 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast and High-Quality Image Denoising via Malleable Convolutions
Jan 04, 2022
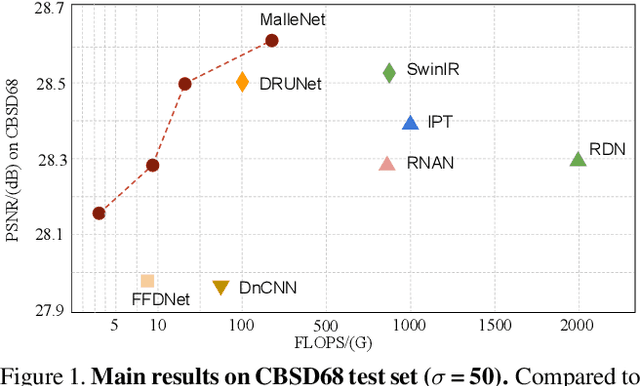
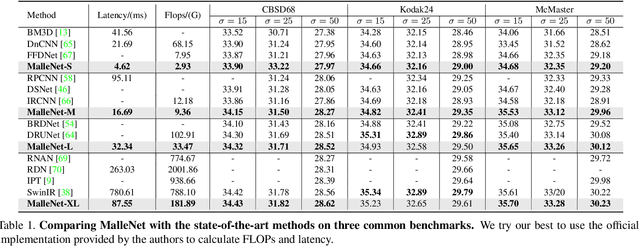
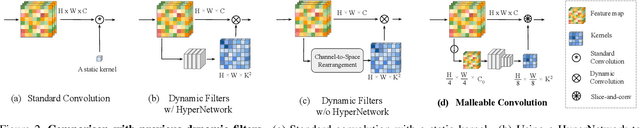
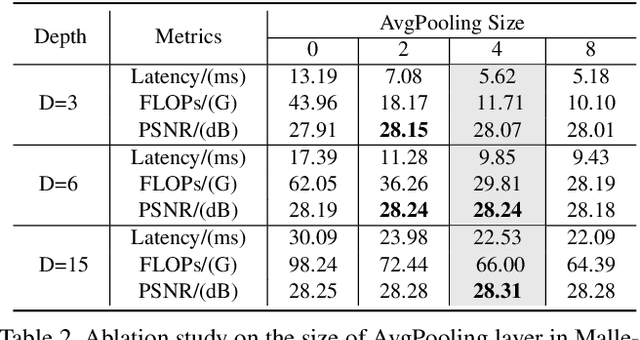
Many image processing networks apply a single set of static convolutional kernels across the entire input image, which is sub-optimal for natural images, as they often consist of heterogeneous visual patterns. Recent works in classification, segmentation, and image restoration have demonstrated that dynamic kernels outperform static kernels at modeling local image statistics. However, these works often adopt per-pixel convolution kernels, which introduce high memory and computation costs. To achieve spatial-varying processing without significant overhead, we present Malleable Convolution (MalleConv), as an efficient variant of dynamic convolution. The weights of MalleConv are dynamically produced by an efficient predictor network capable of generating content-dependent outputs at specific spatial locations. Unlike previous works, MalleConv generates a much smaller set of spatially-varying kernels from input, which enlarges the network's receptive field and significantly reduces computational and memory costs. These kernels are then applied to a full-resolution feature map through an efficient slice-and-conv operator with minimum memory overhead. We further build an efficient denoising network using MalleConv, coined as MalleNet. It achieves high quality results without very deep architecture, e.g., reaching 8.91x faster speed compared to the best performed denoising algorithms (SwinIR), while maintaining similar performance. We also show that a single MalleConv added to a standard convolution-based backbone can contribute significantly to reducing the computational cost or boosting image quality at a similar cost. Project page: https://yifanjiang.net/MalleConv.html
