 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single Domain Generalization for Crowd Counting
Mar 14, 2024

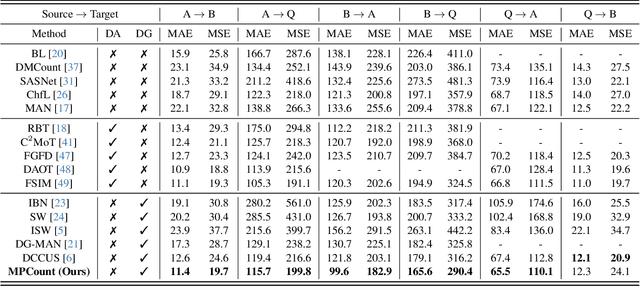
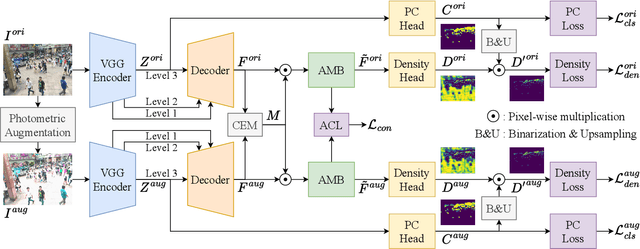
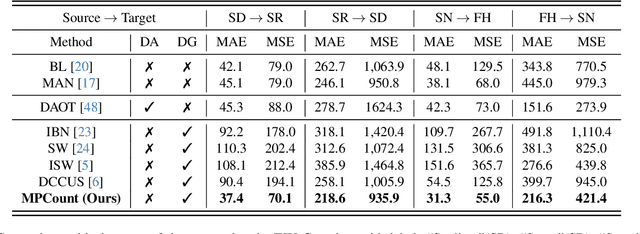
Current image-based crowd counting widely employs density map regression due to its promising results. However, the method often suffers from severe performance degradation when tested on data from unseen scenarios. To address this so-called "domain shift" problem, we investigate single domain generalization (SDG) for crowd counting. The existing SDG approaches are mainly for classification and segmentation, and can hardly be extended to our case due to its regression nature and label ambiguity (i.e., ambiguous pixel-level ground truths). We propose MPCount, a novel SDG approach effective even for narrow source distribution. Reconstructing diverse features for density map regression with a single memory bank, MPCount retains only domain-invariant representations using a content error mask and attention consistency loss. It further introduces patch-wise classification as an auxiliary task to boost the robustness of density prediction to achieve highly accurate labels. Through extensive experiments on different datasets, MPCount is shown to significantly improve counting accuracy compared to the state of the art under diverse scenarios unobserved in the training data of narrow source distribution. Code is available at https://github.com/Shimmer93/MPCount.
LocalMamba: Visual State Space Model with Windowed Selective Scan
Mar 14, 2024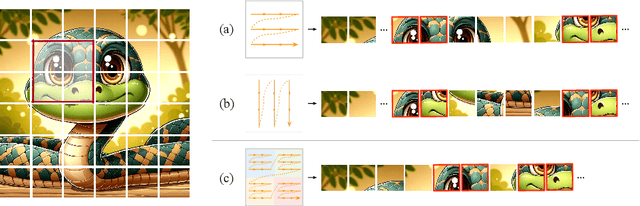
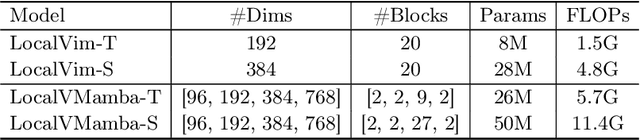
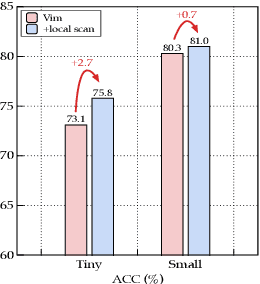
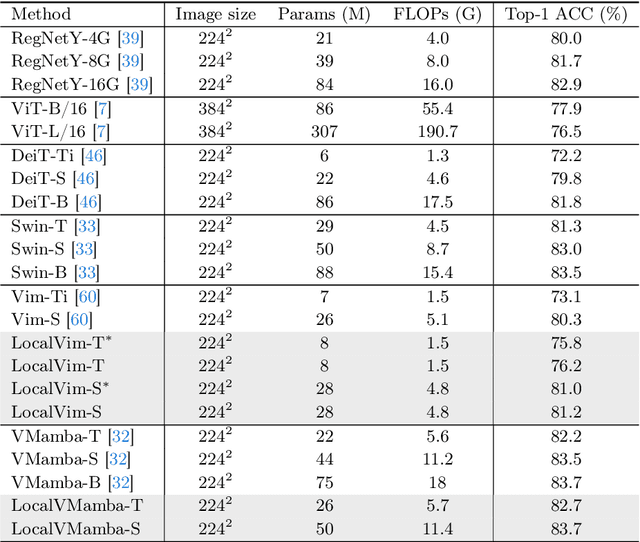
