior information and image features, SAIC model non-autoregressively fills all the skipped words with one iteration. Experimental results on the MS COCO benchmark demonstrate that our SAIC model outperforms the preceding non-autoregressive image captioning models while obtaining a competitive inference speedup. Code is available at https://github.com/feizc/SAIC.
Unsupervised Object-Centric Learning with Bi-Level Optimized Query Slot Attention
Oct 17, 2022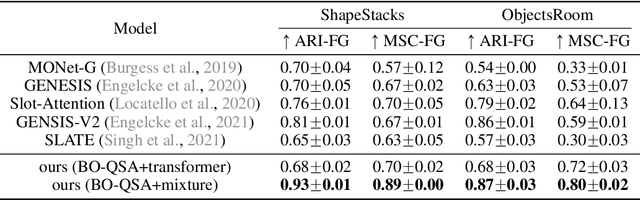

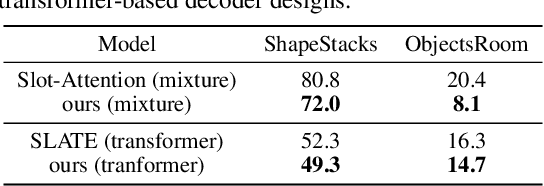
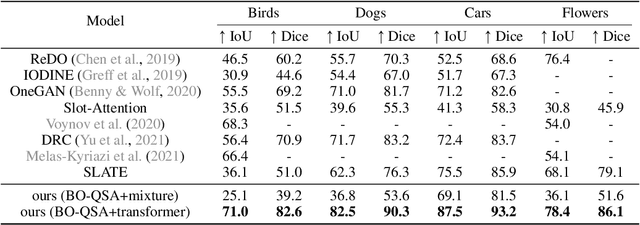
The ability to decompose complex natural scenes into meaningful object-centric abstractions lies at the core of human perception and reasoning. In the recent culmination of unsupervised object-centric learning, the Slot-Attention module has played an important role with its simple yet effective design and fostered many powerful variants. These methods, however, have been exceedingly difficult to train without supervision and are ambiguous in the notion of object, especially for complex natural scenes. In this paper, we propose to address these issues by (1) initializing Slot-Attention modules with learnable queries and (2) optimizing the model with bi-level optimization. With simple code adjustments on the vanilla Slot-Attention, our model, Bi-level Optimized Query Slot Attention, achieves state-of-the-art results on both synthetic and complex real-world datasets in unsupervised image segmentation and reconstruction, outperforming previous baselines by a large margin (~10%). We provide thorough ablative studies to validate the necessity and effectiveness of our design. Additionally, our model exhibits excellent potential for concept binding and zero-shot learning. We hope our effort could provide a single home for the design and learning of slot-based models and pave the way for more challenging tasks in object-centric learning. Our implementation is publicly available at https://github.com/Wall-Facer-liuyu/BO-QSA.