Intelligent Masking: Deep Q-Learning for Context Encoding in Medical Image Analysis
Apr 04, 2022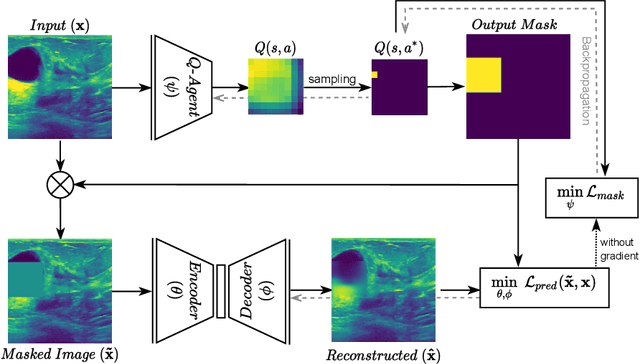
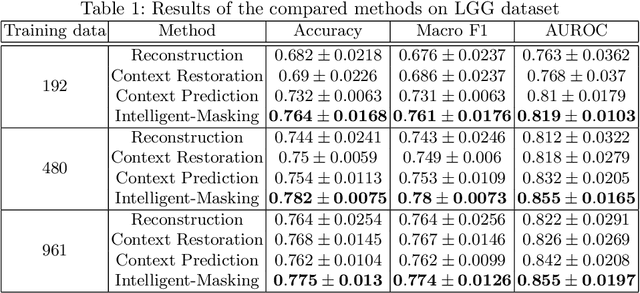
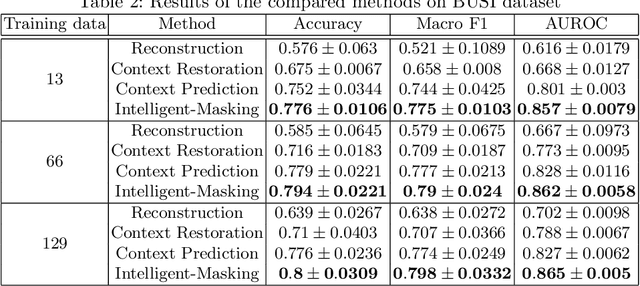
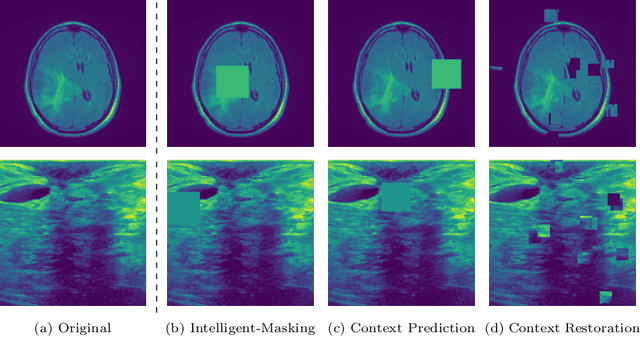
The need for a large amount of labeled data in the supervised setting has led recent studies to utilize self-supervised learning to pre-train deep neural networks using unlabeled data. Many self-supervised training strategies have been investigated especially for medical datasets to leverage the information available in the much fewer unlabeled data. One of the fundamental strategies in image-based self-supervision is context prediction. In this approach, a model is trained to reconstruct the contents of an arbitrary missing region of an image based on its surroundings. However, the existing methods adopt a random and blind masking approach by focusing uniformly on all regions of the images. This approach results in a lot of unnecessary network updates that cause the model to forget the rich extracted features. In this work, we develop a novel self-supervised approach that occludes targeted regions to improve the pre-training procedure. To this end, we propose a reinforcement learning-based agent which learns to intelligently mask input images through deep Q-learning. We show that training the agent against the prediction model can significantly improve the semantic features extracted for downstream classification tasks. We perform our experiments on two public datasets for diagnosing breast cancer in the ultrasound images and detecting lower-grade glioma with MR images. In our experiments, we show that our novel masking strategy advances the learned features according to the performance on the classification task in terms of accuracy, macro F1, and AUROC.