Recent advancements in state space models, notably Mamba, have demonstrated significant progress in modeling long sequences for tasks like language understanding. Yet, their application in vision tasks has not markedly surpassed the performance of traditional Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). This paper posits that the key to enhancing Vision Mamba (ViM) lies in optimizing scan directions for sequence modeling. Traditional ViM approaches, which flatten spatial tokens, overlook the preservation of local 2D dependencies, thereby elongating the distance between adjacent tokens. We introduce a novel local scanning strategy that divides images into distinct windows, effectively capturing local dependencies while maintaining a global perspective. Additionally, acknowledging the varying preferences for scan patterns across different network layers, we propose a dynamic method to independently search for the optimal scan choices for each layer, substantially improving performance. Extensive experiments across both plain and hierarchical models underscore our approach's superiority in effectively capturing image representations. For example, our model significantly outperforms Vim-Ti by 3.1% on ImageNet with the same 1.5G FLOPs. Code is available at: https://github.com/hunto/LocalMamba.
Improving Real-Time Omnidirectional 3D Multi-Person Human Pose Estimation with People Matching and Unsupervised 2D-3D Lifting
Mar 14, 2024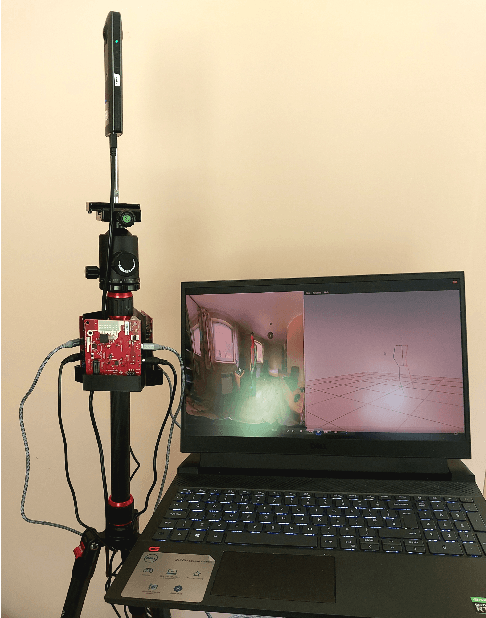
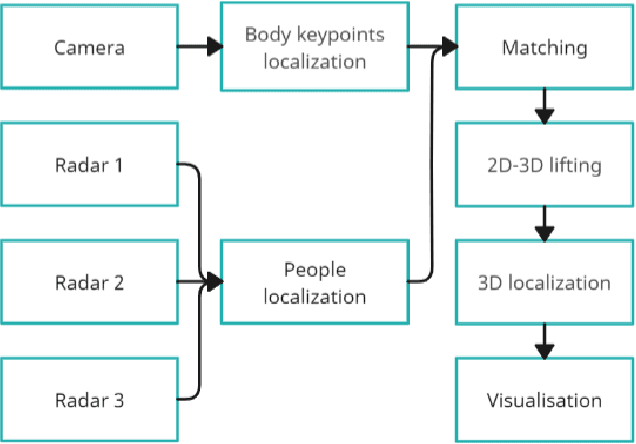
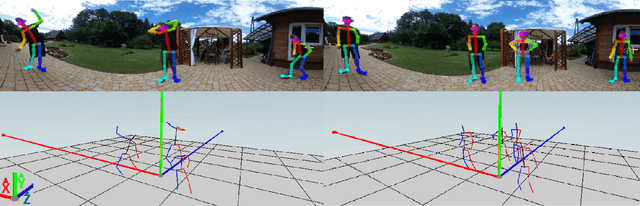
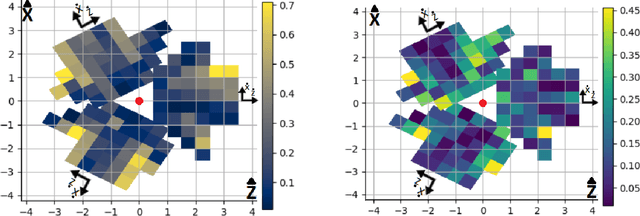
Current human pose estimation systems focus on retrieving an accurate 3D global estimate of a single person. Therefore, this paper presents one of the first 3D multi-person human pose estimation systems that is able to work in real-time and is also able to handle basic forms of occlusion. First, we adjust an off-the-shelf 2D detector and an unsupervised 2D-3D lifting model for use with a 360$^\circ$ panoramic camera and mmWave radar sensors. We