Self-Supervised Learning Through Efference Copies
Oct 17, 2022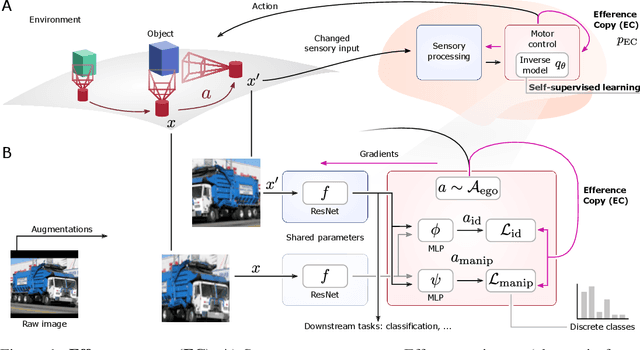
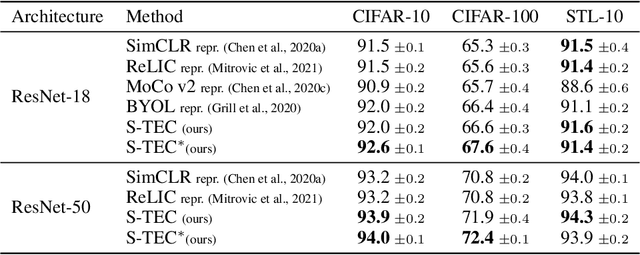
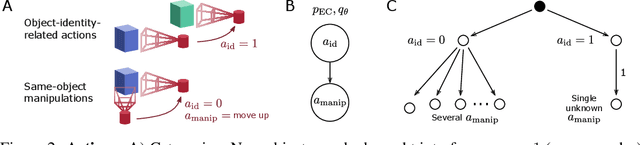
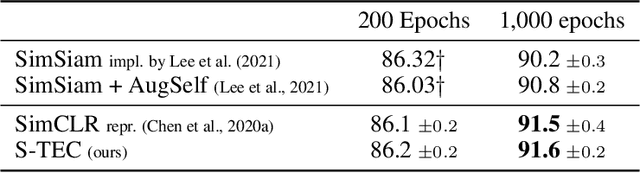
Self-supervised learning (SSL) methods aim to exploit the abundance of unlabelled data for machine learning (ML), however the underlying principles are often method-specific. An SSL framework derived from biological first principles of embodied learning could unify the various SSL methods, help elucidate learning in the brain, and possibly improve ML. SSL commonly transforms each training datapoint into a pair of views, uses the knowledge of this pairing as a positive (i.e. non-contrastive) self-supervisory sign, and potentially opposes it to unrelated, (i.e. contrastive) negative examples. Here, we show that this type of self-supervision is an incomplete implementation of a concept from neuroscience, the Efference Copy (EC). Specifically, the brain also transforms the environment through efference, i.e. motor commands, however it sends to itself an EC of the full commands, i.e. more than a mere SSL sign. In addition, its action representations are likely egocentric. From such a principled foundation we formally recover and extend SSL methods such as SimCLR, BYOL, and ReLIC under a common theoretical framework, i.e. Self-supervision Through Efference Copies (S-TEC). Empirically, S-TEC restructures meaningfully the within- and between-class representations. This manifests as improvement in recent strong SSL baselines in image classification, segmentation, object detection, and in audio. These results hypothesize a testable positive influence from the brain's motor outputs onto its sensory representations.