Toward 3D Spatial Reasoning for Human-like Text-based Visual Question Answering
Sep 21, 2022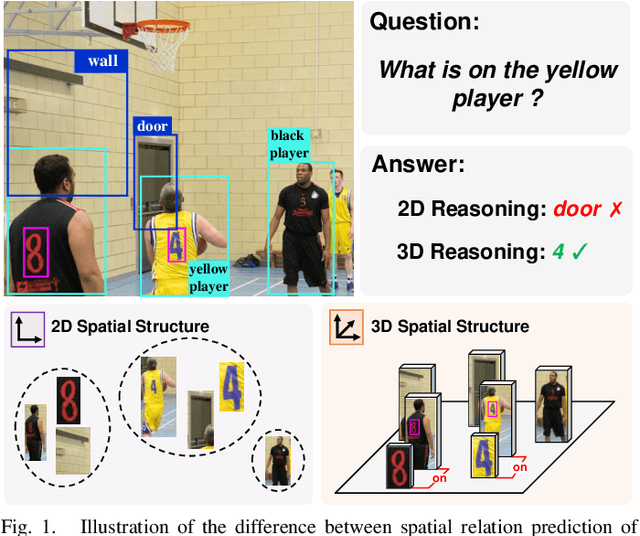
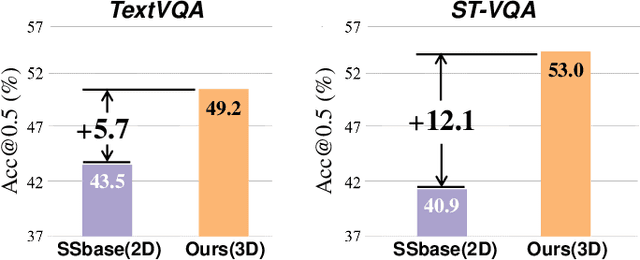
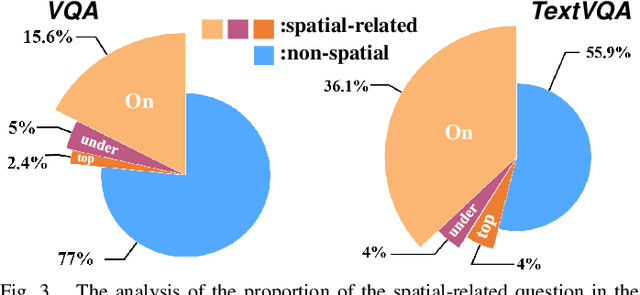
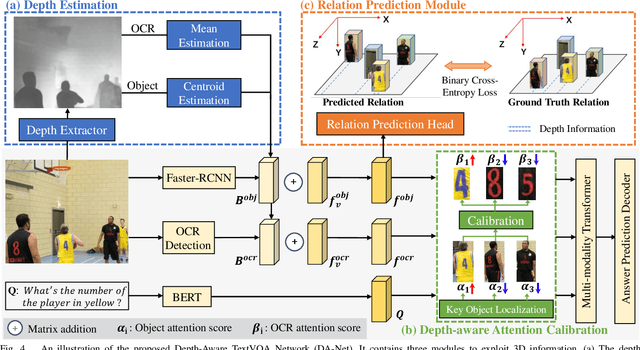
Text-based Visual Question Answering~(TextVQA) aims to produce correct answers for given questions about the images with multiple scene texts. In most cases, the texts naturally attach to the surface of the objects. Therefore, spatial reasoning between texts and objects is crucial in TextVQA. However, existing approaches are constrained within 2D spatial information learned from the input images and rely on transformer-based architectures to reason implicitly during the fusion process. Under this setting, these 2D spatial reasoning approaches cannot distinguish the fine-grain spatial relations between visual objects and scene texts on the same image plane, thereby impairing the interpretability and performance of TextVQA models. In this paper, we introduce 3D geometric information into a human-like spatial reasoning process to capture the contextual knowledge of key objects step-by-step. %we formulate a human-like spatial reasoning process by introducing 3D geometric information for capturing key objects' contextual knowledge. To enhance the model's understanding of 3D spatial relationships, Specifically, (i)~we propose a relation prediction module for accurately locating the region of interest of critical objects; (ii)~we design a depth-aware attention calibration module for calibrating the OCR tokens' attention according to critical objects. Extensive experiments show that our method achieves state-of-the-art performance on TextVQA and ST-VQA datasets. More encouragingly, our model surpasses others by clear margins of 5.7\% and 12.1\% on questions that involve spatial reasoning in TextVQA and ST-VQA valid split. Besides, we also verify the generalizability of our model on the text-based image captioning task.
Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning
Aug 08, 2022
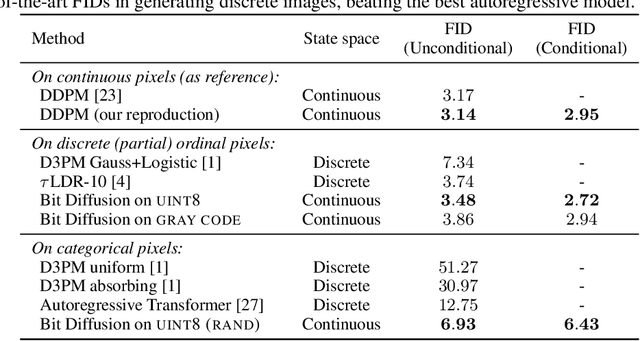


We present Bit Diffusion: a simple and generic approach for generating discrete data with continuous diffusion models. The main idea behind our approach is to first represent the discrete data as binary bits, and then train a continuous diffusion model to model these bits as real numbers which we call analog bits. To generate samples, the model first generates the analog bits, which are then thresholded to obtain the bits that represent the discrete variables. We further propose two simple techniques, namely Self-Conditioning and Asymmetric Time Intervals, which lead to a significant improvement in sample quality. Despite its simplicity, the proposed approach can achieve strong performance in both discrete image generation and image captioning tasks. For discrete image generation, we significantly improve previous state-of-the-art on both CIFAR-10 (which has 3K discrete 8-bit tokens) and ImageNet-64x64 (which has 12K discrete 8-bit tokens), outperforming the best autoregressive model in both sample quality (measured by FID) and efficiency. For image captioning on MS-COCO dataset, our approach achieves competitive results compared to autoregressive models.