then introduce several contributions, including camera and radar calibrations, and the improved matching of people within the image and radar space. The system addresses both the depth and scale ambiguity problems by employing a lightweight 2D-3D pose lifting algorithm that is able to work in real-time while exhibiting accurate performance in both indoor and outdoor environments which offers both an affordable and scalable solution. Notably, our system's time complexity remains nearly constant irrespective of the number of detected individuals, achieving a frame rate of approximately 7-8 fps on a laptop with a commercial-grade GPU.
GaussCtrl: Multi-View Consistent Text-Driven 3D Gaussian Splatting Editing
Mar 14, 2024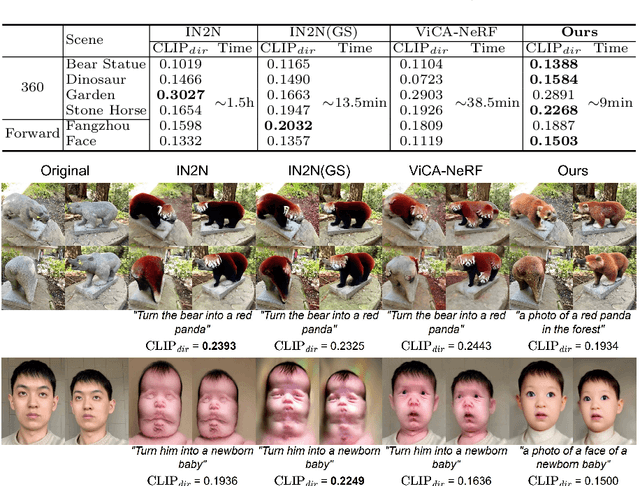
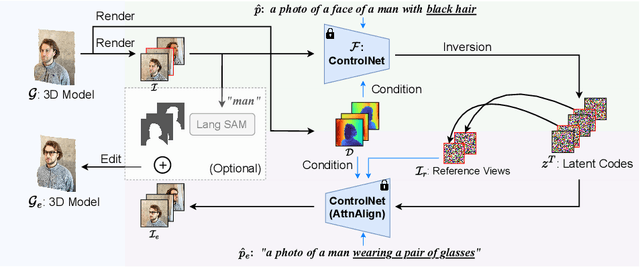


We propose GaussCtrl, a text-driven method to edit a 3D scene reconstructed by the 3D Gaussian Splatting (3DGS). Our method first renders a collection of images by using the 3DGS and edits them by using a pre-trained 2D diffusion model (ControlNet) based on the input prompt, which is then used to optimise the 3D model. Our key contribution is multi-view consistent editing, which enables editing all images together instead of iteratively editing one image while updating the 3D model as in previous works. It leads to faster editing as well as higher visual quality. This is achieved by the two terms: (a) depth-conditioned editing that enforces geometric consistency across multi-view images by leveraging naturally consistent depth maps. (b) attention-based latent code alignment that unifies the appearance of edited images by conditioning their editing to several reference views through self and cross-view attention between images' latent representations. Experiments demonstrate that our method achieves faster editing and better visual results than previous state-of-the-art methods.