How many radiographs are needed to re-train a deep learning system for object detection?
Oct 17, 2022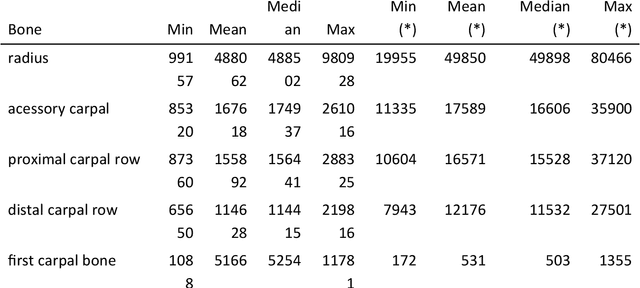
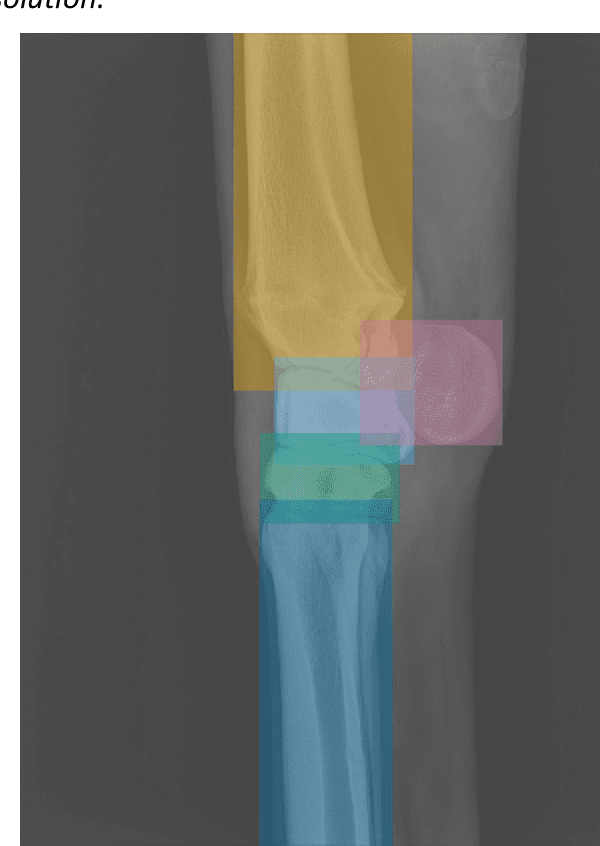
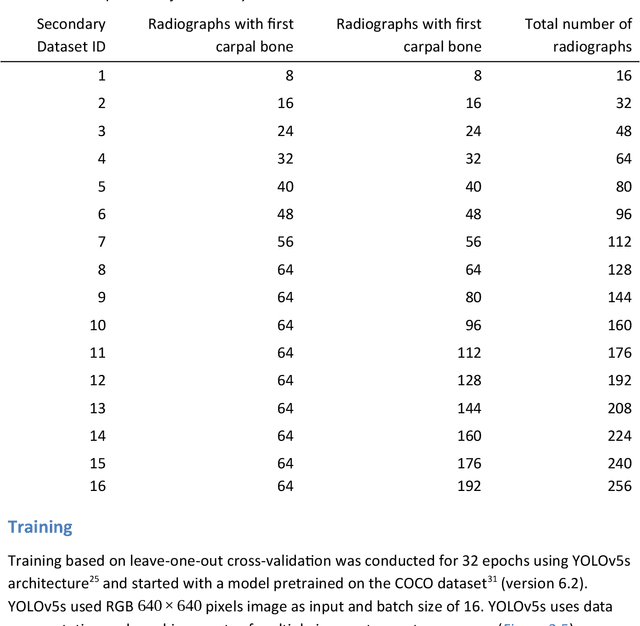
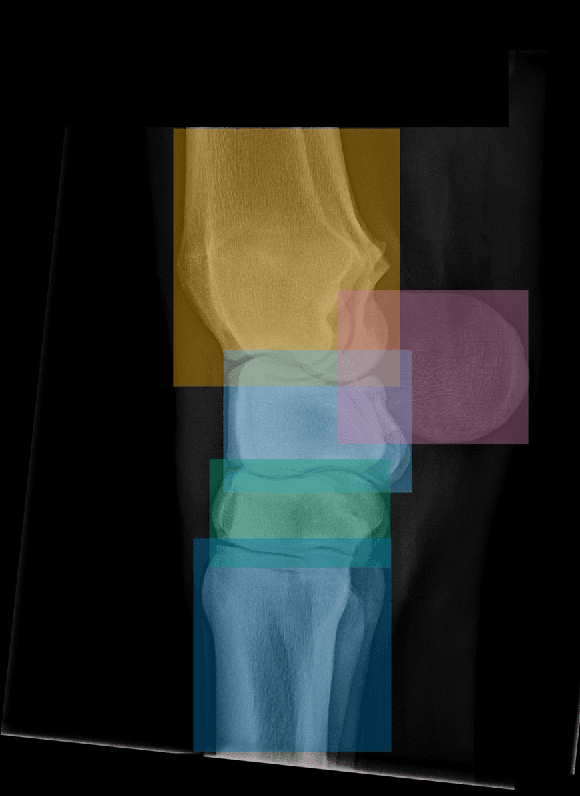
Background: Object detection in radiograph computer vision has largely benefited from progress in deep convolutional neural networks and can, for example, annotate a radiograph with a box around a knee joint or intervertebral disc. Is deep learning capable of detect small (less than 1% of the image) in radiographs? And how many radiographs do we need use when re-training a deep learning model? Methods: We annotated 396 radiographs of left and right carpi dorsal 75 medial to palmarolateral oblique (DMPLO) projection with the location of radius, proximal row of carpal bones, distal row of carpal bones, accessory carpal bone, first carpal bone (if present), and metacarpus (metacarpal II, III, and IV). The radiographs and respective annotations were splited into sets that were used to leave-one-out cross-validation of models created using transfer learn from YOLOv5s. Results: Models trained using 96 radiographs or more achieved precision, recall and mAP above 0.95, including for the first carpal bone, when trained for 32 epochs. The best model needed the double of epochs to learn to detect the first carpal bone compared with the other bones. Conclusions: Free and open source state of the art object detection models based on deep learning can be re-trained for radiograph computer vision applications with 100 radiographs and achieved precision, recall and mAP above 0.95.