Target and Task specific Source-Free Domain Adaptive Image Segmentation
Mar 29, 2022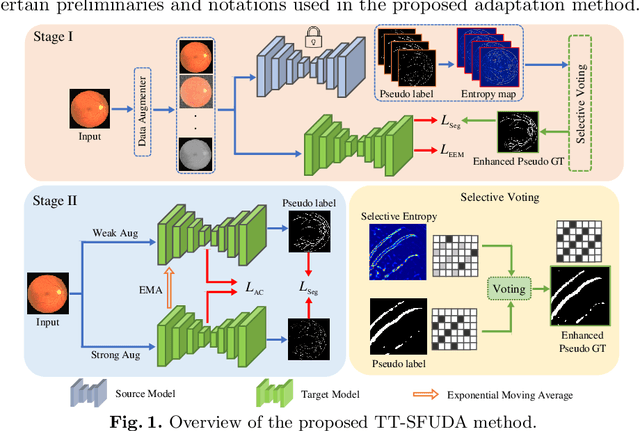
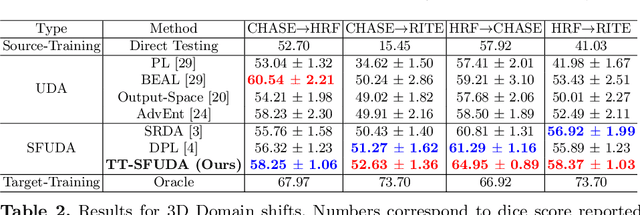

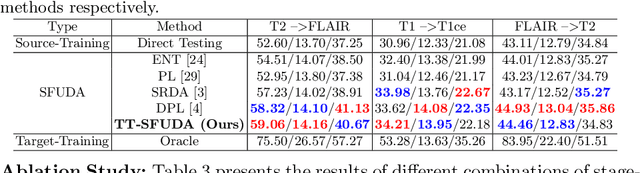
Solving the domain shift problem during inference is essential in medical imaging as most deep-learning based solutions suffer from it. In practice, domain shifts are tackled by performing Unsupervised Domain Adaptation (UDA), where a model is adapted to an unlabeled target domain by leveraging the labelled source domain. In medical scenarios, the data comes with huge privacy concerns making it difficult to apply standard UDA techniques. Hence, a closer clinical setting is Source-Free UDA (SFUDA), where we have access to source trained model but not the source data during adaptation. Methods trying to solve SFUDA typically address the domain shift using pseudo-label based self-training techniques. However, due to domain shift, these pseudo-labels are usually of high entropy and denoising them still does not make them perfect labels to supervise the model. Therefore, adapting the source model with noisy pseudo labels reduces its segmentation capability while addressing the domain shift. To this end, we propose a two-stage approach for source-free domain adaptive image segmentation: 1) Target-specific adaptation followed by 2) Task-specific adaptation. In the first stage, we focus on generating target-specific pseudo labels while suppressing high entropy regions by proposing an Ensemble Entropy Minimization loss. We also introduce a selective voting strategy to enhance pseudo-label generation. In the second stage, we focus on adapting the network for task-specific representation by using a teacher-student self-training approach based on augmentation-guided consistency. We evaluate our proposed method on both 2D fundus datasets and 3D MRI volumes across 7 different domain shifts where we achieve better performance than recent UDA and SF-UDA methods for medical image segmentation. Code is available at https://github.com/Vibashan/tt-sfuda.