UniCode: Learning a Unified Codebook for Multimodal Large Language Models
Mar 14, 2024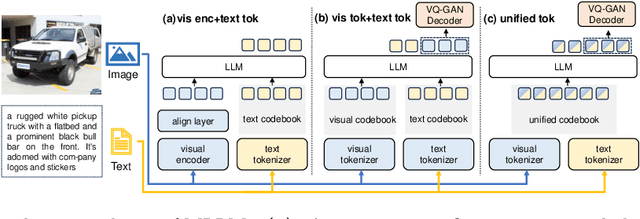

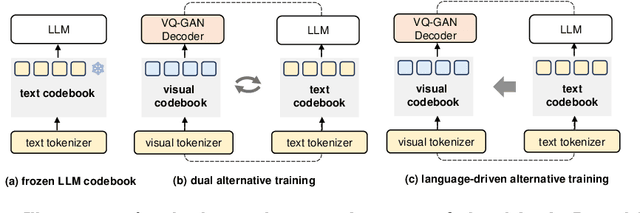
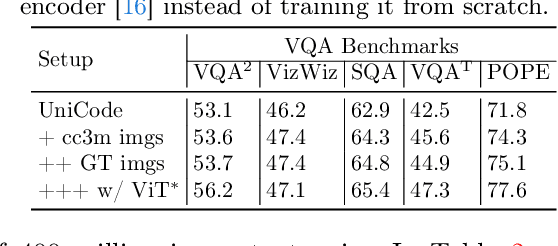
In this paper, we propose \textbf{UniCode}, a novel approach within the domain of multimodal large language models (MLLMs) that learns a unified codebook to efficiently tokenize visual, text, and potentially other types of signals. This innovation addresses a critical limitation in existing MLLMs: their reliance on a text-only codebook, which restricts MLLM's ability to generate images and texts in a multimodal context. Towards this end, we propose a language-driven iterative training paradigm, coupled with an in-context pre-training task we term ``image decompression'', enabling our model to interpret compressed visual data and generate high-quality images.The unified codebook empowers our model to extend visual instruction tuning to non-linguistic generation tasks. Moreover, UniCode is adaptable to diverse stacked quantization approaches in order to compress visual signals into a more compact token representation. Despite using significantly fewer parameters and less data during training, Unicode demonstrates promising capabilities in visual reconstruction and generation. It also achieves performances comparable to leading MLLMs across a spectrum of VQA benchmarks.
V-PRISM: Probabilistic Mapping of Unknown Tabletop Scenes
Mar 14, 2024

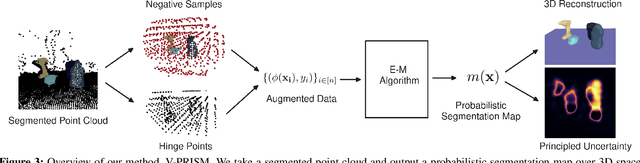
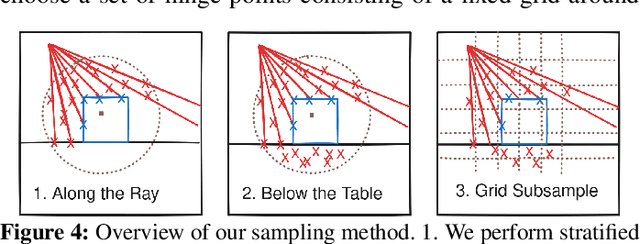
The ability to construct concise scene representations from sensor input is central to the field of robotics. This paper addresses the problem of robustly creating a 3D representation of a tabletop scene from a segmented RGB-D image. These representations are then critical for a range of downstream manipulation tasks. Many previous attempts to tackle this problem do not capture accurate uncertainty, which is required to subsequently produce safe motion plans. In this paper, we cast the representation of 3D tabletop scenes as a multi-class classification problem. To tackle this, we introduce V-PRISM, a framework and method for robustly creating probabilistic 3D segmentation maps of tabletop scenes. Our maps contain both occupancy estimates, segmentation information, and principled uncertainty measures. We evaluate the robustness of our method in (1) procedurally generated scenes using open-source object datasets, and (2) real-world tabletop data collected from a depth camera. Our experiments show that our approach outperforms alternative continuous reconstruction approaches that do not explicitly reason about objects in a multi-class formulation.