Multi-Camera Collaborative Depth Prediction via Consistent Structure Estimation
Oct 05, 2022
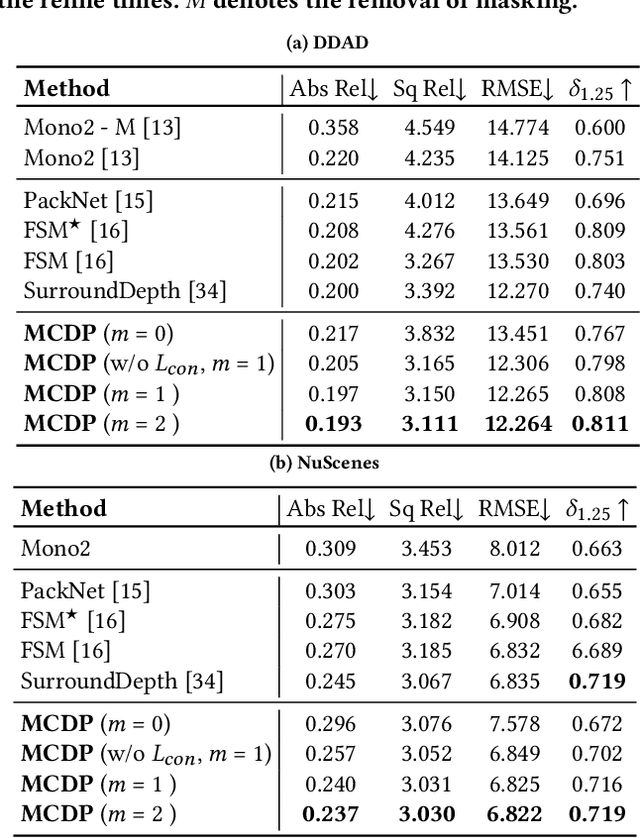

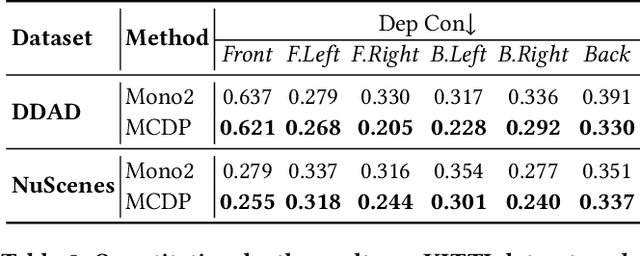
Depth map estimation from images is an important task in robotic systems. Existing methods can be categorized into two groups including multi-view stereo and monocular depth estimation. The former requires cameras to have large overlapping areas and sufficient baseline between cameras, while the latter that processes each image independently can hardly guarantee the structure consistency between cameras. In this paper, we propose a novel multi-camera collaborative depth prediction method that does not require large overlapping areas while maintaining structure consistency between cameras. Specifically, we formulate the depth estimation as a weighted combination of depth basis, in which the weights are updated iteratively by a refinement network driven by the proposed consistency loss. During the iterative update, the results of depth estimation are compared across cameras and the information of overlapping areas is propagated to the whole depth maps with the help of basis formulation. Experimental results on DDAD and NuScenes datasets demonstrate the superior performance of our method.