OCR for TIFF Compressed Document Images Directly in Compressed Domain Using Text segmentation and Hidden Markov Model
Sep 13, 2022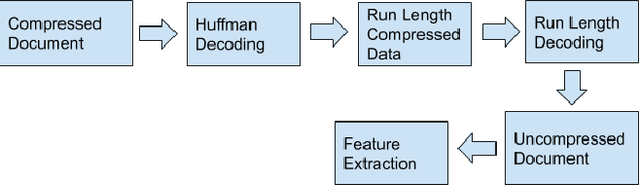

In today's technological era, document images play an important and integral part in our day to day life, and specifically with the surge of Covid-19, digitally scanned documents have become key source of communication, thus avoiding any sort of infection through physical contact. Storage and transmission of scanned document images is a very memory intensive task, hence compression techniques are being used to reduce the image size before archival and transmission. To extract information or to operate on the compressed images, we have two ways of doing it. The first way is to decompress the image and operate on it and subsequently compress it again for the efficiency of storage and transmission. The other way is to use the characteristics of the underlying compression algorithm to directly process the images in their compressed form without involving decompression and re-compression. In this paper, we propose a novel idea of developing an OCR for CCITT (The International Telegraph and Telephone Consultative Committee) compressed machine printed TIFF document images directly in the compressed domain. After segmenting text regions into lines and words, HMM is applied for recognition using three coding modes of CCITT- horizontal, vertical and the pass mode. Experimental results show that OCR on pass modes give a promising results.
Adaptive sampling for scanning pixel cameras
Aug 01, 2022
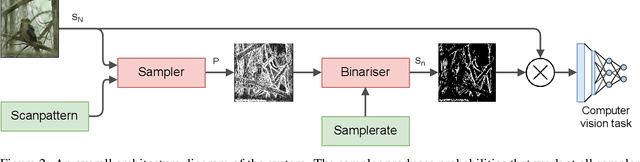
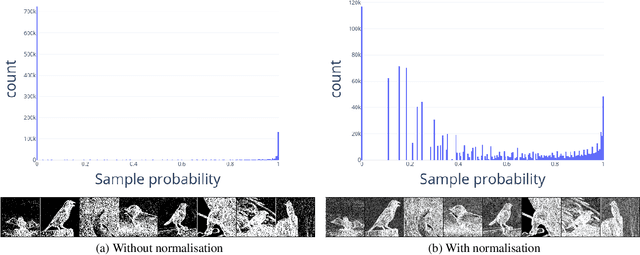
A scanning pixel camera is a novel low-cost, low-power sensor that is not diffraction limited. It produces data as a sequence of samples extracted from various parts of the scene during the course of a scan. It can provide very detailed images at the expense of samplerates and slow image acquisition time. This paper proposes a new algorithm which allows the sensor to adapt the samplerate over the course of this sequence. This makes it possible to overcome some of these limitations by minimising the bandwidth and time required to image and transmit a scene, while maintaining image quality. We examine applications to image classification and semantic segmentation and are able to achieve similar results compared to a fully sampled input, while using 80% fewer samples
The Value of AI Guidance in Human Examination of Synthetically-Generated Faces
Aug 22, 2022



Face image synthesis has progressed beyond the point at which humans can effectively distinguish authentic faces from synthetically generated ones. Recently developed synthetic face image detectors boast "better-than-human" discriminative ability, especially those guided by human perceptual intelligence during the model's training process. In this paper, we investigate whether these human-guided synthetic face detectors can assist non-expert human operators in the task of synthetic image detection when compared to models trained without human-guidance. We conducted a large-scale experiment with more than 1,560 subjects classifying whether an image shows an authentic or synthetically-generated face, and annotate regions that supported their decisions. In total, 56,015 annotations across 3,780 unique face images were collected. All subjects first examined samples without any AI support, followed by samples given (a) the AI's decision ("synthetic" or "authentic"), (b) class activation maps illustrating where the model deems salient for its decision, or (c) both the AI's decision and AI's saliency map. Synthetic faces were generated with six modern Generative Adversarial Networks. Interesting observations from this experiment include: (1) models trained with human-guidance offer better support to human examination of face images when compared to models trained traditionally using cross-entropy loss, (2) binary decisions presented to humans offers better support than saliency maps, (3) understanding the AI's accuracy helps humans to increase trust in a given model and thus increase their overall accuracy. This work demonstrates that although humans supported by machines achieve better-than-random accuracy of synthetic face detection, the ways of supplying humans with AI support and of building trust are key factors determining high effectiveness of the human-AI tandem.