Cloud gap-filling with deep learning for improved grassland monitoring
Mar 14, 2024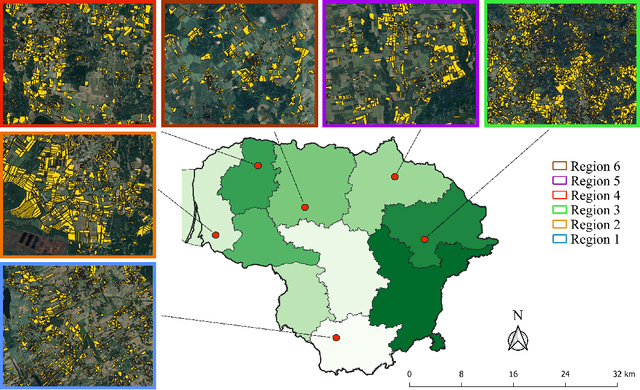
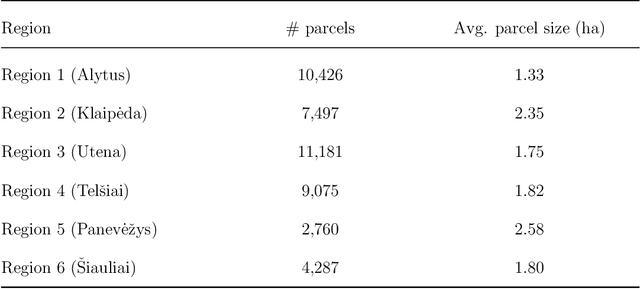

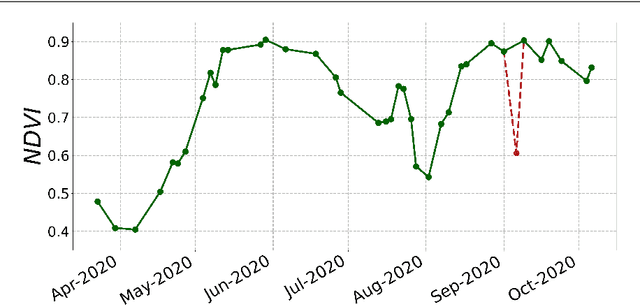
Uninterrupted optical image time series are crucial for the timely monitoring of agricultural land changes. However, the continuity of such time series is often disrupted by clouds. In response to this challenge, we propose a deep learning method that integrates cloud-free optical (Sentinel-2) observations and weather-independent (Sentinel-1) Synthetic Aperture Radar (SAR) data, using a combined Convolutional Neural Network (CNN)-Recurrent Neural Network (RNN) architecture to generate continuous Normalized Difference Vegetation Index (NDVI) time series. We emphasize the significance of observation continuity by assessing the impact of the generated time series on the detection of grassland mowing events. We focus on Lithuania, a country characterized by extensive cloud coverage, and compare our approach with alternative interpolation techniques (i.e., linear, Akima, quadratic). Our method surpasses these techniques, with an average MAE of 0.024 and R^2 of 0.92. It not only improves the accuracy of event detection tasks by employing a continuous time series, but also effectively filters out sudden shifts and noise originating from cloudy observations that cloud masks often fail to detect.
Unleashing Network Potentials for Semantic Scene Completion
Mar 14, 2024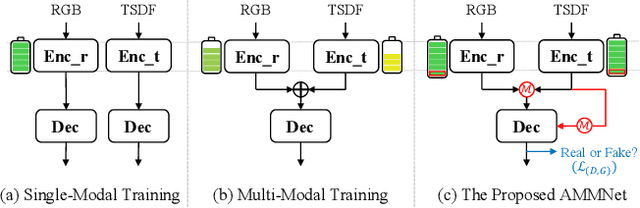
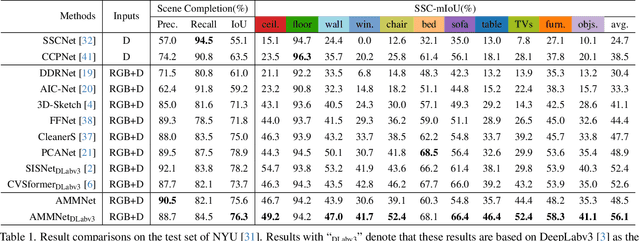
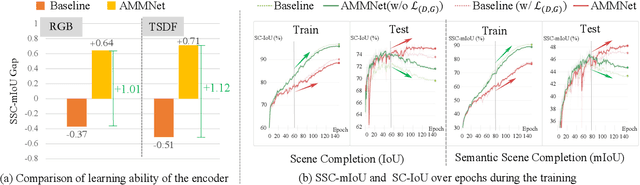
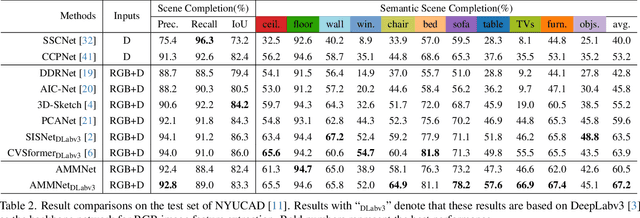
Semantic scene completion (SSC) aims to predict complete 3D voxel occupancy and semantics from a single-view RGB-D image, and recent SSC methods commonly adopt multi-modal inputs. However, our investigation reveals two limitations: ineffective feature learning from single modalities and overfitting to limited datasets. To address these issues, this paper proposes a novel SSC framework - Adversarial Modality Modulation Network (AMMNet) - with a fresh perspective of optimizing gradient updates. The proposed AMMNet introduces two core modules: a cross-modal modulation enabling the interdependence of gradient flows between modalities, and a customized adversarial training scheme leveraging dynamic gradient competition. Specifically, the cross-modal modulation adaptively re-calibrates the features to better excite representation potentials from each single modality. The adversarial training employs a minimax game of evolving gradients, with customized guidance to strengthen the generator's perception of visual fidelity from both geometric completeness and semantic correctness. Extensive experimental results demonstrate that AMMNet outperforms state-of-the-art SSC methods by a large margin, providing a promising direction for improving the effectiveness and generalization of SSC methods.
A Decade's Battle on Dataset Bias: Are We There Yet?
Mar 13, 2024

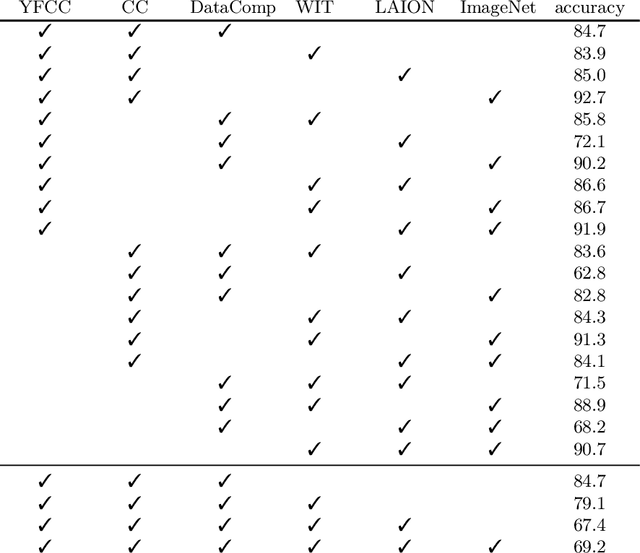
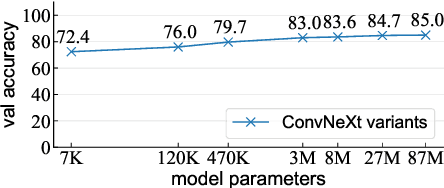
We revisit the "dataset classification" experiment suggested by Torralba and Efros a decade ago, in the new era with large-scale, diverse, and hopefully less biased datasets as well as more capable neural network architectures. Surprisingly, we observe that modern neural networks can achieve excellent accuracy in classifying which dataset an image is from: e.g., we report 84.7% accuracy on held-out validation data for the three-way classification problem consisting of the YFCC, CC, and DataComp datasets. Our further experiments show that such a dataset classifier could learn semantic features that are generalizable and transferable, which cannot be simply explained by memorization. We hope our discovery will inspire the community to rethink the issue involving dataset bias and model capabilities.
Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
Mar 15, 2024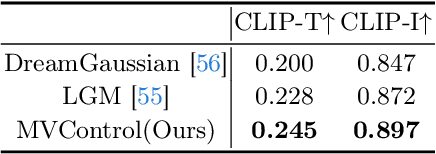
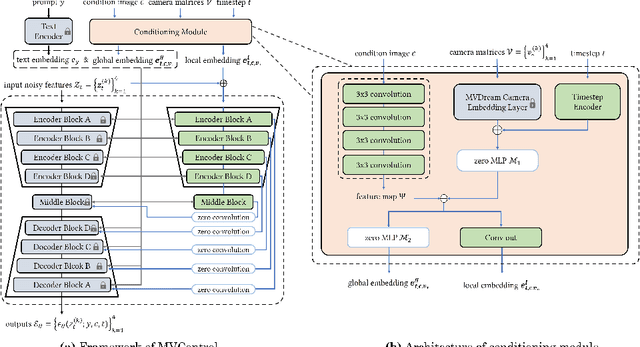
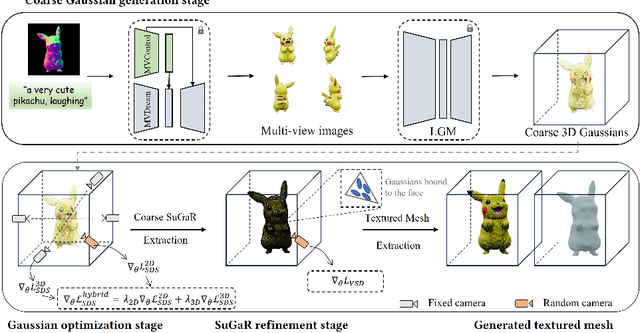

While text-to-3D and image-to-3D generation tasks have received considerable attention, one important but under-explored field between them is controllable text-to-3D generation, which we mainly focus on in this work. To address this task, 1) we introduce Multi-view ControlNet (MVControl), a novel neural network architecture designed to enhance existing pre-trained multi-view diffusion models by integrating additional input conditions, such as edge, depth, normal, and scribble maps. Our innovation lies in the introduction of a conditioning module that controls the base diffusion model using both local and global embeddings, which are computed from the input condition images and camera poses. Once trained, MVControl is able to offer 3D diffusion guidance for optimization-based 3D generation. And, 2) we propose an efficient multi-stage 3D generation pipeline that leverages the benefits of recent large reconstruction models and score distillation algorithm. Building upon our MVControl architecture, we employ a unique hybrid diffusion guidance method to direct the optimization process. In pursuit of efficiency, we adopt 3D Gaussians as our representation instead of the commonly used implicit representations. We also pioneer the use of SuGaR, a hybrid representation that binds Gaussians to mesh triangle faces. This approach alleviates the issue of poor geometry in 3D Gaussians and enables the direct sculpting of fine-grained geometry on the mesh. Extensive experiments demonstrate that our method achieves robust generalization and enables the controllable generation of high-quality 3D content.