Analysis of Master Vein Attacks on Finger Vein Recognition Systems
Oct 18, 2022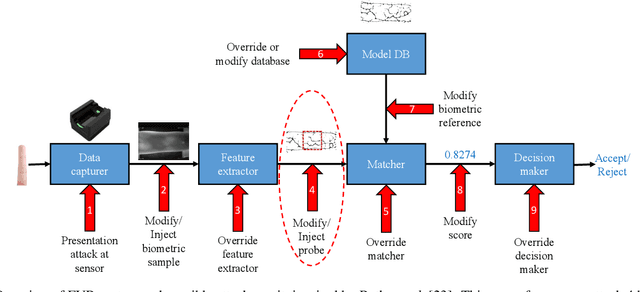
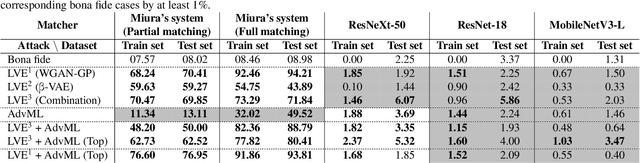
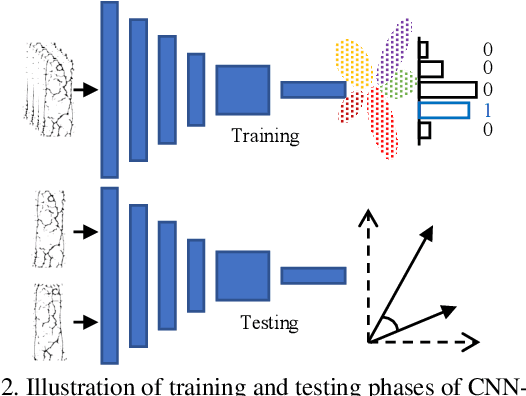
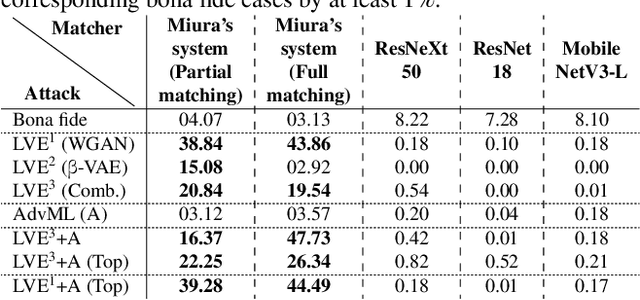
Finger vein recognition (FVR) systems have been commercially used, especially in ATMs, for customer verification. Thus, it is essential to measure their robustness against various attack methods, especially when a hand-crafted FVR system is used without any countermeasure methods. In this paper, we are the first in the literature to introduce master vein attacks in which we craft a vein-looking image so that it can falsely match with as many identities as possible by the FVR systems. We present two methods for generating master veins for use in attacking these systems. The first uses an adaptation of the latent variable evolution algorithm with a proposed generative model (a multi-stage combination of beta-VAE and WGAN-GP models). The second uses an adversarial machine learning attack method to attack a strong surrogate CNN-based recognition system. The two methods can be easily combined to boost their attack ability. Experimental results demonstrated that the proposed methods alone and together achieved false acceptance rates up to 73.29% and 88.79%, respectively, against Miura's hand-crafted FVR system. We also point out that Miura's system is easily compromised by non-vein-looking samples generated by a WGAN-GP model with false acceptance rates up to 94.21%. The results raise the alarm about the robustness of such systems and suggest that master vein attacks should be considered an important security measure.
Vision Paper: Causal Inference for Interpretable and Robust Machine Learning in Mobility Analysis
Oct 18, 2022Artificial intelligence (AI) is revolutionizing many areas of our lives, leading a new era of technological advancement. Particularly, the transportation sector would benefit from the progress in AI and advance the development of intelligent transportation systems. Building intelligent transportation systems requires an intricate combination of artificial intelligence and mobility analysis. The past few years have seen rapid development in transportation applications using advanced deep neural networks. However, such deep neural networks are difficult to interpret and lack robustness, which slows the deployment of these AI-powered algorithms in practice. To improve their usability, increasing research efforts have been devoted to developing interpretable and robust machine learning methods, among which the causal inference approach recently gained traction as it provides interpretable and actionable information. Moreover, most of these methods are developed for image or sequential data which do not satisfy specific requirements of mobility data analysis. This vision paper emphasizes research challenges in deep learning-based mobility analysis that require interpretability and robustness, summarizes recent developments in using causal inference for improving the interpretability and robustness of machine learning methods, and highlights opportunities in developing causally-enabled machine learning models tailored for mobility analysis. This research direction will make AI in the transportation sector more interpretable and reliable, thus contributing to safer, more efficient, and more sustainable future transportation systems.